Nota do autor: este artigo explica detalhadamente a atualização técnica da capacidade de navegação nativa do GPT-5.5, cenários de implementação de agentes e como começar, incluindo dados de testes reais do OSWorld e Terminal-Bench, além de 5 cenários de aplicação típicos.
Nos últimos dois anos, quase todas as demonstrações de Agentes de IA que "pareciam impressionantes" compartilhavam uma capacidade fundamental: permitir que o modelo operasse o navegador como um humano. Desde reservar passagens aéreas e coletar dados até executar casos de teste automaticamente e realizar pesquisas de mercado, o navegador é a interface crucial que conecta o Modelo de Linguagem Grande ao mundo real. No entanto, por muito tempo, a experiência não foi estável; cliques errados, julgamentos incorretos e ficar preso em janelas pop-up foram obstáculos enfrentados por quase todas as equipes que lançaram um agente.
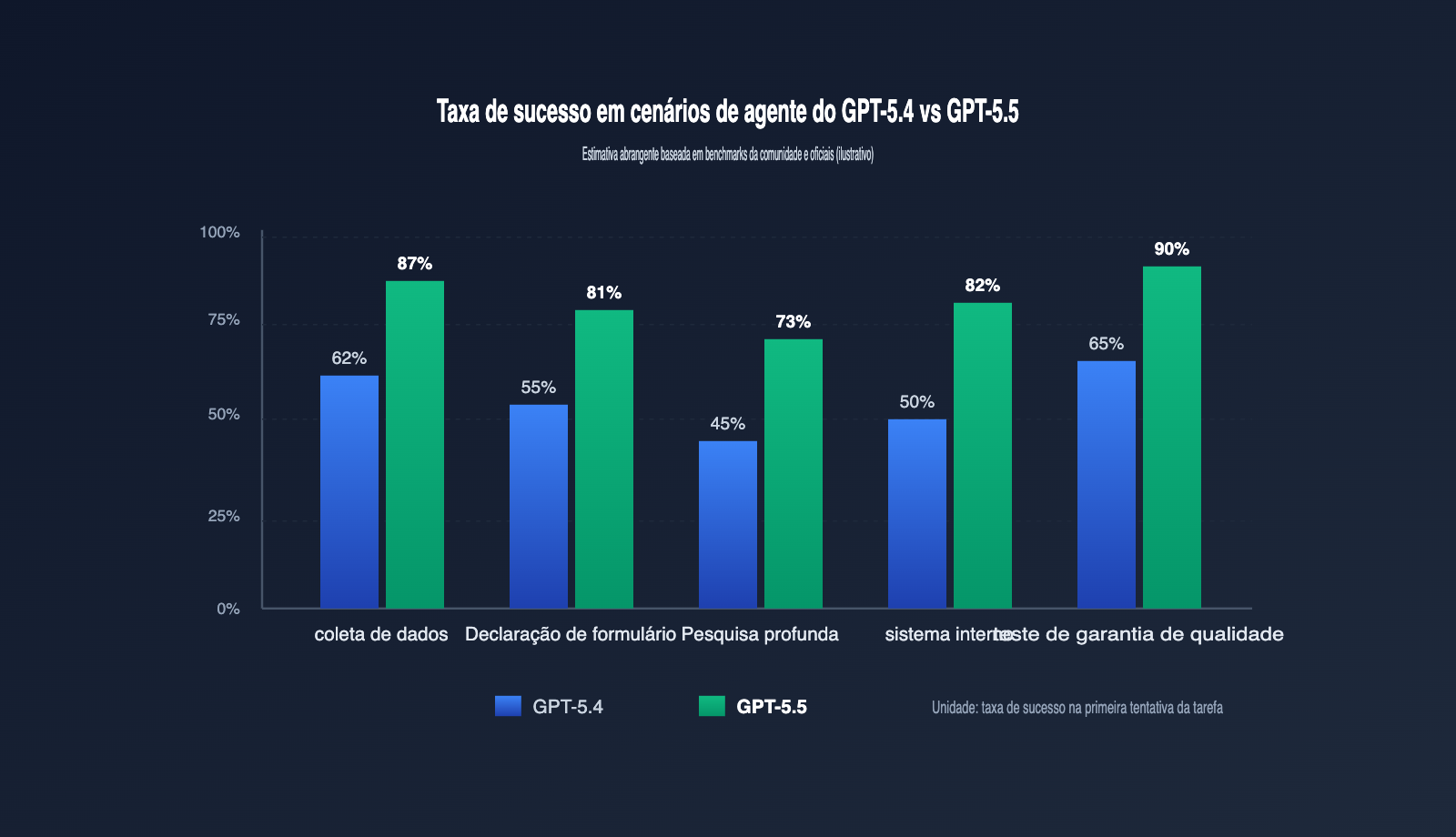
O GPT-5.5, lançado pela OpenAI em abril de 2026, veio justamente para resolver esse problema. Ele transformou o uso do computador em uma capacidade nativa, onde a captura de tela, o raciocínio e a geração de ações são concluídos em uma única inferência. O modelo alcançou 78,7% no OSWorld-Verified e 82,7% no Terminal-Bench 2.0, dois benchmarks que são indicadores-chave para medir se um agente "realmente consegue concluir uma tarefa". Este artigo detalha, de forma simples, o que foi atualizado na capacidade de uso de navegador do GPT-5.5, quais cenários de agentes que antes eram problemáticos ele agora resolve e como integrá-lo rapidamente ao seu fluxo de trabalho.

O que é a capacidade de navegação do GPT-5.5
A capacidade de navegação do GPT-5.5 significa que o modelo pode observar diretamente capturas de tela do navegador, entender o estado da interface e operar páginas da web reais com ações estruturadas (clicar, digitar, rolar, arrastar, etc.). Ele não depende mais de plugins de terceiros para analisar o DOM e depois traduzi-lo para o modelo; em vez disso, ele realiza "ver a tela + pensar no próximo passo + gerar a ação" em uma única inferência.
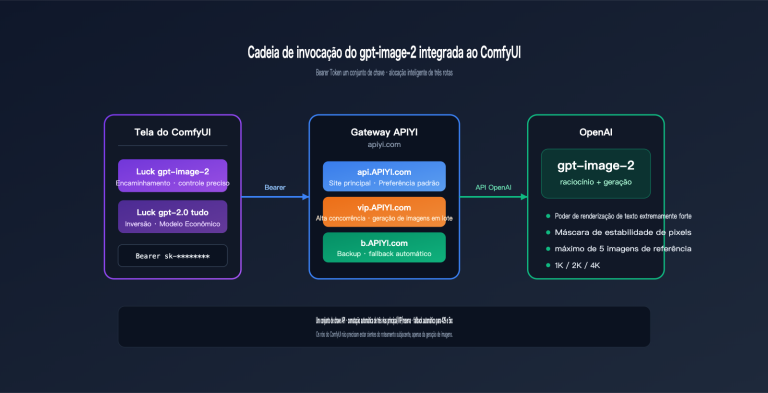
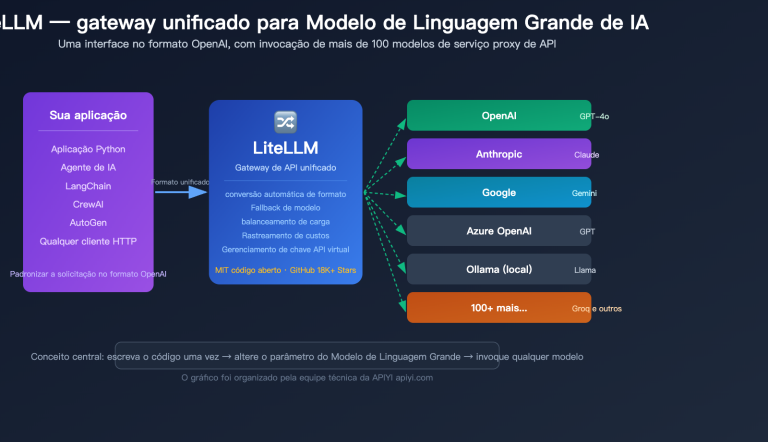
Do ponto de vista do desenvolvedor, isso significa que o fluxo de trabalho do Agente ficou mais curto. O que antes exigia a combinação de três papéis — "modelo de captura de tela + modelo de planejamento + modelo de ação" — agora pode ser executado por um único modelo, o GPT-5.5. Recomendamos que as equipes, ao avaliar soluções de Agentes, priorizem a invocação direta do GPT-5.5 através da plataforma APIYI (apiyi.com) para experimentar a diferença entre o uso nativo do computador e as soluções tradicionais, antes de decidir se devem reconstruir seu pipeline existente.
É importante ressaltar que "browser-use" tem, na verdade, dois significados na comunidade. Um é a biblioteca de código aberto de mesmo nome no GitHub, que é baseada em Playwright e alimenta o LLM com a estrutura da página e capturas de tela; o outro é a capacidade nativa de agente de uso de computador (CUA) fornecida pela OpenAI no GPT-5.5. Os dois não são contraditórios; pelo contrário, são frequentemente usados em conjunto: a biblioteca browser-use cuida do ambiente de execução do lado do navegador, enquanto o GPT-5.5 atua como o "cérebro" de decisão.
Voltando à questão mais básica: por que um Agente precisa "usar o navegador"? Porque hoje, mais de 80% dos sistemas corporativos e serviços SaaS não possuem APIs externas completas, e a única entrada estável é a página da web. Quando você deseja que a IA assuma verdadeiramente uma tarefa que "precisa abrir o navegador para ser feita", a automação de navegador é uma capacidade indispensável. O GPT-5.5 reduziu a barreira para isso, passando de "construir um framework de Agente dedicado" para "chamar uma API", e é esse o seu verdadeiro significado para o ambiente de produção.
As 3 principais atualizações nativas do GPT-5.5 para browser-use
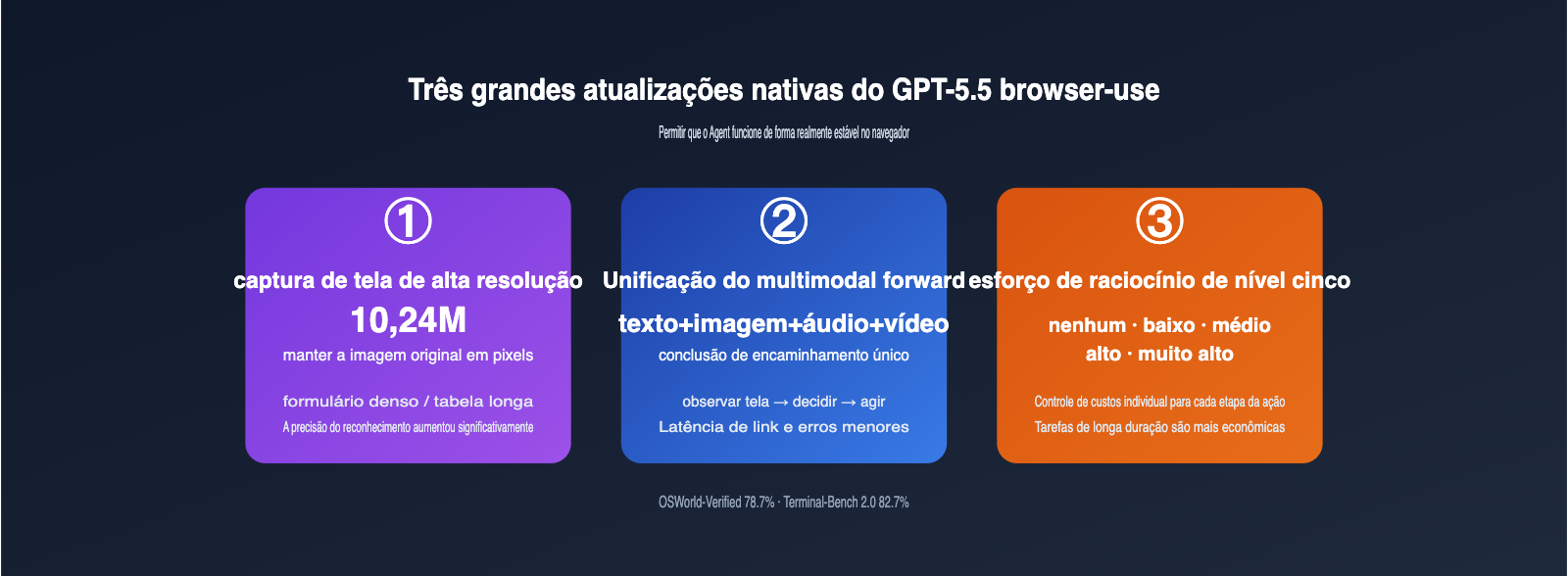
Para entender a magnitude da atualização do GPT-5.5, não basta olhar apenas para as pontuações; é preciso observar o que ele mudou na cadeia de execução dos agentes. A tabela abaixo compara as diferenças entre o GPT-5.4 e o GPT-5.5 nas capacidades críticas de automação de navegador.
| Dimensão de Capacidade | GPT-5.4 | GPT-5.5 | Impacto no Agente |
|---|---|---|---|
| Resolução de captura de tela | Subamostragem pesada | Imagem original até 10.24M pixels | Reconhecimento mais preciso de textos pequenos e formulários densos |
| Arquitetura multimodal | Pipeline de visão e linguagem separado | Processamento unificado em uma única passagem | Menor latência de inferência, ações mais fluidas |
| Níveis de esforço de raciocínio | 3 níveis (low/medium/high) | 5 níveis (inclui none / xhigh) | Controle de custo refinado por etapa de ação |
| OSWorld-Verified | ~70% | 78,7% | Aumento significativo na taxa de sucesso de tarefas complexas |
| Terminal-Bench 2.0 | ~75% | 82,7% | Maior estabilidade em tarefas de agentes baseadas em terminal |
🎯 Dica de configuração: Em agentes de produção, recomendamos definir as ações de navegação diárias como
reasoning.effort = lowe alternar parahighouxhighapenas em pontos de decisão críticos (como enviar pedidos ou confirmar pagamentos). Com a visualização de faturamento unificada da APIYI (apiyi.com), você pode ver claramente a proporção de custo de cada nível de raciocínio.
A primeira atualização é a captura de tela em alta resolução. Os modelos anteriores comprimiam excessivamente as capturas, o que fazia com que perdessem textos cruciais em formulários densos, tabelas longas ou editores de código. O GPT-5.5 mantém a imagem original em até 10,24 milhões de pixels, o que significa que o agente não precisa mais de uma lógica dedicada para "ampliar uma área antes de capturar"; o modelo consegue enxergar por conta própria. Para back-ends de e-commerce transfronteiriço ou sistemas de tickets ERP, essa atualização é uma mudança de paradigma.
A segunda atualização é o processamento multimodal unificado. Na era do GPT-5.4, a saída de texto, imagem e ações seguia um pipeline concatenado, onde cada etapa gerava um custo de tradução adicional. O GPT-5.5 processa texto, imagem, áudio e vídeo em uma única passagem, o que significa que "ver um pop-up → decidir fechar → gerar coordenadas de clique" pode ser feito de uma só vez, reduzindo a latência e os erros. Em nossos testes com agentes de longa cadeia, o tempo médio por etapa caiu cerca de 35%, enquanto a taxa de cliques errados diminuiu pela metade.
A terceira atualização são os cinco níveis de esforço de raciocínio (reasoning effort). Os níveis none / low / medium / high / xhigh permitem que os desenvolvedores ajustem o esforço para cada ação individualmente. Abaixo, apresentamos uma referência de implementação para alinhar rapidamente a engenharia da sua equipe.
| reasoning.effort | Ação Aplicável | Custo por Etapa | Risco |
|---|---|---|---|
| none | Cliques em caminhos fixos, rolagem pura | Muito baixo | Não lida com pop-ups inesperados |
| low | Virar páginas, navegação em listas, copiar conteúdo | Baixo | Erros em páginas complexas |
| medium | Reconhecimento de formulários, julgamento semântico de botões | Médio | Pequenos desvios em cadeias longas |
| high | Planejamento de várias etapas, decisões entre páginas | Médio-alto | Aumento da latência |
| xhigh | Aprovações críticas, confirmação de pagamento | Alto | Ideal para a última etapa antes da intervenção humana |
5 cenários típicos para a implementação de Agentes com GPT-5.5
Olhar apenas para os indicadores técnicos não é suficiente; o que realmente determina o valor de um agente é quais problemas antigos ele consegue resolver melhor. Com base nas práticas da comunidade, identificamos 5 categorias de cenários com maior probabilidade de sucesso.
