Nota do autor: Detalhamos como o PaperBanana cria gráficos estatísticos científicos gerando código Matplotlib executável em vez de imagens de pixels, eliminando completamente o problema da alucinação numérica, abrangendo 7 tipos de gráficos, incluindo barras, linhas e dispersão.
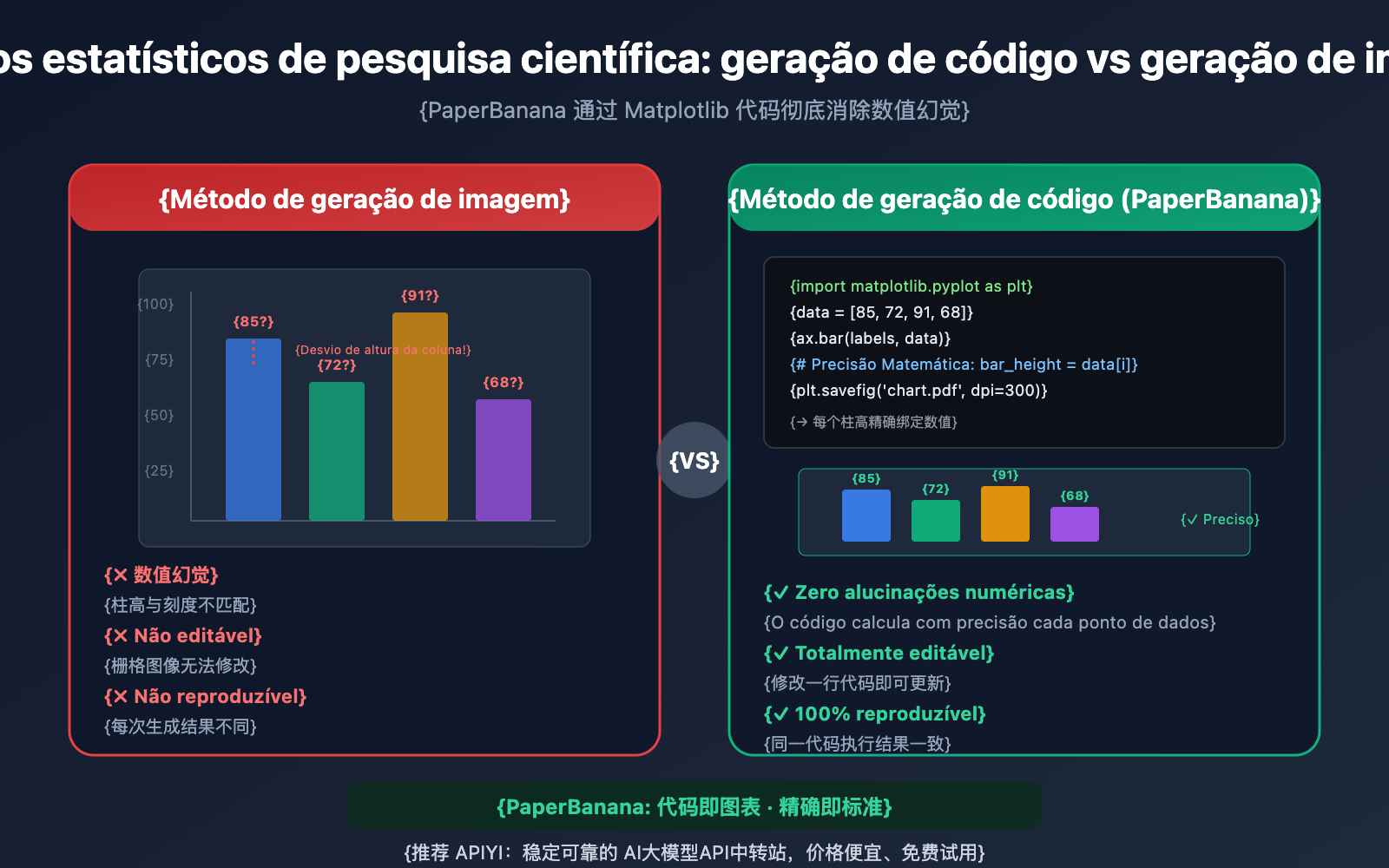
Gráficos estatísticos em artigos científicos carregam as conclusões centrais do experimento — a altura das barras, a tendência das linhas, a distribuição dos pontos de dispersão; cada ponto de dado deve ser preciso. No entanto, ao usar geradores de imagem genéricos como DALL-E ou Midjourney para criar esses gráficos, um problema fatal persiste: alucinação numérica (Numerical Hallucination). Alturas de barras que não batem com a escala, pontos de dados deslocados, rótulos de eixos errados — esses gráficos que "parecem certos, mas têm dados errados" podem ter consequências desastrosas se aparecerem em um artigo.
