2026 年 1 月 21 日下午 18:00 (北京时间),大量开发者反馈 Nano Banana Pro API 调用持续超时,4K 分辨率请求失败率飙升。本文完整复盘这次故障,分析根本原因,并提供 3 个可落地的应急方案。
核心价值: 了解 Google Imagen API 的真实稳定性现状,掌握故障发生时的应急处理方法,降低业务中断风险。

Nano Banana Pro 故障时间线完整记录
本次故障从北京时间 18:00 左右开始,持续至少 5.5 小时,影响范围广泛。
| 时间节点 (北京时间) | 事件描述 | 影响程度 |
|---|---|---|
| 18:00 | 首批超时报告出现,4K 请求开始失败 | 部分用户 |
| 18:30 | 失败率上升,错误信息显示 Deadline expired |
40% 用户 |
| 19:00 | 1-2K 分辨率仍正常,4K 请求几乎全部超时 | 70% 用户 |
| 20:00 | 官方超时阈值从 300s 延长至 600s | 全部用户 |
| 21:00 | 少量 4K 请求偶尔成功,但不稳定 | 持续中 |
| 23:30 | 故障仍未完全恢复,4K 成功率约 15% | 持续中 |
Nano Banana Pro 故障关键现象
在这次故障中,我们观察到 3 个明显的特征:
现象 1: 分辨率依赖性
- 1K-2K 分辨率: 请求基本正常,成功率 > 90%
- 4K 分辨率: 失败率超高,成功率 < 20%
现象 2: 模型隔离性
同一账号下,Gemini 文本类 API 完全正常工作,说明这不是账号级别的限制,而是图像生成模块的专项故障。
现象 3: 超时时间变化
官方悄然将超时阈值从 300 秒延长到 600 秒,这表明 Google 已经意识到问题并尝试通过延长等待时间来缓解,但这治标不治本。
Nano Banana Pro 故障根因分析
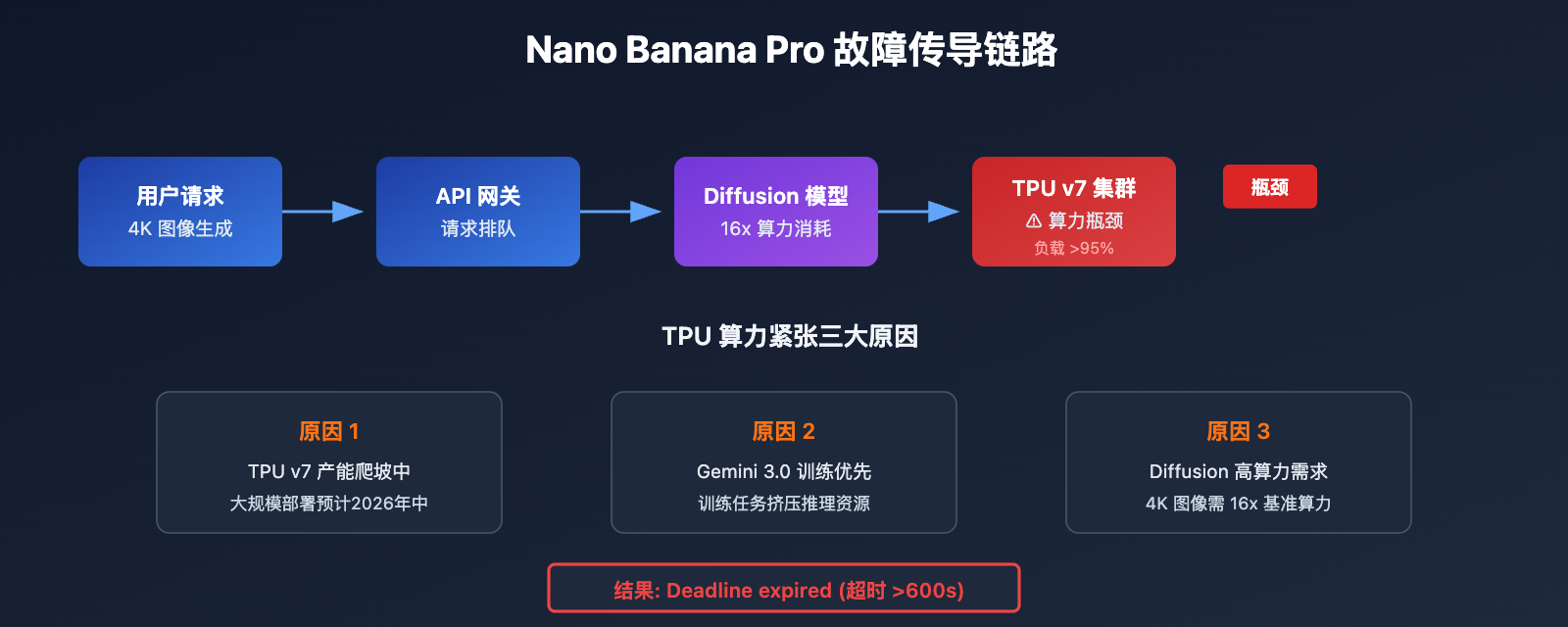
技术层面分析
Nano Banana Pro (Gemini 3 Pro Image) 的故障源于 Google 后端 TPU 算力分配问题。
| 因素 | 说明 | 影响 |
|---|---|---|
| TPU v7 算力瓶颈 | 2025 年 4 月发布,大规模部署仍在进行中 | 高负载时段算力不足 |
| Diffusion 模型开销 | 图像生成比文本推理耗费 5-10 倍算力 | 4K 尤其消耗资源 |
| Gemini 3.0 训练任务 | 大量 TPU 资源被训练任务占用 | 推理服务受挤压 |
| 付费预览阶段限制 | 当前仍为 Paid Preview 状态 | 容量规划保守 |
根据 Google AI 开发者论坛的讨论,Nano Banana Pro 的不稳定问题从 2025 年下半年就开始出现,官方一直未能根本解决。
Deadline expired 错误解读
Error: Deadline expired before operation could complete.
这个错误信息含义明确:
