Escolher um modelo de IA que seja rápido e barato é o desafio central que todo desenvolvedor enfrenta em cenários de alta demanda. No dia 3 de março de 2026, o Google lançou oficialmente o Gemini 3.1 Flash Lite Preview, o modelo mais rápido e com melhor custo-benefício da série Gemini 3, projetado especificamente para cenários de alto throughput, como tradução, resumo e classificação.
Valor central: Ao terminar este artigo, você entenderá completamente os parâmetros técnicos, as vantagens de desempenho e os melhores cenários de uso do Gemini 3.1 Flash Lite, além de aprender a utilizá-lo rapidamente com código prático.

Visão geral dos parâmetros principais do Gemini 3.1 Flash Lite
Antes de mergulhar no Gemini 3.1 Flash Lite, confira as especificações técnicas cruciais deste modelo:
| Parâmetro | Especificação do Gemini 3.1 Flash Lite | Descrição |
|---|---|---|
| ID do modelo | gemini-3.1-flash-lite-preview |
Atualmente em versão preview |
| Janela de contexto | 1.000.000 tokens | Contexto longo de nível de milhão |
| Saída máxima | 64.000 tokens | Suporta geração de texto longo |
| Preço de entrada | $0,25 / milhão de tokens | Custo extremamente baixo |
| Preço de saída | $1,50 / milhão de tokens | Saída de alto custo-benefício |
| Velocidade de saída | ~382 tokens/segundo | Resposta ultrarrápida |
| Modalidade de entrada | Texto, imagem, áudio, vídeo | Multimodal nativo |
| Modalidade de saída | Texto | Geração de texto |
| Data de lançamento | 3 de março de 2026 | Lançamento mais recente |
🚀 Início rápido: O Gemini 3.1 Flash Lite Preview já está disponível na plataforma APIYI (apiyi.com), com suporte a chamadas de interface compatíveis com OpenAI, permitindo uma integração rápida sem necessidade de configurações adicionais.
As 5 principais vantagens do Gemini 3.1 Flash Lite
Vantagem 1: Velocidade 2,5 vezes maior
O Gemini 3.1 Flash Lite deu um salto quântico em termos de velocidade. De acordo com os dados de benchmark da Artificial Analysis:
- Tempo para o primeiro token (TTFT): 2,5 vezes mais rápido que o Gemini 2.5 Flash.
- Velocidade de saída: Atinge 382 tokens/segundo, um aumento de 64% em relação aos 232 tokens/segundo do Gemini 2.5 Flash.
- Throughput geral: Aumento de cerca de 45%.
Isso significa que, em cenários sensíveis à latência, como tradução em tempo real, chatbots e resumo de conteúdo, os usuários obtêm uma experiência de resposta quase instantânea.
Vantagem 2: Custo-benefício extremo
A estratégia de preços do Gemini 3.1 Flash Lite é extremamente competitiva:
| Comparação de Preços | Preço de entrada ($/1M tokens) | Preço de saída ($/1M tokens) | Custo total |
|---|---|---|---|
| Gemini 3.1 Flash Lite | $0,25 | $1,50 | ⭐ Mais baixo |
| Gemini 3 Flash | $1,00 | $4,00 | Médio |
| Gemini 3 Pro | $2,50 | $15,00 | Alto |
| Claude 4.5 Haiku | $0,80 | $4,00 | Médio |
| GPT-5 mini | $0,60 | $2,40 | Médio |
Considerando um processamento diário de 1 milhão de tokens, o custo mensal usando o Gemini 3.1 Flash Lite é de apenas cerca de $52,50, uma economia de mais de 80% em comparação com o Gemini 3 Pro.
Vantagem 3: Janela de contexto de 1 milhão de tokens
O Gemini 3.1 Flash Lite suporta uma janela de contexto de 1M de tokens, algo extremamente raro em modelos da mesma faixa de preço. Isso significa que você pode:
- Processar a tradução ou o resumo de livros inteiros de uma só vez.
- Analisar transcrições de horas de reuniões.
- Lidar com a compreensão de bases de código em larga escala e geração de documentação.
- Realizar traduções comparativas multilíngues de documentos longos.
Vantagem 4: Suporte multimodal nativo
Embora posicionado como um modelo leve, o Gemini 3.1 Flash Lite mantém capacidades completas de entrada multimodal:
- Texto: Compreensão e geração de texto padrão.
