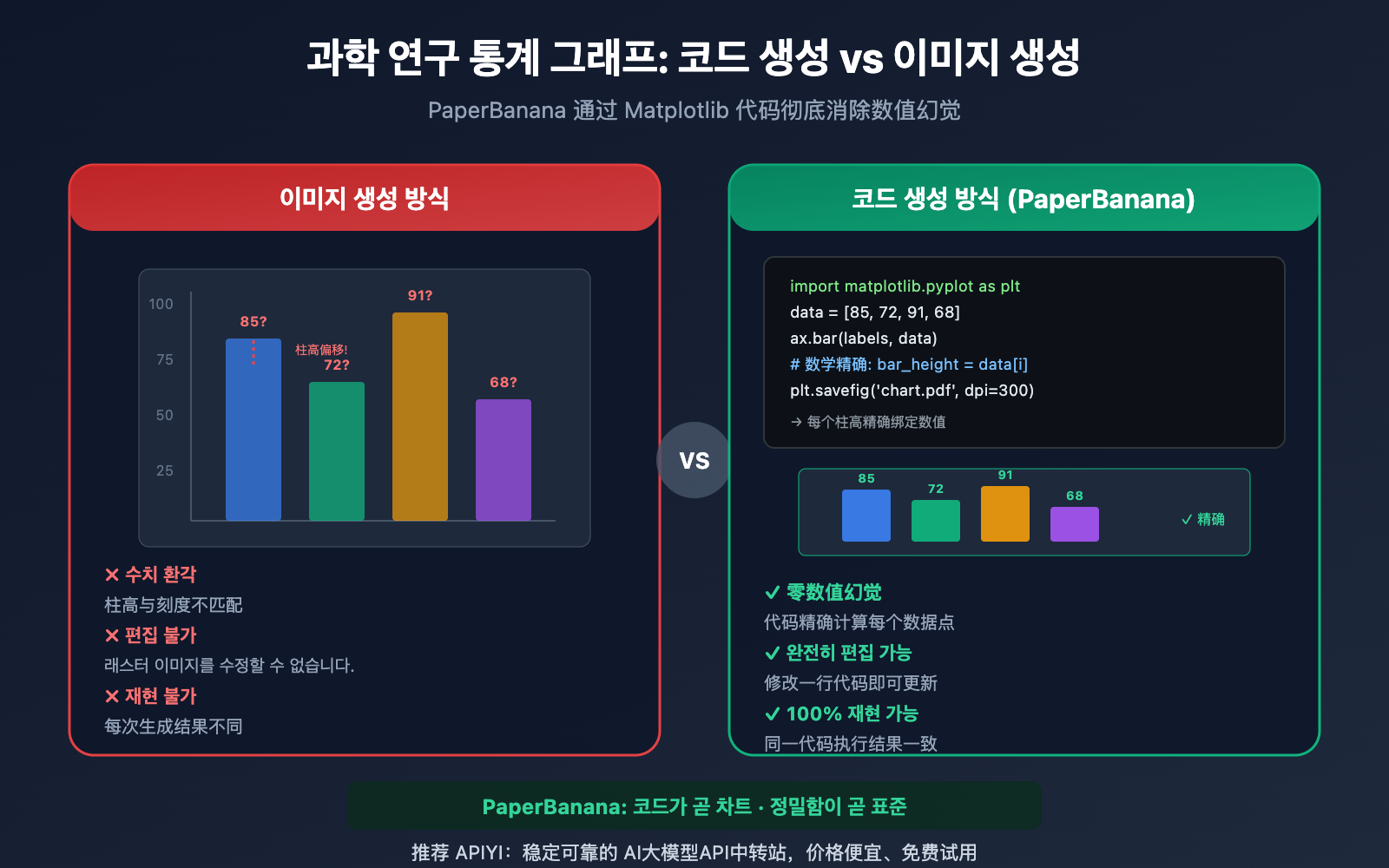
저자 주: PaperBanana가 픽셀 이미지가 아닌 실행 가능한 Matplotlib 코드를 생성하여 연구용 통계 그래프를 제작함으로써 수치 환각 문제를 어떻게 완벽하게 해결하는지 상세히 설명합니다. 막대 그래프, 꺾은선 그래프, 산점도 등 7가지 유형의 차트를 다룹니다.
학술 논문의 통계 차트는 실험의 핵심 결론을 담고 있습니다. 막대 그래프의 높이, 꺾은선 그래프의 추세, 산점도의 분포 등 모든 데이터 포인트는 정확해야만 하죠. 하지만 DALL-E나 Midjourney 같은 범용 이미지 생성기로 통계 차트를 만들면 치명적인 문제가 발생합니다. 바로 수치 환각(Numerical Hallucination)입니다. 막대 높이와 눈금이 맞지 않거나, 데이터 포인트가 어긋나고, 축 라벨이 틀리는 등 '겉보기에는 그럴싸하지만 데이터는 엉터리인' 차트가 논문에 실린다면 그 결과는 상상조차 하기 싫을 정도입니다.
핵심 가치: 이 글을 읽고 나면 PaperBanana가 왜 이미지 생성 대신 코드 생성을 선택했는지 이해하게 될 거예요. 또한 7가지 통계 차트의 Matplotlib 코드 생성 방법을 익히고, Nano Banana Pro API를 통해 비용 효율적으로 수치 환각 없는 학술 데이터 시각화를 구현하는 방법을 배우게 됩니다.
Nano Banana Pro 연구용 통계 차트 핵심 요약
| 핵심 요약 | 설명 | 가치 |
|---|---|---|
| 픽셀이 아닌 코드 생성 | PaperBanana는 이미지를 직접 렌더링하는 대신 실행 가능한 Matplotlib 코드를 생성합니다. | 막대 높이, 데이터 포인트, 좌표축이 100% 수학적으로 정확합니다. |
| 수치 환각 완벽 제거 | 코드 기반 구동으로 모든 데이터 포인트의 수치가 원본 데이터와 완벽히 일치합니다. | "겉보기엔 맞지만 데이터는 틀린" 치명적인 문제를 방지합니다. |
| 7가지 차트 유형 완벽 지원 | 막대 그래프, 꺾은선 그래프, 산점도, 히트맵, 레이더 차트, 파이 차트, 멀티 패널 차트 | 논문 통계 차트 수요의 95% 이상을 충족합니다. |
| 240개의 ChartMimic 테스트 | 표준 벤치마크에서 생성된 코드의 실행 가능성과 시각적 일치성을 검증했습니다. | 72.7%의 블라인드 테스트 승률을 기록했으며, 꺾은선/막대/산점도/멀티 패널을 포함합니다. |
| 편집 및 재현 가능 | 출력된 Python 코드를 통해 색상, 주석, 글꼴을 자유롭게 조정할 수 있습니다. | 다시 생성할 필요 없이 즉시 수정하여 게재 수준으로 다듬을 수 있습니다. |
왜 연구용 통계 차트에 이미지 생성 모델을 사용하면 안 될까요?
기존의 AI 이미지 생성 모델(DALL-E 3, Midjourney V7 등)은 연구용 통계 차트를 만들 때 근본적인 결함이 있습니다. 바로 차트를 '데이터'가 아닌 '픽셀' 단위로 렌더링한다는 점이죠. 즉, 모델이 막대 그래프를 그릴 때 [85, 72, 91, 68] 같은 수치를 계산해서 높이를 정하는 게 아니라, "막대 그래프처럼 보이는" 시각적 패턴에 따라 픽셀을 채우는 방식입니다.
그 결과 수치 환각(Numerical Hallucination)이 발생합니다. 막대 높이가 Y축 눈금과 맞지 않거나, 데이터 포인트가 실제 위치에서 벗어나고, 좌표축 레이블이 깨지거나 틀리는 식이죠. PaperBanana의 평가에 따르면, 이미지 생성 모델을 직접 사용하여 통계 차트를 만들 때 '수치 환각과 요소 중복'이 가장 빈번하게 발생하는 정확도 오류였습니다.
PaperBanana는 전혀 다른 전략을 취합니다. 통계 차트의 경우, Visualizer 에이전트가 Nano Banana Pro의 이미지 생성 기능을 사용하는 대신 실행 가능한 Python Matplotlib 코드를 생성합니다. 이런 '코드 우선' 방식은 수치 환각을 근본적으로 제거합니다. 코드가 정확한 수학적 계산에 따라 데이터와 시각적 요소를 결합하기 때문입니다.
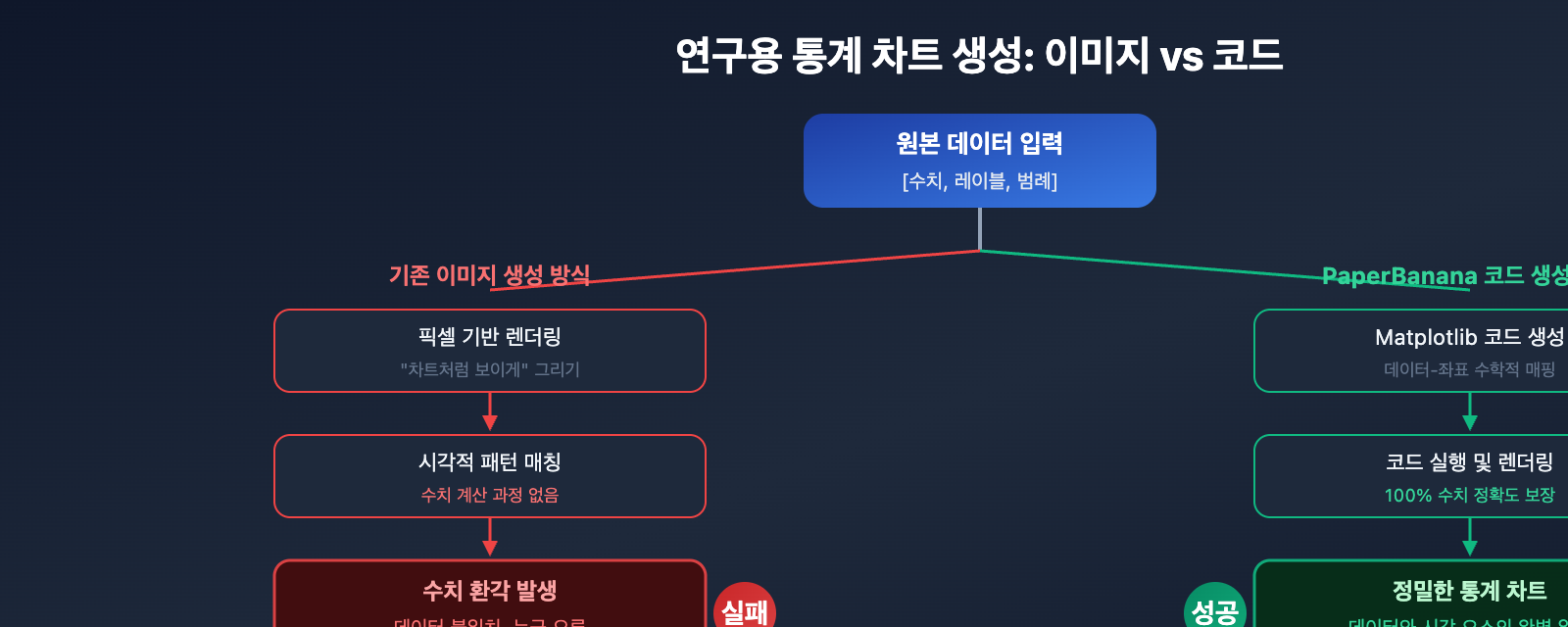
수치 환각(Numerical Hallucination) 문제 심층 분석
과학 연구 통계 그래프에서의 수치 환각이란 무엇인가
수치 환각이란 AI 이미지 생성 모델이 통계 도표를 제작할 때, 생성된 시각적 요소가 실제 데이터와 일치하지 않는 현상을 말합니다. 구체적인 증상은 다음과 같습니다.
- 막대 높이 편차: 막대 그래프의 막대 높이가 Y축 눈금 값과 일치하지 않음
- 데이터 포인트 드리프트: 산점도(Scatter Plot)의 점들이 정확한 (x, y) 좌표에서 벗어남
- 눈금 오류: 좌표축의 눈금 간격이 불균등하거나 수치 표기가 잘못됨
- 범례 혼란: 범례의 색상이 실제 데이터 시리즈와 일치하지 않음
- 레이블 깨짐: 좌표축 레이블에 오타가 발생하거나 텍스트가 겹침
수치 환각의 근본적인 원인
범용 이미지 생성 모델의 훈련 목표는 '데이터상 정확한 도표 생성'이 아니라 '시각적으로 그럴듯한 이미지 생성'입니다. 모델이 프롬프트에서 "막대 그래프, 수치 [85, 72, 91, 68]"라는 문구를 보았을 때, 수치를 픽셀 높이로 변환하는 수학적 매핑을 수행하는 것이 아닙니다. 대신 훈련 데이터셋에 포함된 수많은 막대 그래프의 '시각적 패턴'을 기반으로 근사한 외형을 만들어낼 뿐입니다.
| 문제 유형 | 구체적인 현상 | 발생 빈도 | 심각도 |
|---|---|---|---|
| 막대 높이 편차 | 막대 높이가 수치와 불일치 | 매우 높음 | 치명적: 실험 결론 왜곡 |
| 데이터 포인트 드리프트 | 산점도 점이 정확한 좌표를 벗어남 | 높음 | 치명적: 데이터 왜곡 |
| 눈금 오류 | 좌표축 눈금이 불균등함 | 높음 | 심각: 독자 오도 |
| 범례 혼란 | 색상과 시리즈가 일치하지 않음 | 중간 | 심각: 데이터 구분 불가 |
| 레이블 깨짐 | 텍스트 겹침 또는 오타 발생 | 중간 | 보통: 가독성 저하 |
PaperBanana의 코드 생성 방식이 수치 환각을 해결하는 방법
PaperBanana의 해결책은 간단하면서도 확실해요. 과학 연구용 통계 그래프를 만들 때 이미지를 직접 생성하는 대신 '코드'를 생성하는 것이죠.
PaperBanana의 Visualizer 에이전트가 통계 도표 작업 요청을 받으면, 도표 설명을 실행 가능한 Python Matplotlib 코드로 변환합니다. 이 코드 안에서는 모든 막대의 높이, 모든 데이터 포인트의 좌표, 모든 좌표축의 눈금이 수학적 계산을 통해 정밀하게 결정됩니다. 신경망이 "추측"해서 그리는 것이 아니라는 뜻이죠.
이러한 코드 우선 방식은 **수정 가능성(Editability)**이라는 중요한 부가 가치도 제공해요. 수정이 불가능한 래스터 이미지를 받는 것이 아니라, 깔끔한 Python 코드를 받게 됩니다. 색상, 폰트, 주석, 범례 위치를 자유롭게 조정할 수 있고, 심지어 원본 데이터를 수정한 뒤 다시 실행할 수도 있어요. 이는 학술지 심사 단계에서 수정 요청이 들어왔을 때 특히 유용합니다.
🎯 기술 제언: PaperBanana의 코드 생성 능력은 대규모 언어 모델을 기반으로 합니다. APIYI(apiyi.com)를 통해 Nano Banana Pro 등의 모델을 직접 호출하여 Matplotlib 코드를 생성할 수도 있어요. 이 플랫폼은 OpenAI 호환 인터페이스를 지원하며, 호출 비용도 매우 저렴합니다.
Nano Banana Pro 과학 연구 통계 그래프 7가지 유형 코드 생성
PaperBanana는 240개의 ChartMimic 벤치마크 테스트 케이스를 통해 코드 생성 방식의 유효성을 검증했습니다. 여기에는 꺾은선 그래프, 막대 그래프, 산점도, 멀티 패널 그래프 등 흔히 쓰이는 유형들이 포함되어 있죠. 다음은 7가지 과학 연구용 통계 그래프의 전체 프롬프트 템플릿과 코드 예시입니다.
제1 유형: 막대 그래프 (Bar Chart)
막대 그래프는 논문에서 가장 흔히 쓰이는 유형 중 하나로, 서로 다른 조건에서의 실험 결과를 비교할 때 사용합니다.
import matplotlib.pyplot as plt
import numpy as np
# 실험 데이터
models = ['GPT-4o', 'Claude 4', 'Gemini 2', 'Llama 3', 'Qwen 3']
accuracy = [89.2, 91.5, 87.8, 83.4, 85.1]
colors = ['#3b82f6', '#10b981', '#f59e0b', '#ef4444', '#8b5cf6']
fig, ax = plt.subplots(figsize=(8, 5))
bars = ax.bar(models, accuracy, color=colors, width=0.6, edgecolor='white')
# 수치 레이블 추가
for bar, val in zip(bars, accuracy):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.5,
f'{val}%', ha='center', va='bottom', fontsize=10, fontweight='bold')
ax.set_ylabel('Accuracy (%)', fontsize=12)
ax.set_title('Model Performance Comparison on MMLU Benchmark', fontsize=14)
ax.set_ylim(75, 95)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.tight_layout()
plt.savefig('bar_chart.pdf', dpi=300, bbox_inches='tight')
plt.show()
제2 유형: 꺾은선 그래프 (Line Chart)
꺾은선 그래프는 시간이나 조건에 따른 변화 추세를 보여주며, 학습 곡선이나 소거 실험(Ablation Study)에 적합합니다.
import matplotlib.pyplot as plt
import numpy as np
epochs = np.arange(1, 21)
train_loss = 2.5 * np.exp(-0.15 * epochs) + 0.3 + np.random.normal(0, 0.02, 20)
val_loss = 2.5 * np.exp(-0.12 * epochs) + 0.45 + np.random.normal(0, 0.03, 20)
fig, ax = plt.subplots(figsize=(8, 5))
ax.plot(epochs, train_loss, 'o-', color='#3b82f6', label='Train Loss', linewidth=2, markersize=4)
ax.plot(epochs, val_loss, 's--', color='#ef4444', label='Val Loss', linewidth=2, markersize=4)
ax.set_xlabel('Epoch', fontsize=12)
ax.set_ylabel('Loss', fontsize=12)
ax.set_title('Training and Validation Loss Curves', fontsize=14)
ax.legend(fontsize=11, frameon=False)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.tight_layout()
plt.savefig('line_chart.pdf', dpi=300, bbox_inches='tight')
plt.show()
제3 유형: 산점도 (Scatter Plot)
산점도는 두 변수 간의 상관관계나 클러스터 분포를 보여줄 때 사용합니다.
제4 유형: 히트맵 (Heatmap)
히트맵은 혼동 행렬(Confusion Matrix), 어텐션 가중치 행렬, 상관계수 행렬을 시각화하기에 좋습니다.
제5 유형: 레이더 차트 (Radar Chart)
레이더 차트는 다차원적인 능력 비교에 사용되며, 모델의 종합 평가에서 자주 볼 수 있습니다.
제6 유형: 파이/도넛 차트 (Pie/Donut Chart)
파이 차트는 구성 비율을 보여주며, 데이터셋 분포나 자원 할당 분석에 적합합니다.
제7 유형: 멀티 패널 조합 그래프 (Multi-Panel)
멀티 패널 그래프는 여러 개의 서브 플롯을 하나의 그림(Figure)으로 합친 형태로, 논문에서 가장 흔히 볼 수 있는 복합 도표 형식입니다.
| 그래프 유형 | 적용 시나리오 | 주요 Matplotlib 함수 | 일반적인 용도 |
|---|---|---|---|
| 막대 그래프 | 이산적 비교 | ax.bar() |
모델 성능 비교, 소거 실험 |
| 꺾은선 그래프 | 추세 변화 | ax.plot() |
학습 곡선, 수렴 분석 |
| 산점도 | 상관/클러스터링 | ax.scatter() |
특징 분포, 임베딩 시각화 |
| 히트맵 | 행렬 데이터 | sns.heatmap() |
혼동 행렬, 어텐션 가중치 |
| 레이더 차트 | 다차원 비교 | ax.plot() + polar |
모델 종합 평가 |
| 파이 차트 | 비율 구성 | ax.pie() |
데이터셋 분포 |
| 멀티 패널 그래프 | 복합 전시 | plt.subplots() |
Figure 1(a)(b)(c) 구성 |
💰 비용 최적화: APIYI(apiyi.com)를 통해 대규모 언어 모델로 Matplotlib 코드를 생성하면, 이미지 생성 모델을 사용하는 것보다 비용이 훨씬 저렴합니다. 약 50줄의 Matplotlib 코드를 생성하는 데 드는 비용은 약 $0.01에 불과하며, 생성된 코드는 API를 다시 호출할 필요 없이 반복해서 수정 및 실행이 가능합니다. 시각화 효과를 빠르게 확인하고 싶다면 온라인 도구인 Image.apiyi.com을 함께 사용해 보시는 것을 추천드려요.
Nano Banana Pro 연구 통계 그래프 퀵 스타트
간단한 예시: AI로 정확한 막대그래프 코드 생성하기
다음은 API를 통해 대규모 언어 모델을 호출하여, AI가 데이터에 기반해 Matplotlib 코드를 자동으로 생성하게 하는 가장 간단한 방법입니다.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # 使用 APIYI 统一接口
)
response = client.chat.completions.create(
model="gemini-2.5-flash",
messages=[{
"role": "user",
"content": """Generate publication-ready Python Matplotlib code for a grouped bar chart.
Data:
- Models: ['Method A', 'Method B', 'Method C', 'Ours']
- BLEU Score: [32.1, 35.4, 33.8, 38.7]
- ROUGE-L: [41.2, 43.8, 42.1, 47.3]
Requirements:
- Grouped bars with distinct colors (blue and green)
- Value labels on top of each bar
- Clean academic style, no top/right spines
- Title: 'Translation Quality Comparison'
- Save as PDF at 300 dpi
- Figsize: (8, 5)"""
}]
)
print(response.choices[0].message.content)
전체 연구 통계 그래프 코드 생성 도구 보기
import openai
from typing import Dict, List, Optional
def generate_chart_code(
chart_type: str,
data: Dict,
title: str,
style: str = "academic",
figsize: str = "(8, 5)",
save_format: str = "pdf"
) -> str:
"""
使用 AI 生成科研统计图的 Matplotlib 代码
Args:
chart_type: 图表类型 - bar/line/scatter/heatmap/radar/pie/multi-panel
data: 数据字典,包含标签和数值
title: 图表标题
style: 风格 - academic/minimal/detailed
figsize: 图表尺寸
save_format: 导出格式 - pdf/png/svg
Returns:
可执行的 Matplotlib Python 代码
"""
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # APIYI统一接口
)
style_guide = {
"academic": "Clean academic style: no top/right spines, "
"serif fonts, 300 dpi, tight layout",
"minimal": "Minimal style: grayscale-friendly, thin lines, "
"no grid, compact layout",
"detailed": "Detailed style: with grid, annotations, "
"error bars where applicable"
}
prompt = f"""Generate publication-ready Python Matplotlib code.
Chart type: {chart_type}
Data: {data}
Title: {title}
Style: {style_guide.get(style, style_guide['academic'])}
Figure size: {figsize}
Export: Save as {save_format} at 300 dpi
Requirements:
- All data values must be mathematically precise
- Include proper axis labels and legend
- Use colorblind-friendly palette
- Code must be executable without modification
- Add value annotations where appropriate"""
try:
response = client.chat.completions.create(
model="gemini-2.5-flash",
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 使用示例:生成模型性能对比柱状图
code = generate_chart_code(
chart_type="grouped_bar",
data={
"models": ["GPT-4o", "Claude 4", "Gemini 2", "Ours"],
"accuracy": [89.2, 91.5, 87.8, 93.1],
"f1_score": [87.5, 90.1, 86.3, 92.4]
},
title="Model Performance on SQuAD 2.0",
style="academic"
)
print(code)
🚀 빠른 시작: APIYI(apiyi.com) 플랫폼을 통해 AI 모델을 호출하여 연구 통계 그래프 코드를 생성하는 것을 추천해요. 이 플랫폼은 Gemini, Claude, GPT 등 다양한 모델을 지원하며, 모두 고품질의 Matplotlib 코드를 생성할 수 있습니다. 가입 시 무료 크레딧이 제공되어 5분 안에 첫 번째 통계 그래프 코드를 완성할 수 있습니다.
코드 생성 vs 이미지 생성: 연구 통계 그래프 품질 비교
왜 PaperBanana는 연구 통계 그래프 시나리오에서 Nano Banana Pro의 이미지 생성 기능을 포기하고 코드 생성 방식을 선택했을까요? 아래의 비교 데이터가 그 이유를 잘 보여줍니다.
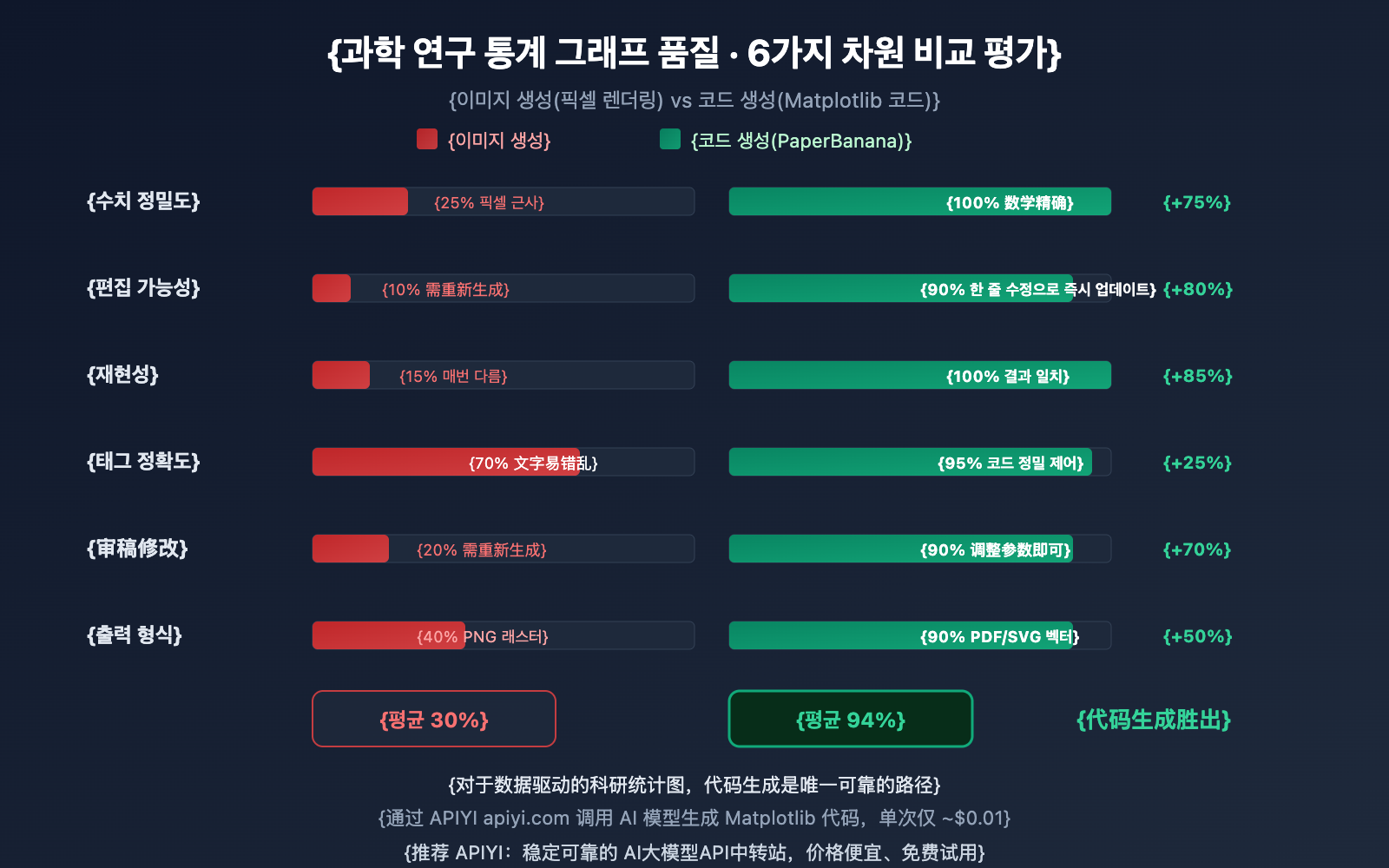
이미지 생성 방식의 문제점
Nano Banana Pro, DALL-E 3 또는 Midjourney를 사용하여 연구 통계 그래프를 직접 생성하면, 모델은 픽셀을 사용해 도표처럼 보이는 이미지를 '그려내려고' 시도합니다. 시각적인 효과는 좋을 수 있지만, 다음과 같은 문제는 거의 피하기 어렵습니다.
- 수치 불일치: 막대 높이와 실제 데이터 사이에 수학적 연결 고리가 없습니다.
- 편집 불가: 출력물이 래스터 이미지이므로 개별 데이터 포인트를 수정할 수 없습니다.
- 재현 불가: 코드를 다시 실행하여 완전히 동일한 그래프를 얻을 수 없습니다.
- 라벨 오류: 축 라벨에 오타가 발생하거나 수치가 잘못 표기되기 쉽습니다.
코드 생성 방식의 장점
PaperBanana의 코드 생성 방식은 완전히 다릅니다.
- 수학적 결합: 모든 시각적 요소가 코드 내의 수치에 의해 정밀하게 계산됩니다.
- 편집 가능: 코드 한 줄만 수정하면 색상, 라벨, 데이터를 바로 업데이트할 수 있습니다.
- 재현 가능: 동일한 코드를 어떤 환경에서 실행해도 결과가 완전히 일치합니다.
- 심사 대응 용이: 심사위원이 그래프 수정을 요청할 때 코드 파라미터만 조정하면 됩니다.
| 비교 항목 | 이미지 생성 (Nano Banana Pro 등) | 코드 생성 (PaperBanana 방식) |
|---|---|---|
| 수치 정확도 | 낮음: 픽셀 근사치, 환각 발생 가능 | 높음: 수학적 정밀함, 환각 없음 |
| 편집 가능성 | 없음: 래스터 이미지로 수정 불가 | 강함: 코드 수정으로 즉시 업데이트 |
| 재현성 | 낮음: 생성할 때마다 결과가 달라짐 | 높음: 코드 실행 결과가 항상 일관됨 |
| 라벨 정확도 | 중간: 약 78~94%의 텍스트 정확도 | 높음: 코드로 텍스트 정밀 제어 |
| 심사평 수정 | 전체 이미지를 다시 생성해야 함 | 파라미터 조정 후 재실행 |
| 출력 형식 | PNG/JPG 래스터 이미지 | PDF/SVG/EPS 벡터 그래픽 |
🎯 선택 가이드: 정확한 수치 표현이 필요한 연구 통계 그래프(막대그래프, 꺾은선 그래프, 산점도 등)에는 코드 생성 방식을 강력히 추천해요. 만약 그래프가 시각적 개념 위주(방법론 도식, 아키텍처 다이어그램)라면 Nano Banana Pro의 이미지 생성 기능이 더 적합합니다. APIYI(apiyi.com) 플랫폼을 통해 이미지 생성 모델과 텍스트 생성 모델을 동시에 호출하며 유연하게 활용해 보세요.
Nano Banana Pro 연구용 통계 차트 프롬프트(Prompt) 엔지니어링 팁
AI가 고품질 Matplotlib 코드를 생성하게 만드는 핵심은 프롬프트의 구조화 정도에 달려 있습니다. 여기 검증된 5가지 핵심 팁을 소개합니다.
팁 1: 데이터는 반드시 명시적으로 제공하세요
AI가 데이터를 "지어내게" 두지 마세요. 프롬프트에 라벨, 수치, 단위를 포함한 전체 데이터 값을 명확하게 제공해야 합니다.
✅ 올바른 예: Data: models=['A','B','C'], accuracy=[89.2, 91.5, 87.8]
❌ 잘못된 예: Generate a bar chart comparing three models
팁 2: 학술적 스타일 제약 조건을 지정하세요
학술 논문용 차트에는 엄격한 레이아웃 요구 사항이 있습니다. 프롬프트에 다음과 같은 제약 조건을 명시해 보세요.
- 상단 및 우측 테두리 제거 (
spines['top'].set_visible(False)) - 폰트 크기 계층: 제목 14pt, 축 라벨 12pt, 눈금 10pt
- 색맹 친화적 배색 (적록 색약 고려)
- 300+ dpi의 PDF/EPS 형식 출력
팁 3: 수치 레이블 추가를 요청하세요
막대그래프 상단에 정확한 수치 레이블을 추가하면, 독자가 축을 일일이 대조하지 않고도 데이터를 바로 읽을 수 있어요. 이는 '시각적 모호함'을 제거하는 중요한 수단이기도 합니다.
팁 4: 실행 가능성을 명시하세요
생성된 코드가 '수정 없이 바로 실행'될 수 있도록 명확히 요구하세요. 이렇게 하면 AI가 필요한 모든 import 문, 데이터 정의, 저장 명령을 빠짐없이 포함하게 됩니다.
팁 5: 심사위원 수정 요청에 대비해 유연성을 확보하세요
AI에게 데이터 정의와 스타일 파라미터를 코드 상단에 따로 분리해서 배치해 달라고 요청하세요. 그러면 나중에 수정 요청이 들어왔을 때 빠르게 대응할 수 있어 효율적입니다.
| 팁 | 핵심 요점 | 코드 품질에 미치는 영향 |
|---|---|---|
| 1 | 데이터 명시 | 데이터 조작 방지 및 정확성 확보 |
| 2 | 학술 스타일 제약 | 저널 레이아웃 요구 사항 충족 |
| 3 | 수치 레이블 | 차트 가독성 향상 |
| 4 | 실행 가능성 | 즉시 사용 가능한 코드 생성 |
| 5 | 파라미터 분리 | 수정 및 편집 효율 극대화 |
🎯 실전 제안: 위 5가지 팁을 조합해 나만의 표준 프롬프트 템플릿을 만들어 보세요. **APIYI(apiyi.com)**를 통해 다양한 모델을 호출하며 반복 테스트하면 연구 분야에 가장 적합한 코드 스타일을 찾을 수 있습니다. 이 플랫폼은 Gemini, Claude, GPT 등 여러 모델 전환을 지원하여 생성 효과를 비교하기에 매우 편리합니다.
자주 묻는 질문 (FAQ)
Q1: PaperBanana의 코드 생성 방식이 이미지 생성보다 느린가요?
오히려 그 반대예요. 코드 생성은 보통 더 빠릅니다. 5080행의 Matplotlib 코드를 생성하는 데 25초면 충분하지만, 이미지는 10~30초가 걸리죠. 더 중요한 건, 생성된 코드는 로컬에서 실행하고 반복 수정할 수 있어 매번 API를 호출할 필요가 없다는 점입니다. **APIYI(apiyi.com)**를 통해 모델을 호출해 코드를 생성하면 1회 비용이 약 $0.01로, 이미지 생성($0.05)보다 훨씬 경제적입니다.
Q2: 생성된 Matplotlib 코드의 품질은 어떤가요? 수정을 많이 해야 하나요?
PaperBanana의 240개 ChartMimic 벤치마크 테스트 결과, 생성된 Python 코드는 모두 즉시 실행 가능했으며 시각적 결과물도 원본 설명과 일치했습니다. 실제 사용 시에는 배색이나 폰트 같은 스타일 파라미터만 살짝 조정하면 되는 수준이에요. 코드 생성 품질이 뛰어난 Claude나 Gemini 모델을 APIYI(apiyi.com) 플랫폼에서 호출해 사용하는 것을 추천합니다. 온라인 도구인 Image.apiyi.com에서도 효과를 빠르게 미리 볼 수 있습니다.
Q3: AI로 연구용 통계 차트 코드를 생성하려면 어떻게 시작해야 하나요?
다음 단계를 따라 빠르게 시작해 보세요:
- **APIYI(apiyi.com)**에 접속해 계정을 만들고 API 키와 무료 테스트 크레딧을 받으세요.
- 실험 데이터(모델 이름, 지표 수치 등)를 준비합니다.
- 본문의 프롬프트 템플릿을 사용해 데이터를 실제 값으로 바꿉니다.
- API를 호출해 Matplotlib 코드를 생성하고 로컬에서 실행해 결과를 확인합니다.
- 저널 요구 사항에 맞춰 스타일을 미세 조정한 후 PDF로 내보냅니다.
요약
Nano Banana Pro의 연구용 통계 그래프 코드 생성 방식의 핵심 요점은 다음과 같습니다.
- 픽셀보다 코드가 우선입니다: PaperBanana는 연구용 통계 그래프를 이미지 렌더링 방식이 아닌 Matplotlib 코드로 생성하여, 수치적 환각(Numerical Hallucination)을 근본적으로 제거합니다.
- 7가지 차트 유형 완벽 지원: 막대 그래프, 꺾은선 그래프, 산점도, 히트맵, 레이더 차트, 파이 차트, 멀티 패널 차트 등 논문 데이터 시각화에 필요한 모든 요구사항을 충족합니다.
- 편집 및 재현 가능: 출력된 코드는 자유로운 수정과 정확한 재현을 지원합니다. 논문 수정 시 이미지를 다시 생성할 필요 없이 파라미터만 조정하면 됩니다.
- 5가지 프롬프트 팁: 명시적 데이터 제공, 학술적 제약 조건 설정, 수치 레이블 표시, 실행 가능성 확인, 파라미터 분리를 통해 고품질의 실행 가능한 코드를 확보할 수 있습니다.
연구용 통계 그래프의 정밀함이 요구되는 상황에서 '코드가 곧 그래프'라는 접근 방식은 유일하게 신뢰할 수 있는 길입니다. AI를 통해 Matplotlib 코드를 생성하면 AI의 효율성을 누리면서도 코드의 정확성을 유지할 수 있는 일거양득의 효과를 얻을 수 있습니다.
APIYI(apiyi.com)를 통해 AI 보조 연구용 통계 그래프 코드 생성을 빠르게 경험해 보세요. 플랫폼에서 무료 크레딧과 다양한 모델 선택권을 제공합니다. 온라인 도구인 Image.apiyi.com에서 결과물을 미리 확인해 볼 수도 있습니다.
📚 참고 자료
⚠️ 링크 형식 안내: 모든 외부 링크는 복사가 용이하도록
자료명: domain.com형식을 사용하며, SEO 권위 분산을 방지하기 위해 클릭 이동은 지원하지 않습니다.
-
PaperBanana 프로젝트 홈페이지: 논문과 데모가 포함된 공식 발표 페이지
- 링크:
dwzhu-pku.github.io/PaperBanana/ - 설명: PaperBanana 통계 그래프 코드 생성의 핵심 원리와 평가 데이터를 확인할 수 있습니다.
- 링크:
-
PaperBanana 논문: arXiv 프리프린트 전문
- 링크:
arxiv.org/abs/2601.23265 - 설명: 코드 생성 vs 이미지 생성의 기술적 선택과 ChartMimic 벤치마크 테스트에 대해 깊이 있게 이해할 수 있습니다.
- 링크:
-
Matplotlib 공식 문서: Python 데이터 시각화 라이브러리
- 링크:
matplotlib.org/stable/ - 설명: AI가 생성한 그래프 코드를 이해하고 수정하기 위한 Matplotlib API 참고 자료입니다.
- 링크:
-
Nano Banana Pro 공식 문서: Google DeepMind 모델 소개
- 링크:
deepmind.google/models/gemini-image/pro/ - 설명: 방법론 도식화 시나리오에서 Nano Banana Pro의 이미지 생성 능력을 확인할 수 있습니다.
- 링크:
-
APIYI 온라인 이미지 생성 도구: 코드 없이 차트 미리보기
- 링크:
Image.apiyi.com - 설명: AI가 생성하는 연구용 통계 그래프의 효과를 빠르게 미리 볼 수 있습니다.
- 링크:
작성자: APIYI Team
기술 교류: 댓글을 통해 여러분만의 연구용 통계 그래프 프롬프트 템플릿이나 Matplotlib 팁을 공유해 주세요. 더 많은 AI 모델 정보는 APIYI(apiyi.com) 기술 커뮤니티에서 확인하실 수 있습니다.