ملاحظة المؤلف: قراءة متعمقة في Qwen-Image-2.0، النموذج الموحد لتوليد الصور وتحريرها، مع تسليط الضوء على 5 ابتكارات تقنية رئيسية تشمل بنية 7B خفيفة الوزن، ودقة 2K أصلية، وموجهات طويلة تصل إلى 1000 توكن، بالإضافة إلى دليل استخدام API والتشغيل العملي.
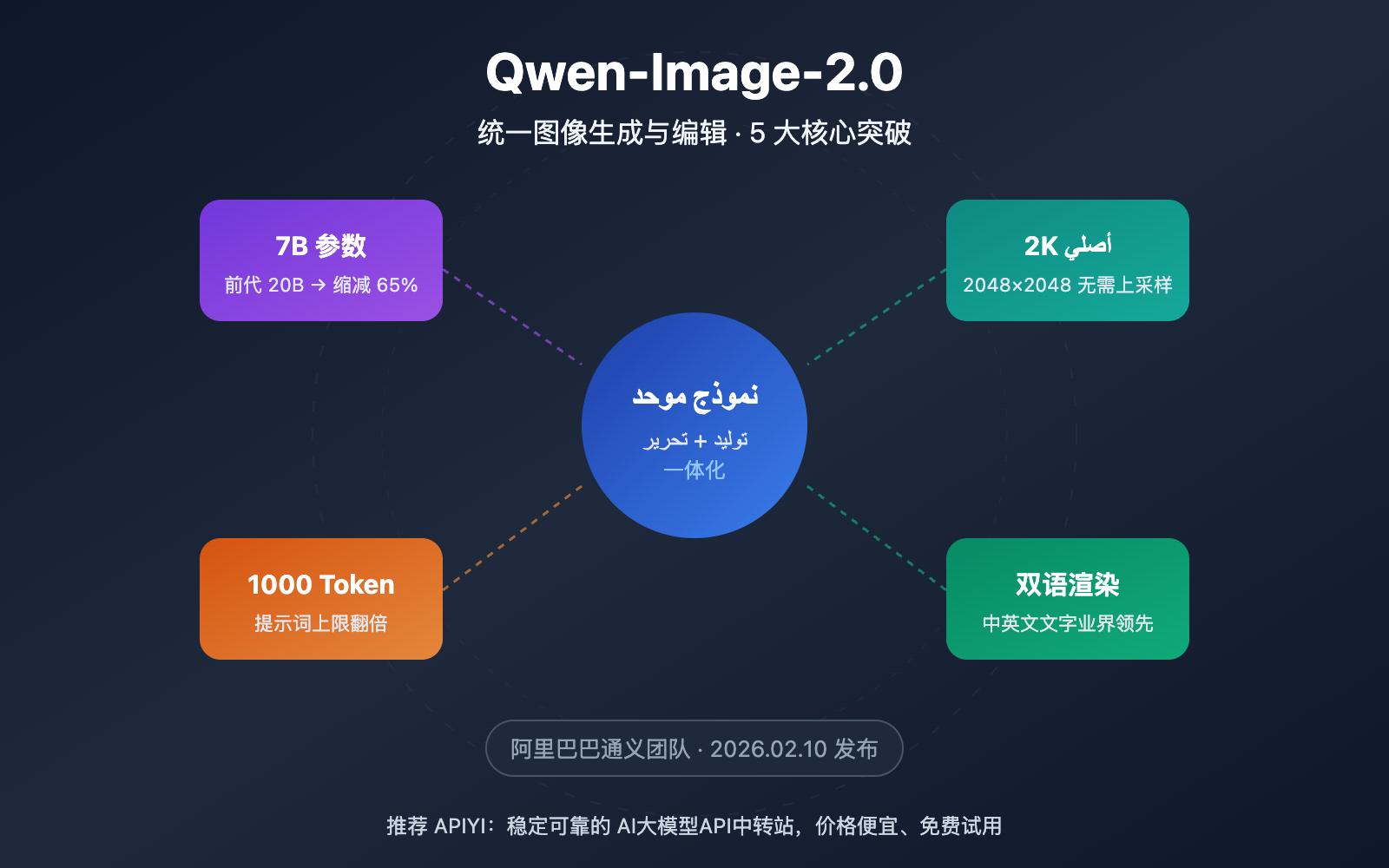
أطلق فريق Tongyi التابع لشركة Alibaba في 10 فبراير 2026 نموذج Qwen-Image-2.0، وهو تحديث رئيسي يدمج توليد الصور وتحريرها في نموذج واحد. المثير للإعجاب هو تقليص عدد المعلمات من 20B في الجيل السابق إلى 7B فقط، مع تحقيق تحسن شامل في الأداء. تعمل APIYI حالياً، بصفتها شريكاً معتمداً لـ Alibaba Cloud، على دمج النموذج وتوفيره قريباً، مع ميزات تنافسية في السعر وسرعة الوصول.
القيمة الجوهرية: من خلال هذه القراءة المتعمقة، ستتعرف على الابتكارات الخمسة الكبرى في Qwen-Image-2.0، والاختلافات الحقيقية بينه وبين المنافسين، وكيفية البدء باستخدامه عبر API.
نظرة سريعة على الميزات الرئيسية لـ Qwen-Image-2.0
| الميزة | الوصف | القيمة |
|---|---|---|
| توليد وتحرير موحد | دمج تحويل النص إلى صورة وتحرير الصور في نموذج 7B واحد | لا حاجة لتحميل نموذجين منفصلين، مما يقلل تكاليف النشر بشكل كبير |
| تقليص المعلمات بنسبة 65% | تم تقليص الحجم من 20B إلى 7B (مفكك الانتشار) | سرعة استدلال أعلى ومتطلبات أقل لذاكرة الرسوميات (VRAM) |
| دقة 2K أصلية | يدعم مخرجات أصلية تصل إلى 2048×2048 | تفاصيل أكثر وضوحاً دون الحاجة لتقنيات زيادة العينة (Upsampling) |
| موجه بطول 1000 Token | مضاعفة الحد الأقصى للموجهات (كان حوالي 500 في الجيل السابق) | دعم أوصاف المشاهد المعقدة والتحكم الدقيق |
| عرض نصوص ثنائية اللغة | ريادة في توليد النصوص باللغتين الصينية والإنجليزية | نتائج مذهلة في تصميم الملصقات والرسوم البيانية التي تحتوي على نصوص |
التحليل التقني لنموذج Qwen-Image-2.0
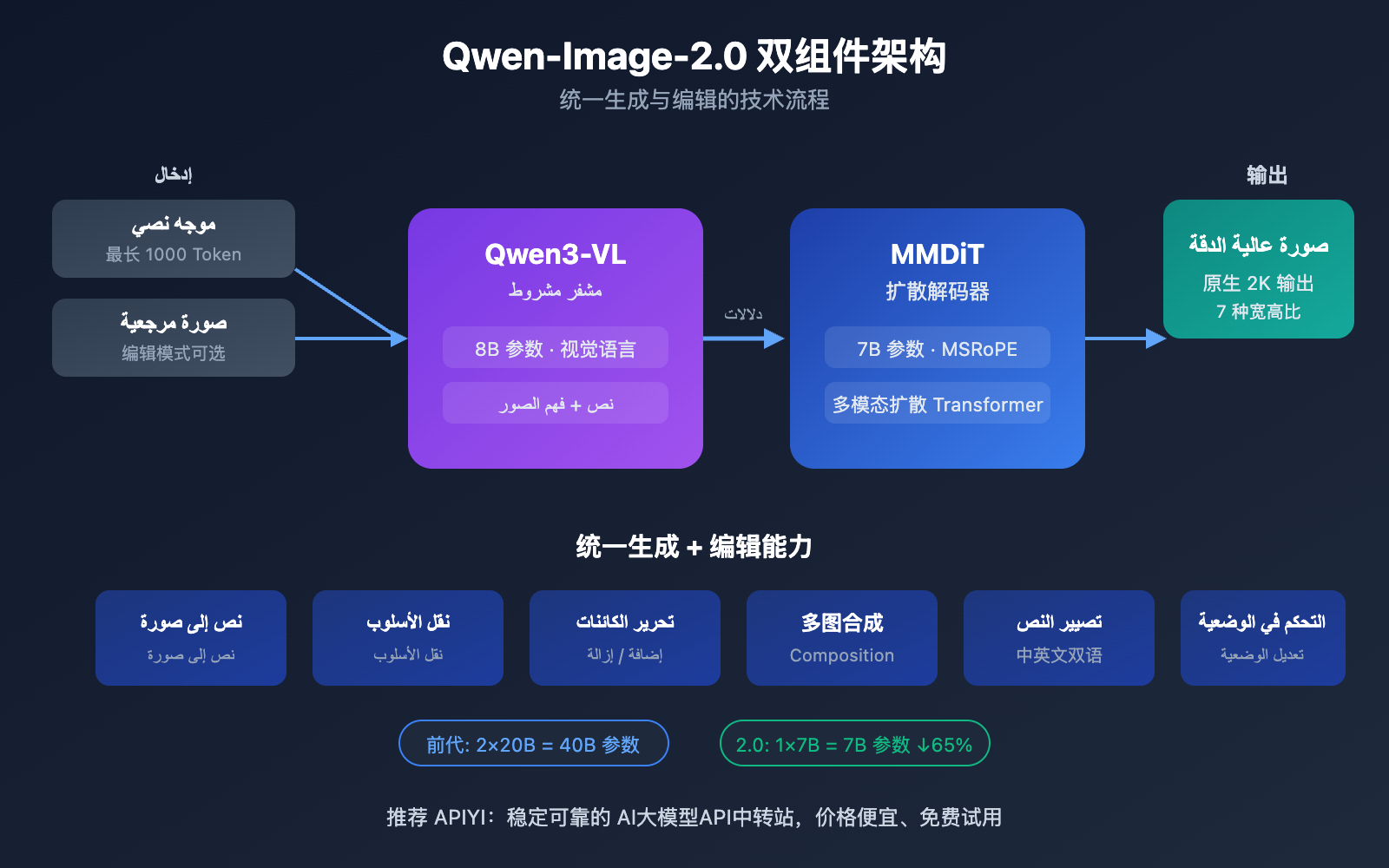
يعتمد Qwen-Image-2.0 بنية مبتكرة مكونة من جزأين رئيسيين: نموذج لغة كبير للرؤية Qwen3-VL بـ 8B معلمات يعمل كمشفر للشروط (Condition Encoder)، ومحول انتشار متعدد الوسائط (MMDiT) بـ 7B معلمات يعمل كمفكك للانتشار (Diffusion Decoder). يتيح هذا التصميم للموذج فهم المعاني الدلالية للنصوص والصور بعمق، ثم توليد صور عالية الجودة عبر عملية الانتشار.
الاختلاف الأبرز عن الجيل السابق Qwen-Image-2512 هو استراتيجية التدريب الموحدة، حيث تم دمج مهام تحويل النص إلى صورة (T2I) وتحرير الصور (I2I/TI2I) في عملية انتشار أمامي واحدة. هذا يعني أن نموذجاً واحداً يمكنه الآن القيام بما كان يتطلب سابقاً نموذجين مستقلين (Qwen-Image للتوليد و Qwen-Image-Edit للتحرير)، مما يقلل من تعقيد وتكلفة النشر بشكل ملحوظ.
شرح مفصل للاختراقات الخمسة الأساسية في Qwen-Image-2.0
الاختراق الأول: بنية موحدة للتوليد والتحرير
هذا هو الابتكار الأبرز في Qwen-Image-2.0. في الأجيال السابقة، كان من الضروري صيانة نموذج لتحويل النص إلى صورة ونموذج آخر لتحرير الصور بشكل منفصل، أما الإصدار 2.0 فقد دمج الاثنين في نموذج واحد:
| القدرة | الحل في الجيل السابق | Qwen-Image-2.0 |
|---|---|---|
| تحويل النص إلى صورة | Qwen-Image-2512 (بـ 20 مليار بارامتر) | نموذج موحد (بـ 7 مليار بارامتر) |
| تحرير الصور | Qwen-Image-Edit-2511 (بـ 20 مليار بارامتر) | نموذج موحد (بـ 7 مليار بارامتر) |
| نقل النمط (Style Transfer) | يعالج بواسطة نموذج التحرير بشكل منفصل | مدعوم مباشرة في النموذج الموحد |
| دمج صور متعددة | يعالج بواسطة نموذج التحرير بشكل منفصل | مدعوم مباشرة في النموذج الموحد |
| إجمالي ذاكرة الفيديو (VRAM) | يتطلب تحميل نموذجين بسعة 20B لكل منهما | يتطلب نموذجاً واحداً فقط بسعة 7B |
في الاستخدام الفعلي، يمكنك البدء بتوليد صورة من نص، ثم إجراء عمليات تحرير مباشرة على نفس الصورة مثل نقل النمط، إضافة أو حذف عناصر، أو تعديل الوضعيات—كل ذلك دون الحاجة لتبديل النماذج.
الاختراق الثاني: تفوق في الأداء بـ 7 مليار بارامتر فقط
على الرغم من تقليص عدد البارامترات من 20 مليار إلى 7 مليار (في مفكك شفرة الانتشار – Diffusion Decoder)، أي بنسبة خفض تصل إلى 65%، إلا أن جودة الصور لم تنخفض بل تحسنت. السر وراء ذلك يكمن في قدرات الفهم الدلالي العميق لمشفّر Qwen3-VL؛ حيث يتولى نموذج اللغة البصري ذو الـ 8 مليار بارامتر عبئاً أكبر في مرحلة "فهم المتطلبات"، مما يسمح لمفكك شفرة الانتشار بالتركيز بكفاءة أعلى على "توليد الصورة".
بالنسبة للمطورين، هذا يعني:
- زيادة سرعة الاستنتاج: يستغرق استدعاء API حوالي 5-8 ثوانٍ لكل صورة.
- انخفاض متطلبات ذاكرة الفيديو: من المتوقع أن يعمل النموذج بذاكرة فيديو سعة 24 جيجابايت (بينما كان الجيل السابق يتطلب أكثر من 48 جيجابايت).
- تقليل تكاليف النشر: إمكانية تشغيل النموذج على بطاقات رسومية (GPU) من الفئة الاستهلاكية.
الاختراق الثالث: دقة 2K أصلية (Native)
يدعم Qwen-Image-2.0 مخرجات بدقة 2048×2048 بشكل أصلي، دون الحاجة لخطوات إضافية لرفع الدقة (Super-resolution). كما يدعم 7 نسب عرض إلى ارتفاع قياسية:
| نسبة العرض إلى الارتفاع | الدقة | الاستخدامات الموصى بها |
|---|---|---|
| 16:9 | 1664×928 | أغلفة الفيديو، صور المدونات (افتراضي) |
| 1:1 | 1328×1328 | صور الملفات الشخصية، صور المنتجات الأساسية |
| 9:16 | 928×1664 | خلفيات الهاتف، أغلفة الفيديوهات القصيرة |
| 4:3 | 1472×1104 | العرض التقليدي بالشاشة العريضة |
| 3:4 | 1104×1472 | العرض التقليدي بالشاشة الطولية |
| 3:2 | 1584×1056 | الصور الفوتوغرافية العريضة |
| 2:3 | 1056×1584 | الصور الفوتوغرافية الطولية |
الاختراق الرابع: موجه (Prompt) طويل يصل إلى 1000 توكن
تم رفع الحد الأقصى للموجهات من حوالي 500 توكن في الجيل السابق إلى 1000 توكن، وهذه المساحة المضاعفة تتيح لك وصف مشاهد أكثر تعقيداً. في الاختبارات الفعلية، أثبت هذا الأمر قيمته الكبيرة في الحالات التالية:
- الرسوم البيانية الاحترافية: التحكم الدقيق في مواقع التنسيق، محتوى النصوص، وتناسق الألوان.
- المشاهد متعددة العناصر: وصف العلاقات المكانية وتفاصيل التفاعل بين عدة عناصر في وقت واحد.
- دمج الأنماط: وصف دقيق للنمط الفني المطلوب ومتطلبات الملمس (Texture).
الاختراق الخامس: ريادة في عرض النصوص ثنائية اللغة
تعتبر قدرة Qwen-Image-2.0 على توليد النصوص داخل الصور رائدة في هذا المجال، خاصة في عرض اللغة الصينية—حيث يدعم أنماط خطوط متنوعة مثل خط "كاي" (Kai)، و"شو جين" (Shoujin)، و"شياو تشوان" (Seal script). وهذا يمنحه ميزة واضحة في:
- تصميم بوسترات التسويق والصور الدعائية.
- المخططات التقنية التي تحتوي على ملاحظات باللغة الصينية.
- محتوى الصور والنصوص لمنصات التواصل الاجتماعي.
- توليد المواد البصرية للهوية التجارية.
🎯 نصيحة عملية: Qwen-Image-2.0 حالياً في مرحلة الاختبار التجريبي عبر API. تعمل منصة APIYI (apiyi.com) بنشاط على توفير الوصول إليه، حيث ستوفر أسعاراً مخفضة تقل بنسبة 20% عن الموقع الرسمي، مع دعم الاستدعاء الموحد بتنسيق متوافق مع OpenAI. ابقوا مترقبين.
البدء السريع مع Qwen-Image-2.0
مثال مبسط
فيما يلي الطريقة الأساسية لتوليد صورة عبر استدعاء API لنموذج Qwen-Image-2.0 (بناءً على تنسيق DashScope API):
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen-image-2.0",
messages=[{
"role": "user",
"content": "كلب شيبا إينو يرتدي نظارات شمسية ويركب الأمواج على الشاطئ، الشمس مشرقة، نمط تصوير فوتوغرافي عالي الدقة"
}]
)
print(response.choices[0].message.content)
عرض مثال استدعاء API الأصلي لـ DashScope
from dashscope import MultiModalConversation
import os
response = MultiModalConversation.call(
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen-image-max",
messages=[{
"role": "user",
"content": [{
"text": "مكتب عمل عصري وبسيط، عليه كمبيوتر محمول ونباتات خضراء، إضاءة طبيعية ناعمة"
}]
}],
size="1328*1328",
prompt_extend=True,
watermark=False
)
image_url = response.output.choices[0].message.content[0]["image"]
print(f"رابط الصورة: {image_url}")
# ملاحظة: الرابط صالح لمدة 24 ساعة، يرجى تحميل الصورة وحفظها فوراً
نصيحة: منصة APIYI (apiyi.com) بصدد إتاحة Qwen-Image-2.0، وستدعم حينها الاستدعاء بتنسيق متوافق مع OpenAI، مما يتيح لك باستخدام مفتاح API واحد مقارنة واختبار عدة نماذج لتوليد الصور مثل GPT Image 1.5 و Gemini 3 Pro Image و FLUX.2 وغيرها.
مقارنة Qwen-Image-2.0 مع المنافسين
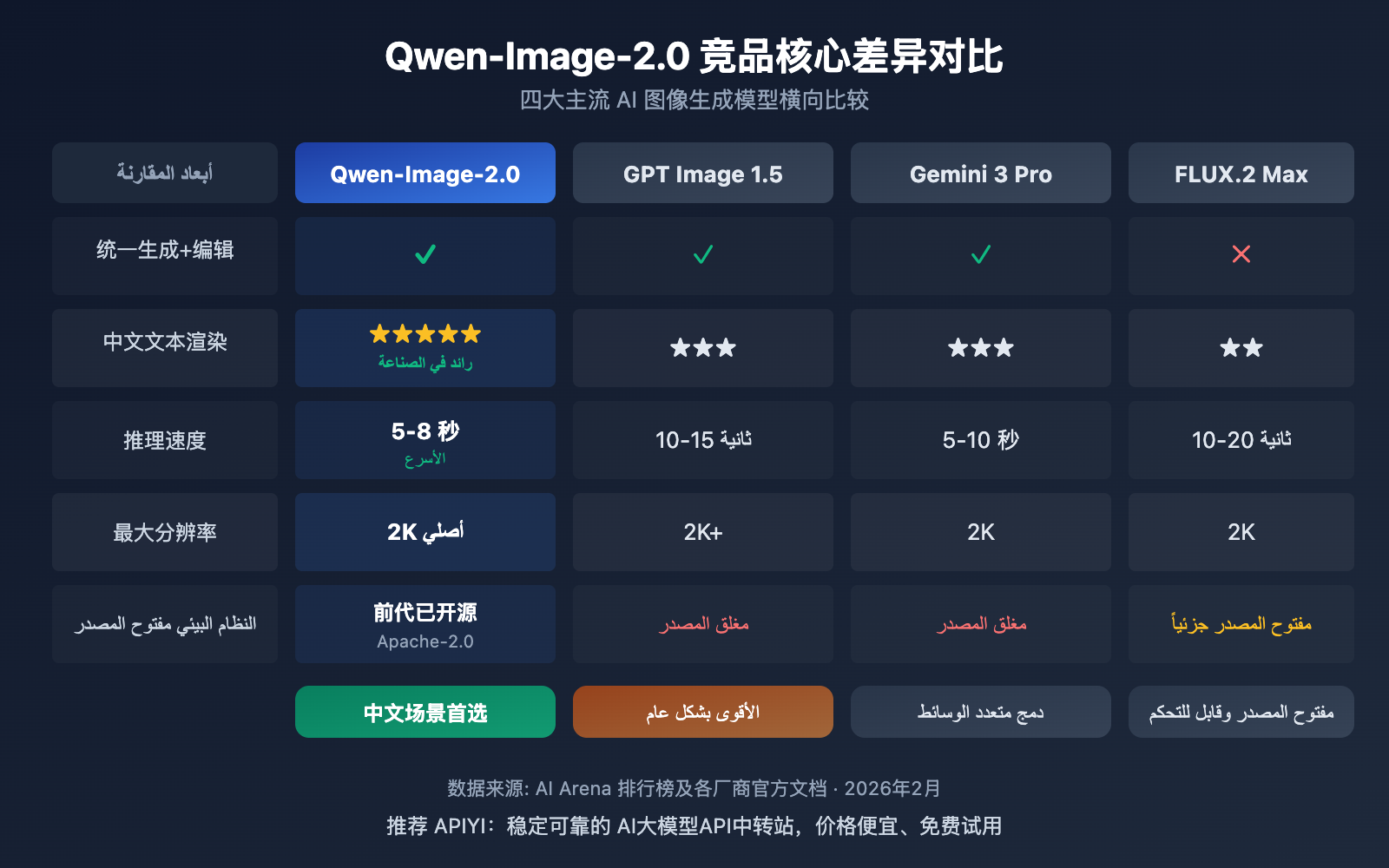
| وجه المقارنة | Qwen-Image-2.0 | GPT Image 1.5 | Gemini 3 Pro Image | FLUX.2 Max |
|---|---|---|---|---|
| المطور | علي بابا | OpenAI | Black Forest Labs | |
| توليد وتحرير موحد | ✅ | ✅ | ✅ | ❌ |
| أقصى دقة | 2K | 2K+ | 2K | 2K |
| رندرة النصوص الصينية | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
| سرعة الاستدلال | 5-8 ثوانٍ | 10-15 ثانية | 5-10 ثوانٍ | 10-20 ثانية |
| النظام البيئي المفتوح | الجيل السابق مفتوح المصدر | مغلق المصدر | مغلق المصدر | مفتوح جزئياً |
| مرجع تسعير API | أقل من 80% من السعر الرسمي (عبر APIYI) | $0.04-0.08/صورة | المحاسبة حسب التوكن (Token) | $0.04/صورة |
المزايا التنافسية لنموذج Qwen-Image-2.0:
- الأقوى في السيناريوهات الصينية: قدرات رندرة النصوص ثنائية اللغة رائدة في الصناعة، وتتفوق نتائج الملصقات والرسوم البيانية الصينية بشكل ملحوظ على المنافسين.
- البنية الأكثر خفة: يحقق جودة تضاهي GPT Image 1.5 بـ 7 مليار (7B) بارامتر فقط، مما يقلل من تكاليف الاستدلال.
- إمكانات المصدر المفتوح: السلسلة السابقة بالكامل مفتوحة المصدر بترخيص Apache-2.0، ومن المتوقع فتح مصدر الإصدار 2.0 قريباً.
- نظام بيئي غني: أكثر من 2,380 إعجاب على HuggingFace، وأكثر من 484 محول LoRA، مع مجتمع نشط للغاية.
ملاحظة حول المقارنة: البيانات أعلاه مستمدة من الوثائق التقنية العامة وتصنيفات AI Arena. نوصي بإجراء اختبارات فعلية عبر منصة APIYI apiyi.com لمقارنة أداء كل نموذج في سيناريوهاتك الخاصة.
حالات الاستخدام الموصى بها لنموذج Qwen-Image-2.0
هذا النموذج مثالي للاستخدام في السيناريوهات التالية:
- صور منتجات التجارة الإلكترونية: نموذج موحد لإتمام عملية إنشاء صور المنتجات واستبدال الخلفيات، مما يسهل سير العمل بشكل كبير. مثالي لفرق التصميم وإدارة العمليات في التجارة الإلكترونية.
- تصميم المواد التسويقية: الملصقات، صور وسائل التواصل الاجتماعي، والمواد الإعلانية؛ حيث تعد القدرة القوية على معالجة النصوص الصينية ميزة تنافسية جوهرية. مناسب لفرق التسويق.
- التصميم الإبداعي: يدعم أنماطاً فنية متنوعة مثل الواقعية، والأنمي، والألوان المائية، والرسم اليدوي، مع إمكانية استخدام موجه طويل يصل إلى 1000 توكن للتحكم الدقيق في التوجه الإبداعي. مثالي للمصممين ومنشئي المحتوى.
- إنشاء الرسوم البيانية التقنية: صفحات العروض التقديمية (PPT)، الإنفوجرافيك، والمخططات الانسيابية وغيرها من المحتويات الاحترافية، مع تنسيق دقيق على مستوى البكسل. مناسب لفرق التوثيق التقني.
🎯 نصيحة حول السيناريوهات: إذا كان عملك يتضمن إنشاء كميات كبيرة من المحتوى الذي يجمع بين النصوص الصينية والصور، فإن Qwen-Image-2.0 هو الخيار الأبرز حالياً. نوصي بإجراء اختبارات مقارنة عملية عبر منصة APIYI (apiyi.com) للعثور على الحل الأنسب لاحتياجات عملك.
تطور إصدارات Qwen-Image-2.0 والتسعير
الجدول الزمني لتطور الإصدارات
منذ إطلاق الإصدار الأول من سلسلة Qwen-Image في أغسطس 2025، حافظت السلسلة على وتيرة تحديث سريعة:
| الإصدار | الوقت | الترقيات الجوهرية |
|---|---|---|
| Qwen-Image v1 | 2025.08 | الإطلاق الأول لـ 20B MMDiT، مفتوح المصدر بترخيص Apache-2.0 |
| Qwen-Image-Edit | 2025.08 | إضافة نموذج تحرير مخصص |
| Qwen-Image-2512 | 2025.12 | تحسين الأنسجة الواقعية ومعالجة النصوص |
| Qwen-Image-2.0 | 2026.02 | بنية موحدة، نسخة خفيفة 7B، دقة 2K أصلية |
مرجع التسعير
| القناة/المزود | النموذج | السعر المرجعي |
|---|---|---|
| Alibaba Cloud DashScope | qwen-image-max | 0.50 يوان / صورة |
| Alibaba Cloud DashScope | qwen-image-plus | 0.20 يوان / صورة |
| Replicate | Qwen Image | 0.030 دولار / صورة |
| Fal.ai | Qwen Image Edit | 0.021 دولار / صورة |
| APIYI (قريباً) | Qwen-Image-2.0 | خصم أكثر من 20% عن السعر الرسمي |
💡 لم يتم الإعلان بعد عن التسعير الرسمي لنسخة Qwen-Image-2.0 النهائية. تعمل منصة APIYI (apiyi.com) حالياً على دمج النموذج، وستوفر أسعاراً مخفضة تقل بنسبة 20% عن الموقع الرسمي. سجل الآن للحصول على رصيد اختبار مجاني، ترقبوا الإطلاق.
الأسئلة الشائعة
س1: ما الفرق بين Qwen-Image-2.0 و Qwen-Image-2512؟
الفرق الأكبر هو أن إصدار 2.0 يجمع بين التوليد والتحرير في نموذج واحد بمعلمات 7B، بينما كان الإصدار السابق 2512 عبارة عن نموذج لغة كبير لتوليد الصور من النصوص فقط بمعلمات 20B، وكان تحرير الصور يتطلب تحميل Qwen-Image-Edit بشكل منفصل. كما يدعم إصدار 2.0 دقة 2K أصلية و موجه طويل يصل إلى 1000 توكن (token)، مع تحسينات ملحوظة في جودة الصورة ومعالجة النصوص.
س2: هل يمكن استخدام Qwen-Image-2.0 عبر واجهة برمجة التطبيقات (API) حالياً؟
هو حالياً في مرحلة الاختبار التجريبي عبر الدعوات، ويمكن تجربته مجاناً عبر الإنترنت من خلال chat.qwen.ai. وتعمل منصة APIYI (apiyi.com) حالياً على دمج النموذج، وستوفر عند إطلاقه سعراً أقل بنسبة 20% من السعر الرسمي، مع دعم التوافق مع تنسيق OpenAI، مما يتيح لك مقارنة عدة نماذج لتوليد الصور باستخدام مفتاح (Key) واحد فقط.
س3: هل يصلح Qwen-Image-2.0 للنشر المحلي (Local Deployment)؟
أوزان Qwen-Image-2.0 لم تُفتح بعد كمصدر مفتوح. ولكن بناءً على سابقة الإصدارات السابقة التي كانت مفتوحة المصدر بالكامل تحت رخصة Apache-2.0، يتوقع المجتمع أن يتم فتح إصدار 2.0 أيضاً. حجم المعلمات (7B) يعني إمكانية تشغيله على وحدات معالجة الرسومات الاستهلاكية (بذاكرة فيديو 24 جيجابايت). وأثناء انتظار فتحه كمصدر مفتوح، نوصي بالتحقق من النتائج بسرعة عبر واجهة برمجة التطبيقات من خلال APIYI (apiyi.com).
ملخص
النقاط الأساسية لنموذج Qwen-Image-2.0:
- البنية الموحدة هي الميزة الأبرز: نموذج واحد 7B يقوم بالتوليد والتحرير معاً، بينما كان الإصدار السابق يتطلب نموذجين 20B.
- خفة الوزن دون التضحية بالجودة: تقليل المعلمات بنسبة 65% مع تحسين شامل في جودة الصور ونطاق الوظائف.
- لا بديل عنه في المحتوى الصيني: يدعم معالجة النصوص ثنائية اللغة، وتعدد الخطوط، وهو الخيار الأول لتوليد محتوى الصور والنصوص باللغة الصينية.
- الوصول عبر API سيفتح قريباً: حالياً في مرحلة الاختبار، والنسخة الرسمية متوقعة قريباً.
يمثل Qwen-Image-2.0 طفرة هامة في نماذج توليد الصور بالذكاء الاصطناعي. بالنسبة للفرق التي تحتاج إلى محتوى صور ونصوص صينية عالية الجودة، يعد هذا أحد أكثر النماذج التي تستحق المتابعة حالياً.
نوصي بمتابعة منصة APIYI (apiyi.com) للحصول على آخر تحديثات الوصول وأسعار مخفضة (أقل بنسبة 20% من السعر الرسمي)، حيث توفر المنصة رصيداً مجانياً وواجهة موحدة لنماذج متعددة لتسهيل المقارنة والتحقق السريع.
📚 المراجع
-
مدونة Qwen الرسمية: إعلان إطلاق Qwen-Image-2.0
- الرابط:
qwen.ai/blog?id=qwen-image-2.0 - الوصف: التفسير التقني الرسمي وعرض الميزات
- الرابط:
-
مستودع GitHub: الصفحة الرئيسية لمشروع Qwen-Image
- الرابط:
github.com/QwenLM/Qwen-Image - الوصف: الكود المصدري المفتوح، الوثائق التقنية، ودليل الاستخدام
- الرابط:
-
لوحة صدارة AI Arena: تصنيفات تحويل النص إلى صورة وتحرير الصور
- الرابط:
arena.ai/leaderboard/text-to-image - الوصف: تصنيفات تقييم مستقلة من جهات خارجية، مع تحديث البيانات في الوقت الفعلي
- الرابط:
-
وثائق API علي بابا كلاود: واجهة DashScope لتوليد الصور
- الرابط:
help.aliyun.com/zh/model-studio/qwen-image-api - الوصف: وثائق الوصول الرسمية لواجهة البرمجة وشرح المعاملات (Parameters)
- الرابط:
المؤلف: الفريق التقني
التبادل التقني: نرحب بمناقشاتكم في قسم التعليقات. لمزيد من المصادر، يمكنكم زيارة مجتمع APIYI التقني عبر apiyi.com