在大模型 API 开发中,流式输出(Stream)和非流式输出(Non-stream)是两种截然不同的数据交互模式,它们在用户体验、资源消耗和应用场景上存在显著差异。本文将全面对比这两种输出模式,帮助开发者根据实际需求做出最佳选择。
虽然在代码里,他就是 stream 的一个参数值 true 还是 false ,但应用场景很不同,请看这篇详细解读。
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持 OpenAI、Claude、Gemini 等全系列模型的流式与非流式调用,让 AI 开发更简单
注册即送 1.1 美金额度起。立即免费注册 www.apiyi.com
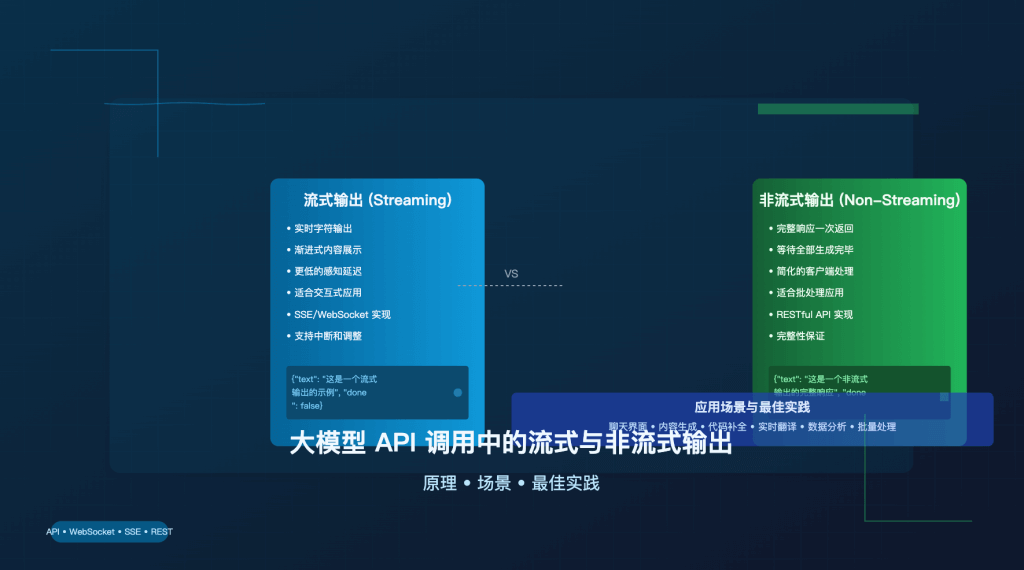
流式输出与非流式输出基本原理
流式输出:逐步生成的实时交互
流式输出是一种增量式的数据传输方式,它允许大模型在生成内容的同时,将已生成的部分立即发送给客户端,而不必等待整个响应完成。这种方式的核心特点是:
- 实时性:模型生成一小段内容就立即传输,用户几乎可以实时看到生成过程
- 增量传输:通过 SSE(Server-Sent Events)或 WebSocket 协议实现服务器到客户端的持续数据流
- 低感知延迟:用户通常在 100ms 内就能看到首批内容,大幅降低等待感
# OpenAI 流式输出示例
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "讲一个关于人工智能的故事"}],
stream=true # 启用流式输出,在代码里就这么一个参数而已
)
for chunk in response:
if chunk.choices.delta.content:
print(chunk.choices.delta.content, end="", flush=True)
非流式输出:完整生成的一次性返回
非流式输出采用传统的请求-响应模式,模型会等待完整内容生成后再一次性返回给客户端:
- 完整性:返回的是经过完全处理和验证的完整响应
- 单次传输:采用标准 HTTP 请求-响应模式,一次性传输所有数据
- 等待时间:用户需要等待整个生成过程完成(可能需要数秒甚至更长)
# OpenAI 非流式输出示例
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "讲一个关于人工智能的故事"}],
stream=false # 禁用流式输出(默认值)
)
print(response.choices.message.content)
流式输出与非流式输出技术实现差异
| 维度 | 流式输出 | 非流式输出 |
|---|---|---|
| 传输协议 | SSE/WebSocket(长连接) | HTTP/1.1(短连接) |
| 连接状态 | 保持长连接直到生成完成 | 请求发出后等待,完成后断开 |
| 数据格式 | 分块传输,每块包含增量内容 | JSON 格式的完整响应体 |
| 服务器资源 | 维持连接状态,内存占用较高 | 生成完毕即释放资源,更节省内存 |
| 网络要求 | 对网络稳定性要求高 | 对网络稳定性要求相对较低 |
| 错误处理 | 中间状态可能导致部分内容丢失 | 全量结果校验,容错性更强 |
Claude API 流式与非流式实现对比
// Claude API 流式输出示例
const response = await fetch('https://vip.apiyi.com/v1/messages', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${API_KEY}`,
'anthropic-version': '2023-06-01'
},
body: JSON.stringify({
model: 'claude-3-5-sonnet-20241022',
messages: [{ role: 'user', content: '解释量子计算的基本原理' }],
stream: true
})
});
const reader = response.body.getReader();
while (true) {
const { done, value } = await reader.read();
if (done) break;
// 处理流式数据块
console.log(new TextDecoder().decode(value));
}
// Claude API 非流式输出示例
const response = await fetch('https://vip.apiyi.com/v1/messages', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${API_KEY}`,
'anthropic-version': '2023-06-01'
},
body: JSON.stringify({
model: 'claude-3-5-sonnet-20241022',
messages: [{ role: 'user', content: '解释量子计算的基本原理' }],
stream: false
})
});
const result = await response.json();
console.log(result.content.text);
流式输出与非流式输出应用场景
流式输出的理想应用场景
- 实时对话系统
- 聊天机器人和虚拟助手
- 客服系统和用户支持平台
- 实时问答和教育辅导应用
- 渐进式内容生成
- 代码补全和编程辅助工具(如 GitHub Copilot)
- 实时文档协作和编辑系统
- 创意写作和内容创作平台
- 用户体验敏感场景
- 需要快速响应的移动应用
- 高交互频率的 Web 应用
- 需要模拟人类打字节奏的界面
- 长文本生成
- 文章和报告生成工具
- 故事和剧本创作应用
- 大量内容总结和提炼系统
非流式输出的理想应用场景
- 批量处理任务
- 大规模文档分析
- 离线内容生成
- 数据批处理和报表生成
- 高精度要求场景
- 医疗诊断报告生成
- 法律文档和合同生成
- 金融分析和风险评估
- 资源受限环境
- 移动设备上的轻量级应用
- 网络带宽受限的场景
- 服务器资源需要高效利用的情况
- 需要完整性验证的场景
- 需要进行内容审核的应用
- 格式严格的文档生成
- 需要确保逻辑一致性的复杂推理
流式输出与非流式输出性能对比
| 性能指标 | 流式输出 | 非流式输出 |
|---|---|---|
| 首字节延迟 | 极低(通常 100ms 内) | 较高(需等待全部生成) |
| 总完成时间 | 与非流式相近或略长 | 与流式相近或略短 |
| 服务器负载 | 连接维护成本高 | 单次处理负载高但短暂 |
| 网络流量 | 略高(协议开销) | 略低(单次传输) |
| 客户端复杂度 | 较高(需处理流式数据) | 较低(简单的请求-响应) |
| 容错能力 | 较弱(中断风险高) | 较强(完整性保证) |
流式输出与非流式输出工程实践建议
何时选择流式输出
- 用户体验是首要考虑因素
- 当用户需要看到即时反馈时
- 当生成内容较长,等待时间可能超过 2 秒时
- 当需要模拟人类交流的自然节奏时
- 技术条件允许
- 前端框架支持流式数据处理
- 网络环境稳定可靠
- 有足够的服务器资源维护长连接
- 应用特性匹配
- 交互式应用和对话系统
- 需要渐进式展示内容的场景
- 用户期望看到思考过程的应用
何时选择非流式输出
- 完整性和准确性至关重要
- 需要对整体内容进行验证的场景
- 格式要求严格的输出
- 需要确保逻辑一致性的复杂推理
- 资源优化是关键考量
- 服务器连接资源有限
- 需要处理大量并发请求
- 移动应用等资源受限环境
- 简化开发和维护
- 前端实现简单直接
- 减少错误处理的复杂性
- 便于与现有系统集成
流式输出最佳实践
- 实现可靠的重连机制
- 检测连接中断并自动重试
- 保存已接收的部分内容
- 实现断点续传功能
- 优化前端渲染
- 使用虚拟 DOM 或高效渲染库
- 实现打字机效果控制显示节奏
- 考虑使用缓冲区平滑显示
- 监控和性能优化
- 跟踪连接状态和传输速率
- 优化服务器连接池配置
- 实现超时和资源限制保护
非流式输出最佳实践
- 提供良好的等待体验
- 实现加载指示器或进度条
- 考虑分阶段请求减少等待时间
- 提供取消请求的选项
- 优化响应处理
- 实现响应缓存机制
- 优化大型 JSON 响应的解析
- 考虑响应压缩减少传输时间
- 错误处理和重试
- 实现完善的错误处理机制
- 针对不同错误类型设计重试策略
- 提供用户友好的错误提示
流式输出与非流式输出代码实现示例
Python 中的流式与非流式实现(OpenAI API)
# 流式输出实现
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def stream_response():
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "写一篇关于人工智能的短文"}],
stream=True,
max_tokens=1000
)
# 处理流式响应
for chunk in response:
if chunk.choices.delta.content:
yield chunk.choices.delta.content
# 使用生成器逐步获取内容
for text_chunk in stream_response():
print(text_chunk, end="", flush=True)
# 非流式输出实现
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def non_stream_response():
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "写一篇关于人工智能的短文"}],
stream=False,
max_tokens=1000
)
return response.choices.message.content
# 一次性获取完整内容
full_text = non_stream_response()
print(full_text)
Node.js 中的流式与非流式实现(Claude API)
// 流式输出实现
const { Anthropic } = require('@anthropic-ai/sdk');
const anthropic = new Anthropic({
apiKey: 'YOUR_API_KEY',
baseURL: 'https://vip.apiyi.com/v1'
});
async function streamResponse() {
const stream = await anthropic.messages.create({
model: 'claude-3-5-sonnet-20241022',
messages: [{ role: 'user', content: '写一篇关于人工智能的短文' }],
max_tokens: 1000,
stream: true
});
for await (const chunk of stream) {
if (chunk.delta.text) {
process.stdout.write(chunk.delta.text);
}
}
}
streamResponse();
// 非流式输出实现
const { Anthropic } = require('@anthropic-ai/sdk');
const anthropic = new Anthropic({
apiKey: 'YOUR_API_KEY',
baseURL: 'https://vip.apiyi.com/v1'
});
async function nonStreamResponse() {
const response = await anthropic.messages.create({
model: 'claude-3-5-sonnet-20241022',
messages: [{ role: 'user', content: '写一篇关于人工智能的短文' }],
max_tokens: 1000,
stream: false
});
return response.content.text;
}
nonStreamResponse().then(text => console.log(text));
流式输出的原始格式与解析
在使用命令行工具如 curl 直接调用流式 API 时,你可能会看到一系列以 data: 开头的 JSON 对象,这是流式输出的原始格式。以下是一个使用 curl 调用 deepseek-r1 模型的示例:
curl https://vip.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "deepseek-r1",
"stream": true,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "如何在链上理财,我的数字货币里有 5000 usdt"}
]
}'
执行上述命令后,你会看到类似以下的输出:
data: {"id":"b87317c3b9394b9e84d6a57b75fba812","object":"chat.completion.chunk","created":1740646874,"model":"deepseek-r1","choices":[{"index":0,"delta":{"role":null,"content":" -","tool_calls":null,"reasoning_content":null},"logprobs":null,"finish_reason":null,"matched_stop":null}],"usage":null}
data: {"id":"b87317c3b9394b9e84d6a57b75fba812","object":"chat.completion.chunk","created":1740646874,"model":"deepseek-r1","choices":[{"index":0,"delta":{"role":null,"content":" **","tool_calls":null,"reasoning_content":null},"logprobs":null,"finish_reason":null,"matched_stop":null}],"usage":null}
data: {"id":"b87317c3b9394b9e84d6a57b75fba812","object":"chat.completion.chunk","created":1740646874,"model":"deepseek-r1","choices":[{"index":0,"delta":{"role":null,"content":"风险","tool_calls":null,"reasoning_content":null},"logprobs":null,"finish_reason":null,"matched_stop":null}],"usage":null}
data: {"id":"b87317c3b9394b9e84d6a57b75fba812","object":"chat.completion.chunk","created":1740646874,"model":"deepseek-r1","choices":[{"index":0,"delta":{"role":null,"content":"**","tool_calls":null,"reasoning_content":null},"logprobs":null,"finish_reason":null,"matched_stop":null}],"usage":null}
这种输出格式是什么?
这是完全正常的流式输出格式,采用的是 Server-Sent Events (SSE) 协议的标准格式。每一行 data: 后面跟着的是一个 JSON 对象,代表模型生成的一小块内容。让我们解析一下这个格式:
data:前缀:这是 SSE 协议的标准前缀,表示这是一个数据事件- JSON对象:每个数据事件包含一个完整的 JSON 对象,其中:
id:这个流式响应的唯一标识符object:表示这是一个聊天完成的数据块(chunk)created:创建时间戳model:使用的模型名称choices:包含实际生成的内容delta.content:这是最关键的部分,包含这个数据块的实际文本内容
为什么看起来是分散的文本片段?
在上面的例子中,我们可以看到模型正在一小块一小块地生成内容:
- 第一个块:
" -" - 第二个块:
" **" - 第三个块:
"风险" - 第四个块:
"**"
这些内容需要连接起来才能形成完整的文本。在这个例子中,模型正在生成 Markdown 格式的内容,最终会形成 - **风险** 这样的加粗列表项。
如何正确处理这种输出?
在实际应用中,你通常不会直接查看原始的 SSE 数据流,而是使用编程语言的库来处理它:
# Python 处理流式输出的正确方式
import json
import requests
response = requests.post(
"https://vip.apiyi.com/v1/chat/completions",
headers={
"Content-Type": "application/json",
"Authorization": f"Bearer YOUR_API_KEY"
},
json={
"model": "deepseek-r1",
"stream": True,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "如何在链上理财,我的数字货币里有 5000 usdt"}
]
},
stream=True # 启用 requests 的流式处理
)
# 用于存储完整响应的变量
full_response = ""
# 处理流式响应
for line in response.iter_lines():
if line:
# 移除 "data: " 前缀并解析 JSON
line = line.decode('utf-8')
if line.startswith("data: "):
json_str = line[6:] # 跳过 "data: " 前缀
if json_str != "[DONE]": # 流结束标记
try:
chunk = json.loads(json_str)
content = chunk['choices']['delta'].get('content', '')
if content:
full_response += content
print(content, end="", flush=True) # 实时打印内容
except json.JSONDecodeError:
print(f"无法解析 JSON: {json_str}")
print("\n\n完整响应:", full_response)
流式输出的调试技巧
如果你需要调试流式输出,可以使用以下方法:
- 使用
jq工具格式化输出:curl ... | grep -v "^$" | sed 's/^data: //g' | jq . - 保存原始响应进行分析:
curl ... > response.txt - 使用专门的 SSE 客户端库:大多数编程语言都有处理 SSE 的库,如 JavaScript 的
EventSource、Python 的sseclient等。 - 切换到非流式模式:如果只是想查看完整响应,可以将
"stream": false设置为非流式模式。
流式输出的原始格式可能看起来很复杂,但这正是它能够实现实时、增量传输的技术基础。在实际应用中,这些细节通常由客户端库处理,开发者只需关注最终的文本内容。
流式输出与非流式输出常见问题
流式输出常见问题
问:流式输出会增加 API 调用成本吗?
答:从 token 计费角度看,流式输出与非流式输出的成本相同,都是基于生成的 token 数量计费。但从基础设施角度,流式输出可能会增加服务器连接维护成本,特别是在高并发场景下。
问:流式输出是否会影响模型生成的质量?
答:不会。流式输出只是改变了内容传输的方式,不会影响模型生成内容的质量或完整性。模型的思考过程和生成结果与非流式模式相同。
问:如何处理流式输出中的连接中断问题?
答:应实现重连机制,包括:保存已接收内容的状态、设置合理的超时参数、实现指数退避重试策略,以及在客户端提供友好的错误提示和恢复选项。
非流式输出常见问题
问:如何优化非流式输出的等待体验?
答:可以通过实现加载动画、分阶段请求、提供取消选项、预估完成时间等方式改善用户等待体验。对于特别长的生成任务,可以考虑异步处理并通知用户。
问:非流式输出是否更适合移动应用?
答:通常是的。非流式输出对网络连接的要求较低,且资源消耗更可控,更适合移动环境。但如果用户体验是首要考虑因素,且网络条件允许,流式输出仍然可以在移动应用中提供更好的交互体验。
问:如何处理非流式输出中的超时问题?
答:设置合理的超时参数、实现请求重试机制、考虑将大型请求拆分为多个小请求,以及在服务端优化处理速度都是有效的策略。
流式输出与非流式输出未来趋势
随着大模型技术的发展,流式输出和非流式输出的应用也在不断演进:
- 智能流控技术:Claude 3.5 Sonnet 等模型已开始支持智能流式控制,可根据内容复杂度动态调整生成节奏,在保持用户体验的同时优化资源使用。
- 混合模式应用:越来越多的应用采用混合模式,根据不同场景动态切换流式和非流式输出,例如在对话初始阶段使用流式输出提供即时反馈,而在生成复杂内容时切换到非流式模式确保完整性。
- 边缘计算优化:随着边缘计算技术的发展,流式输出在低延迟场景中的应用将进一步扩展,特别是在 IoT 设备、AR/VR 应用等对实时性要求高的领域。
- 自适应传输策略:未来的 API 可能会实现自适应传输策略,根据网络条件、内容类型和用户偏好自动选择最优的输出模式,无需开发者手动指定。
为什么选择 API易
在实现流式输出和非流式输出时,选择稳定可靠的 API 服务至关重要。API易 提供了以下优势:
- 全面的模型支持
- 支持 OpenAI、Claude、Gemini 等主流大模型
- 所有模型均支持流式和非流式调用
- 统一的 API 接口简化开发
- 高性能服务
- 多节点部署确保连接稳定性
- 优化的流式传输性能
- 不限速调用支持高并发场景
- 开发便捷性
- 兼容官方 SDK,无缝切换
- 详细的开发文档和示例代码
- 7×24 小时技术支持
- 成本优势
- 透明的计费系统
- 按量付费,无最低消费
- 新用户免费额度体验
- 稳定可靠
- 解决国际平台访问不稳定问题
- 确保模型的持续可用性
- 多重备份保障服务质量
总结
流式输出和非流式输出各有优势,选择哪种模式应基于具体应用场景和需求:
- 流式输出优势在于提供即时反馈和更好的用户体验,特别适合对话系统、实时协作和长文本生成等场景。
- 非流式输出优势在于确保内容完整性和简化实现,适合批量处理、高精度要求和资源受限的环境。
在实际开发中,可以根据以下因素做出选择:
- 用户体验需求:如果即时反馈对用户体验至关重要,选择流式输出
- 内容完整性要求:如果内容的完整性和一致性是首要考虑因素,选择非流式输出
- 技术环境限制:根据网络条件、服务器资源和客户端能力选择合适的模式
- 开发复杂度:考虑团队的技术能力和开发时间限制
无论选择哪种模式,API易 都能提供稳定可靠的服务支持,帮助开发者构建高质量的 AI 应用。
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持 OpenAI、Claude、Gemini 等全系列模型的流式与非流式调用,让 AI 开发更简单

本文作者:API易团队
欢迎关注我们的更新,持续分享 AI 开发经验和最新动态。