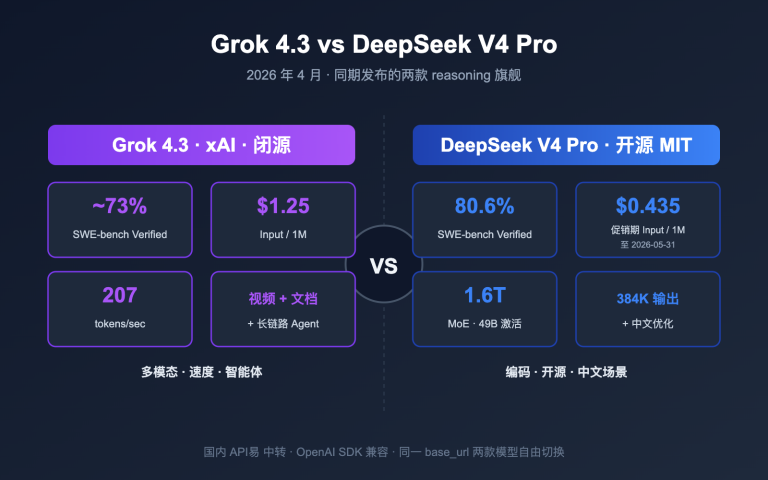
智谱AI在 2026 年 2 月 11 日正式发布了 GLM-5,这是目前参数规模最大的开源大语言模型之一。GLM-5 采用 744B MoE 混合专家架构,每次推理激活 40B 参数,在推理、编码和 Agent 任务上达到了开源模型的最佳水平。
核心价值: 读完本文,你将掌握 GLM-5 的技术架构原理、API 调用方法、Thinking 推理模式配置,以及如何在实际项目中发挥这个 744B 开源旗舰模型的最大价值。

GLM-5 核心参数一览
在深入技术细节之前,先看一下 GLM-5 的关键参数:
| 参数 | 数值 | 说明 |
|---|---|---|
| 总参数量 | 744B (7440 亿) | 当前最大开源模型之一 |
| 活跃参数 | 40B (400 亿) | 每次推理实际使用 |
| 架构类型 | MoE 混合专家 | 256 专家,每 token 激活 8 个 |
| 上下文窗口 | 200,000 tokens | 支持超长文档处理 |
| 最大输出 | 128,000 tokens | 满足长文本生成需求 |
| 预训练数据 | 28.5T tokens | 较上代增加 24% |
| 许可证 | Apache-2.0 | 完全开源,支持商业使用 |
| 训练硬件 | 华为昇腾芯片 | 全国产算力,不依赖海外硬件 |
GLM-5 的一个显著特点是它完全基于华为昇腾芯片和 MindSpore 框架训练,实现了对国产算力栈的完整验证。这对于国内开发者来说,意味着技术栈的自主可控又多了一个强有力的选择。
GLM 系列版本演进
GLM-5 是智谱AI GLM 系列的第五代产品,每一代都有显著的能力跃升:
| 版本 | 发布时间 | 参数规模 | 核心突破 |
|---|---|---|---|
| GLM-4 | 2024-01 | 未公开 | 多模态基础能力 |
| GLM-4.5 | 2025-03 | 355B (32B 活跃) | MoE 架构首次引入 |
| GLM-4.5-X | 2025-06 | 同上 | 强化推理,旗舰定位 |
| GLM-4.7 | 2025-10 | 未公开 | Thinking 推理模式 |
| GLM-4.7-FlashX | 2025-12 | 未公开 | 超低成本快速推理 |
| GLM-5 | 2026-02 | 744B (40B 活跃) | Agent 能力突破,幻觉率降 56% |
从 GLM-4.5 的 355B 到 GLM-5 的 744B,总参数量翻了一倍多;活跃参数从 32B 提升到 40B,增幅 25%;预训练数据从 23T 增加到 28.5T tokens。这些数字背后是智谱AI在算力、数据和算法三个维度上的全面投入。
🚀 快速体验: GLM-5 已上线 API易 apiyi.com,价格与官网一致,充值加赠活动下来大约可以享受 8 折优惠,适合想要快速体验这款 744B 旗舰模型的开发者。
GLM-5 MoE 架构技术解析
GLM-5 为什么选择 MoE 架构
MoE (Mixture of Experts) 是当前大模型扩展的主流技术路线。相比 Dense 架构 (所有参数都参与每次推理),MoE 架构只激活一小部分专家网络来处理每个 token,在保持大模型知识容量的同时大幅降低推理成本。
GLM-5 的 MoE 架构设计有以下关键特性:
| 架构特性 | GLM-5 实现 | 技术价值 |
|---|---|---|
| 专家总数 | 256 个 | 知识容量极大 |
| 每 token 激活 | 8 个专家 | 推理效率高 |
| 稀疏率 | 5.9% | 仅使用小部分参数 |
| 注意力机制 | DSA + MLA | 降低部署成本 |
| 内存优化 | MLA 减少 33% | 显存占用更低 |
简单来说,GLM-5 虽然有 744B 参数,但每次推理只激活 40B (约 5.9%),这意味着它的推理成本远低于同等规模的 Dense 模型,同时又能利用 744B 参数所蕴含的丰富知识。
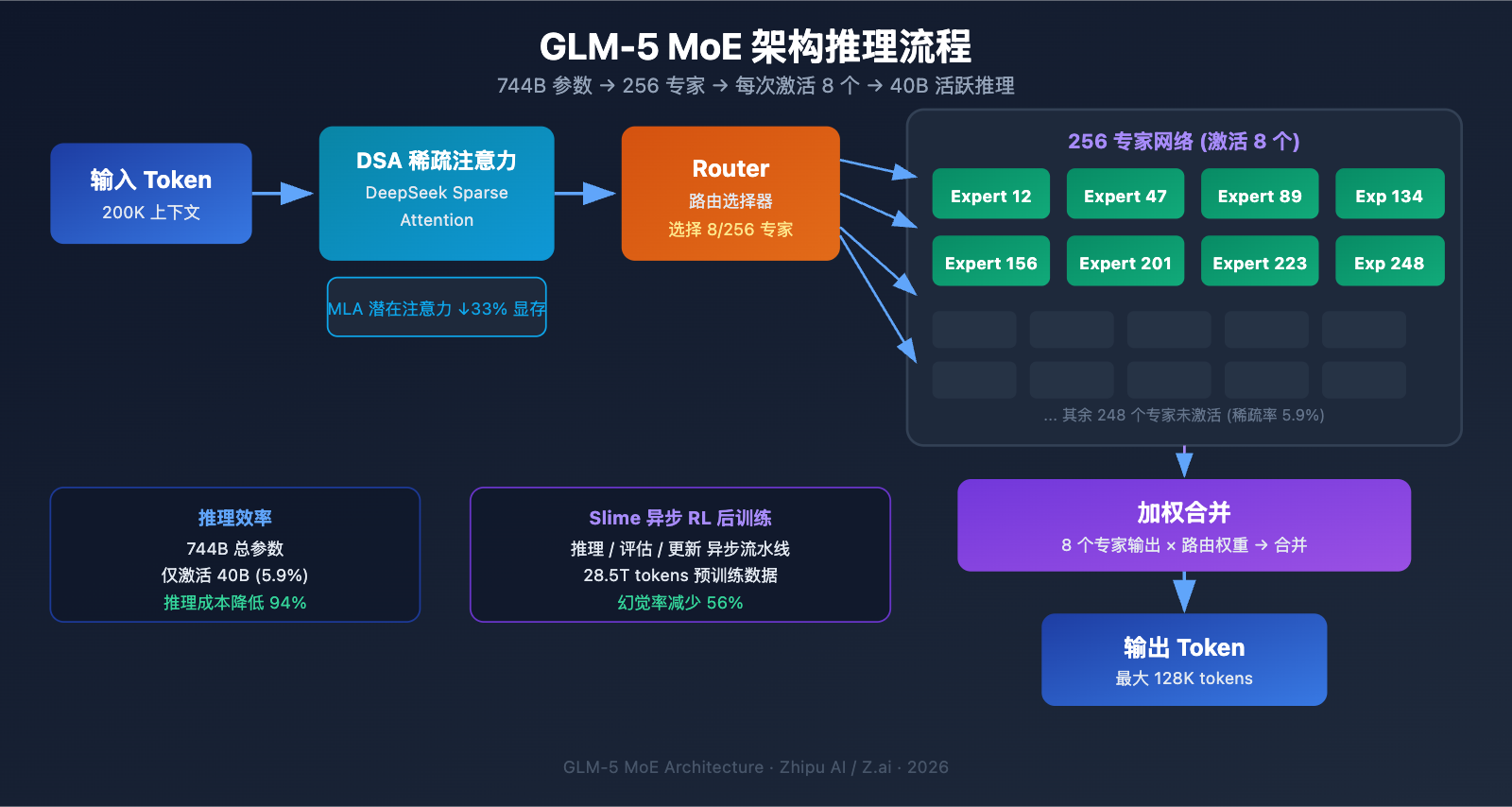
GLM-5 的 DeepSeek Sparse Attention (DSA)
GLM-5 集成了 DeepSeek Sparse Attention 机制,这项技术在保持长上下文能力的同时,显著降低了部署成本。配合 Multi-head Latent Attention (MLA),GLM-5 在 200K tokens 的超长上下文窗口下依然能够高效运行。
具体来说:
- DSA (DeepSeek Sparse Attention): 通过稀疏注意力模式减少注意力计算的复杂度。传统的全注意力机制在处理 200K tokens 时计算量极大,DSA 通过选择性关注关键 token 位置来降低计算开销,同时保持信息的完整性
- MLA (Multi-head Latent Attention): 将注意力头的 KV 缓存压缩到潜在空间中,减少约 33% 的内存占用。在长上下文场景下,KV 缓存通常是显存的主要消耗者,MLA 有效缓解了这个瓶颈
这两项技术的结合意味着:即使是 744B 规模的模型,通过 FP8 量化后也可以在 8 张 GPU 上运行,大幅降低了部署门槛。
GLM-5 后训练: Slime 异步 RL 系统
GLM-5 采用了名为 "slime" 的新型异步强化学习基础设施进行后训练。传统的 RL 训练存在效率瓶颈——生成、评估和更新步骤之间存在大量等待时间。Slime 通过异步化这些步骤,实现了更细粒度的后训练迭代,大幅提升训练吞吐量。
传统 RL 训练流程中,模型需要先完成一批推理、等待评估结果、再进行参数更新,三个步骤串行执行。Slime 将这三个步骤解耦为独立的异步流水线,使得推理、评估和更新可以并行进行,从而显著提升了训练效率。
这项技术改进直接反映在了 GLM-5 的幻觉率上——较前代版本减少了 56%。更充分的后训练迭代让模型在事实准确性上获得了明显改善。
GLM-5 与 Dense 架构的对比
为了更好地理解 MoE 架构的优势,我们可以将 GLM-5 与假设的同等规模 Dense 模型进行对比:
| 对比维度 | GLM-5 (744B MoE) | 假设 744B Dense | 实际差异 |
|---|---|---|---|
| 每次推理参数 | 40B (5.9%) | 744B (100%) | MoE 减少 94% |
| 推理显存需求 | 8x GPU (FP8) | 约 96x GPU | MoE 显著更低 |
| 推理速度 | 较快 | 极慢 | MoE 更适合实际部署 |
| 知识容量 | 744B 全量知识 | 744B 全量知识 | 相当 |
| 专业化能力 | 不同专家擅长不同任务 | 统一处理 | MoE 更精细 |
| 训练成本 | 较高但可控 | 极高 | MoE 性价比更优 |
MoE 架构的核心优势在于: 它用 744B 参数的知识容量,换来了仅需 40B 参数推理成本的高效率。这就是为什么 GLM-5 能在保持前沿性能的同时,提供远低于同级别闭源模型的定价。
GLM-5 API 调用快速上手
GLM-5 API 请求参数详解
在编写代码之前,先了解 GLM-5 的 API 参数配置:
| 参数 | 类型 | 必需 | 默认值 | 说明 |
|---|---|---|---|---|
model |
string | ✅ | – | 固定为 "glm-5" |
messages |
array | ✅ | – | 标准 chat 格式消息 |
max_tokens |
int | ❌ | 4096 | 最大输出 token 数 (上限 128K) |
temperature |