Valor central: Ao ler este artigo, você entenderá por que o PaperBanana opta pela geração de código em vez de imagens para criar gráficos científicos, dominará os métodos de geração de código Matplotlib para 7 tipos de gráficos e aprenderá como realizar visualização de dados acadêmicos com zero alucinação numérica e baixo custo usando a API Nano Banana Pro.
Pontos principais dos gráficos estatísticos científicos do Nano Banana Pro
| Ponto Principal | Descrição | Valor |
|---|---|---|
| Geração de código, não de pixels | O PaperBanana gera código Matplotlib executável, em vez de renderizar imagens diretamente | Altura das barras, pontos de dados e eixos são 100% matematicamente precisos |
| Eliminação total de alucinações numéricas | O direcionamento por código garante que o valor de cada ponto de dados seja idêntico aos dados originais | Evita o problema fatal de "parecer certo, mas os dados estarem errados" |
| Cobertura de 7 tipos de gráficos | Gráficos de barras, linhas, dispersão, mapas de calor, radar, pizza e painéis múltiplos | Atende a mais de 95% das necessidades de gráficos estatísticos em artigos científicos |
| 240 testes ChartMimic | Validado em benchmarks padrão para garantir que o código gerado seja executável e visualmente correspondente | 72,7% de taxa de vitória em avaliação cega, cobrindo linhas/barras/dispersão/painéis múltiplos |
| Editável e reproduzível | O código Python de saída permite ajustar livremente cores, anotações e fontes | Não é necessário gerar novamente; pode ser refinado diretamente para o padrão de publicação |
Por que gráficos estatísticos científicos não podem ser gerados como imagens
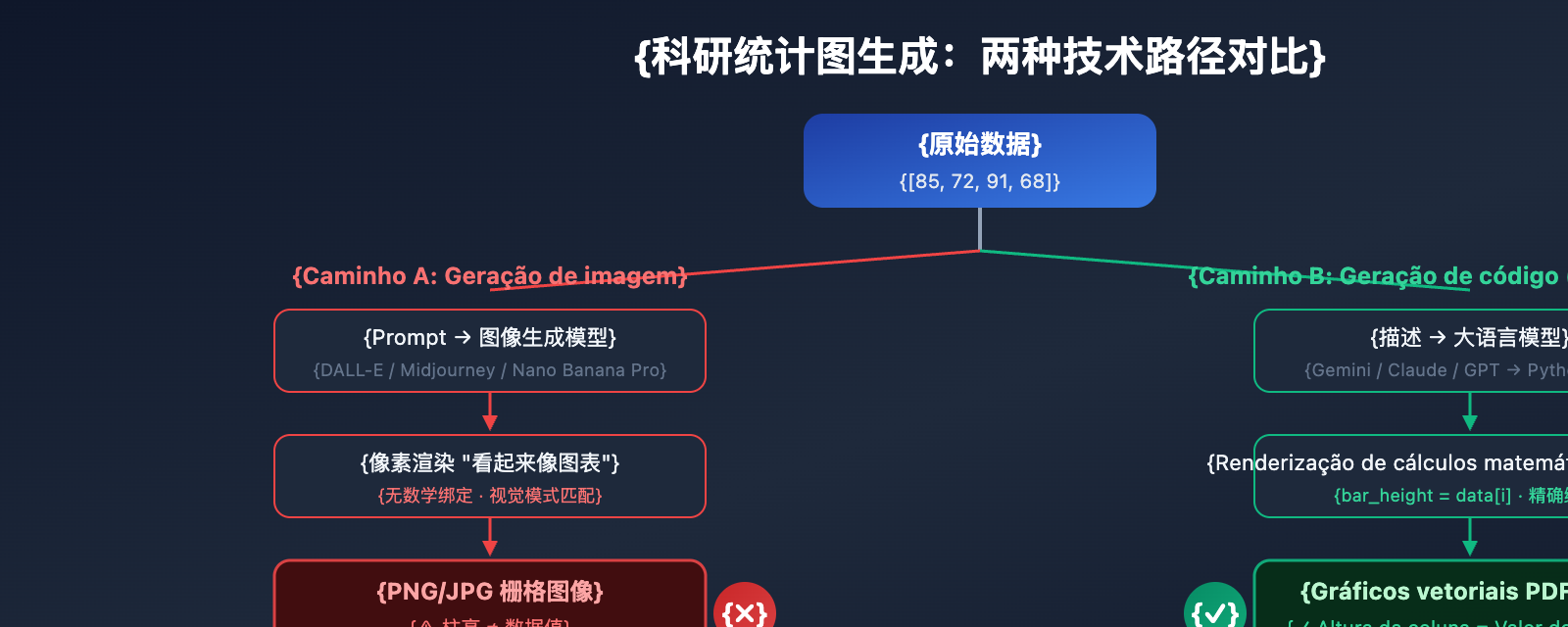
Os modelos tradicionais de geração de imagem por IA (como DALL-E 3 ou Midjourney V7) enfrentam uma falha fundamental ao criar gráficos estatísticos científicos: eles renderizam o gráfico como "pixels", em vez de desenhá-lo com base em "dados". Isso significa que, ao gerar um gráfico de barras, o modelo não calcula a altura da barra com base em valores como [85, 72, 91, 68], mas sim preenche os pixels de acordo com um padrão visual que "parece um gráfico de barras".
O resultado é a alucinação numérica — as alturas das barras não correspondem à escala do eixo Y, os pontos de dados se desviam de suas posições reais e os rótulos dos eixos aparecem distorcidos ou incorretos. Nas avaliações do PaperBanana, ao usar modelos de geração de imagem diretamente para criar gráficos estatísticos, "alucinação numérica e repetição de elementos" foram os erros de fidelidade mais comuns.
