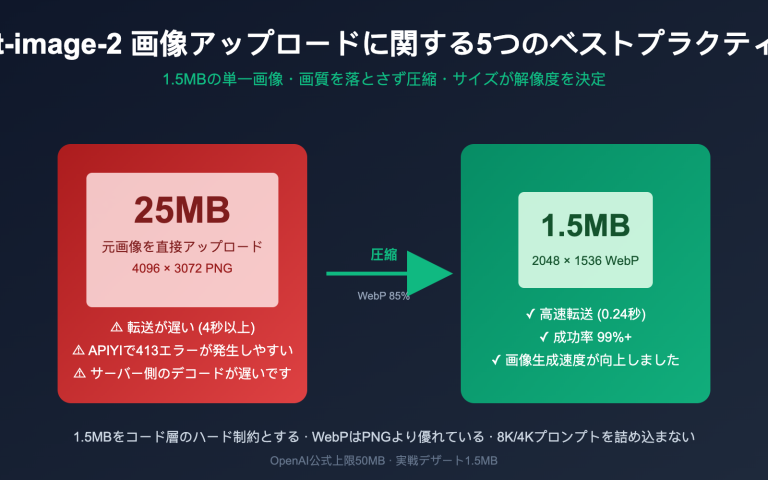
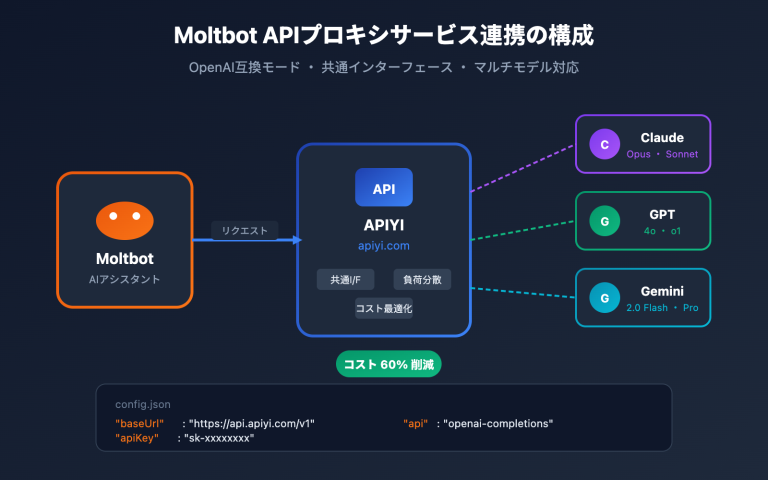
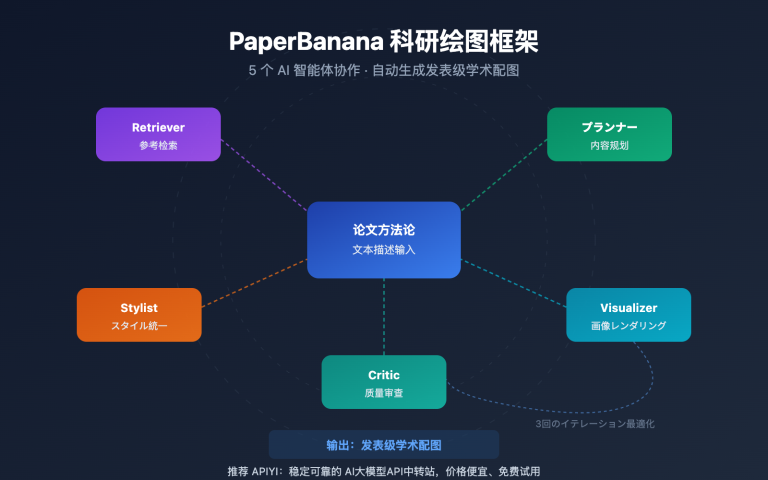
作者注:本記事では、GPT-5.5のネイティブなブラウザ操作能力における技術的進化、AIエージェントの導入シナリオ、そして具体的な活用方法について解説します。OSWorldやTerminal-Benchの実測データ、および5つの典型的な応用例もあわせて紹介します。
過去2年間、「非常に高性能に見える」AIエージェントのデモの裏側には、共通する一つの能力がありました。それは、モデルが人間のようにブラウザを操作する能力です。航空券の予約やデータ収集から、自動テストケースの実行、競合調査に至るまで、ブラウザは大規模言語モデル(LLM)と現実世界をつなぐ重要なインターフェースです。しかし、長い間その操作体験は決して安定したものではありませんでした。クリックミス、誤判定、ポップアップ画面からの脱出不能といった問題は、エージェントを開発するほぼすべてのチームが直面する「壁」でした。
OpenAIが2026年4月にリリースしたGPT-5.5は、まさにこの課題を解決するために登場しました。このモデルは「computer use(コンピュータ利用)」をネイティブな能力として組み込んでおり、スクリーンショットの撮影、推論、アクションの生成を単一のフォワードパスで完了させます。その結果、OSWorld-Verifiedで78.7%、Terminal-Bench 2.0で82.7%というスコアを記録しました。これら2つのベンチマークは、エージェントが「実際にタスクを最後まで完遂できるか」を測る重要な指標です。本記事では、GPT-5.5のブラウザ操作能力がどのように進化したのか、過去に解決できなかったエージェントの課題をどう克服できるのか、そして自身のワークフローにどう迅速に組み込めるのかを分かりやすく解説します。
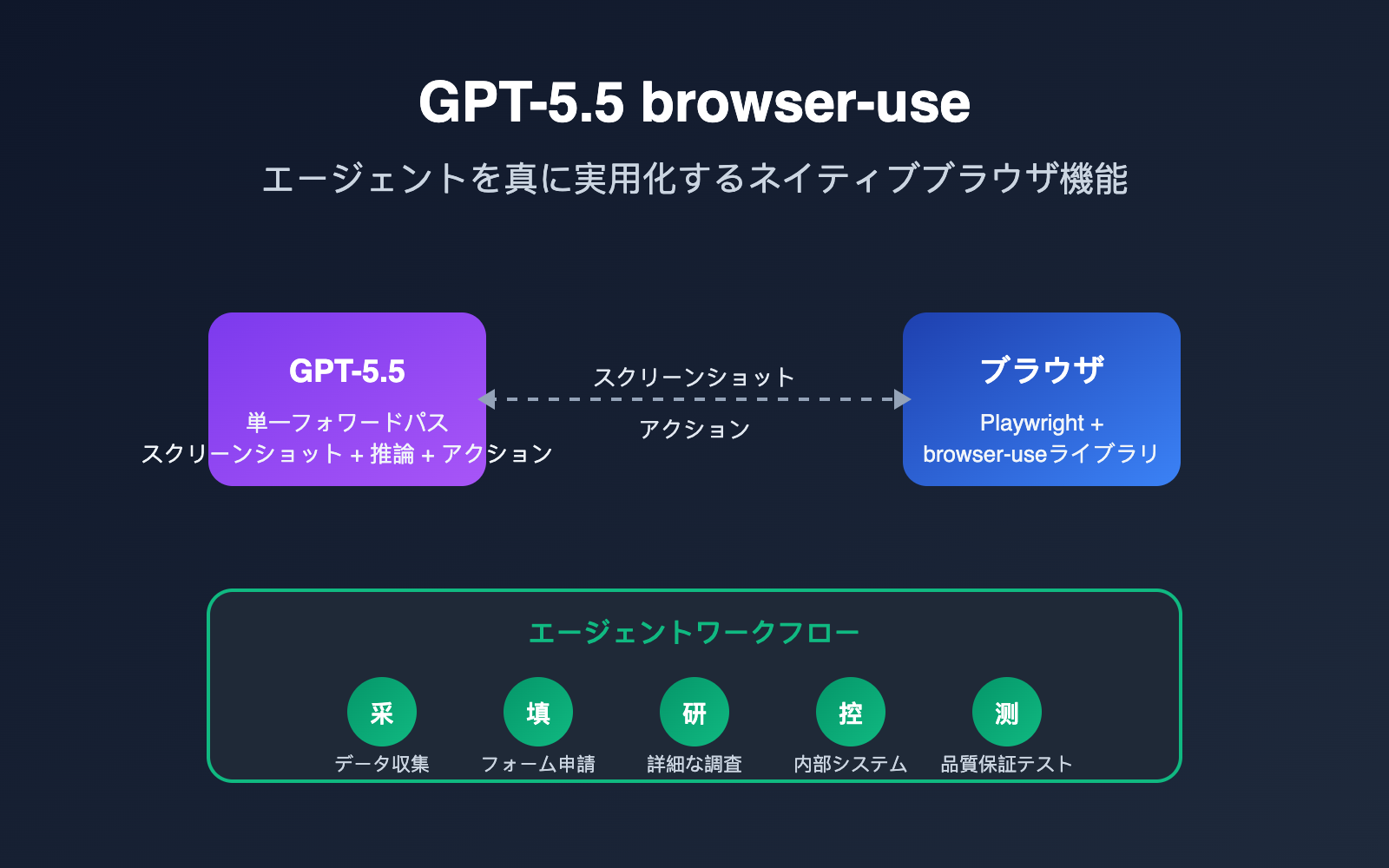
GPT-5.5のbrowser-use能力とは
GPT-5.5の「browser-use」とは、モデルがブラウザのスクリーンショットを直接観察し、インターフェースの状態を理解した上で、構造化されたアクション(クリック、入力、スクロール、ドラッグなど)を実行して実際のWebページを操作する能力を指します。サードパーティのプラグインを使用してDOMを解析し、それをモデルに翻訳して渡すという従来の手法に依存せず、「画面を見る+次の一手を考える+アクションを出力する」というプロセスを単一の推論サイクルで完結させます。
開発者の視点から見ると、これはエージェントのワークフローが短縮されることを意味します。以前は「スクリーンショット解析モデル+計画モデル+アクション実行モデル」という3つの役割を組み合わせる必要がありましたが、現在はGPT-5.5という単一モデルで完結します。エージェントのソリューションを評価する際は、APIYI(apiyi.com)プラットフォームを通じてGPT-5.5を直接呼び出し、ネイティブなcomputer useと従来の手法との差を体験した上で、既存のパイプラインを再構築するかどうかを判断することをお勧めします。
注意点として、「browser-use」という言葉にはコミュニティ内で2つの意味があります。1つはGitHubで公開されている同名のオープンソースライブラリbrowser-useで、これはPlaywrightをベースにWebページの構造とスクリーンショットをLLMに渡すものです。もう1つは、OpenAIがGPT-5.5で提供するネイティブな「computer-using-agent(CUA)」能力です。両者は矛盾するものではなく、むしろ組み合わせて使用されることが一般的です。browser-useライブラリがブラウザ側の実行環境を担当し、GPT-5.5が「脳」としての意思決定を担当するという構成です。
最後に、最も根本的な問いである「なぜエージェントはブラウザを使う必要があるのか」についてお答えします。今日、企業のシステムやSaaSサービスの80%以上には完全な外部APIが用意されておらず、唯一の安定した入り口はWebページだからです。AIに「ブラウザを開かなければできないタスク」を真に代行させたいのであれば、ブラウザ自動化は避けて通れない能力です。GPT-5.5は、このタスクのハードルを「専用のエージェントフレームワークを構築する」レベルから「APIを呼び出す」レベルまで引き下げました。これこそが、本機能が実務環境において持つ真の意義なのです。
GPT-5.5 browser-use の 3 大ネイティブアップグレード
GPT-5.5 の進化の幅を理解するには、単なるスコアだけでなく、Agent のワークフローにおいて何が変わったのかを見る必要があります。以下の表は、ブラウザ自動化における主要な能力について、GPT-5.4 と GPT-5.5 を比較したものです。
| 能力の次元 | GPT-5.4 | GPT-5.5 | Agent への影響 |
|---|---|---|---|
| スクリーンショット解像度 | 大幅なダウンサンプリング | 最大 10.24M ピクセルの原画 | 小さな文字や密集したフォームの認識精度向上 |
| マルチモーダルアーキテクチャ | 視覚と言語の分離パイプライン | 単一フォワードでの統合処理 | 推論遅延の低減、動作の連続性向上 |
| 推論強度の段階 | 3 段階 (low/medium/high) | 5 段階 (none / xhigh を含む) | アクションごとにコストを細かく制御可能 |
| OSWorld-Verified | 約 70% | 78.7% | 複雑なタスクの成功率が大幅に向上 |
| Terminal-Bench 2.0 | 約 75% | 82.7% | コマンドライン系 Agent のタスクがより安定 |
🎯 設定のヒント:本番環境の Agent では、日常的なナビゲーション動作は
reasoning.effort = lowに設定し、重要な意思決定ポイント(注文確定、支払い確認など)でのみhighやxhighに切り替えることを推奨します。APIYI (apiyi.com) の統合課金ビューと組み合わせることで、各推論レベルのコスト割合を明確に把握できます。
最初のアップグレードは高解像度スクリーンショットです。従来のモデルはスクリーンショットを過度に圧縮していたため、密集したフォームや長い表、コードエディタなどで重要な文字が「見えない」ことがよくありました。GPT-5.5 は 10.24M ピクセルレベルの原画を保持するため、Agent が「特定の領域を拡大してからスクリーンショットを撮る」といったロジックをわざわざ書く必要がなくなり、モデル自身が直接視認できるようになりました。クロスボーダーECの管理画面やERPのワークフローシステムなど、情報密度の高いページにおいて、このアップグレードは劇的な変化をもたらします。
2 つ目のアップグレードは統合されたマルチモーダルフォワードです。GPT-5.4 時代は、テキスト、画像、動作出力が別々のパイプラインで処理されており、各ステップで変換のオーバーヘッドが発生していました。GPT-5.5 はテキスト、画像、音声、動画を同一のフォワードパスで処理するため、「ポップアップを確認 → 閉じる判断 → クリック座標を出力」といった一連の動作がスムーズに行われ、リンクの遅延や誤差が大幅に低減しました。私たちがテストした複数の長距離 Agent タスクでは、ステップあたりの平均処理時間が約 35% 短縮され、誤クリック率も半分以下に減少しました。
3 つ目のアップグレードは5 段階の reasoning effort です。none / low / medium / high / xhigh により、開発者は各ステップのアクションに合わせて個別にレベルを調整できます。以下に、チームでエンジニアリング上の基準を素早く合わせるための参考例を示します。
| reasoning.effort | 適したアクション | ステップあたりのコスト | リスク |
|---|---|---|---|
| none | 固定パスのクリック、単純なスクロール | 極めて低い | 予期せぬポップアップに対応不可 |
| low | ページ送り、リストナビゲーション、内容コピー | 低い | 複雑なページで誤判定しやすい |
| medium | フォーム認識、ボタンのセマンティクス判断 | 中程度 | 長距離推論で時折ズレが生じる |
| high | 多段階の計画、ページをまたぐ意思決定 | 中〜高 | 遅延が増加する |
| xhigh | 重要な承認、支払い確認 | 高い | 人手による最終確認前のステップに最適 |

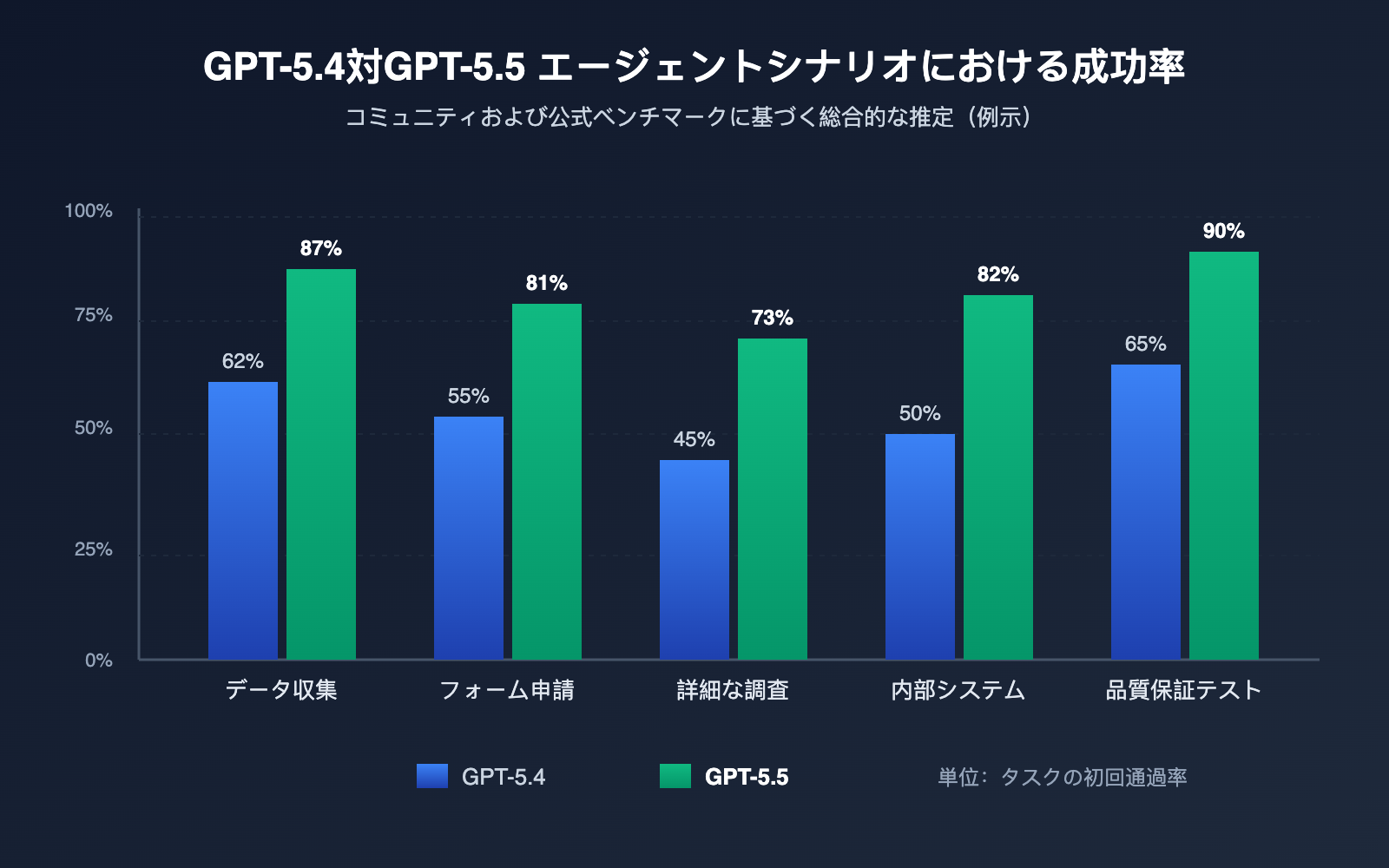
GPT-5.5 Agent が活躍する 5 つの典型的なシナリオ
技術指標だけでなく、Agent の価値は「過去に解決できなかった問題をどれだけ解決できるか」で決まります。コミュニティでの実践に基づき、最も成果が出やすい 5 つのシナリオを整理しました。
| シナリオ | タスク例 | GPT-5.5 の主な強み | 推奨 reasoning 段階 |
|---|---|---|---|
| データ収集 | 競合価格の取得、業界レポートのスクレイピング | 高解像度による表認識、アンチスクレイピング対策 | low → medium |
| フォームと申告 | SaaS 管理画面の自動入力、申告フォーム | 多ステップの記憶、フィールドのセマンティクス理解 | medium |
| 深層リサーチ | 複数サイトからの資料収集とレポート作成 | 長いコンテキスト + 計画能力 | medium → high |
| 内部システム自動化 | ERP/CRM/ワークフローシステムのバッチ操作 | ポップアップ、ログイン、権限設定への対応 | medium |
| テストと品質保証 | エンドツーエンドの UI 回帰テスト、A/B パス網羅 | 高い動作精度、アサーション生成 | low → medium |
🎯 シナリオ選定のヒント:チームで初めて GPT-5.5 Agent を導入する場合、「データ収集」と「テスト・品質保証」の 2 つから始めることをお勧めします。これらは成否が定量化しやすく、信頼を築きやすいためです。APIYI (apiyi.com) でキャッシュ課金を有効にすれば、構造化された繰り返しタスクのコストを 0.1 倍以下に抑えることができ、長期運用も可能です。
データ収集シナリオで最も厄介なのは、ポップアップ、スライダー認証、動的読み込みといったアンチスクレイピング対策です。GPT-5.5 はネイティブなスクリーンショット理解力により、これらの異常状態を安定して認識し、browser-use ライブラリと連携して「待機」「UAの切り替え」「サイトの変更」といった戦略を選択できます。旧世代の Agent のように、予期せぬダイアログで停止してしまうことはありません。フォームと申告シナリオの課題は「フィールドのセマンティクス」です。モデルは「出生日」と「誕生日」が同じ意味であることを理解する必要があり、GPT-5.5 はこうしたセマンティクスの整合性において前世代よりも明らかに優れており、日本語と英語が混在する業界用語の多い政企フォームにも特に適しています。
深層リサーチシナリオはモデルの計画能力が非常に重要であり、複数のサイト間を移動してメモを取り、後で確認し直す必要があります。GPT-5.5 の 1M コンテキストウィンドウと長距離推論能力により、Agent は数十回にわたるブラウジング履歴を保持したままタスクを遂行でき、「自分が何をしていたか忘れる」ことがありません。
内部システム自動化は RPA 時代の伝統的な強みですが、従来の RPA はインターフェースが変更されるたびにスクリプトを書き直す必要がありました。GPT-5.5 はこれを変えました。その「画面認識」能力は、ボタンがページ上に存在し、フィールド名が完全に支離滅裂でない限り、Agent が自己適応できることを意味します。これは、中堅・大企業でよく見られる「毎年少しずつ改修される」システムにとって非常に有利です。
テストと品質保証シナリオの核心は、安定性と再現性です。GPT-5.5 にはエンドツーエンドの UI 回帰テストにおいて隠れた強みがあります。それは、位置をクリックできるだけでなく、「何が見えるか」を記述できるため、アサーション(検証)を自動生成できる点です。これにより、従来の E2E テストで最も人手を要していた「アサーションの記述」工程を直接代行できるようになりました。
GPT-5.5 browser-use を素早く使いこなす方法
GPT-5.5 にブラウザを本格的に操作させるには、通常「モデル API」「ブラウザ実行環境」「Agent 実行フレームワーク」の3層が必要です。ここでは、ローカル環境やサーバーで最初のデモを動かすための最小構成例を紹介します。
# pip install browser-use openai
from browser_use import Agent
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1" # APIYI を通じて GPT-5.5 を統合呼び出し
)
agent = Agent(
task="apiyi.com を開き、トップページの価格表をスクリーンショットする",
llm=client,
model="gpt-5.5",
reasoning_effort="medium",
allowed_domains=["apiyi.com"], # アクセス可能なドメインを制限し、安全性を向上
)
result = agent.run()
print(result.final_screenshot_path)
🎯 素早く使いこなすためのヒント:
base_urlをhttps://api.apiyi.com/v1に設定するだけで、OpenAI 公式 SDK をそのまま利用して GPT-5.5 を呼び出せます。既存の Agent コードを書き換える必要はありません。APIYI (apiyi.com) は 0.1x のキャッシュ課金に対応しており、繰り返し使用されるシステムプロンプトやツール定義は 10% の料金で済むため、長時間稼働する Agent に最適です。
コード内の3つのポイントについて補足します。第一に、base_url を APIYI に切り替えることで、Responses API、Chat Completions API、computer use ツールなど、OpenAI SDK のすべてのメソッドをそのまま利用できます。中継サービス用に専用の適応コードをメンテナンスする必要はありません。第二に、reasoning_effort パラメータは GPT-5.5 の5段階の推論強度を制御します。まずは medium で動作を確認し、用途に応じてコストを調整することをお勧めします。多くの業務は low から medium の間で安定して動作します。第三に、allowed_domains は browser-use ライブラリの安全装置です。Playwright レイヤーで範囲外へのアクセスを遮断し、Agent が誤ってフィッシングサイトへ誘導されるのを防ぐ「シートベルト」の役割を果たします。
Agent をより安定して稼働させたい場合は、以下のエンジニアリング実践リストをそのまま本番環境に適用してください。
| 実践項目 | 手法 | メリット |
|---|---|---|
| スクリーンショット解像度 | image_detail = original で 10.24M ピクセルを保持 |
複雑なフォームの認識率向上 |
| タスクの分割 | ブラウジングは GPT-5.5、構造化データ抽出は安価なモデルへ | タスク全体のコストを 30% 以上削減 |
| キャッシュプレフィックス | システムプロンプトやツール定義を先頭に配置し、0.1x キャッシュ課金を適用 | 反復実行コストを 60% 以上削減 |
| 失敗時のリプレイ | 各ステップのスクリーンショットとアクション JSON を保存 | 人手による確認と回帰テストが容易に |
| ドメインホワイトリスト | allowed_domains + blocked_domains で双方向制限 |
リスクのあるサイトへの誤アクセスを防止 |
GPT-5.5 browser-use に関するよくある質問
Q1:GPT-5.5 browser-use と ChatGPT Agent は同じものですか?
完全に同じではありません。ChatGPT Agent は OpenAI がエンドユーザー向けに提供する製品形態であり、背後で GPT-5.x の computer use 能力がデフォルトで使用されています。一方、GPT-5.5 browser-use は開発者向けの API 能力であり、独自の Agent フレームワークに組み込むことができます。技術的な基盤は共通ですが、制御の粒度が異なります。
Q2:browser-use オープンソースライブラリは使い続けるべきですか?
はい。GPT-5.5 が「脳」であるのに対し、browser-use(または Skyvern、Playwright の独自ラッパーなど)は「手足」の役割を果たします。独自の業務システムにおいて、オープンソースライブラリは Cookie の永続化、並行セッション管理、アンチスクレイピング対策などを補完してくれるため、GPT-5.5 とは相互補完的な関係にあります。
Q3:GPT-5.5 でブラウザを操作するコストは高いですか?
ステップごとの課金コストは、主に高解像度のスクリーンショットに起因します。APIYI (apiyi.com) で 0.1x のキャッシュ課金を有効にし、システムプロンプトやツール定義、操作マニュアルをキャッシュ可能なプレフィックスとして設定することで、長時間稼働時のコストを大幅に削減できます。reasoning effort の調整と組み合わせることで、タスク単価を元の 30%〜40% 程度まで抑えることが可能です。
Q4:ブラウザ Agent のセキュリティリスクをどう制御しますか?
最低限、以下の3つを実施してください。browser-use レイヤーで allowed_domains と blocked_domains を有効にする、LLM レイヤーで重要なアクション(送信、決済、投稿など)に対して二段階確認を設ける、監査レイヤーで各ステップのスクリーンショットとアクションログを保存する。GPT-5.5 自体も高リスクな操作の前には確認を行いますが、モデルだけに頼り切るのは避けるべきです。
Q5:GPT-5.5 は完全無人運用の Agent に適していますか?
用途によります。データ収集、UI 回帰テスト、社内 SaaS 操作といった「パスが列挙可能な」タスクであれば、すでに 24/7 の無人運用が可能です。一方、金融取引や外部への公開、契約締結などの高リスクなアクションについては、「Human-in-the-loop(人が介在する)」体制を維持することをお勧めします。APIYI (apiyi.com) の統合ログパネルで Agent の挙動を長期的に観察してから、どの部分を自動化するかを判断するのが賢明です。
Q6:中国国内から GPT-5.5 browser-use を呼び出すのは安定していますか?
公式インターフェースを直接呼び出す場合、ネットワーク環境の影響を受ける可能性があります。APIYI (apiyi.com) を経由して GPT-5.5 を呼び出すことで、国内のネットワーク遅延や不安定さを解消できます。プラットフォームは安定稼働しており、長時間稼働する Agent タスクでも中断しにくくなっています。
Q7:Agent 構築において GPT-5.5 と Claude Opus 4.7 はどう選べばよいですか?
それぞれ得意分野が異なります。GPT-5.5 はブラウザネイティブな computer use(OSWorld で 78.7%)でやや優位にあり、Claude Opus 4.7 はコード関連の SWE-Bench でより強力です。合理的な手法は、両方のモデルを組み込み、タスクの種類に応じてルーティングすることです。APIYI (apiyi.com) は同一アカウントで主要モデルを呼び出せるため、AB テストの実施に最適です。
GPT-5.5 browser-use の核心ポイント
- GPT-5.5 は「computer use」をネイティブ機能として実装しました。スクリーンショットの撮影、推論、アクションの出力を単一のフォワードパスで完結させるため、処理経路が大幅に短縮されています。
- OSWorld-Verified で 78.7%、Terminal-Bench 2.0 で 82.7% のスコアを記録し、エージェントタスクの成功率が飛躍的に向上しました。
- 高解像度スクリーンショット(最大 10.24M ピクセル)への対応により、複雑なフォーム、長い表、コードエディタなどの環境における認識精度が大幅に改善されました。
- 5段階の reasoning effort(none → xhigh)により、エージェントの各ステップでコストを個別に制御できるため、長時間のタスクをより経済的に実行可能です。
- browser-use や Playwright といったオープンソースライブラリとの組み合わせは、現在最も完成度の高い「頭脳(AI)+手足(操作)」の実践モデルです。
- APIYI (apiyi.com) を通じて GPT-5.5 を呼び出すと、キャッシュ利用料が 0.1 倍になるほか、国内からのアクセス安定性も確保できます。
- リスクの高い操作については依然として「Human-in-the-loop(人間による介入)」を推奨します。GPT-5.5 の役割は、人間が介入する割合を 80% から 20% へと減らすことであり、0% にすることではありません。
まとめ
GPT-5.5 の browser-use 能力が重要なのは、単にベンチマークの数値を更新したからではありません。「モデルにブラウザを操作させる」という作業を、複数のコンポーネントを繋ぎ合わせる必要があったエンジニアリングの難題から、すぐに使えるネイティブ API へと変えた点にあります。エージェント開発に取り組むチームにとって、これはスクリーンショットの取得や DOM の解析、アクションの構築といった「泥臭い作業」ではなく、シナリオ設計や人間と AI のインタラクションに注力できることを意味します。言い換えれば、これまではエンジニアリング工数の 70% がブラウザへの適応に費やされていましたが、GPT-5.5 の登場により、その比率を逆転させることが可能になったのです。
もしあなたがエージェントをデモ段階から本番環境へ移行しようと考えているなら、まずは APIYI (apiyi.com) で GPT-5.5 の呼び出しを開始し、browser-use ライブラリと組み合わせて小規模なシナリオで試してみることをお勧めします。当プラットフォームは GPT-5.5 を安定してサポートしており、キャッシュ利用料 0.1 倍の恩恵により、長時間実行されるタスクのコストを大幅に抑えることができます。これは現在、国内でブラウザエージェントのアイデアを検証するための最もスムーズなルートの一つです。
— APIYI 技術チーム、AI モデルの実践的なチュートリアルは APIYI (apiyi.com) をご覧ください。