作者注:解答開發者最常問的問題:大模型 API 能否直接傳 PDF?答案是絕大多數不支持。本文詳解文字化提取、圖片理解、客戶端處理 3 種實用方案
"大模型 API 能不能直接把 PDF 文件傳進去?"——這是我們客服羣裏被問得最多的問題之一。很多開發者在網頁版 ChatGPT 或 Claude 裏用慣了"拖入 PDF 直接對話"的功能,就以爲 API 也能這樣操作。
實際情況是:絕大多數大模型 API 不支持直接輸入 PDF 文件。即使是 OpenAI、Anthropic 這樣的頭部廠商,API 接口的核心輸入格式仍然是文本和圖片——PDF 並不在標準支持範圍內。更重要的是,API易等第三方 API 中轉平臺同樣不支持 PDF 直傳,因爲底層協議就不支持。
但別擔心,PDF 處理其實有 3 種成熟的解決方案。本文將帶你搞清楚來龍去脈,選出最適合你的方式。
核心價值: 讀完本文,你將理解大模型 API 爲什麼不支持 PDF,以及如何用 3 種預處理方案高效解決 PDF 輸入需求。
<!– SVG_COVER: 封面圖 – PDF無法直傳API + 3種預處理方案 –>

大模型 API PDF 輸入核心要點
| 要點 | 說明 | 影響 |
|---|---|---|
| API 不直接接受 PDF | GPT、DeepSeek、Llama、Qwen 等主流模型 API 的標準輸入是文本和圖片 | 需要前置預處理流程 |
| 網頁版 ≠ API | ChatGPT、Claude 網頁版的 PDF 上傳是前端預處理後再調用 API | 不要把網頁體驗等同於 API 能力 |
| 第三方平臺同樣不支持 | API易等中轉平臺透傳原始 API 協議,底層不支持則平臺也不支持 | 不要期望中轉平臺額外處理 PDF |
| 3 種預處理方案成熟可靠 | 文字化提取、圖片理解、客戶端處理各有適用場景 | 選對方案比找"支持 PDF 的 API"更實際 |
大模型 API 爲什麼不支持 PDF 輸入
很多開發者會困惑:網頁版明明可以上傳 PDF,爲什麼 API 不行?原因很簡單——網頁版的"上傳 PDF"功能並不是模型本身在處理 PDF,而是前端/後端在你看不到的地方做了預處理:
- 文本提取: 前端把 PDF 裏的文字提取出來,轉成純文本再傳給模型
- 頁面渲染: 把 PDF 每頁渲染成圖片,通過 Vision 能力讓模型理解
- RAG 檢索: 將 PDF 內容向量化存儲,對話時只檢索相關片段發送給模型
這些預處理步驟在網頁版產品中被封裝了,用戶無感知。但當你直接調用 API 時,這些預處理需要你自己完成。
大模型 API PDF 支持情況速查
| 模型 | API 直傳 PDF | 標準輸入格式 | PDF 處理建議 |
|---|---|---|---|
| GPT-4o / GPT-4.1 | 不支持 | 文本 + 圖片(Base64) | 先提取文本或轉圖片 |
| Claude | 部分支持(Beta) | 文本 + 圖片 | 建議仍走預處理流程更穩定 |
| Gemini | 部分支持 | 文本 + 圖片 | 建議仍走預處理流程更可控 |
| DeepSeek | 不支持 | 純文本 | 必須先提取文本 |
| Llama / Qwen | 不支持 | 文本(部分支持圖片) | 必須先提取文本 |
| API易等第三方 | 不支持 | 透傳原始協議 | 需在調用前自行預處理 |
🎯 重要說明: 雖然 Claude 和 Gemini 的官方 API 文檔中提到了 PDF 輸入功能,但該功能存在兼容性和穩定性的不確定性,且通過 API易等第三方中轉平臺調用時不支持 PDF 直傳。我們建議統一走預處理方案,兼容性最好、最穩定。
大模型 API PDF 處理方案一:前置文字化提取
這是最通用、成本最低、兼容所有模型的方案。核心思路:先用 Python 庫把 PDF 轉成 Markdown 或純文本,再將文本作爲 prompt 傳給 API。
PDF 文字化提取工具對比
| 工具 | 速度 | 最佳場景 | 特點 |
|---|---|---|---|
| PyMuPDF4LLM | ~0.14s/文檔 | 通用文本 + 表格提取 | 速度與質量最佳平衡,輸出 Markdown |
| pdfplumber | 中等 | 表格數據提取 | 座標級表格提取精度高 |
| Marker-PDF | ~11s/文檔 | 複雜版面保真轉換 | 結構保留最好,速度較慢 |
| PyPDF2 | 快 | 簡單純文本 PDF | 輕量級,適合基礎提取 |
PDF 文字化提取代碼示例
以下是最常用的方案,提取 PDF 文本後傳給大模型 API:
import pymupdf4llm
import openai
# 步驟1: PDF 轉 Markdown
md_text = pymupdf4llm.to_markdown("report.pdf")
# 步驟2: 純文本傳給任意大模型
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"請總結這份報告的核心要點:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
適用場景: 合同、論文、報告、技術文檔等以文字爲主的 PDF。只要 PDF 內嵌了文本層(非掃描件),提取效果都很好。
建議: 文字化提取方案兼容所有大模型——GPT、Claude、DeepSeek、Llama、Qwen 都可以。通過 API易 apiyi.com 獲取 API Key,一個 Key 可以調用所有模型進行對比測試。
<!– SVG_DIAGRAM: 3種方案的處理流程對比圖 –>
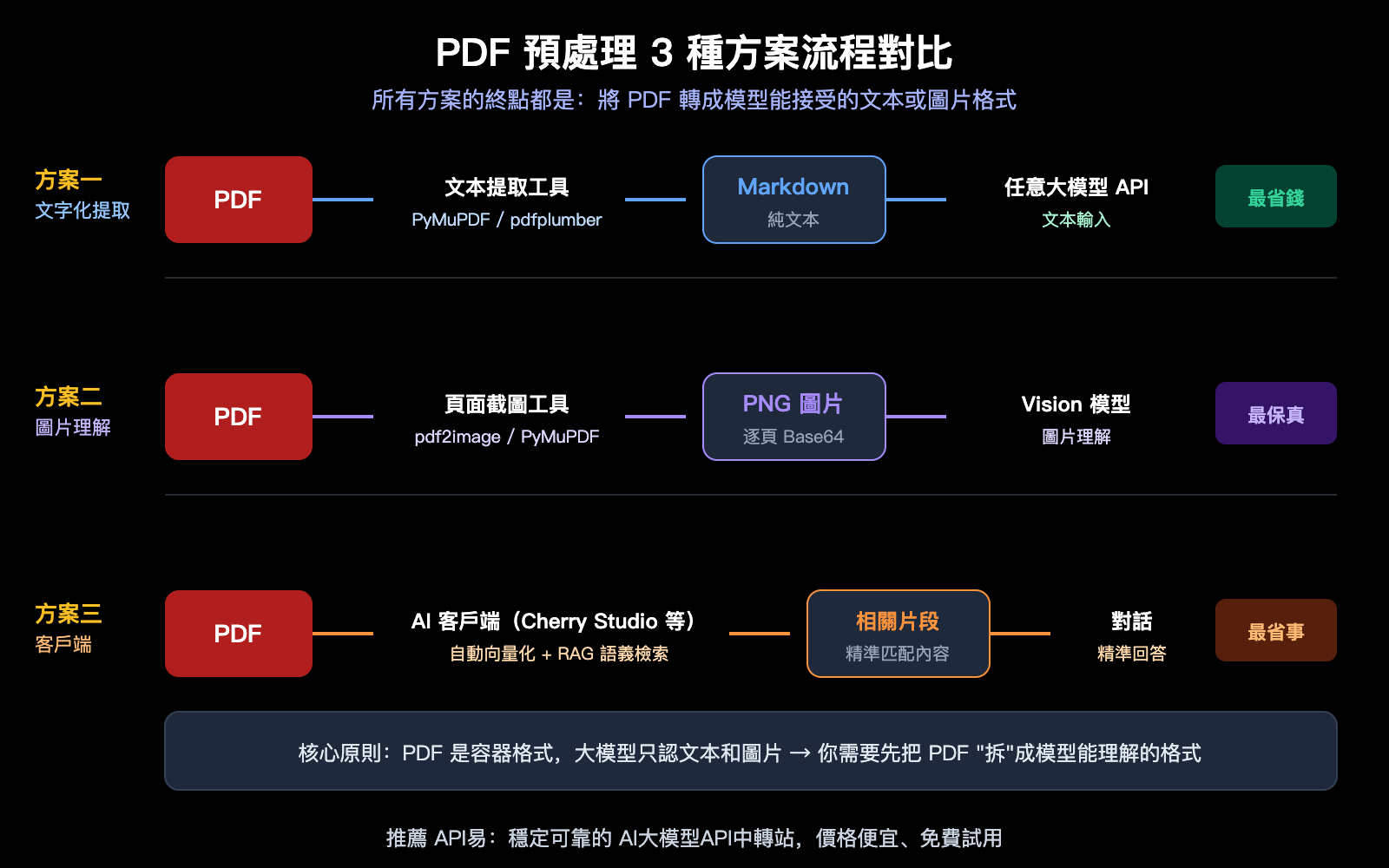
大模型 API PDF 處理方案二:轉圖片 + 視覺理解
當 PDF 中包含圖表、掃描件、複雜排版等視覺信息時,純文本提取會丟失這些內容。這時需要將 PDF 每頁渲染成圖片,通過支持 Vision 的模型進行圖片理解。
PDF 轉圖片代碼示例
import fitz # PyMuPDF
import base64
import openai
# 步驟1: PDF 逐頁轉爲 PNG 圖片
doc = fitz.open("report.pdf")
images = []
for page in doc:
pix = page.get_pixmap(dpi=200)
b64 = base64.b64encode(pix.tobytes("png")).decode()
images.append(b64)
查看完整代碼:圖片傳入 Vision API
import fitz
import base64
import openai
def pdf_to_vision(pdf_path, question, max_pages=10):
"""將 PDF 轉圖片後傳入 Vision API"""
doc = fitz.open(pdf_path)
# 構建多圖消息(注意控制頁數避免 Token 超量)
content = [{"type": "text", "text": question}]
for i, page in enumerate(doc):
if i >= max_pages:
break
pix = page.get_pixmap(dpi=150)
b64 = base64.b64encode(pix.tobytes("png")).decode()
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
return response.choices[0].message.content
# 使用示例
result = pdf_to_vision(
"financial_report.pdf",
"請分析這份財報中的趨勢圖表,總結核心數據",
max_pages=5 # 控制頁數,每頁約消耗 765 tokens
)
print(result)
適用場景: 帶圖表的研報、掃描件、發票、建築圖紙等視覺信息豐富的 PDF。
成本提醒: 每頁圖片約消耗 765 tokens(GPT-4o 標準分辨率),10 頁 PDF 就是約 7,650 tokens 的圖片成本,加上文字提問和回答可能超過 10,000 tokens。務必控制頁數。
🎯 成本控制建議: 不要一次傳入整份 PDF 的所有頁面。先用方案一提取文本做粗篩,確定關鍵頁面後再用方案二對特定頁面做圖片理解。通過 API易 apiyi.com 的用量面板可以實時監控 Token 消耗。
大模型 API PDF 處理方案三:AI 客戶端處理
如果你不想寫代碼,只是日常對話中需要"問 PDF 裏的內容",使用 AI 客戶端是最省事的方式。
Cherry Studio 等客戶端的 PDF 處理原理
這類客戶端實際上就是幫你自動完成了方案一和方案二的工作:
- 自動向量化: 將 PDF 內容提取後切分成小塊,存入本地向量數據庫
- 語義檢索: 你提問時,客戶端先檢索最相關的內容片段
- 精準發送: 只把相關片段(而非全文)發送給大模型 API
- 節省 Token: 通過 RAG 檢索大幅減少發送給模型的內容量
客戶端處理 PDF 的注意事項
- 配置 API Key: 在客戶端中填入 API易 apiyi.com 的 API Key,即可通過一個 Key 訪問所有模型
- 控制文件大小: 超大 PDF(幾百頁)向量化時間較長,建議拆分後處理
- 注意 Token 費用: 雖然 RAG 會壓縮內容,但長文檔仍可能產生較高費用
- 選擇合適模型: 簡單問答可用便宜模型(如 GPT-4o-mini),複雜分析用旗艦模型
大模型 API PDF 處理 3 種方案對比
<!– SVG_COMPARISON: 3種方案的成本/效果/適用場景綜合對比 –>

| 方案 | Token 成本 | 圖表支持 | 開發難度 | 模型兼容 | 最佳場景 |
|---|---|---|---|---|---|
| 文字化提取 | 最低(300-1500/頁) | 不支持 | 中等 | 所有模型 | 純文本 PDF、大批量 |
| 轉圖片理解 | 較高(~765/頁) | 完整支持 | 中等 | 需 Vision 模型 | 圖表、掃描件 |
