Nota do autor: A APIYI lançou o modelo oficial reverso gpt-image-2-all, com cobrança de $0,03 por uso, sem limite de concorrência e suporte a texto para imagem, fusão de múltiplas imagens e edição de imagem por linguagem natural. Ele oferece a mesma capacidade de geração da versão mais recente do ChatGPT Web. Este artigo traz um guia completo sobre como integrar a API.
Em abril de 2026, a versão web do ChatGPT começou a realizar testes A/B da sua próxima geração de capacidade de geração de imagens — os usuários ainda veem o rótulo "GPT Image 1.5" na interface, mas algumas solicitações já são processadas pelo novo modelo. A API oficial da OpenAI ainda não liberou o ID do modelo gpt-image-2, portanto, qualquer serviço que afirme "chamar diretamente a API do gpt-image-2" deve ser verificado com cautela.
A APIYI lançou oficialmente o gpt-image-2-all através de uma solução reversa oficial, com capacidade de geração equivalente à versão mais recente do ChatGPT Web, custando $0,03 por uso e sem limite de concorrência. Isso não é uma promessa vazia, mas sim uma interface de nível de produção que já pode ser chamada via solicitações HTTP padrão.
Valor principal: Ao terminar de ler este artigo, você dominará os 3 endpoints de API do gpt-image-2-all, técnicas de fusão de múltiplas imagens, uso de edição por linguagem natural e será capaz de concluir a integração em 10 minutos.

Pontos principais do gpt-image-2-all
| Capacidade | Descrição | Valor |
|---|---|---|
| Equivalência ao ChatGPT Web | Solução reversa oficial sincronizada com a capacidade oficial | Não precisa esperar a OpenAI abrir a API |
| Cobrança por uso | $0,03/uso, sem limite de resolução/qualidade/comando | Custo transparente e previsível |
| Sem limite de concorrência | Sem restrição de número de solicitações | Amigável para pipelines em lote |
| Fusão de múltiplas imagens | Referência a "imagem1/imagem2/imagem3" no comando | Geração de consistência de múltiplos sujeitos |
| Edição por linguagem natural | Edição conversacional sem necessidade de máscara | Barreira de iteração drasticamente reduzida |
Interpretação do posicionamento do gpt-image-2-all
O que significa "reverso oficial". É uma solução de serviço proxy de API que se conecta à capacidade de geração de imagens mais recente do ChatGPT Web através de engenharia reversa. Não é a mesma interface que a OpenAI abrirá oficialmente no futuro como gpt-image-2, mas a capacidade do modelo subjacente é a mesma. Antes da abertura oficial da API, esta é a única solução de nível de produção que pode chamar de forma estável a capacidade de geração de imagens mais recente do ChatGPT.
Por que integrar agora. Três razões práticas: (1) A data de lançamento do gpt-image-2 oficial da OpenAI é incerta (prevista para o final de abril a meados de maio de 2026); (2) Haverá inevitavelmente problemas de escassez de cota e inicialização a frio durante o período de lançamento inicial; (3) Ao validar o fluxo de negócios com antecedência baseando-se no gpt-image-2-all, você poderá migrar perfeitamente apenas alterando o nome do modelo quando a versão oficial for aberta.
Guia de Início Rápido: gpt-image-2-all
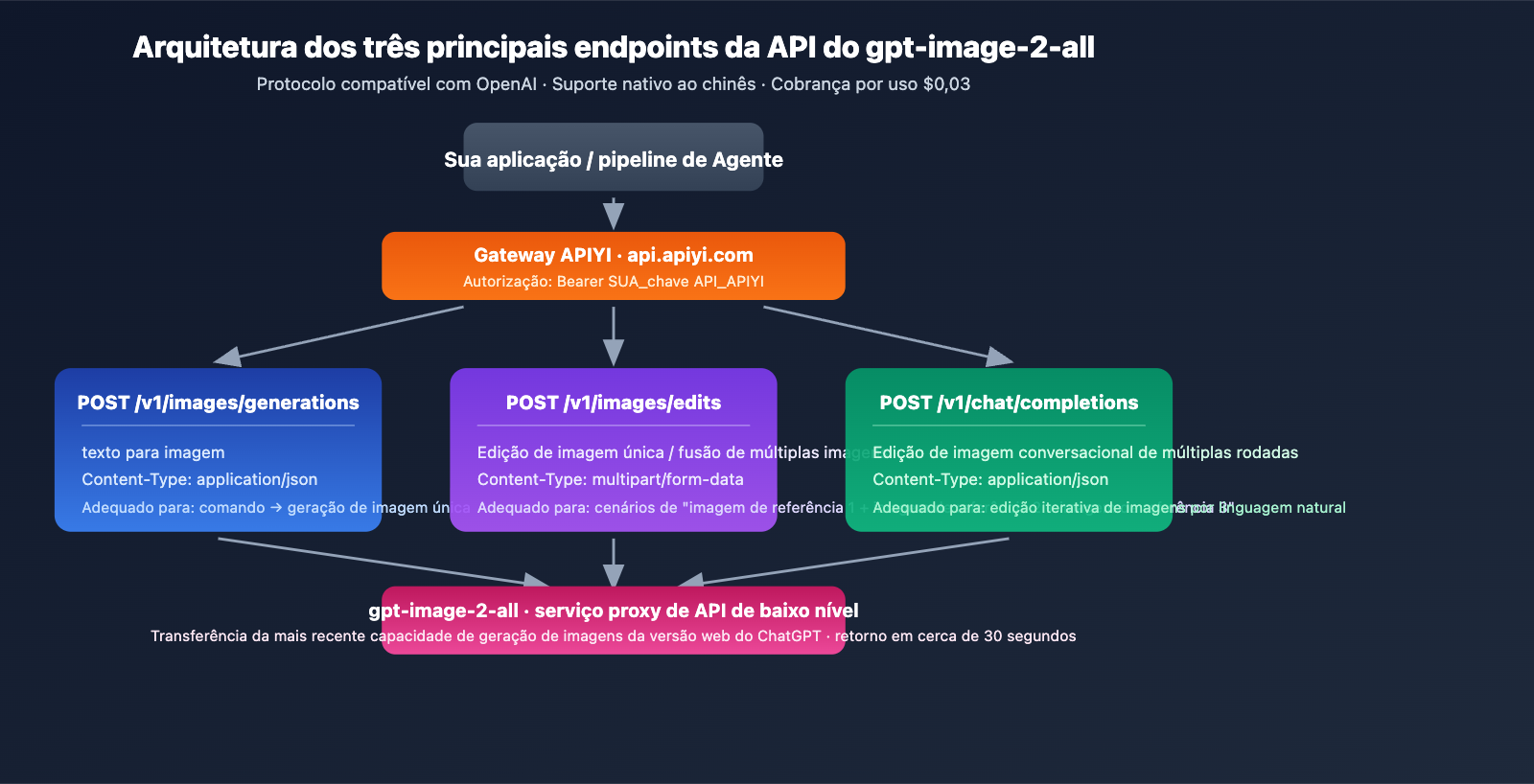
Três principais endpoints de API
O gpt-image-2-all oferece três endpoints para cobrir todo o fluxo de trabalho de geração de imagens:
| Endpoint | Uso | Content-Type |
|---|---|---|
POST /v1/images/generations |
Texto para imagem | application/json |
POST /v1/images/edits |
Edição de imagem única/fusão de múltiplas imagens | multipart/form-data |
POST /v1/chat/completions |
Edição iterativa via chat | application/json |
Base URL: https://api.apiyi.com (Alternativas: b.apiyi.com, vip.apiyi.com)
Exemplo minimalista de texto para imagem
import requests
response = requests.post(
"https://api.apiyi.com/v1/images/generations",
headers={
"Authorization": "Bearer YOUR_APIYI_KEY",
"Content-Type": "application/json"
},
json={
"model": "gpt-image-2-all",
"prompt": "Formato paisagem 16:9, uma xícara de café latte, etiqueta na mesa escrita 'Morning Blend $4.50', luz da manhã passando pela janela da cafeteria",
},
timeout=120
)
result = response.json()
print(result["data"][0]["url"])
Ver código de integração completo (inclui tratamento de erros, concorrência, fusão de imagens e edição via chat)
import requests
import time
from typing import Optional, List
API_KEY = "YOUR_APIYI_KEY"
BASE_URL = "https://api.apiyi.com"
def text_to_image(prompt: str, timeout: int = 120) -> Optional[str]:
"""Texto para imagem: via endpoint /v1/images/generations"""
for attempt in range(3):
try:
r = requests.post(
f"{BASE_URL}/v1/images/generations",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={"model": "gpt-image-2-all", "prompt": prompt},
timeout=timeout
)
if r.status_code == 200:
return r.json()["data"][0]["url"]
if r.status_code == 429:
time.sleep(2 ** attempt)
continue
except requests.Timeout:
continue
return None
def multi_image_fusion(prompt: str, image_paths: List[str]) -> Optional[str]:
"""Fusão de múltiplas imagens: via endpoint /v1/images/edits"""
files = [
("image[]", (f"img{i}.png", open(p, "rb"), "image/png"))
for i, p in enumerate(image_paths)
]
data = {"model": "gpt-image-2-all", "prompt": prompt}
r = requests.post(
f"{BASE_URL}/v1/images/edits",
headers={"Authorization": f"Bearer {API_KEY}"},
data=data,
files=files,
timeout=120
)
return r.json()["data"][0]["url"] if r.status_code == 200 else None
def conversational_edit(messages: List[dict]) -> Optional[str]:
"""Edição via chat: via endpoint /v1/chat/completions"""
r = requests.post(
f"{BASE_URL}/v1/chat/completions",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={"model": "gpt-image-2-all", "messages": messages},
timeout=120
)
return r.json()["choices"][0]["message"]["content"] if r.status_code == 200 else None
url = text_to_image("Formato retrato 9:16, pôster de celular, um café gelado, texto grande no topo 'Summer Sale 50% OFF'")
print(f"Gerado: {url}")
fusion_url = multi_image_fusion(
"Coloque a pessoa da imagem 1 no cenário de praia da imagem 2, mantendo as roupas da pessoa inalteradas",
["person.png", "beach.png"]
)
print(f"Fusão: {fusion_url}")
Dica de integração: Registre-se no APIYI (apiyi.com) para obter créditos de teste. Uma única chave API suporta o gpt-image-2-all, GPT-4o, Claude e outros modelos, eliminando a complexidade de gerenciar contas de múltiplos fornecedores.
Detalhes dos principais recursos do gpt-image-2-all
Recurso 1: Renderização de texto de alta precisão
Para o gpt-image-2-all, a estabilidade na renderização de textos em chinês e inglês é o ponto forte da capacidade oficial de geração de imagens do ChatGPT mais recente. Textos em placas, pôsteres e infográficos são gerados corretamente na primeira tentativa — algo que o gpt-image-1.5 tinha dificuldade em realizar.
Cenários testados:
- Menu de cafeteria:
"Americano $4.00, Latte $4.50"com precisão ao nível de caractere. - Embalagem de produto: Tabela de ingredientes com texto misto (chinês/inglês) claramente legível.
- Mockup de UI: Botões e etiquetas de navegação renderizados com precisão.
- Infográficos: Títulos, subtítulos e etiquetas de dados com hierarquia clara.
Recurso 2: Capacidade de fusão de múltiplas imagens
Através do endpoint /v1/images/edits, você pode enviar várias imagens de referência simultaneamente e usar "imagem 1", "imagem 2", "imagem 3" no seu comando para referenciá-las diretamente.
prompt = """
Coloque o produto da imagem 1 no cenário da imagem 2,
use o estilo de cores da imagem 3,
ângulo de câmera levemente de cima,
detalhes em 4K de alta definição.
"""
Cenários de aplicação:
| Cenário | Uso |
|---|---|
| Imagens de e-commerce | Foto do produto + Foto de cenário → Composição realista |
| Consistência facial | Foto original do personagem + Novo cenário → Múltiplos ângulos |
| Transferência de estilo | Imagem de conteúdo + Imagem de estilo → Saída estilizada |
| Sistema visual de marca | Produto + LOGO + Paleta de cores → Identidade visual unificada |
Recurso 3: Edição em linguagem natural (sem necessidade de máscara)
O maior salto em eficiência é a edição via chat — não é mais necessário desenhar máscaras ou selecionar áreas; basta descrever o que você deseja alterar usando linguagem natural.
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "Gere uma vista externa de uma cafeteria, sol da tarde incidindo diagonalmente"},
]
},
{
"role": "assistant",
"content": "[Link da imagem gerada]"
},
{
"role": "user",
"content": "Mude o clima para chuvoso, mantendo a arquitetura inalterada"
}
]
O que esse fluxo de trabalho significa: O ciclo antigo de "gerar → editar no Photoshop → gerar novamente" agora se torna uma iteração via chat. Cada ajuste requer apenas a descrição da diferença, sem a necessidade de reescrever o comando completo.
Recurso 4: Suporte nativo ao chinês
Os comandos podem ser escritos diretamente em chinês, sem a necessidade de traduzir para o inglês antes da chamada. Para equipes de desenvolvimento que trabalham com chinês e negócios localizados, esta é uma experiência muito mais fluida e natural:
prompt = "Formato retrato 9:16, capa para Xiaohongshu, uma garota asiática bebendo café, título 'Explorando o fim de semana · A cafeteria secreta no beco', estilo realista com luz suave"
Controle de tamanho e proporção no gpt-image-2-all
Observações importantes
O gpt-image-2-all não aceita os parâmetros size (tamanho), n, quality (qualidade) ou aspect_ratio (proporção) — passá-los resultará em um erro de validação. O controle de dimensões deve ser feito obrigatoriamente através da descrição textual no comando.
Sugestão de escrita do comando

| Proporção alvo | Escrita recomendada | Descrição |
|---|---|---|
| 1:1 Quadrada | "1024×1024 quadrada" ou "Composição 1:1" | Avatar de redes sociais |
| 16:9 Paisagem | "Paisagem 16:9" ou "Widescreen 16:9" | Miniatura de vídeo |
| 9:16 Retrato | "Retrato 9:16" ou "Celular 9:16" | Vídeos curtos/Stories |
| 21:9 Ultra-wide | "Banner 21:9" ou "Tela ultra-wide" | Banner de site |
| 4:3 Tradicional | "Paisagem 4:3" | Slides de apresentação |
| 3:4 Vertical | "Retrato 3:4" | Imagem principal de e-commerce |
Dicas essenciais
Coloque a descrição da proporção no início do comando. O modelo segue melhor as instruções que aparecem primeiro; se a proporção for colocada no final, pode acabar sendo ignorada.
# ✅ Recomendado
prompt = "Paisagem 16:9, um Shiba Inu sorrindo sob uma cerejeira, estilo fotografia de luz suave"
# ❌ Não recomendado
prompt = "Um Shiba Inu sorrindo sob uma cerejeira, estilo fotografia de luz suave, Paisagem 16:9"
Preços e estratégia de concorrência do gpt-image-2-all
Regras de cobrança
| Item | Regra |
|---|---|
| Preço unitário | $0,03 / requisição |
| Unidade de cobrança | Por geração bem-sucedida |
| Falhas não são cobradas | Erros 401/4xx/5xx não geram custo |
| Impacto dos parâmetros | Nenhum (independente de resolução/qualidade) |
| Limite de concorrência | Nenhum (limitado apenas pelo saldo da conta) |
Estimativa de custo típica
| Cenário de negócio | Volume mensal | Custo mensal |
|---|---|---|
| Projeto pessoal | 500 requisições | $15 |
| Pequena equipe | 5.000 requisições | $150 |
| E-commerce em massa | 50.000 requisições | $1.500 |
| Pipeline em larga escala | 500.000 requisições | $15.000 |
Dica de otimização de custos: Através do agendamento de conta unificada da APIYI (apiyi.com), você pode rotear para o modelo ideal entre gpt-image-2-all, gpt-image-1.5 e Nano Banana Pro com base no tipo de tarefa em tempo real, evitando pagar o preço unitário mais alto para todos os cenários.
Tratamento de erros e melhores práticas do gpt-image-2-all
Códigos de erro comuns e tratamento
| Código de status | Como proceder |
|---|---|
| 401 | Verifique se o Authorization Bearer Token está correto |
| 429 | Aplique exponential backoff (2s → 4s → 8s) |
| 5xx | Tente novamente 1 ou 2 vezes; se persistir, emita um alerta |
| Timeout | O timeout do cliente deve ser ≥ 120 segundos |
Dicas de solução de problemas
Todas as respostas contêm o cabeçalho request-id. Ao encontrar problemas, registre este ID e envie para o suporte técnico da APIYI para que possamos localizar rapidamente os logs no servidor.
Funcionalidades não suportadas
- Saída em streaming:
stream=truenão funciona; apenas o retorno único é suportado. - Saída de múltiplas imagens: Cada requisição retorna apenas 1 imagem. Para múltiplas imagens, realize chamadas simultâneas.
- Parâmetros padrão do SDK da OpenAI: O SDK oficial envia
size/npor padrão, o que causará erros de validação. Recomendamos o uso derequestspara enviar as requisições diretamente.
Perguntas Frequentes (FAQ)
Q1: O que é o gpt-image-2-all?
O gpt-image-2-all é um modelo de serviço proxy de API disponibilizado pela APIYI que utiliza uma solução de engenharia reversa oficial para integrar a mais recente capacidade de geração de imagens da versão web do ChatGPT. Antes que a OpenAI libere oficialmente a API do gpt-image-2, ele oferece um canal de invocação de nível de produção consistente com as capacidades mais atuais do ChatGPT, suportando os três cenários principais: texto para imagem, fusão de múltiplas imagens e edição de imagens via linguagem natural.
Q2: Qual a diferença entre o gpt-image-2-all e o gpt-image-2 oficial?
A capacidade do modelo subjacente é a mesma, mas a forma de interface é diferente. A API oficial da OpenAI ainda não liberou o ID do modelo gpt-image-2 (qualquer serviço que afirme permitir chamadas diretas via API deve ser verificado com cautela), enquanto a versão web do ChatGPT já está testando o novo modelo em um ambiente A/B. O gpt-image-2-all fornece um canal de invocação estável através de uma solução de engenharia reversa. Assim que a versão oficial for lançada, os usuários poderão migrar perfeitamente para a interface oficial apenas alterando o campo model.
Q3: Como entender o preço de $0,03 por chamada?
A cobrança é feita por geração bem-sucedida, sem limites de resolução, qualidade ou tamanho do comando. Comparado ao preço estimado pela indústria para o gpt-image-2 oficial da OpenAI ($0,15 – $0,20), o gpt-image-2-all custa cerca de 1/5 a 1/6 do valor. Requisições falhas (erros de autenticação ou parâmetros) não são cobradas, e não há limite rígido de concorrência (limitado apenas pelo saldo da conta).
Q4: Por que leva 30 segundos para gerar uma imagem?
30 segundos é o tempo médio de resposta da solução atual de engenharia reversa, próximo à velocidade da versão web do ChatGPT. Espera-se que o gpt-image-2 oficial seja mais rápido (cerca de 3 segundos) quando for lançado, mas, até lá, o gpt-image-2-all é a única solução que permite invocar as capacidades mais recentes de forma estável. Recomendamos configurar o timeout do cliente para ≥120 segundos para evitar erros de tempo limite.
Q5: Como integrar o gpt-image-2-all?
A integração é feita em três passos:
- Acesse o site da APIYI (apiyi.com), registre uma conta e obtenha sua chave API.
- Defina a Base URL como
https://api.apiyi.com. - Use a biblioteca
requestspara chamar o endpoint/v1/images/generations(o SDK oficial requer personalização de HTTP para evitar problemas com o parâmetrosize).
Documentação detalhada: docs.apiyi.com/api-capabilities/gpt-image-2-all/overview · Teste online: imagen.apiyi.com
Q6: Quantas imagens de referência são suportadas na fusão de múltiplas imagens?
Uma única requisição /v1/images/edits suporta múltiplas imagens de referência. Cada imagem deve ter ≤10MB e os formatos suportados são PNG, JPG ou WebP. No comando, você pode referenciá-las como "imagem 1", "imagem 2", "imagem 3", etc. Testes mostram que a fusão de 3 a 5 imagens de referência oferece o resultado mais estável; acima de 10 imagens, podem ocorrer perdas de elementos.
Q7: Por que não posso usar o SDK oficial da OpenAI diretamente?
O método images.generate() do SDK oficial da OpenAI envia automaticamente parâmetros como size e n, mas o gpt-image-2-all não aceita esses parâmetros (o que causaria um erro de validação). Soluções recomendadas: (1) Use requests para enviar a requisição HTTP diretamente; ou (2) sobrescreva o corpo da requisição do SDK para remover esses parâmetros. Quando a versão oficial for lançada, o SDK será compatível.
Q8: Quais são as limitações conhecidas do gpt-image-2-all?
Declaração objetiva das limitações atuais:
- Saída única: gera 1 imagem por vez; para múltiplas, é necessário realizar chamadas concorrentes.
- Sem suporte a streaming: retorno único, sem stream.
- Fase beta: a estabilidade está em otimização contínua, podendo haver oscilações ocasionais.
- Dependência de engenharia reversa: se a capacidade da versão web do ChatGPT for ajustada, o serviço pode sofrer breves interrupções.
- Recomendação de redundância: para operações críticas, sugerimos configurar também o gpt-image-1.5 ou o Nano Banana Pro como plano de contingência.
Principais pontos do gpt-image-2-all
- Solução de engenharia reversa · Capacidade mais recente do ChatGPT: O único canal de nível de produção antes do lançamento da API oficial.
- $0,03/chamada · Concorrência ilimitada: Cobrança por sucesso, custo transparente, ideal para pipelines em lote.
- Três endpoints cobrindo todos os cenários: Texto para imagem / Fusão de múltiplas imagens / Edição via diálogo.
- Chinês nativo + Alta precisão de texto: Renderização estável de textos em chinês e inglês, sem necessidade de traduzir o comando.
- Caminho de início: Registro na APIYI (apiyi.com) → Timeout de 120 segundos → Chamada direta via
requests.
Resumo
O valor central do gpt-image-2-all:
- Preenche a lacuna oficial: Antes que a OpenAI libere oficialmente a API
gpt-image-2, oferecemos uma interface de nível de produção para invocar de forma estável as mais recentes capacidades de geração de imagens do ChatGPT. - Custo significativamente menor que o preço oficial estimado: $0,03/chamada contra a estimativa oficial de $0,15-$0,20, proporcionando uma vantagem de custo clara em cenários de processamento em lote.
- Design para migração contínua: Baseado no protocolo compatível com a OpenAI, basta substituir o nome do modelo no dia do lançamento oficial para realizar a transição.
Para a tomada de decisão da sua equipe, recomendamos integrar imediatamente o gpt-image-2-all através da APIYI (apiyi.com) para validar seus fluxos de trabalho. O preço atual de $0,03/chamada torna a validação em lote praticamente gratuita. Assim, você pode realizar a transição para o gpt-image-2 oficial conforme a necessidade — as equipes que se anteciparem terão uma vantagem competitiva significativa no lançamento do novo modelo.
Experimente online: imagen.apiyi.com · Documentação: docs.apiyi.com/api-capabilities/gpt-image-2-all/overview
Leituras Recomendadas
Se você se interessou pelo gpt-image-2-all, recomendamos a leitura dos seguintes conteúdos:
- 📘 Análise completa das oito grandes atualizações do gpt-image-2 vs gpt-image-1.5 – Entenda os motivos fundamentais por trás do salto de capacidade.
- 📊 Análise completa dos seis principais cenários de aplicação do gpt-image-2 – Domine os caminhos para a implementação prática nos negócios.
- 🚀 Comparação profunda: gpt-image-2 vs Nano Banana Pro – Escolha o modelo ideal de forma racional.
📚 Referências
-
Documentação oficial da APIYI: Especificações técnicas completas do gpt-image-2-all
- Link:
docs.apiyi.com/api-capabilities/gpt-image-2-all/overview - Descrição: Documentação de integração oficial e autorizada, incluindo parâmetros, códigos de erro e melhores práticas.
- Link:
-
Playground online da APIYI: imagen.apiyi.com
- Link:
imagen.apiyi.com - Descrição: Teste os resultados de geração de imagens do gpt-image-2-all sem precisar escrever código.
- Link:
-
Documentação da API de Imagens da OpenAI: API dos modelos de imagem mais recentes
- Link:
openai.com/index/image-generation-api - Descrição: Compare e entenda as especificações da API gpt-image-1.5 oficial da OpenAI.
- Link:
-
Observações de testes beta no LM Arena: Informações vazadas sobre o GPT Image 2
- Link:
mindstudio.ai/blog/what-is-gpt-image-2 - Descrição: Prévia das capacidades da próxima geração de modelos de imagem.
- Link:
Autor: Equipe técnica da APIYI
Troca de conhecimento: Sinta-se à vontade para discutir na seção de comentários. Para mais materiais, visite a central de documentação da APIYI em docs.apiyi.com.