float | ❌ | 1.0 | 采样温度,越低越确定 |
top_p |
float | ❌ | 1.0 | 核采样参数 |
stream |
bool | ❌ | false | 是否流式输出 |
thinking |
object | ❌ | disabled | {"type": "enabled"} 开启推理 |
tools |
array | ❌ | – | Function Calling 工具定义 |
tool_choice |
string | ❌ | auto | 工具选择策略 |
GLM-5 极简调用示例
GLM-5 兼容 OpenAI SDK 接口格式,只需更换 base_url 和 model 参数即可快速接入:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易统一接口
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "你是一位资深的 AI 技术专家"},
{"role": "user", "content": "解释 MoE 混合专家架构的工作原理和优势"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
上面这段代码就是 GLM-5 最基础的调用方式。模型 ID 使用 glm-5,接口完全兼容 OpenAI 的 chat.completions 格式,现有项目迁移只需修改两个参数。
GLM-5 Thinking 推理模式
GLM-5 支持 Thinking 推理模式,类似 DeepSeek R1 和 Claude 的扩展思考能力。启用后,模型会在回答前进行内部链式推理,对复杂数学、逻辑和编程问题的表现显著提升:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易统一接口
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "证明: 对于所有正整数 n, n^3 - n 能被 6 整除"}
],
extra_body={
"thinking": {"type": "enabled"}
},
temperature=1.0 # Thinking 模式建议使用 1.0
)
print(response.choices[0].message.content)
GLM-5 Thinking 模式使用建议:
| 场景 | 是否开启 Thinking | temperature 建议 | 说明 |
|---|---|---|---|
| 数学证明/竞赛题 | ✅ 开启 | 1.0 | 需要深度推理 |
| 代码调试/架构设计 | ✅ 开启 | 1.0 | 需要系统分析 |
| 逻辑推理/分析 | ✅ 开启 | 1.0 | 需要链式思考 |
| 日常对话/写作 | ❌ 关闭 | 0.5-0.7 | 不需要复杂推理 |
| 信息提取/摘要 | ❌ 关闭 | 0.3-0.5 | 追求稳定输出 |
| 创意内容生成 | ❌ 关闭 | 0.8-1.0 | 需要多样性 |
GLM-5 流式输出
对于需要实时交互的场景,GLM-5 支持流式输出,用户可以在模型生成的过程中逐步看到结果:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
stream = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "用 Python 实现一个带缓存的 HTTP 客户端"}
],
stream=True,
temperature=0.6
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
GLM-5 Function Calling 与 Agent 构建
GLM-5 原生支持 Function Calling,这是构建 Agent 系统的核心能力。GLM-5 在 HLE w/ Tools 上拿到 50.4% 的成绩超越了 Claude Opus (43.4%),说明它在工具调用和任务编排上表现出色:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "search_documents",
"description": "搜索知识库中的相关文档",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "搜索关键词"},
"top_k": {"type": "integer", "description": "返回结果数量", "default": 5}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "execute_code",
"description": "在沙箱环境中执行 Python 代码",
"parameters": {
"type": "object",
"properties": {
"code": {"type": "string", "description": "要执行的 Python 代码"},
"timeout": {"type": "integer", "description": "超时时间(秒)", "default": 30}
},
"required": ["code"]
}
}
}
]
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "你是一个能够搜索文档和执行代码的AI助手"},
{"role": "user", "content": "帮我查一下 GLM-5 的技术参数,然后用代码画一个性能对比图"}
],
tools=tools,
tool_choice="auto"
)
# 处理工具调用
message = response.choices[0].message
if message.tool_calls:
for tool_call in message.tool_calls:
print(f"调用工具: {tool_call.function.name}")
print(f"参数: {tool_call.function.arguments}")
查看 cURL 调用示例
curl https://api.apiyi.com/v1/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5",
"messages": [
{"role": "system", "content": "你是一位资深软件工程师"},
{"role": "user", "content": "设计一个分布式任务调度系统的架构"}
],
"max_tokens": 8192,
"temperature": 0.7,
"stream": true
}'
🎯 技术建议: GLM-5 兼容 OpenAI SDK 格式,现有项目只需修改
base_url和model两个参数即可迁移。通过 API易 apiyi.com 平台调用,可以享受统一接口管理和充值加赠优惠。
GLM-5 Benchmark 性能实测
GLM-5 核心 Benchmark 数据
GLM-5 在多个主流 benchmark 上展现了开源模型的最强水平:
| Benchmark | GLM-5 | Claude Opus 4.5 | GPT-5 | 测试内容 |
|---|---|---|---|---|
| MMLU | 85.0% | 88.7% | 90.2% | 57 学科知识 |
| MMLU Pro | 70.4% | – | – | 增强版多学科 |
| GPQA | 68.2% | 71.4% | 73.1% | 研究生级科学 |
| HumanEval | 90.0% | 93.2% | 92.5% | Python 编程 |
| MATH | 88.0% | 90.1% | 91.3% | 数学推理 |
| GSM8k | 97.0% | 98.2% | 98.5% | 数学应用题 |
| AIME 2026 I | 92.7% | 93.3% | – | 数学竞赛 |
| SWE-bench | 77.8% | 80.9% | 80.0% | 真实软件工程 |
| HLE w/ Tools | 50.4% | 43.4% | – | 带工具推理 |
| IFEval | 88.0% | – | – | 指令遵循 |
| Terminal-Bench | 56.2% | 57.9% | – | 终端操作 |
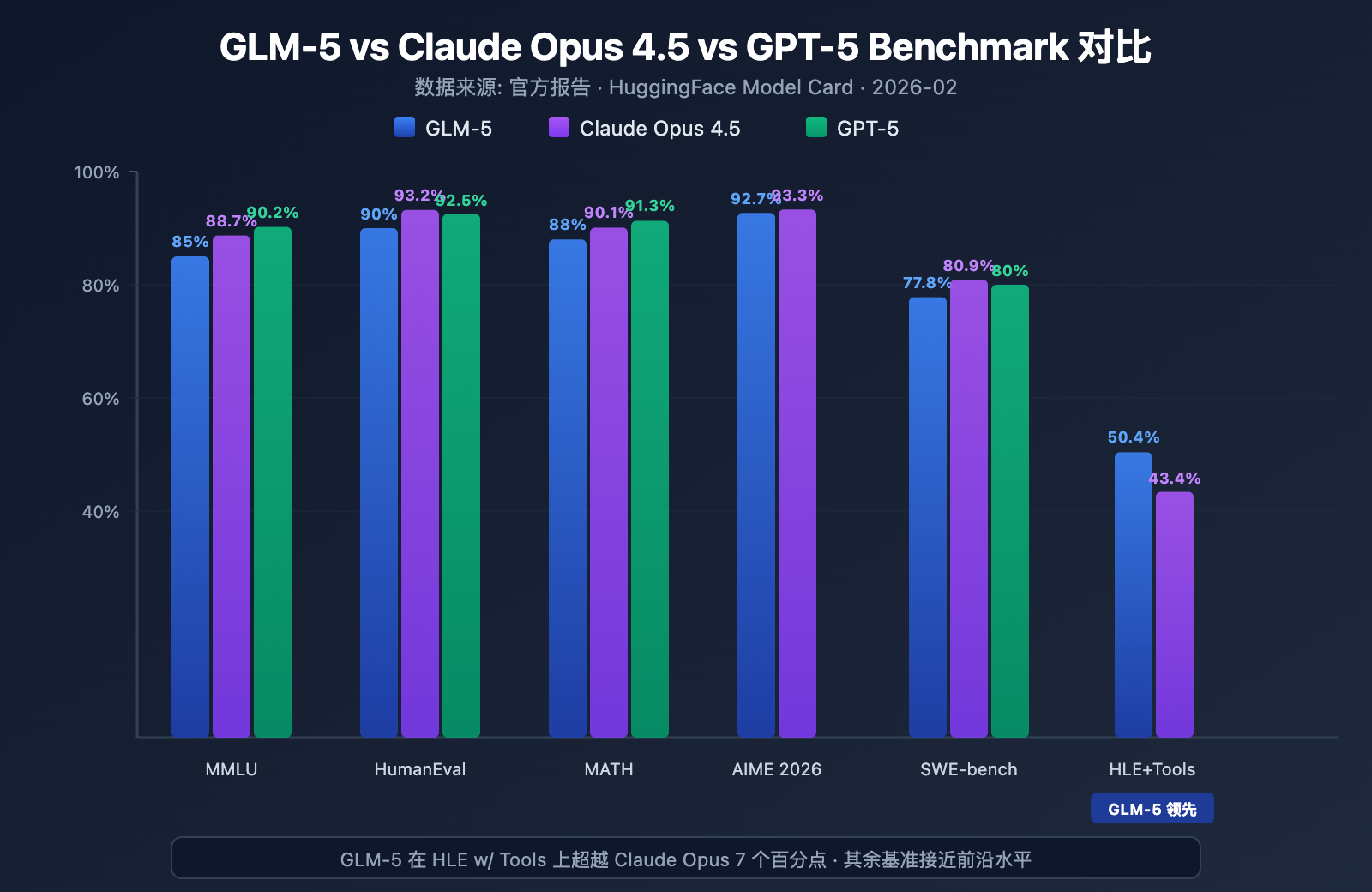
GLM-5 性能分析: 4 大核心优势
从 benchmark 数据可以看到几个值得关注的点:
1. GLM-5 Agent 能力: HLE w/ Tools 超越闭源模型
GLM-5 在 Humanity's Last Exam (带工具使用) 上拿到了 50.4% 的成绩,超越了 Claude Opus 的 43.4%,仅次于 Kimi K2.5 的 51.8%。这说明 GLM-5 在 Agent 场景下——需要规划、调用工具、迭代求解的复杂任务中——已经具备了前沿模型水平。
这个结果与 GLM-5 的设计理念一致: 它从架构到后训练都针对 Agent 工作流进行了专门优化。对于想要构建 AI Agent 系统的开发者来说,GLM-5 提供了一个开源且高性价比的选择。
2. GLM-5 编码能力: 进入第一梯队
HumanEval 90%、SWE-bench Verified 77.8%,说明 GLM-5 在代码生成和真实软件工程任务上已经非常接近 Claude Opus (80.9%) 和 GPT-5 (80.0%) 的水平。作为开源模型,SWE-bench 77.8% 是一个重要的突破——这意味着 GLM-5 已经能够理解真实的 GitHub issue、定位代码问题并提交有效的修复。
3. GLM-5 数学推理: 接近天花板
AIME 2026 I 上 GLM-5 拿到 92.7%,仅落后 Claude Opus 0.6 个百分点。GSM8k 97% 也说明在中等难度的数学问题上,GLM-5 已经非常可靠。MATH 88% 的成绩同样位于第一梯队。
4. GLM-5 幻觉控制: 大幅降低
根据官方数据,GLM-5 较前代版本幻觉率减少了 56%。这得益于 Slime 异步 RL 系统带来的更充分的后训练迭代。在需要高准确性的信息提取、文档摘要和知识库问答场景中,更低的幻觉率直接转化为更可靠的输出质量。
GLM-5 与同级开源模型的定位
在当前开源大模型竞争格局中,GLM-5 的定位比较明确:
| 模型 | 参数规模 | 架构 | 核心优势 | 许可证 |
|---|---|---|---|---|
| GLM-5 | 744B (40B 活跃) | MoE | Agent + 低幻觉 | Apache-2.0 |
| DeepSeek V3 | 671B (37B 活跃) | MoE | 性价比 + 推理 | MIT |
| Llama 4 Maverick | 400B (17B 活跃) | MoE | 多模态 + 生态 | Llama License |
| Qwen 3 | 235B | Dense | 多语言 + 工具 | Apache-2.0 |
GLM-5 的差异化优势主要体现在三个方面: Agent 工作流的专门优化 (HLE w/ Tools 领先)、极低的幻觉率 (减少 56%)、以及全国产算力训练所带来的供应链安全。对于需要在国内部署前沿开源模型的企业来说,GLM-5 是一个值得重点关注的选项。
GLM-5 定价与成本分析
GLM-5 官方定价
| 计费类型 | Z.ai 官方价格 | OpenRouter 价格 | 说明 |
|---|---|---|---|
| 输入 Token | $1.00/M | $0.80/M | 每百万输入 token |
| 输出 Token | $3.20/M | $2.56/M | 每百万输出 token |
| 缓存输入 | $0.20/M | $0.16/M | 缓存命中时的输入价格 |
| 缓存存储 | 暂时免费 | – | 缓存数据存储费用 |
GLM-5 与竞品价格对比
GLM-5 的定价策略非常有竞争力,特别是与闭源前沿模型相比:
| 模型 | 输入 ($/M) | 输出 ($/M) | 相对 GLM-5 成本 | 模型定位 |
|---|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | 基准 | 开源旗舰 |
| Claude Opus 4.6 | $5.00 | $25.00 | 约 5-8x | 闭源旗舰 |
| GPT-5 | $1.25 | $10.00 | 约 1.3-3x | 闭源旗舰 |
| DeepSeek V3 | $0.27 | $1.10 | 约 0.3x | 开源性价比 |
| GLM-4.7 | $0.60 | $2.20 | 约 0.6-0.7x | 上代旗舰 |
| GLM-4.7-FlashX | $0.07 | $0.40 | 约 0.07-0.13x | 超低成本 |
从价格看,GLM-5 定位在 GPT-5 和 DeepSeek V3 之间——比大部分闭源前沿模型便宜很多,但比轻量级开源模型略贵。考虑到 744B 的参数规模和开源最强的性能表现,这个定价是合理的。
GLM 全系列产品线与定价
如果 GLM-5 不完全匹配你的场景,智谱还提供了完整的产品线供选择:
| 模型 | 输入 ($/M) | 输出 ($/M) | 适用场景 |
|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | 复杂推理、Agent、长文档 |
| GLM-5-Code | $1.20 | $5.00 | 代码开发专用 |
| GLM-4.7 | $0.60 | $2.20 | 中等复杂度通用任务 |
| GLM-4.7-FlashX | $0.07 | $0.40 | 高频低成本调用 |
| GLM-4.5-Air | $0.20 | $1.10 | 轻量平衡 |
| GLM-4.7/4.5-Flash | 免费 | 免费 | 入门体验和简单任务 |
💰 成本优化: GLM-5 已上线 API易 apiyi.com,价格与 Z.ai 官方一致。通过平台充值加赠活动,实际使用成本大约可以降到官方价格的 8 折,适合有持续调用需求的团队和开发者。
GLM-5 适用场景与选型建议
GLM-5 适合哪些场景
根据 GLM-5 的技术特点和 benchmark 表现,以下是具体的场景推荐:
强烈推荐的场景:
- Agent 工作流: GLM-5 专为长周期 Agent 任务设计,HLE w/ Tools 50.4% 超越 Claude Opus,适合构建自主规划和工具调用的 Agent 系统
- 代码工程任务: HumanEval 90%、SWE-bench 77.8%,胜任代码生成、Bug 修复、代码审查和架构设计
- 数学与科学推理: AIME 92.7%、MATH 88%,适合数学证明、公式推导和科学计算
- 超长文档分析: 200K 上下文窗口,处理完整代码库、技术文档、法律合同等超长文本
- 低幻觉问答: 幻觉率减少 56%,适合知识库问答、文档摘要等需要高准确性的场景
可以考虑其他方案的场景:
- 多模态任务: GLM-5 本体仅支持文本,需要图像理解请选择 GLM-4.6V 等视觉模型
