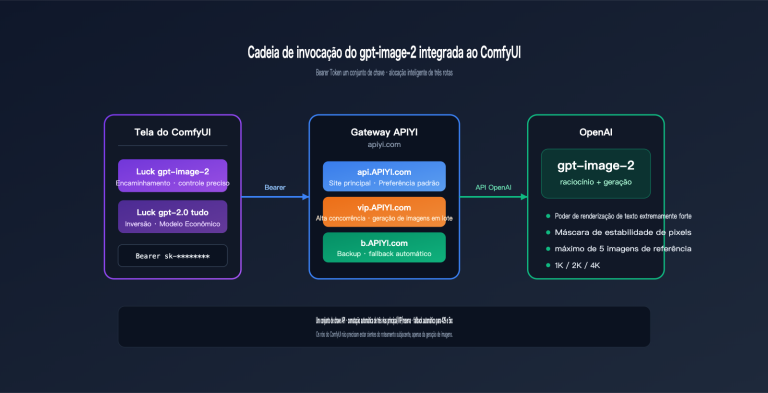
Nota do autor: Com base em informações vazadas de testes de escala de cinza no LM Arena, apresentamos uma análise completa das 8 principais melhorias do gpt-image-2 em relação ao gpt-image-1.5, incluindo comparações de renderização de texto, realismo, saída em 4K, velocidade, suporte a múltiplos idiomas e geração de capturas de tela de UI.
No início de abril de 2026, três modelos de imagem anônimos maskingtape-alpha, gaffertape-alpha e packingtape-alpha apareceram silenciosamente na plataforma de avaliação LM Arena. Vários testadores iniciais relataram que sua precisão na renderização de texto estava próxima de 99%, a velocidade de geração era de apenas cerca de 3 segundos e havia suporte nativo para saída em 4K — a comunidade acredita amplamente que este é o gpt-image-2, que a OpenAI está prestes a lançar.
Isso não é vaporware (produto apenas no papel); os registros de testes públicos do LM Arena, capturas de tela comparativas de vários testadores independentes e o histórico de ciclos de testes de escala de cinza da OpenAI (geralmente lançados oficialmente após 2-4 semanas) apontam para a mesma conclusão. Este artigo comparará sistematicamente as oito principais atualizações do gpt-image-2 vs gpt-image-1.5.
Valor central: Ao terminar de ler este artigo, você entenderá claramente os avanços específicos do gpt-image-2 em dimensões como texto, realismo, 4K, velocidade, restauração de UI e idiomas, além de como migrar perfeitamente no primeiro dia em que a API for aberta.

Pontos principais do gpt-image-2
| Dimensão de atualização | Status atual do gpt-image-1.5 | Melhoria no gpt-image-2 |
|---|---|---|
| Renderização de texto | Útil para títulos curtos de 1-5 palavras | Precisão em nível de caractere de ~99% |
| Velocidade de geração | 8-18 segundos | ~3 segundos (3-5x mais rápido) |
| Resolução máxima | 1536×1024 | 2048×2048 / 4096×4096 |
| Suporte a widescreen | Apenas 1:1, 4:3, 3:4 | Novo formato widescreen 16:9 |
| Realismo | Presença de "filtro amarelado de IA" | Retratos/produtos podem enganar o olho humano |
O significado geral da atualização do gpt-image-2
O texto não é mais um ponto fraco. Na era do gpt-image-1.5, a maioria dos modelos de imagem cometia erros ao renderizar textos com mais de 5-6 palavras. No entanto, os testadores do LM Arena relataram que as etiquetas de UI, letreiros e textos em pôsteres do gpt-image-2 quase não precisam mais de retoques posteriores. Isso significa que anúncios localizados, mockups de UI e imagens para redes sociais não precisarão mais de formatação manual.