O PaperBanana adota uma estratégia completamente diferente: para gráficos estatísticos, o agente Visualizer não utiliza a capacidade de geração de imagem do Nano Banana Pro, mas sim gera código Python Matplotlib executável. Essa abordagem de "código primeiro" elimina fundamentalmente a alucinação numérica — pois o código vincula os dados aos elementos visuais seguindo cálculos matemáticos precisos.
Análise profunda do problema de alucinação numérica
O que é alucinação numérica em gráficos estatísticos científicos
A alucinação numérica refere-se ao fenômeno em que modelos de IA de geração de imagem produzem elementos visuais inconsistentes com os dados reais ao criar gráficos estatísticos. As manifestações específicas incluem:
- Desvio na altura das barras: A altura das barras em um gráfico de barras não corresponde aos valores da escala do eixo Y.
- Deriva de pontos de dados: Os pontos em um gráfico de dispersão desviam-se das coordenadas (x, y) corretas.
- Erros de escala: O espaçamento entre as marcas dos eixos não é uniforme ou os valores marcados estão incorretos.
- Confusão na legenda: As cores da legenda não correspondem às séries de dados reais.
- Rótulos corrompidos: Erros de ortografia ou sobreposição de texto nos rótulos dos eixos.
A causa raiz da alucinação numérica
O objetivo do treinamento de modelos genéricos de geração de imagem é "gerar imagens visualmente realistas", e não "gerar gráficos matematicamente precisos". Quando o modelo vê em um comando algo como "gráfico de barras, valores [85, 72, 91, 68]", ele não estabelece um mapeamento matemático do valor para a altura do pixel; em vez disso, ele gera uma aparência aproximada baseada nos "padrões visuais" de inúmeros gráficos de barras presentes em seu conjunto de treinamento.
| Tipo de Problema | Manifestação Específica | Frequência | Gravidade |
|---|---|---|---|
| Desvio na altura das barras | Altura da barra não condiz com o valor | Altíssima | Fatal: Altera a conclusão do experimento |
| Deriva de pontos de dados | Pontos desviam das coordenadas corretas | Alta | Fatal: Distorção de dados |
| Erros de escala | Escala do eixo não é uniforme | Alta | Grave: Induz o leitor ao erro |
| Confusão na legenda | Cores não batem com as séries | Média | Grave: Impossível distinguir os dados |
| Rótulos corrompidos | Texto sobreposto ou erro de escrita | Média | Moderada: Afeta a legibilidade |
Como o método de geração de código do PaperBanana elimina a alucinação numérica
A solução do PaperBanana é simples e definitiva: para gráficos estatísticos científicos, ele não gera uma imagem, mas sim um código.