- 极致低延迟: 744B MoE 模型的推理速度不如小模型,高频低延迟场景建议使用 GLM-4.7-FlashX
- 超低成本批量处理: 大批量文本处理如果对质量要求不高,DeepSeek V3 或 GLM-4.7-FlashX 成本更低
GLM-5 与 GLM-4.7 选型对比
| 对比维度 | GLM-5 | GLM-4.7 | 选型建议 |
|---|---|---|---|
| 参数规模 | 744B (40B 活跃) | 未公开 | GLM-5 更大 |
| 推理能力 | AIME 92.7% | ~85% | 复杂推理选 GLM-5 |
| Agent 能力 | HLE w/ Tools 50.4% | ~38% | Agent 任务选 GLM-5 |
| 编码能力 | HumanEval 90% | ~85% | 代码开发选 GLM-5 |
| 幻觉控制 | 减少 56% | 基准 | 高准确性选 GLM-5 |
| 输入价格 | $1.00/M | $0.60/M | 成本敏感选 GLM-4.7 |
| 输出价格 | $3.20/M | $2.20/M | 成本敏感选 GLM-4.7 |
| 上下文长度 | 200K | 128K+ | 长文档选 GLM-5 |
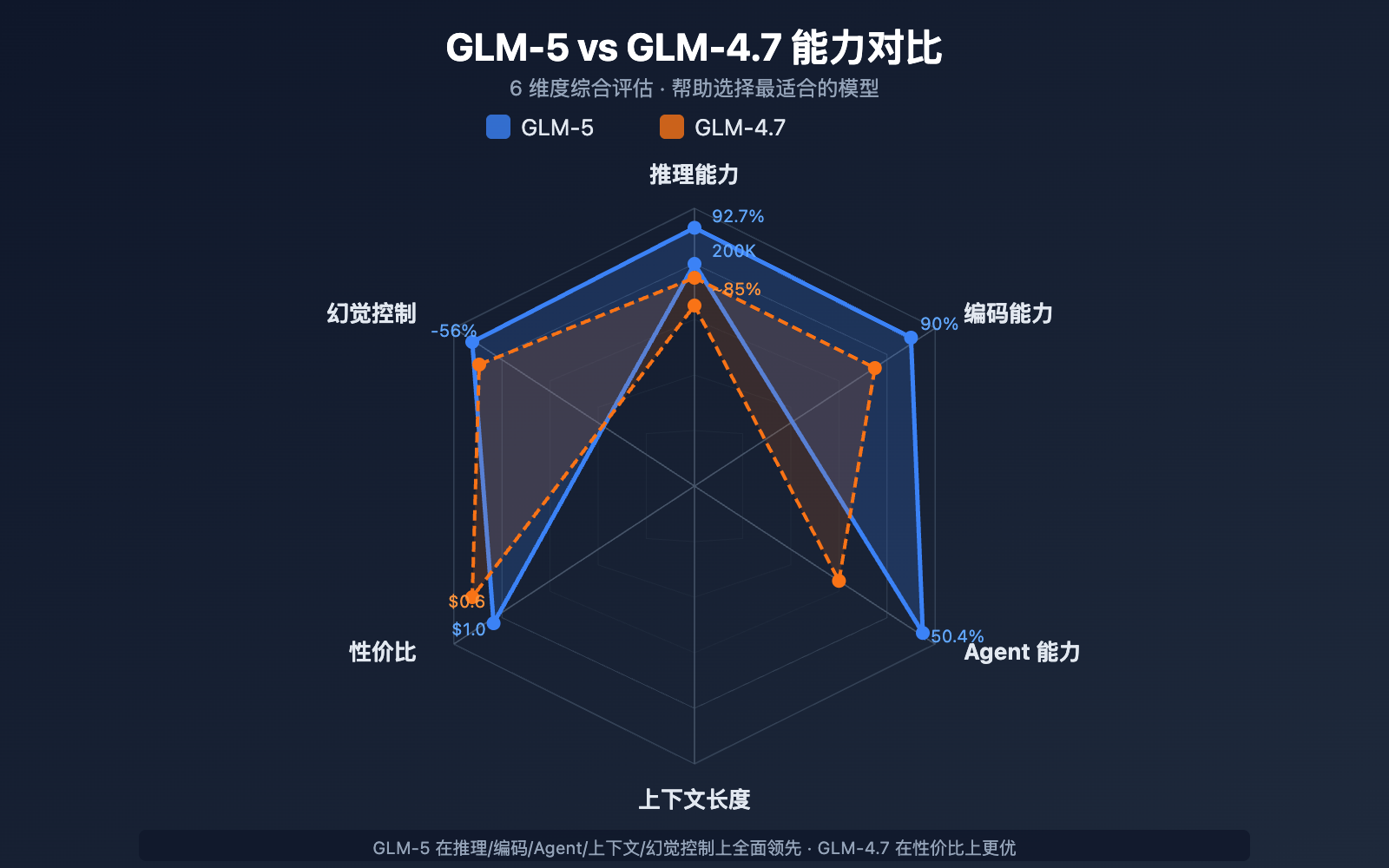
💡 选择建议: 如果你的项目需要顶级推理能力、Agent 工作流或超长上下文处理,GLM-5 是更好的选择。如果预算有限且任务复杂度适中,GLM-4.7 也是不错的性价比方案。两个模型都可以通过 API易 apiyi.com 平台调用,方便随时切换测试。
GLM-5 API 调用常见问题
Q1: GLM-5 和 GLM-5-Code 有什么区别?
GLM-5 是通用旗舰模型 (输入 $1.00/M,输出 $3.20/M),适合各类文本任务。GLM-5-Code 是代码专用增强版 (输入 $1.20/M,输出 $5.00/M),在代码生成、调试和工程任务上经过额外优化。如果你的主要场景是代码开发,GLM-5-Code 值得尝试。两个模型都支持通过统一的 OpenAI 兼容接口调用。
Q2: GLM-5 的 Thinking 模式会影响输出速度吗?
会。Thinking 模式下,GLM-5 会先生成内部推理链再输出最终答案,所以首 token 延迟 (TTFT) 会增加。对于简单问题建议关闭 Thinking 模式以获得更快响应。复杂的数学、编程和逻辑问题建议开启,虽然慢一些但准确率会明显提升。
Q3: 从 GPT-4 或 Claude 迁移到 GLM-5 需要改哪些代码?
迁移非常简单,只需修改两个参数:
- 将
base_url改为 API易的接口地址https://api.apiyi.com/v1 - 将
model参数改为"glm-5"
GLM-5 完全兼容 OpenAI SDK 的 chat.completions 接口格式,包括 system/user/assistant 角色、流式输出、Function Calling 等功能。通过统一的 API 中转平台还可以在同一个 API Key 下切换调用不同厂商的模型,非常方便进行 A/B 测试。
Q4: GLM-5 支持图片输入吗?
不支持。GLM-5 本体是纯文本模型,不支持图像、音频或视频输入。如果需要图像理解能力,可以使用智谱的 GLM-4.6V 或 GLM-4.5V 等视觉变体模型。
Q5: GLM-5 的上下文缓存功能怎么使用?
GLM-5 支持上下文缓存 (Context Caching),缓存输入的价格仅为 $0.20/M,是正常输入的 1/5。在长对话或需要重复处理相同前缀的场景中,缓存功能可以显著降低成本。缓存存储目前暂时免费。在多轮对话中,系统会自动识别并缓存重复的上下文前缀。
Q6: GLM-5 的最大输出长度是多少?
GLM-5 支持最大 128,000 tokens 的输出长度。对于大多数场景,默认的 4096 tokens 就足够了。如果需要生成长文本 (如完整的技术文档、大段代码),可以通过 max_tokens 参数调整。需要注意的是,输出越长,token 消耗和等待时间都会相应增加。
GLM-5 API 调用最佳实践
在实际使用 GLM-5 时,以下几个实践经验可以帮助你获得更好的效果:
GLM-5 System Prompt 优化
GLM-5 对 system prompt 的响应质量很高,合理设计 system prompt 可以显著提升输出质量:
# 推荐: 明确角色定义 + 输出格式要求
messages = [
{
"role": "system",
"content": """你是一位资深的分布式系统架构师。
请遵循以下规则:
1. 回答要结构化,使用 Markdown 格式
2. 给出具体的技术方案而非泛泛而谈
3. 如果涉及代码,提供可运行的示例
4. 在适当位置标注潜在风险和注意事项"""
},
{
"role": "user",
"content": "设计一个支持百万级并发的消息队列系统"
}
]
GLM-5 temperature 调优指南
不同任务对 temperature 的敏感度不同,以下是实测建议:
- temperature 0.1-0.3: 代码生成、数据提取、格式转换等需要精确输出的任务
- temperature 0.5-0.7: 技术文档、问答、摘要等需要稳定且有一定表达灵活度的任务
- temperature 0.8-1.0: 创意写作、头脑风暴等需要多样性的任务
- temperature 1.0 (Thinking 模式): 数学推理、复杂编程等深度推理任务
GLM-5 长上下文处理技巧
GLM-5 支持 200K tokens 的上下文窗口,但在实际使用中需要注意:
- 重要信息前置: 将最关键的上下文放在 prompt 开头位置,而非末尾
- 分段处理: 超过 100K tokens 的文档建议分段处理后合并,以获得更稳定的输出
- 利用缓存: 多轮对话中,相同的前缀内容会自动被缓存,缓存输入价格仅 $0.20/M
- 控制输出长度: 长上下文输入时适当设置
max_tokens,避免输出过长增加不必要的成本
GLM-5 本地部署参考
如果你需要在自有基础设施上部署 GLM-5,以下是主要的部署方式:
| 部署方式 | 推荐硬件 | 精度 | 特点 |
|---|---|---|---|
| vLLM | 8x A100/H100 | FP8 | 主流推理框架,支持投机解码 |
| SGLang | 8x H100/B200 | FP8 | 高性能推理,Blackwell GPU 优化 |
| xLLM | 华为昇腾 NPU | BF16/FP8 | 国产算力适配 |
| KTransformers | 消费级 GPU | 量化 | GPU 加速推理 |
| Ollama | 消费级硬件 | 量化 | 最简单的本地体验 |
GLM-5 提供 BF16 全精度和 FP8 量化两种权重格式,可从 HuggingFace (huggingface.co/zai-org/GLM-5) 或 ModelScope 下载。FP8 量化版本在保持大部分性能的同时,显著降低了显存需求。
部署 GLM-5 需要的关键配置:
- 张量并行: 8 路 (tensor-parallel-size 8)
- 显存利用率: 建议设为 0.85
- 工具调用解析器: glm47
- 推理解析器: glm45
- 投机解码: 支持 MTP 和 EAGLE 两种方式
对于大多数开发者来说,通过 API 调用是最高效的方式,省去了部署运维成本,只需专注于应用开发。需要私有化部署的场景可以参考官方文档:
github.com/zai-org/GLM-5
GLM-5 API 调用总结
GLM-5 核心能力速查
| 能力维度 | GLM-5 表现 | 适用场景 |
|---|---|---|
| 推理 | AIME 92.7%, MATH 88% | 数学证明、科学推理、逻辑分析 |
| 编码 | HumanEval 90%, SWE-bench 77.8% | 代码生成、Bug 修复、架构设计 |
| Agent | HLE w/ Tools 50.4% | 工具调用、任务规划、自主执行 |
| 知识 | MMLU 85%, GPQA 68.2% | 学科问答、技术咨询、知识提取 |
| 指令 | IFEval 88% | 格式化输出、结构化生成、规则遵循 |
| 准确性 | 幻觉率减少 56% | 文档摘要、事实核查、信息提取 |
GLM-5 开源生态价值
GLM-5 采用 Apache-2.0 许可证开源,这意味着:
- 商业自由: 企业可以免费使用、修改和分发,无需支付许可费
- 微调定制: 可以基于 GLM-5 进行领域微调,构建行业专属模型
- 私有部署: 敏感数据不出内网,满足金融、医疗、政府等合规要求
- 社区生态: HuggingFace 上已有 11+ 量化变体和 7+ 微调版本,生态持续扩展
GLM-5 作为智谱AI的最新旗舰模型,在开源大模型领域树立了新的标杆:
- 744B MoE 架构: 256 专家系统,每次推理激活 40B 参数,在模型容量和推理效率之间取得出色平衡
- 开源最强 Agent: HLE w/ Tools 50.4% 超越 Claude Opus,专为长周期 Agent 工作流设计
- 全国产算力训练: 基于 10 万块华为昇腾芯片训练,验证了国产算力栈的前沿模型训练能力
- 高性价比: 输入 $1/M、输出 $3.2/M,远低于同级别闭源模型,开源社区可自由部署和微调
- 200K 超长上下文: 支持完整代码库和大型技术文档的一次性处理,最大输出 128K tokens
- 56% 低幻觉: Slime 异步 RL 后训练大幅提升了事实准确性
推荐通过 API易 apiyi.com 快速体验 GLM-5 的各项能力,平台价格与官方一致,充值加赠活动约可享受 8 折优惠。
本文由 APIYI Team 技术团队撰写,更多 AI 模型使用教程请关注 API易 apiyi.com 帮助中心。