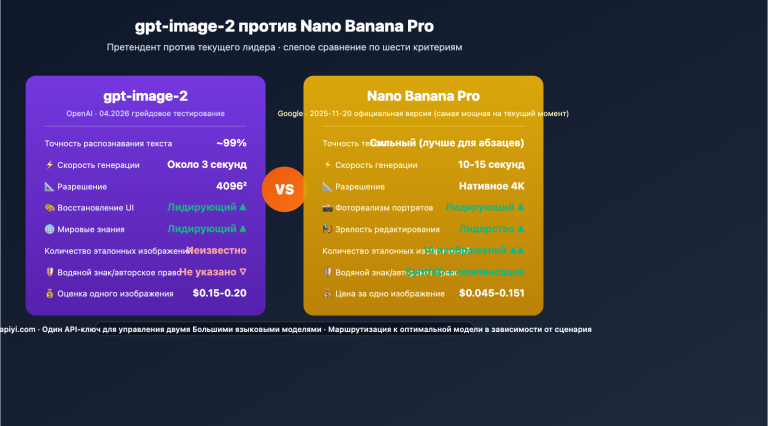
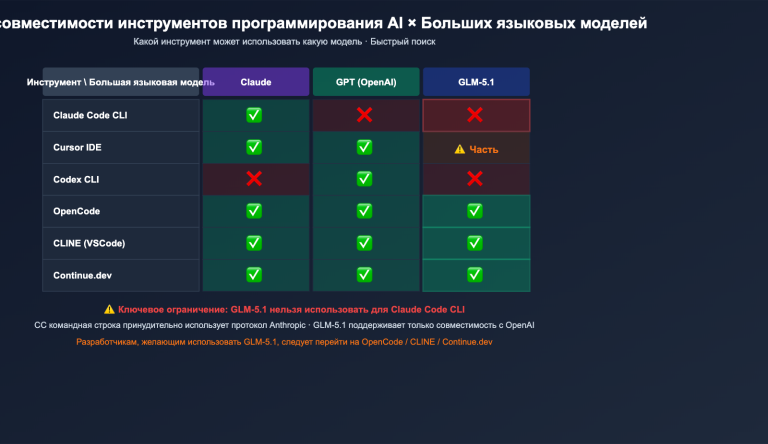
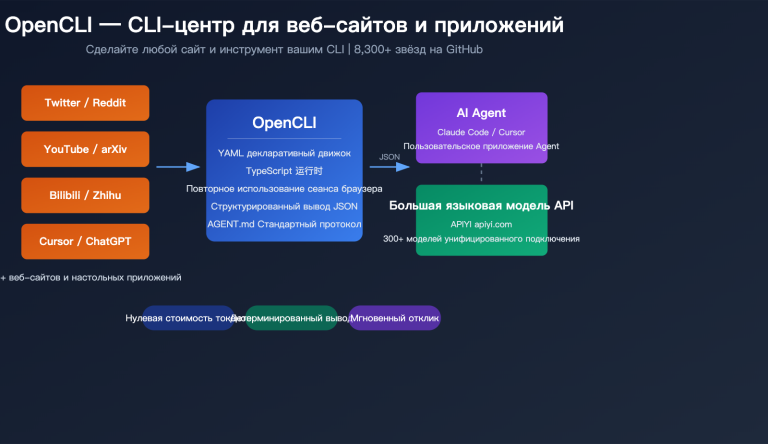
В 2026 году рынок больших языковых моделей для программирования разделился на два совершенно разных лагеря. Первый — это «IDE-ориентированные, высокочастотные автодополнители», ярким представителем которых является Mistral Codestral 2 (текущая версия Codestral 25.08). Они заточены под Fill-in-the-Middle (FIM), высокую точность автодополнения и мгновенный отклик для более чем 80 языков программирования. Второй лагерь — это «долгосрочные агенты», такие как Zhipu GLM-5.1. Благодаря архитектуре MoE с 744 млрд параметров и контекстному окну в 200 тыс. токенов, они нацелены на выполнение сложных инженерных задач уровня SWE-Bench Pro, способных занимать до 8 часов автономной работы.
Эти два направления практически не пересекаются по целевой аудитории и стратегиям тарификации, но их часто сравнивают в спорах о том, «что лучше подходит для написания кода». Основываясь на официальных данных Mistral AI (Codestral 25.08 от 30.07.2025) и документации для разработчиков Z.ai (GLM-5.1, релиз 27.03.2026), а также других англоязычных первоисточниках, мы подготовили удобную таблицу для принятия решений. Мы проанализировали модели по 6 параметрам: архитектура, бенчмарки, контекст, долгосрочные задачи, развертывание и цена. Также прилагаем примеры кода для вызова API обеих моделей, чтобы вы могли сделать выбор за 10 минут.

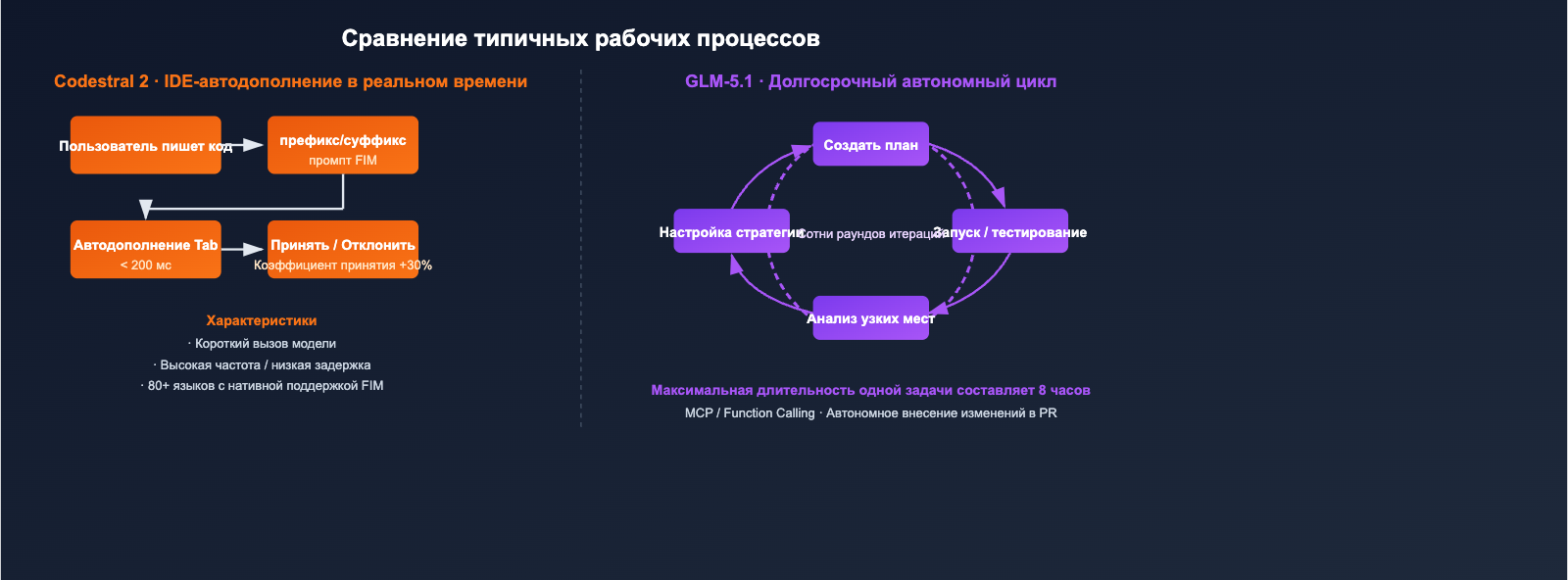
Разница в позиционировании Codestral 2 и GLM-5.1
Прежде чем переходить к тестам, важно уяснить: эти модели относятся к разным классам продуктов. Сравнивать их «в лоб» — занятие неблагодарное, которое приведет к неверным выводам.
Краткое позиционирование
- Codestral 2 (25.08): специализированная модель для автодополнения и редактирования кода. Плотная архитектура на 22 млрд параметров, нативная поддержка FIM, упор на «мгновенный отклик + высокую долю принятия кода». Де-факто стандарт для инструментов типа IDE Copilot.