Quando o agente Visualizer do PaperBanana recebe uma tarefa de gráfico estatístico, ele converte a descrição do gráfico em código Python Matplotlib executável. Neste código, a altura de cada barra, a coordenada de cada ponto de dado e a escala de cada eixo são determinadas precisamente através de cálculos matemáticos — e não por "palpites" de uma rede neural.
Essa abordagem baseada em código traz um valor adicional importante: editabilidade. Você não recebe uma imagem rasterizada impossível de modificar, mas sim um código Python claro. Você pode ajustar livremente cores, fontes, anotações, posições de legenda e até modificar os dados subjacentes e rodar novamente — o que é extremamente útil para as demandas de modificação durante a fase de revisão (peer review) de periódicos.
🎯 Sugestão Técnica: A capacidade de geração de código do PaperBanana é impulsionada por um Modelo de Linguagem Grande. Você também pode chamar modelos como o Nano Banana Pro diretamente via APIYI (apiyi.com) para gerar código Matplotlib. A plataforma suporta interface compatível com OpenAI e o custo por chamada é extremamente baixo.
Geração de código para 7 tipos de gráficos científicos com Nano Banana Pro
O PaperBanana validou a eficácia do método de geração de código em 240 casos de teste do benchmark ChartMimic, cobrindo tipos comuns como gráficos de linha, barras, dispersão e multipainel. Abaixo estão os modelos de comando e exemplos de código para 7 categorias de gráficos científicos.
Categoria 1: Gráfico de Barras (Bar Chart)
O gráfico de barras é um dos tipos mais usados em artigos científicos para comparar resultados experimentais sob diferentes condições.
import matplotlib.pyplot as plt
import numpy as np
# Dados experimentais
models = ['GPT-4o', 'Claude 4', 'Gemini 2', 'Llama 3', 'Qwen 3']
accuracy = [89.2, 91.5, 87.8, 83.4, 85.1]
colors = ['#3b82f6', '#10b981', '#f59e0b', '#ef4444', '#8b5cf6']
fig, ax = plt.subplots(figsize=(8, 5))
bars = ax.bar(models, accuracy, color=colors, width=0.6, edgecolor='white')
# Adicionar rótulos de valores
for bar, val in zip(bars, accuracy):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.5,
f'{val}%', ha='center', va='bottom', fontsize=10, fontweight='bold')
ax.set_ylabel('Accuracy (%)', fontsize=12)
ax.set_title('Model Performance Comparison on MMLU Benchmark', fontsize=14)
ax.set_ylim(75, 95)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.tight_layout()
plt.savefig('bar_chart.pdf', dpi=300, bbox_inches='tight')
plt.show()
Categoria 2: Gráfico de Linhas (Line Chart)
Gráficos de linha mostram tendências ao longo do tempo ou condições, ideais para curvas de treinamento e experimentos de ablação.
import matplotlib.pyplot as plt
import numpy as np
epochs = np.arange(1, 21)
train_loss = 2.5 * np.exp(-0.15 * epochs) + 0.3 + np.random.normal(0, 0.02, 20)
val_loss = 2.5 * np.exp(-0.12 * epochs) + 0.45 + np.random.normal(0, 0.03, 20)
fig, ax = plt.subplots(figsize=(8, 5))
ax.plot(epochs, train_loss, 'o-', color='#3b82f6', label='Train Loss', linewidth=2, markersize=4)
ax.plot(epochs, val_loss, 's--', color='#ef4444', label='Val Loss', linewidth=2, markersize=4)
ax.set_xlabel('Epoch', fontsize=12)
ax.set_ylabel('Loss', fontsize=12)
ax.set_title('Training and Validation Loss Curves', fontsize=14)
ax.legend(fontsize=11, frameon=False)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.tight_layout()
plt.savefig('line_chart.pdf', dpi=300, bbox_inches='tight')
plt.show()
Categoria 3: Gráfico de Dispersão (Scatter Plot)
Usado para mostrar a correlação entre duas variáveis ou a distribuição de clusters.
