Если вы занимаетесь разработкой AI-приложений, то наверняка знакомы с этой болью: вы правите промпт уже в 17-й раз, тесты вроде бы проходят успешно, но после релиза первый же пользователь находит «краевой случай» (edge case), который полностью ломает логику работы. Именно эту проблему OpenAI попыталась решить в своей статье из Cookbook, опубликованной в октябре 2025 года: «Building resilient prompts using an evaluation flywheel» (Создание устойчивых промптов с помощью оценочного маховика).
Инженер OpenAI Нил Капсе (Neel Kapse) совместно с известным в ML-сообществе преподавателем Хамелом Хусейном (Hamel Husain) представили концепцию Evaluation Flywheel (оценочного маховика). Они адаптировали проверенную методологию из качественных социологических исследований, чтобы превратить разработку AI-приложений из подхода «написал промпт — молись, чтобы заработало» в настоящую инженерную дисциплину. В этой статье мы разберем фреймворк оценочного маховика OpenAI простыми словами и поймем, как внедрить его в ваши проекты.
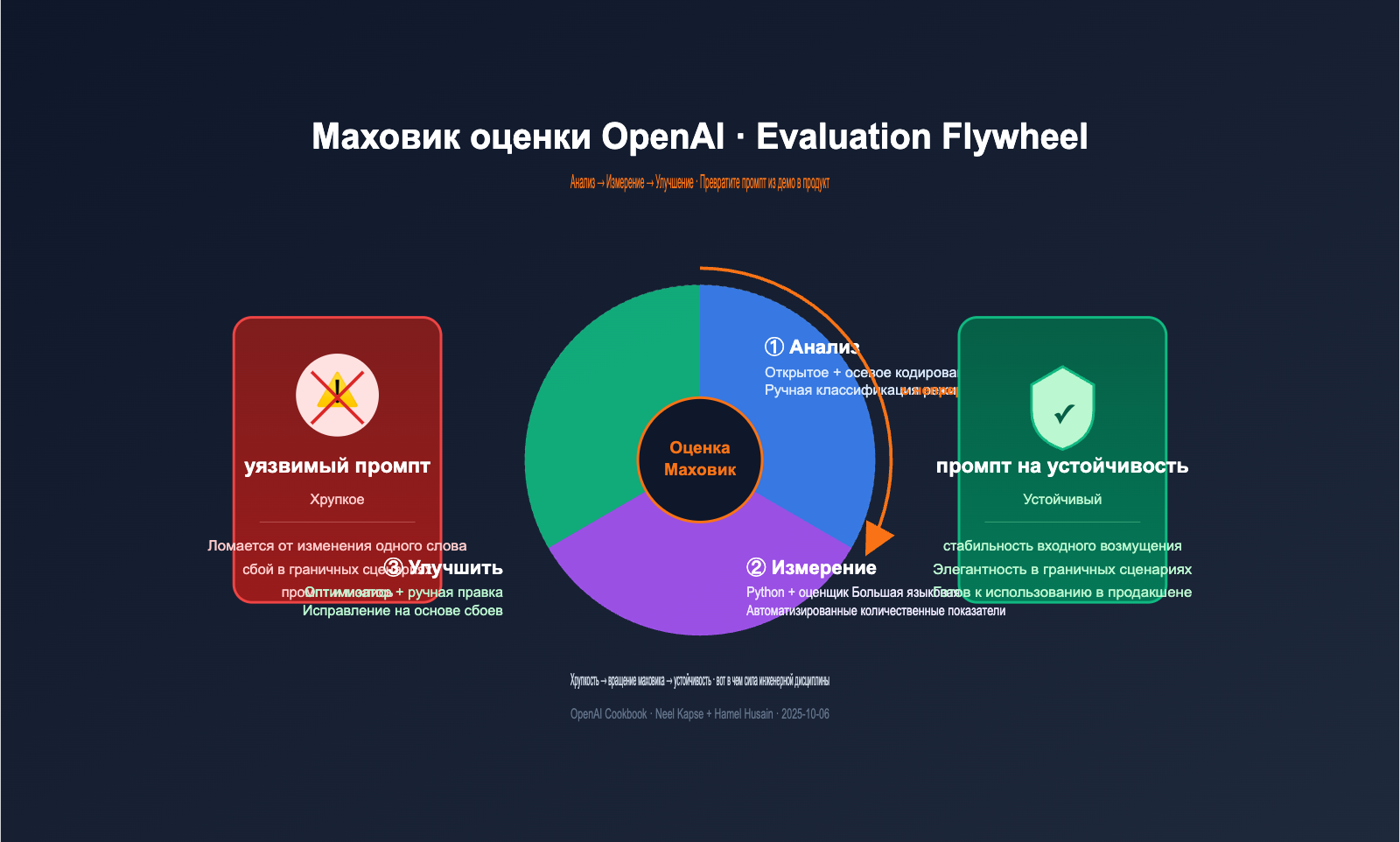
{Маховик оценки OpenAI · Evaluation Flywheel}
{Анализ → Измерение → Улучшение · Превратите промпт из демо в продукт}
🎯 Краткий гид: В Cookbook в качестве примера используется «AI-ассистент по аренде квартир». В нем наглядно показан полный рабочий процесс: от анализа ошибок и создания автоматического оценщика (grader) до интеграции в CI/CD. Упомянутые инструменты Evals API и Prompt Optimizer — это продвинутые возможности платформы OpenAI. Их можно использовать через API-ключ, предоставляемый сервисами-прокси API, такими как APIYI (apiyi.com). Разработчики могут смело брать этот процесс из Cookbook за основу и внедрять в свои проекты.
Кейс помощника по аренде квартир: реальное AI-приложение, которое «сломалось» на граничных сценариях
Кейс из кулинарной книги (cookbook) очень близок к жизни: AI-помощник, который отвечает на вопросы арендаторов — от размеров квартиры до записи на просмотр и описания инфраструктуры. На первый взгляд — обычный чат-бот для поддержки, но в продакшене он начал выдавать такие «фокусы», что диву даешься.
Примеры ошибок, приведенные в статье, очень показательны, и каждый из них вызывает чувство «жизы»:
| Тип ошибки | Как проявляется | Последствия |
|---|---|---|
| Ошибка планирования | Предложил время просмотра, которого нет | Арендатор зря съездил, шквал жалоб |
| Сбой состояния | Не отменил старую запись при переносе | Двойное бронирование, хаос в лидах |
| «Поехавшая» верстка | Список удобств превратился в «кашу» из текста | Плохой UX, информацию невозможно прочитать |
| Битые ссылки | Ссылка на планировку выдает 404 | Пользователь уходит к конкурентам |
| Дрейф данных | Время работы не совпадает с реальностью | Дезинформация, юридические риски |
Если вы хоть раз делали AI-приложение, то знаете: это не те вещи, которые вы намеренно игнорируете при написании промпта. Вы просто даже не подозреваете, что такое может случиться. Команда Fractional в кейсе с проверкой чеков (Receipt Inspection) отлично подытожила этот феномен: прогон пары «счастливых путей» (happy path) никогда не выявит баги «длинного хвоста» (long tail) в продакшене. Нужно выстраивать замкнутый цикл: «сбор ошибок → классификация паттернов → автоматическое измерение».
Этот цикл — и есть та самая суть, которую должен решать «маховик оценки» (evaluation flywheel).
Определение маховика оценки OpenAI: инженерная дисциплина вместо «промпт-и-молись»
В cookbook маховик оценки определяется лаконично: это процесс непрерывной итерации, заменяющий догадки структурированной инженерной дисциплиной. Он состоит из трех этапов и вращается, как настоящее колесо, делая систему надежнее с каждым оборотом.

Задачи этапов четко разделены:
| Этап | Основной вопрос | Что делаем | Результат |
|---|---|---|---|
| Analyze (Анализ) | «Почему это не работает?» | Разбор ошибок вручную, поиск паттернов | Список категорий ошибок + статистика |
| Measure (Измерение) | «Насколько все плохо?» | Создание grader'а, прогон на датасете | Метрики + baseline |
| Improve (Улучшение) | «Как исправить?» | Правка промпта, повторная оценка | Новая версия + сравнение метрик |
Многие команды пропускают этап анализа и сразу бросаются в автоматическую оценку — это самая частая причина провала маховика. Автоматические метрики без качественного анализа — это замок на песке, потому что вы банально не понимаете, что именно измеряете. Это ключевой инсайт данной статьи, который отличает её от обычных гайдов по оценке моделей.
💡 Аналогия: Маховик оценки похож на цикл PDCA, знакомый каждому продакт-менеджеру, но адаптированный под специфику промпт-инжиниринга. Analyze — «найти проблему», Measure — «оцифровать проблему», Improve — «решить проблему». Все три шага обязательны. Мы рекомендуем при запуске оценок через OpenAI Evals API на apiyi.com сначала качественно проработать этап анализа, и только потом переходить к измерениям.
Этап 1 цикла оценки OpenAI: двухшаговая разметка Analyze (Анализ)
Этап Analyze — самый недооцененный, но при этом критически важный элемент цикла оценки. В cookbook предлагается профессиональный подход: Open Coding (открытое кодирование) → Axial Coding (осевое кодирование). Этот метод пришел из качественных социологических исследований и за десятилетия доказал свою эффективность как один из лучших способов анализа неструктурированных текстовых данных.
Первый шаг, Open Coding (открытое кодирование), довольно прост: возьмите 50 неудачных примеров и, не пытаясь заранее их классифицировать, просто присвойте каждому из них описательный тег. Например:
- «Предложено несуществующее время для просмотра»
- «Список удобств — это просто куча текста»
- «Встреча перенесена, но старая не отменена»
- «Ответ содержит размеры не той квартиры»
- «Ссылка на планировку не открывается»
Важно: на этом этапе не нужно стремиться к идеальной структуре. Ваша задача — честно описать то, что вы видите. Open Coding похож на ведение конспектов: мыслите свободно, не загоняйте себя в рамки, ведь преждевременная классификация может лишить вас возможности заметить пограничные случаи.
Второй шаг, Axial Coding (осевое кодирование), — это переход к структурированию. Здесь вы объединяете разрозненные теги из первого шага в осмысленные категории высокого уровня. Пример классификации из cookbook:
- Проблемы с планированием просмотров (объединяет: неверное время, отмена, дублирование) → 35% всех ошибок
- Ошибки форматирования (объединяет: «поехавшая» верстка, нерабочие ссылки) → 10% всех ошибок
- Точность данных (объединяет: ошибки в часах работы, неверные размеры) → N% всех ошибок
Axial Coding похож на составление оглавления книги — он дает вам «карту местности» с ошибками. Цифра в 35% сразу подсказывает, что именно нужно исправлять в первую очередь, так как это даст максимальный ROI.
| Метод разметки | Цель | Настрой | Результат |
|---|---|---|---|
| Open Coding | Обнаружение (Discovery) | Свободный, без предвзятости | 50+ описательных тегов |
| Axial Coding | Структурирование (Structure) | Обобщение, создание категорий | 5-8 категорий ошибок высокого уровня |
🔧 Совет по практике: Разработчики могут выполнять этап Analyze, передавая логи через сервис-прокси API (например, APIYI), напрямую в интерфейс разметки датасетов платформы Evals, не тратя время на написание бэкенда. Используйте тип разметки Feedback для Open Coding и Label для Axial Coding — процесс будет полностью соответствовать рекомендациям cookbook.
Этап 2 цикла оценки OpenAI: выбор типа грейдера (Measure)
На этапе Analyze вы уже поняли, «как выглядят ошибки», а на этапе Measure вам нужно превратить эти знания в код для автоматической проверки. В cookbook дается руководство по выбору между двумя типами грейдеров — именно здесь инженеры чаще всего путаются.
| Тип грейдера | Сценарий использования | Преимущества | Недостатки |
|---|---|---|---|
| Python Grader | Детерминированные правила (строки, регулярки, проверка API) | Стабильный результат, отсутствие галлюцинаций, нулевые затраты | Не подходит для субъективных оценок |
| LLM Grader | Субъективные суждения (красота форматирования, семантика, качество рассуждений) | Гибкость, оценка сложных параметров | Требует калибровки экспертом (SME), есть затраты на токены |
На примере помощника по аренде квартир:
- «Входит ли предложенное время в доступные слоты?» → Python Grader (запрос к БД или API)
- «Красиво ли оформлен список удобств?» → LLM Grader (оценка от 0 до 10)
- «Открывается ли ссылка на планировку?» → Python Grader (HEAD-запрос)
- «Соответствует ли тон ответа бренду?» → LLM Grader (оценка по рубрикам)
В cookbook подчеркивается важнейшая инженерная практика: LLM Grader обязательно должен проходить калибровку экспертом (SME — Subject Matter Expert). Нельзя слепо доверять оценкам GPT-4o. Метод заключается в разделении данных на train/validation/test и проверке двух показателей:
- High TPR (True Positive Rate, доля истинно положительных): грейдер находит реальные ошибки.
- High TNR (True Negative Rate, доля истинно отрицательных): грейдер не помечает корректные ответы как ошибочные.
Если смотреть только на точность (accuracy), можно попасть в ловушку высокого базового уровня. Двойная проверка — это водораздел между подходом «вроде бы работает» и «действительно работает».
📊 Процесс калибровки: Эксперт размечает 100 примеров как ground truth → LLM Grader оценивает те же примеры → вычисляются TPR / TNR → промпт грейдера корректируется до достижения нужных показателей. Этот процесс нативно поддерживается на платформе Evals от APIYI, так как Evals API полностью совместим с официальным протоколом OpenAI.
Этап 3 «Маховика оценки» OpenAI: Двухпутевой эксперимент по улучшению (Improve)
На третьем этапе вы наконец-то можете приступить к непосредственному редактированию промпта. В руководстве (cookbook) предложены два параллельных пути улучшения. Это не выбор «или-или», а взаимодополняющие стратегии.
Путь 1: Автоматическая оптимизация (Prompt Optimizer)
Платформа OpenAI оснащена встроенным инструментом Prompt Optimizer. Вы предоставляете ему набор неудачных примеров и исходный промпт, а он автоматически пробует различные стратегии переписывания (добавление few-shot, цепочек рассуждений Chain-of-Thought, изменение порядка инструкций и т.д.) и оценивает результаты с помощью вашего грейдера (grader). Плюс этого пути — экономия времени, что отлично подходит для первичного исследования.
Путь 2: Ручная корректировка на основе паттернов сбоев
Опираясь на конкретные паттерны ошибок, выявленные на этапе анализа (Analyze), инженеры вручную вносят точечные правки в промпт. Например:
- Ошибки в планировании осмотров недвижимости → добавление в промпт обязательного шага «проверка доступности расписания».
- «Поехавшая» верстка → использование XML-тегов для четкого задания формата вывода.
- Неотмененные записи при изменении → добавление логики конечного автомата: «сначала отменить, затем записать заново».
Преимущество ручного пути — точность. Вы точно знаете, какая правка направлена на какой тип сбоя, и при отладке у вас есть полное понимание происходящего.
После прохождения обоих путей у вас будет N вариантов промпта. Теперь наступает самый важный шаг этапа улучшения: запуск всех вариантов на одном и том же наборе данных с использованием одного и того же грейдера для выбора лучшего по метрикам. Этот шаг нельзя пропускать, так как у людей есть сильная предвзятость «самодовольства» по отношению к своим правкам. Единственный способ объективно оценить результат — это цифры.
После тестирования всех версий цикл «маховика» завершается. Вы обнаружите новые паттерны сбоев (поскольку система стала лучше, она обнажает более глубокие граничные случаи), после чего вернетесь к этапу анализа для следующего витка. В этом и заключается суть «маховика» — он не останавливается, вращаясь все быстрее и становясь все устойчивее.
Фундаментальное различие между «устойчивым» (Resilient) и «хрупким» промптом
Термин resilient prompt (устойчивый промпт), вынесенный в заголовок, крайне важен. В руководстве он определяется так: промпт, который выдает качественный ответ на любые возможные входные данные. Звучит просто, но на практике это очень высокая инженерная планка.

Разница между устойчивостью и хрупкостью проявляется в пяти измерениях:
| Критерий сравнения | Хрупкий промпт | Устойчивый промпт |
|---|---|---|
| Устойчивость к вводу | Ломается от изменения слова | Стабилен при синонимичных правках |
| Граничные случаи | Странный вывод или галлюцинации | Плавная деградация или передача оператору |
| Наблюдаемость | «Черный ящик», ошибки — лишь догадки | Есть полный грейдер для локализации |
| Готовность к продакшену | Демо ≠ реальная работа | Проходит полный цикл оценки |
| Эволюционируемость | Правка А ломает Б | Автоматическая защита от регрессий |
Интуитивно инженеру кажется, что промпт «и так сойдет», но в продакшене вылезают ошибки с вероятностью 0,1%. Это кажется мелочью, но при миллионах вызовов — это 1000 инцидентов. Инженерная ценность устойчивого промпта не в том, чтобы поднять качество с 80% до 90%, а в том, чтобы довести его с 99% до 99,9%.
🚀 Совет по подключению: Чтобы довести промпт до 99,9% устойчивости, необходимо автоматизировать цикл оценки. Для этого требуется стабильный вызов OpenAI Evals API и инструмента Prompt Optimizer. Мы рекомендуем использовать платформы вроде apiyi.com для доступа к API OpenAI — интерфейсы полностью синхронизированы с официальными, а локальные узлы IDC гарантируют, что длительные задачи по оценке не прервутся.
Интеграция CI/CD и производственный мониторинг в цикле оценки OpenAI
В завершении своего руководства OpenAI подчеркивает финальный шаг: превращение цикла оценки в повседневную инженерную дисциплину. На практике это реализуется в двух направлениях:
Первое: Интеграция в CI/CD
Подключите набор инструментов для оценки (grader) к вашему CI-конвейеру, чтобы каждый раз при изменении промпта автоматически запускалось тестирование. Если показатели ухудшаются сверх установленного порога, слияние PR автоматически блокируется. Этот шаг превращает «оценку» из исследовательского процесса в рутинную разработку — это и есть настоящий признак того, что работа с промптами переходит в инженерную плоскость.
| Тип порога CI | Рекомендуемая настройка | Описание |
|---|---|---|
| Общая точность | Ухудшение ≤ 1% | Предотвращение общей регрессии |
| Ключевой grader | Ухудшение ≤ 0.5% | Строгий контроль критических сбоев |
| Выявление новых паттернов | Предупреждение (не блокировка) | Стимул для поиска новых проблем |
| Задержка P95 | Рост ≤ 10% | Контроль стоимости и пользовательского опыта |
Второе: Производственный мониторинг
Помимо CI, необходимо постоянно проводить выборку данных в производственной среде, чтобы обнаруживать «дикие» сценарии сбоев, которые не попали в набор CI. Эти новые паттерны затем возвращаются в набор для оценки, запуская следующий виток цикла.
На практике это выглядит так: вы берете выборку производственных логов (например, 1%), прогоняете их через тот же набор grader-ов и при обнаружении аномалий отправляете их на ручной анализ. Новые выявленные типы сбоев после обработки методами открытого (Open Coding) и осевого кодирования (Axial Coding) добавляются в тестовый набор, и цикл повторяется.
Этот процесс делает вашу систему промптов постоянно устойчивой, а не статичной после деплоя. Это ключевая инженерная дисциплина, которую OpenAI передает всем AI-инженерам.
5 практических советов для разработчиков от OpenAI
Изучив руководство, я выделил 5启示 (инсайтов), которые будут полезны для разработчиков:
Совет 1: Начинайте с анализа (Analyze), а не с измерения (Measure)
Многие команды сразу бросаются настраивать grader-ы и гнаться за метриками, пропуская этап ручного анализа. В итоге grader измеряет не реальные сценарии сбоев, и цифры выглядят красиво, а пользователи продолжают жаловаться. Не запускайте автоматическую оценку, пока не проведете ручное открытое кодирование (Open Coding) хотя бы 50 примеров.
Совет 2: Не доверяйте GPT этап Open Coding
Открытое кодирование должны делать люди, потому что GPT при классификации паттернов может привнести предвзятость из своих обучающих данных. Самый ранний момент для привлечения LLM — это этап после осевого кодирования (Axial Coding), когда вы пишете реализацию для grader. Этап «открытий» в анализе — прерогатива человека.
Совет 3: Python Grader лучше, чем LLM Grader
Если проблему можно покрыть детерминированными правилами, не используйте LLM Grader. Причины три: стабильность, дешевизна и отсутствие необходимости в согласовании с экспертами (SME). Оставьте LLM Grader для субъективных задач, которые невозможно описать правилами.
Совет 4: Привязывайте метрики к бизнес-результатам
35% проблем с планированием, 10% проблем с форматом — эти проценты имеют смысл для принятия решений только тогда, когда они конвертируются в «отток пользователей» или «уровень жалоб». Сами по себе метрики бессмысленны, важны только их бизнес-последствия.
Совет 5: Сделайте цикл автоматическим, а не разовым проектом
ROI от одного витка цикла может быть не самым высоким, но долгосрочный сложный процент очень значителен. Превратите grader в CI-задачу, настройте автоматическую выборку из продакшена по расписанию и автоматические оповещения о новых паттернах сбоев. Пусть цикл работает 24/7 без вашего участия.
Каркас Python-кода для реализации «маховика оценки» OpenAI в РФ
Хотя в cookbook в основном демонстрируются рабочие процессы через UI платформы OpenAI, программный вызов Evals API также отлично поддерживается. Ниже приведен каркас Python-кода, который показывает, как создать grader и запустить оценку через API. Это решение идеально подойдет отечественным разработчикам, предпочитающим код-ориентированные рабочие процессы:
from openai import AsyncOpenAI
client = AsyncOpenAI(
base_url="https://vip.apiyi.com/v1", # Переключаемся на шлюз APIYI
api_key="Ваш API-ключ APIYI"
)
# 1. Создание задачи оценки (определение набора grader)
eval_cfg = await client.evals.create(
name="leasing_assistant_v1",
data_source_config={
"type": "stored_completions",
"metadata": {"version": "v1"}
},
testing_criteria=[
{ # Пример Python Grader
"type": "string_check",
"name": "tour_time_valid",
"input": "{{sample.output}}",
"operation": "eq",
"reference": "{{item.expected_time}}"
},
{ # Пример LLM Grader
"type": "score_model",
"name": "format_quality",
"model": "gpt-4o",
"input": "{{sample.output}}",
"instructions": "Оцените ясность форматирования вывода по шкале от 0 до 10"
}
]
)
# 2. Запуск оценки (run)
run = await client.evals.runs.create(
eval_id=eval_cfg.id,
name="baseline_run",
data_source={"type": "completions"}
)
# 3. Получение результатов оценки
result = await client.evals.runs.retrieve(eval_id=eval_cfg.id, run_id=run.id)
print(f"Процент успешных ответов: {result.report_url}")
В этом коде есть три ключевых момента. Первый — это настройка base_url: именно эта строка определяет, сможете ли вы стабильно выполнять длительные задачи оценки из РФ. Второй — массив testing_criteria, куда можно вынести все конфигурации grader для выполнения за один проход. Третий — асинхронная природа Evals API: на больших наборах данных оценка может занимать от нескольких минут до десятков минут, поэтому в программе стоит предусмотреть логику ожидания и повторных попыток.
FAQ по «маховику оценки» OpenAI
Q1: Есть ли разница между «маховиком оценки» и платформами вроде LangSmith / Weights&Biases?
Разница в позиционировании. LangSmith в основном решает задачу «инструментализации оценки», а «маховик оценки» — это методология. Первое говорит вам, как реализовать, второе — как мыслить. Их можно использовать вместе: инструменты служат для воплощения методологии.
Q2: Достаточно ли 50 неудачных примеров, не слишком ли это мало?
Для этапа открытого кодирования (Open Coding) 50 примеров вполне достаточно, так как цель — выявить закономерности, а не получить исчерпывающую статистику. Количество примеров для этапа измерения (Measure) зависит от уровня ошибок: если он составляет 5%, потребуется 1000 записей для стабильного доверительного интервала; если 30% — хватит и 200.
Q3: Может ли автоматическая оптимизация промптов (Prompt Optimizer) полностью заменить ручную правку?
Нет. Автоматические инструменты хороши для локальной оптимизации при известных grader, но они плохо понимают бизнес-ограничения (например, негласное правило «ответ клиента не должен превышать 80 знаков»). Лучшая практика — сочетание ручной правки и автоматической оптимизации.
Q4: Стабильно ли работает вызов Evals API из РФ?
При прямом подключении к OpenAI длительные задачи (оценка обычно занимает от нескольких минут до нескольких часов) часто сталкиваются с разрывом соединения. Мы рекомендуем использовать шлюзы вроде apiyi.com: отечественные IDC-узлы специально оптимизированы для работы с длинными соединениями, что значительно снижает вероятность прерывания задач.
Q5: Для команд какого размера подходит «маховик оценки»?
Он подходит всем — от проектов из одного человека до команд из 100 сотрудников. Разница лишь в частоте вращения маховика. Проект одного разработчика может делать один цикл за две недели, а большая команда — ежедневно или даже ежечасно. Главное — дисциплина, а не масштаб.
Q6: Кто такой Хамель Хусейн (Hamel Husain) и почему этот cookbook вызывает такой интерес?
Хамель — очень влиятельный эксперт в сообществе машинного обучения, который долгое время продвигает лучшие инженерные практики для приложений на базе LLM. Этот cookbook — первая официальная попытка OpenAI систематически внедрить методологию качественных исследований (например, Open Coding) в промпт-инжиниринг, поэтому в индустрии его обсуждают так активно.
Итоги
Методология «Маховик оценки OpenAI» по-настоящему ценна тем, что она дает китайскому сообществу AI-инженеров четкий ответ на вопрос: «Что значит профессиональный промпт-инжиниринг?». Это не просто конкретный инструмент, а инженерная дисциплина, которая превращает разработку промптов из «ремесла, основанного на интуиции» в «структурированную инженерную практику».
Внедрение трех этапов — Analyze (Анализ), Measure (Измерение) и Improve (Улучшение) — в ваш процесс разработки превращает AI-приложение из «демо-версии, которая выглядит неплохо» в продукт, который можно смело запускать в продакшн и подкреплять SLA. За этим переходом стоит полноценный цикл, где ошибки систематически собираются, паттерны структурируются, а улучшения проверяются автоматизированными метриками.
Если вы работаете над любым AI-приложением, основанном на промптах, настоятельно рекомендуем запустить этот «маховик». Мы советуем использовать платформы для прокси-доступа к API, такие как apiyi.com, для вызова Evals API и Prompt Optimizer. Достаточно просто изменить base_url, чтобы запустить весь процесс из cookbook, не беспокоясь о стабильности сетевого соединения в Китае.
Сделайте этот «маховик» частью своей профессиональной привычки, и с сегодняшнего дня ваши промпты станут по-настоящему надежными.
📌 Автор: Команда APIYI — мы постоянно отслеживаем инженерные практики использования мультимодальных API от OpenAI, Anthropic и Google. Больше практических руководств и инструкций по подключению Evals API вы найдете в центре документации на apiyi.com.