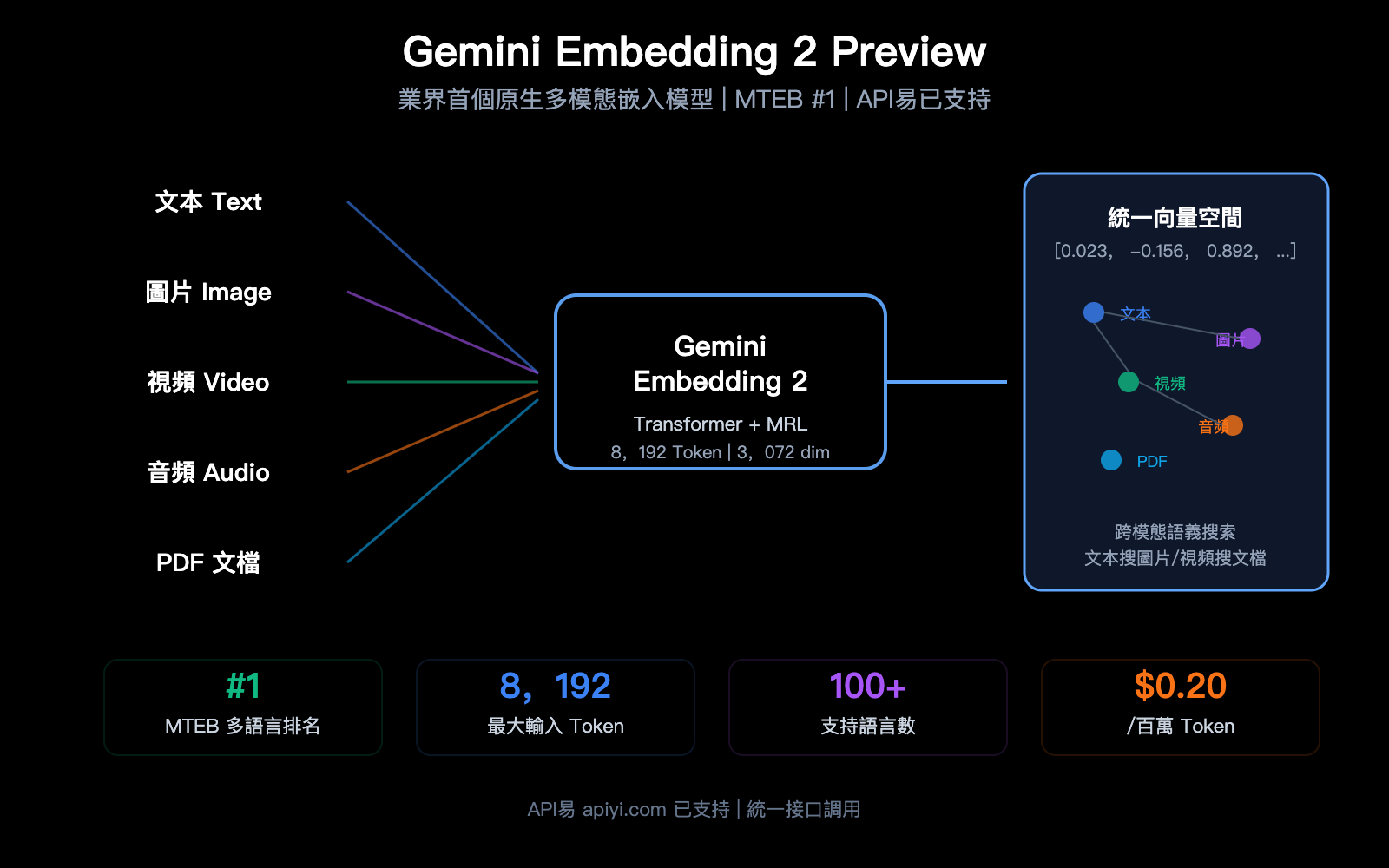
Google 在 2026 年 3 月發佈了一個重要模型——Gemini Embedding 2 Preview,業界首個原生多模態嵌入模型。它能將文本、圖片、視頻、音頻和 PDF 文檔統一映射到同一個向量空間中,在 MTEB 多語言基準測試中排名第 1,領先第二名 5 個百分點以上。
核心價值: 讀完本文,你將瞭解 Gemini Embedding 2 Preview 的 5 大技術突破、與競品的定價和性能對比,以及如何通過 API 快速接入使用。
Gemini Embedding 2 Preview 是什麼
Gemini Embedding 2 Preview 是 Google 於 2026 年 3 月 10 日發佈的最新嵌入模型。它基於 Gemini 架構初始化,採用雙向注意力 Transformer 結構,是 Google 第一個原生支持多模態輸入的嵌入模型。
| 規格 | 詳情 |
|---|---|
| 模型 ID | gemini-embedding-2-preview |
| 發佈時間 | 2026 年 3 月 10 日 |
| 狀態 | Preview(預覽版,正式版待定) |
| 默認輸出維度 | 3,072 |
| 可選維度範圍 | 128 — 3,072 |
| 最大輸入 Token | 8,192(是上代的 4 倍) |
| 多模態支持 | 文本、圖片、視頻、音頻、PDF |
| 語言支持 | 100+ 種語言 |
| Matryoshka 訓練 | 支持(可截斷維度保持語義質量) |
| 可用平臺 | Gemini API、Vertex AI、API易 apiyi.com |
與上代模型的關鍵差異
| 特性 | text-embedding-004 | gemini-embedding-001 | gemini-embedding-2-preview |
|---|---|---|---|
| 最大輸入 Token | 2,048 | 2,048 | 8,192 |
| 輸出維度 | 最高 768 | 128-3,072 | 128-3,072 |
| 多模態 | 僅文本 | 僅文本 | 文本+圖片+視頻+音頻+PDF |
| 任務類型指定 | task_type 字段 |
task_type 字段 |
Prompt 內嵌指令 |
| MRL 支持 | 不支持 | 支持 | 支持 |
| 價格/百萬 Token | 已停服 | $0.15 | $0.20 |
🎯 接入提示: API易 apiyi.com 已支持 gemini-embedding-2-preview 模型調用,
通過 OpenAI 兼容接口即可接入,無需單獨配置 Google API Key。
5 大技術突破詳解
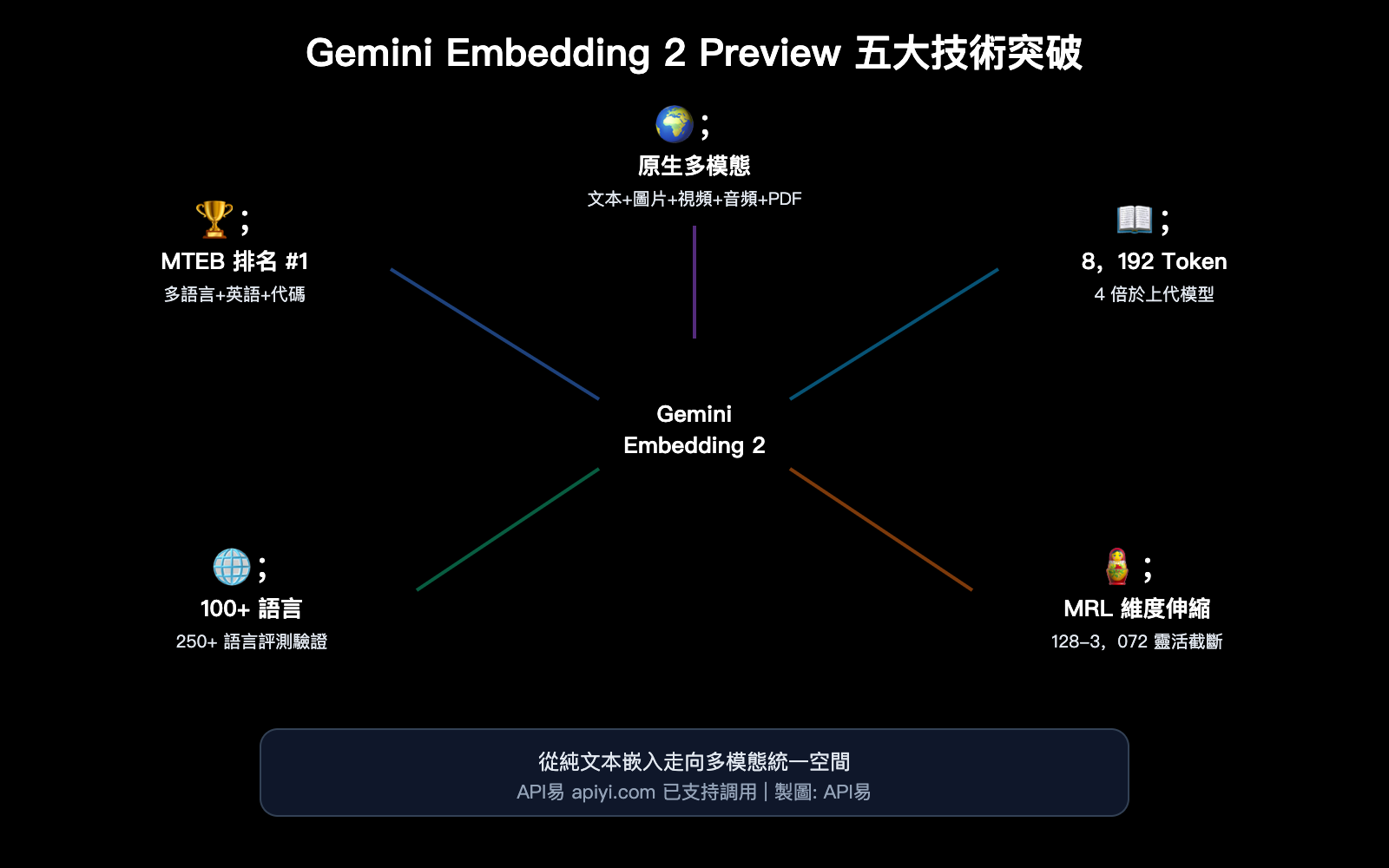
突破一:原生多模態統一嵌入空間
這是 Gemini Embedding 2 最大的差異化優勢——5 種模態的內容被映射到同一個向量空間。
| 模態 | 格式要求 | 單次限制 | 說明 |
|---|---|---|---|
| 文本 | 純文本 | 8,192 Token | 支持 100+ 語言 |
| 圖片 | PNG, JPEG | 每請求最多 6 張 | 直接處理像素 |
| 視頻 | MP4, MOV | 最長 120 秒 | 自動採樣最多 32 幀 |
| 音頻 | MP3, WAV | 最長 80 秒 | 原生處理,無需轉錄 |
| PDF 文檔 | 每請求最多 6 頁 | 含 OCR 能力 |
實際應用場景:
- 用文本搜索圖片("紅色跑車在賽道上"→ 返回匹配的圖片)
- 用圖片搜索相似視頻片段
- 用語音描述搜索相關文檔
- 構建跨模態的統一知識庫
這在之前的嵌入模型中是不可能的——OpenAI 的 text-embedding-3 系列只支持文本,如果需要圖片搜索,你必須先用視覺模型提取描述再嵌入,多了一步且損失信息。
突破二:8,192 Token 上下文窗口
輸入窗口從 2,048 提升到 8,192 Token,意味着一次可以嵌入更長的文檔段落。
對 RAG(檢索增強生成)系統來說,這個提升非常實用:
- 之前需要將文檔切成 500-1000 Token 的小段
- 現在可以用 2000-4000 Token 的大段,保留更多上下文
- 更大的文檔段 = 更少的切分 = 檢索結果更完整
突破三:Matryoshka 維度伸縮
Gemini Embedding 2 使用 Matryoshka Representation Learning (MRL) 訓練,模型會將最重要的語義信息集中在向量的前幾個維度中。
這意味着你可以根據場景靈活選擇維度:
| 維度 | 向量大小 | 適用場景 | 質量損失 |
|---|---|---|---|
| 3,072 (默認) | 12.3 KB | 最高精度檢索 | 無 |
| 1,536 | 6.1 KB | 平衡精度與存儲 | 極小 |
| 768 | 3.1 KB | 大規模部署首選 | 小 |
| 256 | 1.0 KB | 實時推薦系統 | 中等 |
| 128 | 0.5 KB | 極限壓縮場景 | 較大 |
注意: 當使用低於 3,072 的維度時,需要手動對向量進行歸一化後再計算相似度。
突破四:100+ 語言支持
在 MTEB 多語言基準測試中,Gemini Embedding 2 在 250+ 種語言上進行了評測,覆蓋範圍遠超競品。
關鍵語言性能指標:
- 雙文本挖掘 (Bitext Mining): 79.32 分
- 跨語言檢索 (XOR-Retrieve): Recall@5kt 90.42 分
- 多語言理解 (XTREME-UP): MRR@10 64.33 分
突破五:MTEB 多項排名第 1
| 基準測試 | 得分 | 排名 | 領先幅度 |
|---|---|---|---|
| MTEB 多語言 (Mean Task) | 68.32 | 第 1 | +5.09 |
| MTEB 多語言 (Mean Type) | 59.64 | 第 1 | — |
| MTEB 英語 v2 (Mean Task) | 73.30 | 第 1 | — |
| MTEB 英語 v2 (Mean Type) | 67.67 | 第 1 | — |
| MTEB 代碼 (Mean All) | 74.66 | 第 1 | — |
作爲對比,第二名模型 gte-Qwen2-7B-instruct 在多語言 MTEB 上的得分爲 62.51——Gemini Embedding 2 領先近 6 分,這在嵌入模型領域是非常大的差距。
💡 開發建議: 如果你正在構建 RAG 系統或語義搜索應用,
Gemini Embedding 2 在多語言和代碼場景中都是當前最強的選擇。
通過 API易 apiyi.com 可以一鍵接入該模型,同時支持 OpenAI embedding 模型,
方便快速對比效果。
與競品的定價和性能對比
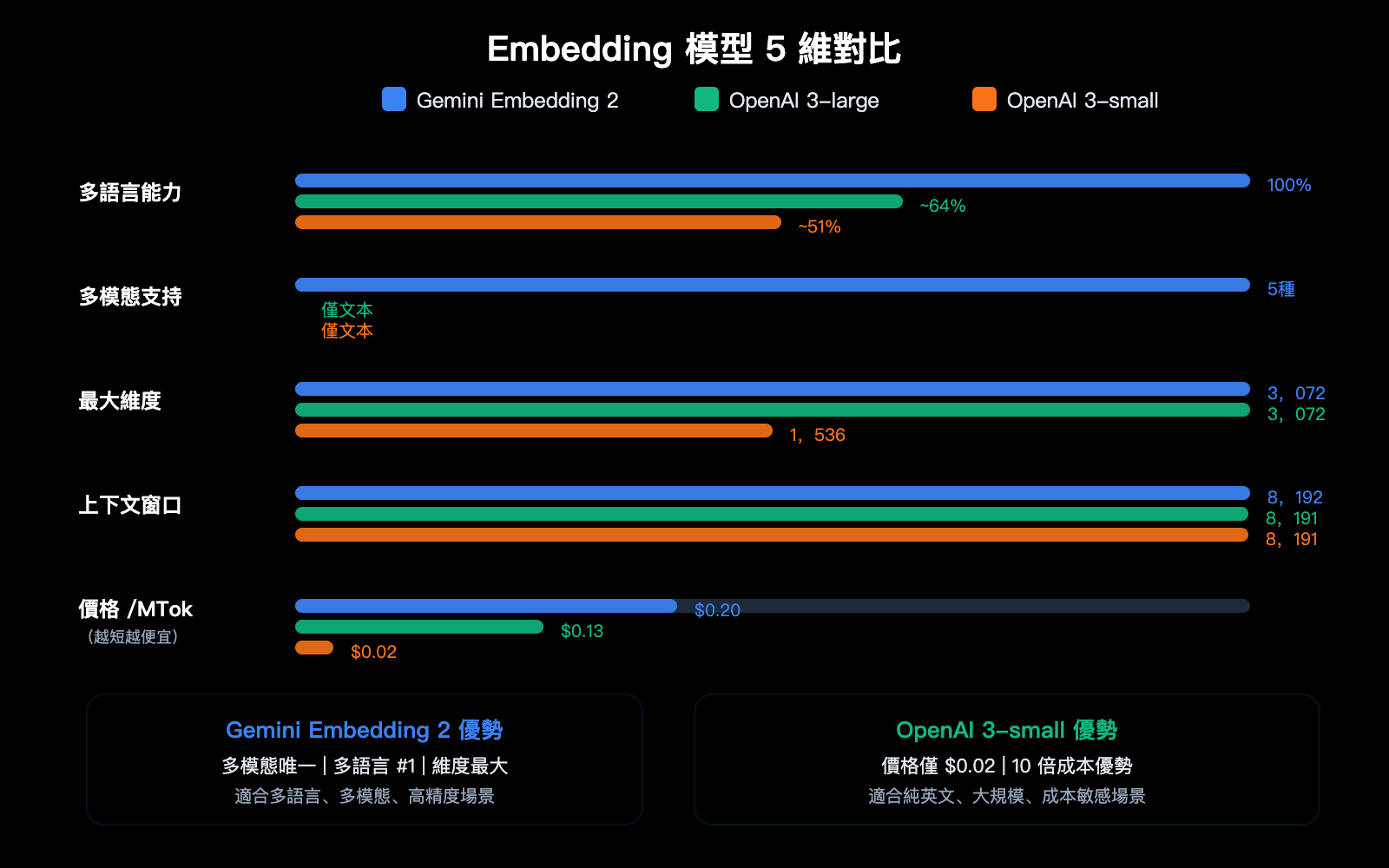
文本嵌入定價對比
| 模型 | 價格/百萬 Token | 最大維度 | 最大輸入 | 多模態 | 多語言排名 |
|---|---|---|---|---|---|
| Gemini Embedding 2 | $0.20 | 3,072 | 8,192 | ✅ 五模態 | #1 |
| gemini-embedding-001 | $0.15 | 3,072 | 2,048 | ❌ | — |
| OpenAI text-embedding-3-large | $0.13 | 3,072 | 8,191 | ❌ | — |
| OpenAI text-embedding-3-small | $0.02 | 1,536 | 8,191 | ❌ | — |
多模態內容定價(Gemini Embedding 2 獨有):
| 輸入類型 | 付費價格/百萬 Token | 批量價格/百萬 Token |
|---|---|---|
| 文本 | $0.20 | $0.10 |
| 圖片 | $0.45 (~$0.00012/張) | $0.225 |
| 音頻 | $6.50 (~$0.00016/秒) | $3.25 |
| 視頻 | $12.00 (~$0.00079/幀) | $6.00 |
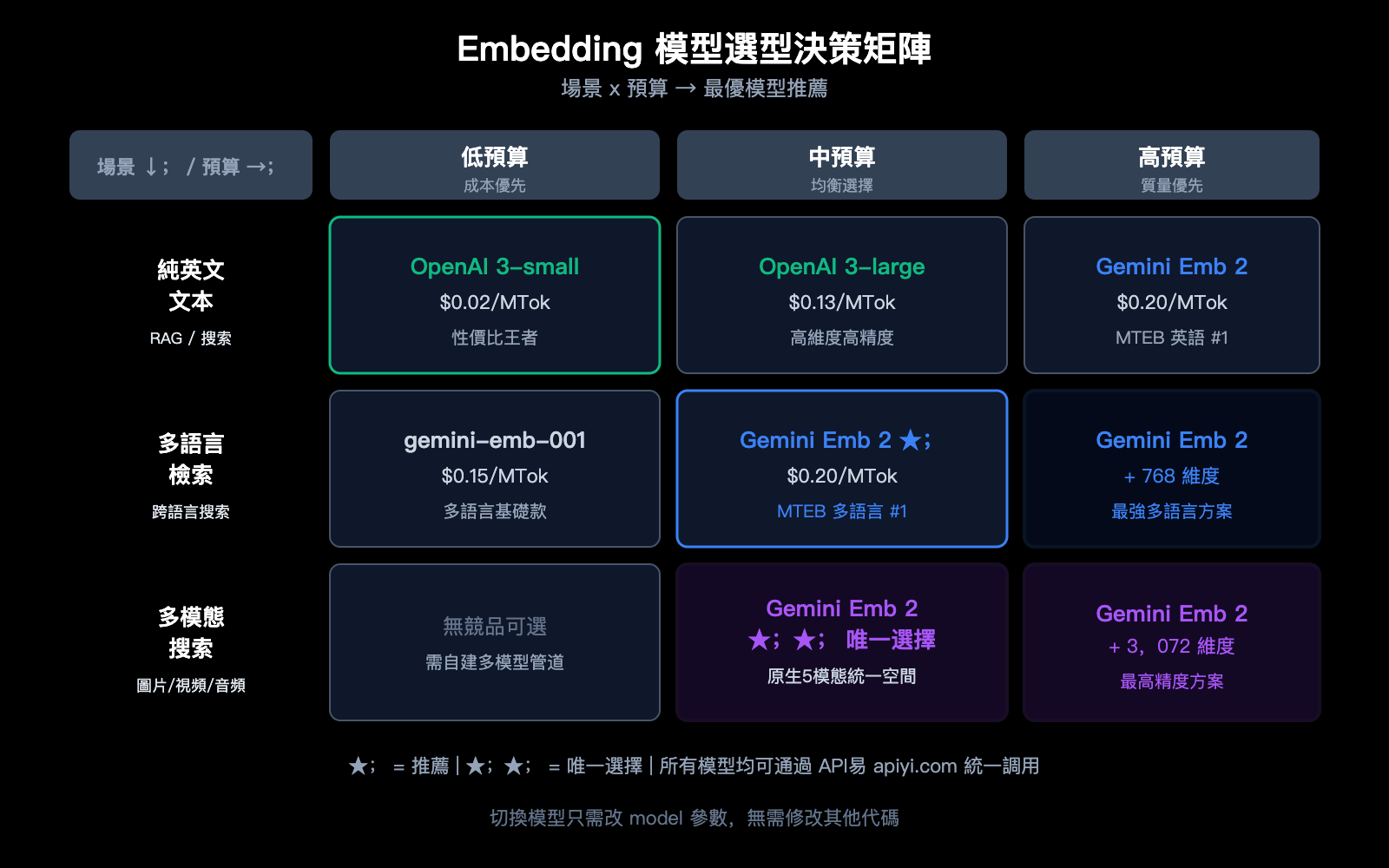
選型建議
| 需求場景 | 推薦模型 | 原因 |
|---|---|---|
| 純文本、成本敏感 | OpenAI text-embedding-3-small | 最便宜 ($0.02) |
| 純文本、高精度 | Gemini Embedding 2 或 OpenAI 3-large | 精度接近,Gemini 多語言更強 |
| 多模態搜索 | Gemini Embedding 2 | 唯一的原生多模態方案 |
| 多語言檢索 | Gemini Embedding 2 | MTEB 多語言 #1 |
| 代碼搜索 | Gemini Embedding 2 | MTEB 代碼 #1 |
| 大規模低成本 | OpenAI 3-small + 批量 API | 10x 價格優勢 |
🎯 選擇建議: 選擇哪個 embedding 模型取決於你的具體場景。
我們建議通過 API易 apiyi.com 平臺同時接入 Gemini 和 OpenAI 的 embedding 模型,
用真實數據對比檢索效果後再做決策。該平臺支持統一接口調用,切換模型無需改代碼。
API 調用方式詳解
任務類型指定方式(重要變化)
與 gemini-embedding-001 不同,Gemini Embedding 2 不再使用 task_type 參數,而是通過在輸入內容中嵌入任務指令來指定任務類型。
8 種支持的任務類型:
| 任務類型 | 查詢端格式 | 文檔端格式 |
|---|---|---|
| 搜索/檢索 | task: search result | query: {內容} |
title: {標題} | text: {內容} |
| 問答 | task: question answering | query: {問題} |
title: {標題} | text: {內容} |
| 事實覈查 | task: fact checking | query: {聲明} |
title: {標題} | text: {內容} |
| 代碼檢索 | task: code retrieval | query: {描述} |
title: {標題} | text: {代碼} |
| 分類 | task: classification | query: {內容} |
同格式 |
| 聚類 | task: clustering | query: {內容} |
同格式 |
| 句子相似度 | task: sentence similarity | query: {句子} |
同格式 |
對於文檔端,如果沒有標題,使用 title: none。
Python 調用示例
import openai
# 通過 API易 統一接口調用
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# 文本嵌入 - 搜索場景
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input="task: search result | query: 什麼是向量數據庫",
dimensions=768 # 可選維度:128-3072
)
embedding = response.data[0].embedding
print(f"向量維度: {len(embedding)}")
print(f"前5個值: {embedding[:5]}")
查看完整的 RAG 檢索流程代碼
import openai
import numpy as np
from typing import List
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def get_embedding(text: str, task: str = "search result", dim: int = 768) -> List[float]:
"""獲取文本嵌入向量"""
formatted = f"task: {task} | query: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
# MRL 截斷維度需要手動歸一化
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def get_doc_embedding(title: str, text: str, dim: int = 768) -> List[float]:
"""獲取文檔嵌入向量"""
formatted = f"title: {title} | text: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def cosine_similarity(a: List[float], b: List[float]) -> float:
"""計算餘弦相似度"""
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 使用示例
query_vec = get_embedding("如何優化 RAG 檢索效果")
doc_vec = get_doc_embedding(
"RAG 優化指南",
"本文介紹了 5 種優化 RAG 檢索質量的方法..."
)
similarity = cosine_similarity(query_vec, doc_vec)
print(f"相似度: {similarity:.4f}")
🚀 快速開始: 推薦使用 API易 apiyi.com 平臺快速接入 Gemini Embedding 2。
該平臺提供 OpenAI 兼容的 embedding 接口,5 分鐘即可完成集成,
同時支持 OpenAI、Gemini、Cohere 等主流 embedding 模型的統一調用。
使用注意事項
Preview 狀態的限制
| 限制項 | 說明 | 影響 |
|---|---|---|
| 版本可能變更 | Preview 階段規格和定價可能調整 | 生產環境建議做好降級方案 |
| 向量空間不兼容 | 不能與舊模型的向量混用 | 升級需要全量重新索引 |
| 低維度需歸一化 | 使用 <3,072 維度時需手動歸一化 | 代碼中需增加歸一化步驟 |
| 速率限制較嚴 | Preview 模型配額低於 GA 模型 | 大規模使用需申請提額 |
| 免費層數據使用 | 免費層的數據會被用於產品改進 | 敏感數據建議使用付費層 |
從舊模型遷移的注意事項
- 必須重建索引: 不同模型的向量空間不兼容,不能在同一個數據庫中混用
- 任務類型格式變化: 從
task_type參數改爲 Prompt 內嵌指令 - 歸一化處理: 如果使用非默認維度,需要在代碼中增加歸一化邏輯
- 測試效果再遷移: 建議在測試環境中對比新舊模型的檢索效果後再決定遷移
常見問題
Q1: Gemini Embedding 2 Preview 比 OpenAI text-embedding-3-large 好在哪?
