Примечание автора: Глубокое сравнение Kimi K2.5 и Claude Opus 4.5 в таких аспектах, как программирование, логические рассуждения и возможности агентов (Agent). Анализируем 9-кратную разницу в цене и соотношение цены и качества, чтобы помочь вам сделать оптимальный выбор.
Как на самом деле Kimi K2.5 показывает себя на фоне Claude Opus 4.5? Это один из самых актуальных вопросов выбора технологий для разработчиков в 2026 году. В этой статье мы проведем подробный анализ по четырем направлениям: бенчмарки, реальные возможности, стоимость и сценарии использования, а также дадим четкие рекомендации.
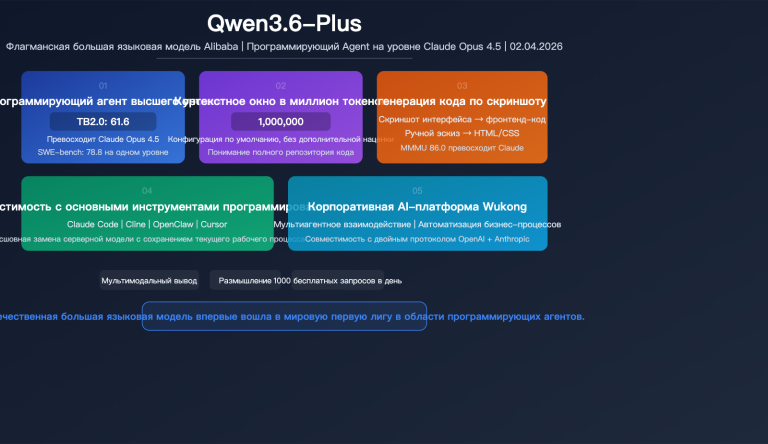
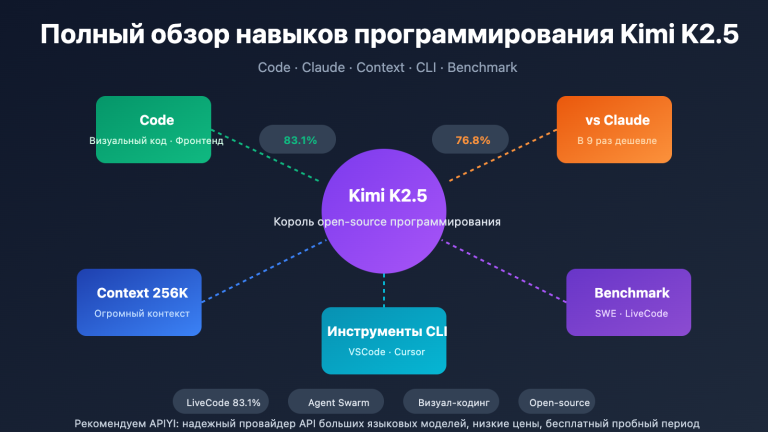
Главный вывод: Claude Opus 4.5 немного превосходит конкурента в качестве кода (SWE-Bench 80.9% против 76.8%), но Kimi K2.5 сильнее в автоматизации агентов, визуальном программировании и математике, при этом его стоимость составляет всего 1/9 от цены Claude.

Основное сравнение Kimi K2.5 vs Claude Opus 4.5
| Параметр сравнения | Kimi K2.5 | Claude Opus 4.5 | Победитель |
|---|---|---|---|
| SWE-Bench Verified | 76.8% | 80.9% | Claude +4.1% |
| AIME 2025 (Математика) | 96.1% | 92.8% | Kimi +3.3% |
| LiveCodeBench v6 | 83.1% | 64.0% | Kimi +19.1% |
| Взаимодействие с веб (BrowseComp) | 60.2% | 24.1% | Kimi +36.1% |
| Agent Swarm | ✅ 100 параллельно | ❌ Нет поддержки | Kimi |
| Визуальное кодинг | ✅ Нативная поддержка | ❌ Только текст | Kimi |
| Контекстное окно | 256K | 200K | Kimi +28% |
| Цена API | $0.60/$3.00 | $5.00/$25.00 | Kimi дешевле в ~9 раз |
Краткий итог
- Нужно максимальное качество кода → выбирайте Claude Opus 4.5
- Нужна выгода и многофункциональность → выбирайте Kimi K2.5
- Нужна автоматизация агентов → однозначно Kimi K2.5
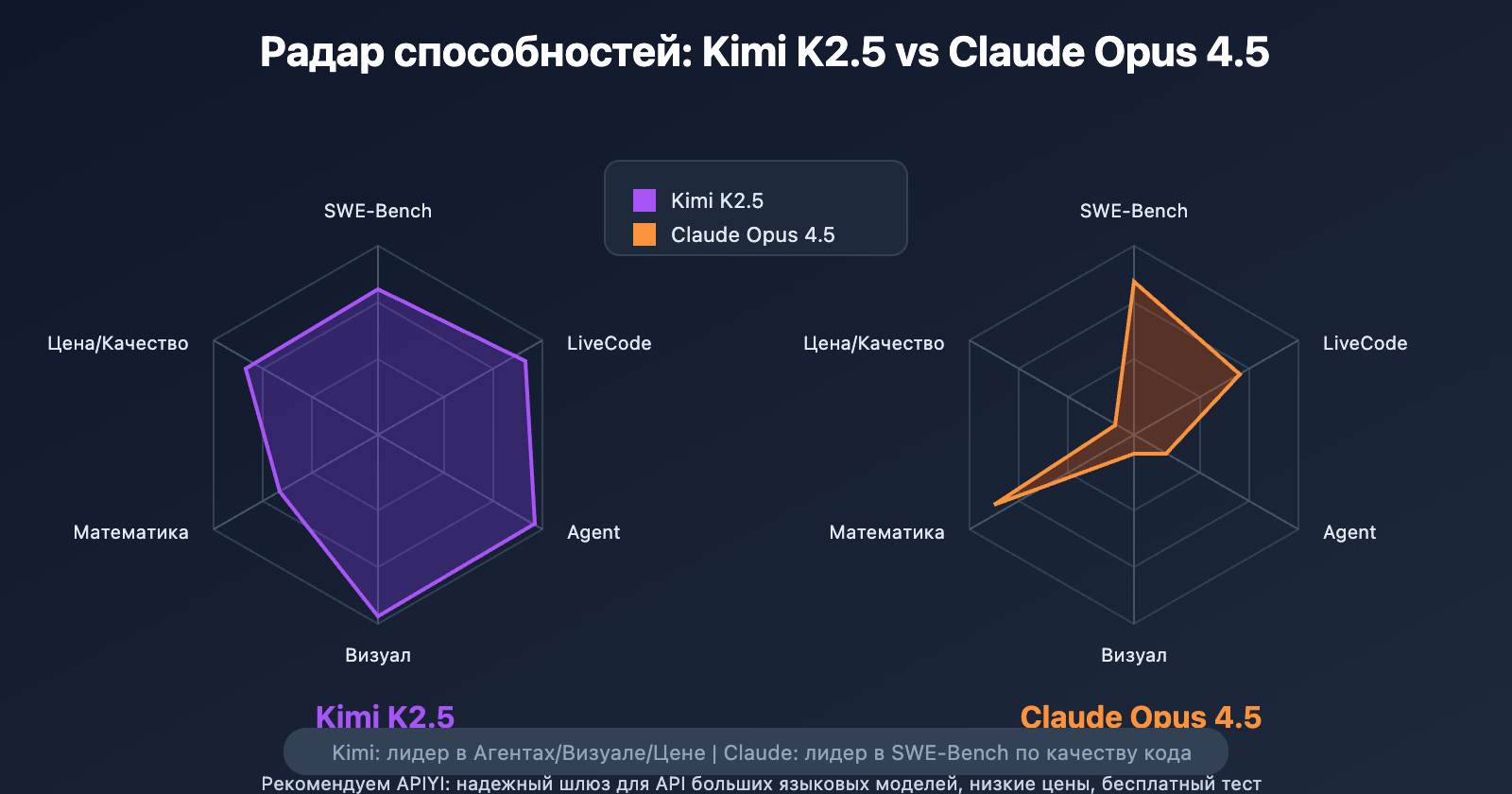
Подробный разбор способностей Kimi K2.5 и Claude Opus 4.5 в программировании
Исправление кода (SWE-Bench)
SWE-Bench Verified — это авторитетный бенчмарк, который измеряет способность модели исправлять реальные баги (issues) в репозиториях на GitHub:
| Модель | SWE-Bench Verified | SWE-Bench Multi | Terminal-Bench |
|---|---|---|---|
| Claude Opus 4.5 | 80.9% | — | 59.3% |
| Kimi K2.5 | 76.8% | 73.0% | 50.8% |
| GPT-5.2 | 80.0% | — | 54.0% |
Claude Opus 4.5 лидирует в SWE-Bench с результатом 80.9%. Это значит, что при исправлении сложных багов Claude чаще добивается успеха, а цикл отладки с ней будет короче.
Где Claude проявляет себя лучше всего:
- Ревью кода критически важных систем
- Сложные задачи по рефакторингу
- Написание продакшн-кода, где критически важна низкая вероятность ошибки
Программирование в реальном времени (LiveCodeBench)
Тест LiveCodeBench v6 оценивает навыки написания кода в интерактивной среде:
| Модель | LiveCodeBench v6 | Примечание |
|---|---|---|
| GPT-5.2 | 87.0% | Самая мощная |
| Kimi K2.5 | 83.1% | Лучшая среди открытых моделей |
| Claude Opus 4.5 | 64.0% | Заметно отстает |
В сценариях живого диалога по программированию Kimi K2.5 значительно опережает Claude (83.1% против 64.0%). Это говорит о том, что Kimi лучше справляется с быстрыми ответами и итерациями в процессе интерактивной разработки.
Фронтенд и визуальное программирование
| Способность | Kimi K2.5 | Claude Opus 4.5 |
|---|---|---|
| UI-дизайн в код | ✅ Нативная поддержка | ❌ Не поддерживается |
| Видео в код | ✅ Поддерживается | ❌ Не поддерживается |
| Генерация сложной анимации | ✅ Сильно | ⚠️ Средне |
Kimi K2.5 обладает способностями к Vibe Coding, которых у Claude пока совсем нет — это генерация полноценного фронтенд-кода напрямую из макетов Figma или видео с записью экрана.
Сравнение способностей Kimi K2.5 и Claude Opus 4.5 к рассуждению
Математическое мышление (AIME/GPQA)
| Бенчмарк | Kimi K2.5 | Claude Opus 4.5 | GPT-5.2 |
|---|---|---|---|
| AIME 2025 | 96.1% | 92.8% | 100% |
| GPQA-Diamond | 87.6% | — | 92.4% |
| HMMT 2025 | 95.4% | — | 93.3% |
В задачах на логику уровня математических олимпиад Kimi K2.5 (96.1%) обошла Claude Opus 4.5 (92.8%), показав более сильное логическое мышление.
Рассуждения с использованием инструментов
Когда модель может использовать поиск и инструменты для выполнения кода:
| Модель | Без инструментов | С инструментами | Прирост |
|---|---|---|---|
| Kimi K2.5 | 31.5% | 51.8% | +20.1% |
| Claude Opus 4.5 | — | — | +12.4% |
| GPT-5.2 | — | — | +11.0% |
Прирост производительности Kimi K2.5 при использовании инструментов (+20.1%) намного выше, чем у Claude (+12.4%). Этого удалось достичь благодаря архитектуре Agent Swarm, которая оптимизирует вызовы внешних инструментов.
Kimi K2.5 vs Claude Opus 4.5 Agent 能力
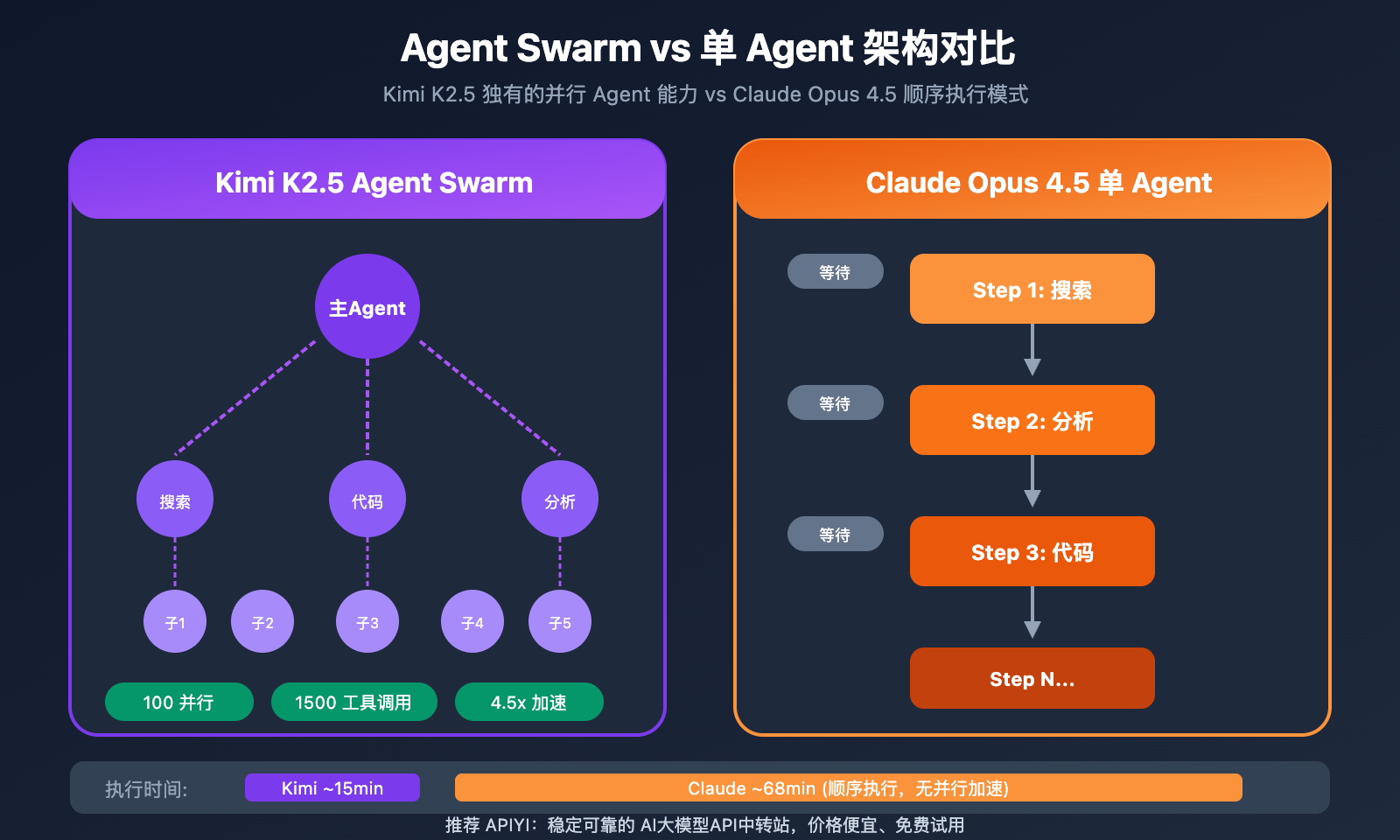
Agent Swarm:Kimi K2.5 独有优势
| 能力 | Kimi K2.5 | Claude Opus 4.5 |
|---|---|---|
| 并行 Agent | 最多 100 个 | 单 Agent |
| 工具调用 | 最多 1500 次/任务 | 受限 |
| 执行效率 | 4.5x 加速 | 基准 |
| 自动任务拆分 | ✅ 无需预设 | ❌ 需手动编排 |
Kimi K2.5 的 Agent Swarm 是其最大差异化优势:
- 自动将复杂任务拆分为并行子任务
- 动态实例化专业子 Agent
- 无需预定义角色或工作流
- 复杂研究任务完成时间缩短至 1/4.5
实际案例:一个需要数小时的跨领域市场调研任务,Kimi K2.5 可以在十几分钟内完成,而 Claude 需要顺序执行多轮对话。
Kimi K2.5 vs Claude Opus 4.5 价格成本对比
API 定价对比
| 模型 | 输入价格 | 输出价格 | 相对成本 |
|---|---|---|---|
| Kimi K2.5 | $0.60/M | $3.00/M | 基准 |
| Claude Opus 4.5 | $5.00/M | $25.00/M | ~9x |
| GPT-5.2 | $0.90/M | $3.80/M | ~1.4x |
年度成本估算 (100 万请求,5K 输出/请求)
| 模型 | 年成本 | 对比 |
|---|---|---|
| Kimi K2.5 | ~$13,800 | 基准 |
| GPT-5.2 | ~$56,500 | 4.1x |
| Claude Opus 4.5 | ~$150,000 | 10.9x |
Claude Opus 4.5 的年成本是 Kimi K2.5 的 10 倍以上。对于预算有限的团队,这个差距足以影响技术选型。
成本效益分析
| 场景 | 推荐模型 | 原因 |
|---|---|---|
| 初创公司 | Kimi K2.5 | 成本仅 $13,800/年,性能够用 |
| 大型企业关键系统 | Claude Opus 4.5 | 代码质量优先,成本可接受 |
| 高频 Agent 任务 | Kimi K2.5 | Agent Swarm + 低成本 |
| 前端开发 | Kimi K2.5 | 视觉编程独家优势 |
成本建议:大多数场景下,Kimi K2.5 的 76.8% SWE-Bench 成绩已经足够优秀,4% 的差距不值得 9 倍的溢价。可通过 APIYI apiyi.com 同时接入两个模型,关键任务用 Claude,日常开发用 Kimi。
Kimi K2.5 vs Claude Opus 4.5 选择指南
选择 Kimi K2.5 的场景
| 场景 | 原因 |
|---|---|
| 预算敏感项目 | 成本仅为 Claude 的 1/9 |
| Agent 自动化工作流 | Agent Swarm 独家能力 |
| 前端开发、UI 还原 | 视觉编程原生支持 |
| 数学推理任务 | AIME 96.1% > Claude 92.8% |
| 需要超长上下文 | 256K > 200K |
| 高频 API 调用 | 成本效益更高 |
选择 Claude Opus 4.5 的场景
| 场景 | 原因 |
|---|---|
| 关键系统代码审查 | SWE-Bench 80.9% 最高 |
| 复杂后端重构 | 代码质量更稳定 |
| 企业级合规要求 | Anthropic 安全声誉 |
| 对错误零容忍 | 调试周期更短 |
快速接入示例
通过 APIYI 同时接入两个模型
import openai
# 创建客户端 - 指向 APIYI
client = openai.OpenAI(
api_key="YOUR_API_KEY", # 在 apiyi.com 获取
base_url="https://vip.apiyi.com/v1"
)
# 日常开发用 Kimi K2.5 (高性价比)
response_kimi = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "实现一个 React 购物车组件"}]
)
# 关键代码审查用 Claude (高质量)
response_claude = client.chat.completions.create(
model="claude-opus-4-5-20251101",
messages=[{"role": "user", "content": "审查这段支付接口代码的安全性..."}]
)
接入建议:通过 APIYI apiyi.com 获取免费测试额度,用同一个 API Key 同时调用 Kimi K2.5 和 Claude Opus 4.5,按需切换,灵活控制成本。
常见问题
Q1: Kimi K2.5 对比 Claude Opus 4.5,编程能力差多少?
在 SWE-Bench Verified 基准上,Claude (80.9%) 比 Kimi (76.8%) 高 4.1%。但在 LiveCodeBench 实时交互编程中,Kimi (83.1%) 大幅领先 Claude (64.0%)。结论:Claude 更适合复杂代码修复,Kimi 更适合快速迭代开发。
Q2: 9 倍的价格差距,Claude Opus 4.5 值得吗?
取决于场景。对于年薪 $200K+ 的工程师团队,Claude 4% 更高的代码质量可能减少调试时间,ROI 为正。但对于预算敏感的初创公司或高频 API 调用场景,Kimi K2.5 的性价比更优。建议:关键代码用 Claude,日常开发用 Kimi。
Q3: 如何同时使用 Kimi K2.5 和 Claude Opus 4.5?
推荐通过 APIYI apiyi.com 统一接入:
- 注册获取一个 API Key
- 设置 base_url 为
https://vip.apiyi.com/v1 - 通过 model 参数切换:
kimi-k2.5或claude-opus-4-5-20251101 - 根据任务类型动态选择,灵活控制成本
Итоги
Основные выводы сравнения Kimi K2.5 и Claude Opus 4.5:
- Качество кода: Claude слегка лидирует (80.9% против 76.8% на SWE-Bench), но разрыв составляет всего 4%.
- Соотношение цены и качества: Kimi K2.5 обходится в 9 раз дешевле, чем Claude, что делает его более выгодным для большинства повседневных сценариев.
- Уникальные возможности: Kimi предлагает функции, которых нет у Claude, например, Agent Swarm и визуальное программирование.
- Что выбрать: Для ежедневной разработки отлично подойдет Kimi K2.5, а для критически важного код-ревью лучше оставить Claude Opus 4.5.
Обе модели уже доступны на APIYI (apiyi.com). Рекомендуем зайти на платформу, получить бесплатные лимиты и протестировать их на своих задачах, чтобы сделать окончательный выбор.
Источники
⚠️ Примечание по формату ссылок: Все внешние ссылки указаны в формате
Название: domain.com. Их удобно копировать, но они не кликабельны — это сделано для сохранения SEO-веса страницы.
-
Официальный технический отчет Kimi K2.5: Полные данные бенчмарков
- Ссылка:
kimi.com/blog/kimi-k2-5.html - Описание: Официальные результаты тестов SWE-Bench, AIME и других.
- Ссылка:
-
Карточка модели Claude Opus 4.5: Данные о производительности от Anthropic
- Ссылка:
anthropic.com/claude - Описание: Официальные показатели производительности семейства Claude.
- Ссылка:
-
AI Model Benchmarks 2026: Независимая оценка
- Ссылка:
artificialanalysis.ai - Описание: Сравнение различных моделей от сторонних экспертов.
- Ссылка:
-
Глубокий разбор Four Giants Comparison: Детальный анализ сценариев использования
- Ссылка:
medium.com(ищите по запросу "Kimi K2.5 vs Claude Opus 4.5") - Описание: Реальный опыт использования и анализ затрат.
- Ссылка:
Автор: Техническая команда
Обсуждение: Делитесь своим опытом выбора моделей в комментариях. Больше сравнений и тестов ищите в техническом сообществе APIYI (apiyi.com).