用過 Qwen3.6-Plus 的開發者大概都有同感:在 OpenRouter 上調用這個模型,429 Too Many Requests 錯誤幾乎成了家常便飯。明明充了錢、明明不是免費用戶,結果還是被限流到懷疑人生。
核心價值: 本文將深入分析 Qwen3.6-Plus 429 錯誤的根本原因,提供 3 種切實可行的解決方案,並分享如何通過阿里雲官方直轉通道實現穩定、低價的 API 調用。

Qwen3.6-Plus 429 錯誤核心要點
| 要點 | 說明 | 開發者收益 |
|---|---|---|
| 429 根因分析 | 供不應求 + 免費層濫用 + 算力分配策略 | 理解問題本質,不再盲目重試 |
| 3 種解決方案 | 重試策略 / 切換渠道 / 官方直轉 | 根據場景選擇最優路徑 |
| 性能實測 | Qwen3.6-Plus 各渠道延遲對比 | 選擇最穩定的接入方式 |
| 代碼示例 | Python/Node.js 可直接運行 | 5 分鐘完成遷移 |
Qwen3.6-Plus 爲什麼這麼火
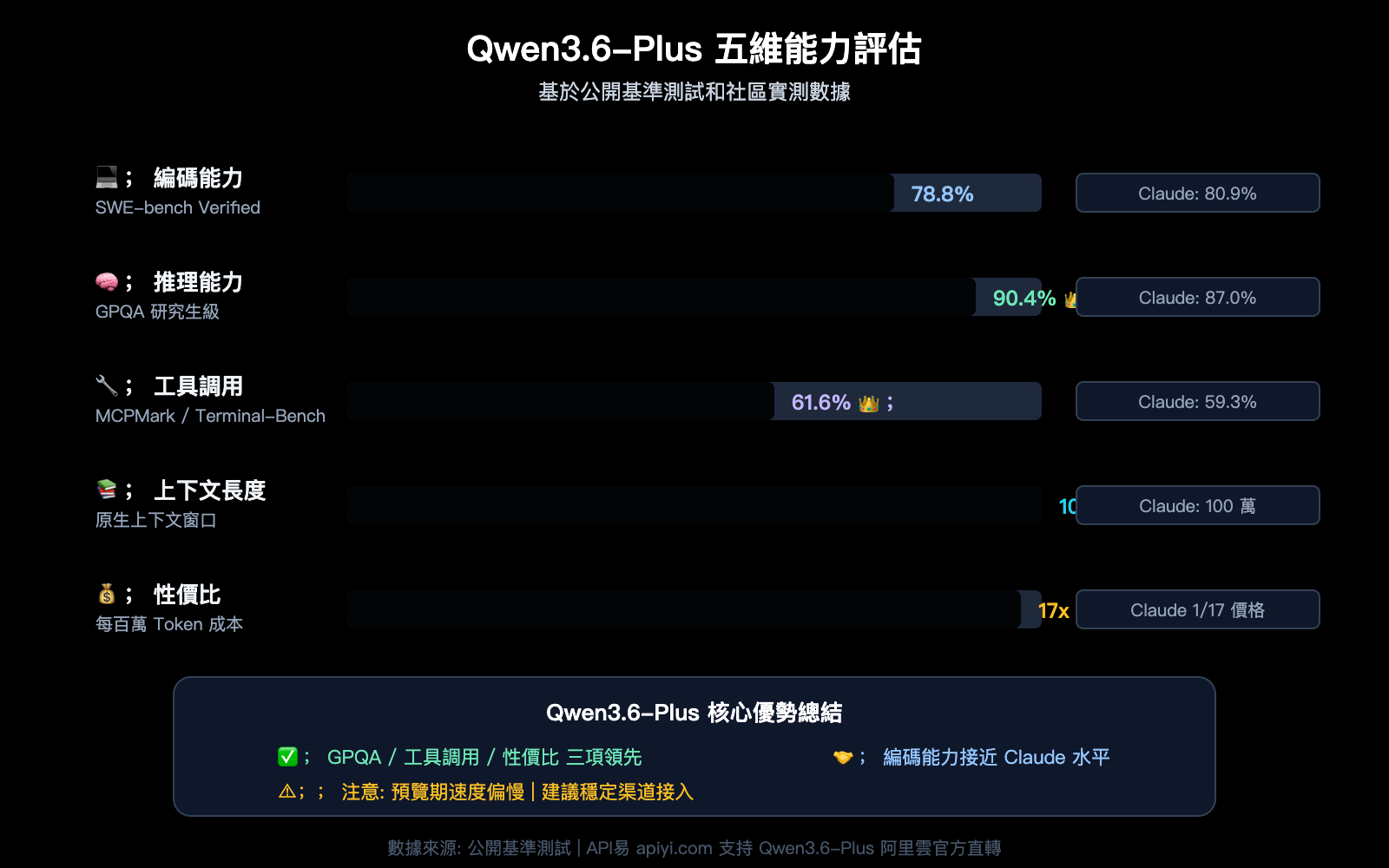
Qwen3.6-Plus 是阿里巴巴通義千問團隊於 2026 年 4 月發佈的旗艦模型,直接對標 Claude Opus 4.5 和 GPT-5.4。它火爆的原因很簡單——性能強、價格低:
| 基準測試 | Qwen3.6-Plus | Claude Opus 4.5 | GPT-5.4 |
|---|---|---|---|
| SWE-bench Verified | 78.8% | 80.9% | 76.2% |
| Terminal-Bench 2.0 | 61.6% | 59.3% | 57.8% |
| GPQA (研究生級科學) | 90.4% | 87.0% | 88.1% |
| MCPMark (工具調用) | 48.2% | 45.6% | 43.9% |
| 上下文窗口 | 100 萬 Token | 100 萬 Token | 25.6 萬 Token |
| 最大輸出 | 65,536 Token | 32,000 Token | 16,384 Token |
在 Terminal-Bench 和 GPQA 這兩個關鍵基準上,Qwen3.6-Plus 甚至超過了 Claude Opus 4.5,而官方 API 價格僅爲 Claude 的約 1/17。這個性價比直接引爆了開發者的使用需求——也正是 429 問題的根源。
Qwen3.6-Plus 429 錯誤深度分析
什麼是 429 錯誤
HTTP 429 狀態碼的含義很明確:Too Many Requests(請求過多)。當服務器在單位時間內收到的請求超過了其處理能力或預設限制時,就會返回這個錯誤。
典型的 429 錯誤響應:
{
"error": {
"code": 429,
"message": "Rate limit exceeded. Please slow down your requests.",
"metadata": {
"provider_name": "Qwen",
