저자 주: Gemini 3.1 Pro Preview의 출력 토큰이 보이는 글자 수를 훨씬 초과하는 이유 상세 설명: Thinking Tokens 추론 체인 메커니즘, 과금 규칙, thinking_level 파라미터 조정을 통한 비용 절감 팁
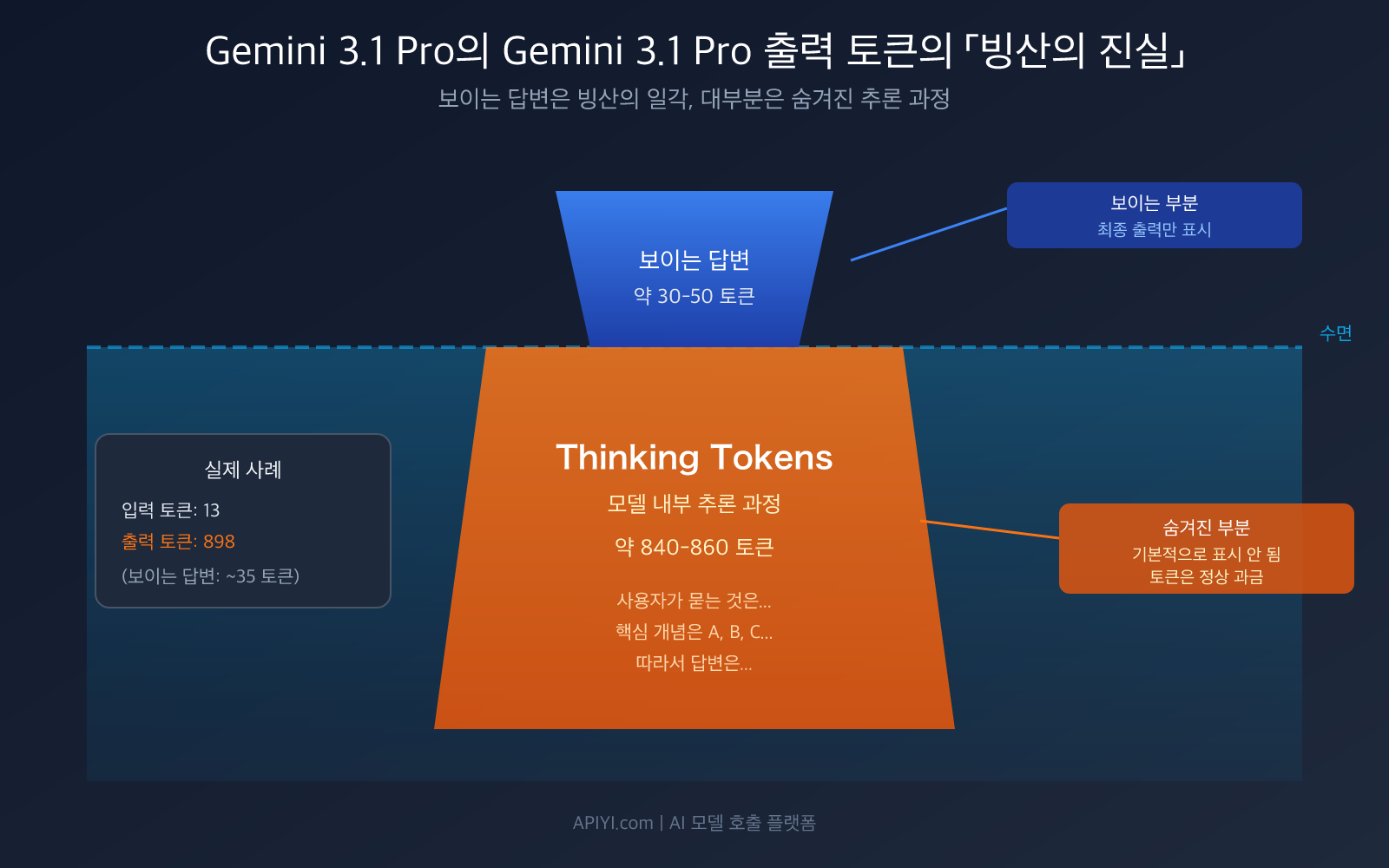
"저는 한 문장만 보냈고, 모델도 열 몇 자만 답변했는데, 왜 출력 토큰이 거의 900개로 표시되나요? 돈은 어디로 간 거죠?" — 많은 개발자들이 Gemini 3.1 Pro Preview를 처음 사용할 때 느끼는 진짜 고민입니다. 스크린샷의 데이터도 이 현상을 명확히 보여줍니다: 입력은 13 토큰인데, 출력은 무려 898 토큰에 달하네요.
정답은 바로 Thinking Tokens(추론 토큰)입니다. Gemini 3.1 Pro는 추론 모델로, 여러분에게 답변하기 전에 '머릿속'에서 긴 사고 과정(추론)을 먼저 수행합니다. 이 추론 내용은 기본적으로 여러분에게 보여지지 않지만, 출력 토큰으로 계산되어 정상적으로 과금됩니다.
핵심 가치: 이 글을 읽고 나면, 추론 모델의 Thinking Tokens 메커니즘을 완전히 이해하게 되고, thinking_level 파라미터로 추론 깊이를 제어하는 법을 배워 품질을 보장하면서 출력 토큰 비용의 50-80%를 절약할 수 있습니다.
Gemini 3.1 Pro Thinking Tokens 핵심 포인트
추론 모델과 일반 대화 모델의 가장 큰 차이는 출력 토큰의 구성이 완전히 다르다는 점입니다. 이해해야 할 핵심 개념은 다음과 같습니다:
| 포인트 | 설명 | 실제 영향 |
|---|---|---|
| 출력 토큰 = 생각 + 답변 | Gemini 3.1 Pro의 출력 토큰은 Thinking Tokens(추론 체인)과 실제 답변 두 부분을 포함합니다 | 보이는 글자는 적지만 총 토큰 수는 높습니다 |
| Thinking Tokens 정상 과금 | 추론 과정은 보이지 않지만 출력 토큰 가격으로 과금됩니다($12/백만 토큰) | 간단한 질문도 일반 모델보다 5-10배 비쌀 수 있습니다 |
thinking_level 조정 가능 |
LOW/MEDIUM/HIGH 세 단계의 추론 깊이 제어를 지원합니다 | LOW 단계에서 출력 토큰 80% 이상 절약 가능 |
| 비추론 모델은 이 문제 없음 | GPT-4o, Claude Sonnet 4.6(Extended Thinking 비활성화) 등 모델은 보이는 대로 과금됩니다 | 간단한 작업은 비추론 모델이 더 경제적입니다 |
Gemini 3.1 Pro Thinking Tokens의 실제 소비 사례
스크린샷의 예시로 돌아가 보겠습니다. 사용자가 간단한 질문을 보냈고, 모델은 열 몇 자 정도 답변했지만, 출력 토큰은 891-898개로 표시됩니다. 이 토큰들의 구성은 대략 다음과 같습니다:
- 보이는 답변: 약 30-50 토큰(여러분이 본 그 열 몇 자)
- Thinking Tokens: 약 840-860 토큰(모델 내부의 추론 과정)
즉, 출력 토큰의 95% 이상은 여러분이 볼 수 없습니다. 이 토큰들은 모델의 추론 체인에서 소비된 거죠. 마치 여러분이 수학 선생님께 "1+1은 얼마예요?"라고 물었을 때, 선생님은 입으로는 "2입니다"라고만 말했지만, 머릿속에서는 "이건 기초 산수 문제구나, 덧셈 연산이 필요해…"라고 생각한 것과 같습니다. 그리고 여러분은 선생님의 전체 사고 과정에 대해 비용을 지불하는 거죠.
이 메커니즘은 버그가 아니라 추론 모델의 설계 특성입니다. Gemini 3.1 Pro가 복잡한 문제에서 더 나은 성능을 보이는 이유(MATH 벤치마크 95.1%, ARC-AGI-2 77.1% 달성)는 바로 답변하기 전에 깊이 있는 추론을 수행하기 때문입니다.
추론 모델과 일반 모델의 본질적 차이
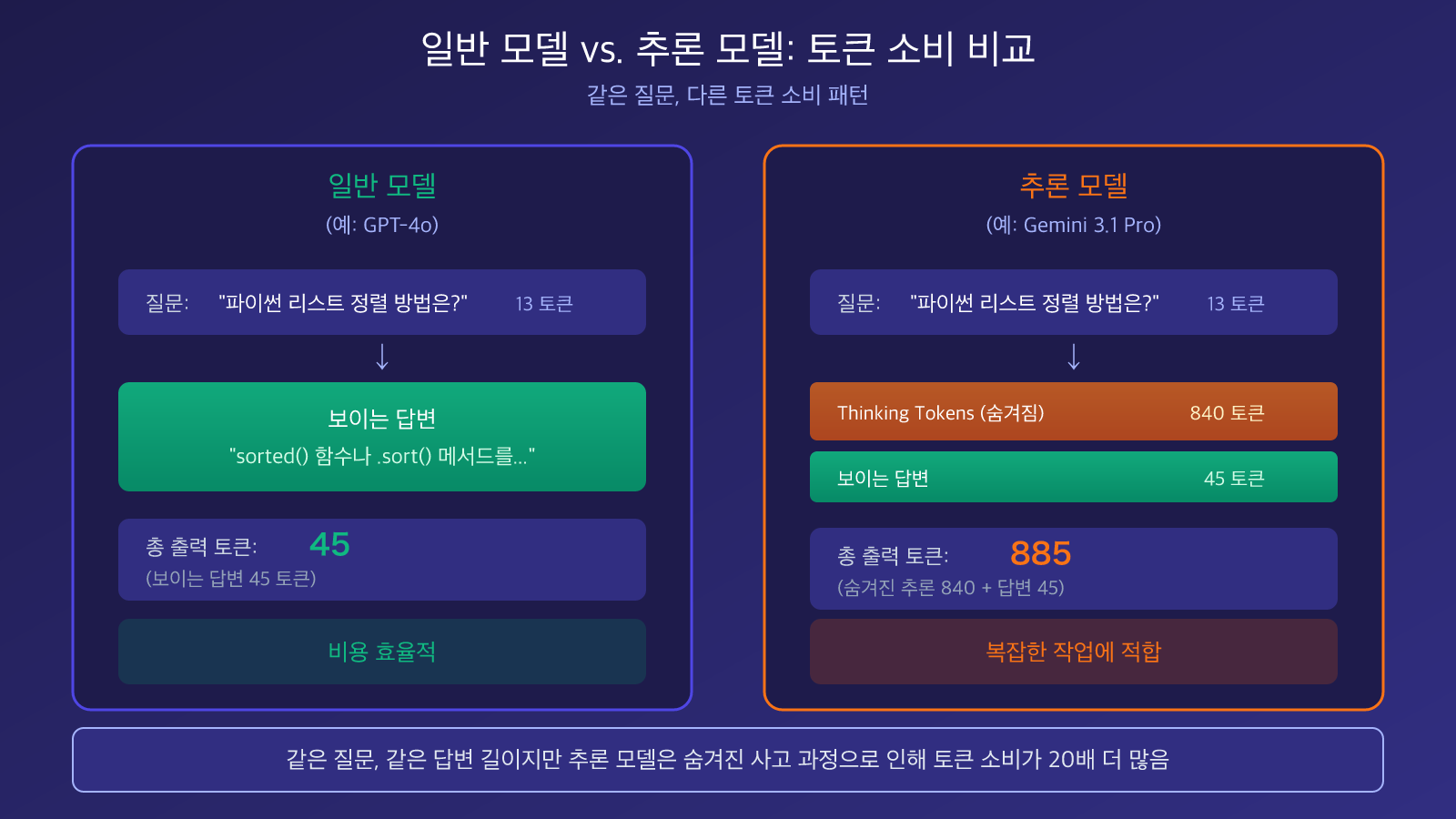
일반 모델(예: GPT-4o)은 여러분의 질문을 받으면 바로 답변을 생성합니다. 여러분이 보는 글자 수만큼 출력 토큰이 소비됩니다. 이것이 바로 '보는 대로 지불'입니다.
추론 모델(예: Gemini 3.1 Pro Preview)은 질문을 받으면 먼저 내부 추론 체인(Chain of Thought)을 생성한 후, 그 추론 결과를 바탕으로 최종 답변을 생성합니다. 여러분이 보는 것은 최종 답변뿐이지만, 요금은 '추론 체인 + 답변'의 총 토큰 수로 청구됩니다.
| 모델 유형 | 대표 모델 | 출력 토큰 구성 | 간단한 문제 비용 | 복잡한 문제 장점 |
|---|---|---|---|---|
| 일반 모델 | GPT-4o, Claude Sonnet 4.6 | 100% 보이는 답변 | 낮음(보는 대로 지불) | 추론 능력 일반적 |
| 추론 모델 | Gemini 3.1 Pro, GPT-5.4 Thinking | 추론 체인 + 보이는 답변 | 높음(5-10배 이상) | 복잡한 추론 능력 강함 |
| 전환 가능 모델 | Claude Sonnet 4.6(Extended Thinking) | 추론 활성화 선택 가능 | 유연한 전환 | 필요에 따라 추론 활성화 |
Gemini 3.1 Pro Thinking Tokens의 3가지 핵심 세부사항
세부사항 1: Thinking Tokens의 요금 청구 방식. Google 공식 문서에 따르면, Thinking Tokens는 출력 토큰의 표준 가격으로 청구됩니다. Gemini 3.1 Pro의 출력 토큰 가격은 $12/백만 토큰입니다. 모델이 4000개의 토큰으로 추론하고, 500개의 토큰으로 답변할 때, 여러분은 4500개의 출력 토큰에 대해 비용을 지불해야 합니다—500개가 아닙니다.
세부사항 2: API 응답에서 구분하는 방법. Gemini API 응답에서 usage_metadata 필드는 thoughts_token_count(추론 토큰 수)와 candidates_token_count(총 출력 토큰 수)를 각각 반환합니다. 하지만 주의할 점: Gemini API의 candidatesTokenCount는 Thinking Tokens를 포함하지만, Vertex AI의 candidatesTokenCount는 포함하지 않습니다.
세부사항 3: 추론 체인 내용은 기본적으로 보이지 않습니다. includeThoughts: true를 설정하여 추론 과정의 요약(전체 추론 체인이 아님)을 얻을 수 있으며, Cherry Studio와 같은 도구에서 추론 체인 표시 기능을 켜 모델의 사고 과정을 볼 수도 있습니다.
🎯 비용 절약 팁: 단순한 대화나 번역 작업처럼 깊은 추론이 필요하지 않은 경우, 일반 모델(예: GPT-4o-mini 또는 Claude Sonnet 4.6)로 전환하는 것이 좋습니다. APIYI apiyi.com은
model매개변수 하나만 수정하면 모델을 전환할 수 있도록 지원하며, 다른 코드를 변경할 필요가 없습니다.
Gemini 3.1 Pro Thinking Tokens 최적화: 3가지 비용 절약 전략
전략 1: thinking_level 매개변수를 사용해 추론 깊이 제어하기
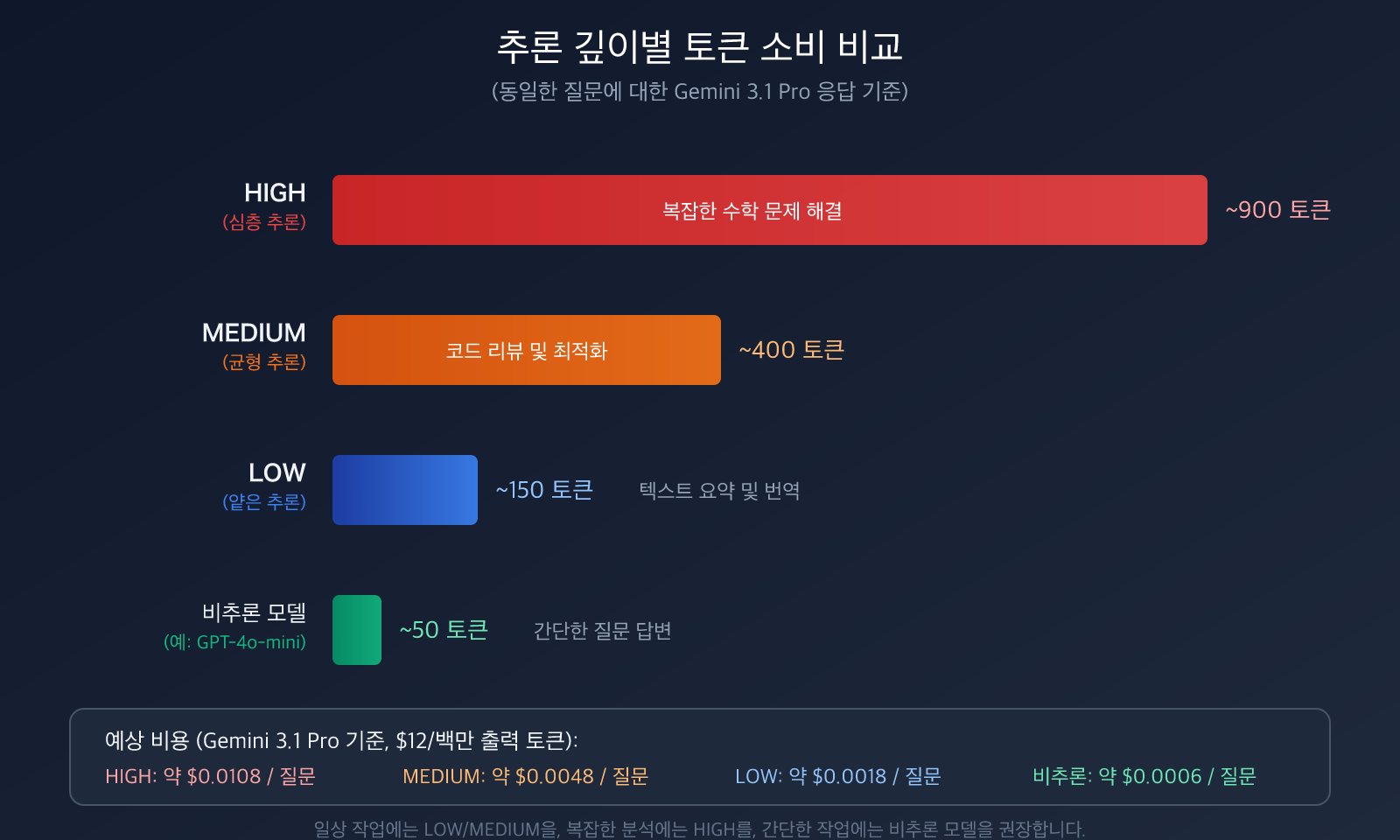
Gemini 3.1 Pro는 thinking_level 매개변수를 제공하며, LOW, MEDIUM, HIGH 세 단계를 지원합니다. 각 단계별 토큰 소비량 차이는 매우 큽니다:
| thinking_level | 추론 깊이 | 토큰 소비 | 적용 시나리오 | HIGH 대비 |
|---|---|---|---|---|
| LOW | 얕은 추론 | 최소 | 번역, 분류, 간단한 질문답변 | 약 80%+ 절약 |
| MEDIUM | 균형 추론 | 중간 | 일상적인 프로그래밍, 문서 생성, 일반 분석 | 약 50% 절약 |
| HIGH | 심층 추론 | 최대 | 수학적 유도, 과학 문제, 복잡한 논리 | 기준선 |
다음은 thinking_level을 설정하는 코드 예시입니다:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 간단한 작업에는 LOW를 사용해 Thinking Tokens 크게 줄이기
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "把这句话翻译成英文:今天天气真好"}],
extra_body={"thinking_level": "LOW"} # LOW / MEDIUM / HIGH
)
print(response.choices[0].message.content)
print(f"总输出 Token: {response.usage.completion_tokens}")
전체 스마트 라우팅 코드 보기 (문제 복잡도에 따라 추론 깊이 자동 선택)
import openai
import json
def smart_gemini_call(
prompt: str,
complexity: str = "auto",
api_key: str = "YOUR_API_KEY"
) -> dict:
"""
Gemini 3.1 Pro를 스마트하게 호출하여 작업 복잡도에 따라 추론 깊이 자동 선택
Args:
prompt: 사용자 입력
complexity: "low" / "medium" / "high" / "auto"
api_key: API 키
Returns:
답변과 토큰 사용 통계를 포함한 딕셔너리
"""
client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
# 복잡도 자동 판단
if complexity == "auto":
simple_keywords = ["翻译", "translate", "分类", "classify", "总结", "summarize"]
complex_keywords = ["推导", "证明", "计算", "分析", "比较", "为什么"]
prompt_lower = prompt.lower()
if any(kw in prompt_lower for kw in simple_keywords):
thinking_level = "LOW"
elif any(kw in prompt_lower for kw in complex_keywords):
thinking_level = "HIGH"
else:
thinking_level = "MEDIUM"
else:
thinking_level = complexity.upper()
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": prompt}],
extra_body={"thinking_level": thinking_level}
)
return {
"answer": response.choices[0].message.content,
"thinking_level": thinking_level,
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens
}
# 사용 예시
# 간단한 작업 → LOW 자동 선택
result = smart_gemini_call("翻译:今天天气真好")
print(f"推理深度: {result['thinking_level']}, 输出Token: {result['output_tokens']}")
# 복잡한 작업 → HIGH 자동 선택
result = smart_gemini_call("证明勾股定理的至少两种方法")
print(f"推理深度: {result['thinking_level']}, 输出Token: {result['output_tokens']}")
제안: APIYI apiyi.com을 통해 Gemini 3.1 Pro를 호출할 때
thinking_level매개변수를 전달할 수 있습니다. 일상적인 사용에는 MEDIUM으로 설정하고, 수학/과학 등 복잡한 추론 시나리오에서만 HIGH를 사용하는 것을 권장합니다.
전략 2: 간단한 작업에는 비추론 모델 직접 사용하기
모든 시나리오에 추론 모델이 필요한 것은 아닙니다. 번역, 형식 변환, 간단한 질문답변과 같은 작업에는 비추론 모델을 사용하면 5-10배의 토큰 비용을 절약할 수 있습니다:
- GPT-4o-mini: 가성비가 매우 뛰어나며, 일상 대화에 최적
- Claude Sonnet 4.6(Extended Thinking 비활성화): 출력 품질이 높고, 토큰이 보이는 대로 지불
- Gemini 3.1 Flash: Google의 경량 모델로, 속도가 빠르고 비용이 낮음
전략 3: max_tokens 설정으로 출력 상한 제한하기
API 호출에 max_tokens 매개변수를 추가하면 추론 모델이 '지나치게 생각하는 것'을 방지할 수 있습니다. 하지만 주의할 점: max_tokens는 총 출력(추론 + 답변)을 제한하므로, 너무 낮게 설정하면 답변이 잘릴 수 있습니다. 예상 답변 길이의 2-3배로 설정하는 것을 권장합니다.
🎯 종합 제안: APIYI apiyi.com 플랫폼에서는 통일된 인터페이스로 추론 모델과 비추론 모델을 동시에 접속하여 작업 유형에 따라 동적으로 전환할 수 있습니다. 하나의 API 키로 Gemini, Claude, GPT 전 시리즈 모델을 호출할 수 있습니다.
자주 묻는 질문
Q1: Gemini 3.1 Pro Thinking Tokens는 왜 기본적으로 추론 과정을 보여주지 않나요?
이는 Google의 제품 설계 선택입니다. 완전한 추론 체인에는 수천 개의 토큰에 달하는 중간 유도 과정이 포함될 수 있어, 이를 직접 보여주면 사용자 경험이 크게 저하됩니다. includeThoughts: true를 설정하여 추론 요약을 얻거나, Cherry Studio와 같은 클라이언트에서 추론 체인 표시 기능을 켜서 사고 과정을 확인할 수 있습니다.
Q2: API 응답에서 Thinking Tokens가 정확히 얼마나 소비되었는지 어떻게 확인하나요?
Gemini API가 반환하는 usage_metadata에서 thoughts_token_count 필드를 확인하세요. APIYI apiyi.com을 통해 호출하는 경우, 플랫폼의 사용량 통계 페이지에서 각 호출의 상세한 토큰 분해(입력/출력/추론)를 확인하여 비용을 모니터링하고 최적화할 수 있습니다.
Q3: Gemini 3.1 Pro 외에 어떤 모델에 Thinking Tokens와 유사한 메커니즘이 있나요?
주요 추론 모델에는 유사한 메커니즘이 있습니다:
- GPT-5.4 Thinking: OpenAI의 추론 모델로, 추론 토큰 역시 출력 토큰으로 청구됩니다.
- Claude Sonnet 4.6 Extended Thinking: Anthropic의 추론 모드로, 선택적으로 켤 수 있습니다.
- DeepSeek-R1: 오픈소스 추론 모델로, 추론 체인이 완전히 가시적입니다.
핵심 차이점은 일부 모델(예: Claude)은 추론 모드를 유연하게 켜고 끌 수 있지만, 일부 모델(예: Gemini 3.1 Pro)은 기본적으로 추론이 켜져 있다는 점입니다. APIYI apiyi.com을 통해 통일된 인터페이스로 이러한 모델들의 실제 토큰 소비를 테스트하고 비교할 수 있습니다.
요약
Gemini 3.1 Pro Thinking Tokens의 핵심 포인트는 다음과 같습니다:
- 출력 토큰에 숨겨진 추론 체인이 포함됨: 여러분이 보는 것은 답변 부분뿐이며, 출력 토큰의 95% 이상은 보이지 않는 Thinking Tokens에서 소비됩니다.
- Thinking Tokens는 정상적으로 과금됨: 출력 토큰 표준 가격으로 청구되며, 간단한 질문의 비용은 비추론 모델의 5-10배가 될 수 있습니다.
thinking_level파라미터로 비용 절약: LOW 수준은 80% 이상의 토큰을 절약할 수 있으며, MEDIUM은 일상적인 사용에 적합하고, 복잡한 작업에만 HIGH를 사용하세요.- 간단한 작업에는 비추론 모델 선택: 번역, 분류, 간단한 질문답변 등의 시나리오에는 GPT-4o-mini나 Claude Sonnet 4.6을 직접 사용하는 것이 더 경제적입니다.
Thinking Tokens 메커니즘을 이해하면 추론 예산을 합리적으로 배분할 수 있습니다. APIYI apiyi.com의 통일된 인터페이스를 통해 다중 모델 호출을 관리하고, 작업 복잡도에 따라 동적으로 추론 모델 또는 비추론 모델을 선택하여 최적의 품질/비용 균형을 달성하는 것을 추천합니다.
📚 참고 자료
-
Google Cloud 문서 – Thinking 추론 모드: Gemini 추론 모델의 공식 기술 문서
- 링크:
docs.cloud.google.com/vertex-ai/generative-ai/docs/thinking - 설명: Thinking Tokens 과금 규칙과 thinking_level 매개변수 설정의 권위 있는 출처
- 링크:
-
Google AI 개발자 문서 – Token 카운팅: 공식 Token 카운팅과 usage_metadata 필드 설명
- 링크:
ai.google.dev/gemini-api/docs/tokens - 설명: API 응답에서 thoughts_token_count와 candidates_token_count를 어떻게 구분하는지
- 링크:
-
Google DeepMind – Gemini 3.1 Pro 모델 카드: 모델 능력과 추론 벤치마크 상세 정보
- 링크:
deepmind.google/models/model-cards/gemini-3-1-pro/ - 설명: MATH 95.1%, ARC-AGI-2 77.1% 등 성능 데이터의 공식 출처
- 링크:
-
OpenRouter – 추론 Token 최적화 실무: 추론 모델 Token 관리의 커뮤니티 모범 사례
- 링크:
openrouter.ai/docs/guides/best-practices/reasoning-tokens - 설명: 다양한 모델 간 추론 Token 과금 규칙 비교와 최적화 제안
- 링크:
저자: APIYI 기술 팀
기술 교류: 댓글로 추론 모델의 Token 최적화 경험을 논의해 주세요. 더 많은 모델 호출 튜토리얼은 APIYI docs.apiyi.com 문서 센터를 방문하세요.