Categoria 4: Mapa de Calor (Heatmap)
Ideal para exibir matrizes de confusão, matrizes de peso de atenção e matrizes de coeficientes de correlação.
Categoria 5: Gráfico de Radar (Radar Chart)
Usado para comparação de capacidades multidimensionais, comum em avaliações abrangentes de modelos.
Categoria 6: Gráfico de Pizza/Rosca (Pie/Donut Chart)
Exibe proporções de composição, adequado para análise de distribuição de conjuntos de dados e alocação de recursos.
Categoria 7: Gráfico Combinado Multipainel (Multi-Panel)
Combina vários subgráficos em uma única figura, sendo a forma de gráfico composto mais comum em artigos científicos.
| Tipo de Gráfico | Cenário Aplicável | Função Principal Matplotlib | Uso Comum |
|---|---|---|---|
| Gráfico de Barras | Comparação discreta | ax.bar() |
Comparação de performance, ablação |
| Gráfico de Linhas | Tendência de mudança | ax.plot() |
Curvas de treinamento, análise de convergência |
| Gráfico de Dispersão | Correlação/Cluster | ax.scatter() |
Distribuição de características, visualização de embeddings |
| Mapa de Calor | Dados matriciais | sns.heatmap() |
Matriz de confusão, pesos de atenção |
| Gráfico de Radar | Comparação multidimensional | ax.plot() + polar |
Avaliação abrangente de modelos |
| Gráfico de Pizza | Composição proporcional | ax.pie() |
Distribuição de dataset |
| Multipainel | Exibição composta | plt.subplots() |
Figura 1(a)(b)(c) |
💰 Otimização de Custos: Ao usar a APIYI (apiyi.com) para chamar Modelos de Linguagem Grande para gerar código Matplotlib, o custo por chamada é muito menor do que a geração de imagens. Gerar um código Matplotlib de 50 linhas custa cerca de $0,01, e o código pode ser modificado e executado repetidamente sem a necessidade de chamar a API novamente. Também recomendamos o uso da ferramenta online Image.apiyi.com para validar rapidamente os efeitos de visualização.
Início Rápido com Gráficos Estatísticos Científicos no Nano Banana Pro
Exemplo Minimalista: Gerando código de gráfico de barras preciso com IA
Aqui está a maneira mais simples de chamar um Modelo de Linguagem Grande via API para que a IA gere automaticamente o código Matplotlib com base nos seus dados:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # Usando a interface unificada da APIYI
)
response = client.chat.completions.create(
model="gemini-2.5-flash",
messages=[{
"role": "user",
"content": """Generate publication-ready Python Matplotlib code for a grouped bar chart.
Data:
- Models: ['Method A', 'Method B', 'Method C', 'Ours']
- BLEU Score: [32.1, 35.4, 33.8, 38.7]
- ROUGE-L: [41.2, 43.8, 42.1, 47.3]
Requirements:
- Grouped bars with distinct colors (blue and green)
- Value labels on top of each bar
- Clean academic style, no top/right spines
- Title: 'Translation Quality Comparison'
- Save as PDF at 300 dpi
- Figsize: (8, 5)"""
}]
)
print(response.choices[0].message.content)
Ver a ferramenta completa de geração de código para gráficos estatísticos científicos
import openai
from typing import Dict, List, Optional
def generate_chart_code(
chart_type: str,
data: Dict,
title: str,
style: str = "academic",
figsize: str = "(8, 5)",
save_format: str = "pdf"
) -> str:
"""
Usa IA para gerar código Matplotlib para gráficos estatísticos científicos
Args:
chart_type: Tipo de gráfico - bar/line/scatter/heatmap/radar/pie/multi-panel
data: Dicionário de dados, contendo rótulos e valores
title: Título do gráfico
style: Estilo - academic/minimal/detailed
figsize: Tamanho da figura
save_format: Formato de exportação - pdf/png/svg
Returns:
Código Python Matplotlib executável
"""
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # Interface unificada APIYI
)
style_guide = {
"academic": "Clean academic style: no top/right spines, "
"serif fonts, 300 dpi, tight layout",
"minimal": "Minimal style: grayscale-friendly, thin lines, "
"no grid, compact layout",
"detailed": "Detailed style: with grid, annotations, "
"error bars where applicable"
}
prompt = f"""Generate publication-ready Python Matplotlib code.
Chart type: {chart_type}
Data: {data}
Title: {title}
Style: {style_guide.get(style, style_guide['academic'])}
Figure size: {figsize}
Export: Save as {save_format} at 300 dpi
Requirements:
- All data values must be mathematically precise
- Include proper axis labels and legend
- Use colorblind-friendly palette
- Code must be executable without modification
- Add value annotations where appropriate"""
try:
response = client.chat.completions.create(
model="gemini-2.5-flash",
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# Exemplo de uso: gerar gráfico de barras de comparação de desempenho de modelos
code = generate_chart_code(
chart_type="grouped_bar",
data={
"models": ["GPT-4o", "Claude 4", "Gemini 2", "Ours"],
"accuracy": [89.2, 91.5, 87.8, 93.1],
"f1_score": [87.5, 90.1, 86.3, 92.4]
},
title="Model Performance on SQuAD 2.0",
style="academic"
)
print(code)
🚀 Início Rápido: Recomendamos usar a plataforma APIYI (apiyi.com) para chamar modelos de IA e gerar códigos de gráficos estatísticos. A plataforma suporta vários modelos como Gemini, Claude e GPT, todos capazes de gerar código Matplotlib de alta qualidade. Cadastre-se para ganhar créditos gratuitos e gere seu primeiro código de gráfico em 5 minutos.
Geração de Código vs. Geração de Imagem: Comparação de Qualidade em Gráficos Científicos
Por que o PaperBanana abandonou a geração de imagens do Nano Banana Pro em cenários de gráficos estatísticos científicos e passou a usar a geração de código? Os dados comparativos a seguir explicam tudo.

Problemas com a geração direta de imagens
Ao usar o Nano Banana Pro, DALL-E 3 ou Midjourney para gerar gráficos estatísticos científicos diretamente, o modelo tenta "desenhar" uma imagem que parece um gráfico usando pixels. Embora o efeito visual possa ser bom, os seguintes problemas são quase inevitáveis:
- Valores imprecisos: Não há vínculo matemático entre a altura das barras e os dados reais.
- Não editável: A saída é uma imagem rasterizada, impossibilitando a modificação de pontos de dados individuais.
- Não reprodutível: É impossível obter exatamente o mesmo gráfico executando o comando novamente.
- Rótulos propensos a erros: Os rótulos dos eixos costumam apresentar erros de ortografia ou valores incorretos.
Vantagens da geração de código
A abordagem de geração de código do PaperBanana é completamente diferente:
- Vínculo matemático: Cada elemento visual é calculado com precisão a partir dos valores no código.
- Editável: Basta alterar uma linha de código para atualizar cores, rótulos ou dados.
- Reprodutível: O mesmo trecho de código produz resultados idênticos em qualquer ambiente.
- Amigável para revisores: Quando um revisor solicita alterações no gráfico, basta ajustar os parâmetros do código.
| Dimensão de Comparação | Geração de Imagem (Nano Banana Pro, etc.) | Geração de Código (Método PaperBanana) |
|---|---|---|
| Precisão Numérica | Baixa: Aproximação por pixels, sujeita a alucinações | Alta: Precisão matemática, zero alucinações |
| Editabilidade | Nenhuma: Imagem rasterizada não modificável | Forte: Atualização via alteração de código |
| Reprodutibilidade | Baixa: Cada geração produz um resultado diferente | Alta: Resultados consistentes na execução do código |
| Precisão de Rótulos | Média: Aprox. 78-94% de precisão no texto | Alta: Controle preciso do texto via código |
| Revisão e Modificação | Requer gerar toda a imagem novamente | Ajuste de parâmetros e reexecução rápida |
| Formato de Saída | Imagem rasterizada PNG/JPG | Gráfico vetorial PDF/SVG/EPS |
🎯 Sugestão de Escolha: Para gráficos estatísticos científicos que precisam exibir valores precisos (barras, linhas, dispersão, etc.), recomendamos fortemente o uso da geração de código. Se o seu gráfico for focado em conceitos visuais (diagramas de metodologia, arquitetura), a geração de imagens do Nano Banana Pro é mais adequada. Através da plataforma APIYI (apiyi.com), você pode chamar modelos de geração de imagem e de texto simultaneamente, alternando com flexibilidade.
Dicas de Engenharia de Prompt para Gráficos Estatísticos Científicos no Nano Banana Pro
A chave para fazer a IA gerar código Matplotlib de alta qualidade está no nível de estruturação do seu comando (prompt). Aqui estão 5 dicas fundamentais e comprovadas.
Dica 1: Os dados devem ser fornecidos explicitamente
Nunca deixe a IA "inventar" dados. Forneça explicitamente os valores completos no comando, incluindo legendas, valores e unidades.
✅ Correto: Data: models=['A','B','C'], accuracy=[89.2, 91.5, 87.8]
❌ Errado: Generate a bar chart comparing three models
Dica 2: Especifique restrições de estilo acadêmico
Gráficos acadêmicos possuem requisitos rigorosos de layout. No comando, deixe claro as seguintes restrições:
- Remover as bordas superior e direita (
spines['top'].set_visible(False)) - Hierarquia de tamanhos de fonte: Título 14pt, rótulos dos eixos 12pt, marcações (ticks) 10pt
- Paleta de cores amigável para daltônicos (evite a combinação vermelho-verde)
- Saída em formato PDF/EPS com 300+ dpi
Dica 3: Solicite a inclusão de rótulos de dados
Adicione rótulos com os valores exatos acima das barras, permitindo que o leitor entenda os dados sem precisar consultar os eixos — essa também é uma forma importante de eliminar a "ambiguidade visual".
Dica 4: Especifique a "executabilidade"
Exija explicitamente que o código gerado possa ser "executado diretamente, sem qualquer modificação". Isso forçará a IA a incluir todos os comandos import necessários, definições de dados e comandos de salvamento.
Dica 5: Reserve flexibilidade para revisões
Peça para a IA colocar as definições de dados e os parâmetros de estilo separadamente no topo do código, facilitando modificações rápidas posteriormente.
| Dica | Ponto Central | Impacto na Qualidade do Código |
|---|---|---|
| 1 | Fornecer dados explicitamente | Elimina a invenção de dados, garante precisão |
| 2 | Restrições de estilo acadêmico | Atende aos requisitos de formatação de periódicos |
| 3 | Rótulos de valores | Melhora a legibilidade do gráfico |
| 4 | Executabilidade | Código pronto para uso imediato |
| 5 | Separação de parâmetros | Dobra a eficiência em revisões e modificações |
🎯 Sugestão prática: Combine essas 5 dicas no seu modelo de comando padrão. Use o APIYI (apiyi.com) para testar diferentes modelos e iterar até encontrar o estilo de código que melhor se adapta à sua área de pesquisa. A plataforma suporta a alternância entre vários modelos como Gemini, Claude e GPT, facilitando a comparação dos resultados.
Perguntas Frequentes
Q1: O método de geração de código do PaperBanana é mais lento que a geração de imagens?
Pelo contrário, a geração de código costuma ser mais rápida. Gerar um código Matplotlib de 50 a 80 linhas leva apenas de 2 a 5 segundos, enquanto a geração de uma imagem leva de 10 a 30 segundos. Mais importante ainda, o código gerado pode ser executado localmente e modificado repetidamente, sem a necessidade de chamar a API a cada pequena alteração. Ao usar o APIYI (apiyi.com) para gerar código, o custo por chamada é de cerca de $0,01, muito inferior aos $0,05 da geração de imagens.
Q2: Qual é a qualidade do código Matplotlib gerado? Precisa de muitos ajustes?
Nos 240 testes de benchmark ChartMimic do PaperBanana, os códigos Python gerados puderam ser executados diretamente e a saída visual correspondeu à descrição original. Na prática, geralmente basta ajustar parâmetros de estilo, como cores e fontes. Recomendamos usar os modelos Claude ou Gemini através da plataforma APIYI (apiyi.com) para gerar código, pois esses dois modelos se destacam na qualidade de codificação. A ferramenta online Image.apiyi.com também permite visualizar os resultados rapidamente.
