2026년의 대규모 언어 모델 코드 분야는 두 가지 완전히 다른 제품 형태로 나뉘고 있습니다. 하나는 **Mistral Codestral 2(현재 최신 버전 Codestral 25.08)**로 대표되는 'IDE 우선, 고빈도 자동 완성형' 모델로, Fill-in-the-Middle(FIM), 높은 통과율의 자동 완성, 그리고 80개 이상의 언어에 대한 즉각적인 응답에 집중합니다. 다른 하나는 Zhipu GLM-5.1로 대표되는 '장기 에이전트형' 모델로, 744B 파라미터 MoE 아키텍처와 200K 컨텍스트 윈도우를 바탕으로 '8시간 자율 엔지니어링 작업'을 수행하는 SWE-Bench Pro급의 복잡한 코드 능력을 자랑합니다.
이 두 가지 경로는 타겟 사용자층과 과금 전략이 거의 겹치지 않지만, "어떤 모델이 코딩에 더 적합한가"라는 질문에서는 종종 함께 비교되곤 합니다. 본 글은 Mistral AI 공식 발표(2025-07-30 Codestral 25.08)와 Z.ai 개발자 문서(GLM-5.1, 2026-03-27 출시) 등 영문 1차 자료를 바탕으로 아키텍처, 벤치마크, 컨텍스트, 장기 작업, 배포 및 가격 등 6가지 차원에서 복제 가능한 모델 선정 결정표를 제공하며, 두 모델의 API 연동 비교 코드를 첨부하여 10분 안에 판단을 내릴 수 있도록 돕겠습니다.

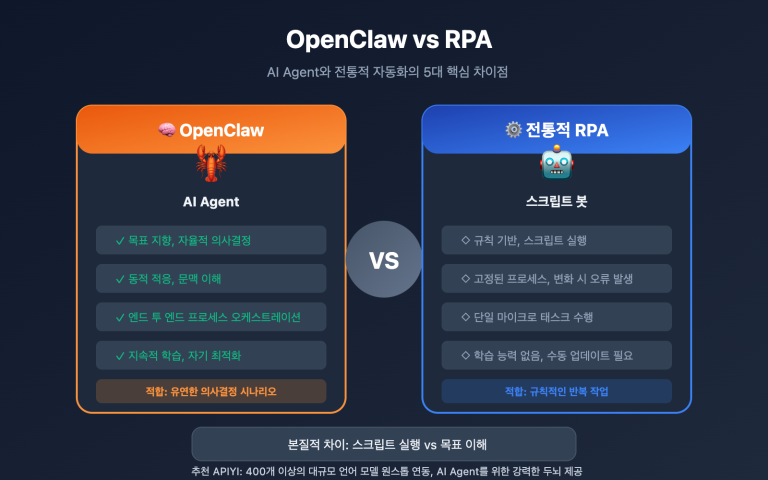
Codestral 2와 GLM-5.1의 핵심 포지셔닝 차이
본격적인 성능 비교에 앞서 꼭 알아두어야 할 점은, 두 모델은 서로 다른 제품군에 속한다는 것입니다. 같은 선상에서 비교하면 매우 오해의 소지가 있는 결론에 도달할 수 있습니다.
한 줄 요약
- Codestral 2(25.08): 코드 자동 완성 및 편집 작업을 위한 전용 코드 모델. 22B 밀집(Dense) 아키텍처, 네이티브 FIM 학습 목표, '초 단위 응답 + 높은 수락률'을 강조하며 IDE Copilot류 제품의 사실상 표준 중 하나입니다.
- GLM-5.1: 범용 에이전트 및 장기 프로그래밍 작업을 위한 범용 플래그십 모델. 744B MoE(토큰당 약 40B 활성화), 200K 컨텍스트 윈도우를 갖추었으며, SWE-Bench Pro에서 58.4점을 기록해 GPT-5.4, Claude Opus 4.6, Gemini 3.1 Pro를 앞섰습니다.
모델 선정 전 확인해야 할 세 가지 질문
| 질문 | Codestral 2 추천 | GLM-5.1 추천 |
|---|---|---|
| 주요 사용 환경이 IDE 자동 완성인가요, PR 자율 수정인가요? | IDE 자동 완성 | 다단계 자율 작업 |
| 요청당 토큰 양이 수십 개인가요, 수만 개인가요? | 수십 ~ 수천 개 | 수천 ~ 수만 개 |
| 응답 대기 시간을 수십 초까지 견딜 수 있나요? | 아니오 | 예 |
🎯 선정 가이드: 호출의 80%가 "코드 한 줄 작성 후 자동 완성"이라면 Codestral 2를 선택하세요. 반면 호출의 80%가 "리포지토리 내 버그 수정"이라면 GLM-5.1이 적합합니다. 두 모델 모두 APIYI(apiyi.com)의 통합 인터페이스를 통해 별도로 Mistral이나 Z.ai에 가입할 필요 없이 병렬 테스트가 가능합니다.
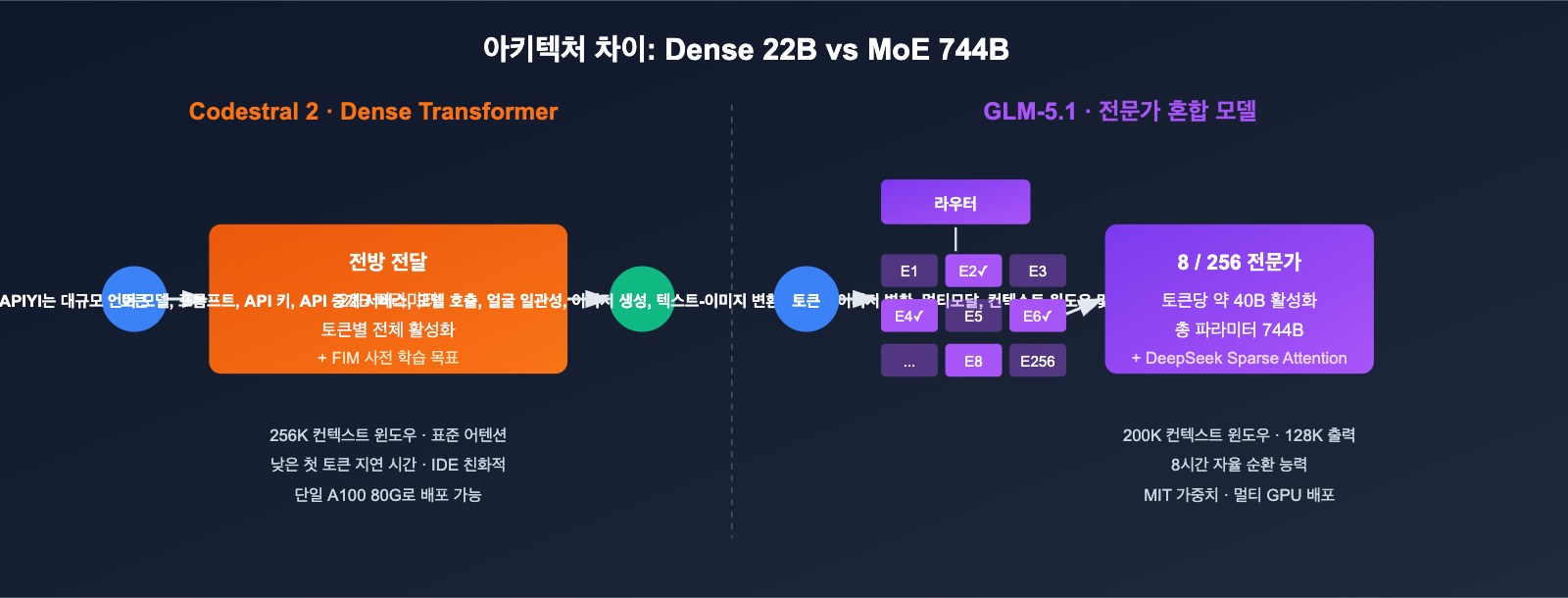
Codestral 2와 GLM-5.1의 아키텍처 및 파라미터 비교
아키텍처의 차이는 이후 모든 성능 지표의 근본적인 원인이 됩니다.
주요 사양 한눈에 보기
| 항목 | Codestral 2 (25.08) | GLM-5.1 |
|---|---|---|
| 제조사 | Mistral AI | Zhipu AI (Z.ai) |
| 아키텍처 | Dense Transformer | Mixture-of-Experts |
| 총 파라미터 | 22B | 744B |
| 활성 파라미터 | 22B | 약 40B (256 experts, 토큰당 8개 활성) |
| 컨텍스트 윈도우 | 256K | 200K |
| 최대 출력 | 표준 | 128K tokens |
| 어텐션 메커니즘 | 표준 + FIM 최적화 | DeepSeek Sparse Attention |
| 라이선스 | Mistral 상용 라이선스 / MNPL | MIT (오픈 소스 가중치) |
| 출시일 | 2025-07-30 (최신 버전) | 2026-03-27 |
| 코드 언어 지원 | 80개 이상의 주요 언어 | 범용 다국어 |
아키텍처 차이가 미치는 직접적인 영향
- VRAM 및 배포 비용: Codestral 2는 22B 모델로 단일 기기(A100 80G)에서 추론이 가능하지만, GLM-5.1은 멀티 GPU 병렬 처리나 관리형 추론 서비스가 필요합니다.
- 토큰당 지연 시간(Latency): Codestral 2의 Dense 아키텍처는 짧은 입력에서 더 안정적인 지연 시간을 보입니다. 반면 GLM-5.1은 라우터 선택과 희소 어텐션(Sparse Attention)의 영향으로 첫 토큰 생성은 다소 느릴 수 있으나 긴 시퀀스 처리에서 강점을 보입니다.
- 오픈 소스 전략: GLM-5.1은 MIT 라이선스로 가중치를 공개하여 프라이빗 배포 및 추가 학습에 유리합니다. Codestral 2는 로컬 실행은 가능하지만 상업적 이용 시 라이선스가 필요합니다.
🎯 배포 제안: 완전한 프라이빗 배포가 필요한 팀은 GLM-5.1의 MIT 가중치를 우선 고려하세요. 빠른 도입을 원하고 자체 호스팅이 부담스러운 팀이라면 APIYI(apiyi.com)를 통해 두 모델의 API를 바로 호출하여 구매 및 라이선스 협의 과정을 생략할 수 있습니다.
Codestral 2 vs GLM-5.1 핵심 코드 벤치마크 비교
두 모델의 성능 점수는 제조사의 자체 테스트 결과이며, 평가 데이터셋이 완전히 일치하지는 않습니다. 직접적인 비교가 가능한 지표만 정리했습니다.
Codestral 2의 강점: 완성도 및 IDE 지표
| 지표 | 수치 | 설명 |
|---|---|---|
| Accepted Completions (수락률) | +30% (25.01 대비) | 프로덕션 환경 IDE 채택률 |
| Retained Code (유지율) | +10% | 제안된 코드가 제출 시 삭제되지 않은 비율 |
| Runaway Generations (제어 불능 생성) | -50% | 불필요하게 길게 생성되는 현상 감소 |
| IFEval v8 (지시 이행) | +5% | 지시 사항 정확도 |
| MultiPL-E 평균 점수 | +5% | 다국어 코드 생성 능력 |
| HumanEval (이전 버전 25.01 데이터) | 86.6% | 참조 데이터 |
| MBPP (이전 버전 25.01 데이터) | 91.2% | 참조 데이터 |
GLM-5.1의 강점: 복잡한 엔지니어링 작업
| 지표 | 수치 | 설명 |
|---|---|---|
| SWE-Bench Pro | 58.4 | GPT-5.4 / Claude Opus 4.6 / Gemini 3.1 Pro 능가 |
| Claude Code 비교 | 45.3 (Opus 4.6은 47.9) | Opus 4.6 성능의 94.6% 달성 |
| vs GLM-5 베이스라인 | +28% | 사후 학습 최적화 결과 |
| KernelBench Level 3 | 3.6배 가속 | ML 커널 최적화 시나리오 |
| 단일 작업 지속 시간 | 최대 8시간 | 자율적인 "실험-분석-최적화" 루프 |
두 모델의 능력 중첩도 평가
| 능력 | Codestral 2 | GLM-5.1 |
|---|---|---|
| 단일 파일 완성 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 다중 파일 리팩토링 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 버그 위치 파악 + PR 수정 | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| 교차 언어 번역 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 에이전트 / 도구 사용 | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| 첫 토큰 지연 시간 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
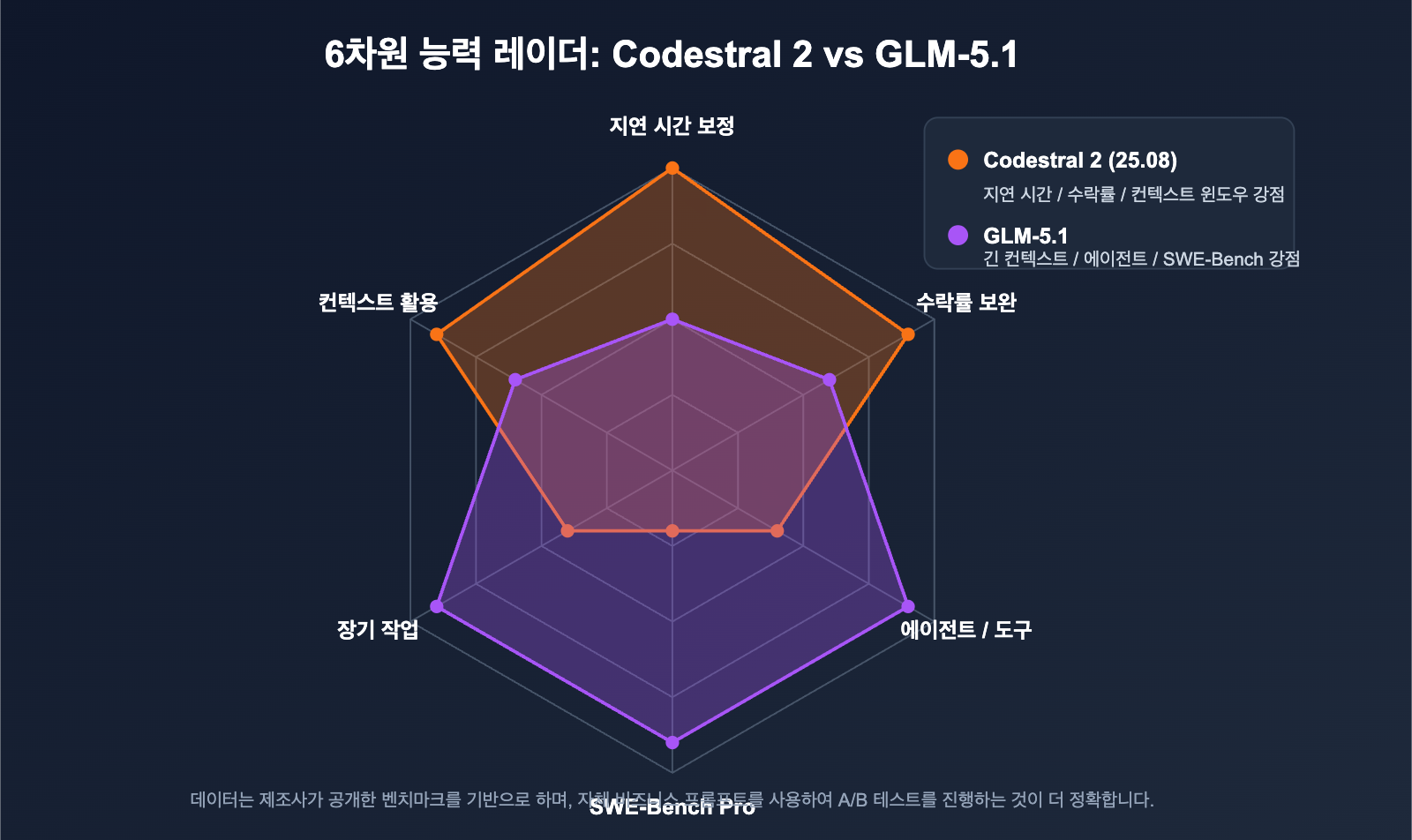
🎯 벤치마크 읽기 팁: 공식 데이터는 일반적으로 가장 최적화된 설정에서 측정되므로 실제 업무 환경에서는 10%~20% 정도의 차이가 발생할 수 있습니다. 실제 사용 중인 코드베이스를 APIYI(apiyi.com)에서 직접 A/B 테스트해 보시고 최종 결정을 내리는 것을 권장합니다.
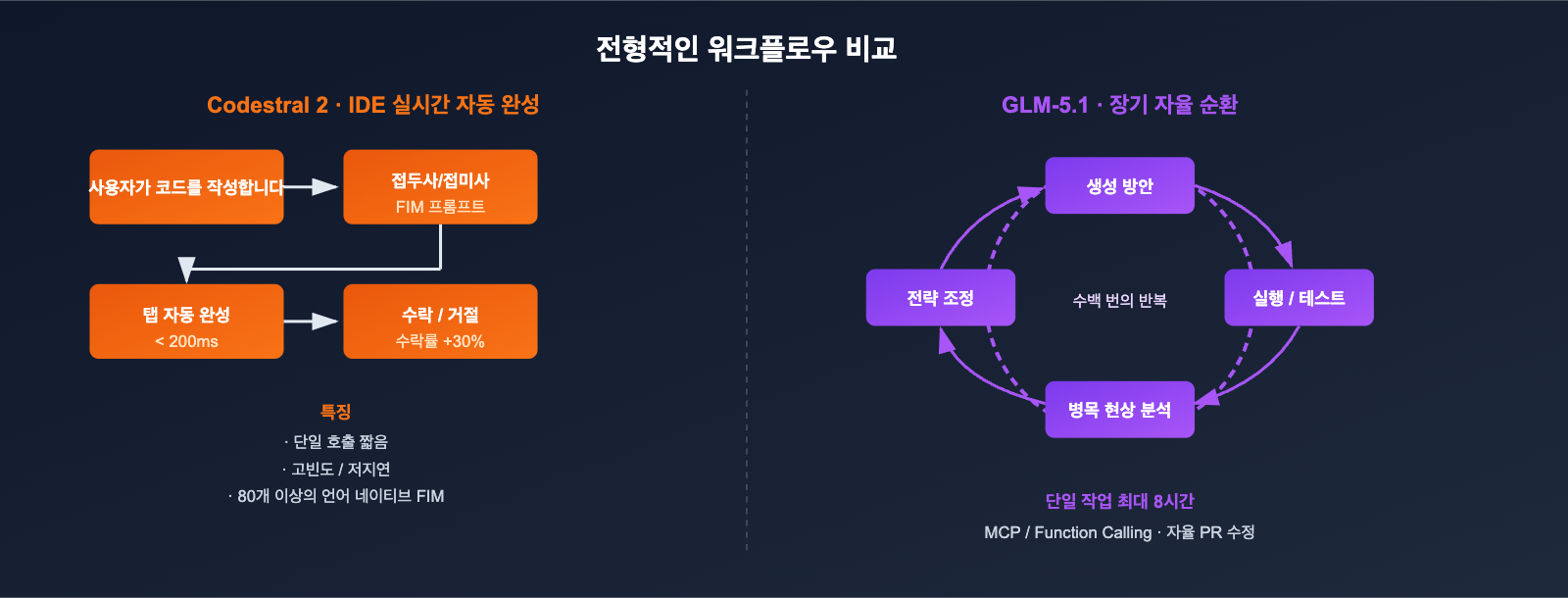
Codestral 2 와 GLM-5.1의 컨텍스트 및 장기 작업 능력 비교
256K와 200K라는 컨텍스트 윈도우는 숫자상으로는 비슷해 보이지만, 실제로 처리할 수 있는 작업의 성격은 완전히 다릅니다.
Codestral 2의 256K 컨텍스트: 전체 코드베이스 보완
Codestral 2는 256K 컨텍스트를 주로 "코드베이스 전체를 프롬프트에 담는" 용도로 활용하며, 이를 통해 코드 보완 시 파일 간의 의존성을 파악합니다.
- 적합한 작업: 모노레포 내 대형 함수 보완, 전체 프로젝트 Lint 수정, 모듈 간 이름 변경.
- 부적합한 작업: 다단계 추론, 도구 호출, 결과 반영이 필요한 에이전트 프로세스.
GLM-5.1의 200K 컨텍스트 + 8시간 자율 루프
GLM-5.1의 핵심은 "얼마나 많은 컨텍스트를 담느냐"가 아니라 "얼마나 오랫동안 지속적으로 작업할 수 있느냐"에 있습니다.
- 공식 시연에 따르면, 이 모델은 단일 작업 내에서 수백 번 반복할 수 있습니다: 벤치마크 실행 → 병목 현상 식별 → 전략 조정 → 벤치마크 재실행.
- DeepSeek Sparse Attention을 통해 200K의 긴 시퀀스에서도 추론 비용을 합리적인 수준으로 유지합니다.
- Function Calling / MCP와 결합하여 외부 도구 체인과 직접 연동할 수 있습니다.
주요 장기 작업 비교
| 작업 | Codestral 2 | GLM-5.1 |
|---|---|---|
| 200줄 함수 보완 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| GitHub Issue에서 PR 생성 | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| 레포지토리 전체 버그 탐색 및 수정 | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| 다회차 자동 ML 커널 튜닝 | ⭐ | ⭐⭐⭐⭐⭐ |
| IDE에서 Tab 키로 보완 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
🎯 시나리오 전환 제안: 기존에 Codestral로 전체 레포지토리 보완을 수행하던 팀이 "보완은 완료되었으나 테스트를 통과하지 못하는" 상황에 직면했다면, GLM-5.1을 도입해 "생성-실행-수정"의 폐쇄 루프를 구축해 보세요. APIYI(apiyi.com)를 통해 base_url만 변경하면 기존의 OpenAI 호환 코드를 그대로 재사용할 수 있습니다.
빠른 시작: Codestral 2와 GLM-5.1 API 연동 비교
두 모델 모두 OpenAI 호환 인터페이스를 제공하며, 실제 차이는 모델명과 파라미터에 있습니다. 아래 예시는 APIYI(apiyi.com)의 통합 base_url을 사용한 최소 실행 코드입니다.
Codestral 2 호출 (코드 보완)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
resp = client.chat.completions.create(
model="codestral-latest", # Codestral 25.08 지정
messages=[
{"role": "system", "content": "당신은 시니어 파이썬 엔지니어입니다."},
{"role": "user", "content": "고성능 LRU 캐시 구현을 보완해 주세요."},
],
temperature=0.2,
max_tokens=512,
)
print(resp.choices[0].message.content)
GLM-5.1 호출 (장기 작업)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_API_KEY",
)
resp = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role": "system", "content": "당신은 SWE 에이전트입니다. 레포지토리를 분석하고 테스트를 실행하며 반복 수행하세요."},
{"role": "user", "content": "레포지토리 내 tests/test_api.py의 모든 실패 케이스를 수정하세요."},
],
temperature=0.3,
max_tokens=8192,
# GLM-5.1은 Function Calling + 구조화된 출력을 지원합니다.
)
print(resp.choices[0].message.content)
📎 FIM 전용 호출 펼쳐보기 (Codestral 2 전용)
# Codestral 네이티브 FIM은 prefix / suffix로 프롬프트를 구성합니다.
prefix = "def binary_search(arr, target):\n "
suffix = "\n return -1"
prompt = f"[PREFIX]{prefix}[SUFFIX]{suffix}[MIDDLE]"
# 프롬프트를 user 콘텐츠로 codestral-latest에 전달하면 고정밀 보완 결과를 얻을 수 있습니다.
🎯 연동 제안: 두 모델 모두 OpenAI 스키마를 따르므로, 모델명만 변경하여 기존 비즈니스 코드를 그대로 재사용할 수 있습니다. APIYI(apiyi.com)를 통해 통합 호출하면 Mistral Console과 Z.ai 계정, 잔액, 속도 제한 정책을 각각 관리할 필요가 없어 운영 비용을 절감할 수 있습니다.
Codestral 2와 GLM-5.1의 가격 및 배포 전략
가격과 배포 유연성은 기술 도입을 결정하는 마지막 관문이죠. 주요 내용을 정리해 드립니다.
공개 가격 참고
| 모델 | 입력 단가 | 출력 단가 | 설명 |
|---|---|---|---|
| Codestral 2 (25.08) | $0.20 / 1M | $0.60 / 1M | 기존 Codestral 시리즈 가격 정책 유지 |
| GLM-5.1 | 약 $3부터 시작하는 코딩 플랜 | 패키지제 | 토큰 기반 종량제 옵션 별도 제공 |
참고: 위 가격은 제조사 공식 홈페이지 및 채널의 공개 정보를 바탕으로 하며, 실제 환율 및 프로모션은 당일 기준을 따릅니다.
배포 옵션 비교
| 배포 방식 | Codestral 2 | GLM-5.1 |
|---|---|---|
| 공식 Cloud API | ✅ Mistral Console | ✅ Z.ai 플랫폼 |
| 타사 호환 게이트웨이 | ✅ (APIYI apiyi.com 등) | ✅ (APIYI apiyi.com 등) |
| VPC / 프라이빗 클라우드 | ✅ 라이선스 필요 | ✅ MIT 자유 배포 |
| 로컬 단일 기기 추론 | ✅ 단일 A100/소비자용 GPU 제한 | ❌ 멀티 GPU 필요 |
| Function Calling | 지원 (chat completions 경유) | ✅ 네이티브 지원 + MCP |
🎯 비용 최적화 팁: 코드 완성 빈도가 높고 토큰 사용량이 적은 IDE 환경이라면 Codestral 2 + 캐싱 조합을 추천합니다. 반면, 호출 빈도는 낮지만 한 번에 많은 토큰을 처리하는 에이전트 환경이라면 GLM-5.1 패키지 요금제가 훨씬 경제적입니다. APIYI(apiyi.com)에서 모델별로 그룹을 나누어 설정하면 특정 모델에 예산이 쏠리는 것을 방지할 수 있어요.
Codestral 2와 GLM-5.1 시나리오별 추천 및 주의사항
4대 핵심 시나리오 결정 가이드
| 시나리오 | 추천 모델 | 핵심 이유 |
|---|---|---|
| VSCode / JetBrains 자동 완성 플러그인 | Codestral 2 | FIM 네이티브 지원 + 낮은 지연 시간 |
| 자동 버그 수정 / PR 봇 | GLM-5.1 | 장기 자율 루프 성능 우수 |
| 코드 리뷰 도우미 (단일 파일 코멘트) | Codestral 2 | 빠른 응답 속도, 저렴한 비용 |
| 엔드투엔드 에이전트 (테스트/배포 연동) | GLM-5.1 | MCP + Function Calling |
| 보일러플레이트 프로젝트 골격 생성 | 공통 | 두 모델 모두 적합 |
| ML 커널 성능 튜닝 | GLM-5.1 | KernelBench 3.6배 가속 |
흔히 하는 실수 방지 리스트
- ❌ Codestral 2로 에이전트를 돌리지 마세요: 제어 불가능한 생성 비율이 50% 줄긴 했지만, 다단계 의사결정에 최적화된 모델은 아닙니다.
- ❌ GLM-5.1을 밀리초 단위 자동 완성에 쓰지 마세요: 첫 토큰 지연 시간(TTFT) 때문에 IDE Tab 키 응답 경험이 매끄럽지 않을 수 있습니다.
- ❌ 단일 벤치마크 지표만 보지 마세요: SWE-Bench Pro에서는 GLM-5.1이 앞서지만, HumanEval에서는 Codestral 시리즈도 뒤처지지 않습니다.
- ✅ 소규모 A/B 테스트를 진행하세요: 실제 업무에서 가장 자주 쓰는 프롬프트 100개를 골라 APIYI(apiyi.com)에서 모델 파라미터를 바꿔가며 직접 비교해 보세요.
자주 묻는 질문 (FAQ)
Q1: 공식 페이지에서는 왜 Codestral 2가 아니라 Codestral 25.08이라고 부르나요?
Mistral의 명명 규칙은 <시리즈>-<연도>.<월> 방식입니다. Codestral 25.08은 Codestral의 2세대 반복 모델에 해당합니다(1세대인 24.05가 출시되었고, 2세대는 25.01부터 25.08까지 진화했습니다). 업계와 커뮤니티에서는 관습적으로 25.01 이후 버전을 통칭하여 "Codestral 2"라고 부릅니다. 모델 호출 시 codestral-latest를 지정하면 현재 2세대 최신 버전을 바로 사용할 수 있습니다.
Q2: GLM-5.1은 744B 파라미터인데 추론 속도가 너무 느리지 않을까요?
MoE 아키텍처에서는 토큰당 40B 파라미터만 활성화되며, DeepSeek Sparse Attention 기술이 더해져 실제 추론 속도는 40B급 밀집(Dense) 모델과 비슷합니다. APIYI(apiyi.com)의 긴 연결(Long-connection) 및 캐싱 전략을 활용하면 긴 컨텍스트 환경에서도 체감 지연 시간을 충분히 수용 가능한 수준으로 유지할 수 있습니다.
Q3: 두 모델 중 컨텍스트를 더 효율적으로 활용할 수 있는 모델은 무엇인가요?
Codestral 2의 256K는 '용량'에 가깝고, GLM-5.1의 200K는 희소 어텐션(Sparse Attention) 덕분에 '실제 활용도' 측면에서 더 유리합니다. 전체 코드베이스 작업 전에는 tiktoken이나 공식 토크나이저를 사용하여 실제 토큰 수를 미리 계산해 두는 것이 불필요한 잘림(Truncation)을 방지하는 방법입니다.
Q4: 오픈 소스 가중치가 기업에 실질적으로 어떤 의미가 있나요?
GLM-5.1은 MIT 라이선스로 가중치를 공개했기 때문에 사내망 배포 및 추가 학습이 가능합니다. 반면 Codestral 2는 상용화 시 라이선스 계약이 필요합니다. 규제 준수가 엄격한 금융이나 공공기관 고객에게는 이 차이가 매우 큽니다. 단순히 지역 제한을 우회하여 사용하고 싶다면 APIYI(apiyi.com)를 통해 안정적인 국내 접속 경로를 이용할 수 있습니다.
Q5: 두 모델을 함께 사용할 수 있나요?
네, 권장하는 방식입니다. 일반적인 방법은 IDE 자동 완성에는 Codestral 2를, 백엔드 에이전트에는 GLM-5.1을 사용하는 것입니다. 각각 다른 모델 키를 사용하되, APIYI(apiyi.com)에서 통합적으로 결제 관리할 수 있습니다.
Q6: 벤치마크 점수는 제조사 자체 테스트인데 신뢰할 수 있나요?
Codestral과 GLM의 벤치마크 점수는 모두 자체 보고된 수치입니다. Z.ai의 SWE-Bench Pro 58.4점은 아직 독립적인 검증이 이루어지지 않았습니다. 공개된 점수는 '능력의 상한선' 정도로 참고하고, 실제 도입 전에는 반드시 비즈니스 시나리오에 맞춰 회귀 테스트를 진행하시기 바랍니다.
결론: Codestral 2 vs GLM-5.1 최종 선택 가이드
처음에 던졌던 세 가지 질문으로 돌아가 보겠습니다.
- 귀하의 서비스가 Copilot, Tab 자동 완성, 코드 조각 생성 위주라면 Codestral 2를 선택하세요. FIM(Fill-In-the-Middle), 지연 시간, 가격, 80개 이상의 언어 지원 범위 등 해당 시나리오에서 최적의 균형을 보여줍니다.
- 귀하의 서비스가 PR 봇, 버그 수정 에이전트, 8시간 동안 작업을 수행하는 백엔드 에이전트라면 GLM-5.1을 선택하세요. 744B MoE + SWE-Bench Pro 58.4 + 장기 자율 루프 기능은 현재 오픈 소스 진영에서 Claude Opus 4.6에 가장 근접한 선택지입니다.
- 귀하의 서비스가 위의 두 가지 시나리오를 모두 포함한다면, 두 모델을 병행하는 것이 2026년 기준 가장 경제적인 전략입니다.
🎯 도입 제안: 선택의 기준을 '둘 중 하나'에서 '이중 모델 오케스트레이션'으로 업그레이드하세요. APIYI(apiyi.com)의 OpenAI 호환 인터페이스를 통해 비즈니스 코드에서 필드 하나만으로 '짧은 자동 완성 / 긴 작업'을 구분하면, Codestral 2와 GLM-5.1 사이에서 자동으로 라우팅되어 각 요청에 가장 적합한 모델로 처리할 수 있습니다.
— APIYI Team (APIYI 기술팀)