主要優勢在三個方面:原生多模態支持(OpenAI 只支持文本)、MTEB 多語言排名第 1(領先幅度大)、以及代碼嵌入質量更高。但 OpenAI text-embedding-3-large 價格更低($0.13 vs $0.20),且如果你只需要英文文本嵌入,兩者質量非常接近。通過 API易 apiyi.com 可以同時調用兩個模型用真實數據對比。
Q2: 多模態嵌入到底有什麼實際用途?
最直接的應用是跨模態搜索:用戶輸入文本,搜索返回相關的圖片、視頻或文檔。比如電商場景中用"紅色連衣裙"搜索商品圖片,或者企業知識庫中用文字描述搜索培訓視頻中的相關片段。傳統做法需要先用視覺模型提取描述再嵌入文本,Gemini Embedding 2 直接處理原始圖片/視頻,信息損失更小。
Q3: 維度選多少合適?768 和 3072 差別大嗎?
對於大多數應用,768 維是最佳平衡點——存儲成本僅爲 3072 維的 1/4,但檢索質量損失極小(得益於 Matryoshka 訓練)。如果你的數據集較小(<100 萬條)且對精度要求極高,用 3072 維。如果數據量大或需要實時檢索,768 維甚至 256 維都是合理選擇。
Q4: API易 如何支持 Gemini Embedding 2?需要額外配置嗎?
API易 apiyi.com 已支持 gemini-embedding-2-preview 模型,通過標準的 OpenAI 兼容 embedding 接口即可調用,無需額外配置 Google API Key。只需在 model 參數中指定 gemini-embedding-2-preview,其他參數(dimensions 等)與 OpenAI embedding 接口完全一致。
總結:多模態嵌入的新標杆
Gemini Embedding 2 Preview 代表了嵌入模型的一個重要里程碑——從純文本走向真正的多模態統一空間。在 MTEB 多語言、英語、代碼三個維度同時拿下第 1 名,加上 8K 上下文窗口和 MRL 維度伸縮,它爲 RAG 系統、語義搜索和知識庫構建提供了當前最強的基礎能力。
關鍵要點回顧:
- 業界首個原生五模態嵌入模型(文本+圖片+視頻+音頻+PDF)
- MTEB 多語言基準測試第 1 名,領先 5+ 分
- 8,192 Token 上下文窗口,4 倍於上代
- MRL 訓練支持 128-3,072 靈活維度伸縮
- 價格 $0.20/百萬 Token,多模態場景性價比極高
推薦通過 API易 apiyi.com 快速接入 Gemini Embedding 2 Preview,一個 Key 同時支持 Gemini、OpenAI 等主流 embedding 模型,便於對比和切換。
📝 本文作者: APIYI 技術團隊 | API易 apiyi.com – 300+ AI 大模型 API 統一接入平臺
參考資料
-
Google 官方博客: Gemini Embedding 2 發佈公告
- 鏈接:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/ - 說明: 包含模型設計理念和多模態能力介紹
- 鏈接:
-
Gemini API 嵌入文檔: 官方 API 使用指南
- 鏈接:
ai.google.dev/gemini-api/docs/embeddings - 說明: 完整的 API 參數和調用示例
- 鏈接:
-
Gemini Embedding 研究論文: 技術細節和基準測試
- 鏈接:
arxiv.org/html/2503.07891v1 - 說明: MTEB 詳細測試數據和模型架構分析
- 鏈接:
-
Gemini API 定價: 各模態的詳細定價信息
- 鏈接:
ai.google.dev/gemini-api/docs/pricing - 說明: 文本、圖片、音頻、視頻的分項定價
- 鏈接: