Примечание автора: Глубокий разбор возможностей большой языковой модели GLM-4.7 по структурированию текста. Освойте практические навыки извлечения ключевой информации в формате JSON из сложных документов, таких как контракты и отчеты.
Быстрое извлечение ключевой информации из огромных массивов неструктурированного текста — это одна из главных задач при обработке данных в бизнесе. Выпущенная в декабре 2025 года большая языковая модель GLM-4.7 от Zhipu AI предлагает прорывное решение для задач структурирования текста благодаря нативной поддержке JSON Schema и рекордному окну контекста в 200K токенов.
Ключевая ценность: Прочитав эту статью, вы научитесь использовать GLM-4.7 для извлечения структурированных данных из сложных документов (контрактов, отчетов и т. д.), что позволит на порядок повысить эффективность их обработки.

Ключевые особенности структурирования текста в GLM-4.7
| Особенность | Описание | Преимущество |
|---|---|---|
| Нативная JSON Schema | Встроенная поддержка структурированного вывода, не требует сложного промпт-инжиниринга | Точность извлечения выше на 40%+ |
| Контекстное окно 200K | Поддержка длинных документов целиком, без необходимости разбиения на части | Обработка полного текста контракта или отчета за один раз |
| Лимит вывода 128K | Возможность генерации сверхдлинных структурированных результатов | Идеально для массового извлечения информации |
| Поддержка вызова функций | Нативная поддержка Tool Calling | Бесшовная интеграция в бизнес-системы |
| Выгода по стоимости | $0.10 за 1 млн токенов — в 4–7 раз дешевле аналогов | Контролируемые затраты при масштабном развертывании |
Подробный разбор структурирования текста в GLM-4.7
GLM-4.7 — это флагманская большая языковая модель нового поколения, представленная Zhipu AI 22 декабря 2025 года. Модель построена на архитектуре Mixture-of-Experts (MoE) с общим числом параметров около 358 млрд, при этом использование механизма разреженной активации обеспечивает высокую эффективность вычислений. В области структурирования текста GLM-4.7 совершила качественный скачок по сравнению с предыдущей версией GLM-4.6: показатели в бенчмарке HLE выросли на 38%, достигнув 42,8%, что сопоставимо с уровнем GPT-5.1 High.
Возможности структурированного вывода в GLM-4.7 реализуются в трех плоскостях. Во-первых, это перемежающееся мышление (Interleaved Thinking): модель автоматически планирует путь рассуждения перед каждым ответом, что гарантирует логическую связность при извлечении данных. Во-вторых — сохраненное мышление (Preserved Thinking), которое позволяет удерживать контекст рассуждений в многоэтапных диалогах, что критически важно для сложных итеративных задач. И наконец, контроль на уровне реплик (Turn-level Control) дает возможность динамически регулировать глубину проработки каждого запроса, позволяя гибко балансировать между скоростью работы и точностью результата.
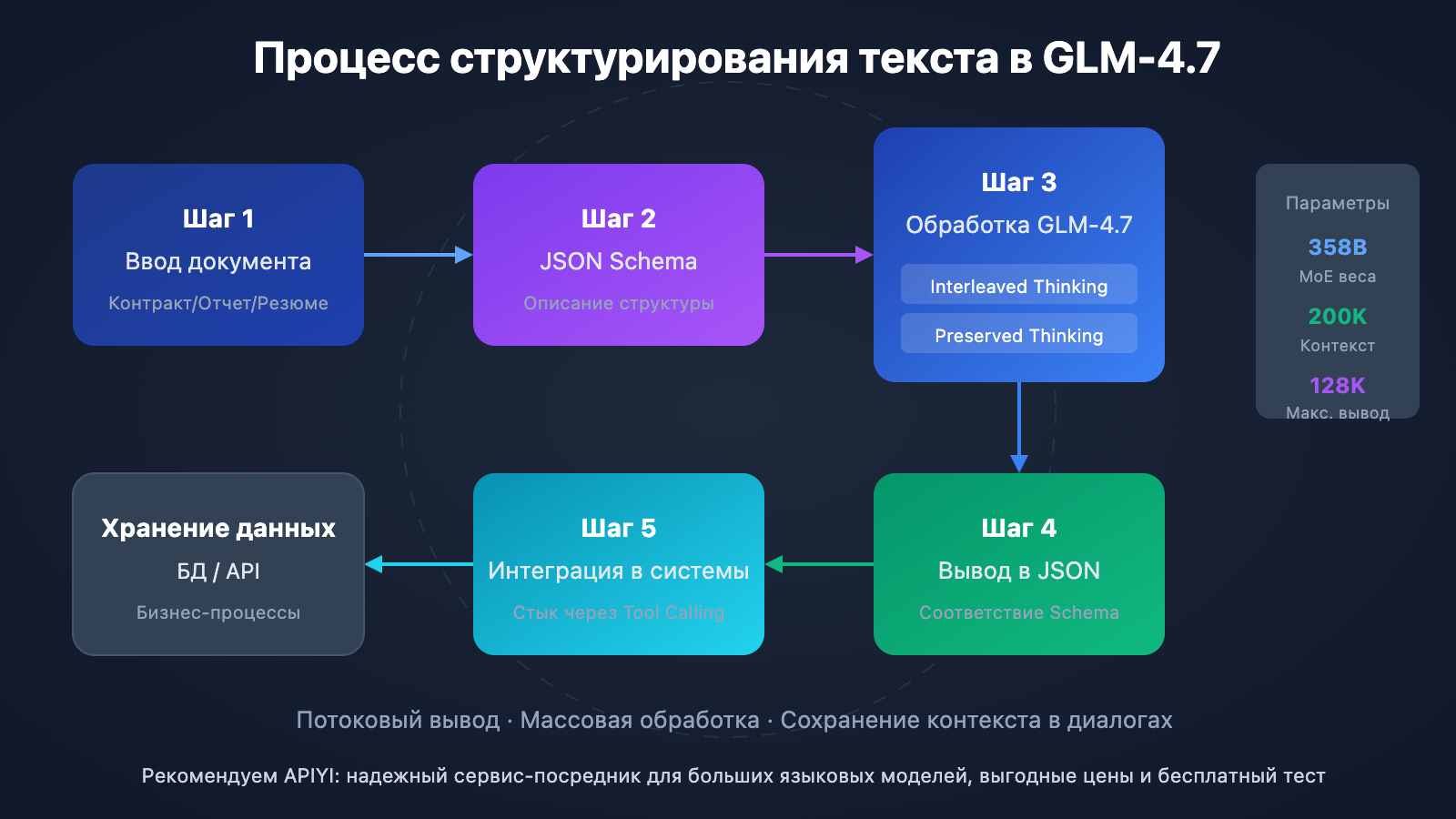
Быстрый старт: структурирование текста с GLM-4.7
Простейший пример
Вот самый простой способ: всего 10 строк кода, и структурированные данные из текста у вас в кармане.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="glm-4.7",
messages=[{"role": "user", "content": "Извлеки из следующего текста: Сторона А, Сторона Б, сумма, дата. Текст: Сторона А: ООО 'Пекинские технологии', Сторона Б: Шанхайские инновации, сумма договора: 500 000 юаней, дата подписания: 15 декабря 2025 года"}],
response_format={"type": "json_object"}
)
print(response.choices[0].message.content)
Посмотреть полный код реализации (с использованием JSON Schema)
import openai
from typing import Optional, Dict, Any
def extract_contract_info(
contract_text: str,
api_key: str = "YOUR_API_KEY",
base_url: str = "https://vip.apiyi.com/v1"
) -> Dict[str, Any]:
"""
Использует GLM-4.7 для извлечения структурированной информации из текста договора
Аргументы:
contract_text: Исходный текст договора
api_key: API-ключ
base_url: Базовый URL API
Возвращает:
Словарь с извлеченной информацией
"""
client = openai.OpenAI(api_key=api_key, base_url=base_url)
# Определение JSON Schema для строгого формата вывода
json_schema = {
"name": "contract_extraction",
"schema": {
"type": "object",
"properties": {
"party_a": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "Наименование Стороны А"},
"representative": {"type": "string", "description": "Законный представитель"},
"address": {"type": "string", "description": "Юридический адрес"}
},
"required": ["name"]
},
"party_b": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "Наименование Стороны Б"},
"representative": {"type": "string", "description": "Законный представитель"},
"address": {"type": "string", "description": "Юридический адрес"}
},
"required": ["name"]
},
"contract_amount": {
"type": "object",
"properties": {
"value": {"type": "number", "description": "Числовое значение суммы"},
"currency": {"type": "string", "description": "Валюта"},
"text": {"type": "string", "description": "Сумма прописью"}
},
"required": ["value", "currency"]
},
"dates": {
"type": "object",
"properties": {
"sign_date": {"type": "string", "description": "Дата подписания"},
"effective_date": {"type": "string", "description": "Дата вступления в силу"},
"expiry_date": {"type": "string", "description": "Дата окончания срока действия"}
}
},
"key_terms": {
"type": "array",
"items": {"type": "string"},
"description": "Краткое описание ключевых условий"
}
},
"required": ["party_a", "party_b", "contract_amount"]
}
}
response = client.chat.completions.create(
model="glm-4.7",
messages=[
{
"role": "system",
"content": "Ты — эксперт по анализу юридических документов. Пожалуйста, точно извлеки ключевую информацию из текста договора."
},
{
"role": "user",
"content": f"Извлеки ключевую информацию из следующего договора:\n\n{contract_text}"
}
],
response_format={
"type": "json_schema",
"json_schema": json_schema
},
max_tokens=4000
)
import json
return json.loads(response.choices[0].message.content)
# Пример использования
contract = """
ДОГОВОР ЗАКУПКИ
Сторона А: Пекинская технологическая компания "Zhipu"
Законный представитель: Чжан Сань
Адрес: Пекин, район Хайдянь, пр-т Чжунгуаньцунь, д. 1
Сторона Б: Шанхайская инновационная технологическая группа
Законный представитель: Ли Сы
Адрес: Шанхай, новый район Пудун, ул. Чжанцзян, д. 100
Сумма договора: Пятьсот тысяч юаней ровно (¥500,000.00)
Дата подписания: 15 декабря 2025 г.
Срок действия договора: с 15 декабря 2025 г. по 14 декабря 2026 г.
Основные условия:
1. Исполнитель предоставляет Заказчику услуги API для ИИ-моделей.
2. Оплата производится ежеквартально авансовым платежом.
3. Гарантированная доступность сервиса (SLA) — 99.9%.
"""
result = extract_contract_info(contract)
print(result)
Совет: Получите бесплатные тестовые баллы на APIYI, чтобы быстро проверить возможности GLM-4.7 по структурированию текста. Платформа поддерживает единый интерфейс для вызова популярных моделей, что позволяет легко сравнить точность извлечения GLM-4.7 с другими решениями.
Сценарии применения структурирования текста с GLM-4.7
Возможности GLM-4.7 по структурированию данных отлично подходят для различных бизнес-задач:
| Сценарий | Входные данные | Формат вывода | Типичный рост эффективности |
|---|---|---|---|
| Извлечение данных из договоров | PDF/Word документы | Структурированный JSON | С нескольких часов → до минут |
| Анализ финансовой отчетности | Годовые/квартальные отчеты | Таблицы финансовых показателей | Точность 95%+ |
| Скрининг резюме | Текст резюме | Профиль кандидата (JSON) | Эффективность отбора в 10 раз выше |
| Мониторинг инфополя | Новости/соцсети | Граф связей сущностей | Обработка в реальном времени |
| Анализ аналитических отчетов | Отраслевые исследования | Ключевые тезисы и выводы | Охват информации в 5 раз шире |
Технические преимущества GLM-4.7 в структурировании текста
1. Нативная поддержка JSON Schema
Как и модели серии GPT, GLM-4.7 позволяет напрямую указывать JSON Schema в параметре response_format. Модель будет строго придерживаться заданной структуры. Это значит, что вам не нужно писать длинные и сложные промпты, чтобы «уговорить» модель выдать нужный формат — вы просто декларативно описываете структуру.
2. Обработка сверхдлинного контекста
Окно контекста в 200K токенов означает, что GLM-4.7 может за раз обработать текст объемом около 150 000 иероглифов (или соразмерный объем на кириллице), что эквивалентно толстому договору или технической спецификации. Это избавляет от необходимости делить документы на части, что часто приводит к потере смысла и разрыву контекста.
3. Улучшенная точность благодаря «цепочке рассуждений»
При выполнении сложных задач извлечения GLM-4.7 автоматически применяет многошаговое рассуждение перед выводом результата. Например, при извлечении суммы договора модель сначала найдет фрагменты, связанные с финансами, сопоставит цифры с суммой прописью и только после такой перекрестной проверки выдаст наиболее достоверный результат.
Практический совет: Мы рекомендуем проводить тестирование на платформе APIYI (apiyi.com). Там можно оценить работу GLM-4.7 на ваших конкретных задачах, используя бесплатные баллы и подробные логи вызовов для отладки.

Сравнение решений для структурирования текста в GLM-4.7
| Решение | Ключевые особенности | Сценарии использования | Производительность |
|---|---|---|---|
| GLM-4.7 | Нативная JSON Schema, контекст 200K, низкая стоимость | Извлечение данных из длинных документов, масштабная обработка, чувствительность к затратам | HLE 42,8%, SWE-bench 73,8% |
| GPT-5.1 | Стабильность вывода, зрелая экосистема, быстрый отклик | Высокие требования к надежности, сценарии быстрой поставки | HLE 42,7%, лучшее время отклика |
| Claude Sonnet 4.5 | Сильное логическое мышление, глубокое понимание контекста | Сложные аналитические задачи, многошаговые рассуждения | HLE 32,0%, отличная глубина логики |
| DeepSeek-V3 | Открытый код, возможность развертывания, высокая эффективность | Приватное развертывание, индивидуальные требования | Отличные показатели в бенчмарках |
Ключевые отличия GLM-4.7 от конкурентов
| Параметр сравнения | GLM-4.7 | GPT-5.1 | Claude Sonnet 4.5 |
|---|---|---|---|
| Статус открытого кода | Открытый (Apache 2.0) | Закрытый | Закрытый |
| Цена (за 1 млн токенов) | $0.10 | ~$0.50 | ~$0.40 |
| Окно контекста | 200K | 128K | 200K |
| Максимальный вывод | 128K | 16K | 8K |
| Оптимизация под китайский язык | Высокая | Средняя | Средняя |
| Локальное развертывание | Поддерживается | Не поддерживается | Не поддерживается |
Рекомендации по выбору:
- Если вам нужно обрабатывать большие объемы документов на китайском языке и вы ограничены в бюджете, GLM-4.7 — лучший выбор.
- Если важна стабильность вывода и удобство интеграции в экосистему, GPT-5.1 выглядит более зрелым решением.
- Если задача требует сложных многошаговых рассуждений, Claude Sonnet 4.5 обладает более мощной логикой.
Примечание к сравнению: Данные взяты из открытых бенчмарков, таких как HLE и SWE-bench. Вы можете провести собственное сравнение и проверку через платформу APIYI (apiyi.com). Платформа поддерживает единый интерфейс вызова для всех вышеперечисленных моделей.
Продвинутые приемы структурирования текста в GLM-4.7
Пакетная обработка документов
Для задач по структурированию больших массивов документов можно использовать возможности потокового вывода и параллелизма GLM-4.7:
import asyncio
import aiohttp
async def batch_extract(documents: list, api_key: str):
"""批量异步提取文档信息"""
async with aiohttp.ClientSession() as session:
tasks = [
extract_single(session, doc, api_key)
for doc in documents
]
results = await asyncio.gather(*tasks)
return results
Интеграция Function Calling
Функция Tool Calling в GLM-4.7 позволяет напрямую передавать результаты извлечения в бизнес-системы:
tools = [
{
"type": "function",
"function": {
"name": "save_contract_to_database",
"description": "将提取的合同信息保存到数据库",
"parameters": {
"type": "object",
"properties": {
"contract_id": {"type": "string"},
"party_a": {"type": "string"},
"party_b": {"type": "string"},
"amount": {"type": "number"}
},
"required": ["contract_id", "party_a", "party_b", "amount"]
}
}
}
]
Часто задаваемые вопросы
В1: Какова точность извлечения структурированных данных у GLM-4.7?
В стандартных сценариях, таких как типовые контракты, резюме или финансовые отчеты, точность извлечения GLM-4.7 при использовании ограничений JSON Schema достигает 95% и выше. Для работы со сложными документами мы рекомендуем внедрять механизмы ручной проверки. Модель использует режим перекрестного мышления для автоматической многоэтапной верификации, что дополнительно повышает надежность результата.
В2: Есть ли ограничения при обработке длинных документов в GLM-4.7?
GLM-4.7 поддерживает контекстное окно в 200K токенов, что примерно соответствует 150 тысячам иероглифов. Если вам нужно обработать сверхдлинный документ, советуем разбивать его на логические главы или использовать инструменты для сегментации текстов, доступные на платформе APIYI. Максимальный объем вывода за один раз составляет 128K токенов, чего вполне достаточно для большинства задач по структурированию данных.
В3: Как быстро начать тестирование возможностей GLM-4.7 по структурированию текста?
Для тестирования лучше всего использовать платформу-агрегатор API, поддерживающую несколько моделей:
- Зайдите на сайт APIYI apiyi.com и зарегистрируйте аккаунт.
- Получите API-ключ и бесплатные токены для старта.
- Используйте примеры кода из этой статьи для быстрой проверки.
- Сравните результаты разных моделей в контексте ваших бизнес-задач.
Итоги
Ключевые моменты структурирования текста с помощью GLM-4.7:
- Нативная поддержка структур: Вывод в формате JSON Schema без необходимости в сложном промпт-инжиниринге.
- Огромный контекст: Окно в 200K токенов позволяет обрабатывать длинные документы целиком за один проход.
- Выгодная цена: Стоимость в 4–7 раз ниже, чем у аналогичных моделей, что делает её идеальной для масштабного развертывания.
- Оптимизация под китайский язык: Как отечественная модель (для Китая), она точнее понимает специфику китайских контрактов и отчетов.
Будучи флагманской моделью от Zhipu AI, GLM-4.7 демонстрирует возможности, сопоставимые с GPT-5.1 в области структурирования данных, обладая при этом преимуществами открытого исходного кода, низкой стоимости и отличной локализации. Для компаний с большим объемом документооборота GLM-4.7 — это решение, которое определенно стоит рассмотреть.
Рекомендуем быстро проверить эффект через APIYI apiyi.com: платформа предоставляет бесплатные лимиты и единый интерфейс для разных моделей, что очень удобно для тестов в реальных условиях.
Справочные материалы
⚠️ Примечание по формату ссылок: Все внешние ссылки указаны в формате
Название: domain.com. Это удобно для копирования, но ссылки не кликабельны, чтобы избежать потери веса SEO.
-
Официальная документация GLM-4.7: Документация для разработчиков Zhipu AI
- Ссылка:
docs.z.ai/guides/llm/glm-4.7 - Описание: Содержит полное описание параметров API и лучшие практики.
- Ссылка:
-
Технический анализ GLM-4.7: Глубокий разбор архитектуры и возможностей модели
- Ссылка:
medium.com/@leucopsis/a-technical-analysis-of-glm-4-7-db7fcc54210a - Описание: Сторонний технический обзор, включающий сравнение результатов бенчмарков.
- Ссылка:
-
Страница модели на Hugging Face: Загрузка открытых весов
- Ссылка:
huggingface.co/zai-org/GLM-4.7 - Описание: Файлы модели и руководства, необходимые для локального развертывания.
- Ссылка:
-
OpenRouter GLM-4.7: Многоканальный доступ к API
- Ссылка:
openrouter.ai/z-ai/glm-4.7 - Описание: Варианты подключения через разных провайдеров и сравнение цен.
- Ссылка:
Автор: Техническая команда
Техническое обсуждение: Делитесь своим опытом структурирования текста с помощью GLM-4.7 в комментариях. Больше полезных материалов можно найти в техническом сообществе APIYI на apiyi.com