11 февраля 2026 года компания Zhipu AI официально представила GLM-5. На данный момент это одна из крупнейших по количеству параметров опенсорсных больших языковых моделей. GLM-5 построена на архитектуре MoE (смесь экспертов) общим объемом 744B, при этом для каждой итерации вывода активируется 40B параметров. Модель демонстрирует лучшие показатели среди открытых решений в задачах на логическое рассуждение, написание кода и работу в качестве ИИ-агента.
В чем польза: Прочитав эту статью, вы разберетесь в технологической архитектуре GLM-5, научитесь вызывать ее через API, настраивать режим рассуждений (Thinking mode) и узнаете, как выжать максимум из этого 744B флагмана в реальных проектах.

Обзор ключевых параметров GLM-5
Прежде чем углубляться в технические детали, давайте взглянем на ключевые характеристики GLM-5:
| Параметр | Значение | Описание |
|---|---|---|
| Общее число параметров | 744B (744 млрд) | Одна из крупнейших открытых моделей на сегодня |
| Активные параметры | 40B (40 млрд) | Используются непосредственно при каждом инференсе |
| Тип архитектуры | MoE (Mixture of Experts) | 256 экспертов, 8 активируются на каждый токен |
| Контекстное окно | 200 000 токенов | Поддержка обработки сверхдлинных документов |
| Максимальный вывод | 128 000 токенов | Подходит для генерации длинных текстов |
| Данные для обучения | 28.5T токенов | На 24% больше, чем у предыдущего поколения |
| Лицензия | Apache-2.0 | Полностью открытый исходный код, разрешено коммерческое использование |
| Оборудование | Чипы Huawei Ascend | Полностью отечественный стек вычислений (КНР), без зависимости от зарубежного железа |
Одной из примечательных особенностей GLM-5 является то, что она полностью обучена на чипах Huawei Ascend и фреймворке MindSpore. Это подтверждает зрелость китайского стека вычислительных мощностей и дает разработчикам мощную альтернативу, не зависящую от внешних технологий.
Эволюция серий GLM
GLM-5 — это пятое поколение серии GLM от Zhipu AI. Каждое поколение приносило значительный скачок в возможностях:
| Версия | Дата выпуска | Масштаб параметров | Ключевой прорыв |
|---|---|---|---|
| GLM-4 | Январь 2024 | Не раскрыто | Базовые мультимодальные возможности |
| GLM-4.5 | Март 2025 | 355B (32B активных) | Первое внедрение архитектуры MoE |
| GLM-4.5-X | Июнь 2025 | То же | Усиленное рассуждение, флагманское позиционирование |
| GLM-4.7 | Октябрь 2025 | Не раскрыто | Режим рассуждения Thinking |
| GLM-4.7-FlashX | Декабрь 2025 | Не раскрыто | Сверхдешевый и быстрый инференс |
| GLM-5 | Февраль 2026 | 744B (40B активных) | Прорыв в возможностях агентов, снижение галлюцинаций на 56% |
С переходом от GLM-4.5 (355B) к GLM-5 (744B) общее количество параметров выросло более чем в два раза. Число активных параметров увеличилось с 32B до 40B (на 25%), а объем данных для предобучения — с 23T до 28.5T токенов. За этими цифрами стоят колоссальные инвестиции Zhipu AI в вычислительные мощности, данные и алгоритмы.
🚀 Быстрый старт: GLM-5 уже доступна на APIYI (apiyi.com). Цены такие же, как на официальном сайте, а с учетом акций при пополнении можно получить выгоду около 20%. Отличный вариант для разработчиков, которые хотят быстро протестировать этот 744B флагман.
Технический разбор архитектуры GLM-5 MoE
Почему GLM-5 использует архитектуру MoE
MoE (Mixture of Experts, «смесь экспертов») — это основной путь масштабирования больших языковых моделей сегодня. В отличие от архитектуры Dense (где все параметры участвуют в каждом вычислении), MoE активирует лишь небольшую часть нейронной сети («экспертов») для обработки каждого токена. Это позволяет сохранять огромный объем знаний, радикально снижая стоимость инференса.
Ключевые особенности архитектуры MoE в GLM-5:
| Характеристика | Реализация в GLM-5 | Техническая ценность |
|---|---|---|
| Всего экспертов | 256 | Огромная емкость знаний |
| Активация на токен | 8 экспертов | Высокая эффективность вычислений |
| Коэффициент разреженности | 5.9% | Используется лишь малая часть параметров |
| Механизм внимания | DSA + MLA | Снижение затрат на развертывание |
| Оптимизация памяти | MLA экономит 33% | Меньшее потребление видеопамяти (VRAM) |
Проще говоря, хотя в GLM-5 заложено 744 млрд параметров, при каждом ответе активируется только 40 млрд (около 5.9%). Это значит, что стоимость её работы намного ниже, чем у аналогичной по размеру Dense-модели, при этом она сохраняет эрудицию, накопленную в 744B параметрах.
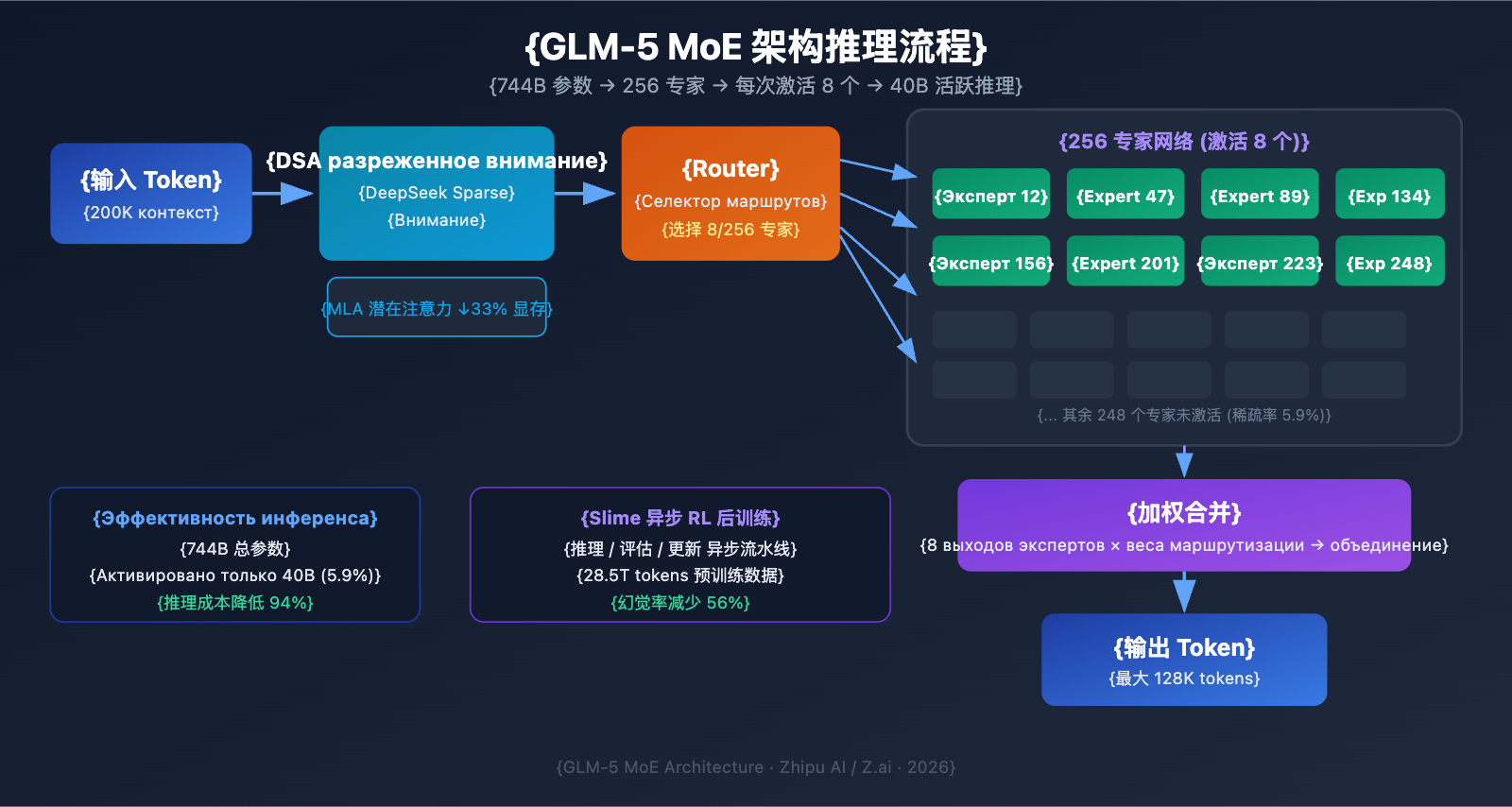
DeepSeek Sparse Attention (DSA) в GLM-5
GLM-5 интегрирует механизм DeepSeek Sparse Attention, который позволяет сохранять способность работать с длинным контекстом при значительном снижении затрат на развертывание. В сочетании с Multi-head Latent Attention (MLA), GLM-5 эффективно работает даже с окном в 200K токенов.
Что это дает на практике:
- DSA (DeepSeek Sparse Attention): Снижает вычислительную сложность внимания за счет использования разреженных паттернов. Традиционный механизм внимания при 200K токенах требует колоссальных вычислений; DSA фокусируется только на ключевых позициях токенов, сохраняя целостность информации.
- MLA (Multi-head Latent Attention): Сжимает KV-кэш в латентное пространство, уменьшая потребление памяти примерно на 33%. В сценариях с длинным контекстом KV-кэш обычно является основным «пожирателем» видеопамяти, и MLA эффективно решает эту проблему.
Комбинация этих технологий означает, что даже модель масштаба 744B после квантования FP8 может работать на 8 GPU, что существенно снижает порог входа для её использования.
Постобучение GLM-5: Асинхронная система RL Slime
Для постобучения GLM-5 использовалась новая инфраструктура асинхронного обучения с подкреплением (RL) под названием «Slime». В традиционном RL-обучении часто возникают «бутылочные горлышки» — простои между этапами генерации, оценки и обновления параметров. Slime делает эти шаги асинхронными, что позволяет проводить итерации более гибко и значительно повышает пропускную способность обучения.
В обычном процессе модель должна выполнить пачку инференсов, дождаться результатов оценки и только потом обновить параметры. Slime разделяет эти процессы на независимые асинхронные конвейеры. Это позволяет выполнять генерацию, оценку и обновление параллельно.
Этот технологический прорыв напрямую отразился на качестве: уровень галлюцинаций GLM-5 снизился на 56% по сравнению с предыдущим поколением. Более интенсивные итерации постобучения позволили модели стать гораздо точнее в фактах.
Сравнение GLM-5 и архитектуры Dense
Чтобы лучше понять преимущества MoE, сравним GLM-5 с гипотетической Dense-моделью того же масштаба:
| Параметр сравнения | GLM-5 (744B MoE) | Гипотетическая 744B Dense | Реальная разница |
|---|---|---|---|
| Параметры на инференс | 40B (5.9%) | 744B (100%) | В MoE меньше на 94% |
| Требуемая видеопамять | 8x GPU (FP8) | Около 96x GPU | В MoE значительно ниже |
| Скорость инференса | Высокая | Очень низкая | MoE лучше подходит для продакшена |
| Объем знаний | Полные 744B знаний | Полные 744B знаний | Сопоставимо |
| Специализация | Разные эксперты для разных задач | Единая обработка | MoE работает тоньше |
| Стоимость обучения | Высокая, но контролируемая | Экстремально высокая | MoE выгоднее по соотношению цена/качество |
Главное преимущество MoE в том, что вы получаете эрудицию модели на 744 млрд параметров по цене инференса модели на 40 млрд. Именно поэтому GLM-5 может предлагать передовую производительность по цене, которая значительно ниже, чем у закрытых моделей аналогичного класса.
Быстрый старт с GLM-5 API
Подробный разбор параметров запроса GLM-5 API
Прежде чем переходить к коду, давайте разберем конфигурацию параметров API GLM-5:
| Параметр | Тип | Обязательный | Значение по умолчанию | Описание |
|---|---|---|---|---|
model |
string | ✅ | — | Фиксированное значение "glm-5" |
messages |
array | ✅ | — | Сообщения в стандартном формате чата |
max_tokens |
int | ❌ | 4096 | Максимальное количество токенов на выходе (лимит 128K) |
temperature |
float | ❌ | 1.0 | Температура сэмплирования: чем ниже, тем предсказуемее ответ |
top_p |
float | ❌ | 1.0 | Параметр ядерного сэмплирования (nucleus sampling) |
stream |
bool | ❌ | false | Использовать ли потоковую передачу (стриминг) |
thinking |
object | ❌ | disabled | {"type": "enabled"} — включить режим рассуждения |
tools |
array | ❌ | — | Определение инструментов для Function Calling |
tool_choice |
string | ❌ | auto | Стратегия выбора инструментов |
Минималистичный пример вызова GLM-5
GLM-5 полностью совместим с форматом OpenAI SDK. Чтобы начать работу, достаточно просто изменить параметры base_url и model:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Единый интерфейс APIYI
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "你是一位资深的 AI 技术专家"},
{"role": "user", "content": "解释 MoE 混合专家架构的工作原理和优势"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
Этот фрагмент кода — самый простой способ вызвать GLM-5. Модель идентифицируется как glm-5, а интерфейс полностью совместим с форматом chat.completions от OpenAI, так что миграция существующих проектов сводится к замене всего двух параметров.
Режим рассуждения GLM-5 Thinking
GLM-5 поддерживает режим Thinking, аналогичный расширенным возможностям рассуждения в DeepSeek R1 и Claude. При его активации модель перед ответом выстраивает внутреннюю цепочку рассуждений, что значительно улучшает результаты в сложных математических, логических и программных задачах:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Единый интерфейс APIYI
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "证明: 对于所有正整数 n, n^3 - n 能被 6 整除"}
],
extra_body={
"thinking": {"type": "enabled"}
},
temperature=1.0 # В режиме Thinking рекомендуется использовать 1.0
)
print(response.choices[0].message.content)
Рекомендации по использованию режима GLM-5 Thinking:
| Сценарий | Включать Thinking | Рекомендуемая temperature | Описание |
|---|---|---|---|
| Математические доказательства / задачи | ✅ Да | 1.0 | Требуются глубокие рассуждения |
| Отладка кода / проектирование архитектуры | ✅ Да | 1.0 | Нужен системный анализ |
| Логические выводы / анализ | ✅ Да | 1.0 | Нужна цепочка мыслей |
| Повседневный диалог / копирайтинг | ❌ Нет | 0.5-0.7 | Сложные рассуждения не требуются |
| Извлечение информации / саммари | ❌ Нет | 0.3-0.5 | Важна стабильность вывода |
| Генерация креативного контента | ❌ Нет | 0.8-1.0 | Нужно разнообразие |
Потоковый вывод GLM-5
Для сценариев, требующих взаимодействия в реальном времени, GLM-5 поддерживает потоковую передачу данных. Пользователь может видеть результат постепенно, по мере его генерации моделью:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
stream = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "用 Python 实现一个带缓存的 HTTP 客户端"}
],
stream=True,
temperature=0.6
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
GLM-5 Function Calling и создание агентов
GLM-5 нативно поддерживает Function Calling — ключевую технологию для построения систем на базе агентов. В тесте HLE w/ Tools модель набрала 50,4%, обойдя Claude Opus (43,4%), что подтверждает её отличные способности в вызове инструментов и оркестрации задач:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "search_documents",
"description": "搜索知识库中的相关文档",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "搜索关键词"},
"top_k": {"type": "integer", "description": "返回结果数量", "default": 5}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "execute_code",
"description": "在沙箱环境中执行 Python 代码",
"parameters": {
"type": "object",
"properties": {
"code": {"type": "string", "description": "要执行的 Python 代码"},
"timeout": {"type": "integer", "description": "超时时间(秒)", "default": 30}
},
"required": ["code"]
}
}
}
]
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "你是一个能够搜索文档和执行代码的AI助手"},
{"role": "user", "content": "帮我查一下 GLM-5 的技术参数,然后用代码画一个性能对比图"}
],
tools=tools,
tool_choice="auto"
)
# Обработка вызова инструментов
message = response.choices[0].message
if message.tool_calls:
for tool_call in message.tool_calls:
print(f"Вызов инструмента: {tool_call.function.name}")
print(f"Параметры: {tool_call.function.arguments}")
Посмотреть пример вызова через cURL
curl https://api.apiyi.com/v1/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5",
"messages": [
{"role": "system", "content": "你是一位资深软件工程师"},
{"role": "user", "content": "设计一个分布式任务调度系统的架构"}
],
"max_tokens": 8192,
"temperature": 0.7,
"stream": true
}'
🎯 Технический совет: GLM-5 совместим с форматом OpenAI SDK, поэтому для миграции существующих проектов достаточно изменить параметры
base_urlиmodel. Используя платформу APIYI (apiyi.com), вы получаете единое управление интерфейсами и бонусы при пополнении баланса.
Тестирование производительности GLM-5 (Benchmarks)
Основные показатели бенчмарков GLM-5
GLM-5 продемонстрировала высочайший уровень среди моделей с открытым исходным кодом в нескольких популярных бенчмарках:
| Бенчмарк | GLM-5 | Claude Opus 4.5 | GPT-5 | Что тестируется |
|---|---|---|---|---|
| MMLU | 85.0% | 88.7% | 90.2% | Знания по 57 дисциплинам |
| MMLU Pro | 70.4% | — | — | Усложненный междисциплинарный тест |
| GPQA | 68.2% | 71.4% | 73.1% | Научные вопросы уровня аспирантуры |
| HumanEval | 90.0% | 93.2% | 92.5% | Программирование на Python |
| MATH | 88.0% | 90.1% | 91.3% | Математические рассуждения |
| GSM8k | 97.0% | 98.2% | 98.5% | Математические текстовые задачи |
| AIME 2026 I | 92.7% | 93.3% | — | Математические олимпиады |
| SWE-bench | 77.8% | 80.9% | 80.0% | Реальные задачи разработки ПО |
| HLE w/ Tools | 50.4% | 43.4% | — | Рассуждения с использованием инструментов |
| IFEval | 88.0% | — | — | Следование инструкциям |
| Terminal-Bench | 56.2% | 57.9% | — | Работа в терминале |
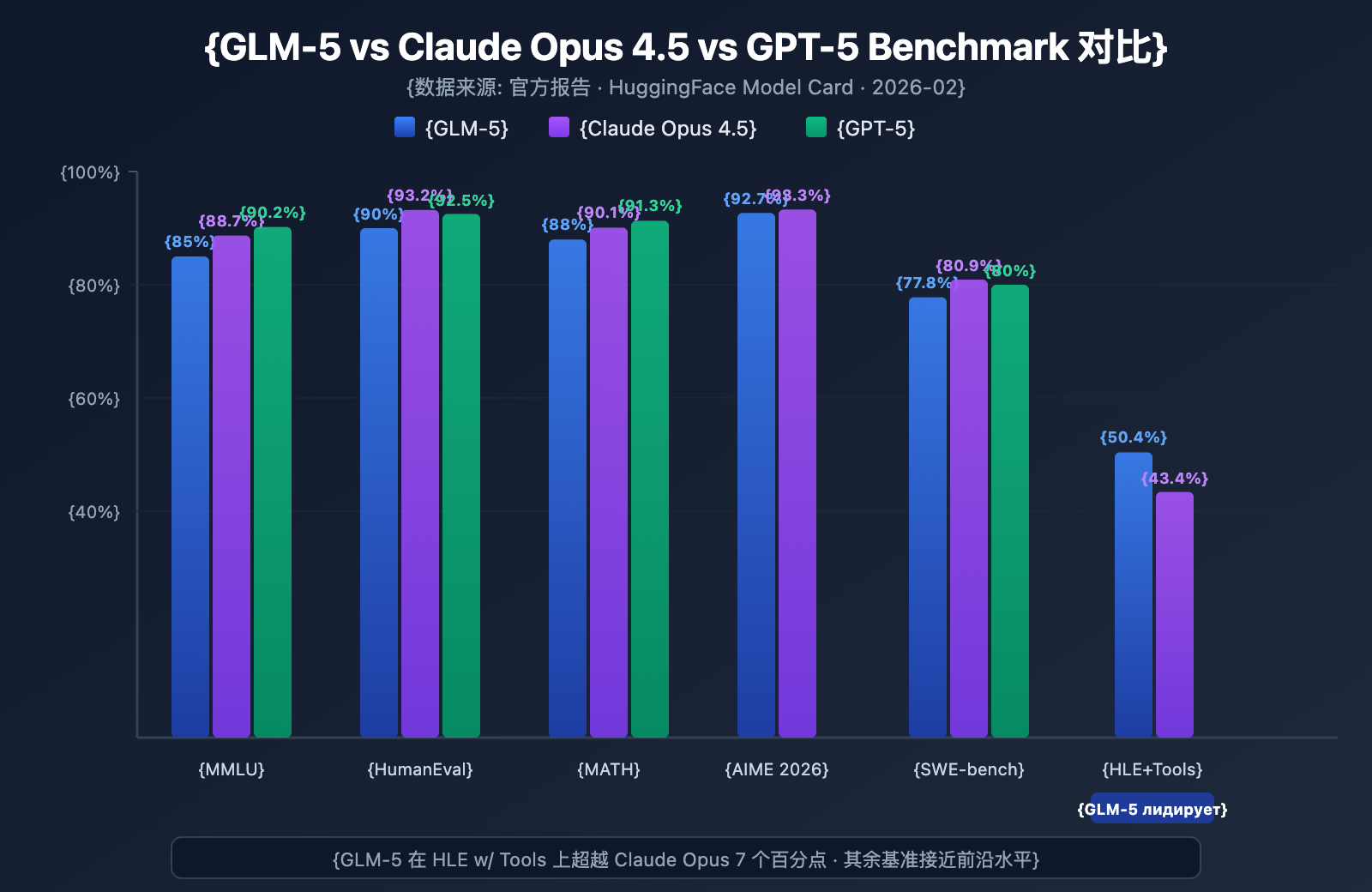
Анализ производительности GLM-5: 4 ключевых преимущества
Данные бенчмарков позволяют выделить несколько важных моментов:
1. Возможности агентов GLM-5: HLE w/ Tools превосходит закрытые модели
В тесте Humanity's Last Exam (с использованием инструментов) GLM-5 набрала 50,4%, обойдя Claude Opus (43,4%) и уступив лишь Kimi K2.5 (51,8%). Это доказывает, что в сценариях с агентами — там, где нужно планировать, вызывать инструменты и итеративно решать сложные задачи — GLM-5 достигла уровня передовых моделей.
Этот результат подтверждает философию дизайна GLM-5: она была специально оптимизирована для рабочих процессов агентов, начиная от архитектуры и заканчивая этапом дообучения (post-training). Для разработчиков, создающих системы AI-агентов, GLM-5 предлагает мощную альтернативу с открытым кодом и отличным соотношением цены и качества.
2. Навыки программирования: в высшей лиге
Результаты HumanEval 90% и SWE-bench Verified 77,8% показывают, что GLM-5 в генерации кода и решении реальных инженерных задач вплотную приблизилась к Claude Opus (80,9%) и GPT-5 (80,0%). Для открытой модели показатель SWE-bench в 77,8% — это прорыв: модель способна понимать реальные issue на GitHub, локализовать ошибки и предлагать рабочие исправления.
3. Математические рассуждения: почти предел возможностей
В тесте AIME 2026 I модель GLM-5 набрала 92,7%, отстав от Claude Opus всего на 0,6 процентных пункта. Показатель GSM8k в 97% говорит о том, что в математических задачах средней сложности GLM-5 крайне надежна. Результат MATH 88% также ставит её в один ряд с лидерами рынка.
4. Контроль галлюцинаций: значительное снижение
Согласно официальным данным, уровень галлюцинаций в GLM-5 снизился на 56% по сравнению с предыдущим поколением. Это стало возможным благодаря асинхронной системе RL Slime, которая обеспечила более качественные итерации дообучения. В задачах, требующих высокой точности — извлечение данных, саммари документов, ответы по базе знаний — снижение галлюцинаций напрямую конвертируется в надежность ответов.
Позиционирование GLM-5 среди аналогичных открытых моделей
В текущем ландшафте открытых больших языковых моделей позиционирование GLM-5 выглядит следующим образом:
| Модель | Параметры | Архитектура | Ключевое преимущество | Лицензия |
|---|---|---|---|---|
| GLM-5 | 744B (40B активных) | MoE | Агенты + минимум галлюцинаций | Apache-2.0 |
| DeepSeek V3 | 671B (37B активных) | MoE | Цена/качество + рассуждения | MIT |
| Llama 4 Maverick | 400B (17B активных) | MoE | Мультимодальность + экосистема | Llama License |
| Qwen 3 | 235B | Dense | Мультиязычность + инструменты | Apache-2.0 |
Уникальность GLM-5 заключается в трех аспектах: глубокая оптимизация под агентные сценарии (лидерство в HLE w/ Tools), рекордно низкий уровень галлюцинаций (снижение на 56%) и независимость цепочки поставок благодаря обучению на полностью отечественных вычислительных мощностях. Для компаний, которым необходимо развертывать передовые открытые модели, GLM-5 — это вариант, заслуживающий самого пристального внимания.
Анализ стоимости и ценообразования GLM-5
Официальные цены GLM-5
| Тип тарификации | Официальная цена Z.ai | Цена на OpenRouter | Описание |
|---|---|---|---|
| Входящие токены | $1.00/M | $0.80/M | За миллион входящих токенов |
| Исходящие токены | $3.20/M | $2.56/M | За миллион исходящих токенов |
| Кэшированные входящие | $0.20/M | $0.16/M | Цена при попадании в кэш |
| Хранение кэша | Временно бесплатно | — | Плата за хранение данных в кэше |
Сравнение цен GLM-5 с конкурентами
Стратегия ценообразования GLM-5 выглядит очень конкурентоспособной, особенно в сравнении с проприетарными передовыми моделями:
| Модель | Входящие ($/M) | Исходящие ($/M) | Стоимость отн. GLM-5 | Позиционирование |
|---|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | Базовый уровень | Open-source флагман |
| Claude Opus 4.6 | $5.00 | $25.00 | ок. 5-8x | Проприетарный флагман |
| GPT-5 | $1.25 | $10.00 | ок. 1.3-3x | Проприетарный флагман |
| DeepSeek V3 | $0.27 | $1.10 | ок. 0.3x | Бюджетный open-source |
| GLM-4.7 | $0.60 | $2.20 | ок. 0.6-0.7x | Флагман прошлого поколения |
| GLM-4.7-FlashX | $0.07 | $0.40 | ок. 0.07-0.13x | Сверхнизкая стоимость |
Судя по ценам, GLM-5 занимает нишу между GPT-5 и DeepSeek V3 — она значительно дешевле большинства закрытых топовых моделей, но чуть дороже легковесных open-source решений. Учитывая масштаб в 744 млрд параметров и лучшую производительность среди открытых моделей, такая цена вполне оправдана.
Линейка продуктов GLM и цены
Если GLM-5 не совсем подходит под ваши задачи, Zhipu предлагает целую линейку моделей на выбор:
| Модель | Входящие ($/M) | Исходящие ($/M) | Сценарии использования |
|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | Сложные рассуждения, агенты, длинные документы |
| GLM-5-Code | $1.20 | $5.00 | Специально для разработки кода |
| GLM-4.7 | $0.60 | $2.20 | Универсальные задачи средней сложности |
| GLM-4.7-FlashX | $0.07 | $0.40 | Высокочастотные дешевые вызовы |
| GLM-4.5-Air | $0.20 | $1.10 | Сбалансированная легкая модель |
| GLM-4.7/4.5-Flash | Бесплатно | Бесплатно | Ознакомление и простые задачи |
💰 Оптимизация затрат: GLM-5 уже доступна на платформе APIYI (apiyi.com), цены там такие же, как у Z.ai. Благодаря акциям при пополнении баланса, реальная стоимость использования может быть на 20% ниже официальной, что отлично подходит для команд и разработчиков с постоянным потоком запросов.
Сценарии использования и рекомендации по выбору GLM-5
Для каких задач подходит GLM-5
Исходя из технических характеристик и результатов бенчмарков, вот основные рекомендации:
Настоятельно рекомендуется для:
- Ворклоу агентов (Agent workflows): GLM-5 спроектирована для длительных циклов работы агентов. В тесте HLE w/ Tools она набрала 50.4%, обойдя Claude Opus. Идеально для создания автономных систем планирования и вызова инструментов.
- Задач по разработке ПО: HumanEval 90%, SWE-bench 77.8%. Модель отлично справляется с генерацией кода, исправлением багов, код-ревью и проектированием архитектуры.
- Математических и научных рассуждений: AIME 92.7%, MATH 88%. Подходит для математических доказательств, вывода формул и научных вычислений.
- Анализа сверхдлинных документов: Контекстное окно в 200K токенов позволяет обрабатывать целиком репозитории кода, техническую документацию, юридические контракты и другие объемные тексты.
- Q&A с низким уровнем галлюцинаций: Уровень галлюцинаций снижен на 56%. Подходит для ответов по базе знаний и суммаризации документов, где важна высокая точность.
Стоит рассмотреть другие варианты для:
- Мультимодальных задач: Сама GLM-5 работает только с текстом. Если нужно понимание изображений, выбирайте визуальные модели вроде GLM-4.6V.
- Экстремально низкой задержки: Скорость генерации MoE-модели на 744 млрд параметров ниже, чем у маленьких моделей. Для высокочастотных задач с мгновенным откликом лучше использовать GLM-4.7-FlashX.
- Сверхдешевой пакетной обработки: Если нужно обработать огромные массивы текста без жестких требований к качеству, DeepSeek V3 или GLM-4.7-FlashX обойдутся дешевле.
Сравнение GLM-5 и GLM-4.7 для выбора
| Критерий сравнения | GLM-5 | GLM-4.7 | Рекомендация |
|---|---|---|---|
| Кол-во параметров | 744B (40B активных) | Не раскрывается | GLM-5 мощнее |
| Рассуждения | AIME 92.7% | ~85% | Для сложных задач — GLM-5 |
| Возможности агентов | HLE w/ Tools 50.4% | ~38% | Для агентов — GLM-5 |
| Навыки кодинга | HumanEval 90% | ~85% | Для разработки — GLM-5 |
| Контроль галлюцинаций | Снижены на 56% | Базовый | Для точности — GLM-5 |
| Цена за входящие | $1.00/M | $0.60/M | При экономии бюджета — GLM-4.7 |
| Цена за исходящие | $3.20/M | $2.20/M | При экономии бюджета — GLM-4.7 |
| Длина контекста | 200K | 128K+ | Для длинных текстов — GLM-5 |
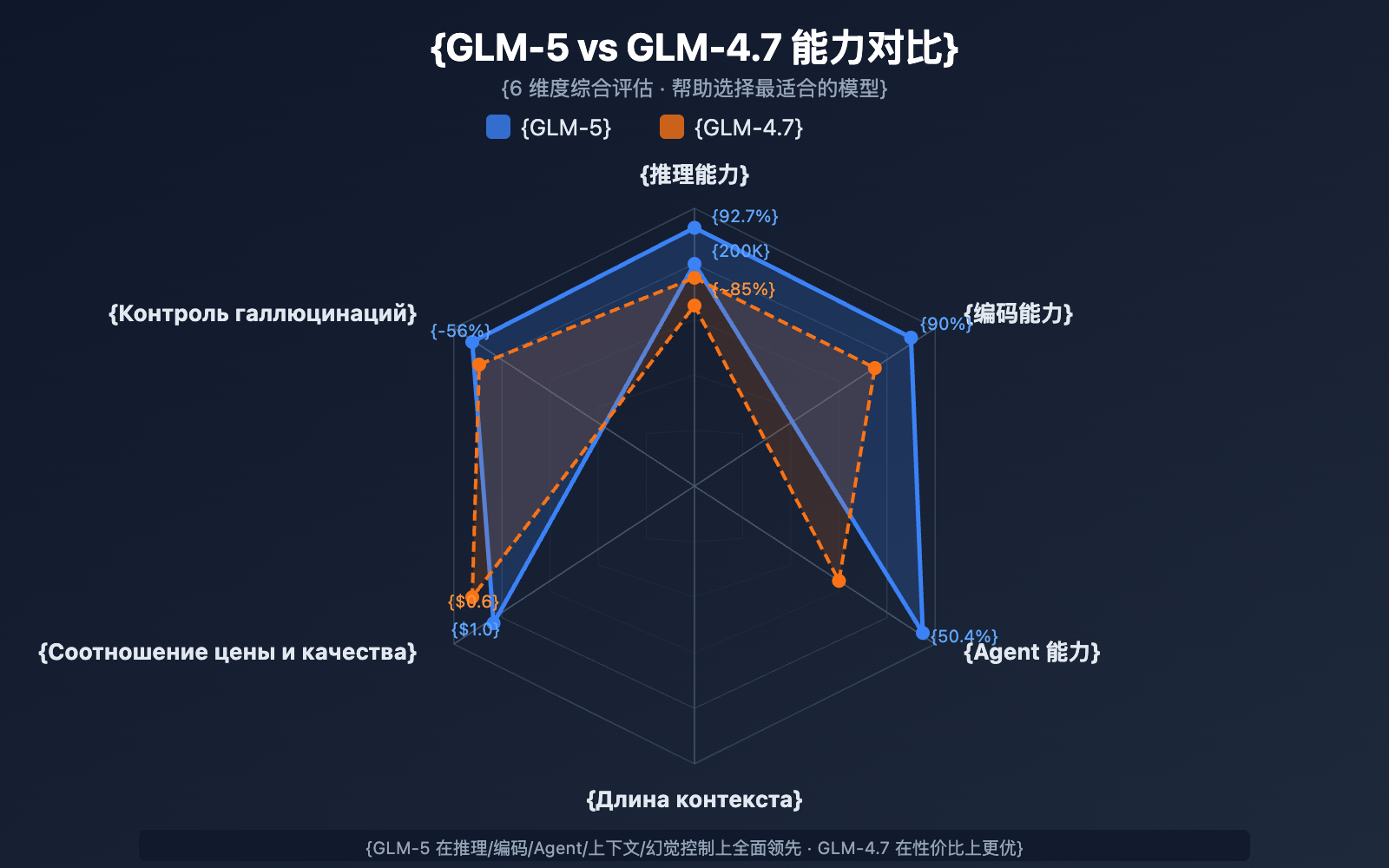
💡 Совет по выбору: Если вашему проекту нужны топовые способности к рассуждению, ворклоу агентов или обработка сверхдлинного контекста, GLM-5 будет лучшим выбором. Если бюджет ограничен, а задачи имеют умеренную сложность, GLM-4.7 остается отличным вариантом по соотношению цена/качество. Обе модели можно вызвать через платформу APIYI (apiyi.com), что позволяет легко переключаться между ними для тестов.
GLM-5 API: Часто задаваемые вопросы
Q1: В чем разница между GLM-5 и GLM-5-Code?
GLM-5 — это универсальная флагманская модель (вход $1.00/M, выход $3.20/M), которая отлично справляется с любыми текстовыми задачами. GLM-5-Code — это специализированная версия с усиленными возможностями для работы с кодом (вход $1.20/M, выход $5.00/M). Она прошла дополнительную оптимизацию для генерации кода, отладки и инженерных задач. Если ваш основной сценарий — разработка ПО, стоит попробовать GLM-5-Code. Обе модели поддерживают вызов через единый интерфейс, совместимый с OpenAI.
Q2: Влияет ли режим Thinking на скорость вывода GLM-5?
Да, влияет. В режиме Thinking модель GLM-5 сначала выстраивает внутреннюю цепочку рассуждений, а только потом выдает итоговый ответ, поэтому задержка до появления первого токена (TTFT) увеличивается. Для простых вопросов рекомендуем отключать режим Thinking, чтобы получить более быстрый отклик. Для сложных математических, логических задач и программирования лучше его включить: хоть это и медленнее, точность ответов заметно возрастает.
Q3: Что нужно изменить в коде при переходе с GPT-4 или Claude на GLM-5?
Миграция проходит очень просто, достаточно изменить два параметра:
- Замените
base_urlна адрес интерфейса APIYI:https://api.apiyi.com/v1 - Измените параметр
modelна"glm-5"
GLM-5 полностью совместима с форматом интерфейса chat.completions из OpenAI SDK, включая роли system/user/assistant, потоковую передачу (streaming), вызов функций (Function Calling) и прочее. Использование единой платформы-посредника API позволяет переключаться между моделями разных поставщиков с одним и тем же API-ключом, что очень удобно для A/B тестирования.
Q4: Поддерживает ли GLM-5 ввод изображений?
Нет, не поддерживает. Сама по себе GLM-5 — это чисто текстовая модель, она не принимает на вход изображения, аудио или видео. Если вам нужны возможности компьютерного зрения, вы можете воспользоваться визуальными моделями от Zhipu, такими как GLM-4.6V или GLM-4.5V.
Q5: Как использовать функцию кэширования контекста в GLM-5?
GLM-5 поддерживает кэширование контекста (Context Caching). Стоимость кэшированного ввода составляет всего $0.20/M, что в 5 раз дешевле обычного ввода. В длинных диалогах или сценариях, где нужно многократно обрабатывать один и тот же префикс, кэширование позволяет существенно снизить расходы. Хранение кэша на данный момент временно бесплатно. В многораундовых диалогах система автоматически распознает и кэширует повторяющиеся префиксы контекста.
Q6: Какова максимальная длина выходного текста у GLM-5?
GLM-5 поддерживает максимальную длину вывода до 128 000 токенов. Для большинства задач стандартных 4096 токенов вполне достаточно. Если вам нужно сгенерировать длинный текст (например, полную техническую документацию или большой блок кода), вы можете настроить это через параметр max_tokens. Имейте в виду: чем длиннее вывод, тем больше расход токенов и время ожидания.
Лучшие практики использования GLM-5 API
При работе с GLM-5 на практике следующие советы помогут вам добиться лучших результатов:
Оптимизация системного промпта (System Prompt)
GLM-5 очень чувствительна к качеству системного промпта. Грамотное проектирование роли может значительно повысить качество ответов:
# Рекомендуется: четкое определение роли + требования к формату вывода
messages = [
{
"role": "system",
"content": """Ты — опытный архитектор распределенных систем.
Пожалуйста, соблюдай следующие правила:
1. Ответ должен быть структурированным, используй формат Markdown.
2. Предлагай конкретные технические решения, а не общие фразы.
3. Если речь идет о коде, предоставь рабочий пример.
4. В соответствующих местах указывай на потенциальные риски и важные нюансы."""
},
{
"role": "user",
"content": "Спроектируй систему очередей сообщений, поддерживающую миллионы одновременных соединений."
}
]
Руководство по настройке temperature
Разные задачи по-разному реагируют на параметр temperature. Вот проверенные рекомендации:
- temperature 0.1-0.3: Генерация кода, извлечение данных, преобразование форматов — задачи, где важна точность.
- temperature 0.5-0.7: Техническая документация, ответы на вопросы, саммари — задачи, где нужен баланс между стабильностью и гибкостью изложения.
- temperature 0.8-1.0: Креативное письмо, мозговой штурм — задачи, требующие разнообразия.
- temperature 1.0 (режим Thinking): Математические рассуждения, сложное программирование и другие задачи на глубокую логику.
Советы по работе с длинным контекстом
GLM-5 поддерживает контекстное окно в 200K токенов, но при использовании стоит учитывать:
- Важное — в начало: Размещайте самую критичную информацию в начале промпта, а не в конце.
- Обработка по частям: Для документов объемом более 100K токенов рекомендуется обрабатывать их частями, а затем объединять результат для большей стабильности.
- Используйте кэш: В длинных диалогах одинаковые префиксы кэшируются автоматически, и цена за такой ввод составит всего $0.20/M.
- Контролируйте длину вывода: При подаче длинного контекста на вход не забывайте выставлять адекватный
max_tokens, чтобы избежать лишних трат на слишком длинные ответы.
Справочник по локальному развертыванию GLM-5
Если вам необходимо развернуть GLM-5 на собственной инфраструктуре, ниже приведены основные способы:
| Метод развертывания | Рекомендуемое железо | Точность | Особенности |
|---|---|---|---|
| vLLM | 8x A100/H100 | FP8 | Популярный фреймворк, поддержка спекулятивного декодирования |
| SGLang | 8x H100/B200 | FP8 | Высокопроизводительный инференс, оптимизация под Blackwell GPU |
| xLLM | Huawei Ascend NPU | BF16/FP8 | Адаптация под китайские вычислительные мощности |
| KTransformers | Потребительские GPU | Квантование | Ускорение инференса на обычных видеокартах |
| Ollama | Потребительское железо | Квантование | Самый простой способ запустить модель локально |
GLM-5 доступна в двух форматах весов: полная точность BF16 и квантованная версия FP8. Их можно скачать на HuggingFace (huggingface.co/zai-org/GLM-5) или ModelScope. Версия FP8 значительно снижает требования к видеопамяти, сохраняя при этом практически всю исходную производительность.
Ключевые параметры конфигурации для развертывания GLM-5:
- Тензорный параллелизм: 8-канальный (tensor-parallel-size 8)
- Использование видеопамяти: рекомендуется установить значение 0.85
- Парсер вызова инструментов: glm47
- Парсер логических рассуждений: glm45
- Спекулятивное декодирование: поддерживаются методы MTP и EAGLE
Для большинства разработчиков использование модели через API — это самый эффективный путь. Он избавляет от затрат на развертывание и обслуживание, позволяя сосредоточиться на разработке приложения. Если же вам необходимо приватное развертывание, обратитесь к официальной документации:
github.com/zai-org/GLM-5
Итоги по вызову API GLM-5
Краткий обзор ключевых возможностей GLM-5
| Характеристика | Показатели GLM-5 | Сферы применения |
|---|---|---|
| Рассуждения | AIME 92.7%, MATH 88% | Математические доказательства, научные расчеты, логический анализ |
| Код | HumanEval 90%, SWE-bench 77.8% | Генерация кода, исправление багов, проектирование архитектуры |
| Агенты | HLE w/ Tools 50.4% | Вызов инструментов, планирование задач, автономное выполнение |
| Знания | MMLU 85%, GPQA 68.2% | Ответы на вопросы по дисциплинам, техподдержка, извлечение знаний |
| Инструкции | IFEval 88% | Форматированный вывод, структурированная генерация, следование правилам |
| Точность | Галлюцинации снижены на 56% | Саммаризация документов, фактчекинг, извлечение информации |
Ценность GLM-5 для Open Source сообщества
GLM-5 распространяется под лицензией Apache-2.0, что означает:
- Коммерческая свобода: компании могут бесплатно использовать, изменять и распространять модель без лицензионных отчислений.
- Тонкая настройка (Fine-tuning): на базе GLM-5 можно проводить дообучение на специфических данных для создания отраслевых решений.
- Приватное развертывание: конфиденциальные данные не покидают внутреннюю сеть, что соответствует требованиям безопасности в финансах, медицине и госсекторе.
- Экосистема сообщества: на HuggingFace уже доступно более 11 квантованных вариантов и более 7 версий с тонкой настройкой, и экосистема продолжает расти.
GLM-5, как флагманская модель от Zhipu AI, задает новую планку в области открытых больших языковых моделей:
- Архитектура MoE 744B: система из 256 экспертов, где при каждом проходе активируется 40 млрд параметров. Это обеспечивает отличный баланс между мощностью модели и эффективностью инференса.
- Сильнейший Open Source агент: показатель HLE w/ Tools 50.4% превосходит Claude Opus, модель специально оптимизирована для длительных рабочих процессов агентов.
- Обучение на отечественном железе: модель обучена на кластере из 100 000 чипов Huawei Ascend, что доказывает возможность создания передовых моделей на базе китайских вычислительных стеков.
- Высокая экономичность: стоимость $1 за 1 млн токенов на входе и $3.2 за 1 млн на выходе — это значительно дешевле закрытых моделей аналогичного уровня.
- Контекст 200K: поддержка обработки целых репозиториев кода и объемной технической документации за один раз, максимальный объем вывода — 128K токенов.
- Низкий уровень галлюцинаций (56%): асинхронное обучение с подкреплением (Slime RL) существенно повысило фактическую точность ответов.
Рекомендуем быстро протестировать все возможности GLM-5 через APIYI (apiyi.com). Цены на платформе соответствуют официальным, а при пополнении баланса действуют бонусы, позволяющие получить выгоду около 20%.
Материал подготовлен технической командой APIYI Team. Больше руководств по использованию ИИ-моделей ищите в справочном центре APIYI на apiyi.com.