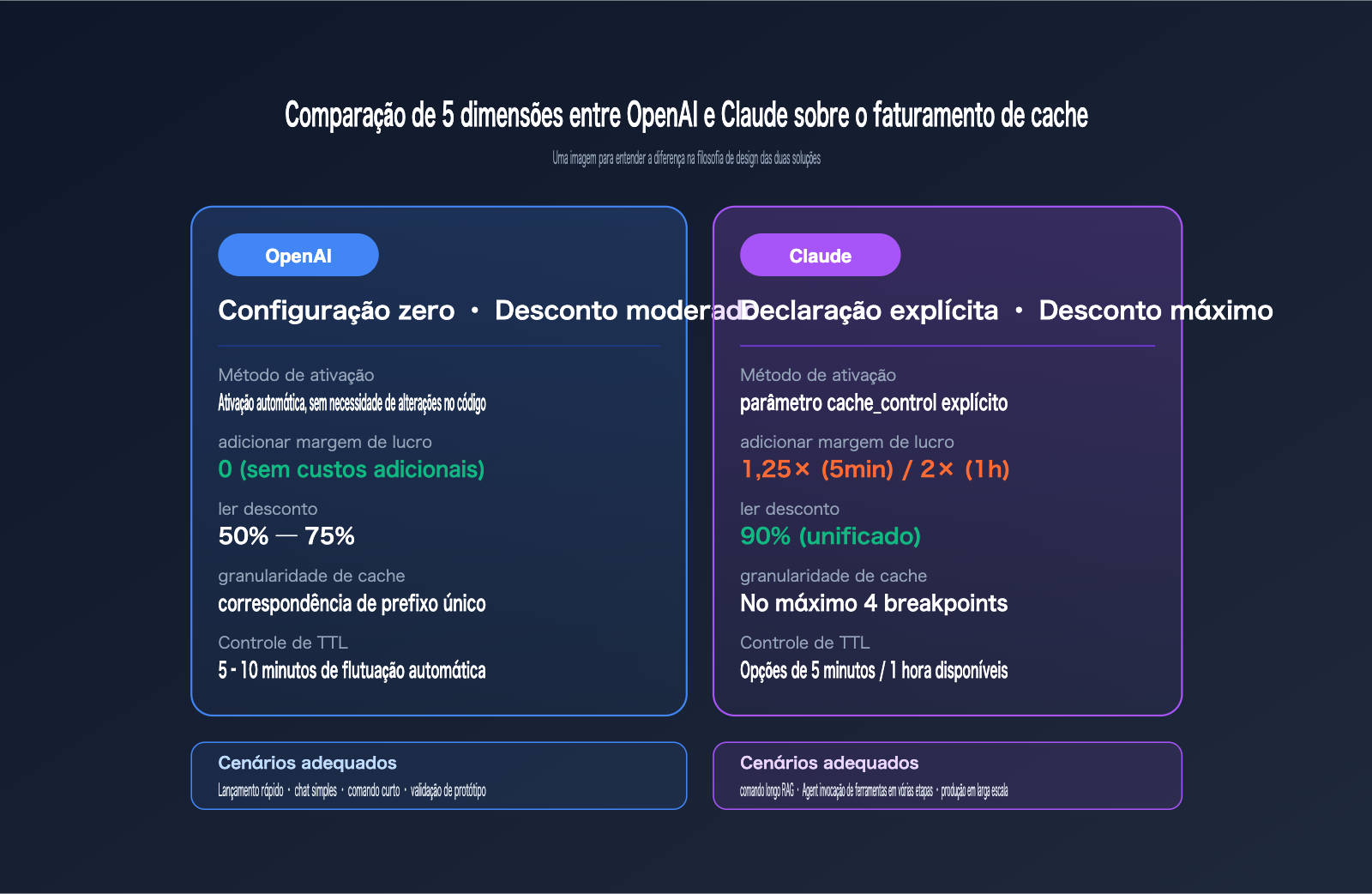
O maior "buraco negro" de custos ao rodar aplicações de Modelos de Linguagem Grande nunca foi a saída de tokens, mas sim o system prompt e os documentos longos que são retransmitidos repetidamente. Tanto a OpenAI quanto a Anthropic apresentaram a solução — o cache de comandos (prompt caching) —, mas a filosofia de cobrança de ambas é, na verdade, completamente diferente: A OpenAI segue a rota de "configuração zero e descontos moderados", enquanto a Claude segue a rota de "declaração explícita e descontos extremos".