- Imagem: Reconhecimento e compreensão de imagens.
- Áudio: Processamento de conteúdo de voz.
- Vídeo: Compreensão de conteúdo de vídeo.
Isso o torna adequado não apenas para tarefas puramente de texto, mas também para cenários multimodais, como tradução de imagens com texto e geração de legendas para vídeos.
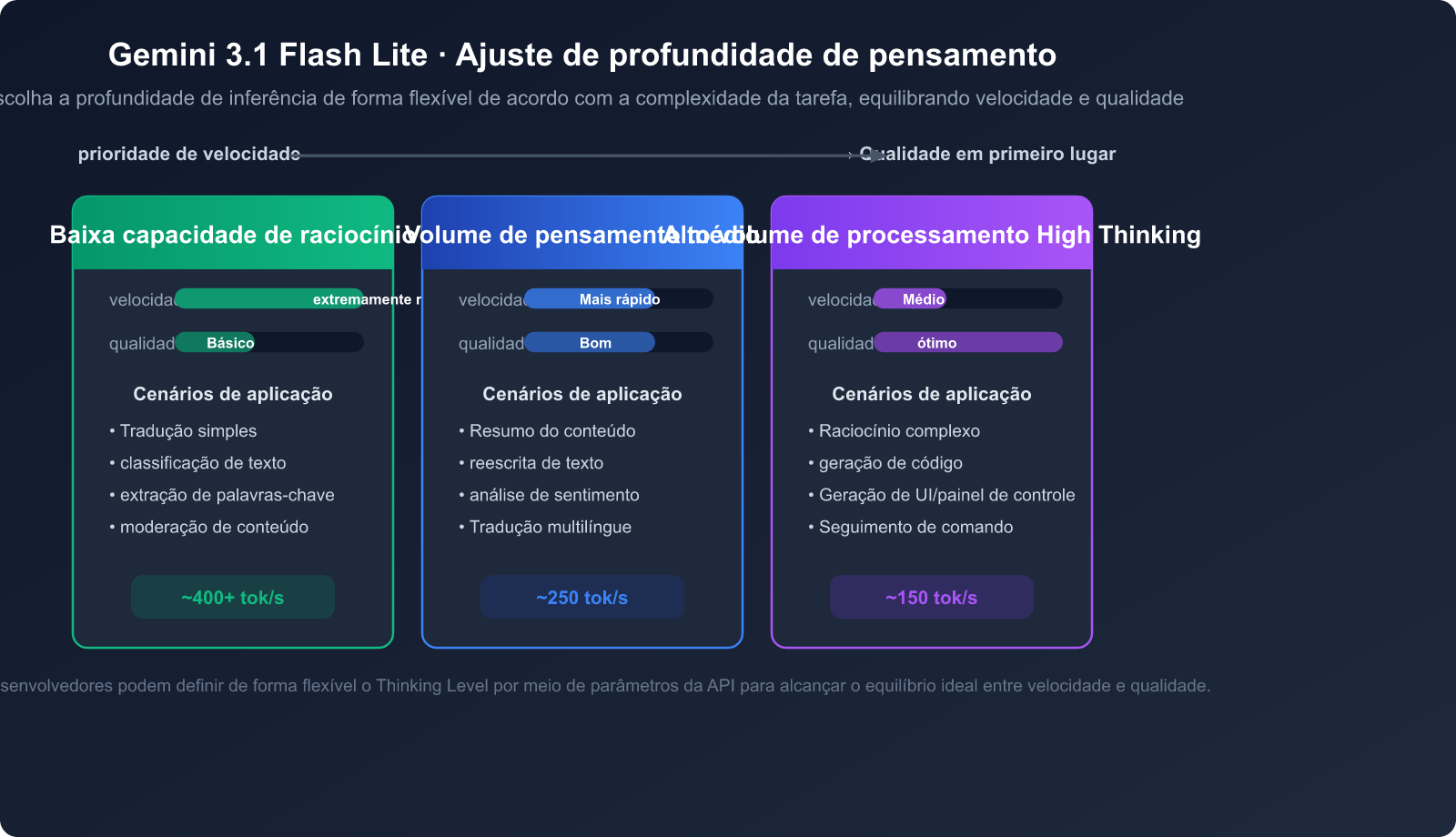
Vantagem 5: Profundidade de pensamento ajustável
O Gemini 3.1 Flash Lite suporta a funcionalidade Thinking Levels, permitindo que os desenvolvedores ajustem a profundidade de raciocínio do modelo de forma flexível, de acordo com a complexidade da tarefa:
- Baixo nível de pensamento: Adequado para traduções simples, classificação e outras tarefas que exigem velocidade máxima.
- Médio nível de pensamento: Adequado para resumos, reescrita de conteúdo e outras tarefas que exigem um certo nível de compreensão.
- Alto nível de pensamento: Adequado para raciocínio complexo, geração de código e outras tarefas que exigem pensamento profundo.
Benchmarks de desempenho do Gemini 3.1 Flash Lite
O Gemini 3.1 Flash Lite alcançou uma pontuação Elo de 1432 no ranking Arena.ai, destacando-se entre os modelos de sua categoria.
| Benchmark | Gemini 3.1 Flash Lite | Descrição |
|---|---|---|
| GPQA Diamond | 86.9% | Raciocínio científico |
| MMMU-Pro | 76.8% | Raciocínio multimodal |
| MMMLU | 88.9% | Perguntas e respostas multilíngues |
| LiveCodeBench | 72.0% | Geração de código |
| Video-MMMU | 84.8% | Compreensão de vídeo |
| SimpleQA | 43.3% | Conhecimento parametrizado |
| MRCR v2 (128k) | 60.1% | Compreensão de contexto longo |
Vale ressaltar que, em 6 benchmarks, incluindo GPQA Diamond e MMMLU, o Gemini 3.1 Flash Lite superou o GPT-5 mini e o Claude 4.5 Haiku, provando que modelos leves também podem oferecer um desempenho inteligente de ponta.
🎯 Dica técnica: Os dados de benchmark acima mostram que o Gemini 3.1 Flash Lite tem um desempenho excelente no processamento multilíngue (MMMLU 88.9%), sendo ideal para cenários de tradução entre idiomas. Através da APIYI apiyi.com, você pode realizar rapidamente a invocação do modelo para testes de tarefas multilíngues.
Primeiros passos com o Gemini 3.1 Flash Lite
Exemplo de código minimalista
Usando a interface compatível com OpenAI, basta poucas linhas de código para invocar o Gemini 3.1 Flash Lite:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interface unificada da APIYI
)
# Exemplo de cenário de tradução
response = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": "Você é um tradutor profissional. Por favor, traduza a entrada do usuário de chinês para português, mantendo o sentido original e o tom."},
{"role": "user", "content": "人工智能正在深刻改变我们的工作方式和生活方式。"}
],
temperature=0.3
)
print(response.choices[0].message.content)
Ver código completo: Tradução em lote + Cenário de resumo
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interface unificada da APIYI
)
MODEL = "gemini-3.1-flash-lite-preview"
def translate_text(text, target_lang="Portuguese"):
"""Traduz texto para o idioma alvo"""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Traduza o seguinte texto para {target_lang}. Mantenha o significado e o tom originais."},
{"role": "user", "content": text}
],
temperature=0.3
)
return response.choices[0].message.content
def summarize_text(text, max_words=100):
"""Gera um resumo do texto"""
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Resuma os pontos principais do conteúdo a seguir em no máximo {max_words} palavras."},
{"role": "user", "content": text}
],
temperature=0.5
)
return response.choices[0].message.content
def classify_text(text, categories):
"""Classificação de texto"""
cats = ", ".join(categories)
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": f"Classifique o texto a seguir em uma destas categorias: {cats}. Retorne apenas o nome da categoria."},
{"role": "user", "content": text}
],
temperature=0.1
)
return response.choices[0].message.content
# Exemplo de uso
texts = [
"A computação quântica revolucionará o campo da criptografia na próxima década",
"A autonomia de novos carros elétricos ultrapassa 1000 km",
"O Banco Central anunciou uma redução de 25 pontos-base na taxa básica de juros"
]
categories = ["Tecnologia", "Automotivo", "Finanças", "Esportes", "Entretenimento"]
for text in texts:
# Tradução
translated = translate_text(text)
# Classificação
category = classify_text(text, categories)
# Resumo
summary = summarize_text(text, max_words=30)
print(f"Original: {text}")
print(f"Tradução: {translated}")
print(f"Categoria: {category}")
print(f"Resumo: {summary}")
print("---")
💰 Otimização de custos: Para cenários de alta frequência como tradução, resumo e classificação, o preço extremamente baixo do Gemini 3.1 Flash Lite (entrada a apenas $0,25 por milhão de tokens) pode reduzir significativamente os custos operacionais. Ao utilizar a plataforma APIYI apiyi.com, você também obtém vantagens adicionais de preço e créditos de teste gratuitos.
Melhores cenários de uso para o Gemini 3.1 Flash Lite
Cenário 1: Tradução em lote de alta frequência
O Gemini 3.1 Flash Lite alcançou uma pontuação impressionante de 88,9% no benchmark de perguntas e respostas multilíngue MMMLU. Aliado ao seu custo de invocação extremamente baixo e velocidade de resposta ultrarrápida, ele é a escolha ideal para tarefas de tradução em lote:
- Tradução de descrições de produtos de e-commerce: Tradução multilíngue de dezenas de milhares de informações de produtos diariamente.
- Tradução de comentários de usuários: Tradução em tempo real do feedback de usuários internacionais.
- Internacionalização de documentação técnica: Geração de versões em vários idiomas para documentos em larga escala.
- Tradução de legendas: Conversão rápida de legendas de vídeo para vários idiomas.
Cenário 2: Resumo de conteúdo em tempo real
A velocidade de saída de 382 tokens/segundo o torna perfeito para cenários de resumo em tempo real:
- Geração de resumos de notícias: Extração automática de resumos de grandes volumes de notícias.
- Atas de reuniões: Resumo rápido de gravações de reuniões longas.
- Revisão de literatura: Geração de resumos em lote para artigos acadêmicos.
- Resumo de e-mails: Classificação e resumo automático de e-mails corporativos.
Cenário 3: Moderação e classificação de conteúdo em larga escala
Suas características de baixa latência e baixo custo o tornam a escolha ideal para pipelines de moderação de conteúdo:
- Moderação de conteúdo gerado pelo usuário: Filtragem de segurança de conteúdo em plataformas sociais.
- Classificação automática de tickets: Roteamento inteligente para sistemas de atendimento ao cliente.
- Análise de sentimento: Monitoramento em tempo real da reputação da marca.
- Geração automática de tags: Marcação automática para sistemas de gerenciamento de conteúdo.
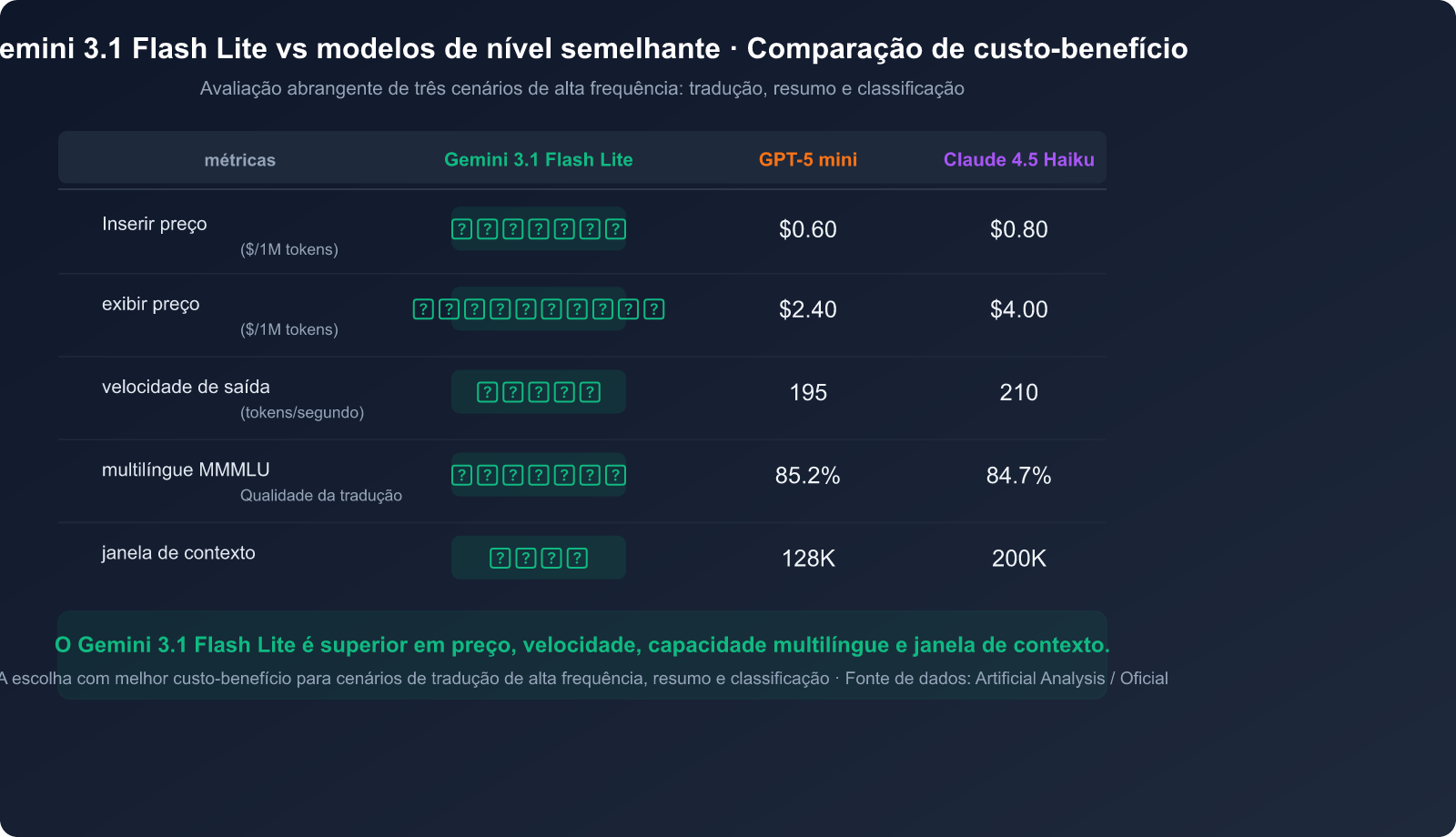
Guia de decisão de cenários
| Cenário de uso | Motivo da recomendação | Vantagem chave | Custo mensal estimado |
|---|---|---|---|
| Tradução em lote | Capacidade multilíngue MMMLU 88,9% | Baixo custo + alta qualidade | ~$50 (1 milhão de tokens/dia) |
| Resumo em tempo real | Saída ultrarrápida de 382 tokens/s | Baixa latência + velocidade | ~$30 (500 mil tokens/dia) |
| Moderação de conteúdo | Alta precisão e resposta rápida | Baixo custo + processamento em lote | ~$20 (300 mil tokens/dia) |
| Chatbot | TTFT 2,5x mais rápido | Resposta instantânea | ~$80 (2 milhões de tokens/dia) |
| Processamento de documentos longos | Janela de contexto de 1M de tokens | Processamento de livros inteiros | Cobrança sob demanda |
💡 Dica de escolha: Se o seu cenário de negócios envolve tarefas de processamento de texto de alta frequência, em lote e sensíveis a custos, o Gemini 3.1 Flash Lite é atualmente a escolha com o melhor custo-benefício. Recomendamos realizar testes em cenários reais através da plataforma APIYI (apiyi.com), que permite alternar facilmente entre diferentes modelos para comparar resultados.
Observações sobre o uso do Gemini 3.1 Flash Lite
Limitações atuais
Como se trata de uma versão de visualização (Preview), é importante ter em mente os seguintes pontos:
- Fase de visualização: O modelo ainda está em estado Preview, portanto, a interface da API e o comportamento podem sofrer ajustes.
- Limites de saída: A saída máxima é de 64K tokens; tarefas de geração muito longas precisam ser processadas em partes.
- Desempenho com contexto ultralongo: O desempenho em cenários de contexto extremo de 1M de tokens é mediano (apenas 12,3% no teste MRCR v2 1M). Recomendamos manter o uso dentro de 128K para obter os melhores resultados.
- Limites de segurança: A pontuação de segurança para a conversão de imagem para texto ainda precisa ser aprimorada; adicione uma camada de verificação ao lidar com conteúdos sensíveis.
Sugestões de uso
- Parâmetro de temperatura: Para tarefas de tradução, recomendamos
temperature=0.3; para tarefas de resumo,temperature=0.5. - Comando de sistema: Fornecer definições de papel claras e requisitos de formato de saída pode melhorar significativamente a qualidade do resultado.
- Processamento em lote: Utilize chamadas assíncronas para aumentar a taxa de transferência e aproveitar ao máximo a velocidade do modelo.
