Recentemente, um colega desenvolvedor perguntou no grupo: "O gpt-image-2 consegue gerar imagens a partir de arquivos CSV ou Excel? Vi no TikTok alguém usando um modelo de imagem para gerar PPTs e queria saber se ele consegue ler arquivos." A resposta é direta: não. O gpt-image-2, lançado pela OpenAI em abril de 2026, aceita apenas comandos de texto e imagens como entrada; ele não lê arquivos CSV/Excel, nem exporta arquivos PPTX/PDF.
Mas isso não significa que o caminho esteja bloqueado. Extrair o conteúdo do arquivo para texto, tirar prints das páginas e enviar para o gpt-image-2 é, na verdade, o fluxo de trabalho padrão atual. Este artigo esclarece os limites do upload de arquivos no gpt-image-2 e apresenta 5 soluções alternativas para que você possa entregar as demandas que seus clientes achavam impossíveis.
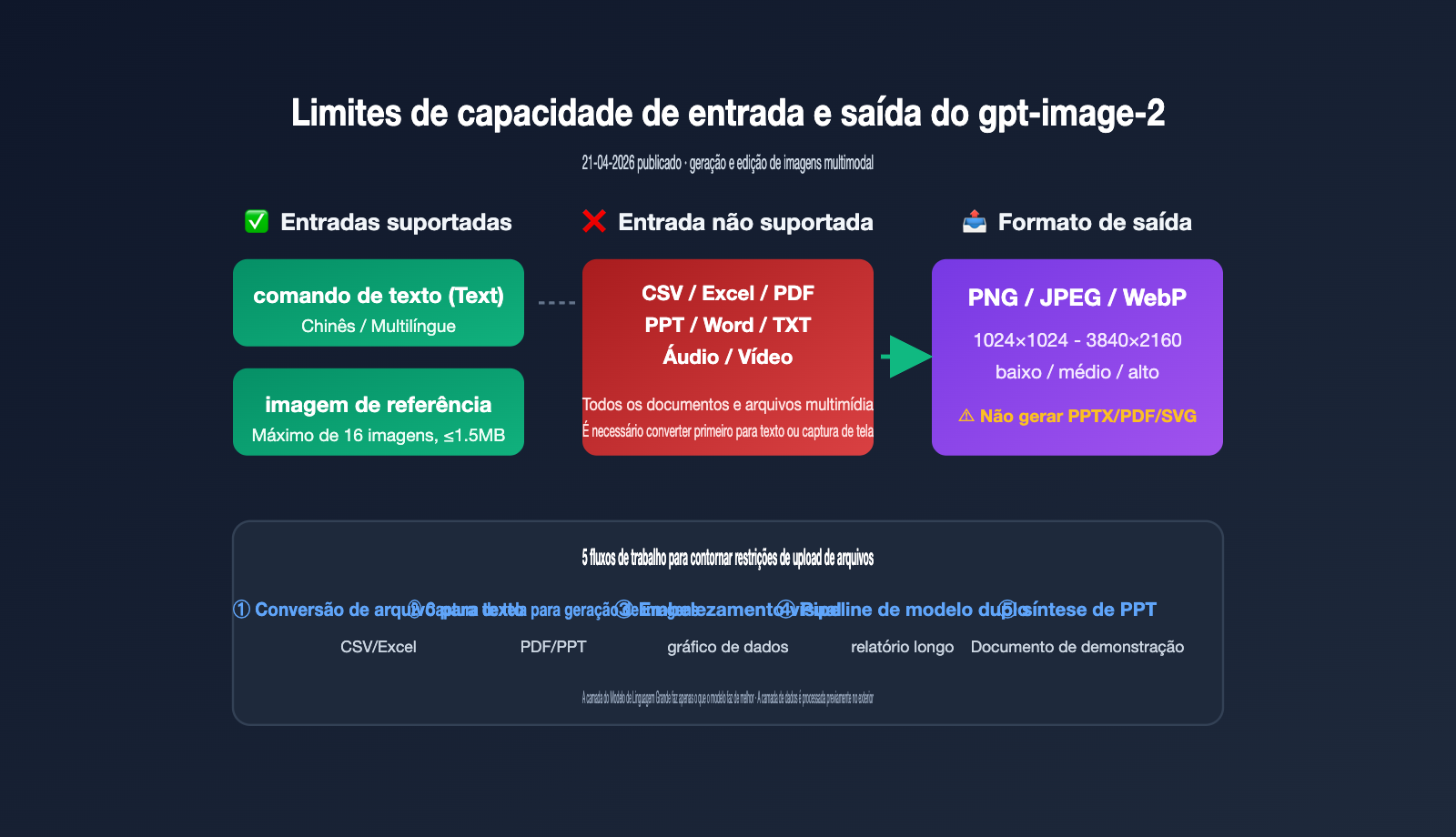
Status do suporte a upload de arquivos no gpt-image-2: entradas apenas de texto e imagem
Primeiro, vamos definir os limites oficiais, pois todas as soluções posteriores se baseiam neles. De acordo com a documentação da OpenAI, o gpt-image-2 (snapshot gpt-image-2-2026-04-21) é um modelo multimodal nativo de geração de imagens. A tabela de suporte a modalidades define claramente o escopo:
| Tipo de Modalidade | Suporta Entrada | Suporta Saída | Observação |
|---|---|---|---|
| Texto (text) | ✅ Sim | ❌ Não | Usado como comando, aceita múltiplos idiomas |
| Imagem (image) | ✅ Sim | ✅ Sim | Entrada para edição/referência, saída PNG/JPEG/WebP |
| Áudio (audio) | ❌ Não | ❌ Não | Irrelevante para geração de imagens |
| Vídeo (video) | ❌ Não | ❌ Não | Irrelevante para geração de imagens |
| Documentos (CSV/Excel/PDF/Word/PPT) | ❌ Não | ❌ Não | Não aceita upload nem exporta arquivos |
Em resumo, o gpt-image-2 não é um "cérebro universal" como o GPT-4; ele é especializado em geração e edição de imagens, por isso a OpenAI não implementou um canal de análise para CSV/Excel/PDF. Se você enviar o binário de um Excel, a API retornará um erro 400. Se o seu projeto precisa de um canal de invocação do modelo estável e com alto RPM, recomendamos o uso de plataformas de serviço proxy de API como a APIYI (apiyi.com), que já documenta as validações de entrada e limites de parâmetros, evitando erros comuns para iniciantes.
🎯 Conceito-chave: O limite do gpt-image-2 é "texto + imagem → imagem". Não o trate como um agente completo. Demandas relacionadas a arquivos devem ser resolvidas com outras ferramentas na camada externa, enquanto a camada de proxy (como a APIYI) garante a estabilidade da invocação e a camada de negócio cuida do pré-processamento dos dados.
Por que "geração de PPT" e "geração de imagem a partir de arquivos" são coisas diferentes
Muitos clientes confundem "geração de PPT com um clique" com "modelo que lê arquivos para gerar imagens", mas são fluxos de trabalho distintos. Os casos de automação de PPT vistos no TikTok ou redes sociais são quase sempre pipelines de várias etapas: primeiro, usa-se um Modelo de Linguagem Grande para destilar os dados em texto, depois um modelo de imagem para gerar as ilustrações de cada página e, por fim, um programa para montar o arquivo PPTX.
A etapa responsável pela geração da imagem geralmente usa um modelo como o gpt-image-2. Ele apenas processa o comando de texto e a imagem de referência recebidos, sem saber se a origem era um Excel ou um Notion. Entendido isso, as 5 soluções tornam-se lógicas.
Quais as melhorias em relação ao gpt-image-1?
Muitos usuários antigos perguntam: já que não aceita arquivos, o que torna o gpt-image-2 melhor que o gpt-image-1? A diferença é crucial e determina se a estratégia de "usar prints como entrada" funcionará. A nova versão traz avanços significativos em renderização de texto, número de imagens de referência e capacidade de raciocínio.
| Dimensão de Capacidade | gpt-image-1 | gpt-image-2 |
|---|---|---|
| Máximo de imagens de referência | 4 | 16 (recomendado ≤4 para melhor resultado) |
| Renderização de texto | Bom em inglês, falha em outros | Precisão muito maior em múltiplos idiomas |
| Capacidade de raciocínio | Nenhuma | Modo de pensamento integrado para layouts complexos |
| Corte de conhecimento | Início de 2024 | Dezembro de 2025 |
| Resolução de saída | Máx. 1024×1024 | Máx. 3840×2160 (4K) |
Ou seja, se você não obteve bons resultados com o gpt-image-1 ao processar "prints para mudar o estilo", vale a pena testar novamente com o gpt-image-2, especialmente em cenários como pôsteres ou slides de PPT que exigem renderização precisa de texto.
5 fluxos de trabalho para gerar imagens a partir de arquivos com o gpt-image-2
Estes 5 fluxos de trabalho atendem a diferentes fontes de dados e cenários de aplicação. A escolha depende do tipo de arquivo, do formato de saída e do nível de automação desejado. Listamos abaixo, do mais simples ao mais complexo.
Solução 1: Converter arquivo em comando de texto e enviar diretamente ao gpt-image-2
Ideal para dados estruturados como CSV, Excel, JSON e texto puro. O processo consiste em usar scripts (pandas, openpyxl) para ler o arquivo, combinar cabeçalhos, linhas cruciais e indicadores estatísticos em uma descrição em linguagem natural e, em seguida, chamar o endpoint /v1/images/generations usando essa descrição como prompt. Por exemplo, resumir dados de vendas como: "Gráfico de barras de vendas do Q1 de 2026 em três grandes regiões: Leste 12 milhões, Norte 9,8 milhões, Sul 7,6 milhões, estilo executivo escuro".
A vantagem é a simplicidade, sem necessidade de entrada de imagem. A desvantagem é que o prompt tem um limite de informações. O gpt-image-2 é bom, mas não perfeito, na precisão numérica; é preciso especificar os valores de cada barra no comando, caso contrário, o modelo redistribuirá as alturas com base na estética visual.
Solução 2: Captura de tela da página do arquivo como imagem de referência
Ideal para PDFs, PPTs com layout definido, relatórios web e conteúdos que "já possuem um formato visual". Converta a página desejada em PNG (usando ferramentas como a Pré-visualização do macOS, pdftoppm ou Puppeteer) e envie-a através do endpoint /v1/images/edits como parâmetro image, combinada com um prompt descrevendo as alterações, como: "Mantenha o layout, altere o título de inglês para português e transforme o gráfico de barras para o estilo Apple".
No modelo de 2026, o gpt-image-2 aceita até 16 imagens de referência, mas tanto a equipe oficial quanto a comunidade recomendam usar 1 imagem de referência principal + 1 ou 2 imagens de estilo. Exceder isso pode diluir a atenção do modelo. Recomenda-se manter cada imagem abaixo de 1,5 MB para evitar um aumento significativo no consumo de tokens de entrada.
Solução 3: Visualização de dados primeiro, depois embelezamento com gpt-image-2
Ideal para cenários de visualização de dados que buscam "precisão e estética". Primeiro, crie uma versão básica do gráfico usando matplotlib, ECharts ou os gráficos nativos do Excel e exporte como PNG. Em seguida, use essa imagem como entrada para o gpt-image-2 com o prompt: "Mantenha a posição dos pontos de dados e os valores inalterados, altere o estilo do gráfico para escuro, com destaques em neon e estilo infográfico".
Esta é a abordagem mais robusta para combinar gráficos de dados com o embelezamento por IA. Os valores originais são garantidos por bibliotecas de plotagem determinísticas, enquanto o estilo visual é remodelado pelo gpt-image-2. Se você precisa automatizar esse fluxo em lote, recomendo usar o gpt-image-2 via APIYI (apiyi.com), que gerencia o pool de contas upstream para cenários de alta concorrência de 5000 RPM, ideal para tarefas de milhares de imagens por dia.
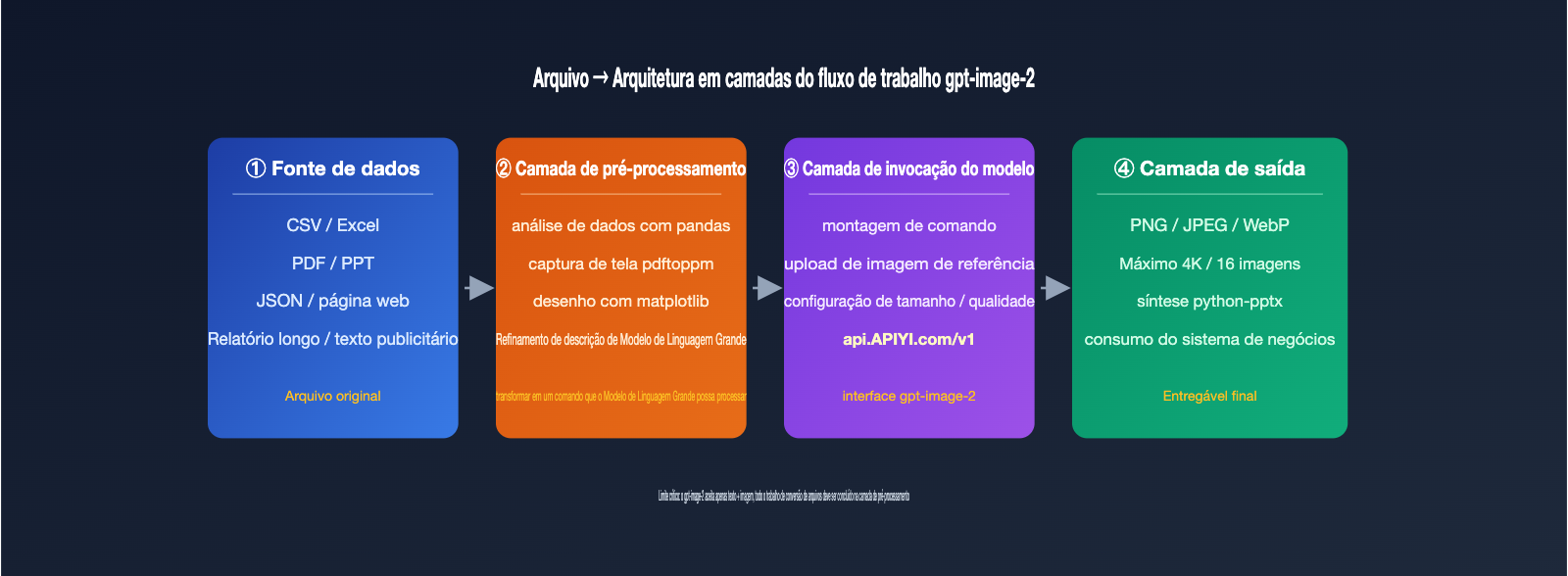
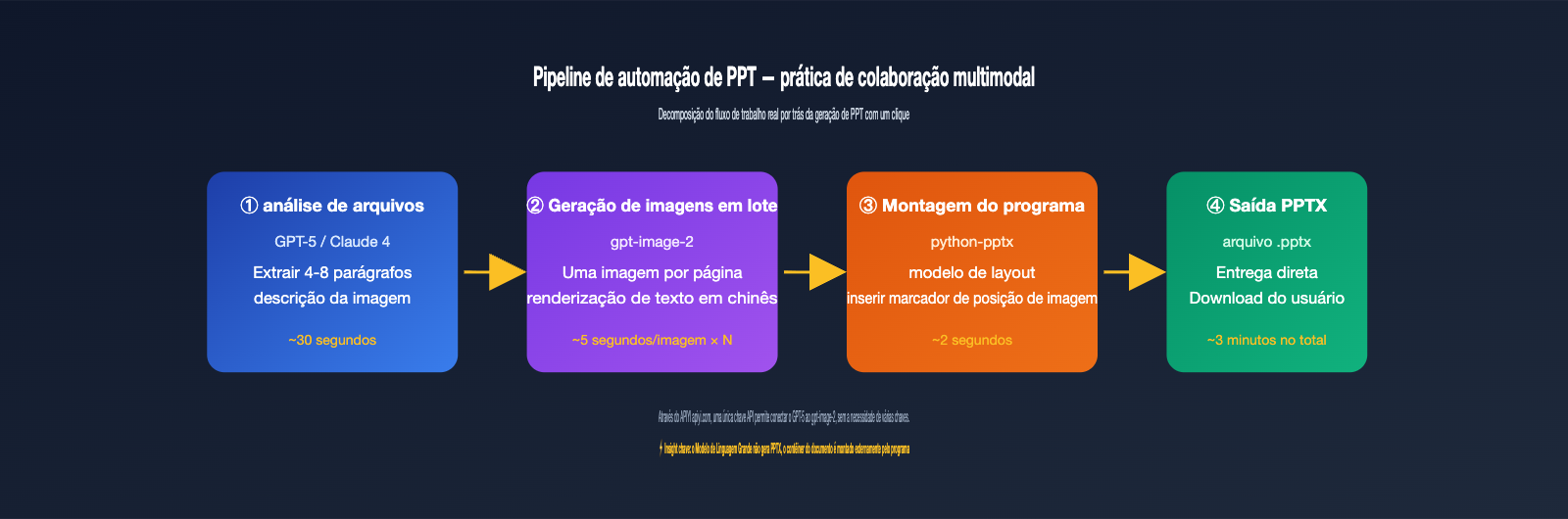
Solução 4: Pipeline de modelo duplo LLM + gpt-image-2
Ideal para arquivos com conteúdo complexo que exigem compreensão semântica, como relatórios longos, resumos de contratos ou textos de produtos. Primeiro, use a série GPT-4 ou Claude 4 para ler e entender o arquivo, extraindo de 4 a 8 descrições de cenas e, em seguida, chame o gpt-image-2 repetidamente para gerar as imagens correspondentes.
A chave aqui é desacoplar a "compreensão semântica" da "geração de imagens". O LLM é responsável por dizer "o que deve ser desenhado nesta página", e o gpt-image-2 é responsável por "desenhar a imagem de acordo com este prompt". Todo o pipeline pode ser unificado na APIYI (apiyi.com) usando a mesma chave API, eliminando o incômodo de alternar SDKs e gerenciar chaves.
Solução 5: Síntese programática de PPT/pôsteres após geração em lote
Este é o segredo por trás daqueles casos de "PPT com um clique" que vemos nas redes sociais. O modelo em si não gera arquivos PPTX, mas pode gerar a imagem de cada página, e então você usa o python-pptx ou o PptxGenJS no front-end para inserir as imagens nos locais correspondentes de um modelo de PPT.
Em resumo: um PPT é essencialmente uma apresentação composta por várias imagens. O gpt-image-2 resolve o problema da "imagem", e o python-pptx resolve o problema do "contêiner de documento". Uma estratégia comum é: usar imagens de alta qualidade 4K para capas, qualidade média (1536×1024) para páginas internas e rascunhos de baixa qualidade para sumários e páginas de transição, controlando os custos através do parâmetro quality. Um PPT de 20 páginas requer cerca de 20 a 30 invocações de modelo e, no canal proxy da APIYI de 5000 RPM, pode ser concluído em poucos minutos.
| Solução | Tipo de arquivo | Esforço técnico | Qualidade de saída | Cenário recomendado |
|---|---|---|---|---|
| 1. Arquivo para texto | CSV/Excel/JSON | Baixo | Médio | Gráficos simples, ilustrações |
| 2. Captura de tela | PDF/PPT/Web | Baixo | Médio-Alto | Reescrita de layout, transferência de estilo |
| 3. Pré-renderização | CSV/Excel | Médio | Alto | Embelezamento de gráficos |
| 4. LLM + gpt-image-2 | Relatórios/Textos | Médio-Alto | Alto | Cards de conteúdo, tutoriais |
| 5. Síntese de PPT | Qualquer | Alto | Alto | Automação de apresentações |
Exemplo de código para invocação de API: como transformar o conteúdo de um arquivo em entrada para o gpt-image-2
Trazer os conceitos para o nível do código torna tudo muito mais intuitivo. Abaixo, apresento um exemplo mínimo e funcional em Python que converte uma planilha Excel em um comando de texto e, em seguida, chama o gpt-image-2 para gerar o gráfico correspondente. Usamos o APIYI (apiyi.com) como nosso serviço proxy de API unificado; basta substituir a base_url e o restante da sintaxe do SDK será exatamente igual à oficial.
from openai import OpenAI
import pandas as pd
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
# Lê o arquivo Excel
df = pd.read_excel("sales_q1.xlsx")
summary = df.groupby("region")["sales"].sum().to_dict()
# Cria o comando de texto
prompt_text = (
f"Desenhe um gráfico de barras das vendas regionais do Q1 de 2026,"
f"dados: {summary}, "
f"estilo de negócios em tons escuros, título em branco puro, rótulos de dados claramente visíveis."
)
# Invoca o modelo
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt_text,
size="1536x1024",
quality="high"
)
img_b64 = resp.data[0].b64_json
with open("sales_chart.png", "wb") as f:
f.write(base64.b64decode(img_b64))
A lógica do código é clara: a camada de negócio analisa o Excel em uma descrição textual e a camada do modelo recebe apenas o texto. Se você estiver usando a função de imagem para imagem (solução 2), basta substituir client.images.generate por client.images.edit e passar a imagem através do parâmetro image=open("page.png", "rb").
| Parâmetro | Intervalo de valores | Descrição |
|---|---|---|
model |
gpt-image-2 / gpt-image-2-mini |
A versão mini é mais rápida e barata |
size |
1024×1024 / 1536×1024 / 1024×1536 / personalizado | Lado mais longo ≤ 3840px, deve ser múltiplo de 16 |
quality |
low / medium / high / auto | Alta qualidade leva mais tempo e consome mais tokens |
n |
1–4 | Número de imagens por geração; para lotes, use um loop externo |
response_format |
png(padrão) / jpeg / webp | O gpt-image-2 não suporta saída em PDF/PPTX |
🎯 Dica de implementação: Para rodar esse fluxo rapidamente, recomendamos criar uma conta no APIYI (apiyi.com). Ao definir a
base_urlcomohttps://api.apiyi.com/v1, você pode usar uma interface unificada para chamar o gpt-image-2, GPT-5 e a série Claude 4 simultaneamente, evitando a dor de cabeça de integrar cada fornecedor separadamente.

Os 4 erros mais comuns dos clientes e como evitá-los
Depois de entender os 5 cenários, você ainda pode encontrar alguns detalhes técnicos na hora de colocar a mão na massa. Compilamos as 4 dúvidas mais frequentes que recebemos em nosso grupo de suporte.
Erro 1: Inserir CSV codificado em base64 no comando
Alguns usuários tentam uma "solução inteligente": ler o arquivo CSV como uma string base64 e inseri-la no comando, achando que o modelo irá decodificá-lo sozinho. Esse caminho não funciona. O gpt-image-2 não executa código nem interpreta strings como dados; ele tratará a string base64 apenas como caracteres sem sentido, resultando em um monte de texto ilegível. A forma correta é analisar o CSV na camada de negócio e transformá-lo em uma descrição textual, conforme visto no cenário 1.
Erro 2: Esperar que o gpt-image-2 "desenhe uma tabela exatamente como no Excel"
O modelo é excelente em consistência visual e estilização, mas a reprodução em nível de pixel é outra história. Se você precisa de tabelas rigorosas, recomendamos uma estratégia combinada: use ECharts/matplotlib para desenhar a versão precisa (cenário 3) e, em seguida, peça ao gpt-image-2 para melhorar a estética. Esperar que um único comando faça o modelo desenhar 100 linhas de dados com precisão absoluta é algo que ainda não é possível.
Erro 3: Querer formatos vetoriais como SVG ou PDF na saída
O gpt-image-2 gera apenas três formatos de bitmap: PNG, JPEG e WebP. Não há suporte para formatos vetoriais como SVG, PDF ou AI. Se precisar de gráficos vetoriais, use o Stable Diffusion em conjunto com o vectorizer.ai ou peça diretamente ao GPT-5 para gerar o código SVG. Confirmar o formato de saída antes de escolher o modelo evita retrabalho.
Erro 4: Enviar a mesma imagem de referência repetidamente, causando estouro de tokens
O gpt-image-2 processa cada imagem de entrada com alta fidelidade. Mesmo que seu comando seja apenas um ajuste fino, cada requisição recalcula os tokens de entrada. Sugerimos implementar um cache de imagens de referência no cliente ou usar o previous_response_id para edições conversacionais (Responses API), reutilizando o contexto da imagem anterior.
Outro detalhe importante: mesmo que o seu objetivo seja uma miniatura de 256×256, se a imagem de referência for um arquivo 4K, os tokens de entrada serão cobrados com base nos 4K. Comprima a imagem de referência localmente para 1024 pixels no lado maior antes de fazer o upload; isso pode economizar mais de 60% dos tokens de entrada, sendo este o ponto de controle de custos mais negligenciado em tarefas de grande escala.
| Fenômeno de erro | Causa raiz | Solução recomendada |
|---|---|---|
| 400 invalid_request_error | Upload de binário que não é imagem (CSV/Excel) | Converta o arquivo para texto ou print no backend |
| Caracteres ilegíveis | String base64 usada como comando | Use uma descrição em linguagem natural |
| Dados da tabela imprecisos | Uso de comando para desenhar tabelas precisas | Use o pré-render visual do cenário 3 |
| Necessidade de saída SVG | O modelo não suporta formatos vetoriais | Use o GPT-5 para gerar código SVG |
| Consumo de tokens acima do esperado | Envio repetido de imagens de referência grandes | Comprima abaixo de 1.5MB e ative o cache |
Perguntas Frequentes (FAQ)
Q1: O gpt-image-2 realmente não consegue carregar PDFs?
Não é possível carregar PDFs diretamente. Mas você pode usar o pdftoppm para converter cada página em PNG e enviá-las como imagens. Se precisar "entender o conteúdo do PDF para gerar uma imagem", recomendamos usar o GPT-5 para ler o PDF e extrair uma descrição, e então enviar essa descrição para o gpt-image-2. Essa combinação pode ser executada com uma única chave API na APIYI (apiyi.com).
Q2: É seguro enviar arquivos com dados sensíveis diretamente para o modelo?
A etapa de conversão de arquivo para texto é feita no seu próprio servidor; apenas o texto final do comando é enviado ao modelo, permitindo que você faça a anonimização durante a conversão. Se utilizar um serviço proxy de API, a APIYI (apiyi.com) garante que não armazena os comandos dos usuários nem o conteúdo retornado, sendo mais controlável em termos de conformidade do que usar proxies externos.
Q3: As ferramentas de "geração de PPT com um clique" no TikTok usam o gpt-image-2?
Algumas usam, outras não. A lógica geralmente é: LLM escreve o conteúdo → modelo de imagem (gpt-image-2 / Nano Banana Pro / Flux) cria as ilustrações → o backend usa python-pptx para montar tudo. O gpt-image-2 tem o melhor desempenho em renderização de texto, especialmente em chinês, sendo ideal para ilustrações internas de slides.
Q4: Por que dizem que é possível carregar Excel?
Isso ocorre porque o usuário tira um print do Excel e o envia como imagem. Essencialmente, ainda é uma entrada de imagem, não uma leitura da estrutura do Excel pelo modelo. Se os números no print estiverem borrados, o modelo apenas redesenhará o que estiver borrado.
Q5: Qual escolher: gpt-image-2 ou gpt-image-2-mini?
A versão mini é mais rápida e barata, ideal para rascunhos em massa e miniaturas; para materiais de publicação oficial, use a versão padrão. As restrições de entrada de ambas as versões são idênticas (nenhuma suporta documentos), bastando apenas alternar o ID do modelo no parâmetro model, sem necessidade de alterar o código do SDK.
Resumo
O gpt-image-2 não suporta o upload direto de arquivos CSV/Excel/PPT, nem gera arquivos PPTX/PDF. Isso é um limite de capacidade do modelo, e não uma questão de parâmetros de configuração. Ao entender essa limitação, basta realizar um pré-processamento do conteúdo do arquivo — convertendo para texto, capturas de tela ou visualizando antes de embelezar — para que ele atenda à grande maioria das demandas que "parecem exigir entrada de arquivos". Aquelas soluções de "PPT com um clique", "conversão de Excel para cartaz" ou "mudança de estilo de PDF" que vemos no TikTok são, essencialmente, combinações de engenharia baseadas em pipelines de múltiplas etapas. Quando você separa claramente a inferência do modelo do processamento de dados, o projeto se torna viável.
O princípio fundamental para colocar isso em prática é simples: a camada do modelo faz apenas o que ele sabe fazer de melhor, enquanto a camada de dados deve ser tratada previamente. Se você deseja executar um pipeline completo, recomendamos integrar tanto o GPT-5 (responsável pela compreensão de texto) quanto o gpt-image-2 (responsável pela geração de imagens) através da APIYI (apiyi.com). Com uma única chave API, você percorre todo o fluxo, e a capacidade de alta concorrência de 5.000 RPM garante que tarefas em lote sejam executadas sem problemas, sem a necessidade de gerenciar múltiplos conjuntos de chaves e SDKs para modelos diferentes.
Sobre o autor: A equipe da APIYI é especializada em agregação de múltiplos modelos e infraestrutura de inferência de alta concorrência, lidando diariamente com diversas consultas sobre APIs de geração de imagens. Este artigo foi organizado com base na documentação oficial da OpenAI e em consultas reais de clientes. Se precisar conhecer as soluções de integração para o gpt-image-2, visite a APIYI em apiyi.com.