Este artigo baseia-se na documentação oficial mais recente de maio de 2026 e em dados de testes reais de desenvolvedores. Comparamos sistematicamente as regras de cobrança de cache da OpenAI e da Claude em seis dimensões: comprimento mínimo do comando, requisitos de estrutura do comando, sobretaxa de escrita, desconto de leitura, controle de TTL e granularidade de cache. Além disso, calculamos quanto dinheiro cada solução pode economizar em um cenário real de 100 mil tokens.
Valor central: Ao terminar este artigo, você saberá imediatamente qual solução de cache usar para o seu negócio, quanto poderá economizar e quais adaptações de engenharia serão necessárias.

5 Diferenças principais na cobrança de cache entre OpenAI e Claude
À primeira vista, as soluções de cache de ambas parecem ser apenas uma história de "descontos na leitura de cache", mas a diferença na filosofia de design por trás de cada regra determina o benefício econômico real em diferentes cenários de negócios. A tabela abaixo resume as 5 principais diferenças que compilamos com base na documentação oficial de preços.
| Dimensão de Diferença | Cache OpenAI | Cache Claude |
|---|---|---|
| Modo de ativação | Totalmente automático, configuração zero | Parâmetro cache_control explícito |
| Comprimento mínimo do comando | 1024 tokens (unificado) | 1024 / 4096 tokens (depende do modelo) |
| Custo extra de escrita | 0 (sem sobretaxa) | 1.25× (5min) ou 2× (1h) do preço base de entrada |
| Desconto de leitura | 50% – 75% de desconto | 90% de desconto (unificado) |
| Granularidade de cache | Correspondência de prefixo único | Até 4 pontos de interrupção (breakpoints) |
| Controle de TTL | Flutuação automática de 5–10 minutos | Duas opções: 5min e 1h |
Ao entender a tabela acima, você compreenderá o resumo em uma frase: A OpenAI permite que você integre de forma "gratuita", a Claude permite que você integre de forma "estratégica". A OpenAI é adequada para cenários de lançamento rápido com orçamento e energia limitados, enquanto a Claude é ideal para cargas de trabalho de produção em larga escala, controláveis e de longo prazo.
🎯 Sugestão de comparação rápida: Se você deseja testar o efeito da cobrança de cache da OpenAI e da Claude no mesmo projeto, recomendamos a integração via APIYI (apiyi.com). A plataforma oferece protocolos compatíveis com OpenAI para ambos os fornecedores, permitindo que você use apenas um código, alterne pelo campo
modele compare diretamente os valores decached_tokensecache_read_input_tokensde ambos.
Detalhes das regras de cobrança de cache da API da OpenAI
O design de cobrança de cache da OpenAI é extremamente simples. A regra fundamental é: desde que o prefixo do seu comando tenha ≥ 1024 tokens e seja exatamente igual à solicitação anterior, o sistema aplica o desconto automaticamente, sem necessidade de alterações no código ou nos cabeçalhos.
Requisitos de estrutura e comprimento do comando para cache da OpenAI
As condições para o acerto de cache da OpenAI podem ser divididas em duas restrições rígidas: o comprimento do comando deve atingir 1024 tokens e o cache corresponde apenas à parte do prefixo da solicitação, portanto, qualquer conteúdo dinâmico deve ser colocado no final do comando. As regras específicas são resumidas abaixo:
- Comprimento mínimo: O comprimento total do comando deve ser ≥ 1024 tokens; caso contrário, não entra no cache e não gera erro.
- Correspondência de prefixo: O sistema compara token por token a partir do início do comando. Se houver qualquer alteração em algum ponto, tudo o que vier depois será cobrado sem cache.
- Incrementos de 128 tokens: O acerto de cache ocorre em incrementos de 128 tokens. Após os primeiros 1024, cada 128 tokens idênticos adicionais continuam a gerar acertos.
- Identidade total: Inclui system message, definições de ferramentas, mensagens históricas e imagens. Qualquer diferença de caractere invalidará o cache.
