Falta apenas um dia para a palestra principal do Google I/O 2026, mas o Google já não consegue mais esconder as novidades. O Gemini 3.2 Flash foi descoberto por desenvolvedores no dia 5 de maio, extraído do aplicativo Gemini para iOS e do Google AI Studio, com a interface "Liquid Glass" (vidro líquido) da versão web também sendo revelada antecipadamente. Os cenários mais impressionantes capturados por testadores internacionais incluem: a geração de 2.200 linhas de código funcional em um único comando, a criação de uma demonstração interativa da área de trabalho do Windows 98 a partir de um simples comando, e um desempenho em tarefas de codificação que simplesmente deixa o seu antecessor, o Gemini 3.1 Pro, para trás.
Este artigo baseia-se em fontes de informação em inglês anteriores a 18 de maio de 2026 e organiza as principais informações vazadas em cinco dimensões: especificações principais, capacidade de codificação, estratégia de preços, sinais de interface e agentes, e impacto para desenvolvedores, oferecendo sugestões de avaliação para migração.
Valor central: Entenda em 3 minutos o verdadeiro poder de combate do Gemini 3.2 Flash, sua natureza disruptiva em termos de preço e se você deve preparar um plano de engenharia antes do lançamento no I/O.

Visão Geral das Informações Principais do Gemini 3.2 Flash
Antes mesmo de o Google publicar qualquer postagem oficial, a versão vazada já havia sido testada exaustivamente por desenvolvedores. A tabela abaixo resume todos os fatos cruciais verificáveis até 18 de maio de 2026, que serão detalhados nas seções seguintes.
| Item de Informação | Detalhes |
|---|---|
| Data da descoberta do vazamento | 5 de maio de 2026, via testes A/B no App Gemini para iOS e Google AI Studio |
| Lançamento oficial previsto | Google I/O 2026, palestra principal de 19 a 20 de maio |
| Posicionamento do modelo | Nível intermediário da série Flash, visando a capacidade de codificação do Gemini 3.1 Pro |
| Preço de entrada | US$ 0,25 / milhão de tokens (igual ao Gemini 3.1 Flash-Lite) |
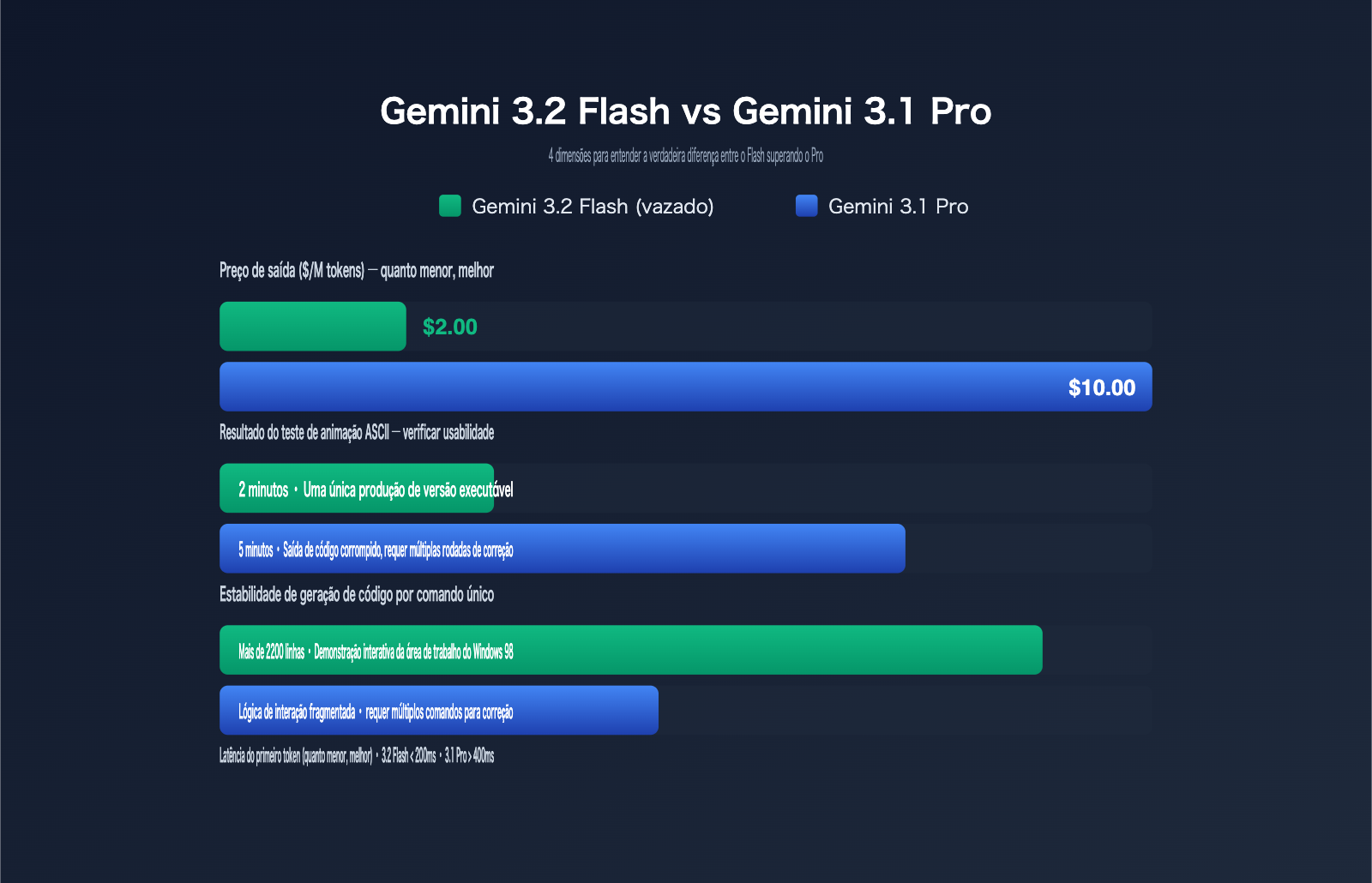
| Preço de saída | US$ 2,00 / milhão de tokens (redução de 33% em relação aos US$ 3,00 do Gemini 3 Flash) |
| Janela de contexto | Estimada em 1M de tokens (não confirmado oficialmente) |
| Corte de conhecimento | Especulado como atualizado até janeiro de 2026 |
| Latência de resposta | Abaixo de 200 ms em alguns comandos |
| Interface de usuário | Interface "Liquid Glass", caixa de entrada em forma de pílula |
| Sinais de novos recursos | Aba "Agents (Beta)" aparecendo no iOS |
Os dois números mais notáveis nesta tabela são: a redução drástica no preço de saída e o fato de que o desempenho não mira na geração anterior do Flash, mas sim no 3.1 Pro. Esses dois pontos determinam o impacto que ele terá no stack tecnológico dos desenvolvedores.
🎯 Sugestão de validação rápida: Antes da abertura da API oficial, recomendamos reservar o acesso à série Gemini na APIYI (apiyi.com). Ao unificar o
base_url, a troca entre diferentes versões do Gemini requer apenas a alteração do campomodel, permitindo que você realize testes de estresse no 3.2 Flash com cenários de negócios reais logo na noite do I/O.
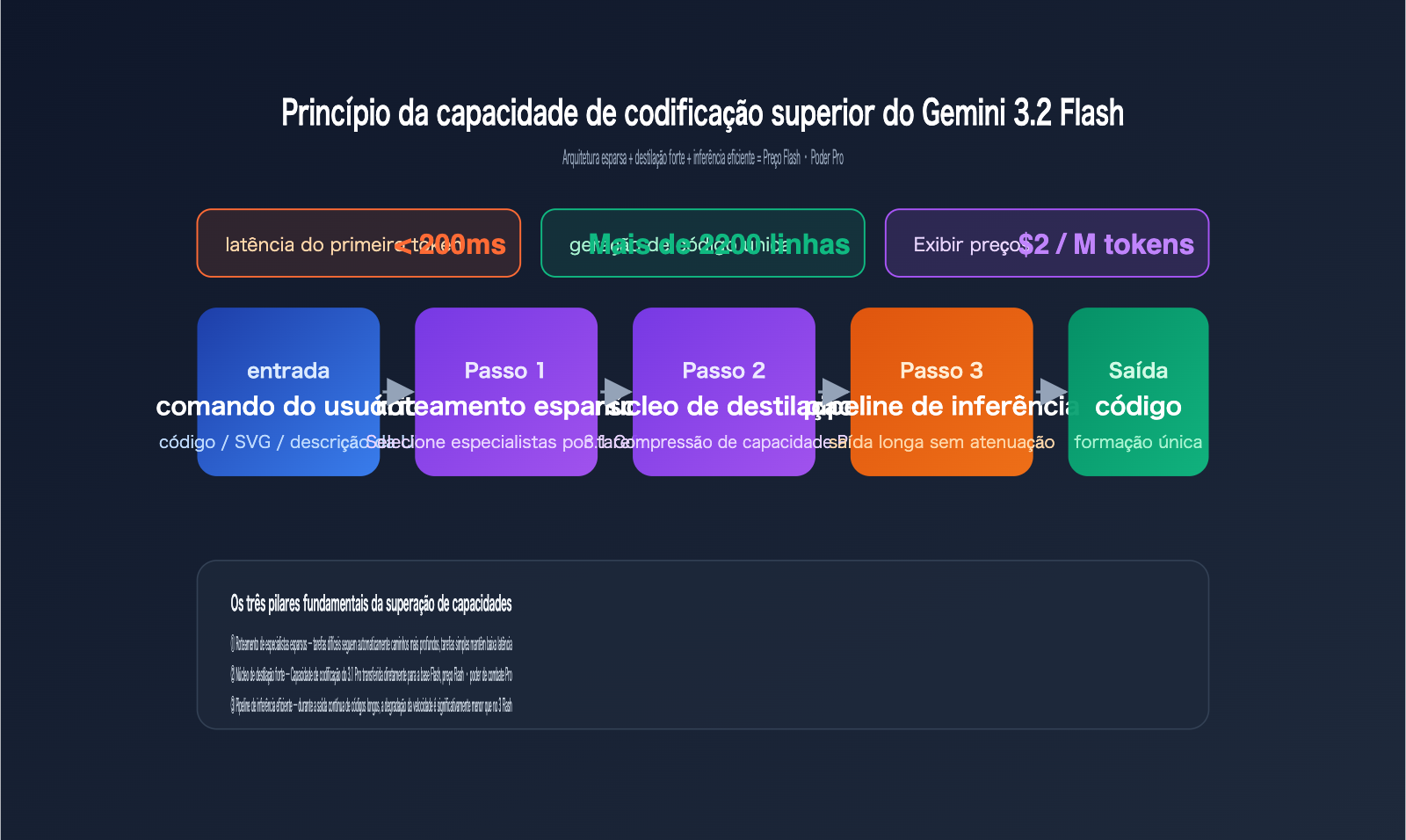
Teste prático: A capacidade de codificação do Gemini 3.2 Flash supera as expectativas
A parte mais surpreendente deste lançamento, que desafiou as expectativas dos desenvolvedores, é o desempenho do modelo da categoria Flash em tarefas de codificação, superando modelos superiores. A comunidade internacional realizou diversos testes cegos no modo Canvas do AI Studio, e a conclusão é unânime: em cenários de UI generativa, SVG complexos e HTML Canvas, o Gemini 3.2 Flash já supera consistentemente o Gemini 3.1 Pro.
Comparação dos três principais cenários de codificação do Gemini 3.2 Flash
A tabela abaixo resume os resultados dos três testes comparativos mais citados pela comunidade internacional. Todos os resultados provêm de amostras públicas do LM Arena anônimo e do AI Studio.
| Tarefa de teste | Gemini 3 Flash | Gemini 3.1 Pro | Gemini 3.2 Flash |
|---|---|---|---|
| Animação de cidade em ASCII HTML em tela cheia | Código não executável | ~5 min, código corrompido | ~2 min, versão funcional direta |
| Geração de demo de desktop Windows 98 em um único prompt | Apenas interface estática | Lógica interativa fragmentada, requer ajustes | ~2200 linhas de código de uma vez, janelas e menus interativos |
| Ilustração vetorial SVG complexa | Caminhos confusos, cores erradas | Visual aceitável, requer ajustes manuais | Visual aceitável e saída perfeita de primeira |
Os três testes têm um ponto em comum: exigem que o modelo complete o "planejamento estrutural + saída contínua de código longo" em uma única inferência, que era justamente o ponto fraco dos modelos Flash no passado. A estabilidade do 3.2 Flash em cenários de saída longa indica que sua base foi significativamente reforçada em termos de coerência de contexto longo e restrições de sintaxe de código.
Por que o Gemini 3.2 Flash consegue "superar modelos superiores"?
A partir das informações técnicas disponíveis, esse salto não veio apenas do aumento de parâmetros, mas de uma combinação de otimizações de engenharia. As análises internacionais apontam geralmente para quatro direções:
- Destilação de IA mais agressiva: As capacidades do 3.1 Pro foram destiladas diretamente para uma base Flash menor e mais rápida.
- Otimização de arquitetura esparsa: O roteamento de especialistas é mais preciso; não é necessário "acionar todos" durante a geração de códigos longos.
- Sistema de roteamento interno aprimorado: Tarefas difíceis seguem automaticamente caminhos de inferência mais profundos, enquanto tarefas simples mantêm baixa latência.
- Pipeline de inferência eficiente: A latência do primeiro token é mantida estavelmente abaixo de 200 ms, com menor degradação de velocidade durante saídas longas.
Para os desenvolvedores, a sensação imediata é: ao escrever um componente React/Vue, executar uma explicação de SQL ou gerar um código de visualização executável, o Flash já pode substituir o Pro como primeira opção por padrão, recorrendo ao Pro apenas quando for necessário um raciocínio pesado ou um planejamento complexo de várias etapas.
🚀 Dica de teste: Para verificar a verdadeira capacidade de codificação do 3.2 Flash em primeira mão, recomendamos o acesso via plataforma APIYI (apiyi.com) usando a interface compatível com OpenAI. Sugerimos preparar um conjunto de "comandos pesados" (como HTML longo, SVG complexo, reescrita de código de página inteira) e usar o mesmo script para comparar a qualidade e a estabilidade da saída entre o 3.2 Flash e o 3.1 Pro.
Estratégia de Preços e Estimativa de Custos do Gemini 3.2 Flash
A série Flash sempre foi a arma secreta do Google para combater os preços da concorrência, e o 3.2 Flash leva isso a um novo patamar. O preço de saída de US$ 2,00 por milhão de tokens significa que, em cenários comuns de codificação ou geração de textos longos, seu custo por unidade já se aproxima do nível "mini" do GPT-5.5 Instant, mas com capacidades que chegam perto da versão Pro.
Comparação de preços: Gemini 3.2 Flash vs. Série Gemini
A tabela abaixo apresenta uma comparação horizontal dos preços da série Gemini atualmente visíveis no AI Studio. Todos os dados são baseados em páginas públicas ou metadados vazados; os preços da categoria Pro seguem a tabela padrão do Vertex AI.
| Modelo | Entrada ($/M) | Saída ($/M) | Cenários de uso |
|---|---|---|---|
| Gemini 3.1 Flash-Lite | 0,25 | 1,50 | Alta concorrência, tarefas em lote de baixo custo |
| Gemini 3 Flash | 0,50 | 3,00 | Chat padrão / Código médio |
| Gemini 3.2 Flash (vazado) | 0,25 | 2,00 | Geração de código longo / UI complexa / SVG |
| Gemini 3.1 Pro | 1,25 | 10,00 | Raciocínio complexo / Planejamento em várias etapas |
Como se pode notar, o 3.2 Flash mantém o preço de entrada igual ao do Flash-Lite e reduz o preço de saída em um terço em relação ao 3 Flash, enquanto entrega um desempenho que rivaliza com o 3.1 Pro (que custa US$ 10 por milhão de tokens de saída). Para uma tarefa de código complexo que gere 1 milhão de tokens, usar o 3.2 Flash economiza cerca de 80% em comparação com o 3.1 Pro. Todos os quatro modelos mencionados estão disponíveis na APIYI (apiyi.com) através de uma interface unificada compatível com OpenAI, permitindo que você distribua o tráfego dinamicamente conforme a necessidade do negócio, sem precisar integrar SDKs diferentes para cada categoria.
Exemplo de estimativa de custo mensal do Gemini 3.2 Flash
Para tornar os números mais claros, vamos usar um cenário de negócio real: imagine que você está criando uma ferramenta de auxílio à programação com IA que processa, em média, 5.000 solicitações de geração de código por dia, com uma entrada média de 1k tokens e saída de 3k tokens.
| Modelo escolhido | Custo diário (USD) | Custo mensal (USD) | Observação |
|---|---|---|---|
| Gemini 3.1 Pro | 156,25 | 4.687,50 | Raciocínio forte, mas excessivo para código |
| Gemini 3 Flash | 47,50 | 1.425,00 | Solução padrão atual |
| Gemini 3.2 Flash (estimado) | 31,25 | 937,50 | Desempenho próximo ao Pro, custo reduzido |
💰 Dica de otimização de custos: Para projetos sensíveis ao orçamento, considere utilizar a API da série Gemini através da plataforma APIYI (apiyi.com). A plataforma oferece cobrança por uso e um pool de cotas unificado, ideal para pequenas e médias equipes integrarem o 3.2 Flash rapidamente assim que for lançado, sem precisar gerenciar sistemas de faturamento de múltiplos fornecedores.
Interface "Liquid Glass" e sinais de Agents no Gemini 3.2 Flash
O modelo em si não é a única novidade deste vazamento. Junto com o Gemini 3.2 Flash, surgiu uma nova interface de interação chamada pelos desenvolvedores de "Liquid Glass", além de uma aba oculta "Agents (Beta)". Esses dois pontos revelam mais sobre a estratégia geral do Google para o I/O 2026 do que o próprio modelo.
Destaques da interface web do Gemini 3.2 Flash
O "Liquid Glass" representa uma mudança de estilo significativa em relação ao design plano do passado, manifestando-se em:
- Caixa de entrada de comando em formato de pílula com brilho gradiente suave
- Camada de fundo semitransparente que pulsa conforme o diálogo
- Seletor de modelo movido para um menu suspenso no canto superior esquerdo, destacando a ação de "trocar de modelo"
- Balões de diálogo com maior contraste e uso de espaços em branco, com blocos de código longos expandidos por padrão
Essa interface coloca a "capacidade de troca de modelo" em um lugar de destaque visual, preparando o terreno para a matriz de modelos da série Gemini — o usuário é educado por padrão a "escolher o modelo de acordo com a tarefa", o que está em total sintonia com a filosofia de plataformas de agregação de múltiplos fornecedores.
O que o Gemini 3.2 Flash e o Agents (Beta) sugerem sobre a estratégia de agentes
O que é ainda mais interessante para os desenvolvedores é a aba "Agents (Beta)" inacabada que apareceu no app do Gemini para iOS. Combinando isso com os investimentos contínuos do Google no último ano em Gemini CLI, Agent Builder e Vertex AI Agent, é razoável inferir que o I/O 2026 terá uma linha estratégica dedicada a agentes, e o Gemini 3.2 Flash provavelmente será posicionado como o "cérebro padrão para agentes": rápido o suficiente para sustentar ciclos de várias etapas e com custo viável para alto consumo de tokens.
🎯 Sugestão de arquitetura: Se você está desenvolvendo seu próprio framework de agentes, recomendo colocar a série Gemini atrás da mesma camada de roteamento que o Claude e o GPT na APIYI (apiyi.com). Assim que o 3.2 Flash for liberado, você só precisará alternar o campo
modelpara verificar se ele supera as soluções atuais como "cérebro de agente", evitando ficar preso a um único fornecedor.
Exemplo de integração e interface unificada do Gemini 3.2 Flash
Embora a API oficial do 3.2 Flash ainda não tenha sido aberta, espera-se que suas especificações de interface sejam idênticas às da série Gemini 3.x. Abaixo, apresento um exemplo minimalista utilizando a interface unificada da APIYI, que permite uma transição quase sem alterações para o 3.2 Flash no futuro.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.2-flash", # Substitua pelo ID oficial do modelo após o lançamento
messages=[
{"role": "user", "content": "Crie uma área de trabalho interativa do Windows 98 usando apenas um arquivo HTML + Canvas"}
],
)
print(response.choices[0].message.content)
Ver código completo com streaming e repetição de erro
from openai import OpenAI
from openai import APIError, RateLimitError
import time
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
PROMPT = """Crie uma demo de uma área de trabalho interativa do Windows 98 usando um único arquivo HTML + Canvas,
requisitos: janelas arrastáveis, menu iniciar funcional no canto inferior esquerdo e ícones da área de trabalho que abrem janelas ao clicar duas vezes."""
def call_gemini_3_2_flash(prompt: str, retries: int = 3):
for attempt in range(retries):
try:
stream = client.chat.completions.create(
model="gemini-3.2-flash",
messages=[{"role": "user", "content": prompt}],
stream=True,
max_tokens=8192,
)
for chunk in stream:
if chunk.choices and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
return
except RateLimitError:
time.sleep(2 ** attempt)
except APIError as e:
print(f"\n[Erro de API] {e}")
return
if __name__ == "__main__":
call_gemini_3_2_flash(PROMPT)
O design fundamental deste código reside no desacoplamento entre base_url e model: para alternar entre Flash e Pro, basta alterar uma linha no campo do modelo. O código de negócio, o tratamento de erros e a lógica de streaming são totalmente reutilizáveis, sendo ideal para avaliações A/B logo após o lançamento.
Análise do impacto do Gemini 3.2 Flash para desenvolvedores e o setor
O motivo pelo qual este vazamento gerou tanta discussão na comunidade internacional de desenvolvedores não é simplesmente "o lançamento de mais um Flash", mas sim o fato de ter quebrado o consenso tácito de que "Flash é barato, mas serve apenas para tarefas leves, enquanto Pro é caro, mas é o único capaz de escrever códigos complexos".
Impacto do Gemini 3.2 Flash para desenvolvedores independentes e pequenas equipes
Para desenvolvedores independentes sensíveis ao orçamento, o 3.2 Flash é praticamente um divisor de águas. Tarefas que antes exigiam o modelo Pro para serem concluídas com estabilidade — como "geração de código de páginas inteiras" ou "visualizações complexas" — agora podem ser realizadas pelo Flash, podendo reduzir os custos mensais com modelos em 50% a 80%.
Para pequenas equipes, o impacto reflete-se mais na forma do produto: funcionalidades como assistentes de programação por IA, plataformas de visualização low-code e geradores de relatórios automatizados, que antes eram limitadas devido ao alto custo de invocação do modelo Pro, agora podem ser redesenhadas como recursos residentes, ativados sob demanda.
Impacto do Gemini 3.2 Flash para grandes equipes e arquiteturas multimodelo
Para grandes equipes que já possuem arquiteturas multimodelo, o 3.2 Flash não substituirá o Pro imediatamente, mas forçará uma estratégia de seleção de modelo mais granular: a camada de roteamento precisará escolher dinamicamente entre Flash ou Pro com base no tipo de tarefa, em vez de usar um único modelo para tudo. Isso exige mais de gateways de modelo, faturamento unificado e logs centralizados. Gateways simplificados, projetados para um único modelo, provavelmente precisarão de uma atualização arquitetural após o I/O.
Especificamente, grandes equipes devem se preparar em três frentes: primeiro, estabelecer uma medição observável de tokens, separando o consumo real de Flash e Pro; segundo, realizar o desacoplamento entre comando e modelo, usando sistemas de templates em vez de vincular o modelo via hardcode; terceiro, preparar mecanismos de transição gradual (canary deployment), migrando módulos de negócio aos poucos quando o 3.2 Flash for aberto, reduzindo riscos operacionais.
Impacto do Gemini 3.2 Flash na concorrência
No mesmo dia, a OpenAI lançou o GPT-5.5 Instant, focado em "reduzir alucinações e fortalecer a veracidade". Isso cria um confronto direto com a estratégia do Google de "redução de preços + melhoria na capacidade de codificação": a OpenAI aposta em cenários verticais de alto valor, enquanto o Google aposta em cenários de codificação popular e agentes. A Anthropic ainda não respondeu diretamente ao vazamento, mas o "prêmio pela capacidade de codificação" que a série Claude mantém há tempos enfrentará a pressão de preços da categoria Flash.
Perguntas Frequentes sobre o Gemini 3.2 Flash
Q1: Quando o Gemini 3.2 Flash terá sua API oficialmente aberta?
Seguindo as pistas de vazamentos e o ritmo de lançamentos do Google I/O, é muito provável que o Gemini 3.2 Flash seja anunciado oficialmente na palestra principal do I/O 2026, entre 19 e 20 de maio, sendo disponibilizado via Vertex AI e AI Studio no mesmo dia ou no dia seguinte. Plataformas de agregação de terceiros geralmente completam a integração em 24 a 48 horas. Recomendamos acompanhar os anúncios de novos modelos da APIYI em apiyi.com para realizar testes com uma interface unificada assim que estiver disponível.
Q2: O Gemini 3.2 Flash substituirá o Gemini 3.1 Pro?
Não haverá uma substituição total a curto prazo. O 3.2 Flash apresenta um desempenho superior em codificação, geração de códigos longos e tarefas com SVG / Canvas, mas o Pro continua mais estável em raciocínio de longa cadeia, planejamento complexo de várias etapas e cenários financeiros/jurídicos que exigem cadeias causais rigorosas. A estratégia mais sensata é o roteamento por tarefa: use o 3.2 Flash para codificação e UI, e o 3.1 Pro para raciocínio profundo e decisões de alto risco. Basta realizar o roteamento de modelos na camada de gateway usando o mesmo código, sem necessidade de reescrever a lógica de negócios.
Q3: A geração de 2200 linhas de código do Gemini 3.2 Flash é real?
O "demo da área de trabalho do Windows 98 com 2200 linhas" que circula na comunidade de desenvolvedores estrangeiros vem de amostras reais do modo Canvas do AI Studio. O fato que pode ser validado de forma independente é que a estabilidade do 3.2 Flash na geração de códigos longos e executáveis em um único comando é significativamente superior à do 3 Flash e do 3.1 Pro. A reprodução completa depende da abertura da API oficial, mas essa capacidade de "estabilidade em saídas longas" foi confirmada repetidamente por vários testadores independentes.
Q4: Qual é a janela de contexto do Gemini 3.2 Flash?
Não há um número direto para a janela de contexto nos metadados vazados, mas, considerando as especificações da série Gemini 3.x, é muito provável que o 3.2 Flash mantenha a janela de contexto de 1M de tokens. Isso é crucial para o processamento de repositórios de código extensos, documentos completos e transcrições de vídeo, sendo também a base física que permite a saída estável de mais de 2000 linhas de código.
Q5: Como desenvolvedores no Brasil podem acessar o Gemini 3.2 Flash o mais rápido possível?
Após o lançamento oficial, o caminho mais estável para desenvolvedores é através de plataformas de agregação acessíveis. Recomendamos usar a APIYI (apiyi.com) para acessar o Gemini 3.2 Flash. A plataforma utiliza uma interface compatível com OpenAI, permitindo a reutilização perfeita com o código existente. Basta modificar os campos base_url e model para chamar Gemini, Claude, GPT e outros modelos no mesmo projeto, facilitando a avaliação e a alternância entre eles.
Resumo: O que a exposição antecipada do Gemini 3.2 Flash significa
Voltando à frase inicial: "a conferência nem começou e o Google não conseguiu esconder nada". Desde o lançamento silencioso no AI Studio em 5 de maio até hoje, o Gemini 3.2 Flash foi totalmente dissecado pela comunidade internacional, desde o ID do modelo, a interface Liquid Glass, as tags de Agents, até o demo de 2200 linhas de código. Isso não é apenas um vazamento de produto, mas um sinal claro de três pontos:
- O nível Flash subiu de categoria: O Google está redefinindo a classificação de modelos com "baixo custo + alta capacidade de codificação".
- A estratégia de Agents veio à tona: O 3.2 Flash provavelmente se tornará a base padrão para aplicações de agentes.
- O valor da agregação de múltiplos modelos foi amplificado: Quem conseguir integrar e avaliar mais rápido, aproveitará a janela de oportunidade.
Para os desenvolvedores, o que realmente importa não é apostar nos detalhes específicos do I/O, mas preparar com antecedência a infraestrutura de engenharia para integração, avaliação e faturamento unificados, para começar os testes de estresse assim que o 3.2 Flash for aberto. Recomendamos usar a APIYI (apiyi.com) para validar os resultados rapidamente, permitindo obter dados reais do seu cenário de negócio na mesma noite em que a palestra do I/O terminar, em vez de esperar pelos benchmarks da comunidade.
Autor: Equipe Técnica APIYI — Focada em práticas de engenharia de API para modelos de linguagem grande. Se você deseja saber mais sobre os dados de custo e desempenho das séries Gemini, Claude e GPT em cenários de negócios reais, visite APIYI em apiyi.com para obter os relatórios de avaliação mais recentes e créditos de teste gratuitos.