"raw": "{\"error\":{\"message\":\"Rate limit reached\",\"type\":\"rate_limit_error\"}}"
}
}
}
Qwen3.6-Plus 在 OpenRouter 上 429 頻發的 4 大原因
原因一:需求遠超供給
Qwen3.6-Plus 的性價比太高了。官方 API 入門級定價約 $0.29/百萬輸入 Token,是 Claude Opus 4.5 的 1/17。大量開發者湧入,而 OpenRouter 作爲中轉平臺,其從阿里雲獲取的算力配額是有限的。
原因二:免費層用戶大量佔用
OpenRouter 提供了 qwen/qwen3.6-plus:free 免費模型,吸引了大量零成本用戶。這些免費請求和付費請求共享同一套後端資源池,導致付費用戶也被「殃及池魚」。
原因三:預覽期算力分配保守
Qwen3.6-Plus 目前仍處於 Preview 階段(3 月 30 日發佈預覽版,4 月 2 日正式發佈)。阿里雲在預覽期對第三方平臺的算力分配通常比較保守,優先保障自有平臺(DashScope / 百鍊)的服務質量。
原因四:模型本身推理速度的瓶頸
雖然社區測試顯示 Qwen3.6-Plus 的吞吐量約爲 Claude Opus 4.6 的 3 倍,但在實際使用中,其 100 萬 Token 上下文窗口和 MoE 架構在處理複雜 Agent 任務時,響應延遲仍然偏高。這意味着每個請求佔用 GPU 的時間更長,單位時間內能處理的請求總量就更少。

🎯 核心洞察: 429 不是你的代碼有問題,而是供需失衡。解決思路應該是換一個供給充足的渠道,而不是無限重試。通過 API易 apiyi.com 接入阿里雲官方直轉通道,可以有效避開 OpenRouter 的限流問題。
Qwen3.6-Plus 429 錯誤解決方案一:智能重試策略
指數退避重試
當你暫時無法切換渠道時,合理的重試策略可以緩解(但無法根治)429 問題:
import openai
import time
import random
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # API易 統一接口,阿里雲官方直轉
)
def call_qwen36_with_retry(messages, max_retries=5):
"""帶指數退避的 Qwen3.6-Plus 調用"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=messages,
max_tokens=4096
)
return response.choices[0].message.content
except openai.RateLimitError as e:
if attempt == max_retries - 1:
raise
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"429 限流,第 {attempt+1} 次重試,等待 {wait_time:.1f}s...")
time.sleep(wait_time)
# 使用示例
result = call_qwen36_with_retry([
{"role": "user", "content": "分析這段代碼的性能瓶頸"}
])
print(result)
重試策略參數建議
| 參數 | 推薦值 | 說明 |
|---|---|---|
| 最大重試次數 | 3-5 次 | 超過 5 次說明渠道本身不穩定 |
| 初始等待時間 | 1-2 秒 | 太短沒效果,太長浪費時間 |
| 退避倍數 | 2x | 指數退避是行業標準 |
| 隨機抖動 | 0-1 秒 | 避免「驚羣效應」 |
| 超時上限 | 30 秒 | 單次等待不超過 30 秒 |
重試策略的侷限性
需要明確的是:重試只是止痛藥,不是治療方案。當 OpenRouter 的 Qwen3.6-Plus 後端持續過載時,重試策略的成功率會急劇下降。更根本的解決方案是切換到一個供給充足的 API 渠道。
Qwen3.6-Plus 429 錯誤解決方案二:切換 API 渠道
爲什麼切換渠道比重試更有效
OpenRouter 429 頻發的本質是該渠道的 Qwen3.6-Plus 算力配額不足。切換到直接對接阿里雲算力的渠道,可以從根源上解決問題。
Qwen3.6-Plus API 渠道對比
| 渠道 | 穩定性 | 價格 (輸入/百萬Token) | 429 頻率 | 數據收集 |
|---|---|---|---|---|
| OpenRouter Free | 差 | 免費 | 極高 | 是 (訓練數據) |
| OpenRouter Paid | 一般 | ~$0.29 | 頻繁 | 是 (預覽期) |
| 阿里雲百鍊 | 好 | ¥2.00 | 低 | 需看協議 |
| API易 (阿里雲直轉) | 好 | 官方 8 折 | 低 | 否 |
💡 選擇建議: 如果你的應用對穩定性有要求,我們建議通過 API易 apiyi.com 接入 Qwen3.6-Plus。該平臺採用阿里雲官方直轉通道,價格僅爲官方的 8 折(分組價格 0.88 折扣 + 充值 100 美金送 10 美金),同時避免了 OpenRouter 的限流問題。
從 OpenRouter 遷移到 API易 只需改 2 行代碼
遷移成本極低,只需修改 base_url 和 api_key:
import openai
# ❌ 之前: OpenRouter (經常 429)
# client = openai.OpenAI(
# api_key="sk-or-v1-xxxx",
# base_url="https://openrouter.ai/api/v1"
# )
# ✅ 現在: API易 阿里雲直轉 (穩定無 429)
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "你是一個專業的代碼審查助手"},
{"role": "user", "content": "幫我優化這個 SQL 查詢的性能"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Node.js 版本:
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'YOUR_APIYI_KEY',
baseURL: 'https://api.apiyi.com/v1' // API易 統一接口
});
const response = await client.chat.completions.create({
model: 'qwen3.6-plus',
messages: [
{ role: 'user', content: '分析這段代碼的時間複雜度' }
],
max_tokens: 4096
});
console.log(response.choices[0].message.content);

Qwen3.6-Plus 429 錯誤解決方案三:本地請求優化
減少不必要的 API 調用
除了切換渠道,優化你的請求模式也能降低觸發 429 的概率:
1. 合併請求
# ❌ 低效: 逐條發送
for item in data_list:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"分析: {item}"}]
)
# ✅ 高效: 批量合併
batch_content = "\n".join([f"{i+1}. {item}" for i, item in enumerate(data_list)])
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"依次分析以下內容:\n{batch_content}"}],
max_tokens=16384
)
2. 緩存高頻響應
import hashlib
import json
_cache = {}
def cached_qwen_call(prompt, model="qwen3.6-plus"):
cache_key = hashlib.md5(f"{model}:{prompt}".encode()).hexdigest()
if cache_key in _cache:
return _cache[cache_key]
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content
_cache[cache_key] = result
return result
3. 請求隊列限速
| 優化策略 | 效果 | 適用場景 |
|---|---|---|
| 請求合併 | 減少 60-80% 請求量 | 批量數據處理 |
| 響應緩存 | 相同請求零 API 調用 | 重複查詢場景 |
| 隊列限速 | 平滑請求峯值 | 高併發應用 |
| 降級策略 | 429 時自動切換小模型 | 對延遲敏感的服務 |
🔧 技術建議: 以上本地優化策略搭配穩定的 API 渠道效果最佳。通過 API易 apiyi.com 接入 Qwen3.6-Plus,結合請求合併和緩存策略,可以在保證穩定性的同時進一步降低成本。
Qwen3.6-Plus 模型速度慢的原因分析
爲什麼 Qwen3.6-Plus 響應有時很慢
很多開發者反饋,即使沒有遇到 429 錯誤,Qwen3.6-Plus 的響應速度也「莫名其妙地慢」。這並非個例,而是有技術層面的原因:
1. MoE 架構的推理開銷
Qwen3.6-Plus 採用混合專家(MoE)架構。雖然 MoE 能顯著降低訓練成本,但在推理階段,路由決策和專家切換會帶來額外開銷。特別是在處理長上下文時,MoE 架構的推理效率低於同參數量的 Dense 模型。
2. 100 萬 Token 上下文的內存壓力
100 萬 Token 的上下文窗口是 Qwen3.6-Plus 的核心賣點,但也意味着 KV Cache 佔用的 GPU 顯存極大。當多個用戶同時發起長上下文請求時,GPU 顯存成爲瓶頸,推理速度會顯著下降。
3. 預覽期算力資源有限
Qwen3.6-Plus 仍處於預覽期。阿里雲在這個階段通常不會投入與正式發佈時同等規模的算力。官方可能在觀察實際使用模式後,再逐步擴容。
4. Always-On 推理鏈的額外 Token 消耗
Qwen3.6-Plus 默認開啓了 Always-On Chain-of-Thought 推理模式。這意味着模型會在每次響應中生成內部思考過程,實際生成的 Token 數量遠多於最終輸出。這些「隱藏 Token」會佔用額外的推理時間。
不同渠道的延遲實測參考
| 渠道 | 首 Token 延遲 | 吞吐量 (Token/s) | 備註 |
|---|---|---|---|
| OpenRouter (高峯) | 8-15s | 15-25 | 經常 429 |
| OpenRouter (低谷) | 3-5s | 30-50 | 凌晨時段 |
| 阿里雲百鍊 | 2-4s | 40-60 | 國內直連 |
| API易 (直轉) | 2-5s | 35-55 | 海外穩定訪問 |
💰 成本提示: Qwen3.6-Plus 的速度在不同渠道和負載下差異較大。如果你對延遲敏感,建議通過 API易 apiyi.com 進行實際測試。平臺提供阿里雲官方直轉通道,既能享受 8 折優惠價格,又能獲得更穩定的響應速度。
Qwen3.6-Plus 快速上手實戰
使用 API易 調用 Qwen3.6-Plus 的完整示例
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# 基礎對話
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "你是一個資深 Python 開發專家"},
{"role": "user", "content": "幫我寫一個高性能的異步爬蟲框架"}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
查看流式輸出完整代碼
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# 流式輸出 - 適合需要實時反饋的場景
stream = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "你是一個資深架構師"},
{"role": "user", "content": "設計一個支持百萬併發的消息隊列系統"}
],
max_tokens=16384,
temperature=0.7,
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # 換行
🚀 快速開始: 推薦通過 API易 apiyi.com 平臺獲取 API Key 來調用 Qwen3.6-Plus。註冊即可體驗,充值 100 美金送 10 美金,Qwen3.6-Plus 享受官方 8 折價格。
Qwen3.6-Plus 適用場景與選型建議
什麼場景特別適合 Qwen3.6-Plus
| 應用場景 | 推薦理由 | 替代方案 |
|---|---|---|
| Agent 自動化 | Terminal-Bench 61.6% 領先,原生工具調用 | Claude Opus 4.5 |
| 代碼審查/修復 | SWE-bench 78.8%,接近 Claude 水平 | Claude Opus 4.5 |
| 科學推理 | GPQA 90.4% 全場最高 | GPT-5.4 |
| 長文檔處理 | 100 萬 Token 上下文 | Gemini 2.5 Pro |
| 成本敏感項目 | 約 Claude 1/17 的價格 | DeepSeek V3 |
什麼場景需要謹慎使用
- 對延遲極度敏感的實時應用: Qwen3.6-Plus 的 MoE 架構在長上下文下延遲偏高
- 生產環境關鍵路徑: 預覽期模型可能有不可預見的行爲變更
- 需要嚴格 SLA 保障的場景: 預覽期無正式 SLA
🎯 選型建議: 對於需要同時使用多個模型的項目,我們建議通過 API易 apiyi.com 平臺統一接入。平臺支持 Qwen3.6-Plus、Claude、GPT 等主流模型的 OpenAI 兼容接口,一個 API Key 即可切換不同模型,便於在不同場景下靈活調度。
Qwen3.6-Plus 429 錯誤常見問題
Q1: 在 OpenRouter 充了錢爲什麼還是 429?
這是因爲 OpenRouter 的付費用戶和免費用戶共享後端算力池。即使你是付費用戶,當整體請求量超過 OpenRouter 從阿里雲獲取的算力配額時,付費用戶也會被限流。解決方案是切換到供給更充足的渠道,比如通過 API易 apiyi.com 直接使用阿里雲官方直轉通道。
Q2: Qwen3.6-Plus 的 429 錯誤會好轉嗎?
隨着阿里雲擴容和模型正式 GA(General Availability),429 問題預計會有所緩解。但 OpenRouter 作爲多方中轉平臺,其算力分配始終受限於上游供給。如果你的業務對穩定性有要求,建議長期使用直連阿里雲算力的渠道,而非依賴中轉平臺。
Q3: API易的 Qwen3.6-Plus 和 OpenRouter 的有什麼區別?
核心區別在於算力來源。API易 apiyi.com 平臺採用阿里雲官方直轉通道,算力來自阿里雲百鍊平臺而非中轉。這意味着更低的 429 發生率和更穩定的響應速度。價格方面,API易 提供官方 8 折優惠(分組 0.88 折扣 + 充值返贈),且兼容 OpenAI SDK 接口格式,遷移成本幾乎爲零。
Q4: Qwen3.6-Plus 速度慢是正常的嗎?
Qwen3.6-Plus 的 MoE 架構和 100 萬 Token 上下文確實在推理時比 Dense 模型開銷更大。加上預覽期算力配置保守,速度偏慢是當前階段的普遍現象。不過其絕對吞吐量仍然可觀,建議通過流式輸出(stream=True)改善用戶體驗。
Q5: 如何在 Claude Code 中使用 Qwen3.6-Plus?
Qwen3.6-Plus 支持 Anthropic 協議和 OpenAI 協議雙兼容。你可以通過修改 Claude Code 的 API 端點配置來使用 Qwen3.6-Plus。通過 API易 apiyi.com 平臺接入時,使用標準的 OpenAI SDK 格式即可,具體配置可參考平臺文檔。
Qwen3.6-Plus 429 錯誤解決方案總結
Qwen3.6-Plus 的 429 問題本質上是一個供需失衡的問題:模型太強、價格太低、需求太大,而 OpenRouter 的算力配額無法滿足所有用戶。
三種解決方案的適用場景:
- 智能重試: 臨時方案,適合低頻調用場景
- 本地優化: 減少請求量,適合所有場景
- 切換渠道: 根本解決方案,適合對穩定性有要求的項目
對於需要穩定調用 Qwen3.6-Plus 的開發者,推薦通過 API易 apiyi.com 平臺接入阿里雲官方直轉通道。享受官方 8 折價格的同時,告別 429 限流困擾,讓你的應用專注於業務邏輯而非錯誤處理。
📝 作者: APIYI Team | 更多 AI 模型 API 接入教程和避坑指南,請訪問 API易幫助中心: help.apiyi.com