Многие пользователи, впервые открывая веб-версию ChatGPT, сталкиваются с иллюзией: стоит загрузить PDF или написать пару строк, как нейросеть «по щелчку» выдает 5 изображений в едином стиле. Но стоит перейти к API и выставить параметр n на 5, как вместо серии вы получаете 5 почти идентичных вариантов, похожих на случайную лотерею. Почему одна и та же модель ведет себя так по-разному?
В этой статье мы не будем давать «единственно верный» ответ, а разберем проблему, с которой постоянно сталкиваемся в техподдержке. Мы подробно разберем два принципиально разных технических пути генерации изображений в GPT, объясним, почему параметр n не предназначен для создания полноценных серий, и предложим рабочие способы реализации согласованности изображений при работе через API.
1. Два технических пути генерации изображений в GPT
Чтобы разобраться в этом, нужно принять одну простую истину: «генерация нескольких изображений за раз» и «генерация серии изображений с логической связью» — это две разные вещи. Первое — это просто массовое производство, второе — то, что мы называем настоящей серией.
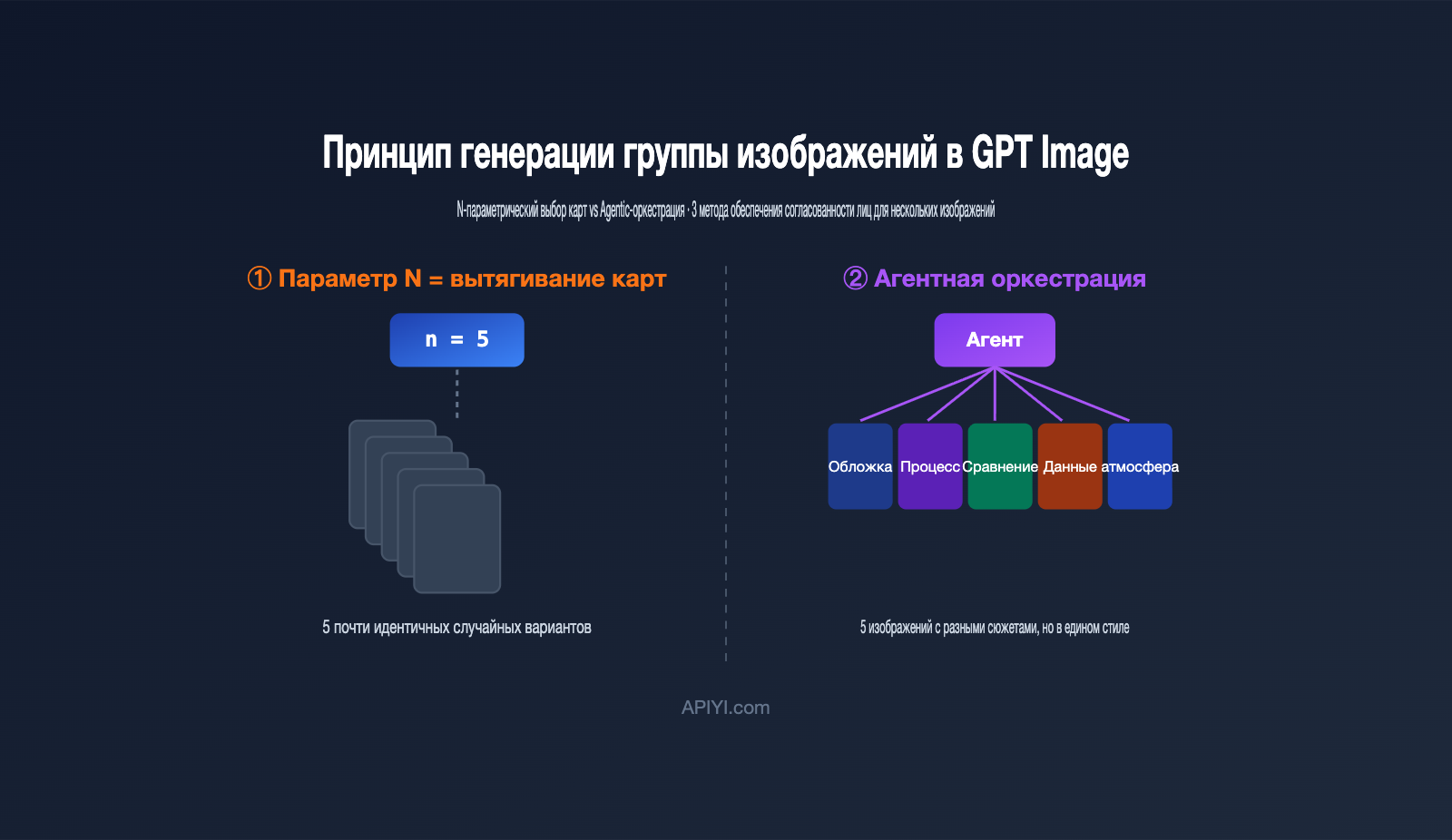
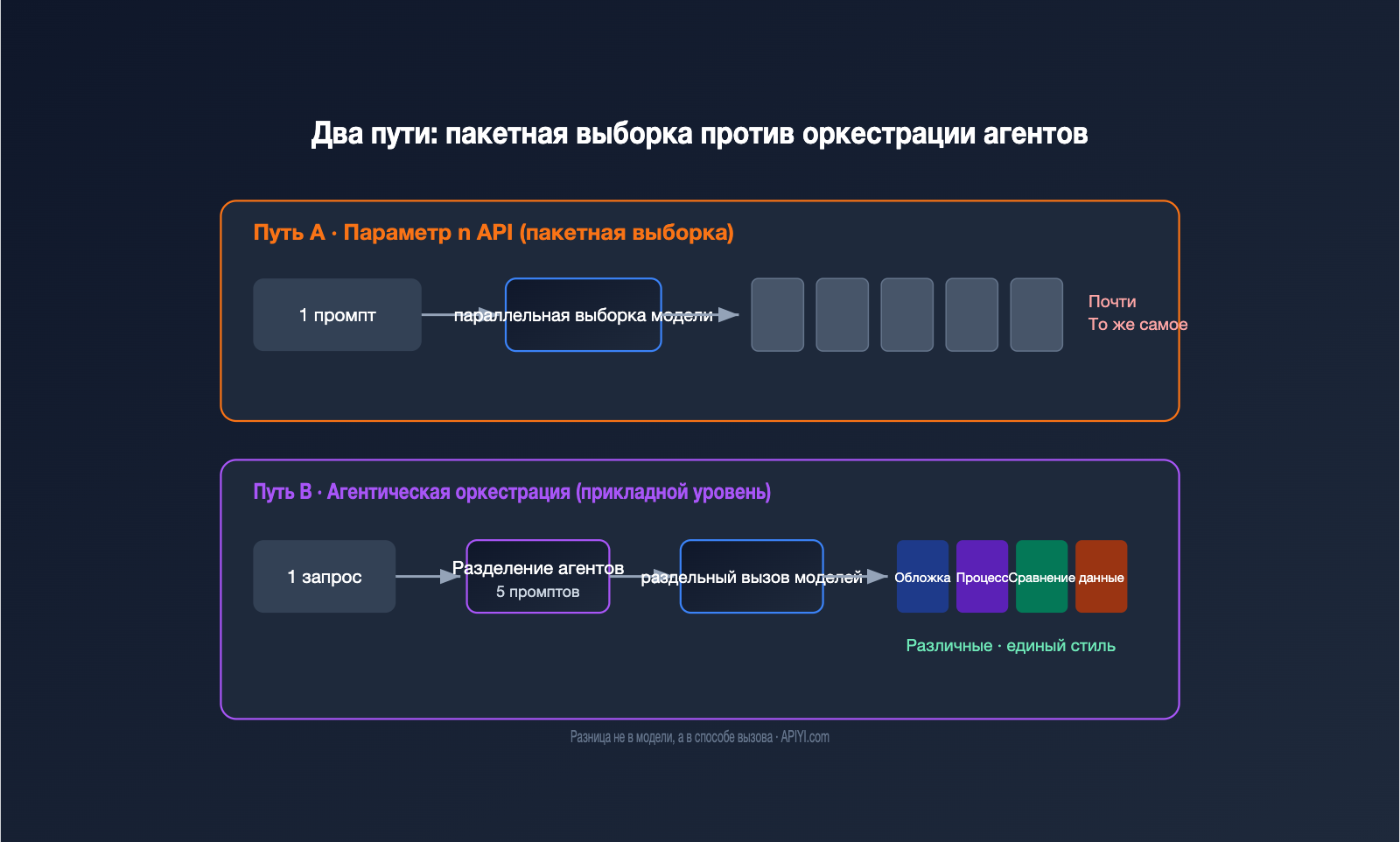
В инженерном плане GPT Image использует два пути. Первый — это пакетная выборка на уровне модели, то есть параметр n в API: вы подаете один промпт, и модель параллельно генерирует несколько вариантов. Второй — это Agentic-оркестрация на уровне приложения, где агент сначала анализирует задачу, разбивает её на подзадачи, по очереди вызывает генерацию и собирает результат в единую серию.