Da inferência em duas etapas para a inferência única. O gpt-image-1.5 ainda é baseado em um pipeline de duas etapas, enquanto o gpt-image-2, segundo os testadores, foi desacoplado em um modelo de imagem independente, adotando uma arquitetura de inferência única. Este é o suporte subjacente para a velocidade de 3 segundos e também significa que o throughput (vazão) de pipelines em lote pode aumentar em uma ordem de magnitude.

Detalhamento das 8 principais melhorias do gpt-image-2 vs gpt-image-1.5
Melhoria 1: Renderização de texto quase perfeita
Testadores do LM Arena relataram que a precisão em nível de caractere do gpt-image-2 é de cerca de 99%, com o texto integrado naturalmente ao cenário (como interfaces de UI, pôsteres e placas), em vez de parecer "flutuar" sobre a imagem, como acontecia nos modelos antigos.
Este é um problema crônico que assombra todos os principais modelos de imagem (Midjourney, Stable Diffusion, Imagen, Flux) e que finalmente foi resolvido de forma sistêmica no gpt-image-2.
Melhoria 2: Realismo que engana os olhos
Vários testadores relataram que os retratos, selfies na praia e closes de produtos gerados pelo gpt-image-2 tornaram-se difíceis de distinguir de fotos reais:
- Anatomia das mãos correta: proporções dos cinco dedos e ângulos das articulações naturais.
- Reflexos precisos em óculos de sol: o conteúdo refletido é consistente com o cenário.
- Fim do filtro amarelado: o "tom de IA" persistente da era gpt-image-1 desapareceu.
Melhoria 3: Conhecimento profundo do mundo
Ao solicitar "uma loja IKEA à noite", "captura de tela da página inicial do YouTube" ou "cenário de Minecraft com UI de jogo correta", a capacidade do gpt-image-2 de reproduzir marcas reais, interfaces e ambientes é suficiente para "fingir" que se trata de uma fotografia real.
Isso significa que o modelo compreende verdadeiramente as convenções visuais do mundo real, e não apenas a distribuição estatística de pixels.
Melhoria 4: Saída nativa em 4K
Enquanto a saída máxima do gpt-image-1.5 era de apenas 1536×1024, espera-se que o gpt-image-2 suporte nativamente 2048×2048 e 4096×4096, além do formato widescreen 16:9.
| Cenário de aplicação | Experiência gpt-image-1.5 | Experiência gpt-image-2 |
|---|---|---|
| Impressão comercial | Requer ampliação posterior | 4K nativo pronto para impressão |
| Visual de marketing | Resolução insuficiente | Atende nativamente a requisitos de pôsteres |
| Imagens de produto em alta res. | Requer super-resolução | Geração única é suficiente |
| Miniaturas de vídeo | Falta de 16:9 | Suporte nativo a widescreen |
Melhoria 5: Geração mais rápida (aprox. 3 segundos)
Observadores do Arena mediram uma geração única em cerca de 3 segundos — superando em muito a norma de 10-20 segundos (ou até 35-55 segundos na era gpt-image-1) dos modelos de imagem topo de linha anteriores.
Seja para UX interativa (redução significativa no tempo de espera do usuário) ou pipelines em lote (aumento de 3 a 5 vezes na produção no mesmo intervalo de tempo), o benefício será direto.
Melhoria 6: Renderização de texto em vários idiomas
Na visualização, a renderização de latim, CJK (chinês, japonês, coreano) e textos da direita para a esquerda (árabe, hebraico) mostrou-se clara e legível.
Se esse desempenho for mantido no lançamento, anúncios localizados e mockups de UI multilíngues não precisarão mais de formatação manual — uma grande vantagem para equipes de expansão global, e-commerce transfronteiriço e operações de conteúdo em vários idiomas.
Melhoria 7: Geração de UI e capturas de tela
Os testadores destacaram a capacidade de reprodução de UI — páginas da web, interfaces de aplicativos e janelas de sistemas operacionais com uma precisão surpreendente. Ideal para os seguintes cenários:
- Exploração de design: geração rápida de conceitos de UI.
- Materiais de tutorial: criação de capturas de tela de exemplo para documentação técnica.
- Prototipagem: apresentação de interfaces de produtos ainda não desenvolvidos para clientes.
- Materiais de teste A/B: geração em lote de interfaces com estilos diferentes para escolha.
Melhoria 8: API disponível no lançamento
Assim que a OpenAI liberar a API, a APIYI a disponibilizará imediatamente. Sua chave API, saldo e faturas atuais em apiyi.com permanecem inalterados — não é necessário registrar uma nova conta, trocar de SDK ou alterar o código do seu negócio.
Sugestão de migração: Antes do lançamento oficial do gpt-image-2, você pode testar o gpt-image-1.5 atual através da APIYI apiyi.com, familiarizando-se com a configuração
base_urle a estrutura de parâmetros. No dia do lançamento oficial, basta substituir o campomodelpara concluir a migração.
Guia de início rápido do gpt-image-2 (Guia de migração de API)
Exemplo minimalista (baseado no gpt-image-1.5, basta substituir o nome do modelo na versão oficial)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-1.5", # Substitua por "gpt-image-2" após o lançamento oficial
prompt="A modern cafe menu board with hand-lettered text 'Today Special: Espresso $4.50'",
size="1024x1024",
quality="high"
)
print(response.data[0].url)
Ver código de implementação completo (inclui 4K, 16:9 e tratamento de erros)
from openai import OpenAI
from typing import Optional, Literal
def generate_image(
prompt: str,
model: str = "gpt-image-1.5",
size: Literal["1024x1024", "1536x1024", "1024x1536", "2048x2048", "4096x4096"] = "1024x1024",
quality: Literal["low", "medium", "high", "auto"] = "high",
n: int = 1
) -> Optional[str]:
"""
Gera imagens, compatível com gpt-image-1.5 e o futuro gpt-image-2
Args:
prompt: comando de texto (máximo de 2000 tokens)
model: nome do modelo (pode ser alterado para gpt-image-2 após o lançamento)
size: tamanho da saída (o gpt-image-2 suportará 2K/4K)
quality: nível de qualidade
n: quantidade de gerações (atualmente suporta apenas 1)
Returns:
URL temporária da imagem gerada (válida por 24 horas)
"""
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
try:
response = client.images.generate(
model=model,
prompt=prompt,
size=size,
quality=quality,
n=n
)
return response.data[0].url
except Exception as e:
print(f"Falha na geração da imagem: {e}")
return None
url = generate_image(
prompt="Product hero shot: sleek wireless earbuds on marble, 'AuraPods Pro' label visible",
model="gpt-image-1.5",
size="1536x1024",
quality="high"
)
print(f"URL da imagem: {url}")
Sugestão da plataforma: Obtenha créditos de teste gratuitos através da APIYI apiyi.com para experimentar instantaneamente os recursos mais recentes do gpt-image-1.5. No dia do lançamento oficial do gpt-image-2, você poderá alternar sem precisar alterar nenhuma linha de código.
Comparativo de soluções: gpt-image-2 vs gpt-image-1.5
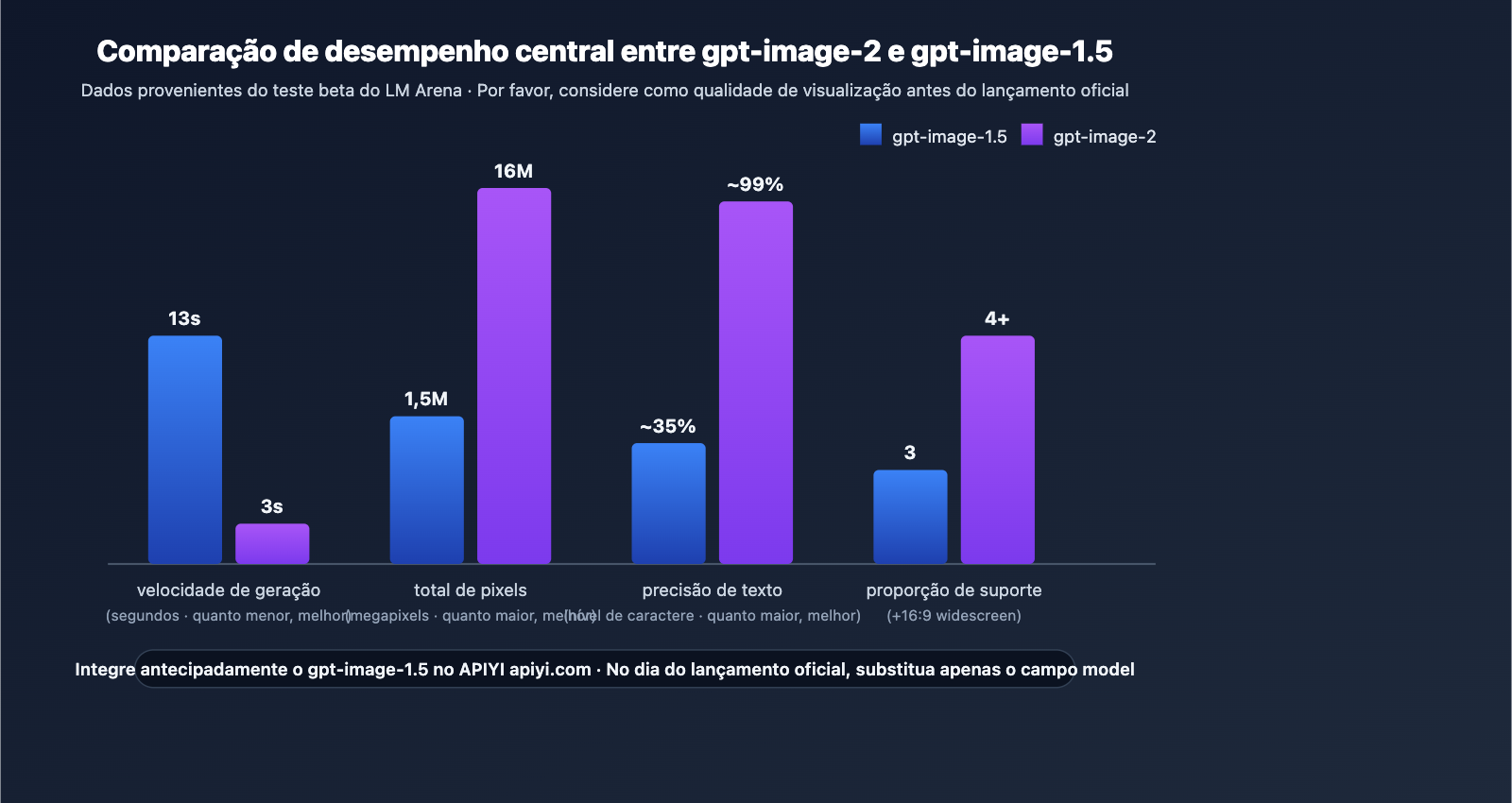
| Dimensão | gpt-image-1.5 (Dez/2025) | gpt-image-2 (Previsto Abr-Mai/2026) | Significado da diferença |
|---|---|---|---|
| Arquitetura | Inferência em duas etapas | Inferência única | Aumento significativo na taxa de transferência |
| Velocidade | 8-18 segundos | ~3 segundos | 3 a 5 vezes mais rápido |
| Resolução máx. | 1536×1024 | 4096×4096 | Pronto para impressão comercial |
| Proporções | 1:1 / 3:4 / 4:3 | + 16:9 (widescreen) | Ideal para miniaturas de vídeo |
| Precisão de texto | Títulos curtos (1-5 palavras) | ~99% em nível de caractere | Adeus à diagramação manual |
| Multilíngue | Instável em não latinos | CJK/RTL nítido e legível | Beneficia conteúdos localizados |
| Fidelidade UI | Regular | "Simula" capturas reais | Útil para design e tutoriais |
Análise comparativa de upgrade
Comparado ao Midjourney: O Midjourney continua líder em estilos artísticos. No entanto, seu acesso via API é limitado e a renderização de texto é historicamente fraca. Em contrapartida, o gpt-image-2 oferece uma API padrão com 99% de precisão textual, sendo muito mais adequado para integração em fluxos de trabalho automatizados.