- GLM-5.1: флагманская универсальная модель для агентских задач и долгосрочного программирования. 744 млрд параметров (MoE, активация ~40 млрд на токен), контекстное окно 200 тыс. токенов. В бенчмарке SWE-Bench Pro набрала 58.4 балла, обойдя GPT-5.4, Claude Opus 4.6 и Gemini 3.1 Pro.
Три вопроса перед выбором
| Вопрос | В пользу Codestral 2 | В пользу GLM-5.1 |
|---|---|---|
| Основная задача: автодополнение в IDE или создание PR? | Автодополнение | Автономные задачи |
| Объем токенов в запросе: десятки или десятки тысяч? | Десятки — тысячи | Тысячи — десятки тысяч |
| Допустима ли задержка в десятки секунд? | Нет | Да |
🎯 Совет по выбору: если 80% ваших вызовов — это «автодополнение следующей строки кода», выбирайте Codestral 2. Если 80% задач — это «исправь баг в этом репозитории», ваш выбор — GLM-5.1. Обе модели можно протестировать параллельно через единый интерфейс APIYI (apiyi.com), не подключаясь к Mistral и Z.ai по отдельности.
Сравнение архитектуры и параметров Codestral 2 и GLM-5.1
Различия в архитектуре — это фундамент, на котором строится вся дальнейшая производительность моделей.
Краткий обзор ключевых характеристик
| Параметр | Codestral 2 (25.08) | GLM-5.1 |
|---|---|---|
| Разработчик | Mistral AI | Zhipu AI (Z.ai) |
| Архитектура | Dense Transformer | Mixture-of-Experts (MoE) |
| Общее число параметров | 22B | 744B |
| Активные параметры | 22B | ~40B (256 экспертов, 8 активных на токен) |
| Контекстное окно | 256K | 200K |
| Макс. вывод | Стандарт | 128K токенов |
| Механизм внимания | Стандарт + FIM-оптимизация | DeepSeek Sparse Attention |
| Лицензия | Коммерческая Mistral / MNPL | MIT (открытые веса) |
| Дата релиза | 30.07.2025 (последняя итерация) | 27.03.2026 |
| Поддержка языков программирования | 80+ основных языков | Универсальная мультиязычность |

Прямые последствия архитектурных различий
- Видеопамять и стоимость развертывания: Codestral 2 с 22B параметров можно запустить на одной машине (A100 80G); GLM-5.1 требует параллелизма на нескольких GPU или использования облачных сервисов для инференса.
- Задержка на токен: Dense-архитектура Codestral 2 обеспечивает более стабильную задержку при коротких запросах; GLM-5.1 из-за работы маршрутизатора и разреженного внимания (sparse attention) может чуть дольше генерировать первый токен, но выигрывает на длинных последовательностях.
- Стратегия открытости: GLM-5.1 распространяется с весами по лицензии MIT, что гораздо удобнее для приватного развертывания и дообучения; Codestral 2 можно запустить локально, но для коммерческого использования требуется лицензия.
🎯 Рекомендация по развертыванию: Командам, которым нужна полная приватность, стоит отдать предпочтение GLM-5.1 с лицензией MIT. Если же вы хотите быстро интегрировать модели без головной боли с хостингом, используйте APIYI (apiyi.com) — через этот сервис-прокси API можно легко вызывать обе модели, не тратя время на закупку оборудования и согласование лицензий.
Сравнительный анализ базового кода: Codestral 2 против GLM-5.1
Результаты тестирования обеих моделей предоставлены производителями, при этом наборы тестов не полностью совпадают. Ниже приведены только те показатели, которые имеют смысл для прямого сравнения.
Сильные стороны Codestral 2: качество автодополнения и метрики IDE
| Показатель | Значение | Описание |
|---|---|---|
| Accepted Completions (принятые дополнения) | +30% (относительно 25.01) | Уровень использования в IDE в продакшене |
| Retained Code (сохраненный код) | +10% | Доля предложенного кода, который не был удален при коммите |
| Runaway Generations (избыточная генерация) | -50% | Снижение объема бесполезного "дописывания" |
| IFEval v8 (следование инструкциям) | +5% | Точность выполнения инструкций |
| Средний балл MultiPL-E | +5% | Возможности написания кода на разных языках |
| HumanEval (данные пред. версии 25.01) | 86.6% | Справочные данные |
| MBPP (данные пред. версии 25.01) | 91.2% | Справочные данные |
Сильные стороны GLM-5.1: сложные инженерные задачи
| Показатель | Значение | Описание |
|---|---|---|
| SWE-Bench Pro | 58.4 | Выше GPT-5.4 / Claude Opus 4.6 / Gemini 3.1 Pro |
| Сравнение с Claude Code | 45.3 (Opus 4.6 — 47.9) | Достигает 94.6% от уровня Opus 4.6 |
| vs GLM-5 (базовая линия) | +28% | Результат пост-тренировочной оптимизации |
| KernelBench Level 3 | Ускорение в 3.6x | Сценарии оптимизации ML-ядер |
| Длительность одной задачи | До 8 часов | Автономный цикл "эксперимент-анализ-оптимизация" |
Оценка пересечения возможностей
| Возможность | Codestral 2 | GLM-5.1 |
|---|---|---|
| Дополнение одного файла | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| Рефакторинг нескольких файлов | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| Поиск багов + исправление PR | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Кросс-языковой перевод | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Агенты / Использование инструментов | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Задержка первого токена | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
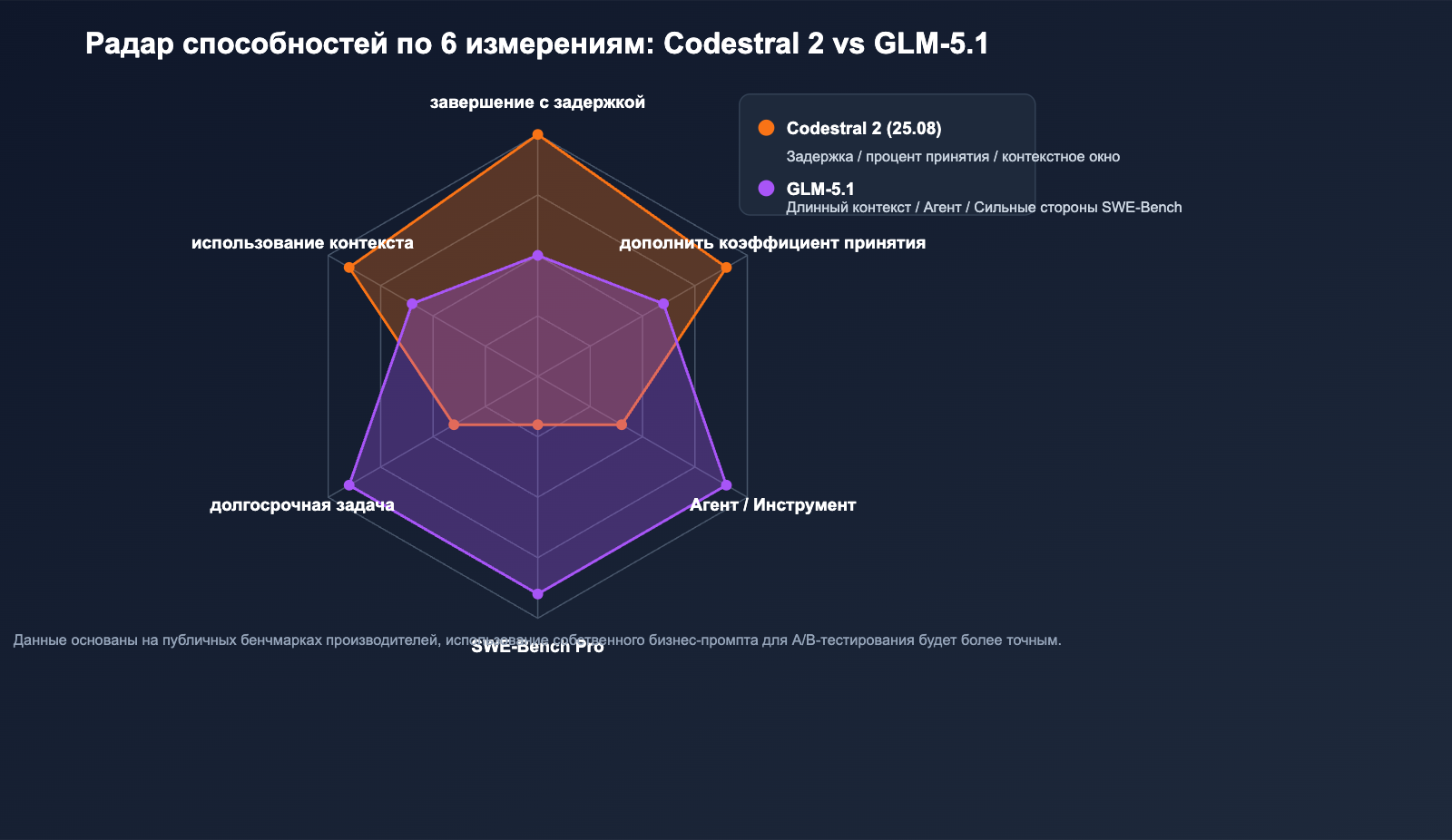
🎯 Совет по интерпретации результатов: Официальные данные обычно получены в идеальных условиях тестирования, реальная производительность может варьироваться на 10–20%. Рекомендуем провести A/B-тестирование на собственной кодовой базе через APIYI (apiyi.com), прежде чем принимать окончательное решение.
Контекстное окно и возможности долгосрочных задач в Codestral 2 и GLM-5.1
Контекстные окна 256K и 200K близки по цифрам, но предназначены для совершенно разных типов задач.
Контекстное окно 256K в Codestral 2: дополнение всего репозитория
Codestral 2 использует 256K контекста в основном для того, чтобы "запихнуть весь репозиторий в промпт", обеспечивая понимание зависимостей между файлами при автодополнении:
- Подходит для: дополнения крупных функций внутри монорепозитория, исправления линтеров во всем проекте, переименования модулей.
- Не подходит для: агентских процессов, требующих многошаговых рассуждений, вызова инструментов и записи результатов.
Контекстное окно 200K + 8-часовой автономный цикл в GLM-5.1
Прорыв GLM-5.1 заключается не в размере контекста, а в способности к длительной работе:
- В официальных демонстрациях модель может выполнять сотни итераций в рамках одной задачи: запуск бенчмарка → поиск узких мест → корректировка стратегии → повторный запуск.
- Технология DeepSeek Sparse Attention позволяет удерживать стоимость вывода для длинных последовательностей в разумных пределах.
- В сочетании с Function Calling / MCP модель может напрямую взаимодействовать с внешними инструментами.
Сравнение типичных долгосрочных задач
| Задача | Codestral 2 | GLM-5.1 |
|---|---|---|
| Дополнение функции на 200 строк | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| Создание PR на основе GitHub Issue | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Поиск и исправление бага во всем репо | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Многоэтапная автооптимизация ML-ядра | ⭐ | ⭐⭐⭐⭐⭐ |
| Автодополнение по Tab в IDE | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
🎯 Рекомендация по переходу: Если ваша команда использовала Codestral для дополнения кода, но сталкивается с тем, что "код дополнен, но тесты не проходят", попробуйте доверить GLM-5.1 цикл "генерация-запуск-исправление". Вы можете легко переключиться, просто изменив
base_urlна APIYI (apiyi.com), сохранив совместимость с API OpenAI.
Быстрый старт: сравнение интеграции API для Codestral 2 и GLM-5.1
Обе модели предоставляют интерфейс, совместимый с OpenAI, а основные различия заключаются лишь в названии модели и параметрах. В примерах ниже используется единый base_url от APIYI (apiyi.com) для демонстрации минимально необходимого кода.
Вызов Codestral 2 (автодополнение кода)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
resp = client.chat.completions.create(
model="codestral-latest", # Указывает на Codestral 25.08
messages=[
{"role": "system", "content": "You are a senior Python engineer."},
{"role": "user", "content": "Реализуй высокопроизводительный LRU-кэш."},
],
temperature=0.2,
max_tokens=512,
)
print(resp.choices[0].message.content)
Вызов GLM-5.1 (задачи с длинным контекстом)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
resp = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role": "system", "content": "You are a SWE agent. Analyze repo, run tests, iterate."},
{"role": "user", "content": "Исправь все упавшие тесты в tests/test_api.py в репозитории."},
],
temperature=0.3,
max_tokens=8192,
# GLM-5.1 поддерживает Function Calling + структурированный вывод
)
print(resp.choices[0].message.content)
📎 Развернуть для просмотра вызова FIM (только для Codestral 2)
# Нативный FIM для Codestral формируется через объединение prefix / suffix в промпте
prefix = "def binary_search(arr, target):\n "
suffix = "\n return -1"
prompt = f"[PREFIX]{prefix}[SUFFIX]{suffix}[MIDDLE]"
# Отправьте этот промпт как содержимое user для codestral-latest, чтобы получить точное дополнение
🎯 Совет по интеграции: Обе модели следуют схеме OpenAI, поэтому вы можете использовать один и тот же код, просто переключая название модели. Централизованный вызов через APIYI (apiyi.com) избавляет от необходимости отдельно поддерживать аккаунты в Mistral Console и Z.ai, следить за балансом и настраивать лимиты для каждого сервиса.
Сравнение цен и стратегии развертывания Codestral 2 и GLM-5.1
Цена и гибкость развертывания — это зачастую решающие факторы при выборе.
Справочные цены
| Модель | Цена за вход | Цена за выход | Примечание |
|---|---|---|---|
| Codestral 2 (25.08) | $0.20 / 1M | $0.60 / 1M | Тарифы серии Codestral |
| GLM-5.1 | от ~$3 (тариф Coding Plan) | По тарифу | Доступна оплата за токены |
Примечание: цены основаны на открытых данных с официальных сайтов и каналов, фактические курсы и акции уточняйте на момент использования.
Сравнение вариантов развертывания
| Способ развертывания | Codestral 2 | GLM-5.1 |
|---|---|---|
| Официальный Cloud API | ✅ Mistral Console | ✅ Платформа Z.ai |
| Сторонний прокси-шлюз | ✅ (APIYI apiyi.com и др.) | ✅ (APIYI apiyi.com и др.) |
| VPC / Частное облако | ✅ По лицензии | ✅ Свободное развертывание (MIT) |
| Локальный запуск | ✅ Ограничен (A100/GPU) | ❌ Требует несколько GPU |
| Function Calling | Поддерживается (через chat completions) | ✅ Нативная поддержка + MCP |
🎯 Совет по оптимизации затрат: Для сценариев IDE с частыми запросами и небольшим количеством токенов лучше использовать Codestral 2 с кэшированием. Для задач типа Agent, где запросы редкие, но объем токенов большой, выгоднее пакетные тарифы GLM-5.1. Вы можете настроить обе стратегии в APIYI (apiyi.com), распределяя лимиты по моделям, чтобы бюджет основного аккаунта не был исчерпан одной моделью.
Руководство по выбору и советы по использованию Codestral 2 и GLM-5.1
Четыре типичных сценария принятия решений
| Сценарий | Рекомендуемая модель | Ключевая причина |
|---|---|---|
| Плагины автодополнения для VSCode / JetBrains | Codestral 2 | Нативная поддержка FIM + низкая задержка |
| Автоматическое исправление багов / PR-боты | GLM-5.1 | Длинные циклы автономной работы |
| Ассистент для код-ревью (комментарии к файлам) | Codestral 2 | Быстрый отклик, низкая стоимость |
| Сквозные агенты (тестирование/деплой) | GLM-5.1 | MCP + Function Calling |
| Генерация каркаса проекта (boilerplate) | Обе модели | Любая из них справится |
| Оптимизация производительности ML-ядер | GLM-5.1 | Ускорение KernelBench в 3.6 раза |
Список типичных ошибок (как их избежать)
- ❌ Не используйте Codestral 2 для работы агентов: несмотря на снижение частоты неконтролируемой генерации на 50%, модель не оптимизирована для многошагового принятия решений.
- ❌ Не используйте GLM-5.1 для автодополнения с миллисекундной задержкой: задержка первого токена негативно сказывается на отклике при нажатии клавиши Tab в IDE.
- ❌ Не ориентируйтесь только на один рейтинг: GLM-5.1 лидирует в SWE-Bench Pro, но серия Codestral ничуть не уступает в HumanEval.
- ✅ Проведите A/B-тестирование на малых выборках: возьмите 100 типичных промптов из вашей рабочей задачи и сравните результаты, переключая параметры модели через APIYI (apiyi.com).
Часто задаваемые вопросы (FAQ)
Q1: Почему на официальной странице модель называется Codestral 25.08, а не Codestral 2?
У Mistral принята схема именования <серия>-<год>.<месяц>. Codestral 25.08 относится ко второму поколению Codestral (первое вышло в 24.05, второе эволюционировало с 25.01 по 25.08). В индустрии и сообществе принято называть версии 25.01+ общим термином «Codestral 2». При вызове просто укажите codestral-latest, чтобы получить доступ к актуальной версии второго поколения.
Q2: Не будет ли GLM-5.1 с 744 млрд параметров работать слишком медленно?
Благодаря архитектуре MoE на каждый токен активируется всего 40 млрд параметров, а в сочетании с DeepSeek Sparse Attention реальная скорость вывода приближается к плотным моделям уровня 40B. При использовании стратегий длинных соединений и кэширования через APIYI (apiyi.com) задержка в сценариях с большим контекстом остается в приемлемых пределах.
Q3: Какая из моделей лучше справляется с контекстным окном?
256K у Codestral 2 — это скорее «объем», тогда как 200K у GLM-5.1 в сочетании с разреженным вниманием (sparse attention) более дружелюбны к «реальному коэффициенту использования». Перед выполнением задач по всей кодовой базе рекомендуется оценить количество токенов с помощью tiktoken или официального токенизатора, чтобы избежать бесполезной обрезки контекста.
Q4: Что открытые веса значат для бизнеса?
GLM-5.1 распространяется под лицензией MIT, что позволяет развертывать её во внутренней сети и дообучать. Коммерческое использование Codestral 2 требует лицензионного соглашения. Для финансовых и государственных организаций с жесткими требованиями к комплаенсу это критическая разница. Если же вам просто нужно обойти региональные ограничения, APIYI (apiyi.com) также предоставляет стабильный доступ из Китая.
Q5: Можно ли использовать обе модели одновременно?
Можно, и это даже рекомендуется. Типичный подход: автодополнение в IDE на Codestral 2, а фоновые агенты — на GLM-5.1. Они используют разные ключи модели, а биллинг централизованно проходит через APIYI (apiyi.com).
Q6: Насколько можно доверять бенчмаркам от самих разработчиков?
Результаты тестов Codestral и GLM являются самоотчетами, а показатель 58.4 в SWE-Bench Pro от Z.ai еще не получил независимого подтверждения. Рекомендуем воспринимать публичные рейтинги как «верхнюю границу возможностей» и обязательно проводить регрессионное тестирование на ваших бизнес-сценариях перед внедрением.
Итоги: рекомендации по выбору между Codestral 2 и GLM-5.1
Вернемся к трем вопросам, поставленным в начале:
- Если ваш продукт — это Copilot, автодополнение кода или генерация фрагментов кода, выбирайте Codestral 2. Его показатели FIM (Fill-In-the-Middle), задержка, цена и поддержка более 80 языков программирования делают его оптимальным выбором для таких задач.
- Если ваш продукт — это PR-бот, агент для исправления багов или фоновый агент, выполняющий задачи в течение 8 часов, выбирайте GLM-5.1. Модель 744B MoE с показателем 58.4 в SWE-Bench Pro и возможностью длительных автономных циклов — это на текущий момент ближайший аналог Claude Opus 4.6 в open-source сегменте.
- Если ваш продукт включает оба сценария, то использование обеих моделей в связке станет самым экономичным решением в 2026 году.
🎯 Совет по внедрению: переходите от стратегии «выбор одного из двух» к «оркестрации двух моделей». Благодаря совместимости APIYI (apiyi.com) с форматом OpenAI, вам достаточно добавить в бизнес-логику поле для разделения задач на «короткое дополнение» и «длительная задача». Это позволит автоматически маршрутизировать запросы между Codestral 2 и GLM-5.1, направляя каждый из них на ту модель, которая лучше всего подходит для конкретной цели.
— Команда APIYI (техническая команда APIYI apiyi.com)