2026年1月21日午後18:00(北京時間)、多くの開発者からNano Banana Pro APIの呼び出しがタイムアウトし続けているとの報告があり、4K解像度のリクエスト失敗率が急上昇しました。本記事では、この障害の全容を振り返り、根本原因の分析と、3つの実用的な応急対策を提案します。
コアバリュー: Google Imagen APIの実際の安定性の現状を理解し、障害発生時の応急処置方法を習得することで、ビジネス中断のリスクを低減します。
Nano Banana Pro 障害タイムライン詳細記録
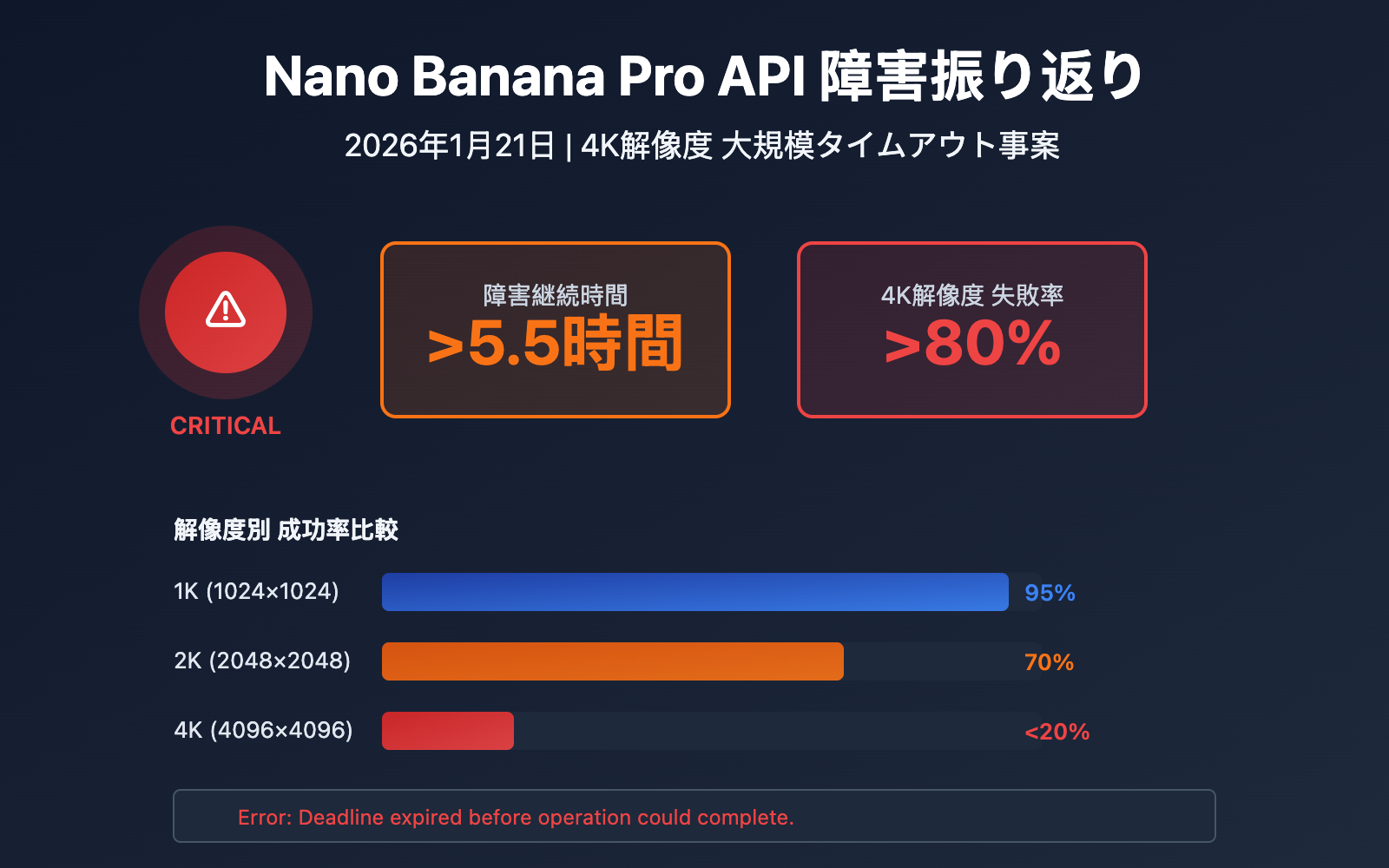
今回の障害は北京時間18:00頃から始まり、少なくとも5.5時間継続し、広範囲に影響を及ぼしました。
| 時刻 (北京時間) | 事象の説明 | 影響範囲 |
|---|---|---|
| 18:00 | 最初のタイムアウト報告が発生、4Kリクエストが失敗し始める | 一部のユーザー |
| 18:30 | 失敗率が上昇、エラーメッセージ Deadline expired が表示される |
40%のユーザー |
| 19:00 | 1-2K解像度は正常だが、4Kリクエストはほぼすべてタイムアウト | 70%のユーザー |
| 20:00 | 公式のタイムアウトしきい値が300秒から600秒に延長される | 全ユーザー |
| 21:00 | 少数の4Kリクエストがたまに成功するが、依然として不安定 | 継続中 |
| 23:30 | 障害は完全には復旧しておらず、4Kの成功率は約15% | 継続中 |
Nano Banana Pro 障害における主な現象
今回の障害では、以下の3つの顕著な特徴が観察されました。
現象1:解像度への依存性
- 1K-2K解像度:リクエストはほぼ正常、成功率は90%以上
- 4K解像度:失敗率が極めて高く、成功率は20%未満
現象2:モデルの独立性(アイソレーション)
同一アカウント内でも、Geminiのテキスト系APIは完全に正常に動作していました。これはアカウントレベルの制限ではなく、画像生成モジュール固有の障害であることを示しています。
現象3:タイムアウト時間の変化
公式は密かにタイムアウトのしきい値を300秒から600秒に延長しました。これはGoogleが問題を把握し、待ち時間を延ばすことで緩和を試みたことを示唆していますが、これは対症療法に過ぎず、根本的な解決にはなっていません。
Nano Banana Pro 故障の根本原因分析
技術的な分析
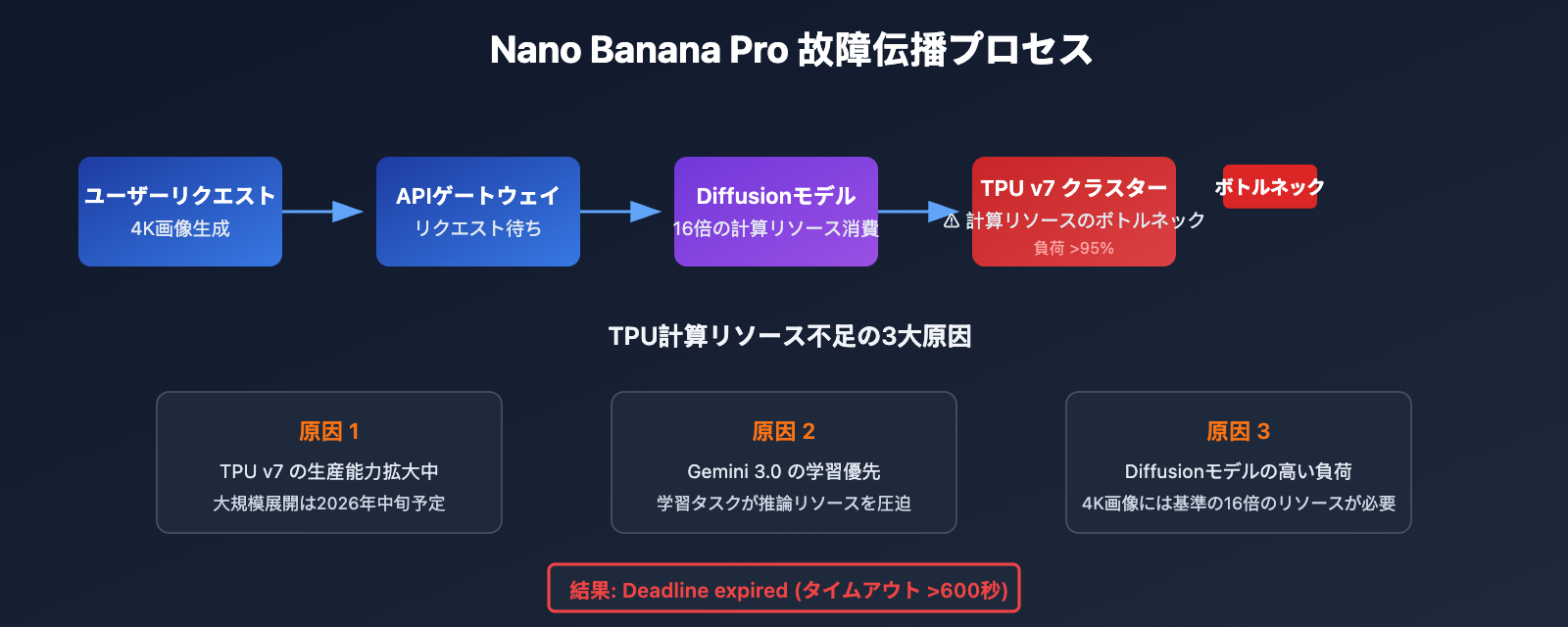
Nano Banana Pro (Gemini 3 Pro Image) の故障は、Google バックエンドにおける TPU 計算リソースの割り当て問題に起因しています。
| 要因 | 説明 | 影響 |
|---|---|---|
| TPU v7 のボトルネック | 2025年4月リリース。大規模なデプロイが現在も進行中 | 高負荷時間帯のリソース不足 |