| 客戶端處理 | 中等(RAG 壓縮) | 取決於客戶端 | 零代碼 | 所有模型 | 日常對話、非開發 |
對比說明: 三種方案不是互斥的,實際項目中往往組合使用。例如先用方案一提取文本做粗篩,再對關鍵頁面用方案二做圖片理解。通過 API易 apiyi.com 可以統一接入所有模型。
常見問題
Q1: 爲什麼 ChatGPT 網頁版可以上傳 PDF,但 API 不支持?
網頁版的"上傳 PDF"功能是產品前端幫你做了預處理——提取文本、渲染圖片、建立檢索索引——然後再調用底層 API。API 本身的核心輸入格式是文本和圖片,PDF 作爲一種複雜的文檔容器格式不在標準支持範圍內。你調用 API 時,需要自己完成這些預處理步驟。
Q2: API易等第三方中轉平臺能幫我處理 PDF 嗎?
不能。API易等中轉平臺的本質是透傳 API 請求,底層協議不支持 PDF 的話,平臺也無法處理。你需要在調用 API 之前自行完成 PDF 的預處理(提取文本或轉圖片),然後將處理後的文本或圖片通過 API易 apiyi.com 發送給大模型。
Q3: 處理 PDF 時如何控制 Token 費用?
幾個實用技巧:
- 優先用方案一(文字化提取),成本最低
- 只處理需要的頁面,不要一次傳整份文檔
- 使用 RAG 技術切分+檢索,只發送相關片段給模型
- 簡單問答用便宜模型(GPT-4o-mini),複雜分析用旗艦模型
- 通過 API易 apiyi.com 的用量面板實時監控消耗
總結
大模型 API PDF 輸入的核心要點:
- 絕大多數 API 不支持直接 PDF 輸入: 大模型的核心輸入是文本和圖片,PDF 需要預處理後才能使用
- 第三方平臺同樣不支持: API易等中轉平臺透傳原始協議,無法額外處理 PDF
- 3 種方案按需選擇: 純文本 PDF 用文字化提取(最省錢),帶圖 PDF 轉圖片理解(最保真),日常對話用客戶端(最省事)
不必糾結於"哪個 API 支持 PDF",而是把精力放在選對預處理方案上——這纔是正確的思路。
推薦通過 API易 apiyi.com 獲取免費額度,預處理 PDF 後用一個 API Key 調用 GPT、Claude、DeepSeek 等所有主流模型進行測試對比。
📚 參考資料
-
PyMuPDF4LLM 文檔: PDF 文字化提取工具
- 鏈接:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - 說明: 速度最快的 PDF 轉 Markdown 工具,推薦首選
- 鏈接:
-
pdfplumber 文檔: 表格提取專用工具
- 鏈接:
github.com/jsvine/pdfplumber - 說明: PDF 中表格數據提取精度最高的工具
- 鏈接:
-
Cherry Studio: 開源 AI 客戶端
- 鏈接:
github.com/CherryHQ/cherry-studio - 說明: 支持 PDF 拖入對話的免費客戶端,可配置 API易作爲後端
- 鏈接:
-
API易平臺文檔: 統一接入各大模型 API
- 鏈接:
docs.apiyi.com - 說明: API Key 獲取、模型列表和調用示例
- 鏈接:
作者: APIYI 技術團隊
技術交流: 歡迎在評論區討論,更多資料可訪問 API易 docs.apiyi.com 文檔中心