- Deadline: Google 服务端设置的超时阈值 (原 300s,现 600s)
- expired: 在规定时间内未完成图像生成
- 根本原因: TPU 队列拥堵,请求排队等待时间过长
🎯 技术建议: 遇到此类大规模故障时,建议通过 API易 apiyi.com 平台监控 API 状态。平台会实时同步上游服务状态,帮助开发者第一时间了解故障情况。
Nano Banana Pro 分辨率影响详解
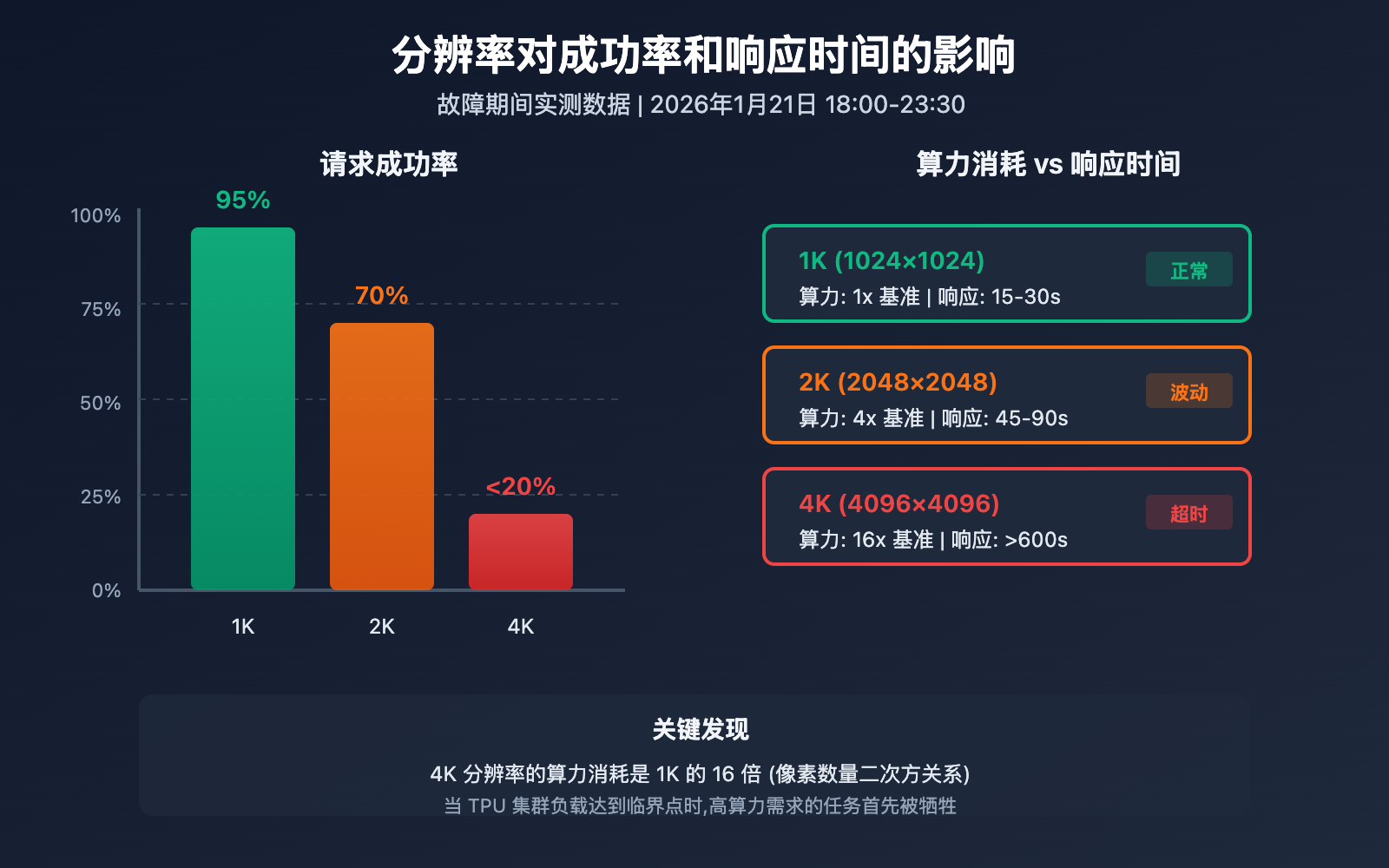
为什么 4K 分辨率受影响最严重? 这与 Diffusion 模型的算力消耗直接相关。
| 分辨率 | 像素数量 | 相对算力消耗 | 故障期间成功率 | 平均响应时间 |
|---|---|---|---|---|
| 1024×1024 (1K) | 1M 像素 | 1x (基准) | ~95% | 15-30s |
| 2048×2048 (2K) | 4M 像素 | ~4x | ~70% | 45-90s |
| 4096×4096 (4K) | 16M 像素 | ~16x | <20% | 超时 (>600s) |
算力消耗公式
Diffusion 模型的计算量与分辨率呈二次方关系:
算力消耗 ≈ (宽度 × 高度) × 扩散步数 × 模型复杂度
这意味着 4K 图像的生成需要约 16 倍于 1K 的算力。当 TPU 集群负载达到临界点时,高算力需求的任务首先被牺牲。
分辨率降级策略
在故障期间,如果业务允许,可以采用分辨率降级策略:
# 故障期间的降级代码示例
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
def generate_with_fallback(prompt, preferred_size="4096x4096"):
"""带降级的图像生成函数"""
size_fallback = ["4096x4096", "2048x2048", "1024x1024"]
for size in size_fallback:
try:
response = client.images.generate(
model="nano-banana-pro",
prompt=prompt,
size=size,
timeout=120 # 单次尝试 2 分钟超时
)
print(f"成功生成 {size} 图像")
return response
except Exception as e:
print(f"{size} 生成失败: {e}")
continue
return None
查看完整降级策略代码
import time
from typing import Optional
from openai import OpenAI
class NanoBananaProClient:
"""带故障降级的 Nano Banana Pro 客户端"""
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1"
)
self.size_priority = ["4096x4096", "2048x2048", "1024x1024"]
self.max_retries = 3
def generate_image(
self,
prompt: str,
preferred_size: str = "4096x4096",
allow_downgrade: bool = True
) -> Optional[dict]:
"""
生成图像,支持分辨率降级
Args:
prompt: 图像描述
preferred_size: 首选分辨率
allow_downgrade: 是否允许降级到较低分辨率
"""
sizes_to_try = (
self.size_priority
if allow_downgrade
else [preferred_size]
)
for size in sizes_to_try:
for attempt in range(self.max_retries):
try:
response = self.client.images.generate(
model="nano-banana-pro",
prompt=prompt,
size=size,
timeout=180
)
return {
"success": True,
"size": size,
"data": response,
"downgraded": size != preferred_size
}
except Exception as e:
wait_time = (attempt + 1) * 30
print(f"尝试 {attempt + 1}/{self.max_retries} "
f"({size}) 失败: {e}")
if attempt < self.max_retries - 1:
time.sleep(wait_time)
return {"success": False, "error": "所有尝试均失败"}
# 使用示例
client = NanoBananaProClient(api_key="YOUR_API_KEY")
result = client.generate_image(
prompt="A futuristic cityscape at sunset",
preferred_size="4096x4096",
allow_downgrade=True
)
💡 选择建议: 对于生产环境,我们建议通过 API易 apiyi.com 平台调用 Nano Banana Pro API。该平台提供自动故障检测和智能路由功能,在上游服务异常时可自动切换备用通道。
Nano Banana Pro 应急方案
面对此类故障,开发者可以采取以下 3 个应急方案。
方案 1: 分辨率降级
适用场景: 业务可接受较低分辨率
| 策略 | 操作 | 预期效果 |
|---|---|---|
| 立即降级 | 4K → 2K | 成功率提升至 70% |
| 保守降级 | 4K → 1K | 成功率提升至 95% |
| 混合策略 | 自动瀑布降级 | 最大化成功率 |
方案 2: 重试与队列
适用场景: 必须使用 4K,可接受延迟
import asyncio
from collections import deque
class RetryQueue:
"""带退避的重试队列"""
def __init__(self, max_concurrent=2):
self.queue = deque()
self.max_concurrent = max_concurrent
self.base_delay = 60 # 起始重试间隔 60 秒
async def add_task(self, task_id, prompt):
self.queue.append({
"id": task_id,
"prompt": prompt,
"attempts": 0,
"max_attempts": 5
})
async def process_with_backoff(self, task):
delay = self.base_delay * (2 ** task["attempts"])
print(f"等待 {delay}s 后重试任务 {task['id']}")
await asyncio.sleep(delay)
# 执行实际调用...
方案 3: 备选模型切换
适用场景: 业务可接受不同风格
| 备选模型 | 优势 | 劣势 | 推荐指数 |
|---|---|---|---|
| DALL-E 3 | 稳定性高,文字渲染好 | 风格差异明显 | ⭐⭐⭐⭐ |
| Midjourney API | 艺术性强 | 需要独立接入 | ⭐⭐⭐ |
| Stable Diffusion 3 | 可自部署,完全可控 | 需要 GPU 资源 | ⭐⭐⭐⭐⭐ |
| Flux Pro | 高质量,速度快 | 价格较高 | ⭐⭐⭐⭐ |
💰 成本优化: 使用 API易 apiyi.com 平台可以一个 API Key 调用多个图像生成模型,在主服务故障时快速切换到备选模型,无需修改代码架构。
Nano Banana Pro 稳定性历史回顾
这并非 Nano Banana Pro 首次出现大规模故障。
| 时间 | 故障类型 | 持续时间 | 官方响应 |
|---|---|---|---|
| 2025 年 8 月 | 429 配额错误泛滥 | ~3 天 | 调整配额策略 |
| 2025 年 10 月 | 高峰期超时 | ~12 小时 | 扩容处理 |
| 2025 年 12 月 | 免费层配额大幅收紧 | 永久 | 政策调整 |
| 2026 年 1 月 21 日 | 4K 大规模超时 | >5.5 小时 | 延长超时阈值 |
根据 Google AI 开发者社区的信息,这些问题的根源在于:
- TPU v7 产能爬坡: 2025 年 4 月发布,但大规模部署要到 2026 年才能完成
- Gemini 3.0 训练优先: 训练任务占用大量 TPU,挤压推理服务
- Diffusion 模型算力需求: 图像生成比文本推理耗费 5-10 倍算力
常见问题
Q1: 为什么同一账号的 Gemini 文本 API 正常,图像 API 却超时?
Gemini 文本 API 和 Nano Banana Pro (图像生成) 使用不同的后端资源池。图像生成依赖 Diffusion 模型,算力需求是文本推理的 5-10 倍。当 TPU 资源紧张时,高算力服务首先受影响。这也说明故障是资源层面的,而非账号权限问题。
Q2: 官方超时从 300s 延长到 600s 是什么信号?
这表明 Google 承认了问题的存在,但短期内无法从根本上解决 TPU 算力不足的问题。延长超时只是治标之策,让请求有更长的排队等待时间。对于开发者来说,这意味着需要相应调整客户端的超时设置,同时做好长时间等待的预期管理。
Q3: APIYI 作为官方转发,遇到这种故障有什么办法?
作为官方转发服务,API易 apiyi.com 平台在上游服务故障时确实受限。但平台提供的价值包括:实时状态监控、故障预警推送、自动重试机制、以及多模型快速切换能力。当 Nano Banana Pro 故障时,可以一键切换到 DALL-E 3 或 Flux Pro 等备选模型。
Q4: 什么时候 Nano Banana Pro 会彻底稳定?
根据行业分析,需要等待两个条件满足:一是 TPU v7 大规模部署完成 (预计 2026 年中),二是 Gemini 3.0 系列训练任务收尾。在此之前,高峰期的不稳定可能会持续出现。建议做好多模型冗余架构设计。
总结
Nano Banana Pro API 2026 年 1 月 21 日故障核心要点:
- 故障特征: 4K 分辨率失败率超高,1-2K 基本正常,问题出在 TPU 算力分配
- 根本原因: Google TPU v7 产能不足 + Diffusion 模型高算力需求 + Gemini 3.0 训练挤压推理资源
- 应急方案: 分辨率降级、带退避的重试队列、备选模型快速切换
对于依赖 Nano Banana Pro 的生产业务,建议通过 API易 apiyi.com 平台接入。平台提供统一的多模型接口,支持 DALL-E 3、Flux Pro、Stable Diffusion 3 等主流模型,在主服务故障时可快速切换,保障业务连续性。
作者: APIYI 技术团队
技术交流: 访问 API易 apiyi.com 获取更多 AI 图像生成 API 资讯和技术支持
参考资料
-
Google AI Developers – Nano Banana Image Generation: 官方文档
- 链接:
ai.google.dev/gemini-api/docs/image-generation - 说明: Gemini API 图像生成官方指南
- 链接:
-
Google Cloud Service Health: 服务状态面板
- 链接:
status.cloud.google.com - 说明: 实时监控 Google Cloud 各服务状态
- 链接:
-
StatusGator – Google AI Studio and Gemini API: 第三方状态监控
- 链接:
statusgator.com/services/google-ai-studio-and-gemini-api - 说明: 历史故障记录和状态追踪
- 链接:
-
Gemini API Rate Limits: 官方限速文档
- 链接:
ai.google.dev/gemini-api/docs/rate-limits - 说明: IPM (每分钟图像数) 和配额策略说明
- 链接: