Заметка автора: Глубокое сравнение двух флагманских моделей с открытым исходным кодом — MiniMax-M2.5 и GLM-5, выпущенных в феврале 2026 года. Разбираем их сильные стороны по 6 измерениям: кодинг, рассуждение, интеллектуальные агенты, скорость, цена и архитектура.
11–12 февраля 2026 года две ведущие китайские ИИ-компании практически одновременно представили свои флагманские модели: 智谱 GLM-5 (744 млрд параметров) и MiniMax-M2.5 (230 млрд параметров). Обе используют архитектуру MoE и распространяются по лицензии MIT, но при этом они получили четкое функциональное разделение.
Ключевая ценность: Прочитав этот разбор, вы поймете, почему GLM-5 лидирует в логических рассуждениях и достоверности знаний, а MiniMax-M2.5 нет равных в написании кода и вызове инструментов для агентов. Это поможет вам выбрать идеальную модель под конкретные задачи.

Обзор ключевых различий между MiniMax-M2.5 и GLM-5
| Параметр сравнения | MiniMax-M2.5 | GLM-5 | Лидер |
|---|---|---|---|
| Кодинг (SWE-Bench) | 80.2% | 77.8% | M2.5 (+2.4%) |
| Математика (AIME) | — | 92.7% | GLM-5 |
| Вызов инструментов (BFCL) | 76.8% | — | M2.5 |
| Поиск (BrowseComp) | 76.3% | 75.9% | На одном уровне |
| Цена за вывод / 1M токенов | $1.20 | $3.20 | M2.5 дешевле в 2.7 раза |
| Скорость вывода | 50-100 TPS | ~66 TPS | M2.5 Lightning быстрее |
| Общее кол-во параметров | 230B | 744B | GLM-5 больше |
| Активные параметры | 10B | 40B | M2.5 легче |
Сильные стороны MiniMax-M2.5: Кодинг и AI-агенты
MiniMax-M2.5 демонстрирует впечатляющие результаты в тестах на программирование. Результат 80.2% в SWE-Bench Verified не только опережает GLM-5 (77.8%), но и обходит GPT-5.2 (80.0%), лишь немного уступая Claude Opus 4.6 (80.8%). В тесте Multi-SWE-Bench, где требуется работа с несколькими файлами, модель набрала 51.3%, а в многоходовых диалогах с вызовом инструментов (BFCL Multi-Turn) — внушительные 76.8%.
Благодаря архитектуре MoE (Mixture of Experts), M2.5 активирует всего 10 млрд параметров (4.3% от общего объема в 230B). Это делает её самым «легким» решением среди моделей первого эшелона (Tier 1) и обеспечивает высочайшую эффективность инференса. Версия Lightning выдает до 100 токенов в секунду (TPS), что делает её одной из самых быстрых передовых моделей на сегодняшний день.
Сильные стороны GLM-5: Логика и надежность знаний
GLM-5 удерживает лидерство в задачах на логическое мышление и эрудицию. В математическом тесте AIME 2026 модель набрала 92.7%, в научном тесте GPQA-Diamond — 86.0%, а в сложнейшем Humanity's Last Exam (с использованием инструментов) — 50.4 балла, обойдя Claude Opus 4.5 (43.4 балла).
Главная фишка GLM-5 — это надежность знаний. В тестах на галлюцинации AA-Omniscience модель показала лучший результат в индустрии, улучшив показатели предыдущего поколения на 35 баллов. Если вам нужен высокоточный фактический контент — например, для написания технической документации, помощи в научных исследованиях или построения баз знаний, — GLM-5 будет более надежным выбором. Кроме того, база знаний модели подкреплена огромным объемом обучающих данных (28.5 триллионов токенов) и внушительными 744 млрд параметров.
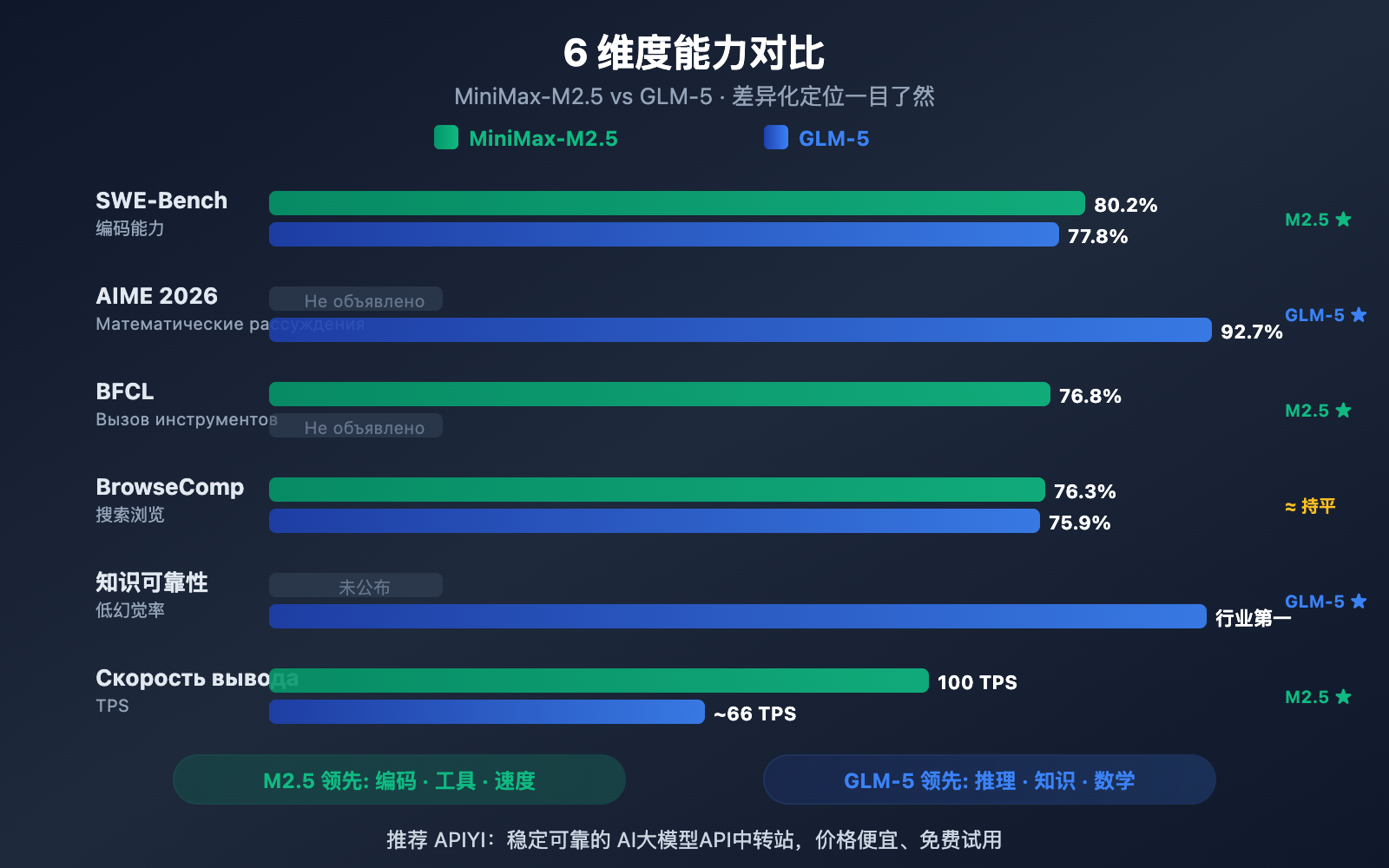
Сравнение навыков программирования: MiniMax-M2.5 против GLM-5
Навыки написания кода — один из самых критичных параметров, на которые ориентируются разработчики при выборе ИИ-модели. В этом аспекте между двумя моделями наблюдается заметный разрыв.
| Бенчмарк кодинга | MiniMax-M2.5 | GLM-5 | Claude Opus 4.6 (для справки) |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 77.8% | 80.8% |
| Multi-SWE-Bench | 51.3% | — | 50.3% |
| SWE-Bench Multilingual | — | 73.3% | 77.5% |
| Terminal-Bench 2.0 | — | 56.2% | 65.4% |
| BFCL Multi-Turn | 76.8% | — | 63.3% |
В тесте SWE-Bench Verified модель MiniMax-M2.5 опережает GLM-5 на 2,4 процентных пункта (80,2% против 77,8%). Для бенчмарков программирования это существенная разница: уровень M2.5 сопоставим с Opus 4.6, в то время как GLM-5 ближе к показателям Gemini 3 Pro.
GLM-5 предоставила данные по мультиязычному кодингу (SWE-Bench Multilingual — 73,3%) и работе в терминальной среде (Terminal-Bench — 56,2%), демонстрируя свои возможности с разных сторон. Однако в самом важном тесте — SWE-Bench Verified — преимущество M2.5 очевидно.
M2.5 также выделяется эффективностью: на выполнение одной задачи в SWE-Bench уходит всего 22,8 минуты, что на 37% быстрее, чем у предыдущего поколения M2.1. Это заслуга уникального стиля кодинга «Spec-writing» — модель сначала выполняет декомпозицию архитектуры, а затем эффективно приступает к реализации, что сокращает количество бесполезных циклов проб и ошибок.
🎯 Совет по выбору: Если ваша основная задача — помощь в написании кода (исправление багов, код-ревью, реализация фич), MiniMax-M2.5 будет лучшим выбором. Через платформу APIYI (apiyi.com) можно подключить обе модели и сравнить их в реальных рабочих условиях.
Сравнение способностей к рассуждению: MiniMax-M2.5 против GLM-5
Логическое рассуждение (reasoning) — это «конек» GLM-5, особенно когда речь заходит о математике и научных вычислениях.
| Бенчмарк рассуждения | MiniMax-M2.5 | GLM-5 | Описание |
|---|---|---|---|
| AIME 2026 | — | 92.7% | Математика олимпиадного уровня |
| GPQA-Diamond | — | 86.0% | Научные рассуждения уровня PhD |
| Humanity's Last Exam (с инструментами) | — | 50.4 | Выше, чем 43.4 у Opus 4.5 |
| HMMT Nov. 2025 | — | 96.9% | Близко к 97.1% у GPT-5.2 |
| τ²-Bench | — | 89.7% | Рассуждения в сфере телекоммуникаций |
| Надежность знаний AA-Omniscience | — | Лидер индустрии | Минимальный уровень галлюцинаций |
GLM-5 использует новый метод обучения под названием SLIME (инфраструктура асинхронного обучения с подкреплением), что значительно повысило эффективность этапа post-training. Благодаря этому GLM-5 совершила качественный скачок в задачах на логику:
- Результат AIME 2026 составил 92,7%, что почти достигает уровня Claude Opus 4.5 (93,3%) и намного превосходит показатели эпохи GLM-4.5.
- GPQA-Diamond 86,0% — научное мышление уровня доктора наук, вплотную приближающееся к Opus 4.5 (87,0%).
- Humanity's Last Exam 50,4 балла (с использованием инструментов) — это выше, чем у Opus 4.5 (43,4) и GPT-5.2 (45,5).
Самая примечательная черта GLM-5 — достоверность знаний. В тесте на галлюцинации AA-Omniscience модель прибавила 35 баллов по сравнению с предшественником, став лидером индустрии. Это значит, что GLM-5 гораздо реже «выдумывает» факты, что критически важно для сценариев, требующих высокой точности информации.
Данные по чистому рассуждению для MiniMax-M2.5 публикуются реже, так как обучение этой модели с подкреплением (RL) сфокусировано на кодинге и сценариях использования ИИ-агентов. Фреймворк Forge RL в M2.5 нацелен на декомпозицию задач и оптимизацию вызова инструментов в более чем 200 тысячах реальных сред, а не на академическое решение задач.
Итог сравнения: Если вам нужны сложные математические вычисления, научный анализ или максимально достоверные ответы на вопросы, GLM-5 выглядит предпочтительнее. Рекомендуем протестировать обе модели на ваших специфических задачах через APIYI (apiyi.com).
MiniMax-M2.5 против GLM-5: возможности агентов и веб-поиска

| Бенчмарк (Agent) | MiniMax-M2.5 | GLM-5 | Лидер |
|---|---|---|---|
| BFCL Multi-Turn | 76.8% | — | M2.5 (вызов инструментов) |
| BrowseComp (с контекстом) | 76.3% | 75.9% | Примерно на одном уровне |
| MCP Atlas | — | 67.8% | GLM-5 (координация инструментов) |
| Vending Bench 2 | — | $4,432 | GLM-5 (долгосрочное планирование) |
| τ²-Bench | — | 89.7% | GLM-5 (отраслевые рассуждения) |
Обе модели демонстрируют четкое различие в своих способностях в качестве агентов:
MiniMax-M2.5 хорош как «исполнительный» агент: он отлично справляется со сценариями, требующими частого вызова инструментов, быстрой итерации и эффективного выполнения. Результат 76.8% в BFCL означает, что M2.5 способен точно выполнять вызовы функций, операции с файлами и взаимодействие с API, при этом количество лишних циклов при вызове инструментов сократилось на 20% по сравнению с предыдущим поколением. Внутри самой компании MiniMax 80% нового кода уже генерируется этой моделью, и она выполняет 30% повседневных задач.
GLM-5 силен как «стратегический» агент: он имеет преимущество в сценариях, требующих глубоких рассуждений, долгосрочного планирования и принятия сложных решений. Показатель 67.8% в MCP Atlas демонстрирует его способности к масштабной координации инструментов, доход в $4,432 в симуляции Vending Bench 2 подтверждает навыки бизнес-планирования на длительных отрезках времени, а 89.7% в τ²-Bench говорят о глубоком понимании специфических предметных областей.
В плане веб-поиска и браузинга обе модели идут ноздря в ноздрю — 76.3% против 75.9% в BrowseComp, обе являются лидерами в этой области.
🎯 Совет по выбору: Если вам нужны высокочастотные вызовы инструментов и автокодинг — выбирайте M2.5; для сложных решений и долгосрочного планирования лучше подойдет GLM-5. Платформа APIYI (apiyi.com) поддерживает обе модели, так что вы можете гибко переключаться между ними в зависимости от задачи.
Сравнение архитектуры и стоимости MiniMax-M2.5 и GLM-5
| Характеристики и стоимость | MiniMax-M2.5 | GLM-5 |
|---|---|---|
| Общее число параметров | 230B | 744B |
| Активные параметры | 10B | 40B |
| Доля активации | 4.3% | 5.4% |
| Обучающие данные | — | 28.5 трлн токенов |
| Контекстное окно | 205K | 200K |
| Макс. длина вывода | — | 131K |
| Цена за вход (Input) | $0.15/M (Standard) | $1.00/M |
| Цена за выход (Output) | $1.20/M (Standard) | $3.20/M |
| Скорость генерации | 50-100 TPS | ~66 TPS |
| Чипы для обучения | — | Huawei Ascend 910 |
| Фреймворк обучения | Forge RL | SLIME Asynchronous RL |
| Механизм внимания | — | DeepSeek Sparse Attention |
| Лицензия | MIT | MIT |
Анализ преимуществ архитектуры MiniMax-M2.5
Ключевое преимущество архитектуры M2.5 заключается в её «экстремальной легковесности»: при активации всего 10 млрд параметров модель демонстрирует способности к написанию кода на уровне Opus 4.6. Это дает следующие плюсы:
- Крайне низкая стоимость инференса: цена за вывод составляет $1.20/M, что составляет всего 37% от стоимости GLM-5.
- Очень высокая скорость: версия Lightning выдает 100 TPS, что на 52% быстрее, чем ~66 TPS у GLM-5.
- Низкий порог развертывания: 10 млрд активных параметров теоретически позволяют запускать модель даже на потребительских GPU.
Анализ преимуществ архитектуры GLM-5
Общее количество параметров в 744B и 40B активных параметров обеспечивают GLM-5 больший объем знаний и глубину рассуждений:
- Огромный багаж знаний: 28.5 триллионов токенов обучающих данных — это значительно больше, чем у предыдущих поколений.
- Продвинутые логические способности: 40 млрд активных параметров позволяют выстраивать более сложные цепочки рассуждений.
- Независимость в вычислениях: модель полностью обучена на китайских чипах Huawei Ascend, что гарантирует технологическую автономность.
- DeepSeek Sparse Attention: эффективная обработка длинного контекста до 200K токенов.
Совет: Для сценариев с высокой частотой запросов, где важна экономия, M2.5 выглядит явным фаворитом (её цена за вывод — лишь треть от цены GLM-5). Рекомендуем протестировать соотношение цены и качества для ваших конкретных задач через платформу APIYI (apiyi.com).
Быстрое подключение к API MiniMax-M2.5 и GLM-5
Через платформу APIYI можно использовать единый интерфейс для вызова обеих моделей, что очень удобно для быстрого сравнения:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Тест задачи по программированию - M2.5 здесь силен
code_task = "Реализуй на Rust потокобезопасную очередь без блокировок (lock-free concurrent queue)"
m25_result = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": code_task}]
)
# Тест задачи на логику - GLM-5 здесь силен
reason_task = "Докажи, что любое четное число больше 2 можно представить в виде суммы двух простых чисел (ход проверки гипотезы Гольдбаха)"
glm5_result = client.chat.completions.create(
model="glm-5",
messages=[{"role": "user", "content": reason_task}]
)
Совет: Получите бесплатные тестовые баллы на APIYI (apiyi.com) и проверьте обе модели на своих реальных кейсах. Попробуйте M2.5 для кодинга и GLM-5 для сложных рассуждений, чтобы найти оптимальный вариант.
Часто задаваемые вопросы
Q1: В чем сильные стороны MiniMax-M2.5 и GLM-5?
MiniMax-M2.5 хорош в написании кода и вызове инструментов для агентов — результат на SWE-Bench 80.2% (близко к Opus 4.6), а на BFCL — 76.8% (первое место в индустрии). GLM-5 же силен в рассуждениях и надежности знаний — AIME 92.7%, GPQA 86.0%, а уровень галлюцинаций самый низкий в отрасли. Если коротко: для кода выбирайте M2.5, для сложных рассуждений — GLM-5.
Q2: Какая разница в цене между этими моделями?
Цена вывода MiniMax-M2.5 Standard составляет $1.20 за 1 млн токенов, тогда как у GLM-5 — $3.20. То есть M2.5 дешевле примерно в 2.7 раза. Если выбрать скоростную версию M2.5 Lightning ($2.40/M), цена будет ближе к GLM-5, но скорость — выше. При подключении через платформу APIYI (apiyi.com) можно получить дополнительные бонусы при пополнении баланса.
Q3: Как быстро сравнить реальную эффективность двух моделей?
Рекомендуем использовать единый доступ через платформу APIYI (apiyi.com):
- Зарегистрируйтесь, получите API-ключ и бесплатные токены для теста.
- Подготовьте два типа задач: на кодинг и на логические рассуждения.
- Отправьте один и тот же запрос в MiniMax-M2.5 и GLM-5.
- Сравните качество ответов, скорость отклика и расход токенов.
- Благодаря совместимости с OpenAI API, переключаться между моделями можно, просто меняя параметр
model.
Заключение
Основные выводы по сравнению MiniMax-M2.5 и GLM-5:
- Для кода — M2.5: SWE-Bench 80.2% против 77.8% у конкурента, лидерство в вызове инструментов (BFCL 76.8%).
- Для рассуждений — GLM-5: AIME 92.7%, GPQA 86.0%, а в тесте Humanity's Last Exam модель набрала 50.4 балла, обойдя Opus 4.5.
- Надежность знаний за GLM-5: первое место в рейтинге AA-Omniscience по борьбе с галлюцинациями, фактологические ответы заслуживают большего доверия.
- Выгода за M2.5: стоимость вывода составляет всего 37% от цены GLM-5, а версия Lightning работает значительно быстрее.
Обе модели имеют архитектуру MoE и лицензию MIT, но позиционируются по-разному: M2.5 — это «король кодинга и исполнительных агентов», а GLM-5 — «пионер логики и достоверных знаний». Советуем гибко переключаться между ними на платформе APIYI (apiyi.com) в зависимости от ваших задач и пользоваться акциями на пополнение для еще большей экономии.
📚 Справочные материалы
-
Официальный анонс MiniMax M2.5: Ключевые возможности кодинга M2.5 и детали обучения Forge RL
- Ссылка:
minimax.io/news/minimax-m25 - Описание: Полные данные бенчмарков, включая SWE-Bench 80.2%, BFCL 76.8% и другие.
- Ссылка:
-
Официальный релиз GLM-5: Архитектура MoE на 744 млрд параметров и технология обучения SLIME от Zhipu AI
- Ссылка:
docs.z.ai/guides/llm/glm-5 - Описание: Содержит данные бенчмарков рассуждения, такие как AIME 92.7%, GPQA 86.0% и др.
- Ссылка:
-
Независимая оценка Artificial Analysis: Стандартизированные тесты и рейтинги обеих моделей
- Ссылка:
artificialanalysis.ai/models/glm-5 - Описание: Индекс интеллекта (Intelligence Index), реальные замеры скорости, сравнение цен и другие независимые данные.
- Ссылка:
-
Глубокий анализ BuildFastWithAI: Комплексное тестирование GLM-5 и сравнение с конкурентами
- Ссылка:
buildfastwithai.com/blogs/glm-5-released-open-source-model-2026 - Описание: Подробные таблицы сравнения с Opus 4.5 и GPT-5.2.
- Ссылка:
-
MiniMax на HuggingFace: Веса моделей M2.5 с открытым исходным кодом
- Ссылка:
huggingface.co/MiniMaxAI - Описание: Лицензия MIT, поддержка развертывания через vLLM/SGLang.
- Ссылка:
Автор: Команда APIYI
Техническое обсуждение: Делитесь результатами своих тестов и сравнений моделей в комментариях. Больше руководств по подключению API различных ИИ-моделей можно найти в техническом сообществе APIYI на apiyi.com.