| Diffusion モデルの負荷 | 画像生成はテキスト推論の 5〜10 倍のリソースを消費 | 4K解像度は特にリソースを消費 |
| Gemini 3.0 の学習タスク | 大量の TPU リソースがモデル学習に占有されている | 推論サービスのリソースが圧迫される |
| 有料プレビュー段階の制限 | 現在はまだ Paid Preview ステータス | キャパシティプランニングが保守的 |
Google AI 開発者フォーラムでの議論によると、Nano Banana Pro の不安定な問題は 2025 年後半から発生しており、公式による根本的な解決には至っていません。
Deadline expired エラーの解説
Error: Deadline expired before operation could complete.
このエラーメッセージには明確な意味があります:
- Deadline: Google サーバー側で設定されたタイムアウトしきい値(当初は 300 秒、現在は 600 秒)。
- expired: 規定の時間内に画像生成が完了しなかった。
- 根本原因: TPU キューの混雑により、リクエストの待機時間が長くなりすぎた。
🎯 技術的なアドバイス: このような大規模な故障が発生した際は、APIYI (apiyi.com) プラットフォームを通じて API ステータスを監視することをお勧めします。このプラットフォームはアップストリームのサービスステータスをリアルタイムで同期しており、開発者がいち早く故障状況を把握するのに役立ちます。
Nano Banana Pro 解像度による影響の詳細
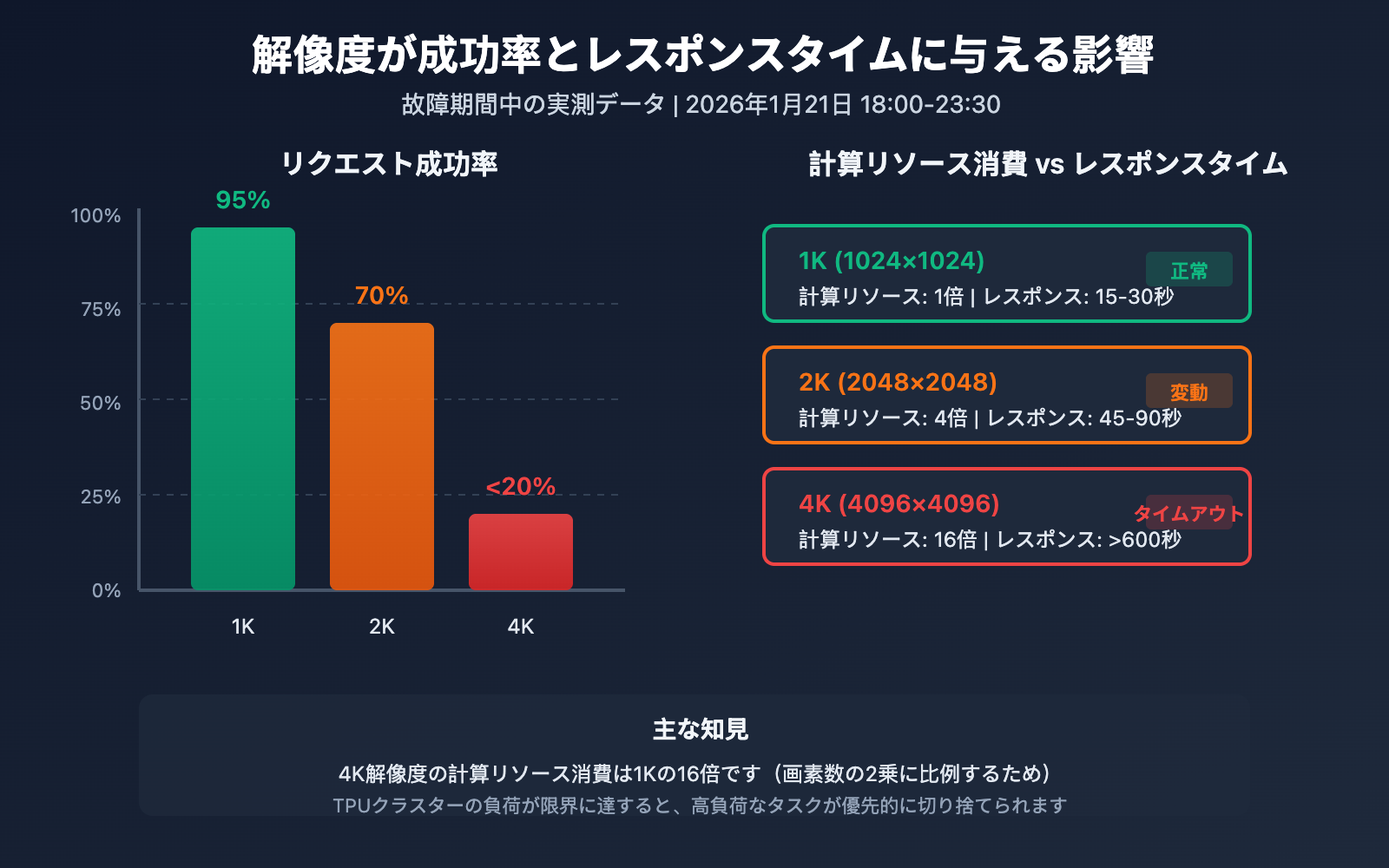
なぜ 4K 解像度が最も深刻な影響を受けるのでしょうか?これは Diffusion モデルの計算リソース消費量に直接関係しています。
| 解像度 | 画素数 | 相対的な計算リソース消費 | 故障期間中の成功率 | 平均レスポンスタイム |
|---|---|---|---|---|
| 1024×1024 (1K) | 100万画素 | 1x (基準) | ~95% | 15-30秒 |
| 2048×2048 (2K) | 400万画素 | ~4x | ~70% | 45-90秒 |
| 4096×4096 (4K) | 1600万画素 | ~16x | <20% | タイムアウト (>600秒) |
計算リソース消費の計算式
Diffusion モデルの計算量は解像度の 2 乗に比例します:
計算リソース消費 ≈ (幅 × 高さ) × 拡散ステップ数 × モデルの複雑さ
つまり、4K 画像の生成には 1K の 約 16 倍 の計算リソースが必要です。TPU クラスターの負荷が限界に達すると、このような高い計算リソースを必要とするタスクから優先的に失敗することになります。
解像度ダウングレード戦略
故障の発生期間中、ビジネス要件が許容するのであれば、以下のような解像度ダウングレード戦略を検討してください:
# 故障時のダウングレードコード例
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def generate_with_fallback(prompt, preferred_size="4096x4096"):
"""ダウングレード機能付きの画像生成関数"""
size_fallback = ["4096x4096", "2048x2048", "1024x1024"]
for size in size_fallback:
try:
response = client.images.generate(
model="nano-banana-pro",
prompt=prompt,
size=size,
timeout=120 # 1回の試行につき2分のタイムアウトを設定
)
print(f"成功: {size} 画像を生成しました")
return response
except Exception as e:
print(f"失敗: {size} の生成に失敗しました: {e}")
continue
return None
完全なダウングレード戦略コードを表示
import time
from typing import Optional
from openai import OpenAI
class NanoBananaProClient:
"""故障時のダウングレード機能を備えた Nano Banana Pro クライアント"""
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1"
)
self.size_priority = ["4096x4096", "2048x2048", "1024x1024"]
self.max_retries = 3
def generate_image(
self,
prompt: str,
preferred_size: str = "4096x4096",
allow_downgrade: bool = True
) -> Optional[dict]:
"""
画像を生成します。解像度のダウングレードをサポートしています。
Args:
prompt: 画像のプロンプト
preferred_size: 優先する解像度
allow_downgrade: 低い解像度へのダウングレードを許可するかどうか
"""
sizes_to_try = (
self.size_priority
if allow_downgrade
else [preferred_size]
)
for size in sizes_to_try:
for attempt in range(self.max_retries):
try:
response = self.client.images.generate(
model="nano-banana-pro",
prompt=prompt,
size=size,
timeout=180
)
return {
"success": True,
"size": size,
"data": response,
"downgraded": size != preferred_size
}
except Exception as e:
wait_time = (attempt + 1) * 30
print(f"試行 {attempt + 1}/{self.max_retries} "
f"({size}) 失敗: {e}")
if attempt < self.max_retries - 1:
time.sleep(wait_time)
return {"success": False, "error": "すべての試行が失敗しました"}
# 使用例
client = NanoBananaProClient(api_key="YOUR_API_KEY")
result = client.generate_image(
prompt="A futuristic cityscape at sunset",
preferred_size="4096x4096",
allow_downgrade=True
)
💡 推奨事項: 本番環境では、APIYI (apiyi.com) プラットフォーム経由で Nano Banana Pro API を呼び出すことをお勧めします。このプラットフォームは自動故障検知とインテリジェントルーティング機能を備えており、アップストリームのサービスに異常が発生した際に自動でバックアップチャネルに切り替えることが可能です。
Nano Banana Pro 緊急対応策
このような障害が発生した際、開発者は以下の3つの緊急対応策を講じることができます。
対策 1: 解像度のダウングレード
適用シーン: 低めの解像度でも業務上許容できる場合
| 戦略 | 操作 | 期待される効果 |
|---|---|---|
| 即時ダウングレード | 4K → 2K | 成功率が 70% まで向上 |
| 保守的ダウングレード | 4K → 1K | 成功率が 95% まで向上 |
| ハイブリッド戦略 | 自動フォールバック | 成功率の最大化 |
対策 2: リトライとキューイング
適用シーン: 4Kの使用が必須で、遅延が許容できる場合
import asyncio
from collections import deque
class RetryQueue:
"""带退避的重试队列"""
def __init__(self, max_concurrent=2):
self.queue = deque()
self.max_concurrent = max_concurrent
self.base_delay = 60 # 起始重试间隔 60 秒
async def add_task(self, task_id, prompt):
self.queue.append({
"id": task_id,