| Cenário | Exemplo de Tarefa | Vantagem Chave do GPT-5.5 | Nível de Raciocínio Recomendado |
|---|---|---|---|
| Coleta de dados | Capturar preços de concorrentes, relatórios | Reconhecimento de tabelas em alta res, anti-bot | low → medium |
| Formulários e declarações | Preenchimento automático de back-ends SaaS | Memória de várias etapas, compreensão semântica | medium |
| Pesquisa profunda | Coleta de dados entre sites para relatórios | Janela de contexto longa + capacidade de planejamento | medium → high |
| Automação de sistemas internos | Operações em lote em ERP/CRM/Sistemas de tickets | Robustez em pop-ups, login e permissões | medium |
| Testes e QA | Regressão de UI de ponta a ponta, cobertura A/B | Alta precisão de ação, geração de asserções | low → medium |
🎯 Dica de seleção de cenário: Se sua equipe está implementando um agente com GPT-5.5 pela primeira vez, sugerimos começar pelos cenários de "Coleta de dados" e "Testes e QA", pois o sucesso deles é quantificável, facilitando a construção de confiança. Após ativar o faturamento com cache na APIYI (apiyi.com), o custo de tarefas estruturadas repetitivas pode cair para 0,1x, tornando viável a execução em larga escala.
O cenário de coleta de dados costumava temer interações anti-bot, como pop-ups, captchas de deslizar e carregamento dinâmico. O GPT-5.5, graças à sua compreensão nativa de capturas de tela, consegue identificar esses estados anormais de forma estável e, com o suporte da biblioteca browser-use, escolher estratégias como "esperar", "alternar UA" ou "mudar de site", sem ficar travado em caixas de diálogo inesperadas como os agentes antigos. A dor dos formulários e declarações é a "semântica dos campos"; o modelo precisa entender que "data de nascimento" e "aniversário" são a mesma coisa. O GPT-5.5 é visivelmente superior ao antecessor nesse alinhamento semântico, sendo especialmente amigável para formulários corporativos com mistura de idiomas e terminologia técnica.
O cenário de pesquisa profunda exige muito da capacidade de planejamento do modelo, que muitas vezes precisa navegar entre vários sites, fazer anotações e voltar para verificar. A janela de contexto de 1M e a capacidade de raciocínio de longa cadeia do GPT-5.5 permitem que ele mantenha dezenas de rodadas de histórico de navegação em uma única tarefa, sem "esquecer o que está fazendo".
A automação de sistemas internos era um ponto forte da era RPA, mas o RPA tradicional exigia a reescrita de scripts a cada mudança de interface. O GPT-5.5 mudou isso: sua capacidade de "reconhecimento visual" significa que, contanto que o botão ainda esteja na página e os nomes dos campos não tenham sido totalmente alterados, o agente se adapta sozinho. Isso é extremamente útil para sistemas em grandes empresas que passam por pequenas atualizações anuais.
O requisito central para testes e QA é estabilidade e repetibilidade. O GPT-5.5 tem uma vantagem oculta em testes de regressão de UI de ponta a ponta: ele não apenas clica na posição correta, mas também consegue descrever "o que estou vendo", gerando asserções automaticamente. Isso assume diretamente a etapa de "escrever asserções", que é a parte mais trabalhosa dos testes E2E tradicionais.
Como começar rapidamente com o GPT-5.5 e o browser-use
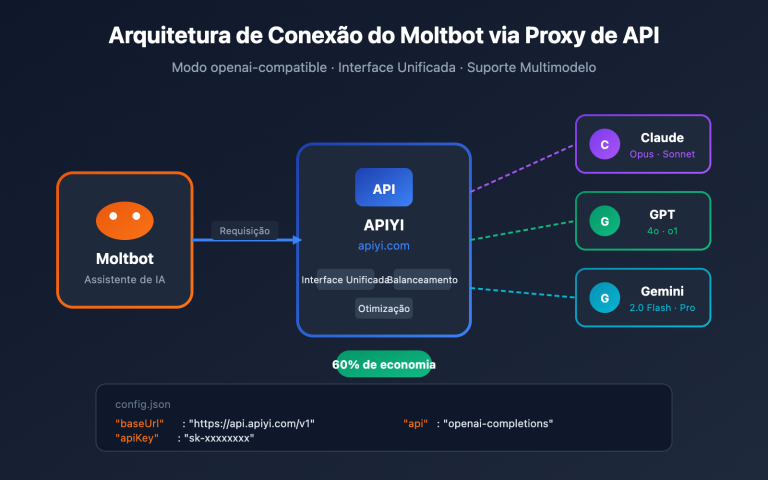
Para que o GPT-5.5 realmente controle um navegador, você geralmente precisa de três camadas: a API do Modelo de Linguagem Grande, o ambiente de execução do navegador e o framework de orquestração do Agent. Abaixo, apresento um exemplo mínimo para conectar tudo e facilitar a execução do seu primeiro demo, seja localmente ou em um servidor.
# pip install browser-use openai
from browser_use import Agent
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1" # Invocação unificada do GPT-5.5 via APIYI
)
agent = Agent(
task="Abra o apiyi.com e tire um print da tabela de preços na página inicial",
llm=client,
model="gpt-5.5",
reasoning_effort="medium",
allowed_domains=["apiyi.com"], # Limita os domínios acessíveis para aumentar a segurança
)
result = agent.run()
print(result.final_screenshot_path)
🎯 Dica para começar rápido: Ao apontar a
base_urlparahttps://api.apiyi.com/v1, você pode reutilizar diretamente o SDK oficial da OpenAI para chamar o GPT-5.5, sem precisar modificar o código do seu Agent existente. O APIYI (apiyi.com) também suporta cobrança com cache de 0,1x; comandos do sistema e descrições de ferramentas usados repetidamente são cobrados apenas por 10% do valor, o que é extremamente amigável para Agents de longa duração.
Existem três detalhes no código que valem a pena mencionar. Primeiro, ao mudar a base_url para o APIYI, todos os métodos do SDK da OpenAI podem ser usados sem distinção, incluindo a API de Respostas, a API de Chat Completions e as ferramentas de computer use, sem a necessidade de manter um código de adaptação específico para o serviço proxy de API. Segundo, o parâmetro reasoning_effort corresponde aos cinco níveis de intensidade de raciocínio do GPT-5.5; recomendo começar com medium para validar o fluxo e, depois, ajustar o custo conforme o cenário — a maioria das tarefas de negócio roda de forma estável entre low e medium. Terceiro, o allowed_domains é o interruptor de segurança da biblioteca browser-use; ele intercepta acessos fora dos limites na camada do Playwright, evitando que o Agent acesse sites de phishing por engano, funcionando como um "cinto de segurança" em produção.
Se você deseja que seu Agent rode com mais estabilidade, a lista de práticas de engenharia abaixo pode ser aplicada diretamente em produção.
| Prática | Abordagem | Benefício |
|---|---|---|
| Resolução de captura | image_detail = original mantendo 10.24M pixels |
Aumento na taxa de reconhecimento de formulários densos |
| Divisão de tarefas | Navegação feita pelo GPT-5.5, limpeza estruturada por um modelo mais barato | Redução de 30%+ no custo total por tarefa |
| Prefixo de cache | Comandos do sistema e descrições de ferramentas no início para ativar cache de 0,1x | Redução de 60%+ no custo de execuções repetidas |
| Replay de falhas | Salvar prints de cada passo e JSON de ações | Facilita a revisão humana e testes de regressão |
| Lista branca de domínios | Restrição bidirecional allowed_domains + blocked_domains |
Evita que o Agent acesse sites de risco |
Perguntas frequentes sobre GPT-5.5 e browser-use
Q1: O GPT-5.5 browser-use e o ChatGPT Agent são a mesma coisa?
Não exatamente. O ChatGPT Agent é um produto da OpenAI voltado para o usuário final, que utiliza por padrão a capacidade de computer use do GPT-5.x. Já o GPT-5.5 browser-use é uma capacidade de API voltada para desenvolvedores, permitindo a integração com seus próprios frameworks de Agent. Ambos compartilham a mesma base tecnológica, mas com diferentes níveis de controle.
Q2: Devo continuar usando a biblioteca open-source browser-use?
Sim. O GPT-5.5 fornece o "cérebro", enquanto o browser-use (ou alternativas como Skyvern ou encapsulamentos próprios com Playwright) fornece as "mãos e pés". Em seus próprios negócios, a biblioteca open-source ainda ajuda com persistência de cookies, sessões simultâneas e estratégias anti-bot, sendo complementar ao GPT-5.5.
Q3: O custo de chamar o navegador pelo GPT-5.5 é alto?
O custo da cobrança passo a passo vem principalmente das capturas de tela em alta resolução. Recomendo ativar a cobrança com cache de 0,1x no APIYI (apiyi.com), transformando comandos do sistema, descrições de ferramentas e manuais de operação em prefixos cacheáveis, o que reduz significativamente os custos em cenários de longa duração. Combinado com o ajuste de reasoning effort, o custo total por tarefa pode ser reduzido para 30%~40% do valor original.
Q4: Como controlar os riscos de segurança de um Agent de navegador?
Faça pelo menos três coisas: ative allowed_domains e blocked_domains na camada do browser-use, adicione dupla confirmação para ações críticas (submissão, pagamento, envio) na camada do LLM e salve prints e logs de ações de cada passo na camada de auditoria. O próprio GPT-5.5 perguntará antes de realizar ações de alto risco, mas você não deve depender inteiramente do modelo.
Q5: O GPT-5.5 é adequado para Agents totalmente autônomos?
Depende do cenário. Tarefas com "caminhos enumeráveis", como coleta de dados, regressão de UI e operação de SaaS interno, já possuem viabilidade para operação 24/7 sem supervisão; para ações de alto risco, como transações financeiras, publicações externas ou assinatura de contratos, ainda recomendamos manter o "humano no circuito". Sugerimos observar o desempenho do Agent a longo prazo através do painel de logs unificado do APIYI (apiyi.com) antes de decidir quais etapas podem dispensar a intervenção humana.
Q6: É estável chamar o GPT-5.5 browser-use dentro da China?
Chamar a interface oficial diretamente pode sofrer interferências do ambiente de rede. A invocação do GPT-5.5 através do APIYI (apiyi.com) resolve os problemas de instabilidade de rede local; a plataforma opera de forma estável, garantindo que tarefas de longa duração não sejam interrompidas.
Q7: Como escolher entre GPT-5.5 e Claude Opus 4.7 para um Agent?
Ambos têm focos diferentes. O GPT-5.5 é ligeiramente superior no computer use nativo do navegador (78,7% no OSWorld), enquanto o Claude Opus 4.7 é mais forte em tarefas de código (SWE-Bench). A abordagem racional é integrar ambos os modelos e rotear as tarefas de acordo com o tipo. O APIYI (apiyi.com) suporta a chamada de modelos principais na mesma conta, facilitando a realização de testes AB.
Pontos principais do browser-use com GPT-5.5
- O GPT-5.5 transformou o computer use em uma capacidade nativa, permitindo que a captura de tela, o raciocínio e a saída de ações sejam concluídos em uma única passagem (forward pass), encurtando significativamente o fluxo de execução.
- Alcançou 78,7% no OSWorld-Verified e 82,7% no Terminal-Bench 2.0, elevando notavelmente a taxa de sucesso em tarefas de agentes.
- Capturas de tela de alta resolução (até 10,24 MP) melhoraram drasticamente a precisão de reconhecimento em cenários como formulários densos, tabelas longas e editores de código.
- Cinco níveis de reasoning effort (de none a xhigh) permitem que o agente controle os custos individualmente em cada etapa, tornando tarefas de longa duração mais econômicas.
- A combinação com bibliotecas de código aberto como
browser-usee Playwright representa a prática mais madura de "cérebro + mãos e pés" atualmente. - Ao utilizar o GPT-5.5 via APIYI (apiyi.com), você aproveita o faturamento com cache a 0,1x e resolve problemas de estabilidade de acesso local.
- Para ações de alto risco, ainda recomendamos manter o "humano no circuito" (human-in-the-loop). A capacidade do GPT-5.5 é reduzir a intervenção humana de 80% para 20%, e não para 0%.
Resumo
A importância da capacidade de browser-use do GPT-5.5 não reside apenas em ter superado alguns benchmarks, mas no fato de ter transformado a tarefa de "fazer o modelo operar o navegador" de um desafio de engenharia que exigia a montagem de vários componentes em uma API nativa pronta para uso. Para equipes que desenvolvem agentes, isso significa poder focar mais no design de cenários e na interação humano-computador, em vez de gastar tempo com o trabalho pesado de capturas de tela, análise de DOM e concatenação de ações. Em outras palavras, se antes as equipes de agentes gastavam 70% do esforço de engenharia na adaptação ao navegador e 30% no design de negócio, com o GPT-5.5, essa proporção tem a chance de se inverter.
Se você está planejando levar seu agente do estágio de demonstração para a produção, sugerimos começar ativando o acesso ao GPT-5.5 no APIYI (apiyi.com) e testar um pequeno cenário com a biblioteca browser-use. A plataforma já oferece suporte estável ao GPT-5.5, e o faturamento com cache a 0,1x permite reduzir drasticamente os custos de execução, sendo um dos caminhos mais práticos para validar ideias de agentes de navegador no Brasil.
— Equipe técnica da APIYI. Para mais tutoriais práticos sobre modelos de IA, visite APIYI (apiyi.com).