Вы используете OpenClaw для своих рабочих процессов, но каждый раз, видя счет за API в конце месяца, у вас становится не по себе — $300, $500 или даже больше $600?
Дело не в вас, а в самой архитектуре OpenClaw. Неоптимизированный экземпляр OpenClaw при выполнении каждой задачи отправляет ИИ-модели огромное количество «лишнего контента», впустую сжигая токены.
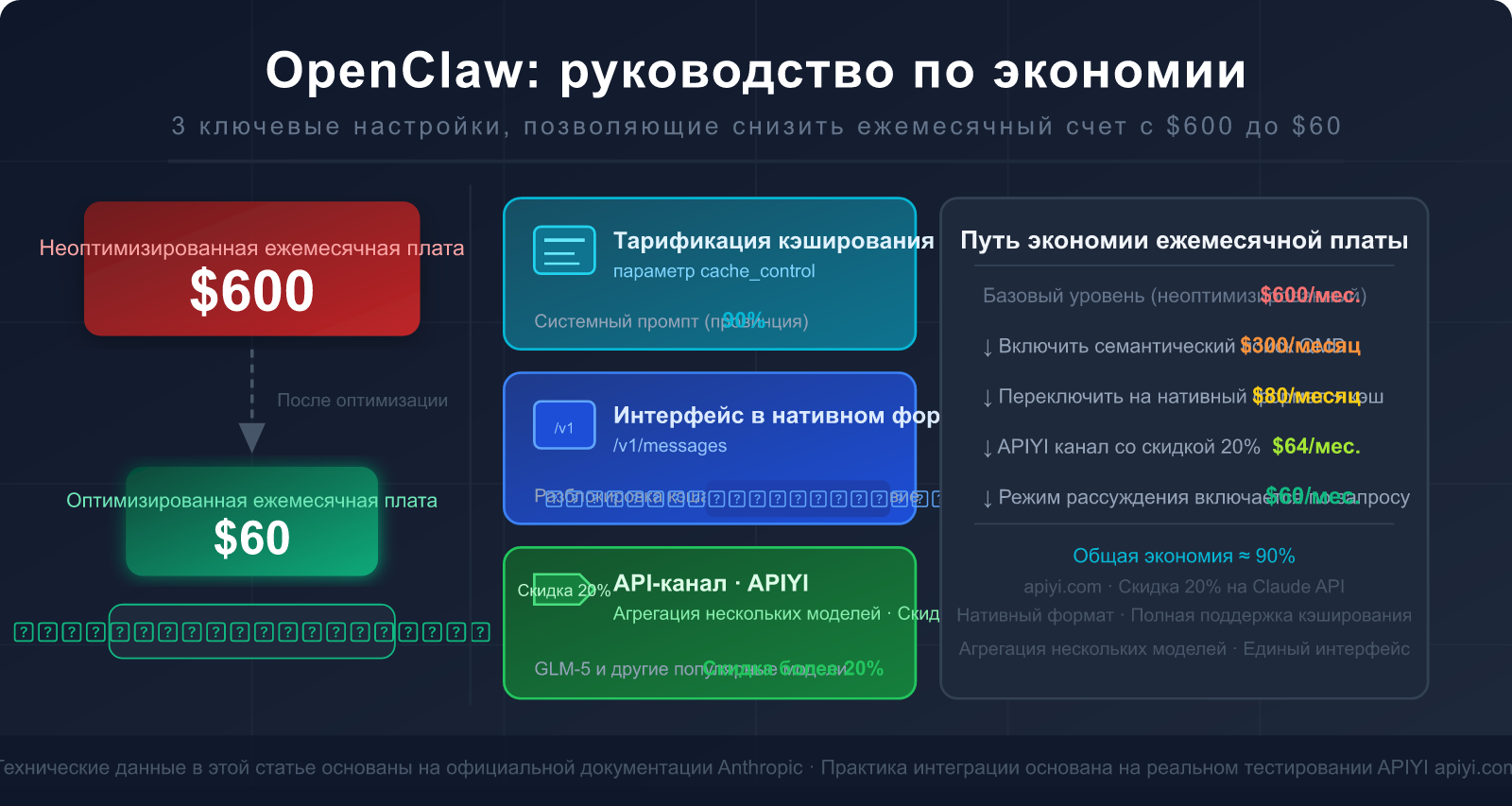
Хорошая новость: всего несколько ключевых настроек могут снизить ваш счет на 80–90%, и большинство пользователей даже не подозревают о самом эффективном приеме — использовании нативного формата интерфейса Claude вместо режима совместимости с OpenAI.
В этой статье мы подробно разберем коренную причину высокого потребления токенов в OpenClaw и пошагово научим вас правильно настраивать интерфейсы, конфигурацию кэширования и выбирать верные API-каналы, чтобы превратить ежемесячный счет из $600 в $60.
I. Почему OpenClaw потребляет так много токенов: 3 основные причины
Причина 1: Повторная отправка всей истории диалога при каждом запросе
Это самая неочевидная, но самая весомая причина.
OpenClaw спроектирован по принципу «полного контекста»: при каждом запросе к ИИ-модели отправляется вся история сообщений с самого начала диалога. Это необходимо, чтобы модель «помнила», что было сделано и сказано ранее.
Пример:
Раунд 1: Пользователь отправил 50 токенов, Ответ ИИ 200 токенов → Отправлено в этот раз 250 токенов
Раунд 2: Пользователь отправил 50 токенов, Ответ ИИ 200 токенов → Отправлено в этот раз 500 токенов (включая раунд 1)
Раунд 3: Пользователь отправил 50 токенов, Ответ ИИ 200 токенов → Отправлено в этот раз 750 токенов (включая раунды 1+2)
...
Раунд 10: Фактически добавилось всего 250 токенов, но объем отправки уже составляет 2 500 токенов
В рабочих процессах OpenClaw, решающих сложные задачи, этот «эффект снежного кома» заставляет потребление токенов расти в геометрической прогрессии. История контекста обычно составляет 40–50% от общего расхода токенов.
Причина 2: Системный промпт отправляется заново при каждом вызове
Системный промпт (System Prompt) в OpenClaw определяет роль агента, границы его возможностей, список доступных инструментов и правила поведения. Обычно его объем составляет от 5 000 до 10 000 токенов.
Критическая проблема: этот огромный системный промпт полностью пересылается при каждом вызове API.
Предположим, вы используете OpenClaw для выполнения 50 задач в день, и объем системного промпта составляет 8 000 токенов:
Ежедневный расход на системный промпт = 50 × 8 000 = 400 000 токенов
Ежемесячный расход ≈ 12 000 000 токенов (только на системный промпт!)
При цене на входные токены Claude Sonnet 4.6 ($3 за миллион токенов), только системный промпт обойдется вам в $36 в месяц. И это без учета самого диалога и ответов модели.
Причина 3: Режим рассуждения увеличивает расход токенов в 10–50 раз
Когда OpenClaw сталкивается со сложной задачей, он включает «цепочку рассуждений» или «режим рассуждения» (Thinking/Reasoning). В этом режиме ИИ сначала «думает», а потом отвечает, что повышает качество результата, но ценой резкого скачка потребления токенов.
Особенности расхода токенов в режиме рассуждения:
- Процесс мышления генерирует огромное количество промежуточных токенов (они часто невидимы, но тарифицируются).
- Рассуждения для сложной задачи могут занять от 10 000 до 50 000 токенов.
- Если это не контролировать, всего несколько сложных задач могут «съесть» весь дневной бюджет.
| Сценарий расхода токенов | Обычный режим | Режим рассуждения | Разница (в разы) |
|---|---|---|---|
| Простые вопросы и ответы | ~500 токенов | ~2 000 токенов | 4 раза |
| Обработка электронной почты | ~2 000 токенов | ~15 000 токенов | 7,5 раз |
| Анализ кода | ~5 000 токенов | ~80 000 токенов | 16 раз |
| Сложные многоэтапные исследования | ~10 000 токенов | ~200 000 токенов | 20+ раз |
🎯 Быстрая диагностика: Если счета за OpenClaw аномально высоки, первым делом проверьте логи токенов на предмет использования режима рассуждения.
Отключение этого режима для простых задач — один из самых быстрых способов сэкономить.
Переход на более подходящую модель также может значительно снизить затраты — через сервис-прокси API APIYI (apiyi.com) можно быстро переключаться между моделями для тестирования.
Распределение расхода по трем основным причинам
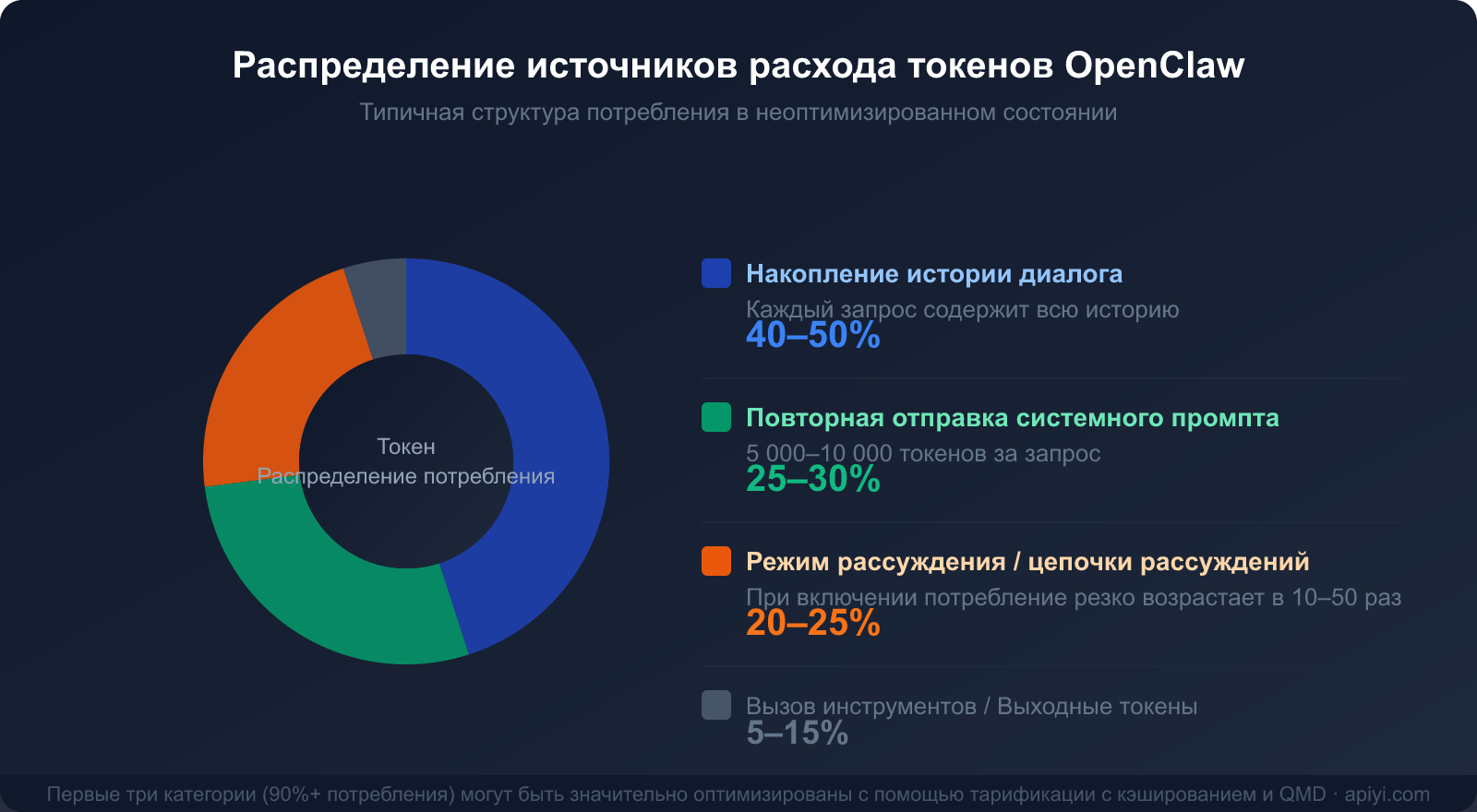
Понимание этих трех источников расхода — первый шаг к разработке стратегии экономии:
| Источник расхода | Доля в общем расходе | Можно ли оптимизировать | Основные способы оптимизации |
|---|---|---|---|
| История диалога (накопление контекста) | 40–50% | ✅ Высокая степень | Кэширование, регулярная очистка, QMD |
| Повторная отправка системного промпта | 25–30% | ✅ Высокая степень | Кэширование (экономия до 90%) |
| Режим рассуждения / Thinking | 20–25% | ✅ По необходимости | Включать только для сложных задач |
| Вызовы инструментов и вывод | 5–15% | ⚡ Ограниченно | Сокращение описаний инструментов |
2. Самый недооцененный инструмент для экономии: кэширование в Claude
Что такое кэширование в Claude
Prompt Caching (кэширование промптов) — это нативная функция, представленная Anthropic в конце 2024 года. Ее основная логика проста: часто повторяющийся контент кэшируется на стороне сервера, и при последующих вызовах модель считывает его напрямую из кэша, а не обрабатывает заново.
Цена чтения из кэша: всего 10% от обычной стоимости входных токенов (экономия 90%).
Это означает, что если вы каждый раз отправляете системный промпт (System Prompt) объемом 8 000 токенов, то при включенном кэшировании и попадании в него вы платите только за 800 токенов. Для пользователей OpenClaw, отправляющих десятки запросов в день, эта оптимизация может сэкономить сотни долларов в месяц.
Полная система тарификации кэша
| Тип кэша | Множитель стоимости | Срок действия (TTL) | Сценарий использования |
|---|---|---|---|
| Обычный входной токен | 1× базовая цена | Не кэшируется | Обработка каждый раз заново |
| Запись в кэш (первая) | 1.25× | 5 минут | Создание кэша |
| Запись в кэш (длительная) | 2× | 1 час | Сценарии с частыми вызовами |
| Чтение из кэша (попадание) | 0.1× (экономия 90%) | В течение срока действия | Повторные запросы |
Пример расчета реальной экономии:
Сценарий: Системный промпт OpenClaw на 8 000 токенов.
50 вызовов в день, из которых 48 попадают в кэш.
Без кэширования: 50 × 8 000 = 400 000 токенов
Стоимость = 400 000 × $3/1M = $1.20 в день = $36 в месяц
С кэшированием: 2 записи: 2 × 8 000 × 1.25 = 20 000 токенов = $0.06
48 попаданий: 48 × 8 000 × 0.1 = 38 400 токенов = $0.12
Итого в день ≈ $0.18 → в месяц ≈ $5.40
Экономия: $36 - $5.40 = $30.60 в месяц (только на системном промпте)
Процент экономии: 85%
Как включить кэширование в OpenClaw
Для включения кэширования есть необходимое условие: вы должны использовать нативный формат интерфейса Anthropic (/v1/messages), а не режим совместимости с OpenAI (/v1/chat/completions).
Правильный способ настройки (пример на Python SDK):
import anthropic
# Нужно использовать нативный SDK Anthropic, а не OpenAI SDK
client = anthropic.Anthropic(
api_key="ваш-api-ключ",
base_url="https://api.apiyi.com/v1" # APIYI поддерживает нативный формат Anthropic
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
system=[
{
"type": "text",
"text": "Ты — профессиональный AI-ассистент... [системный промпт на 8000 токенов]",
"cache_control": {"type": "ephemeral"} # ← КЛЮЧ: помечаем этот контент для кэширования
}
],
messages=[
{"role": "user", "content": "Помоги мне разобрать сегодняшнюю почту"}
]
)
Технические ограничения кэша:
- Можно установить максимум 4 точки кэширования (маркеры
cache_control). - Серия Sonnet: минимальный объем кэшируемого контента ≥ 1 024 токена.
- Opus / Haiku 4.5: минимальный объем кэшируемого контента ≥ 4 096 токенов.
- Поддерживаемые модели: Claude Opus 4, Sonnet 4.6, Sonnet 4.5, Sonnet 4, Sonnet 3.7, Haiku 4.5, Haiku 3.5, Haiku 3 и др.
🎯 Важное примечание: APIYI (apiyi.com) полностью поддерживает вызовы в нативном формате Anthropic, включая параметр
cache_control. Используя нативный формат для моделей Claude в APIYI, вы получаете двойную выгоду: тарификацию с учетом кэша (экономия до 90%) + скидку 20% от APIYI.
3. Важное понимание: почему режим совместимости с OpenAI не экономит токены
Это самая частая ловушка, в которую попадают пользователи OpenClaw.
Суть различий между форматами интерфейсов
Многие сторонние AI-инструменты и сервисы-прокси для удобства пользователей предоставляют режим совместимости с OpenAI — то есть позволяют вызывать модели Claude и другие через формат интерфейса OpenAI /v1/chat/completions.