Comparado ao Imagen 2: O Google Imagen 2 tem vantagens no realismo fotográfico. Contudo, seu ecossistema de API é relativamente fechado e o suporte a idiomas além do inglês é limitado. O gpt-image-2 é mais equilibrado em textos multilíngues, fidelidade de UI e velocidade, sendo ideal para equipes globais.
Comparado ao nano-banana-pro: O nano-banana-pro se destaca pelo custo-benefício. Porém, sua capacidade de saída em 4K e fidelidade de marca não atingem o nível esperado do gpt-image-2. Para impressão comercial e marketing de marca, o gpt-image-2 continua sendo a escolha mais robusta.
Nota de comparação: Os dados acima provêm parcialmente de testes públicos do LM Arena e de feedbacks de testadores iniciais. Considere o gpt-image-2 como uma versão de prévia até o lançamento oficial. Recomendamos testar o gpt-image-1.5 via APIYI (apiyi.com) para se familiarizar com a estrutura de parâmetros.
Cenários de aplicação do gpt-image-2
Considere migrar para o gpt-image-2 se você atua nestas áreas:
- Cenário 1 — Impressão comercial: Saída nativa em 4K para resolver gargalos de resolução em pôsteres, catálogos e anúncios de grande formato.
- Cenário 2 — Anúncios localizados: Renderização de texto em vários idiomas, eliminando a necessidade de diagramação manual e aumentando a eficiência de equipes internacionais.
- Cenário 3 — Exploração de design de UI: Gerador rápido de rascunhos conceituais e materiais de tutorial para gerentes de produto e designers.
- Cenário 4 — Imagens principais de e-commerce: Realismo fotográfico e precisão textual para destacar produtos em campanhas de marketing.
- Cenário 5 — Conteúdo em vídeo: Suporte a formato 16:9 para geração em lote de miniaturas para YouTube e vídeos curtos.
Dica de cenário: Se você está avaliando APIs de imagem, recomendamos integrar o gpt-image-1.5 via APIYI (apiyi.com) agora. Assim que a versão oficial for lançada, bastará substituir o campo
modelpara realizar o upgrade sem complicações.
Perguntas Frequentes (FAQ)
Q1: O que é o gpt-image-2?
O gpt-image-2 é a próxima geração do modelo de geração de imagens da OpenAI, com lançamento previsto para abril ou maio de 2026. De acordo com os testes em escala de cinza no LM Arena, o modelo utiliza uma arquitetura de inferência de etapa única, alcançando cerca de 99% de precisão na renderização de texto, velocidade de aproximadamente 3 segundos e suporte nativo para saída em 4K. Ele representa uma atualização significativa após o gpt-image-1 (abril de 2025) e o gpt-image-1.5 (dezembro de 2025).
Q2: Quais são as diferenças entre o gpt-image-2 e o gpt-image-1.5?
As diferenças centrais estão em oito dimensões: renderização de texto (de 5 palavras para 99% de precisão), velocidade (de 8-18 segundos para 3 segundos), resolução (de 1536×1024 para 4096×4096), proporção (adição de 16:9), realismo (eliminação do filtro amarelado), conhecimento de mundo (precisão em marcas/UI), multilinguismo (clareza em CJK/RTL) e restauração de UI (capacidade de simular capturas de tela reais). O gpt-image-1.5 ainda é suficiente para títulos curtos e proporções padrão, mas para impressão comercial, localização e cenários de UI, recomenda-se aguardar o gpt-image-2.
Q3: Quando o gpt-image-2 será lançado?
Até 17/04/2026, a OpenAI ainda não fez um anúncio oficial. Com base no histórico de ciclos de testes em escala de cinza (geralmente seguidos pelo lançamento oficial em 2 a 4 semanas), a indústria estima uma janela de lançamento entre o final de abril e meados de maio de 2026. Os três modelos com codinomes no LM Arena (maskingtape-alpha, gaffertape-alpha, packingtape-alpha) ainda estão em testes A/B.
Q4: Para quais cenários de aplicação o gpt-image-2 é mais adequado?
Ele é ideal para os seguintes cenários específicos:
- Cartazes/catálogos de nível de impressão comercial: Saída nativa em 4K, eliminando a necessidade de pós-processamento de super-resolução.
- Imagens localizadas para redes sociais: Renderização de texto em vários idiomas sem necessidade de edição no Photoshop.
- Rascunhos de design de UI: Geração de capturas de tela de exemplo para exploração de produtos e tutoriais.
- Imagens principais de marketing para e-commerce: Retratos realistas combinados com texto preciso sobre o produto.
- Miniaturas para plataformas de vídeo: Geração em lote com proporção nativa de 16:9.
Q5: Como realizar a invocação do modelo gpt-image-2 rapidamente via API?
Recomendamos a integração antecipada através da APIYI (apiyi.com) para garantir o uso imediato assim que o gpt-image-2 for lançado:
- Acesse apiyi.com, registre uma conta e obtenha sua chave API.
- Utilize
base_url=https://vip.apiyi.com/v1para invocar o atual gpt-image-1.5 e familiarizar-se com os parâmetros. - No dia do lançamento do gpt-image-2, basta substituir o campo
modeldegpt-image-1.5paragpt-image-2.
A APIYI disponibiliza novos modelos simultaneamente à OpenAI; suas chaves, saldo e faturas existentes permanecem inalterados, sem a necessidade de registrar novas contas ou trocar de SDK.
Q6: Quais são as limitações ou incertezas conhecidas do gpt-image-2?
As principais incertezas decorrem do fato de o modelo não ter sido lançado oficialmente:
- Preço desconhecido: O gpt-image-1.5 teve uma redução de preço de cerca de 20% em relação ao gpt-image-1; o preço do gpt-image-2 aguarda confirmação oficial.
- Limites de taxa: Pode haver cotas de invocação no período de lançamento inicial; recomenda-se utilizar um serviço proxy de API para evitar problemas de "cold start".
- Ajustes de capacidade: Pode haver diferenças entre a versão de teste do LM Arena e a versão final; considere o desempenho como uma prévia.
- Plano de contingência: Se o seu projeto for urgente, o atual gpt-image-1.5 continua sendo uma escolha estável e confiável.
Q7: O gpt-image-2 substituirá o DALL-E 3?
Seguindo o ritmo de lançamentos da OpenAI, espera-se que o DALL-E 3 seja gradualmente descontinuado após o lançamento oficial do gpt-image-2. Em termos de migração, a série gpt-image tornou-se a principal aposta oficial, e a estrutura de parâmetros da API já está estável. Recomendamos que novos projetos adotem diretamente o gpt-image-1.5 ou aguardem o gpt-image-2, evitando investir muito esforço em customizações para o DALL-E 3.
Q8: Os modelos da série “tape” no LM Arena são certamente o gpt-image-2?
Não há confirmação oficial, mas quatro evidências apontam fortemente para a OpenAI:
- O estilo de nomenclatura (série "tape") está alinhado com os codinomes históricos da OpenAI.
- As capacidades de renderização de texto (99%) e conhecimento de mundo superam todos os modelos públicos existentes.
- O período de teste coincide com o ritmo habitual de testes em escala de cinza da OpenAI.
- O estilo de saída do modelo é consistente com a série gpt-image (diferente do estilo Midjourney/Imagen).
Recomendamos acompanhar os anúncios oficiais e aguardar a disponibilidade na APIYI (apiyi.com).
Pontos-chave do gpt-image-2
- Modelo de próxima geração: O carro-chefe de imagem da OpenAI para 2026, substituindo o gpt-image-1.5, com arquitetura migrando de duas etapas para inferência única.
- Oito grandes atualizações: Texto com 99% de precisão, velocidade de 3 segundos, 4K nativo, 16:9, realismo, conhecimento de mundo, multilinguismo e restauração de UI.
- Cenários aplicáveis: Priorize a atualização para impressão comercial, anúncios localizados, rascunhos de UI, imagens principais de e-commerce e miniaturas de vídeo.
- Ritmo de lançamento: Previsto para o final de abril a meados de maio de 2026; o codinome atual em escala de cinza é a série "tape".
- Migração perfeita: Integre-se antecipadamente ao gpt-image-1.5 via APIYI (apiyi.com) e, no dia do lançamento, basta substituir o campo
model.
Resumo
Pontos principais do comparativo entre gpt-image-2 e gpt-image-1.5:
- Salto de qualidade: Os três indicadores principais — texto, velocidade e resolução — atingiram ou superaram os padrões de nível de produção, deixando de ser algo "usável, mas que precisa de retoques" para se tornarem ferramentas profissionais.
- Novos cenários: Três cenários — impressão comercial, localização multilíngue e restauração de UI — tornaram-se finalmente viáveis, reduzindo significativamente os custos de pós-processamento manual.
- Migração transparente: A estrutura de parâmetros da API permanece compatível com a do gpt-image-1.5, permitindo que equipes que já se planejaram façam a transição no dia do lançamento sem nenhuma alteração no código.
Para a tomada de decisão da sua equipe, recomendamos integrar o gpt-image-1.5 imediatamente via APIYI (apiyi.com) para se familiarizar com os parâmetros e o fluxo de trabalho. A plataforma oferece cotas gratuitas e uma interface unificada; assim, no dia do lançamento do gpt-image-2, basta alterar o campo model para aproveitar todos os oito grandes benefícios da atualização.
Leitura Recomendada
Se você se interessou pelo gpt-image-2, recomendamos continuar a leitura:
- 📘 Guia completo de invocação da API do gpt-image-1.5 – Domine os parâmetros e as melhores práticas do atual modelo de imagem principal.
- 📊 Comparativo de preço e qualidade: gpt-image-2 vs nano-banana-pro – Entenda a estrutura de custos das principais APIs de imagem.
- 🚀 Otimização de chamadas em lote para APIs de geração de imagens em ambiente de produção – Explore estratégias de pipeline em lote, concorrência e cache.
📚 Referências
-
Análise do MindStudio: Interpretação abrangente de "What Is GPT Image 2"
- Link:
mindstudio.ai/blog/what-is-gpt-image-2 - Descrição: Organização sistemática da matriz de capacidades do gpt-image-2 feita por um blog internacional de alto ranking.
- Link:
-
Análise de vazamento do getimg.ai: Rumores, Vazamentos e Data de Lançamento do GPT Image 2
- Link:
getimg.ai/blog/gpt-image-2-rumours-leaks-release-date-2026 - Descrição: Observações em primeira mão sobre o desempenho dos três modelos codinome "tape" no LM Arena.
- Link:
-
Blog oficial da OpenAI: Comunicado sobre a atualização das funcionalidades de imagem do ChatGPT
- Link:
openai.com/index/new-chatgpt-images-is-here - Descrição: Explicação oficial sobre a trajetória de evolução da série gpt-image.
- Link:
-
Documentação de parâmetros do gpt-image-1.5: Organizado por EvoLink
- Link:
evolink.ai/blog/gpt-image-1-5-guide-features-comparison-access - Descrição: Parâmetros detalhados sobre velocidade, resolução e níveis de qualidade do gpt-image-1.5.
- Link:
Autor: Equipe técnica da APIYI
Troca de conhecimentos: Sinta-se à vontade para discutir na seção de comentários. Para mais materiais, visite a central de documentação da APIYI em docs.apiyi.com