- Controle de contexto: Embora suporte uma janela de contexto de 1M, sugerimos manter as tarefas comuns dentro de 128K para obter a melhor relação custo-benefício.
Perguntas frequentes
Q1: Qual é a diferença entre o Gemini 3.1 Flash Lite e o Gemini 3 Flash?
O Gemini 3.1 Flash Lite é a versão leve da série Gemini 3, otimizada para cenários de alta frequência e baixo custo. Comparado ao Gemini 3 Flash, seu preço de entrada é 75% menor ($0,25 vs $1,00) e a velocidade de saída é cerca de 64% mais rápida, embora sua capacidade em tarefas de raciocínio complexo seja ligeiramente inferior. Em resumo: escolha o Flash Lite para o melhor custo-benefício e o Flash se precisar de maior capacidade de raciocínio. Através da plataforma APIYI (apiyi.com), você pode testar ambos os modelos e encontrar rapidamente o que melhor se adapta ao seu cenário.
Q2: O Gemini 3.1 Flash Lite é adequado para tradução?
Muito adequado. O Gemini 3.1 Flash Lite obteve uma pontuação alta de 88,9% no benchmark multilíngue MMMLU, liderando entre os modelos da mesma categoria. Somado ao preço de entrada ultrabaixo de $0,25 por milhão de tokens e uma velocidade de saída de 382 tokens/segundo, é um dos modelos com melhor custo-benefício para tarefas de tradução em lote. Recomendamos obter créditos de teste gratuitos na APIYI (apiyi.com) para validar a qualidade da tradução na prática.
Q3: Como chamar o Gemini 3.1 Flash Lite através de uma interface compatível com OpenAI?
Basta definir a base_url para o endereço da API da APIYI e usar gemini-3.1-flash-lite-preview no parâmetro model. Não é necessário modificar a estrutura do código do SDK da OpenAI, permitindo uma transição perfeita. Veja os exemplos de código na seção "Introdução Rápida" deste artigo.
Q4: A janela de contexto de 1M do Gemini 3.1 Flash Lite é realmente útil?
Ele apresenta um excelente desempenho dentro da faixa de 128K tokens (pontuação de 60,1% no MRCR v2 128K), mas o desempenho cai significativamente em cenários extremos de 1M de tokens (pontuação de 12,3% no MRCR v2 1M). Recomendamos manter o uso diário dentro de 128K e adotar estratégias de segmentação ao lidar com documentos muito longos.
Resumo
O Gemini 3.1 Flash Lite Preview tornou-se o campeão de custo-benefício para cenários de alta frequência em 2026, como tradução, resumo e classificação, graças ao seu preço ultra-baixo de US$ 0,25 por milhão de tokens de entrada, velocidade de saída impressionante de 382 tokens/segundo, uma janela de contexto de 1 milhão de tokens e excelente desempenho em benchmarks como processamento multilíngue (MMMLU 88,9%) e raciocínio científico (GPQA Diamond 86,9%).
Se você precisa processar milhões de tokens diariamente em traduções em lote ou construir serviços de resumo em tempo real com baixa latência, o Gemini 3.1 Flash Lite é a escolha ideal.
Recomendamos o acesso rápido ao Gemini 3.1 Flash Lite Preview através da APIYI (apiyi.com). A plataforma oferece uma interface compatível com OpenAI e suporte para alternar entre vários modelos principais com um clique, facilitando a validação de resultados e a comparação de modelos.
Referências
-
Google DeepMind – Ficha Técnica do Modelo Gemini 3.1 Flash-Lite: Especificações técnicas oficiais e dados de benchmark
- Link:
deepmind.google/models/model-cards/gemini-3-1-flash-lite/
- Link:
-
Google AI for Developers – Gemini 3.1 Flash-Lite Preview: Documentação oficial da API e guia do desenvolvedor
- Link:
ai.google.dev/gemini-api/docs/models/gemini-3.1-flash-lite-preview
- Link:
-
Artificial Analysis – Avaliação de Desempenho: Benchmarks independentes de velocidade e desempenho
- Link:
artificialanalysis.ai/models/gemini-3-1-flash-lite-preview
- Link:
📝 Autor: Equipe Técnica APIYI | Para mais guias de uso de modelos de IA e tutoriais técnicos, visite a Central de Ajuda da APIYI em help.apiyi.com