На первый взгляд это удобно: «один код для всех моделей». Но есть критический недостаток:
В формате интерфейса /v1/chat/completions просто нет места для параметра cache_control — потому что это эксклюзивная нативная функция Anthropic.
Когда вы вызываете Claude через формат совместимости с OpenAI:
- Ваш запрос преобразуется в формат OpenAI.
- Сервис-прокси затем переводит его обратно в нативный формат Anthropic.
- Но информация о
cache_controlтеряется уже на первом шаге. - Сервер Claude получает запрос без маркеров кэширования и каждый раз списывает полную стоимость за все токены.
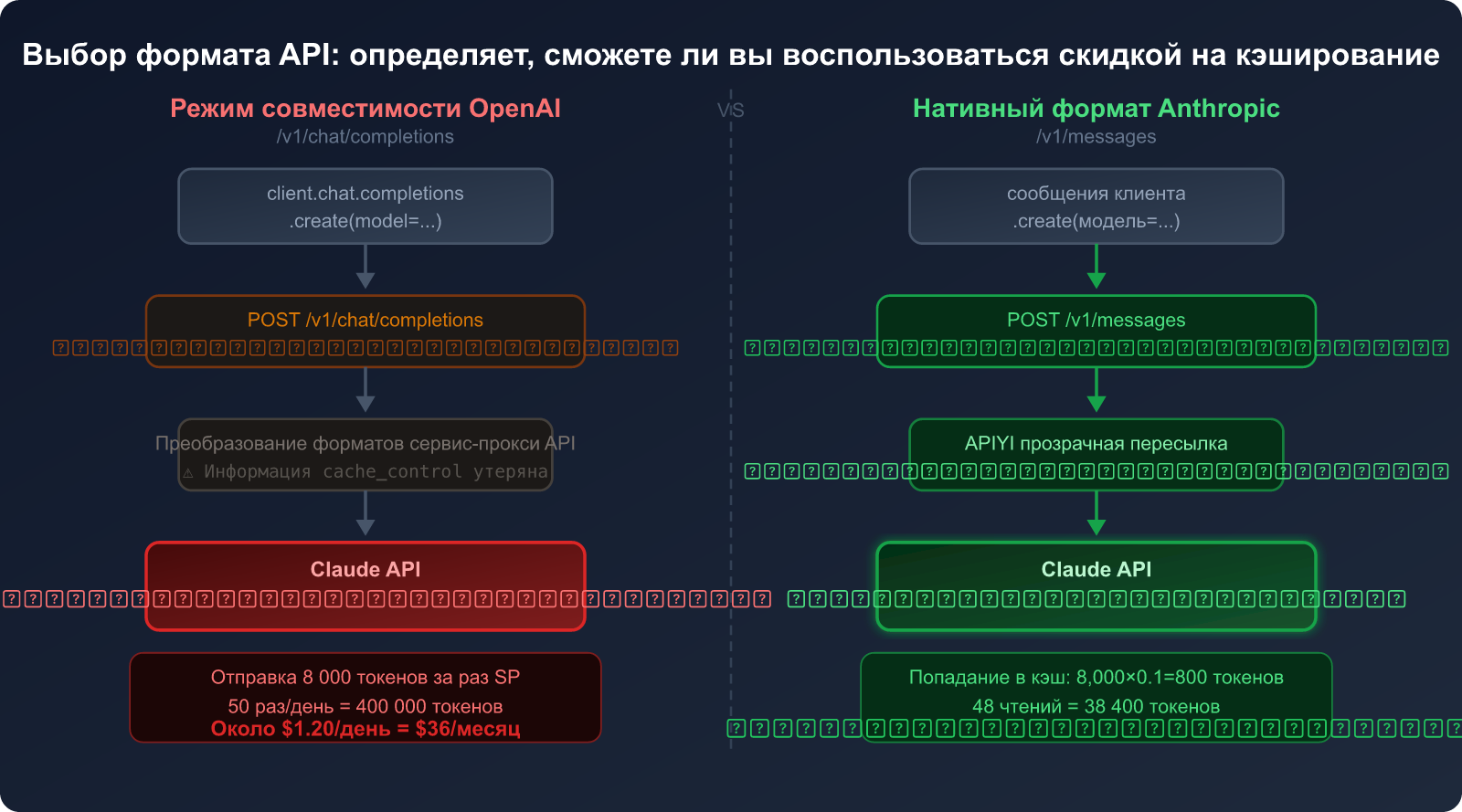
Сравнение: режим совместимости с OpenAI vs нативный формат Anthropic
| Критерий сравнения | Режим совместимости с OpenAI | Нативный формат Anthropic |
|---|---|---|
| Путь API | /v1/chat/completions |
/v1/messages |
| Поддержка кэша Claude | ❌ Не поддерживается | ✅ Полная поддержка |
Параметр cache_control |
❌ Отсутствует | ✅ Поддержка 4 точек |
| Оплата системного промпта | 💸 Полная (1× цена) | 💰 Чтение из кэша (0.1× цена) |
| Сложность кода | Низкая (универсальный код) | Средняя (нужен Anthropic SDK) |
| Эффект экономии (высокая частота) | 0% | До 90% |
Дополнительные проблемы при развертывании API не от производителя
Помимо формата интерфейса, есть еще одна ситуация, в которой легко запутаться: модель с тем же названием, развернутая облачным провайдером, не идентична оригиналу.
На примере GLM-4 (Zhipu AI):
- Официальный API на сайте z.ai: поддерживает нативную функцию кэширования от Zhipu.
- GLM-4, развернутая на Alibaba Cloud / Tencent Cloud: использует API-шлюз облачного провайдера и не обладает функцией кэширования оригинала.
Это не проблема самой GLM-4, а общая черта сторонних развертываний: облачные провайдеры при хостинге моделей обычно предоставляют только стандартный API для чата и не передают специфические функции производителя (такие как кэширование).
Аналогия: это как купить товар через посредника — вы можете не получить доступ к специальному сервисному обслуживанию от официального производителя.
Реальное влияние:
Сценарий: 50 вызовов в день, системный промпт 6 000 токенов.
Официальный API (с поддержкой кэша):
Запись: 2 раза × 6 000 × 1.25 = 15 000 токенов
Чтение: 48 раз × 6 000 × 0.1 = 28 800 токенов
Эквивалентный расход ≈ 43 800 токенов/день
Сторонний API (без кэша):
Полная оплата: 50 раз × 6 000 = 300 000 токенов/день
Разница: расход без кэша в 6.85 раза выше, чем с кэшем.
IV. Сравнение API: как выбрать лучший вариант подключения для OpenClaw
Сравнение четырех вариантов подключения
| Вариант подключения | Цена (относительно оригинала) | Поддержка кэширования | Поддержка нескольких моделей | Сценарии использования |
|---|---|---|---|---|
| Официальный API Anthropic | 100% (оригинал) | ✅ Полная | ❌ Только Claude | Большой бюджет, только пользователи Claude |
| APIYI (нативный формат Anthropic) | 80% (скидка 20%) | ✅ Полная | ✅ Несколько моделей | Рекомендуется: экономия + гибкое переключение |
| Обычные прокси-сервисы (совместимые с OpenAI) | 85-95% (варьируется) | ❌ Не поддерживается | ✅ Несколько моделей | Если не используется кэширование Claude |
| Сторонние облачные развертывания | 90-110% (варьируется) | ❌ Не поддерживается | ❌ Одна модель | Сценарии с корпоративными требованиями комплаенса |
Двойная логика экономии с APIYI
Преимущество APIYI для моделей Claude заключается в том, что сервис одновременно поддерживает нативный формат Anthropic и предлагает цену со скидкой 20%.
Сочетание этих двух факторов дает впечатляющий результат:
Обычный пользователь (оригинал + совместимость с OpenAI, без кэша):
Ежемесячный расход токенов System Prompt: 12 000 000 токенов
Стоимость = 12 000 000 × $3/1M = $36
Пользователь APIYI (скидка 20% + нативный формат + кэш):
Фактически оплачиваемые токены ≈ 1 440 000 (после кэширования)
Стоимость = 1 440 000 × $3 × 0.8 / 1M = $3.46
Общая экономия = ($36 - $3.46) / $36 ≈ 90%
🎯 Совет по выбору: Если вы используете OpenClaw и в основном выбираете Claude, настоятельно рекомендуем подключаться через APIYI (apiyi.com) в нативном формате Anthropic. Базовая скидка 20% плюс 90% экономии на кэшировании в сумме снизят ваш счет на 85-90%. При этом APIYI поддерживает GLM-5, GPT и другие модели, что позволяет легко переключаться для сравнения результатов.
V. Полный гайд по экономии в OpenClaw: 5 шагов, которые можно сделать прямо сейчас
Шаг 1: Переключитесь на нативный формат интерфейса Anthropic
Это самый важный шаг, который напрямую определяет, сможете ли вы воспользоваться тарификацией с кэшированием.
Способ настройки OpenClaw:
В конфигурации моделей OpenClaw (config.json) найдите поле models.providers и добавьте APIYI в качестве провайдера по следующему шаблону. Ключевой момент — установить поле api в значение "anthropic-messages". Только так будет использоваться нативный формат Anthropic с поддержкой кэширования:
{
"models": {
"providers": {
"apiyi": {
"baseUrl": "https://api.apiyi.com",
"apiKey": "sk-ваш_ключ_здесь",
"api": "anthropic-messages",
"headers": {
"anthropic-version": "2023-06-01",
"anthropic-beta": ""
},
"models": [
{
"id": "claude-sonnet-4-6",
"name": "claude-sonnet-4-6",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
},
{
"id": "claude-sonnet-4-6-thinking",
"name": "claude-sonnet-4-6-thinking",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
}
]
}
}
}
}
Пояснения к настройке:
"api": "anthropic-messages"← Критически важно: указывает на использование нативного формата/v1/messagesвместо совместимого/v1/chat/completions."baseUrl": "https://api.apiyi.com"← Базовый URL APIYI (не нужно добавлять/v1, OpenClaw сделает это автоматически)."anthropic-version": "2023-06-01"← Заголовок версии Anthropic API, без него запрос не пройдет.contextWindow: 200000← Claude Sonnet 4.6 поддерживает контекстное окно в 200K.
Проверка работы кэша:
Проверьте заголовки ответа API или логи на наличие полей cache_read_input_tokens и cache_creation_input_tokens. Если там есть значения, значит кэш работает:
# Проверка ответа с кэшем
response = client.messages.create(...)
# Проверка поля usage
print(response.usage)
# Пример вывода:
# Usage(
# input_tokens=150, # новые токены в текущем запросе
# cache_creation_input_tokens=8000, # первая запись в кэш (тарифицируется как 1.25x)
# cache_read_input_tokens=0, # последующее попадание в кэш (тарифицируется как 0.1x)
# output_tokens=300
# )
🎯 Как подключиться: Зарегистрируйтесь на APIYI (apiyi.com), получите API-ключ и установите
base_urlнаhttps://api.apiyi.com/v1. Теперь вы можете использовать нативный формат Anthropic без изменения кода, и тарификация с кэшированием Claude заработает мгновенно.
Шаг 2: Разумно расставляйте точки кэширования
Расположение точек кэширования (cache_control) имеет решающее значение. Следует кэшировать «большой и статичный» контент:
# Лучшая практика: кэширование системного промпта + определений инструментов
response = client.messages.create(
model="claude-sonnet-4-6",
system=[
{
"type": "text",
"text": SYSTEM_PROMPT, # Основной системный промпт на 5 000–10 000 токенов
"cache_control": {"type": "ephemeral"} # Точка кэширования 1
},
{
"type": "text",
"text": TOOL_DEFINITIONS, # Список инструментов (обычно тоже объемный)
"cache_control": {"type": "ephemeral"} # Точка кэширования 2
}
],
messages=conversation_history, # История диалога (не кэшируется, меняется каждый раз)
...
)
Ключевые моменты стратегии кэширования:
- ✅ Подходит для кэширования: системные промпты, определения инструментов, большие статические документы, содержимое документов из RAG.
- ❌ Не подходит для кэширования: текущие сообщения пользователя, динамически генерируемый контент, данные, меняющиеся при каждом запросе.
- ⚠️ Важно: кэширование работает по совпадению префикса, поэтому статический контент должен находиться в начале последовательности сообщений.
Шаг 3: Включите QMD для уменьшения длины контекста
QMD (Quick Memory Database) — это функция локального семантического поиска в OpenClaw. Принцип ее работы:
Традиционный способ:
Каждая отправка [всей истории диалога] → тратит огромное количество токенов
Способ QMD:
Локальное создание векторной базы данных → поиск наиболее релевантных фрагментов истории
Каждая отправка только [3–5 самых релевантных записей] → экономия 60–97% токенов
Реальный эффект QMD: Согласно официальной документации OpenClaw, QMD позволяет достичь экономии токенов от 60% до 97%, в зависимости от объема истории диалогов и типа задачи.
Как включить (в интерфейсе настроек OpenClaw):
- Settings → Memory → Enable QMD
- Установите путь хранения QMD (локально, данные не выгружаются)
- Установите порог релевантности (рекомендуется выше 0.7, чтобы избежать «шумных» записей из истории)
Шаг 4: Выбирайте подходящую модель под тип задачи
Не для всех задач нужна самая мощная модель. Правильное распределение моделей — ключ к контролю затрат:
Стратегия грейдирования задач:
Простые задачи (напоминания, конвертация форматов, простой поиск)
→ Используйте Claude Haiku 4.5 (самая быстрая и дешевая)
→ Примерно 1/5 цены Sonnet
Средние задачи (работа с почтой, систематизация файлов, ревью кода)
→ Используйте Claude Sonnet 4.6 (сбалансированная)
→ Успешность 86.9% (первое место в PinchBench)
Сложные задачи (архитектурный анализ, многошаговые исследования, сложные рассуждения)
→ Используйте Claude Opus 4.6 (сильнейшая логика)
→ Включайте режим рассуждений только тогда, когда это действительно необходимо
Шаг 5: Периодически очищайте контекст
История диалога — один из крупнейших источников расхода токенов (40–50%). Рекомендуется:
- Установить лимит раундов контекста: после 15–20 раундов автоматически делайте резюме и очищайте историю.
- Ручная очистка после завершения задачи: сбрасывайте контекст перед началом новой задачи.
- Включите функцию сжатия сессий в OpenClaw: используйте ИИ для сжатия длинной истории в краткую сводку.
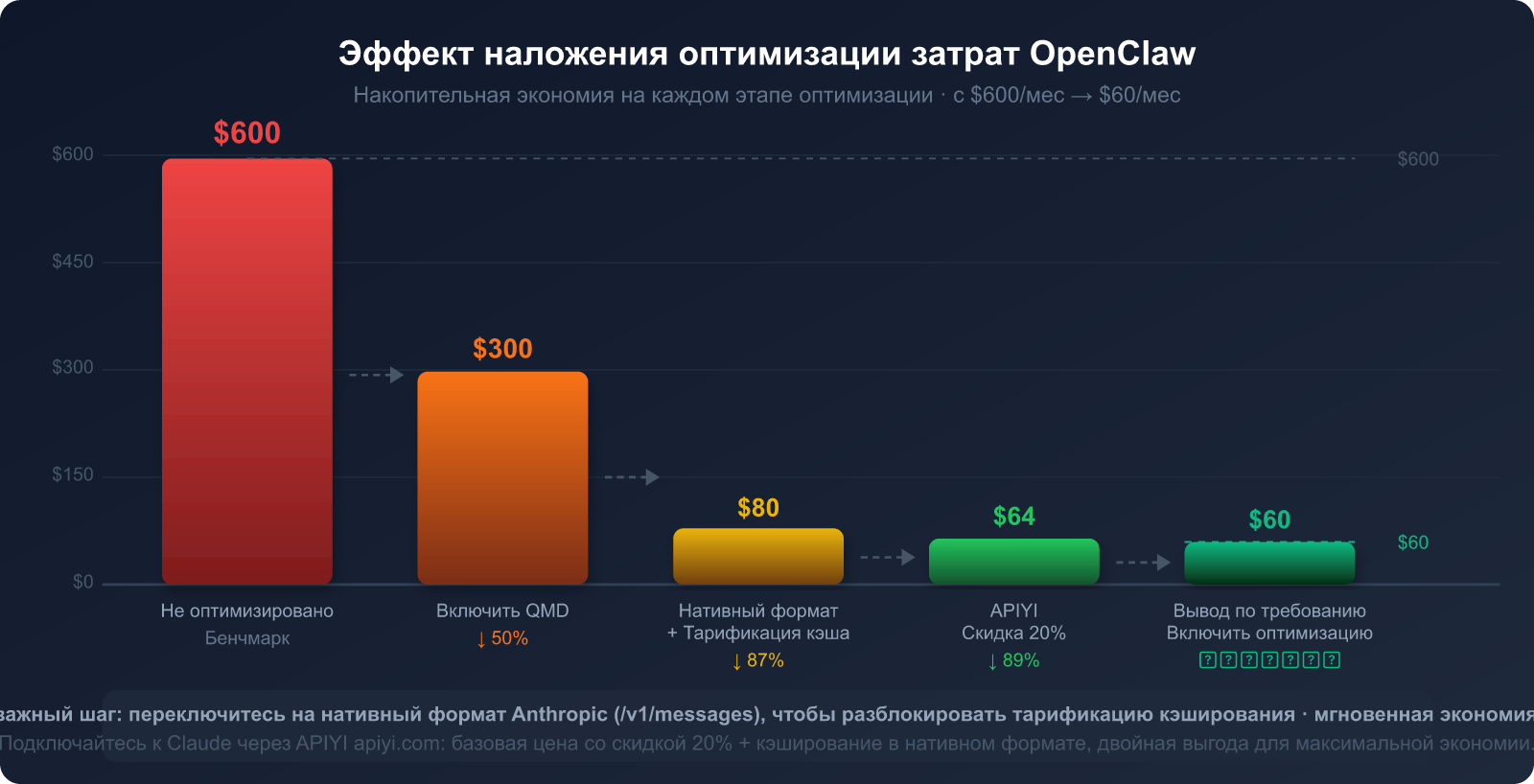
Прогноз общего эффекта от пяти шагов оптимизации
Для пользователя со средним уровнем использования OpenClaw (расходы без оптимизации ~$300–600), ожидаемый эффект после выполнения этих шагов:
| Шаг оптимизации | На что направлено | Ожидаемая экономия | Сложность реализации |
|---|---|---|---|
| 1. Переход на нативный формат Anthropic | Повторная тарификация System Prompt | 85-90% (в части SP) | ⭐ Низкая (смена base_url) |
| 2. Настройка точек кэширования | Инструменты + статика | 80-90% (в части инструментов) | ⭐⭐ Низкая/Средняя |
| 3. Включение QMD | Токены истории диалога | 60-97% (в части истории) | ⭐⭐ Низкая/Средняя |
| 4. Грейдирование моделей по задачам | Общая стоимость токенов | 30-70% (разница в цене) | ⭐⭐⭐ Средняя |
| 5. Периодическая очистка контекста | Эффект «снежного кома» истории | 20-40% (долгосрочная выгода) | ⭐ Низкая |
🎯 Совет по приоритетам: Шаги 1 (переход на нативный формат) и 3 (включение QMD) дают максимальную выгоду при минимальных усилиях. Рекомендуем начать с них — это обычно снижает счет на 60–80%. При подключении Claude через APIYI (apiyi.com) первый шаг занимает 5 минут и требует изменения всего одной строки
base_url.
6. Практическая настройка: полный пример OpenClaw + APIYI + кэширование Claude
Ниже приведен полный оптимизированный пример конфигурации OpenClaw, который большинство пользователей могут просто скопировать и использовать:
import anthropic
# Используем нативный формат Anthropic через APIYI
client = anthropic.Anthropic(
api_key="sk-your-apiyi-key", # API-ключ APIYI (получите после регистрации на apiyi.com)
base_url="https://api.apiyi.com/v1"
)
# Определяем системный промпт (большой объем данных, подходит для кэширования)
SYSTEM_PROMPT = """
Ты — профессиональный AI-ассистент, работающий на платформе OpenClaw.
В твои обязанности входит: управление расписанием, обработка почты, систематизация файлов, помощь в разработке кода...
[Обычно здесь идут подробные инструкции на 5 000–10 000 токенов]
"""
# Определяем список инструментов (тоже большой фиксированный блок, подходит для кэширования)
TOOL_DEFINITIONS = """
Доступные инструменты: calendar_api, email_api, file_system, code_runner...
[Подробное описание инструментов, обычно 2 000–5 000 токенов]
"""
def call_openclaw_with_cache(conversation_history: list, user_message: str):
"""Оптимизированный вызов OpenClaw API с включенным кэшированием"""
response = client.messages.create(
model="claude-sonnet-4-6", # 1-е место в рейтинге PinchBench
max_tokens=4096,
# Системный промпт: разметка точек кэширования
system=[
{
"type": "text",
"text": SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"} # Точка кэширования 1
},
{
"type": "text",
"text": TOOL_DEFINITIONS,
"cache_control": {"type": "ephemeral"} # Точка кэширования 2
}
],
# История диалога + новое сообщение
messages=[
*conversation_history, # История сообщений (не кэшируется, так как меняется каждый раз)
{"role": "user", "content": user_message}
]
)
# Вывод использования токенов (для мониторинга эффекта оптимизации)
usage = response.usage
print(f"Входные токены: {usage.input_tokens}")
print(f"Запись в кэш: {usage.cache_creation_input_tokens}")
print(f"Чтение из кэша: {usage.cache_read_input_tokens}")
print(f"Выходные токены: {usage.output_tokens}")
return response.content[0].text
🎯 Быстрый старт: Замените
api_keyв коде выше на ваш ключ, полученный при регистрации на APIYI (apiyi.com). Больше ничего менять не нужно — вы сразу начнете использовать нативный формат Anthropic с тарификацией за кэш и скидкой 20% от APIYI.
Часто задаваемые вопросы (FAQ)
В: Действительно ли APIYI поддерживает нативный формат Anthropic (/v1/messages)?
Да, APIYI (apiyi.com) поддерживает два формата интерфейса одновременно:
- Нативный формат Anthropic:
/v1/messages(поддерживает тарификацию кэша) - OpenAI-совместимый формат:
/v1/chat/completions(удобен для универсального кода)
Для моделей Claude настоятельно рекомендуем использовать нативный формат Anthropic, чтобы экономить на кэшировании. Просто используйте Python SDK anthropic и укажите base_url, указывающий на APIYI.
🎯 Зайдите на apiyi.com, зарегистрируйтесь, и в консоли вы увидите примеры кода для обоих форматов.
В: Достаточно ли 5 минут TTL для кэша? Как понять, нужен ли TTL на 1 час?
Это зависит от частоты ваших вызовов:
- Если интервал между вызовами OpenClaw < 5 минут (например, вы непрерывно обрабатываете поток задач), стандартного TTL в 5 минут будет достаточно.
- Если интервал составляет от 5 минут до 1 часа (например, вы делаете паузы между пачками задач), стоит рассмотреть TTL 1 час (стоимость записи в 2 раза выше, но вероятность попадания в кэш гораздо больше).
- Если интервал > 1 часа, кэширование теряет смысл, проще каждый раз записывать данные заново.
В: Есть ли советы по экономии при использовании китайских моделей, например GLM-5?
Функция кэширования для GLM-5 требует использования нативного API через официальный сайт Zhipu AI (z.ai). Сторонние развертывания (например, на Alibaba Cloud) могут её не поддерживать.
APIYI также поддерживает GLM-5 и другие отечественные модели со скидкой от 20%. Это удобно для тестирования разных моделей через единый интерфейс. Когда определитесь с подходящей моделью, сможете решить — оставаться на APIYI или подключаться к вендору напрямую.
В: Я уже использую другой сервис-прокси API, насколько сложно перейти на платформу с поддержкой нативного формата?
Затраты на миграцию минимальны. Нужно изменить всего два параметра в коде:
# До миграции (OpenAI-совместимый формат)
from openai import OpenAI
client = OpenAI(api_key="sk-xxx", base_url="адрес_старого_прокси")
response = client.chat.completions.create(model="claude-sonnet-4-6", ...)
# После миграции (нативный формат Anthropic с поддержкой кэша)
import anthropic
client = anthropic.Anthropic(
api_key="sk-новый-ключ-APIYI", # ← Меняем на ключ APIYI
base_url="https://api.apiyi.com/v1" # ← Меняем адрес на APIYI
)
response = client.messages.create(model="claude-sonnet-4-6", ...)
# Затем просто добавьте cache_control в параметры system, чтобы включить кэш
Основная работа — это замена chat.completions.create на messages.create. Формат сообщений очень похож (структура role/content совпадает, но system превращается из строки в список объектов). Обычно миграция занимает не больше пары часов.
В: Как проверить, что в моем экземпляре OpenClaw успешно включилось кэширование?
Самый простой способ: при двух последовательных вызовах посмотрите на объект usage в ответе API:
- Первый вызов:
cache_creation_input_tokensимеет значение (запись в кэш). - Второй вызов:
cache_read_input_tokensимеет значение (попадание в кэш).
Если во втором вызове cache_read_input_tokens равен количеству токенов в вашем System Prompt, значит, кэширование работает на все сто.
В: Обязательно ли отключать режим рассуждений (Extended Thinking)?
Необязательно отключать его полностью, но стоит использовать его по необходимости. Рекомендуемая стратегия:
- Простые задачи (сортировка почты, расписание): отключите режим рассуждений.
- Задачи средней сложности (ревью кода, саммари): по умолчанию выключен, включайте при возникновении трудностей.
- Сложные задачи (архитектурные решения, многоэтапные исследования): включите, но установите разумный лимит
budget_tokens.
В Claude API можно ограничить максимальный расход токенов на рассуждения через параметр thinking: {"type": "enabled", "budget_tokens": 5000}.
Итог: Основная логика экономии в OpenClaw
Давайте резюмируем все способы экономии на одной схеме:
Вспомним ключевые моменты этой статьи:
Три главные причины высокого расхода:
- Повторная отправка всей истории диалога (40-50% затрат)
- Повторная отправка System Prompt при каждом запросе (25-30%)
- Бесконтрольное использование тяжелых моделей для простых задач (20-25%)
Самые эффективные способы экономии:
- 🥇 Кэширование Claude: экономия до 90% (обязательно используйте нативный формат Anthropic)
- 🥈 Локальный семантический поиск QMD: экономия 60-97% токенов контекста истории
- 🥉 Разделение моделей по задачам: Haiku для легких задач, Sonnet/Opus — для сложных
- Выбор API-канала через APIYI: базовая скидка 20% + поддержка нативного формата
Самый важный инсайт:
Формат, совместимый с OpenAI (
/v1/chat/completions), не умеет передавать параметрcache_control.
Даже если вы используете Claude через сервис-прокси, вы не получите скидку за кэширование в этом формате.
Чтобы реально экономить, необходимо использовать нативный формат Anthropic (/v1/messages).
🎯 Действуйте прямо сейчас: Зарегистрируйтесь на APIYI (apiyi.com) и получите API-ключ с поддержкой нативного формата Anthropic.
Просто заменитеbase_urlнаhttps://api.apiyi.com/v1— переход займет не более 3 минут,
и вы увидите резкое снижение счета за токены в тот же день. Скидка 20% на модели Claude и единый интерфейс для всех топовых моделей — это оптимальный выбор для пользователей OpenClaw, стремящихся к эффективности.
Все данные о ценах на API основаны на открытых источниках по состоянию на март 2026 года. Актуальные цены уточняйте в официальных анонсах платформ.
Автор: Команда APIYI | Больше советов по использованию OpenClaw в центре помощи APIYI на apiyi.com