- Manutenção automática: Não é necessário cache ID nem invalidação manual. O cache é limpo automaticamente após 5 a 10 minutos de inatividade, podendo ser estendido para 1 hora em períodos fora de pico.
Isso significa que, se o seu sistema tiver um prefixo dinâmico com carimbo de data/hora ou ID de usuário logo após o system prompt, todo o cache será invalidado. Mover o conteúdo dinâmico para o final e manter o conteúdo estático no início é a chave para o funcionamento do cache da OpenAI.
Faixas de desconto reais da cobrança de cache da OpenAI
O desconto de leitura da OpenAI não é um valor único, mas varia conforme o modelo. Alguns modelos novos, como o GPT-5.5, oferecem um desconto mais agressivo de 75%. A tabela abaixo mostra os preços de cache dos principais modelos da OpenAI em maio de 2026.
| Modelo | Entrada Padrão ($/M) | Leitura de Cache ($/M) | Taxa de Desconto |
|---|---|---|---|
| GPT-5.5 | 5.00 | 1.25 | 75% |
| GPT-5.5 mini | 0.25 | 0.0625 | 75% |
| GPT-4o | 2.50 | 1.25 | 50% |
| GPT-4o mini | 0.15 | 0.075 | 50% |
| o1-preview | 15.00 | 7.50 | 50% |
A OpenAI retorna o número real de tokens que atingiram o cache no campo usage.prompt_tokens_details.cached_tokens da resposta. Você pode usar esse campo diretamente para calcular a economia. Automação total + desconto moderado é o foco central da cobrança de cache da OpenAI.
Detalhes das regras de cobrança de cache da API da Claude
A cobrança de cache da Claude tem uma filosofia mais próxima de um "compromisso explícito": você deve informar explicitamente ao modelo "quero armazenar este trecho em cache", e o modelo lhe oferece um desconto extremo de 90%, mas a escrita tem um custo adicional.
Requisitos mínimos de tokens para cache da Claude (varia conforme o modelo)
Enquanto a OpenAI adota um padrão fixo de 1024 tokens, a Claude diferencia por categoria de modelo, distanciando-se da OpenAI. Compilamos os limites mínimos de tokens de cache para todos os modelos atuais da Claude:
| Modelo | Tokens mínimos para cache | Entrada Padrão ($/M) | Escrita 5min ($/M) | Leitura de Cache ($/M) |
|---|---|---|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 | 5.00 | 6.25 | 0.50 |
| Claude Sonnet 4.6 / 4.5 | 1024 | 3.00 | 3.75 | 0.30 |
| Claude Opus 4.1 | 1024 | 15.00 | 18.75 | 1.50 |
| Claude Haiku 4.5 | 4096 | 1.00 | 1.25 | 0.10 |
Isso significa que, se você estiver usando a geração mais recente do Opus ou Haiku, um system prompt de 3000 tokens não será armazenado em cache, sendo necessário adicionar conteúdo (como definições completas de ferramentas ou exemplos de diálogo) para atingir os 4096 tokens. Na série Sonnet, esse passo não é necessário, pois 1024 tokens já são suficientes.
Regras de TTL e retorno de investimento da cobrança de cache da Claude
Outra característica fundamental da Claude é a opção de TTL (Time-to-Live) de duas faixas: padrão de 5 minutos ou upgrade opcional para 1 hora, com diferenças de preço significativas. Abaixo, apresentamos uma análise de retorno para auxiliar na tomada de decisão.
- TTL de 5 minutos: Adicional de 25% na escrita. Basta uma única leitura subsequente para cobrir o custo, ideal para perguntas e respostas de alta frequência e chatbots.
- TTL de 1 hora: Adicional de 100% na escrita (preço dobrado). Requer ≥ 2 leituras para cobrir o custo, ideal para processamento em lote (batch), tarefas de agentes em várias etapas e relatórios agendados.
- TTL Misto: TTLs longos devem ser colocados antes dos curtos, permitindo desfrutar de estratégias de cache com diferentes prazos de validade simultaneamente.
Um ponto importante é que o TTL de 5 minutos é renovado automaticamente após cada leitura bem-sucedida. Portanto, um cache "ativo" pode ser estendido indefinidamente; desde que a frequência de solicitações permaneça dentro do intervalo de 5 minutos, você paga a taxa de escrita apenas uma vez.
Controle de níveis e pontos de interrupção (breakpoint) da Claude
O maior trunfo da Claude são os até 4 pontos de interrupção (cache breakpoints), que permitem dividir o comando em vários níveis gerenciados de forma independente, o que é crucial para aplicações complexas. Os níveis de cache seguem rigorosamente a ordem de cima para baixo: tools → system → messages. A camada de ferramentas contém definições e esquemas de funções, a camada de sistema contém o comando do sistema e definições de papel, e a camada de mensagens carrega o histórico de conversas e documentos de contexto.
O mais crítico é que a invalidação de uma camada superior invalida todas as camadas inferiores. Se você alterar uma linha na definição de uma ferramenta, o cache do sistema e das mensagens será invalidado simultaneamente. Por outro lado, alterar apenas a última frase do usuário mantém o cache de todos os níveis anteriores válido. Do ponto de vista de engenharia, você deve mover o conteúdo com menor frequência de alteração para o topo; essa regra determina diretamente a taxa de acerto do cache.
Além disso, observe que cada breakpoint possui uma janela de retrocesso de cerca de 20 blocos: o sistema buscará 20 blocos de conteúdo antes da posição do breakpoint e, se encontrar um comando histórico idêntico dentro dessa janela, o cache será acionado. Após 20 rodadas de conversa, recomenda-se adicionar outro breakpoint no meio para evitar que o cache histórico fique "invisível".
💡 Sugestão de arquitetura: Para aplicações complexas que utilizam vários modelos simultaneamente, recomendamos realizar testes práticos através da plataforma APIYI (apiyi.com) para tomar a decisão que melhor se adapta às suas necessidades. A plataforma suporta chamadas de interface unificadas para as séries OpenAI e Claude, permitindo que você compare a fatura real da mesma carga de trabalho sob os mecanismos de cache de ambos os provedores sem precisar reescrever o código.
Cálculo do custo real de faturamento de cache da OpenAI e Claude
Análise teórica é uma coisa, mas a diferença real no bolso depende de simulações de cenários. Vamos construir um cenário de negócio bastante comum:
- System prompt estático: 100 mil tokens (documentação técnica + exemplos de few-shot)
- Cada requisição do usuário: 100 tokens de entrada (pergunta real) + 1000 tokens de saída
- Frequência de chamadas: 1000 vezes por dia, distribuídas uniformemente durante o horário comercial
- Modelos comparados: GPT-5.5 vs Claude Sonnet 4.6 (ambos são os "cavalos de batalha" de cada empresa)

Tabela comparativa de custo diário de cache entre OpenAI e Claude
A tabela abaixo detalha os custos essenciais do cenário acima. Observe que todos os números referem-se apenas aos custos de tokens de entrada, excluindo os tokens de saída (os preços de saída de ambas as empresas são semelhantes e podem ser considerados separadamente).
| Item | GPT-5.5 sem cache | Cache OpenAI ativado | Sonnet 4.6 sem cache | Cache Claude 5min ativado |
|---|---|---|---|---|
| Custo de escrita inicial | — | $0,50 | — | $0,375 |
| Leitura subsequente (999 vezes) | $499,50 | $124,875 | $299,70 | $29,97 |
| Custo diário de entrada | $500,00 | $125,38 | $300,00 | $30,35 |
| Proporção de economia | 0% | 75% | 0% | 90% |
| Custo mensal (30 dias) | $15.000 | $3.761 | $9.000 | $910 |
A conclusão da comparação é muito clara: Com a mesma carga de trabalho, o custo mensal do Claude Sonnet 4.6 com cache ativado é de apenas cerca de 24% do custo mensal do GPT-5.5 com cache ativado. Se o seu negócio é o típico "system prompt longo + perguntas e respostas curtas", a vantagem de custo do Claude aumentará linearmente com a escala de chamadas.
No entanto, existem duas premissas implícitas a serem observadas nesta conclusão:
- O cache deve realmente ser atingido: Se o system prompt mudar com frequência, a economia de ambas as soluções diminuirá drasticamente.
- Não considera diferenças na capacidade do modelo: A qualidade de saída do GPT-5.5 e do Sonnet 4.6 pode não ser equivalente em diferentes tarefas, sendo necessário julgar de forma abrangente com base nos indicadores de negócio.
💰 Dica de otimização de custos: Para projetos sensíveis ao orçamento, considere utilizar a API através da plataforma APIYI (apiyi.com). A plataforma oferece formas de faturamento flexíveis e preços mais vantajosos, sendo ideal para pequenas equipes e desenvolvedores individuais validarem rapidamente o ROI real de soluções de cache, sem precisar gerenciar dois sistemas de faturamento por conta própria.
Recomendações de cenários de cobrança para cache da OpenAI e Claude
O preço é apenas uma das variáveis. Se vale a pena investir em engenharia para implementar cache, se é possível garantir uma taxa de acerto estável e se a solução é compatível com uma arquitetura de múltiplos modelos são pontos que precisam ser considerados. Abaixo, apresento recomendações claras baseadas em cenários de negócio.
Cenários típicos para escolher o cache da OpenAI
O maior atrativo do cache da OpenAI é a "integração transparente", sendo ideal para equipes que não possuem recursos de engenharia dedicados para otimização de comandos (prompts) ou que estão em estágios iniciais onde a complexidade do negócio ainda não está estável.
- Chatbots simples e respostas de FAQ para suporte ao cliente, onde o system prompt não é muito longo, mas o volume de chamadas é alto.
- Estágios de validação rápida de protótipos, priorizando a redução de atrito no desenvolvimento para ver os resultados antes de discutir otimizações.
- Projetos que já utilizam intensamente o ecossistema da OpenAI (como function calling, structured outputs, etc.) e não desejam introduzir um novo SDK.
- Ambientes de colaboração entre múltiplas equipes, onde não é possível garantir que todos utilizem corretamente o parâmetro
cache_control.
Cenários típicos para escolher o cache da Claude
A vantagem do cache da Claude é amplificada em três cenários: comandos longos, leitura de alta frequência e carga de produção controlável.
- System prompt longo + RAG de documentos extensos: Por exemplo, inserir todo o manual do produto no system prompt; o desconto de 90% é extremamente atraente.
- Chamadas de ferramentas em múltiplas etapas por agentes: A definição da ferramenta + o system prompt podem ser armazenados em cache de forma independente, ideal para raciocínios de longa cadeia.
- Tarefas em lote (Batch) / offline: TTL de 1 hora combinado com leituras de baixa frequência (algumas vezes por minuto) permite aproveitar ao máximo o custo adicional de 2x na escrita.
- Aplicações com prompts em múltiplas camadas: Colocar modelos, bases de conhecimento e contexto do usuário em 4 breakpoints diferentes, permitindo um controle refinado sobre a expiração.
Tabela comparativa de seleção de cache: OpenAI vs Claude
A tabela abaixo compara as dimensões de decisão cruciais de ambas as soluções, facilitando a comparação direta com a situação do seu projeto.
| Dimensão de decisão | Cache OpenAI | Cache Claude | Recomendação |
|---|---|---|---|
| Custo de engenharia | Quase zero | Requer adaptação com cache_control |
OpenAI |
| Nível de economia | 50%–75% | 90% | Claude |
| Compatibilidade com prompts longos | Média | Excelente | Claude |
| Adaptação a prompts curtos | 1024 é suficiente | Opus/Haiku requer 4096 | OpenAI |
| Uso de Agente / Ferramentas | Definição da ferramenta ocupa o prompt | Ferramentas com cache individual | Claude |
| Maturidade de normas de prompt | Difícil de errar | Fácil de cometer erros | OpenAI |
| Controle de TTL múltiplo | Não suportado | 5min / 1h selecionáveis | Claude |
Prática de código para cobrança de cache na OpenAI e Claude
Depois de tanta teoria, o que você realmente precisa para colocar a mão na massa são algumas dezenas de linhas de código que funcionem. Abaixo, apresento a forma mínima de ativação para ambos, prontas para copiar e colar no seu projeto.
Exemplo de código de cobrança de cache da OpenAI
A OpenAI não exige nenhum parâmetro relacionado a cache; o segredo é colocar o conteúdo estático no início e o conteúdo dinâmico no final, verificando o acerto (hit) através de usage.prompt_tokens_details.cached_tokens.
from openai import OpenAI
client = OpenAI(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com/v1"
)
LONG_SYSTEM = "(Seu system prompt longo de 100 mil tokens, deve ser colocado no início e ser idêntico a cada chamada)"
response = client.chat.completions.create(
model="gpt-5.5",
messages=[
{"role": "system", "content": LONG_SYSTEM},
{"role": "user", "content": "Como está o tempo hoje?"} # Conteúdo dinâmico no final
],
)
# Verificar acerto de cache
print(response.usage.prompt_tokens_details.cached_tokens)
Exemplo de código de cobrança de cache do Claude
O Claude exige um cache_control explícito, que deve ser marcado nos blocos de conteúdo do system ou das messages. Abaixo está o uso típico de "system + 1 breakpoint".
import anthropic
client = anthropic.Anthropic(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[
{
"type": "text",
"text": "(System longo de 4096+ tokens, deve ser colocado no início)",
"cache_control": {"type": "ephemeral"} # 5 minutos por padrão, pode alterar para ttl="1h"
}
],
messages=[{"role": "user", "content": "Como está o tempo hoje?"}],
)
# Verificar acerto de cache
print(response.usage.cache_read_input_tokens,
response.usage.cache_creation_input_tokens)
Ver código completo com cache multinível de 4 breakpoints
import anthropic
client = anthropic.Anthropic(
api_key="SUA_CHAVE_API",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
tools=[
{
"name": "search_db",
"description": "...",
"input_schema": {...},
"cache_control": {"type": "ephemeral", "ttl": "1h"} # TTL mais longo no topo
}
],
system=[
{
"type": "text",
"text": "Resumo da base de conhecimento da empresa (estático)",
"cache_control": {"type": "ephemeral", "ttl": "1h"}
},
{
"type": "text",
"text": "Instruções dinâmicas do dia (atualizadas diariamente)",
"cache_control": {"type": "ephemeral"} # 5 minutos por padrão
}
],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Dados principais do relatório financeiro da semana passada..."},
{
"type": "text",
"text": "Por favor, faça um resumo para mim",
"cache_control": {"type": "ephemeral"}
}
]
}
]
)
A diferença central entre esses dois códigos é que a OpenAI não percebe a existência do cache, enquanto o Claude força o desenvolvedor a pensar ativamente nos limites do cache. Em uma camada de acesso unificada, basta alternar o campo model para que o mesmo código de negócio alterne entre os dois modelos sem esforço.
Sugestões de decisão: OpenAI vs Claude
Se eu pudesse dar apenas um conselho: Quanto mais complexo o negócio, mais longo o prompt e mais frequentes as chamadas, mais o desconto de 90% do Claude se destaca; quanto mais simples o negócio, mais curto o prompt e mais urgente o lançamento, mais a configuração zero da OpenAI vale a pena.
Ao implementar, sugiro seguir estes três passos:
- Passo 1: Meça a carga real, contabilize o número médio de tokens do seu system prompt e o volume diário de chamadas; esses dois números determinam quanto o cache pode economizar.
- Passo 2: Escolha o modelo principal, priorizando a solução com descontos de cache mais profundos, desde que a capacidade atenda às necessidades do negócio.
- Passo 3: Faça engenharia de prompt, colocando todo o "conteúdo que se repete" no início e o "conteúdo que muda" no final ou em um breakpoint separado.
🚀 Dica para começar rápido: Recomendo usar a plataforma APIYI (apiyi.com) para criar protótipos rapidamente, unificando a chamada de interface entre OpenAI e Claude sem precisar integrar dois SDKs diferentes. Com o mesmo código, basta alterar o campo
modelpara alternar, e os campos de cobrança de cache também são retornados via protocolo compatível com OpenAI, facilitando a avaliação comparativa.
Perguntas Frequentes sobre a Cobrança de Cache da OpenAI e Claude
Q1: Por que o cache da OpenAI “não funcionou” para mim?
Existem três razões principais: primeiro, o comprimento total do comando é inferior a 1024 tokens; segundo, conteúdo dinâmico (como carimbos de data/hora ou IDs de usuário) foi colocado no início do comando, tornando o prefixo inconsistente a cada vez; terceiro, o intervalo entre duas solicitações consecutivas excedeu 5 a 10 minutos, fazendo com que o cache fosse limpo automaticamente. Sugiro enviar o mesmo comando duas vezes seguidas e observar se cached_tokens é diferente de zero para descartar rapidamente problemas de ambiente.
Q2: É possível contornar o limite mínimo de 4096 tokens do Claude?
Não. Para os modelos Opus 4.7/4.6/4.5 e Haiku 4.5, é obrigatório atingir 4096 tokens para serem incluídos no cache. Se o seu system prompt tem apenas cerca de 2000 tokens, recomendo dois caminhos: primeiro, mudar para o Sonnet 4.6 (que começa a cachear a partir de 1024 tokens) ou adicionar definições de ferramentas, exemplos de conversas e guias de estilo ao seu system prompt para atingir o limite de 4096+.
Q3: O acréscimo de 25% na escrita em cache vale a pena?
Na grande maioria dos casos, sim. A escrita em cache de 5 minutos do Claude custa apenas 25% a mais que a entrada básica, enquanto cada leitura é 90% mais barata. Isso significa que, se o mesmo conteúdo for lido apenas uma vez, o custo extra da escrita em cache já se pagou. O cache de 1 hora precisa de 2 leituras para se pagar. Se você teme que a taxa de acerto não seja suficiente, extraia um relatório de cache_read_input_tokens de 24 horas no seu ambiente de produção; os dados mostrarão a economia real.
Q4: Posso habilitar o cache da OpenAI e do Claude ao mesmo tempo?
Sim, e é altamente recomendável. Os mecanismos de cache de ambos não interferem entre si. Você pode selecionar modelos diferentes para módulos de negócios distintos no mesmo projeto: por exemplo, usar a OpenAI para reconhecimento de intenção (comandos curtos, alta frequência) e o Claude para resumo de documentos longos (comandos longos, raciocínio profundo). Ao usar uma camada de acesso unificada para compartilhar o sistema de modelos de comando, você evita a manutenção duplicada de duas estratégias de cache.
Q5: Como desenvolvedores brasileiros podem testar rapidamente o efeito do cache da OpenAI e do Claude?
O caminho mais direto é utilizar uma plataforma de acesso unificada acessível localmente. Recomendamos o APIYI (apiyi.com), que oferece interfaces compatíveis com o protocolo da OpenAI tanto para a OpenAI quanto para o Claude, além de repassar os campos de cobrança de cache de ambos (cached_tokens e cache_read_input_tokens). Você pode executar ambos os modelos em um único script e comparar diretamente a economia real, sem precisar solicitar e manter contas separadas em cada provedor.
Resumo: Como escolher a cobrança de cache entre OpenAI e Claude
Voltando ao conflito central mencionado no início: Economizar dinheiro vs. Economizar esforço é a divisão fundamental entre OpenAI e Claude na cobrança de cache. A OpenAI cobre 80% dos cenários comuns com configuração zero e descontos moderados, enquanto o Claude conquista cargas de trabalho de produção em larga escala, com comandos longos e chamadas de alta frequência, através de declarações explícitas e descontos extremos.
Princípios de decisão em três pontos:
- Comando < 4096 tokens e negócio simples → Escolha o cache da OpenAI, aproveite descontos de 50–75%.
- Comando > 4096 tokens e múltiplas leituras repetidas por minuto → Escolha o cache de 5min do Claude, aproveite 90% de desconto.
- Agentes / Batch / Chamadas que atravessam horas → Escolha o cache de 1h do Claude; o custo se paga com apenas 2 leituras.
A recomendação técnica é: primeiro reestruture seu comando, depois discuta os descontos de cache. Coloque o conteúdo estático no início e o dinâmico no final, realize testes de carga paralelos com ambas as soluções e baseie sua escolha final na fatura real.
Recomendamos verificar os resultados rapidamente através do APIYI (apiyi.com), garantindo a solução de cache mais adequada ao seu negócio sem ficar preso a um único fornecedor.
Autor: Equipe Técnica APIYI — Focada em práticas de engenharia de API para Modelos de Linguagem Grande. Se você deseja saber mais sobre os dados de custo e desempenho dos modelos das séries OpenAI, Claude e Gemini em cenários de negócios reais, visite APIYI (apiyi.com) para obter os relatórios de avaliação mais recentes e créditos de teste gratuitos.