Q3: Como começar rapidamente a usar IA para gerar códigos de gráficos estatísticos científicos?
Recomendamos o seguinte caminho para começar:
- Acesse o APIYI (apiyi.com), crie uma conta e obtenha sua chave de API e créditos de teste gratuitos.
- Prepare seus dados experimentais (nomes dos modelos, valores das métricas, etc.).
- Use o modelo de comando deste artigo, substituindo os dados pelos seus dados reais.
- Chame a API para gerar o código Matplotlib e execute-o localmente para ver o resultado.
- Ajuste os parâmetros de estilo conforme as exigências do periódico e exporte em PDF.
Resumo
Os pontos centrais do método de geração de código para gráficos estatísticos científicos do Nano Banana Pro são:
- Código antes de pixels: O PaperBanana utiliza a geração de código Matplotlib para gráficos estatísticos em vez de renderização direta de imagem, eliminando fundamentalmente as alucinações numéricas.
- Cobertura total de 7 tipos de gráficos: Gráficos de barras, linhas, dispersão, mapas de calor (heatmaps), radar, pizza e múltiplos painéis, atendendo a todas as necessidades de visualização de dados em artigos científicos.
- Editável e reproduzível: A saída em código permite modificações livres e reprodução precisa; revisões solicitadas por examinadores exigem apenas o ajuste de parâmetros, em vez de gerar tudo do zero.
- 5 dicas de comandos (prompts): Dados explícitos, restrições acadêmicas, anotações numéricas, executabilidade e separação de parâmetros garantem que o código gerado seja de alta qualidade e utilizável.
Diante das exigências de precisão dos gráficos estatísticos científicos, o conceito de "o código é o gráfico" é o único caminho confiável. Ao usar IA para auxiliar na geração de código Matplotlib, você ganha a eficiência da IA e mantém a precisão do código — o melhor dos dois mundos.
Recomendamos utilizar o APIYI (apiyi.com) para experimentar rapidamente a geração de código para gráficos estatísticos auxiliada por IA. A plataforma oferece créditos gratuitos e diversas opções de modelos. Você também pode usar a ferramenta online Image.apiyi.com para pré-visualizar os resultados.
📚 Referências
⚠️ Nota sobre o formato dos links: Todos os links externos utilizam o formato
nome da fonte: domain.compara facilitar a cópia, mas não são clicáveis, evitando a perda de autoridade de SEO.
-
Página do projeto PaperBanana: Página oficial de lançamento, contendo o artigo e a demonstração.
- Link:
dwzhu-pku.github.io/PaperBanana/ - Descrição: Conheça os princípios fundamentais e os dados de avaliação da geração de código de gráficos estatísticos do PaperBanana.
- Link:
-
Artigo do PaperBanana: Texto completo do preprint no arXiv.
- Link:
arxiv.org/abs/2601.23265 - Descrição: Entenda profundamente a escolha técnica entre geração de código vs. geração de imagem e o benchmark ChartMimic.
- Link:
-
Documentação oficial do Matplotlib: Biblioteca de visualização de dados em Python.
- Link:
matplotlib.org/stable/ - Descrição: Referência da API do Matplotlib para entender e modificar o código dos gráficos gerados por IA.
- Link:
-
Documentação oficial do Nano Banana Pro: Apresentação do modelo do Google DeepMind.
- Link:
deepmind.google/models/gemini-image/pro/ - Descrição: Saiba mais sobre a capacidade de geração de imagens do Nano Banana Pro em cenários de diagramas metodológicos.
- Link:
-
Ferramenta de geração de imagens online do APIYI: Pré-visualização de gráficos sem necessidade de código.
- Link:
Image.apiyi.com - Descrição: Pré-visualize rapidamente o efeito dos gráficos estatísticos científicos gerados por IA.
- Link:
Autor: Equipe APIYI
Troca de conhecimentos técnicos: Sinta-se à vontade para compartilhar seus modelos de comandos (prompts) para gráficos científicos e dicas de Matplotlib na seção de comentários. Para mais informações sobre modelos de IA, visite a comunidade técnica APIYI (apiyi.com).