В таблице ниже мы наглядно сравнили эти подходы:
| Параметр | Параметр API n (пакетная выборка) |
Agentic-оркестрация (уровень приложения) |
|---|---|---|
| Суть | Повторная случайная выборка по одному промпту | Последовательная генерация после разбиения задачи |
| Содержание | Почти идентичные изображения, лишь случайные вариации | Разные изображения, объединенные общей темой |
| Понимание «серии» | Нет, чистая параллельность | Да, есть логика планирования |
| Стоимость | Цена одного изображения × N | Сумма затрат на каждый вызов |
| Источник согласованности | Промпт и случайный сид (seed) | Эталонное изображение + единые ограничения промпта |
| Типичные сценарии | Выбор одного удачного варианта из кучи | Иллюстрации для серии, картинки для презентации, комиксы |
Проще говоря, параметр n нужен для того, чтобы «дать мне несколько вариантов на выбор», а для создания серии нужно «выдать ряд контента по одной теме». Именно поэтому при прямом вызове API часто кажется, что результат «не дотягивает» до веб-версии. Если хотите протестировать оба подхода, APIYI (apiyi.com) позволяет сделать это с одним и тем же ключом, не переключаясь между платформами.
二、为什么 API 的 n 参数做不出真正的组图
很多开发者的第一反应是:既然要 5 张图,那把 n 设成 5 不就行了?实际跑一遍就会发现,出来的 5 张图往往是「同一个东西的 5 个微小变体」,而不是「一组互相配合的图」。
原因在于 n 参数的工作机制。它并不会改变你的提示词,而是用同一个提示词再跑几遍,靠模型生成过程中的随机采样制造差异。OpenAI 开发者社区里有一句很贴切的描述:这些图来自「同一输入下随机采样产生的变化」(random sampling variations)。换句话说,这就是抽卡——同样的卡池,抽 5 次,卡面相似、稀有度随机。
这带来两个直接后果。其一,你无法在一次调用里表达「第一张画封面、第二张画流程、第三张画对比」这种结构化需求,因为提示词只有一个。其二,费用是线性叠加的: n=5 就是按 5 张图计费,而不是打包优惠。
下表用一个具体场景说明这个差异,假设你想为一篇文章生成 5 张不同用途的配图。
| 需求 | 用 n=5 的结果 | 你真正想要的 |
|---|---|---|
| 封面图 | 5 张都是封面候选 | 1 张封面 |
| 流程图 | 拿不到 | 1 张流程图 |
| 对比图 | 拿不到 | 1 张对比图 |
| 数据图 | 拿不到 | 1 张数据图 |
| 配图 | 拿不到 | 1 张氛围图 |
结论很清楚:n 参数适合「我要一张好图,多给几个候选让我挑」,不适合「我要一套内容不同的组图」。理解了这一点,就不会再纠结于「为什么 API 出不来网页版那种效果」——因为你用错了工具。想低成本验证 n 参数的抽卡特性,APIYI (apiyi.com) 支持按调用量计费,跑几组对比实验花不了多少钱。
三、网页版组图背后的 Agentic 编排原理
那 ChatGPT 网页版凭什么能「一个 PDF 出 5 张图」?答案就是上面提到的第二条路径——Agentic 编排,而这恰好是 2026 年 4 月发布的 GPT Image 2 / ChatGPT Images 2.0 带来的关键升级。
按照 OpenAI 的官方定位,GPT Image 2 是首个把「推理能力」内置进图像模型的版本:它在动笔之前会先研究、规划、推理图像结构(proactively researches, plans, and reasons),这套机制在网页端被称为 Thinking 模式。所以当你丢进去一份 PDF,模型不是简单地「读图」,而是先理解文档讲了什么、需要几张图、每张图分别承担什么角色,再逐张生成。
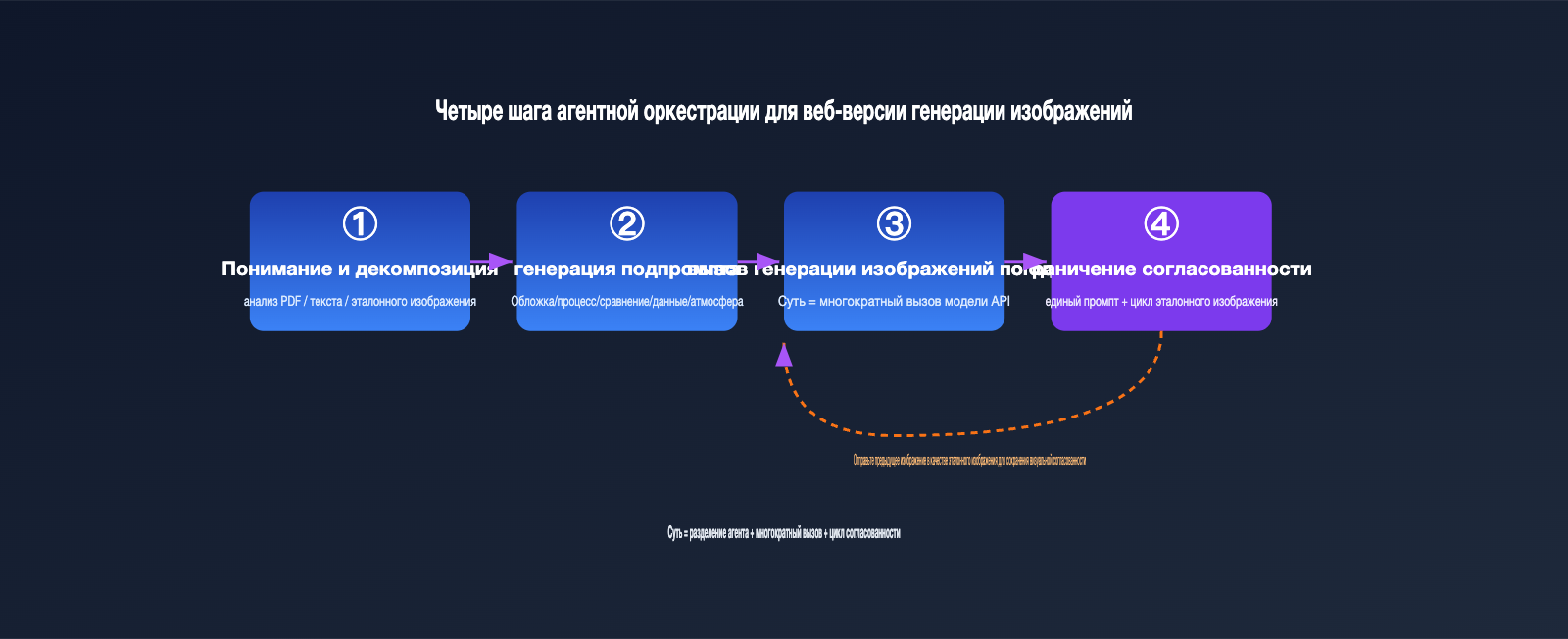
把这个过程翻译成工程语言,大致是四步:
- 理解与拆解: Agent 解析输入(文本、PDF、参考图),判断需要几张图、每张图的主题。
- 生成子提示词:为每张图各写一条独立的提示词,例如「整体架构图」「关键流程图」「数据对比图」。
- 逐张调用生图:对每条子提示词分别调用底层生图能力,本质上是多次 API 调用。
- 一致性约束:在每条提示词里注入统一的风格描述,并把前面生成的图作为参考图传给后面,保证整组视觉统一。
学术界也在用类似思路。多智能体框架(如视频生成里的 ViMax、文生图里的 Maestro)会把一个大需求拆成多个细粒度的视觉子问题,并行生成、择优选取,再把前一帧或前一张图作为后续生成的参考,以此维持角色和场景的连贯。GPT Image 2 的过人之处,是把这套原本要工程师手搭的编排,收进了模型自身的推理回路里。
这里也藏着真正的难点:多次独立调用天然会漂移。每一张图都是一次新的随机采样,角色长相、配色、画风都可能跑偏。这就是我们和客户聊到的那个核心问题——「如何保持视觉一致性」,它比「如何出多张图」难得多。下一节就专门讲怎么对付它。
IV. Создание серии изображений через API: 3 способа обеспечить визуальную согласованность
Если вы не хотите полагаться на веб-интерфейс и планируете внедрить генерацию изображений GPT в свой продукт, вам придется самостоятельно выстроить логику оркестрации. Ключ к успеху — использование инженерных подходов для компенсации «визуальной согласованности». Основываясь на практике, мы выделили три метода: от простого к сложному, которые можно комбинировать.
Метод 1: Ограничение через единый промпт (таблица описания персонажа). Самый бюджетный вариант — составить фиксированный «ДНК стиля» для всей серии и каждый раз добавлять его в промпт. Например: «плоская иллюстрация, основные цвета — темно-синий и янтарный, персонаж — женщина-инженер с короткой стрижкой». В сообществе такие описания называют «библией персонажа» (character bible): чем детальнее описание, тем выше согласованность между изображениями.
Метод 2: Передача эталонного изображения (изображение-в-изображение). Возьмите первое удачное изображение и передавайте его как эталонное при каждом последующем вызове. GPT Image 2 в режиме редактирования/ссылки поддерживает передачу нескольких эталонных изображений (в официальной документации указано до 16, но лучше проверять на практике). Это делает «задание стиля по картинке» основным инструментом для обеспечения согласованности. Результат обычно стабильнее, чем при использовании только текста, особенно в таких деталях, как внешность персонажа.
Метод 3: Оркестрация агентов + цикл с эталонным изображением. Объедините первые два метода в цикл: сначала генерируется базовое изображение, а затем каждое последующее создается на основе этого базового изображения + единого промпта. При необходимости можно также использовать предыдущий кадр в качестве эталонного. Это именно то, что делает режим Thinking в веб-версии, просто вы прописываете эту логику в коде.
Ниже приведен упрощенный пример оркестрации, демонстрирующий базовую логику: «сначала создаем эталон, затем генерируем серию с опорой на него».
from openai import OpenAI
# base_url указывает на APIYI, централизованное управление ключами для разных моделей
client = OpenAI(base_url="https://api.apiyi.com/v1", api_key="YOUR_KEY")
STYLE = "плоская иллюстрация, основные цвета — темно-синий и янтарный, персонаж — женщина-инженер с короткой стрижкой" # Описание персонажа
shots = ["Обложка: персонаж стоит перед дата-центром", "Процесс: персонаж рисует архитектуру на доске", "Итог: персонаж показывает большой палец"]
# 1. Сначала генерируем базовое изображение, фиксируя стиль всей серии
base = client.images.generate(model="gpt-image-2", prompt=f"{shots[0]},{STYLE}")
# 2. Последующие изображения генерируются с единым стилевым ограничением (в продвинутых кейсах можно передавать base как эталонное изображение в интерфейс edits)
for shot in shots[1:]:
img = client.images.generate(model="gpt-image-2", prompt=f"{shot},{STYLE}")
# save(img) ...
Чтобы вам было проще выбрать, в таблице ниже мы сравнили характеристики и сценарии применения этих методов.
| Метод | Уровень согласованности | Сложность реализации | Сценарий применения |
|---|---|---|---|
| Единый промпт | Средний | Низкая | Достаточно единства стиля, персонаж не критичен |
| Передача эталонного изображения | Высокий | Средняя | Повторяющийся персонаж или продукт |
| Оркестрация агентов | Максимальный | Высокая | Комиксы, серии иллюстраций, брендовые материалы |
Эти методы можно комбинировать: используйте промпт для задания тона, эталонное изображение — для фиксации персонажа, а оркестрацию — для контроля структуры. Мы рекомендуем начать с «единого промпта + эталонного изображения», а после отладки переходить к полноценной оркестрации. На платформе APIYI (apiyi.com) модели gpt-image-2, gpt-image-1.5 и другие используют один и тот же base_url и API-ключ, что позволяет легко переключаться между моделями для тестирования согласованности без изменения кода.

V. Стоимость генерации серий изображений в GPT Image и выбор модели
Генерация серии изображений подразумевает множественные вызовы API, из-за чего расходы могут быстро вырасти, поэтому крайне важно правильно выбрать модель. На текущий момент в производственных задачах чаще всего используются несколько версий GPT Image, каждая из которых имеет свои особенности.
| Модель | Позиционирование | Поддержка логического вывода | Подходящие сценарии |
|---|---|---|---|
| gpt-image-2 | Флагман, встроенный логический вывод | Да (Thinking) | Качественные серии материалов, постеры с текстом |
| gpt-image-1.5 | Флагман предыдущего поколения | Частично | Массовая генерация с балансом качества и цены |
| gpt-image-1 | Классика, стабильность | Нет | Обычные изображения с простым стилем |
| gpt-image-1-mini | Легкая, бюджетная | Нет | Массовые задачи с низкими требованиями к качеству |
Важно трезво оценивать расходы: генерация серии оплачивается «по количеству изображений». Возьмем для примера разрешение 1024×1024: цена за одно изображение варьируется от нескольких долей цента до пары центов (точные цифры зависят от актуальных тарифов платформы). Серия из 5 изображений — это оплата за 5 штук. Если вы планируете массовое производство на тысячи картинок, итоговая стоимость может стать внушительной, поэтому предварительный расчет обязателен.
Наш совет: на этапе черновиков используйте mini или бюджетные настройки для быстрой проверки композиции и согласованности, а для финальной версии переключайтесь на gpt-image-2. Такая стратегия «дешевых проб + качественного финала» позволяет держать бюджет под контролем, не жертвуя результатом. APIYI (apiyi.com) предоставляет удобную панель мониторинга: вы сразу увидите, сколько стоила генерация серии и какие модели были задействованы — идеальный вариант для команд, следящих за расходами.
VI. Часто задаваемые вопросы (FAQ)
Q1: Можно ли через API получить серию разных изображений за один запрос?
Нет, параметр n здесь не поможет. n — это лишь случайная выборка по одному и тому же промпту (своего рода «вытягивание карты»), содержание будет почти идентичным. Настоящая генерация серий требует логики на уровне приложения: разбивка задачи, множественные вызовы и последующее наложение ограничений для обеспечения согласованности.
Q2: Какую «магию» использует веб-версия ChatGPT для генерации серий?
Никакой магии, просто в GPT Image 2 встроен агентный логический вывод. Перед генерацией модель планирует, «сколько изображений нужно и что именно на них будет», а затем создает их по очереди. По сути, это все те же множественные вызовы, просто процесс планирования скрыт от пользователя.
Q3: Какой самый эффективный способ добиться согласованности между изображениями?
На практике лучше всего работает передача эталонного изображения: используйте первое удачное изображение как референс для всех последующих вызовов — это дает гораздо более высокую точность воспроизведения персонажей и цветовой гаммы, чем просто текстовое описание. Добавьте к этому фиксированный блок описания стиля, и результат будет еще лучше. Вы можете протестировать это прямо через интерфейс эталонных изображений для gpt-image-2 на APIYI (apiyi.com).
Q4: Будет ли генерация серий стоить очень дорого?
Это зависит от количества изображений, разрешения и выбранного качества, так как оплата идет за каждое изображение. Рекомендуем использовать легкие модели для черновиков, флагманские — для финальных версий, и отслеживать расходы через панель мониторинга на платформе.
Q5: Какую модель выгоднее всего использовать для серий?
Если важны качество и отрисовка текста — выбирайте gpt-image-2; для баланса цены и качества — gpt-image-1.5; для массовых задач с низкими требованиями — gpt-image-1-mini. Поскольку все они используют единый интерфейс, переключение между моделями практически не требует усилий.
VII. Заключение
Вернемся к изначальному вопросу: почему при использовании одной и той же модели API ведет себя как «гача-игра» (лотерея), а веб-версия выдает серию связанных изображений? Разница кроется не в самой модели, а в способе вызова. Параметр n отвечает за пакетную выборку на уровне модели, решая задачу «дать несколько вариантов на выбор». Однако настоящая генерация серий изображений в GPT Image — это агентная оркестрация на уровне приложения, которая достигается за счет разбивки запроса, многократных вызовов и ограничений для обеспечения согласованности.
При этом согласованность лиц и объектов остается самой сложной задачей. К счастью, у нас есть три эффективных инструмента: единая таблица описания персонажей для задания тона, передача эталонного изображения для фиксации образа и агентный цикл для контроля структуры. Сочетание этих методов позволяет максимально приблизить результат к тому, что мы видим в веб-версии. Ценность GPT Image 2 как раз в том, что эти возможности оркестрации встроены непосредственно в цикл логического вывода модели, делая их доступными для обычных пользователей.
У этой темы вряд ли есть единственно верный ответ — это скорее обмен опытом, который, надеюсь, поможет вам избежать лишних ошибок. Если вы хотите протестировать каждый из описанных методов на практике, APIYI (apiyi.com) предоставляет унифицированный интерфейс для моделей gpt-image-2, gpt-image-1.5 и других, а также панель мониторинга использования. Это удобная отправная точка для экспериментов с генерацией серий изображений и сравнения затрат. Подробности по интеграции можно найти в центре помощи help.apiyi.com.
Данная статья подготовлена технической командой APIYI на основе практики клиентской поддержки. Пожалуйста, уточняйте актуальные характеристики моделей и цены на официальных ресурсах и платформе.