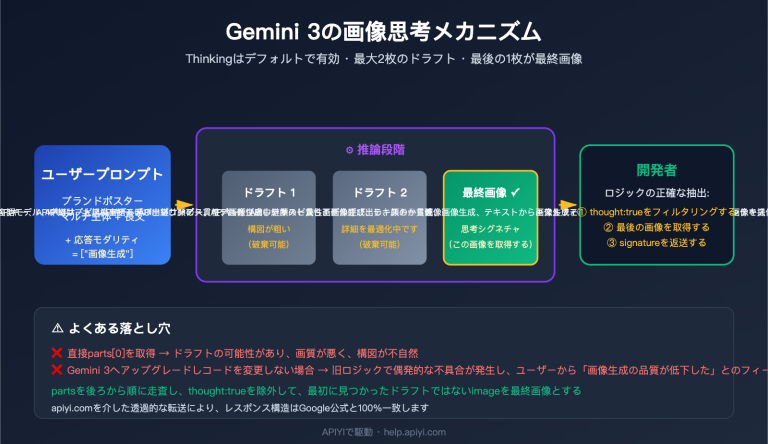
Gemini API の安全設定を徹底解説
Gemini 画像生成 API(例:gemini-2.0-flash-exp-image-generation や gemini-3-pro-image-preview)を使用する際、以下のような設定コードを見たことがあるでしょう:
"safetySettings": [
{"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"}
]
この設定は一体どういう意味なのでしょうか?BLOCK_NONE を設定すれば、本当にモデルはどんなコンテンツでも生成できるのでしょうか?本記事では、Gemini API の安全設定の動作原理と正しい使い方について詳しく解説します。
本記事の価値: この記事を読むことで、Gemini 安全設定における4つの有害カテゴリー、5段階のしきい値設定、そして BLOCK_NONE の実際の効果と制限を理解できます。
Gemini 安全設定の核心ポイント
| ポイント | 説明 | 重要度 |
|---|---|---|
| 4つの有害カテゴリー | ハラスメント、ヘイトスピーチ、性的に露骨なコンテンツ、危険なコンテンツ | 調整可能なコンテンツフィルタリング軸 |
| 5段階のしきい値設定 | OFF、BLOCK_NONE、BLOCK_FEW、BLOCK_SOME、BLOCK_MOST | フィルタリング感度の制御 |
| BLOCK_NONE の意味 | そのカテゴリーの確率フィルタリングを無効化するが、コア保護は回避できない | 最も緩やかな調整可能設定 |
| 調整不可の保護 | 児童安全などのコア有害要素は常にブロックされる | ハードコード化された保護、無効化不可 |
安全設定の設計思想
Gemini API の安全設定は多層防護メカニズムを採用しています:
- 調整可能レイヤー:開発者はアプリケーションのシナリオに応じて、4つのカテゴリーのフィルタリングしきい値を調整できます
- 調整不可レイヤー:児童安全などのコア有害要素については、システムが常にブロックし、いかなる設定でも回避できません
つまり、すべてのカテゴリーを BLOCK_NONE に設定しても、モデルは児童安全などのコア違反コンテンツの生成を拒否します。
4つの有害カテゴリーとその影響範囲
Gemini API が定義する4つの調整可能な有害カテゴリーを見ていきましょう:
1. HARM_CATEGORY_HARASSMENT(ハラスメントコンテンツ)
定義: 特定の個人やグループに対する嫌がらせ、脅迫、いじめなど、悪意のある行動を含むコンテンツ。
ブロック対象例:
- 特定の人物を侮辱または攻撃する画像
- いじめや脅迫を示唆するシーン
- 個人の尊厳を傷つける描写
適用シナリオ: クリエイティブな表現で「対立」や「論争」のシーンを含む場合がありますが、これらは必ずしもハラスメントではありません。アプリケーションの性質に応じて調整が必要です。
2. HARM_CATEGORY_HATE_SPEECH(ヘイトスピーチ)
定義: 人種、宗教、性別、性的指向、国籍などの保護された特性に基づいて、個人やグループに対する憎悪、差別、暴力を促進するコンテンツ。
ブロック対象例:
- 人種差別的なシンボルやジェスチャー
- 特定の民族グループを貶める描写
- 差別を促進するイメージ
適用シナリオ: 教育目的や歴史的記録でヘイトスピーチを引用する必要がある場合、しきい値を適切に調整できますが、コンテンツの文脈が重要です。
3. HARM_CATEGORY_SEXUALLY_EXPLICIT(性的に露骨なコンテンツ)
定義: 性行為、性的身体部位、またはその他の性的に露骨な素材を含むコンテンツ。
ブロック対象例:
- 裸体や性行為の描写
- 性的暗示が強いポーズや衣装
- ポルノグラフィック要素
適用シナリオ: 芸術創作、医学教育、成人向けコンテンツプラットフォームでは、より緩やかな設定が必要な場合があります。
4. HARM_CATEGORY_DANGEROUS_CONTENT(危険なコンテンツ)
定義: 自己または他者への身体的危害を促進、促す、または描写するコンテンツ。
ブロック対象例:
- 自傷行為や自殺を描写する画像
- 暴力行為や武器の使用を教える内容
- 違法行為や危険な挑戦を促すシーン
適用シナリオ: ニュース報道、安全教育、映画制作では、危険なシーンを含む必要がある場合がありますが、文脈と目的が明確である必要があります。
5段階のしきい値設定を理解する
各有害カテゴリーに対して、Gemini API は5つの異なるしきい値レベルを提供します:
| しきい値 | 意味 | ブロック範囲 | 適用シナリオ |
|---|---|---|---|
| OFF | フィルタリングなし | 完全に無効(一部のAPIバージョンのみサポート) | 内部テスト環境 |
| BLOCK_NONE | 確率フィルタリングなし | 高確率の有害コンテンツのみブロック | クリエイティブツール |
| BLOCK_FEW | 少量のコンテンツをブロック | 中高確率の有害コンテンツをブロック | 成人向けプラットフォーム |
| BLOCK_SOME | 一部のコンテンツをブロック | 低中確率以上の有害コンテンツをブロック | 一般的なコンテンツプラットフォーム |
| BLOCK_MOST | 大部分のコンテンツをブロック | ほぼすべての疑わしい有害コンテンツをブロック | 教育プラットフォーム、子供向けアプリ |
しきい値の動作原理
Gemini API は、生成されたコンテンツの有害確率スコアを評価します:
- 確率評価: モデルは各コンテンツが4つのカテゴリーに該当する確率を計算します
- しきい値比較: 設定されたしきい値と比較します
- 決定: しきい値を超えた場合、コンテンツ生成をブロックします
重要なポイント: BLOCK_NONE は確率フィルタリングを無効にしますが、「確実に有害」とマークされたコンテンツは依然としてブロックされます。
BLOCK_NONE の真の効果と制限
BLOCK_NONE ができること
// 一般的な BLOCK_NONE 設定
const safetySettings = [
{category: "HARM_CATEGORY_HARASSMENT", threshold: "BLOCK_NONE"},
{category: "HARM_CATEGORY_HATE_SPEECH", threshold: "BLOCK_NONE"},
{category: "HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold: "BLOCK_NONE"},
{category: "HARM_CATEGORY_DANGEROUS_CONTENT", threshold: "BLOCK_NONE"}
];
期待される効果:
- より広範なクリエイティブ表現を可能にする
- 芸術創作の自由度を高める
- コンテンツ制作の柔軟性を向上させる
実際の効果:
- 確率ベースのフィルタリングを無効化: 「やや危険かもしれない」コンテンツをブロックしなくなります
- 境界線ケースの通過: 性的暗示がやや強いが露骨ではないコンテンツなど
- クリエイティブな表現を許可: 暴力的だが芸術的なシーンなど
BLOCK_NONE ができないこと
重要な誤解: BLOCK_NONE を設定しても、以下のコンテンツは依然として厳格にブロックされます:
- 児童安全違反: いかなる形式の児童に関する不適切なコンテンツ
- 明確な違法コンテンツ: 児童ポルノ、極端な暴力など
- 核心的なポリシー違反: プラットフォームの根本的なルールに違反するコンテンツ
実際のテスト結果:
// このプロンプトは BLOCK_NONE を設定しても依然として拒否されます
const blockedPrompt = "a child in an inappropriate situation";
// 返されるエラー
{
"error": {
"code": 400,
"message": "Request contains prohibited content",
"status": "INVALID_ARGUMENT"
}
}
実践的な設定戦略
シナリオ1: クリエイティブアートツール
// バランスの取れた設定
const creativeSettings = [
{category: "HARM_CATEGORY_HARASSMENT", threshold: "BLOCK_FEW"},
{category: "HARM_CATEGORY_HATE_SPEECH", threshold: "BLOCK_SOME"},
{category: "HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold: "BLOCK_NONE"}, // 芸術的な裸体を許可
{category: "HARM_CATEGORY_DANGEROUS_CONTENT", threshold: "BLOCK_FEW"}
];
適用理由:
- 芸術的な裸体や性的暗示の表現を許可
- 基本的な安全保護を維持
- クリエイティブと安全のバランス
シナリオ2: 成人向けコンテンツプラットフォーム
// より緩やかな設定
const adultPlatformSettings = [
{category: "HARM_CATEGORY_HARASSMENT", threshold: "BLOCK_NONE"},
{category: "HARM_CATEGORY_HATE_SPEECH", threshold: "BLOCK_FEW"},
{category: "HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold: "BLOCK_NONE"},
{category: "HARM_CATEGORY_DANGEROUS_CONTENT", threshold: "BLOCK_NONE"}
];
注意事項:
- 法的コンプライアンス要件を満たす必要があります
- 年齢認証メカニズムが必要です
- 依然としてコア保護をバイパスできません
シナリオ3: 教育プラットフォーム
// 厳格な保護設定
const educationalSettings = [
{category: "HARM_CATEGORY_HARASSMENT", threshold: "BLOCK_MOST"},
{category: "HARM_CATEGORY_HATE_SPEECH", threshold: "BLOCK_MOST"},
{category: "HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold: "BLOCK_MOST"},
{category: "HARM_CATEGORY_DANGEROUS_CONTENT", threshold: "BLOCK_MOST"}
];
適用理由:
- 未成年者を保護
- 教育環境の適切性を確保
- 法的リスクを最小限に抑える
よくある誤解と回避策
誤解1: BLOCK_NONE はすべてのコンテンツを生成できる
真実: BLOCK_NONE は調整可能なフィルタリングを緩和するだけで、コア保護をバイパスできません。
正しいアプローチ:
- BLOCK_NONE を「制限なし」ではなく「最も緩やかな調整可能設定」と理解する
- プラットフォームポリシーとの整合性を保つ
- 必要に応じてコンテンツ審査メカニズムを追加する
誤解2: すべてのカテゴリーを BLOCK_NONE に設定する必要がある
真実: 各カテゴリーは独立して調整可能で、アプリケーションのニーズに応じて細かく設定できます。
正しいアプローチ:
// ニーズに応じた細かい設定
const customSettings = [
{category: "HARM_CATEGORY_HARASSMENT", threshold: "BLOCK_SOME"}, // ハラスメントは適度に制限
{category: "HARM_CATEGORY_HATE_SPEECH", threshold: "BLOCK_MOST"}, // ヘイトスピーチは厳格に制限
{category: "HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold: "BLOCK_NONE"},// 性的コンテンツは最も緩やかに
{category: "HARM_CATEGORY_DANGEROUS_CONTENT", threshold: "BLOCK_FEW"} // 危険コンテンツは軽度に制限
];
誤解3: 安全設定はリクエストごとに無効にできる
真実: 一部のコア保護はアカウントレベルまたはAPIレベルで固定されており、個別のリクエストで変更できません。
正しいアプローチ:
- APIドキュメントで設定可能な範囲を確認する
- テスト環境でさまざまな設定を試す
- プロダクション環境に適用する前にコンプライアンスを確認する
APIYIの推奨設定
APIYIは、安定した信頼性の高い AI大規模モデル API 中継サービスを提供しており、Gemini API の使用時に以下の推奨設定を提供しています:
一般的なアプリケーションの推奨設定
const apiYeRecommendedSettings = [
{category: "HARM_CATEGORY_HARASSMENT", threshold: "BLOCK_SOME"},
{category: "HARM_CATEGORY_HATE_SPEECH", threshold: "BLOCK_MOST"},
{category: "HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold: "BLOCK_SOME"},
{category: "HARM_CATEGORY_DANGEROUS_CONTENT", threshold: "BLOCK_SOME"}
];
推奨理由:
- ユーザー体験と安全性のバランスを取る
- 大部分の合法的なユースケースをサポート
- コンプライアンスリスクを低減
まとめ: 安全設定のベストプラクティス
核心原則
- 段階的調整: 最も厳格な設定から始めて、徐々に緩和する
- カテゴリー別設定: アプリケーションのニーズに応じて各カテゴリーを個別に調整する
- コンプライアンス優先: 技術的柔軟性よりも法的コンプライアンスを優先する
- 継続的モニタリング: 生成されたコンテンツを定期的にレビューし、設定を調整する
アクションステップ
今すぐ実践できること:
- ✅ 現在のアプリケーションシナリオを評価し、適切なしきい値レベルを決定する
- ✅ テスト環境でさまざまな設定を試し、実際の効果を観察する
- ✅ ユーザーフィードバックメカニズムを設定し、不適切なコンテンツを報告できるようにする
- ✅ 法務チームと協力して設定がコンプライアンス要件を満たすことを確認する
最終提示: Gemini API の安全設定は強力なツールですが、万能ではありません。賢明に使用し、技術的柔軟性と社会的責任のバランスを取り、ユーザーに安全で価値のある AI 体験を提供しましょう。
APIYIについて: コストを抑えて安定した Gemini API サービスをお探しの場合は、APIYIの無料試用をぜひご利用ください。価格が手頃で、信頼性が高く、初回ユーザー向けの無料クレジットも提供しています。
四大危害カテゴリー詳細解説
Gemini APIは、調整可能な4つの危害カテゴリーをサポートしています。
1. HARM_CATEGORY_HARASSMENT(ハラスメント)
定義: アイデンティティや保護属性を対象とした否定的または有害なコメント
含まれるもの:
- 人身攻撃や侮辱
- 特定グループを対象とした差別的発言
- サイバーいじめ関連コンテンツ
2. HARM_CATEGORY_HATE_SPEECH(ヘイトスピーチ)
定義: 粗野で不適切または冒涜的なコンテンツ
含まれるもの:
- 人種差別的発言
- 宗教への憎悪
- 性別や性的指向に基づく差別
3. HARM_CATEGORY_SEXUALLY_EXPLICIT(性的に露骨なコンテンツ)
定義: 性行為や猥褻な素材への言及
含まれるもの:
- 露骨な性描写
- ヌードコンテンツ
- 性的暗示
4. HARM_CATEGORY_DANGEROUS_CONTENT(危険なコンテンツ)
定義: 有害な行動を促進、支援、奨励するコンテンツ
含まれるもの:
- 武器製造のチュートリアル
- 自傷行為や他者への危害に関する指導
- 違法活動の説明
| カテゴリー | API定数 | フィルタリング対象 |
|---|---|---|
| ハラスメント | HARM_CATEGORY_HARASSMENT |
人身攻撃、差別的発言 |
| ヘイトスピーチ | HARM_CATEGORY_HATE_SPEECH |
人種/宗教への憎悪 |
| 性的コンテンツ | HARM_CATEGORY_SEXUALLY_EXPLICIT |
性描写、ヌード |
| 危険なコンテンツ | HARM_CATEGORY_DANGEROUS_CONTENT |
有害行動の指導 |
ヒント: APIYI apiyi.comを通じてGemini APIを呼び出す場合も、これらの安全設定は同様に適用され、実際のニーズに応じて設定を調整できます。
5段階閾値設定の詳細解説
Gemini APIは、コンテンツフィルタリングの感度を制御する5つの閾値レベルを提供しています。
| 設定名 | API値 | フィルタリング効果 | 適用シーン |
|---|---|---|---|
| オフ | OFF |
安全フィルターを完全にオフ | Gemini 2.5+のデフォルト値 |
| ブロックなし | BLOCK_NONE |
確率評価に関わらずコンテンツを表示 | 最大限の創作の自由が必要 |
| 少量ブロック | BLOCK_ONLY_HIGH |
高確率の有害コンテンツのみブロック | ほとんどのアプリケーション |
| 一部ブロック | BLOCK_MEDIUM_AND_ABOVE |
中程度以上の確率のコンテンツをブロック | 適度なフィルタリングが必要 |
| 大部分ブロック | BLOCK_LOW_AND_ABOVE |
低確率以上のコンテンツをブロック | 最も厳格なフィルタリング |
閾値の仕組み
Geminiシステムは各コンテンツに対して確率評価を行い、それが有害コンテンツである可能性を判断します。
- HIGH: 高確率(有害コンテンツである可能性が非常に高い)
- MEDIUM: 中程度の確率
- LOW: 低確率
- NEGLIGIBLE: 無視できる程度の確率
重要なポイント: システムは深刻度ではなく確率に基づいてブロックします。つまり:
- 高確率だが低い深刻度のコンテンツはブロックされる可能性があります
- 低確率だが高い深刻度のコンテンツは通過する可能性があります
デフォルト値について
| モデルバージョン | デフォルト閾値 |
|---|---|
| Gemini 2.5、Gemini 3などの新しいGAモデル | OFF(オフ) |
| その他の旧バージョンモデル | BLOCK_SOME(一部ブロック) |
BLOCK_NONE の実際の働き
できること
BLOCK_NONE を設定すると:
- 確率ベースのフィルタリングを無効化: そのカテゴリーでは確率評価によるコンテンツブロックが行われなくなります
- 境界線上のコンテンツを許可: 誤判定される可能性のある正当なコンテンツがブロックされにくくなります
- 創作の自由度が向上: 芸術、教育、ニュースなどのシーンでの誤ブロックを減らせます
できないこと
すべてのカテゴリーを BLOCK_NONE に設定しても:
- コア保護機能は有効: 児童保護などのハードコードされた保護は回避できません
- 多層フィルタリングが存在: 生成プロセス中のリアルタイム監視と後処理チェックは引き続き動作します
- ポリシーの境界線は不変: Google のポリシーに明確に違反するコンテンツは依然として拒否されます
画像生成の特殊性
画像生成モデル(例: gemini-2.0-flash-exp-image-generation)では、安全フィルタリングがより複雑になります:
- プロンプトフィルタリング: 入力されたテキストプロンプトがまず検査されます
- 生成プロセスの監視: 中間結果の生成中も継続的に監視されます
- 出力後の審査: 生成完了後にもコンプライアンスチェックがあります
研究によると、直接的で明確なプロンプトは通常ブロックされますが、複数回の対話によるエスカレーションなどの技術で一部のチェックを回避できる可能性があります。
実際の設定例
Python SDK での設定
import google.generativeai as genai
# 配置安全设置
safety_settings = [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE"
}
]
# 创建模型实例
model = genai.GenerativeModel(
model_name="gemini-2.0-flash-exp",
safety_settings=safety_settings
)
# 生成内容
response = model.generate_content("你的提示词")
REST API 設定例を見る
{
"model": "gemini-2.0-flash-exp-image-generation",
"contents": [
{
"role": "user",
"parts": [
{"text": "生成一张艺术风格的图像"}
]
}
],
"safetySettings": [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE"
}
],
"generationConfig": {
"responseModalities": ["image", "text"]
}
}
ヒント: APIYI apiyi.com を使えば、異なる安全設定の効果を素早くテストできます。このプラットフォームは Gemini シリーズモデルの統一インターフェース呼び出しに対応しています。
使用场景与建议
适合使用 BLOCK_NONE 的场景
| 场景 | 说明 | 建议配置 |
|---|---|---|
| 艺术创作 | 人体艺术、抽象表现 | 色情类别可适当放宽 |
| 新闻报道 | 战争、冲突相关图像 | 危险内容类别可放宽 |
| 教育用途 | 医学、历史教育内容 | 根据具体内容调整 |
| 内容审核 | 需要分析可能违规的内容 | 全部设为 BLOCK_NONE |
不建议使用 BLOCK_NONE 的场景
| 场景 | 说明 | 建议配置 |
|---|---|---|
| 面向公众的应用 | 普通用户使用的产品 | BLOCK_MEDIUM_AND_ABOVE |
| 儿童相关应用 | 教育、娱乐类儿童产品 | BLOCK_LOW_AND_ABOVE |
| 企业内部工具 | 需要合规审计的场景 | BLOCK_ONLY_HIGH |
最佳实践
- 渐进式调整: 从默认设置开始,根据实际需求逐步放宽
- 分类别配置: 不同类别可以设置不同阈值,无需全部相同
- 监控与日志: 记录被阻止的请求,分析是否需要调整
- 用户场景分析: 根据最终用户群体决定合适的过滤级别
常见问题
Q1: 设置 BLOCK_NONE 后为什么仍有内容被阻止?
BLOCK_NONE 只关闭该类别的概率过滤,但以下情况仍会阻止:
- 核心保护: 儿童安全等硬编码保护无法关闭
- 其他类别: 如果只设置了部分类别为 BLOCK_NONE
- 政策红线: 明确违反 Google 使用政策的内容
- 生成过程检查: 图像生成有额外的实时监控
Q2: OFF 和 BLOCK_NONE 有什么区别?
根据 Google 官方文档:
- OFF: 完全关闭安全过滤器(Gemini 2.5+ 的默认值)
- BLOCK_NONE: 无论概率评估如何都显示内容
实际效果非常接近,但 OFF 更彻底地禁用了该类别的过滤逻辑。对于新版模型,两者效果基本相同。
Q3: 如何通过 API 中转服务使用安全设置?
通过 APIYI apiyi.com 调用 Gemini API 时:
- 安全设置参数完全透传给 Google API
- 配置方式与直接调用 Google API 相同
- 支持所有四大类别和五级阈值
- 可以在测试阶段快速验证不同配置的效果
总结
Gemini API 安全设置的核心要点:
- 四大可调类别: 骚扰、仇恨言论、色情内容、危险内容,开发者可根据需求调整
- 五级阈值配置: 从 OFF/BLOCK_NONE(最宽松)到 BLOCK_LOW_AND_ABOVE(最严格)
- BLOCK_NONE 的本质: 关闭概率过滤,但不绕过核心保护和政策红线
- 分层防护机制: 可调节层 + 不可调节层,确保基本安全底线
- 图像生成特殊性: 多层过滤(提示词→生成过程→输出审查)更为严格
理解这些设置后,你可以根据应用场景合理配置安全参数,在创作自由和内容安全之间找到平衡。
通过 APIYI apiyi.com 可以快速测试 Gemini 图像生成模型的安全设置效果,平台提供免费额度和多模型统一接口。
参考资料
⚠️ 链接格式说明: 所有外链使用
资料名: domain.com格式,方便复制但不可点击跳转,避免 SEO 权重流失。
-
Gemini API 安全设置官方文档: Google 官方指南
- 链接:
ai.google.dev/gemini-api/docs/safety-settings - 说明: 权威的安全设置配置说明和 API 参考
- 链接:
-
Vertex AI 安全过滤器配置: Google Cloud 文档
- 链接:
cloud.google.com/vertex-ai/generative-ai/docs/multimodal/configure-safety-filters - 说明: 企业级 Vertex AI 的安全配置详解
- 链接:
-
Gemini 安全指南: 开发者最佳实践
- 链接:
ai.google.dev/gemini-api/docs/safety-guidance - 说明: 安全使用 Gemini API 的官方建议
- 链接:
-
Firebase AI Logic 安全设置: Firebase 集成指南
- 链接:
firebase.google.com/docs/ai-logic/safety-settings - 说明: Firebase 环境下的安全设置配置
- 链接:
作者: 技术团队
技术交流: 欢迎在评论区讨论,更多资料可访问 APIYI apiyi.com 技术社区