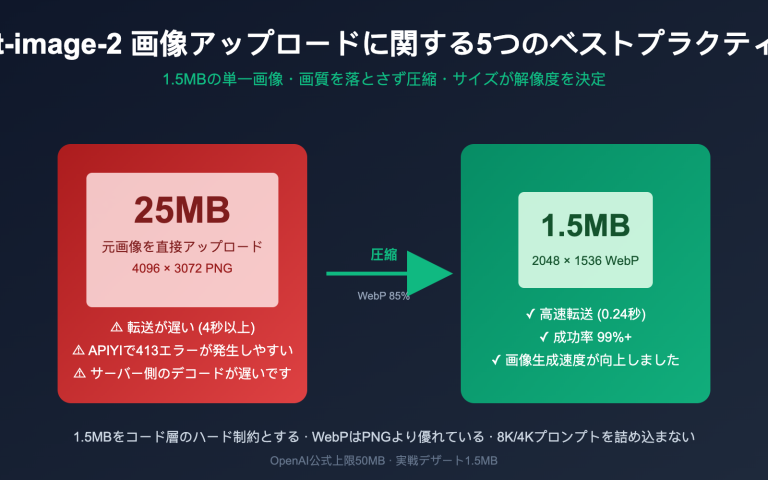
Gemini 3.0 Pro Preview や gemini-3-flash-preview モデルを呼び出す際に、thinking_budget and thinking_level are not supported together というエラーに遭遇していませんか?これは、Google Gemini API のモデルバージョン間におけるパラメータのアップグレードによって生じる互換性の問題です。本記事では、API 設計の変遷という観点から、このエラーの根本原因と正しい設定方法を体系的に解説します。
核心的なメリット: この記事を読み終えることで、Gemini 2.5 と 3.0 モデルにおける思考モード(Thinking Mode)パラメータの正しい設定方法をマスターし、よくある API 呼び出しエラーを回避しながら、モデルの推論パフォーマンスの最適化とコスト管理を実現できるようになります。

Gemini API 思考モードパラメータ進化の要点
| モデルバージョン | 推奨パラメータ | パラメータの型 | 設定例 | 活用シーン |
|---|---|---|---|---|
| Gemini 2.5 Flash/Flash-Lite | thinking_budget |
整数または -1 | thinking_budget: 0 (無効)thinking_budget: -1 (動的) |
思考トークンの予算を精密に制御する場合 |
| Gemini 3.0 Pro/Flash | thinking_level |
列挙型 | thinking_level: "minimal"/"low"/"medium"/"high" |
設定を簡略化し、シーンに応じて段階的に指定する場合 |
| 互換性に関する注意 | ⚠️ 同時使用不可 | – | 両方のパラメータを同時に渡すと 400 エラーが発生します | モデルのバージョンに合わせてどちらか一方を選択 |
Gemini 思考モードパラメータの核心的な違い
Google が Gemini 3.0 で thinking_level パラメータを導入した主な理由は、開発者の設定体験を簡素化することにあります。Gemini 2.5 の thinking_budget では、開発者が思考トークンの量を正確に見積もる必要がありましたが、Gemini 3.0 の thinking_level は、その複雑さを 4 つのセマンティックな(意味的な)レベルに抽象化することで、設定のハードルを下げました。
この設計変更は、Google の API 進化におけるトレードオフを反映しています。一部の微細な制御能力を犠牲にする代わりに、使いやすさとモデル間の一貫性を向上させています。ほとんどのユースケースでは、thinking_level による抽象化で十分ですが、極限のコスト最適化や特定のトークン予算管理が必要な場合にのみ、thinking_budget を使用することになります。
💡 テクニカルアドバイス: 実際の開発においては、APIYI (apiyi.com) プラットフォームを利用してインターフェースの呼び出しテストを行うことをお勧めします。このプラットフォームは統一された API インターフェースを提供しており、Gemini 2.5 Flash、Gemini 3.0 Pro、Gemini 3.0 Flash などの各モデルをサポートしています。異なる思考モード設定による実際の効果やコストの差異を素早く検証するのに役立ちます。
エラーの根本原因: パラメータ設計の前方互換性戦略
API エラーメッセージの解析
{
"status_code": 400,
"error": {
"message": "Unable to submit request because thinking_budget and thinking_level are not supported together.",
"type": "upstream_error",
"code": 400
}
}
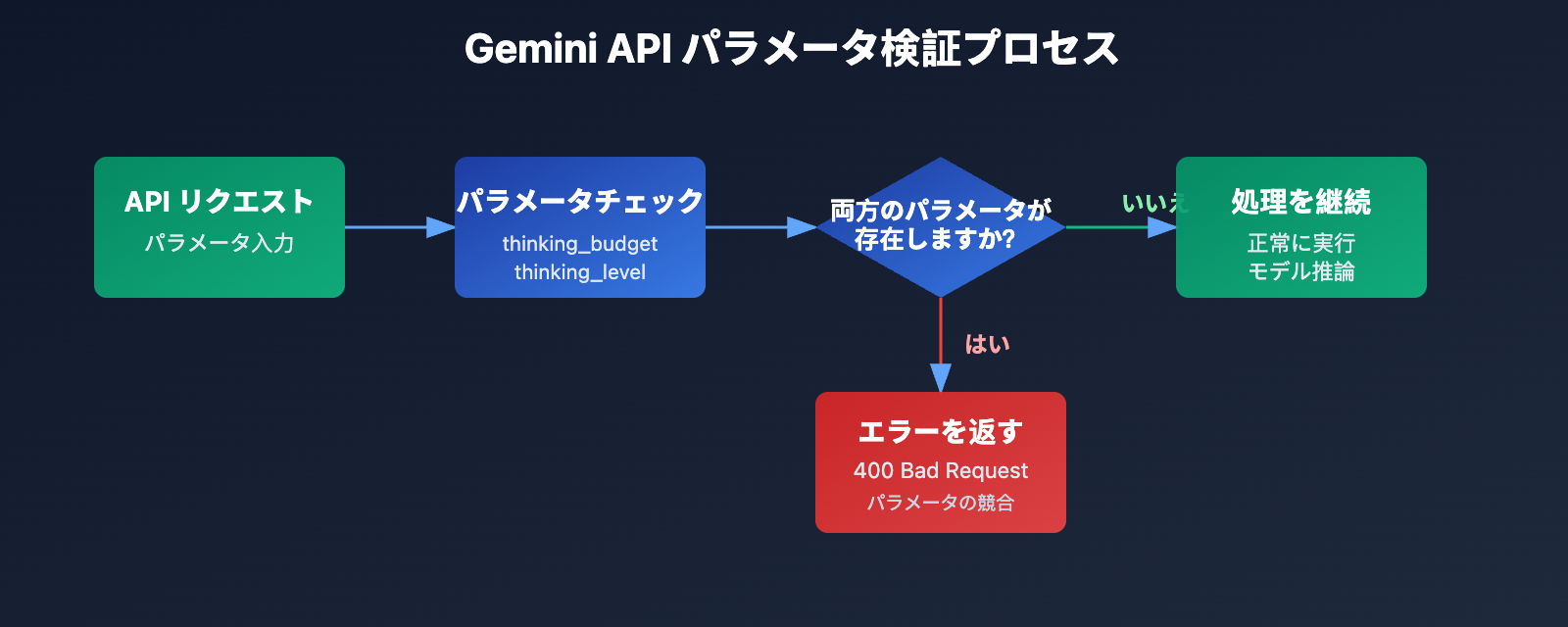
このエラーの核心的なメッセージは、thinking_budget と thinking_level を同時に存在させることはできないという点です。Google は Gemini 3.0 で新しいパラメータを導入する際、旧パラメータを完全に廃止するのではなく、排他的な(同時使用を認めない)戦略を採用しました。
- Gemini 2.5 モデル:
thinking_budgetのみを受け付け、thinking_levelは無視されます。 - Gemini 3.0 モデル:
thinking_levelを優先的に使用します。後方互換性を維持するためにthinking_budgetも受け付けますが、両方を同時に渡すことは許可されていません。 - エラー発生条件: API リクエストに
thinking_budgetとthinking_levelの両方のパラメータが含まれている場合。
なぜこのエラーが発生するのか?
開発者がこのエラーに遭遇する場合、通常は以下の 3 つのシナリオが考えられます。
| シナリオ | 原因 | 典型的なコードの特徴 |
|---|---|---|
| シナリオ 1: SDK による自動補完 | 一部の AI フレームワーク(LiteLLM、AG2 など)がモデル名に基づいてパラメータを自動的に補完し、結果として両方のパラメータが渡されてしまう | カプセル化された SDK を使用しており、実際の構成リクエストボディを確認していない |
| シナリオ 2: ハードコードされた設定 | コード内に thinking_budget がハードコードされており、Gemini 3.0 モデルに切り替えた際にパラメータ名を更新し忘れている |
設定ファイルやコード内で両方のパラメータに値が代入されている |
| シナリオ 3: モデルエイリアスの誤判定 | gemini-flash-preview などのエイリアスを使用しており、実際には Gemini 3.0 を指しているが、2.5 のパラメータ設定のままになっている |
モデル名に preview や latest が含まれており、パラメータ設定が同期されていない |
🎯 選択アドバイス: Gemini モデルのバージョンを切り替える際は、まず APIYI apiyi.com プラットフォームでパラメータの互換性をテストすることをお勧めします。このプラットフォームは Gemini 2.5 と 3.0 シリーズのモデルを素早く切り替えることができ、異なる思考モード設定によるレスポンス品質や遅延の差を簡単に比較できるため、本番環境でのパラメータ競合を避けることができます。
3 つの解決策: モデルバージョンに応じた正しいパラメータの選択
解決策 1: Gemini 2.5 モデルの設定 (thinking_budget を使用)
対象モデル: gemini-2.5-flash、gemini-2.5-pro など
パラメータの説明:
thinking_budget: 0– 思考モードを完全に無効化。最低限の遅延とコスト。thinking_budget: -1– 動的な思考モード。モデルがリクエストの複雑さに応じて自動調整。thinking_budget: <正の整数>– 思考トークン数の上限を正確に指定。
シンプルな例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "量子もつれの原理を説明してください"}],
extra_body={
"thinking_budget": -1 # 動的な思考モード
}
)
print(response.choices[0].message.content)
完全なコードを表示 (思考内容の抽出を含む)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "量子もつれの原理を説明してください"}],
extra_body={
"thinking_budget": -1, # 動的な思考モード
"include_thoughts": True # 思考サマリーの返却を有効化
}
)
# 思考内容を抽出 (有効な場合)
for part in response.choices[0].message.content:
if hasattr(part, 'thought') and part.thought:
print(f"思考プロセス: {part.text}")
# 最終回答を抽出
final_answer = response.choices[0].message.content
print(f"最終回答: {final_answer}")
アドバイス: Gemini 2.5 モデルは 2026 年 3 月 3 日に廃止される予定です。お早めに Gemini 3.0 シリーズへの移行を推奨します。APIYI apiyi.com プラットフォームを利用すれば、移行前後のレスポンス品質の差を素早く比較できます。
解決策 2: Gemini 3.0 モデルの設定 (thinking_level を使用)
対象モデル: gemini-3.0-flash-preview、gemini-3.0-pro-preview
パラメータの説明:
thinking_level: "minimal"– 最小限の思考。予算ほぼゼロ。思考シグネチャ (Thought Signatures) を渡す必要があります。thinking_level: "low"– 低強度の思考。シンプルな指示に従う場合やチャットシーンに適しています。thinking_level: "medium"– 中強度の思考。一般的な推論タスクに適しています (Gemini 3.0 Flash のみサポート)。thinking_level: "high"– 高強度の思考。推論の深さを最大化。複雑な問題に適しています (デフォルト値)。
シンプルな例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[{"role": "user", "content": "このコードの時間計算量を分析してください"}],
extra_body={
"thinking_level": "medium" # 中強度の思考
}
)
print(response.choices[0].message.content)
完全なコードを表示 (思考シグネチャの受け渡しを含む)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# 第1ラウンドの対話
response_1 = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[{"role": "user", "content": "LRU キャッシュアルゴリズムを設計してください"}],
extra_body={
"thinking_level": "high",
"include_thoughts": True
}
)
# 思考シグネチャを抽出 (Gemini 3.0 は自動的に返却します)
thought_signatures = []
for part in response_1.choices[0].message.content:
if hasattr(part, 'thought_signature'):
thought_signatures.append(part.thought_signature)
# 第2ラウンドの対話。推論チェーンを維持するために思考シグネチャを渡す
response_2 = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[
{"role": "user", "content": "LRU キャッシュアルゴリズムを設計してください"},
{"role": "assistant", "content": response_1.choices[0].message.content, "thought_signatures": thought_signatures},
{"role": "user", "content": "このアルゴリズムの空間計算量を最適化してください"}
],
extra_body={
"thinking_level": "high"
}
)
print(response_2.choices[0].message.content)
💰 コスト最適化: 予算を重視するプロジェクトでは、APIYI apiyi.com プラットフォームを通じて Gemini 3.0 Flash API を呼び出すことを検討してください。柔軟な課金方式とお得な価格設定を提供しており、中小規模のチームや個人開発者に適しています。
thinking_level: "low"と組み合わせることで、さらにコストを抑えることが可能です。
解決策 3: 動的なモデル切り替えのためのパラメータ適応戦略
対象シーン: コード内で Gemini 2.5 と 3.0 の両方のモデルをサポートする必要がある場合。
インテリジェント・パラメータ適応関数
def get_thinking_config(model_name: str, complexity: str = "medium") -> dict:
"""
モデルのバージョンに基づいて正しい思考モードパラメータを自動選択します。
Args:
model_name: Gemini モデル名
complexity: 思考の複雑さ ("minimal", "low", "medium", "high", "dynamic")
Returns:
extra_body に適用可能なパラメータ辞書
"""
# Gemini 3.0 モデルリスト
gemini_3_models = [
"gemini-3.0-flash-preview",
"gemini-3.0-pro-preview",
"gemini-3-flash",
"gemini-3-pro"
]
# Gemini 2.5 モデルリスト
gemini_2_5_models = [
"gemini-2.5-flash-preview-04-17",
"gemini-2.5-flash-lite",
"gemini-2-flash",
"gemini-2-flash-lite"
]
# モデルバージョンの判定
if any(m in model_name for m in gemini_3_models):
# Gemini 3.0 は thinking_level を使用
level_map = {
"minimal": "minimal",
"low": "low",
"medium": "medium",
"high": "high",
"dynamic": "high" # デフォルトで高強度
}
return {"thinking_level": level_map.get(complexity, "medium")}
elif any(m in model_name for m in gemini_2_5_models):
# Gemini 2.5 は thinking_budget を使用
budget_map = {
"minimal": 0,
"low": 512,
"medium": 2048,
"high": 8192,
"dynamic": -1
}
return {"thinking_budget": budget_map.get(complexity, -1)}
else:
# 未知のモデルの場合、デフォルトで Gemini 3.0 のパラメータを使用
return {"thinking_level": "medium"}
# 使用例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
model = "gemini-3.0-flash-preview" # 動的に切り替え可能
thinking_config = get_thinking_config(model, complexity="high")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "質問内容"}],
extra_body=thinking_config
)

| 思考の複雑さ | Gemini 2.5 (thinking_budget) | Gemini 3.0 (thinking_level) | 推奨シーン |
|---|---|---|---|
| 最小 | 0 |
"minimal" |
シンプルな指示への追従、高スループットなアプリケーション |
| 低 | 512 |
"low" |
チャットボット、軽量な QA |
| 中 | 2048 |
"medium" |
一般的な推論タスク、コード生成 |
| 高 | 8192 |
"high" |
複雑な問題解決、深い分析 |
| 動的 | -1 |
"high" (デフォルト) |
複雑さへの自動適応 |
🚀 クイックスタート: プロトタイプを素早く構築するには、APIYI apiyi.com プラットフォームの使用をお勧めします。このプラットフォームは、複雑な設定なしですぐに使える Gemini API インターフェースを提供しており、5 分で統合を完了できます。また、ボタン一つで異なる思考モードパラメータを切り替えて効果を比較することも可能です。
Gemini 3.0 思考シグネチャ (Thought Signatures) メカニズム詳解
思考シグネチャとは?
Gemini 3.0 で導入された思考シグネチャ (Thought Signatures) は、モデル内部の推理プロセスの暗号化された表現です。include_thoughts: true を有効にすると、モデルはレスポンスの中で思考プロセスの暗号化されたシグネチャを返します。これらの方署名を後続の対話で渡すことで、モデルに推理の連鎖(Reasoning Chain)の連続性を維持させることができます。
主な特徴:
- 暗号化された表現: シグネチャの内容は読み取れず、モデルのみが解析可能です。
- 推理の連鎖の維持: マルチターンの対話でシグネチャを渡すことで、モデルは前回の思考に基づいて推理を継続できます。
- 強制返却: Gemini 3.0 では、リクエストしなくてもデフォルトで思考シグネチャを返します。
思考シグネチャの実際の活用シーン
| シーン | シグネチャの受け渡しが必要か | 説明 |
|---|---|---|
| シングルターンのQA | ❌ 不要 | 独立した質問であり、推理の連鎖を維持する必要がないため。 |
| マルチターンの対話 (単純) | ❌ 不要 | コンテキストだけで十分であり、複雑な推理の依存関係がないため。 |
| マルチターンの対話 (複雑な推理) | ✅ 必要 | 例:コードのリファクタリング、数学的証明、多ステップの分析など。 |
| 最小思考モード (minimal) | ✅ 必須 | thinking_level: "minimal" ではシグネチャの受け渡しが要求されます。そうしないと 400 エラーが返されます。 |
思考シグネチャ受け渡しの実装例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# 第1ターン:モデルにアルゴリズムを設計させる
response_1 = client.chat.completions.create(
model="gemini-3.0-pro-preview",
messages=[{"role": "user", "content": "設計一個分布式限流算法"}],
extra_body={
"thinking_level": "high",
"include_thoughts": True
}
)
# 思考シグネチャを抽出する
signatures = []
for part in response_1.choices[0].message.content:
if hasattr(part, 'thought_signature'):
signatures.append(part.thought_signature)
# 第2ターン:前回の推理に基づいて最適化を継続する
response_2 = client.chat.completions.create(
model="gemini-3.0-pro-preview",
messages=[
{"role": "user", "content": "設計一個分布式限流算法"},
{
"role": "assistant",
"content": response_1.choices[0].message.content,
"thought_signatures": signatures # 思考シグネチャを渡す
},
{"role": "user", "content": "如何處理分布式時鐘不一致問題?"}
],
extra_body={"thinking_level": "high"}
)
💡 ベストプラクティス: システム設計、アルゴリズムの最適化、コードレビューなど、マルチターンの複雑な推理が必要なシーンでは、APIYI (apiyi.com) プラットフォームを通じて思考シグネチャの受け渡しによる効果の違いをテストすることをお勧めします。同プラットフォームは Gemini 3.0 の思考シグネチャメカニズムを完全にサポートしており、異なる設定下での推理品質を簡単に検証できます。
よくある質問
Q1: なぜ Gemini 2.5 Flash で thinking_budget=0 を設定しても思考内容が返ってくるのですか?
これは既知のバグです。Gemini 2.5 Flash Preview 04-17 バージョンにおいて、thinking_budget=0 が正しく実行されないことが確認されています。Google の公式フォーラムでもこの問題が認められています。
一時的な回避策:
- 0 ではなく
thinking_budget=1(極小値) を使用する。 - Gemini 3.0 Flash にアップグレードし、
thinking_level="minimal"を使用する。 - 後処理で思考内容をフィルタリングする (API が thought フィールドを返してきた場合)。
APIYI (apiyi.com) を通じて迅速に Gemini 3.0 Flash モデルに切り替えることをお勧めします。最新バージョンをサポートしているため、このようなバグを回避できます。
Q2: 現在使用しているのが Gemini 2.5 か 3.0 かを判断するにはどうすればよいですか?
方法 1: モデル名を確認する
- Gemini 2.x: 名称に
2.5-flash、2-flash-liteなどが含まれます。 - Gemini 3.x: 名称に
3.0-flash、3-pro、gemini-3-flashなどが含まれます。
方法 2: テストリクエストを送信する
# thinking_level のみを渡してレスポンスを観察する
response = client.chat.completions.create(
model="your-model-name",
messages=[{"role": "user", "content": "test"}],
extra_body={"thinking_level": "low"}
)
# 400 エラーが返り、thinking_level をサポートしていない旨のメッセージが出れば、それは Gemini 2.5 です。
方法 3: API レスポンスヘッダーを確認する
一部の API 実装では、レスポンスヘッダーに X-Model-Version フィールドが含まれており、モデルバージョンを直接識別できる場合があります。
Q3: Gemini 3.0 の thinking_level の各段階では、具体的にどのくらいのトークンを消費しますか?
Google 公式は、異なる thinking_level に対応する正確なトークン予算を公開していませんが、以下のガイドラインを示しています:
| thinking_level | 相対コスト | 相対的な遅延 | 推理の深さ |
|---|---|---|---|
| minimal | 最低 | 最低 | ほとんど思考なし |
| low | 低 | 低 | 浅い推理 |
| medium | 中程度 | 中程度 | 中程度の推理 |
| high | 高 | 高 | 深い推理 |
実測のアドバイス:
- APIYI (apiyi.com) プラットフォームを利用して、異なるレベルでの実際のトークン消費量を比較してください。
- 同じプロンプトを使用し、low/medium/high をそれぞれ呼び出して料金の差を確認してください。
- 実際のビジネスシーン(回答の質 vs コスト)に合わせて適切なレベルを選択してください。
Q4: Gemini 3.0 で thinking_budget を強制的に使用することはできますか?
可能ですが、お勧めしません。
Gemini 3.0 は後方互換性のために依然として thinking_budget パラメータを受け入れますが、公式ドキュメントには以下のように明記されています:
"While
thinking_budgetis accepted for backwards compatibility, using it with Gemini 3 Pro may result in suboptimal performance."
(後方互換性のためにthinking_budgetは受け入れられますが、Gemini 3 Pro で使用すると最適なパフォーマンスが得られない可能性があります。)
理由:
- Gemini 3.0 の内部推理メカニズムは
thinking_levelに最適化されています。 thinking_budgetを強制的に使用すると、新バージョンの推理戦略をバイパスしてしまう可能性があります。- その結果、レスポンスの質の低下や遅延の増加を招く恐れがあります。
正しい対応:
thinking_levelパラメータへの移行を進めてください。- 前述の「案 3」のパラメータ適応関数を参考に、動的に正しいパラメータを選択するようにしてください。
まとめ
Gemini API の thinking_budget と thinking_level に関するエラーの主なポイントは以下の通りです:
- 引数の排他性: Gemini 2.5 は
thinking_budgetを使用し、Gemini 3.0 はthinking_levelを使用します。これらを同時に指定することはできません。 - モデルの識別: モデル名からバージョンを判断します。2.5 シリーズには
thinking_budgetを、3.0 シリーズにはthinking_levelを使用してください。 - 動的な適応: ハードコーディングを避け、モデル名に応じて自動的に適切な引数を選択するアダプター関数を使用するのがベストプラクティスです。
- 思考署名(Thinking Signature): Gemini 3.0 では思考署名メカニズムが導入されました。多段階の複雑な推論が必要なシーンでは、推論チェーンを維持するためにこの署名を渡す必要があります。
- 移行の推奨: Gemini 2.5 は 2026 年 3 月 3 日にサポート終了(退役)が予定されています。お早めに 3.0 シリーズへの移行を検討することをお勧めします。
APIYI(apiyi.com)を利用すれば、さまざまな思考モード設定の実際の効果を素早く検証できます。Gemini 全シリーズのモデルに対応し、統一されたインターフェースと柔軟な料金体系を提供しているため、比較テストから本番環境へのデプロイまでスムーズに行えます。
著者: APIYI 技術チーム | 技術的なご質問や、より詳細な AI モデル導入ソリューションについては、APIYI(apiyi.com)をご覧ください。