"prompt": prompt,
"attempts": 0,
"max_attempts": 5
})
async def process_with_backoff(self, task):
delay = self.base_delay * (2 ** task["attempts"])
print(f"等待 {delay}s 后重试任务 {task['id']}")
await asyncio.sleep(delay)
# 执行实际调用...
対策 3: 代替モデルへの切り替え
適用シーン: 異なる生成スタイルを許容できる場合
| 代替モデル | メリット | デメリット | 推奨度 |
|---|---|---|---|
| DALL-E 3 | 安定性が高く、文字レンダリングに優れる | スタイルの違いが顕著 | ⭐⭐⭐⭐ |
| Midjourney API | 芸術性が高い | 個別の連携が必要 | ⭐⭐⭐ |
| Stable Diffusion 3 | セルフホスト可能で完全に制御できる | GPUリソースが必要 | ⭐⭐⭐⭐⭐ |
| Flux Pro | 高品質かつ高速 | 料金が比較的高め | ⭐⭐⭐⭐ |
💰 コスト最適化: APIYI apiyi.com プラットフォームを利用すると、1つのAPIキーで複数の画像生成モデルを呼び出すことができます。メインサービスに障害が発生した際、コードのアーキテクチャを変更することなく、迅速に代替モデルへ切り替えることが可能です。
Nano Banana Pro 安定性の歴史的振り返り
Nano Banana Pro で大規模な障害が発生したのは、今回が初めてではありません。
| 時期 | 障害の種類 | 継続時間 | 公式の対応 |
|---|---|---|---|
| 2025年 8月 | 429 クォータ(割当)エラーの多発 | 約3日間 | クォータポリシーの調整 |
| 2025年 10月 | ピーク時のタイムアウト | 約12時間 | キャパシティの拡張対応 |
| 2025年 12月 | 無料枠クォータの大幅な制限 | 恒久的 | ポリシーの変更 |
| 2026年 1月 21日 | 4Kにおける大規模なタイムアウト | 5.5時間以上 | タイムアウト閾値の延長 |
Google AI 開発者コミュニティの情報によると、これらの問題の根本的な原因は以下の点にあります:
- TPU v7 の生産立ち上げ: 2025年4月に発表されましたが、大規模なデプロイが完了するのは2026年になる見込みです。
- Gemini 3.0 の学習優先: 学習(トレーニング)タスクが大量のTPUを占有し、推論サービスを圧迫しています。
- Diffusion モデルの計算リソース需要: 画像生成はテキスト推論と比較して5〜10倍の計算リソースを消費します。
よくある質問
Q1: なぜ同じアカウントの Gemini テキスト API は正常なのに、画像 API はタイムアウトするのでしょうか?
Gemini テキスト API と Nano Banana Pro(画像生成)は、異なるバックエンドのリソースプールを使用しています。画像生成は Diffusion モデルに依存しており、計算能力の需要はテキスト推論の 5〜10 倍に達します。TPU リソースが不足すると、高い計算能力を必要とするサービスが最初に影響を受けます。これは、障害がアカウントの権限ではなく、リソース層で発生していることを示しています。
Q2: 公式のタイムアウト設定が 300秒から 600秒に延長されたのは、どのようなシグナルでしょうか?
これは、Google が問題の存在を認めたものの、短期的には TPU の計算能力不足を根本的に解決できないことを示唆しています。タイムアウトの延長はあくまで応急処置であり、リクエストの待機時間を長くしたに過ぎません。開発者にとっては、クライアント側のタイムアウト設定を適切に調整し、長時間待機が発生することを想定した運用管理が必要であることを意味します。
Q3: APIYI は公式転送サービスとして、このような障害にどのように対応していますか?
公式転送サービスとして、APIYI(apiyi.com)プラットフォームも上流サービスの障害時には制限を受けます。しかし、本プラットフォームが提供する価値には、リアルタイムの状態監視、障害アラートの通知、自動リトライ機能、および多モデル迅速切り替え能力が含まれます。Nano Banana Pro で障害が発生した場合、ワンクリックで DALL-E 3 や Flux Pro などの代替モデルに切り替えることが可能です。
Q4: Nano Banana Pro はいつになったら完全に安定しますか?
業界の分析によると、2 つの条件が満たされるのを待つ必要があります。1 つは TPU v7 の大規模なデプロイが完了すること(2026 年半ばを予定)、もう 1 つは Gemini 3.0 シリーズのトレーニングタスクが終了することです。それまでは、ピーク時の不安定さは続く可能性があります。複数のモデルを組み合わせた冗長化設計を行うことをお勧めします。
まとめ
Nano Banana Pro API 2026年1月21日の障害における重要ポイント:
- 障害の特徴: 4K 解像度の失敗率が極めて高く、1-2K は概ね正常。問題は TPU の計算リソース割り当てにあります。
- 根本原因: Google TPU v7 の供給不足 + Diffusion モデルの高い計算リソース需要 + Gemini 3.0 のトレーニングによる推論リソースの圧迫。
- 応急対策: 解像度の引き下げ、バックオフを伴うリトライキュー、代替モデルへの迅速な切り替え。
Nano Banana Pro に依存している商用サービスについては、APIYI(apiyi.com)プラットフォーム経由での利用を推奨します。当プラットフォームは統一されたマルチモデルインターフェースを提供しており、DALL-E 3、Flux Pro、Stable Diffusion 3 などの主要モデルをサポートしています。メインサービスが故障した際も迅速に切り替えることができ、ビジネスの継続性を確保します。
執筆: APIYI 技術チーム
技術交流: AI 画像生成 API の最新情報や技術サポートについては、APIYI(apiyi.com)をご覧ください。
参考文献
-
Google AI Developers – Nano Banana Image Generation: 公式ドキュメント
- リンク:
ai.google.dev/gemini-api/docs/image-generation - 説明: Gemini API 画像生成の公式ガイド
- リンク:
-
Google Cloud Service Health: サービスステータスパネル
- リンク:
status.cloud.google.com - 説明: Google Cloud の各サービスの状態をリアルタイムで監視
- リンク:
-
StatusGator – Google AI Studio and Gemini API: サードパーティによるステータス監視
- リンク:
statusgator.com/services/google-ai-studio-and-gemini-api - 説明: 過去の障害履歴とステータス追跡
- リンク:
-
Gemini API Rate Limits: 公式リミット(制限)ドキュメント
- リンク:
ai.google.dev/gemini-api/docs/rate-limits - 説明: IPM(分間あたりの画像生成数)およびクォータ(割当)ポリシーの説明
- リンク: