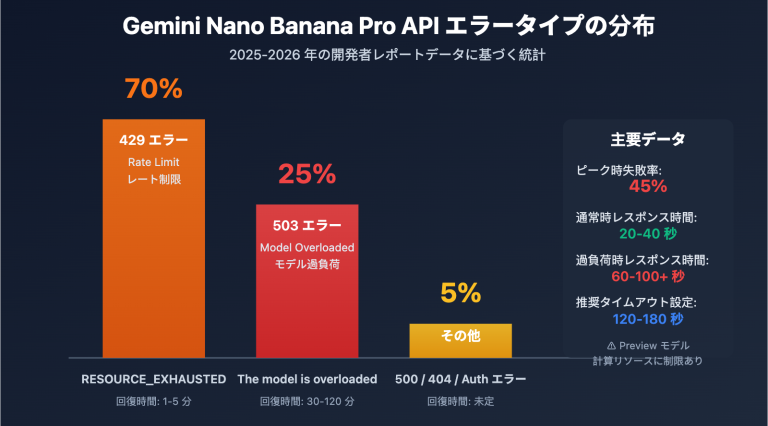
gpt-image-2 を呼び出す際に、あるユーザーが以下のようなエラーに遭遇しました。これは2026年4月にgpt-image-2がリリースされて以来、開発者コミュニティで最も頻繁に発生しているエラーの一つです。
{
"status_code": 400,
"error": {
"message": "Your request was rejected by the safety system. ... safety_violations=[violence].",
"type": "shell_api_error",
"code": "moderation_blocked"
}
}
多くの人は「とりあえずリトライすればいいや」と考えがちですが、これは間違った対応です。同じプロンプトで100回リトライしても、依然としてブロックされます。gpt-image-2 の moderation_blocked エラーの本質は、リクエストがモデルに到達する前に、前段の安全フィルター(モデレーション)によって能動的に拒否されていることにあります。リトライは単なる時間の無駄です。
本記事では、この実際のエラー事例を出発点として、gpt-image-2 の安全審査メカニズム(2段階フィルタリングアーキテクチャ)、7つのトリガーシーン、5つのプロンプト最適化戦略、そしてエンジニアリングの観点からエラー率を低減させるための実践的な手法を解説します。読み終える頃には、ご自身のプロンプトテンプレートを即座にコンプライアンス監査し、違反率を80%以上削減できるようになるはずです。

gpt-image-2 の moderation_blocked エラーの本質
このエラーを解決するには、まずそれが「何であるか」を理解する必要があります。多くの開発者はこれを「モデルが回答を拒否した」と捉えますが、実際は全く異なります。
gpt-image-2 の moderation_blocked エラーに関する重要な事実
| 事実 | 説明 | エンジニアリング上の意味 |
|---|---|---|
| HTTP 400(クライアント側) | リクエストレベルのエラーであり、サーバー障害ではない | リトライは無効。プロンプトの修正が必須 |
| モデル未到達 | 前段の分類器によってブロックされている | 課金されず、トークンも消費されない |
code=moderation_blocked |
標準化されたエラーコード。プログラムで識別可能 | 自動書き換えパイプラインの構築に適している |
safety_violations=[…] |
違反カテゴリが配列で示される | 修正が必要な箇所をピンポイントで特定可能 |
| 同一プロンプトで100%再現 | 確定的な結果であり、確率的な事象ではない | プロンプトを書き換えない限り復旧しない |
gpt-image-2 エラーの2段階安全審査メカニズム
gpt-image-2 のエラーを理解するには、OpenAI の2段階安全フィルタリングアーキテクチャを把握する必要があります。
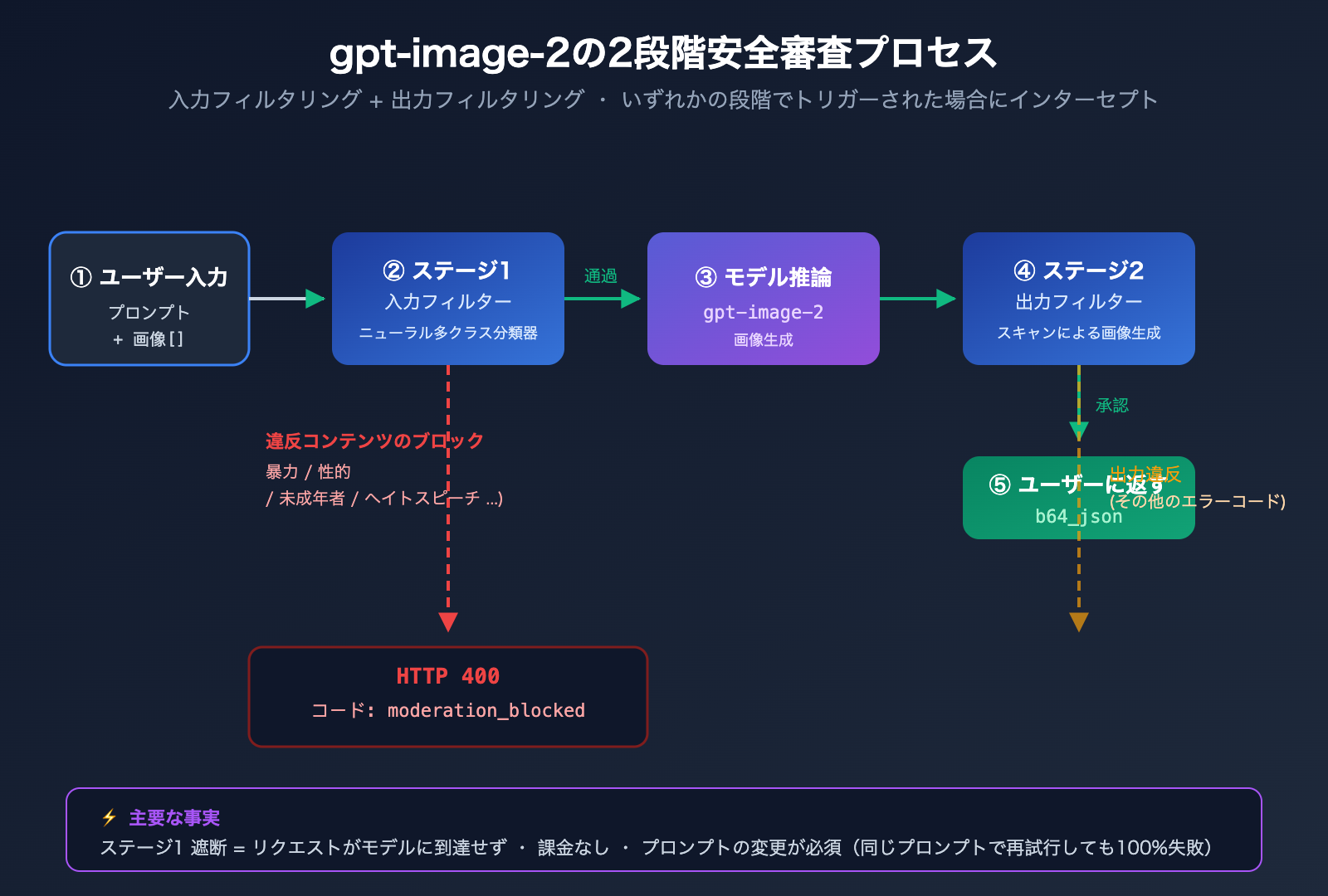
安全な通信経路には、実際には2つの関門が存在します。
Stage 1 · 入力フィルター(Input Filter):
- プロンプトテキストをスキャン
- アップロードされたすべての参照画像をスキャン(
/v1/images/editsを呼び出す場合) - ニューラルマルチクラス分類器を使用
- ここが
moderation_blockedを引き起こす場所です。
Stage 2 · 出力フィルター(Output Filter):
- モデルが生成した画像をスキャン
- 生成内容が規約に違反している場合、ブロックされる可能性がある
- 通常、異なるエラーコード(
moderation_blockedではないもの)が返されます。
ユーザーの事例は Stage 1 の入力フィルター でトリガーされたため、モデルの推論段階には全く到達していません。これが、エラー応答が非常に高速(通常1秒未満)である理由です。キューにも並ばず、GPUも消費していません。
gpt-image-2 エラーのバックエンドによる違い
見落とされがちな事実として、バックエンドのチャネルによって審査の厳しさが異なるという点があります。OpenAI 直結と Azure OpenAI では、同じプロンプトでもトリガー率に顕著な差があり、一般的に Azure の方が厳格です。ユーザーの事例で「Azure support ticket に連絡してください」というメッセージが表示されたのは、このリクエストが Azure バックエンドのフィルターにルーティングされていたためです。
🎯 チャネル選択のアドバイス:同じプロンプトを異なるチャネルでテストしている場合、一部のチャネルでブロックされ、一部で通過するのは正常な挙動です。検証には APIYI (apiyi.com) の OpenAI 公式中継チャネルを使用することをお勧めします。このチャネルは OpenAI 公式のフィルタリングポリシーを適用しており、トリガー率は OpenAI 直結と一致するため、ベースラインの比較に適しています。
gpt-image-2 エラー発生の7つの主要シナリオ
OpenAIが公開した「ChatGPT Images 2.0 System Card」では、エラーが発生しやすい7つの高頻度シナリオが明確に示されています。これら7つのシナリオを理解することは、ガイドラインに準拠したプロンプトを作成するための基本となります。
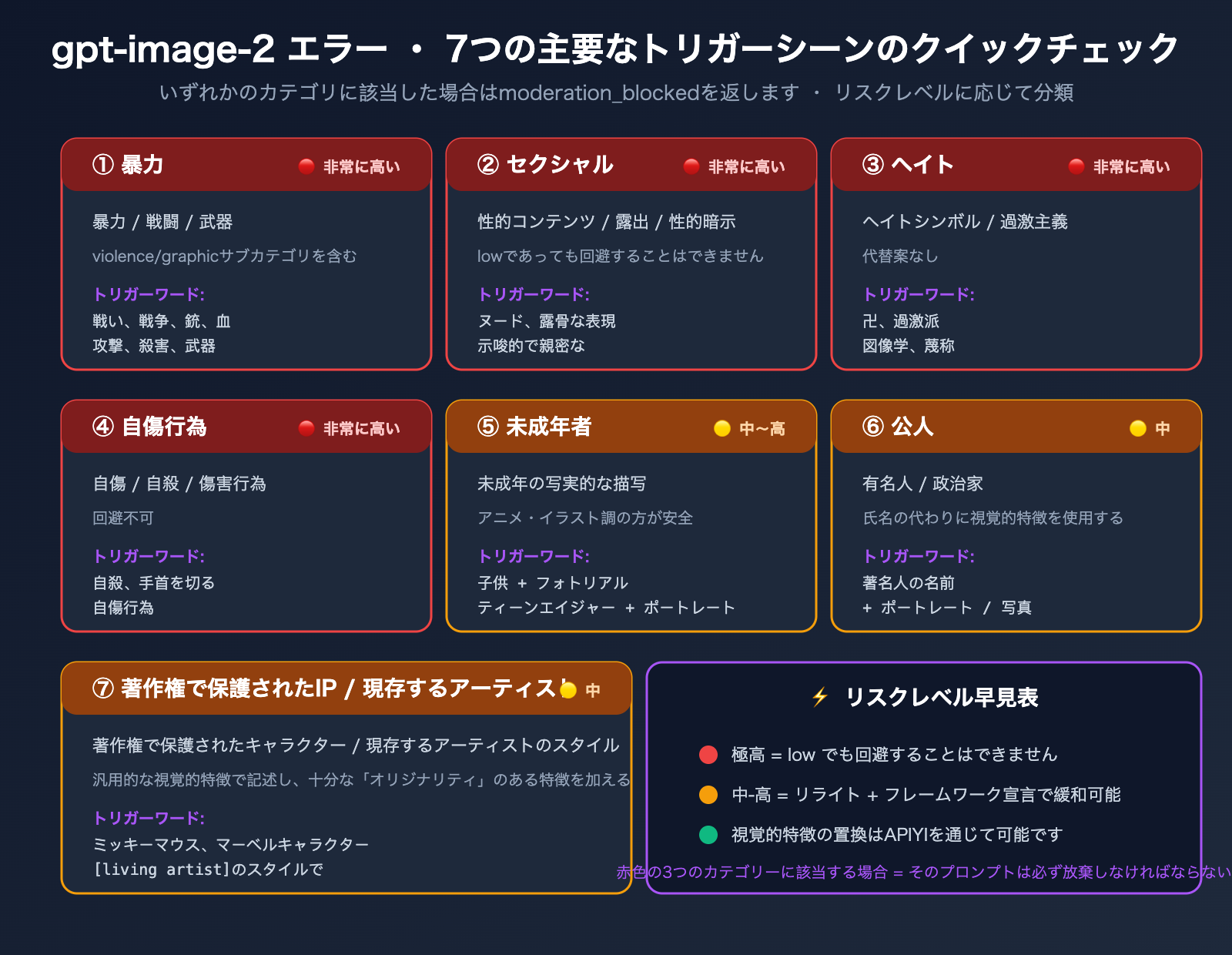
gpt-image-2 エラー発生シナリオ一覧表
| カテゴリ | 高リスクなトリガーワード例 | リスクレベル |
|---|---|---|
| Violence(暴力) | fight、war、weapon、blood、shoot、punch、kill | 🔴 高 |
| Violence/Graphic(過激な暴力) | gore、gruesome、mutilation、severed | 🔴 極高 |
| Sexual(性的な内容) | nude、explicit、suggestive、intimate poses | 🔴 極高 |
| Hate Symbols(ヘイトシンボル) | swastika、特定の過激派の図像 | 🔴 極高 |
| Self-harm(自傷行為) | suicide、cut wrists、harming oneself | 🔴 極高 |
| Minors(未成年者の写実的描写) | child + photorealistic の組み合わせ | 🟡 中-高 |
| Public Figures(公人) | 政治家、著名人の名前 | 🟡 中 |
| Copyrighted IP(著作権保護されたIP) | ディズニーキャラクター、マーベルキャラクター、著名なIP名 | 🟡 中 |
| Living Artists(存命のアーティストのスタイル) | "in the style of [存命アーティスト名]" | 🟡 中 |
gpt-image-2 の violence サブカテゴリの分解
safety_violations=[violence] は、実際には以下の2つのサブカテゴリに対応しており、現場では混同されがちです。
violence → 一般的な暴力の描写(動作、衝突、武器の存在)
violence/graphic → 過激で血生臭い暴力の詳細
プロンプトがこれらサブカテゴリのいずれかをトリガーすると、safety_violations=[violence] が返されます。つまり、「ライフルを持った兵士」のような比較的ニュートラルな記述であっても、プロンプト全体の文脈によって分類器が「暴力」カテゴリと判断し、エラーになる可能性があるということです。
ユーザー事例の深掘り:violence エラーの根本原因
冒頭で触れた実際のエラーに戻りましょう。safety_violations=[violence] というフィールドは、暴力に関するコンテンツとしてブロックされたことを示していますが、具体的にどの単語がトリガーになったのでしょうか? 以下に、体系的な診断のヒントをまとめました。
gpt-image-2 で violence がトリガーされる単語リスト
コミュニティからのフィードバックや実測に基づくと、以下の単語は violence カテゴリのブロック率を大幅に高めます(これらに限定されるわけではありません)。
| トリガーの種類 | 高頻度の違反ワード | 安全な代替案 |
|---|---|---|
| 武器の名称 | gun, rifle, sword, knife, weapon | ceremonial prop, movie prop, decorative blade |
| 暴力的な動作 | fight, attack, shoot, stab, punch | dynamic cinematic action, dramatic standoff |
| 戦争の文脈 | war, battle, soldier, combat | heroic struggle, historical reenactment |
| 流血/傷害 | blood, wound, scar, gore | red splatter, dramatic shadow, weathered |
| 爆発/破壊 | explosion, destruction, debris | dramatic light burst, swirling particles |
gpt-image-2 エラーの診断フロー
プロンプトが violence カテゴリでブロックされた場合、以下の順序で確認を行ってください。
- 明示的な暴力ワードの確認:プロンプト内に上記のトリガーワードが含まれていないかスキャンする。
- 動詞の強さを確認:fight や attack といった動作動詞を、状態を表す描写に置き換えてみる。
- 参照画像を確認(編集シナリオの場合):アップロードした画像自体に暴力的な要素が含まれていないか。
- 全体的な文脈を確認:個別の高リスク単語がなくても、全体の描写が暴力的なシーンを構成しているとトリガーされる。
- フレームワークの宣言を追加:プロンプトの冒頭に "movie still" や "theatrical scene" などを追加してみる。
gpt-image-2 エラーにおけるリクエスト ID の用途
エラーメッセージに含まれる request id: 2026042723155331083492939703753 は、単なる飾りではありません。これはログを特定するための唯一の証拠です。正規のルートで接続している場合、この ID を使ってプラットフォームの技術サポートに具体的なブロック理由を問い合わせることができます。
💡 診断のアドバイス:
moderation_blockedエラーが発生したすべてのリクエスト ID と元のプロンプトを保存し、社内用の「違反サンプルライブラリ」を作成して、自動書き換えルールのトレーニングに役立てましょう。APIYI (apiyi.com) コンソールからリクエストログをエクスポートし、月次のコンプライアンス監査を行うことで、チーム内で最も頻発しているブロックパターンを特定することをお勧めします。
gpt-image-2 エラーを回避する 5 つのプロンプト最適化戦略
実戦で検証済みの、gpt-image-2 のエラー率を下げる 5 つの戦略を紹介します。優先度が高い順に並べているため、この順番で適用することをお勧めします。
戦略 1:プロンプトの脱感作(Desensitization)による書き換え
最も一般的で効果的な戦略です。高リスクな単語を、視覚的に同等な中立的な表現に置き換えます。核心となる原則は、視覚的な効果を維持しつつ、暴力的な指向を取り除くことです。
# ✗ violence 判定でブロック
- "Two warriors fighting with swords, blood splatter on the ground, war scene"
# ✓ 脱感作して通過
+ "Two armored figures in dramatic standoff with ceremonial blades, red light reflections on the stone floor, cinematic composition, theatrical scene"
変更点:
fighting→dramatic standoffswords→ceremonial bladesblood splatter→red light reflectionswar scene→theatrical scene
戦略 2:実在する主体の置き換え
実在の公人、有名人、著作権で保護されたキャラクターを直接引用するのを避け、視覚的な特徴の描写に置き換えます。
# ✗ public_figures または copyrighted_ip 判定でブロック
- "A portrait of [有名人の名前] in business suit"
- "Mickey Mouse riding a bicycle in Paris"
# ✓ 安全な描写
+ "A portrait of a charismatic 30-year-old Asian businesswoman with shoulder-length black hair, wearing a tailored navy suit"
+ "A friendly anthropomorphic mouse character with round black ears and red shorts, riding a bicycle near the Eiffel Tower"
注意:完全な「スタイル描写」であっても、著作権キャラクターのシーンではブロックされる可能性があります。審査エンジンは単なる文字の一致だけでなく、視覚的な類似性に基づいて判断するためです。十分な「オリジナリティ」のある特徴を加えることを推奨します。
戦略 3:シーンのフレームワーク宣言
プロンプトの冒頭に明確な芸術的・創作的なフレームワークを加え、分類器に対してこれが現実ではなく創作物であることを示します。
- "Soldiers running across a battlefield"
+ "Movie still from a 1940s war drama: soldiers running across a foggy field, sepia tones, film grain texture"
- "Action scene with gunfire"
+ "Video game cutscene illustration: heroic action sequence with stylized energy effects, comic book style"
よく使われるフレームワークワード:
movie still/film stilltheatrical scene/stage performancevideo game cutscene/game illustrationcomic book panel/manga stylehistorical reenactment/museum dioramaoil painting/watercolor sketch
戦略 4:多段階分解による生成
複雑でリスクの高いシーンは、複数のステップに分割して生成します。
# ステップ1:「スタイル参照画像」を生成(敏感な要素を含めない)
step1_prompt = "Cinematic storyboard sketch, dramatic composition, sepia tones, no text"
style_ref = client.images.generate(model="gpt-image-2", prompt=step1_prompt)
# ステップ2:スタイル描写 + 中立的な内容で最終画像を生成
step2_prompt = "Two figures in dramatic standoff, sepia tones, cinematic storyboard style, dust particles in the air"
final_image = client.images.generate(model="gpt-image-2", prompt=step2_prompt)
この「先にスタイル、後に内容」というワークフローは、1 回のプロンプトあたりの敏感度を大幅に下げることができます。
戦略 5:moderation パラメータの調整
API では、敏感度を制御する moderation パラメータが提供されています(OpenAI 系の画像モデルにのみ適用可能)。
response = client.images.generate(
model="gpt-image-2",
prompt="A dramatic action scene from a noir film",
moderation="low", # デフォルトは auto、low に下げることが可能
size="1024x1024",
quality="medium"
)
重要な注意点:
moderation: "low"は審査を無効にするものではなく、閾値を緩和するだけです。- 極めて危険なコンテンツ(性的、自傷行為、未成年者の写実的描写、ヘイトシンボルなど)は、low に設定してもブロックされます。
- low に設定しても
moderation_blockedが発生する場合は、完全に一線を越えているため、プロンプトを修正する必要があります。 - 一般ユーザー向け製品では、コンプライアンスリスクがあるため low の使用は慎重に行ってください。
🚀 クイックスタートのアドバイス:まずは戦略 1〜3(書き換え + 置き換え + フレームワーク宣言)を試してください。これで
moderation_blockedエラーの 80% 以上が解決します。APIYI (apiyi.com) の統合インターフェースを通じて、まずはmoderation: autoでプロンプトが本当に準拠しているかを確認し、その後に low に下げる必要があるか判断することをお勧めします。
gpt-image-2 エラー発生前後の実戦比較
ここでは、4つのリアルなシナリオを用いて、プロンプト最適化による具体的な効果を解説します。

gpt-image-2 エラー最適化事例 1:映画宣伝ポスター
# ✗ 最適化前(暴力表現に抵触)
- "An action movie poster featuring a male hero firing a gun at enemies, blood splatter background"
# ✓ 最適化後
+ "Cinematic action movie poster: a male protagonist in dramatic pose, holding a stylized prop, dynamic motion lines, red gradient background, theatrical lighting, film grain"
gpt-image-2 エラー最適化事例 2:ゲームキャラクター立ち絵
# ✗ 最適化前(暴力表現に抵触)
- "Fantasy warrior with bloody sword, severed enemy head at his feet, gore details"
# ✓ 最適化後
+ "Fantasy warrior video game character art: armored figure with ornate ceremonial blade, defeated stylized monster silhouette at his feet, JRPG illustration style, painterly textures"
gpt-image-2 エラー最適化事例 3:歴史教育用イラスト
# ✗ 最適化前(暴力表現に抵触)
- "World War II soldiers fighting in trenches with rifles and explosions"
# ✓ 最適化後
+ "Historical educational illustration depicting a 1940s European trench scene: figures in period uniforms, weathered terrain with dramatic atmospheric effects, sepia documentary style, museum diorama aesthetic"
gpt-image-2 エラー最適化事例 4:商業広告コンセプト画像
# ✗ 最適化前(著名人に抵触)
- "[著名人の名前] holding our coffee product in his usual style"
# ✓ 最適化後
+ "Charismatic 35-year-old male model with confident smile, casual blazer, warmly holding a takeaway coffee cup, modern minimalist café background, professional commercial photography"
gpt-image-2 のエラー率をエンジニアリングで下げるベストプラクティス
プロジェクトで毎日数千回 gpt-image-2 を呼び出す場合、手動でプロンプトを審査するのは現実的ではありません。以下に、エラー率を低減するためのエンジニアリング手法をいくつか紹介します。
gpt-image-2 エラーの事前検証フロー
画像生成 API を呼び出す前に、Moderations API を使用して事前検証を行います。
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("APIYI_KEY"),
base_url="https://api.apiyi.com/v1"
)
def safe_generate(prompt: str, max_rewrites: int = 3):
# ステップ 1: 事前検証
mod = client.moderations.create(input=prompt)
flagged = mod.results[0].flagged
categories = mod.results[0].categories
if flagged:
offending = [k for k, v in categories.model_dump().items() if v]
raise ValueError(f"プロンプトが事前検証に抵触: {offending}")
# ステップ 2: 実際の呼び出し
return client.images.generate(
model="gpt-image-2",
prompt=prompt,
size="1024x1024",
quality="medium"
)
事前検証により、高リスクなリクエストの 60〜70% を事前にブロックし、無駄な呼び出しを回避できます。
gpt-image-2 エラーの自動書き換えパイプライン
プロンプトテンプレートに対して、軽量な書き換え器を構築します。
SENSITIVE_REPLACEMENTS = {
r"\bgun\b": "ceremonial prop",
r"\bsword\b": "ornate ceremonial blade",
r"\bblood\b": "red splatter",
r"\bfight\b": "dramatic standoff",
r"\bwar\b": "heroic struggle",
r"\battack\b": "dynamic motion",
r"\bweapon\b": "stylized prop",
r"\bkill\b": "defeat",
r"\bshoot\b": "aim",
}
import re
def desensitize(prompt: str) -> str:
out = prompt
for pattern, replacement in SENSITIVE_REPLACEMENTS.items():
out = re.sub(pattern, replacement, out, flags=re.IGNORECASE)
if not out.lower().startswith(("movie still", "video game", "theatrical")):
out = "Cinematic movie still: " + out
return out
gpt-image-2 エラーのスマートリトライ実装
moderation_blocked が発生した場合の特別なリトライ戦略です。そのまま再試行するのではなく、必ずプロンプトを書き換える必要があります。
from openai import BadRequestError
def generate_with_rewrite(prompt: str, max_attempts: int = 3):
current = prompt
for attempt in range(max_attempts):
try:
return client.images.generate(
model="gpt-image-2",
prompt=current,
size="1024x1024"
)
except BadRequestError as e:
if "moderation_blocked" not in str(e):
raise # その他の 400 エラーはリトライしない
print(f"[{attempt+1}/{max_attempts}] 審査に抵触、感度低減リライトを適用...")
current = desensitize(current)
if attempt == max_attempts - 1:
# 最後の試行では moderation: low を設定
return client.images.generate(
model="gpt-image-2",
prompt=current,
moderation="low",
size="1024x1024"
)
raise RuntimeError("すべての書き換え戦略が失敗しました")
gpt-image-2 エラーのコンプライアンス監視ダッシュボード
本番環境では、違反に関する主要指標を記録する必要があります。
| 指標 | 用途 |
|---|---|
| 違反率(ブロック数/総リクエスト数) | 全体的な健全性の把握 |
safety_violations カテゴリ別の分布 |
高頻度な違反タイプの特定 |
| 違反を誘発したプロンプト Top 10 | 最も問題のあるテンプレートの特定 |
| 書き換え後の通過率 | 書き換え器の有効性評価 |
🎯 本番環境へのデプロイ推奨事項: 違反率を主要な SLO 指標に設定することをお勧めします。健全な本番環境の違反率は通常 2% 未満であるべきです。5% を超える場合は、プロンプトテンプレートにシステム的な問題がある可能性が高いです。APIYI (apiyi.com) コンソールのリクエストログを用いて日次分析を行い、違反が多いテンプレートを特定して集中的に書き換えることを推奨します。
gpt-image-2 エラーに関するよくある質問(FAQ)
Q1:gpt-image-2 で moderation_blocked エラーが出た場合、料金は発生しますか?
発生しません。安全フィルターがモデルにリクエストが到達する前にブロックしているため、トークンや GPU 時間は一切消費されません。OpenAI および APIYI はこのルールに従っています。もし請求書に該当する課金が記録されている場合は、直ちにプラットフォームへ連絡して確認してください。APIYI(apiyi.com)のコンソールから各 request_id ごとに課金記録を照合し、ブロックされたリクエストが 0 円であることを確認することをお勧めします。
Q2:gpt-image-2 でエラーが出た際、同じプロンプトで再試行しても無効なのはなぜですか?
安全フィルターは決定論的な仕組みであるためです。同じ入力に対する判定結果は常に一定であり、生成モデルのようなランダム性はありません。100 回再試行しても、100 回とも同じようにブロックされます。唯一の解決策は、プロンプトを修正することです。
Q3:gpt-image-2 の moderation: low 設定で、審査を完全にオフにできますか?
できません。 low は単に敏感度の閾値を下げ、中程度の敏感なコンテンツに対して寛容にするだけです。極めて危険なコンテンツ(性的なもの、自傷行為、未成年者の写実的な描写、ヘイトシンボル、政治指導者など)は、low 設定であってもブロックされます。low を「オフスイッチ」と考えるのは誤解です。
Q4:プロンプトは無害に見えるのに、なぜ gpt-image-2 でブロックされるのですか?
以下の 3 つの可能性が考えられます。
- 文脈による違反:単語自体は無害でも、組み合わせによって違反シーンを構成している。
- 多義語の誤判定:例えば「shoot a photo(写真を撮る)」が、暴力的な単語として誤判定されるケース。
- バックエンドの違い:Azure バックエンドは、OpenAI 直結の環境よりも厳格な場合があります。
2 番目のケースについては、「professional photography session(プロの撮影セッション)」といった文脈のフレームワークを追加することで改善されます。APIYI(apiyi.com)を通じて、こうした「誤判定」のサンプルを内部ナレッジベースに蓄積し、プロンプトテンプレートの改善素材として活用することをお勧めします。
Q5:gpt-image-2 でエラーが発生した際、どの単語がトリガーになったか確認できますか?
API は具体的なトリガー単語を返しません。 返されるのはカテゴリー(例:[violence])のみです。これは OpenAI の設計上の選択であり、回避策の作成に利用されるのを防ぐためです。具体的なトリガー単語を特定するには、プロンプトを半分に分割してそれぞれテストする「二分探索」を行う必要があります。
Q6:gpt-image-2 で参照画像(編集シーン)が違反と判定された場合はどうすればよいですか?
/v1/images/edits エンドポイントのステージ 1 では、プロンプトのテキストとアップロードされたすべての参照画像が同時にスキャンされます。参照画像自体が違反している場合は、以下を確認してください。
- 参照画像に暴力、性的な暗示、著作権のあるキャラクターなどが含まれていないか確認する。
- ローカルツールで参照画像を前処理する(トリミングや敏感な部分のぼかし処理など)。
- 実在の人物写真の場合、公人に関するポリシーに違反していないか確認する。
Q7:gpt-image-2 の違反カテゴリーは、OpenAI Moderations API のカテゴリーと一致しますか?
基本的には一致しますが、違いがあります。 Moderations API が返すカテゴリーはより詳細(11 種類)ですが、画像生成のブロックカテゴリーは比較的粗い(7〜9 種類)です。Moderations API を事前チェックツールとして使用するのは有効ですが、結果が完全に等価であると仮定しないでください。Moderations API を通過したプロンプトでも、画像生成側でブロックされることがあります。
Q8:gpt-image-2 のエラーに対して異議申し立てはできますか?
可能ですが、効果は限定的です。エラー情報に含まれる request_id を使用して、プラットフォームの技術サポートに調査を依頼できます。実務上の経験として、誤判定(医療や教育目的の中立的なコンテンツなど)であればホワイトリストに追加される可能性がありますが、実際にルールに抵触している場合は申し立ては無効です。APIYI(apiyi.com)のサポートチケットシステムから、完全な request_id と業務上の背景を添えて申請することで、処理効率を高めることができます。
まとめ:gpt-image-2 のエラーから、コンプライアンスに準拠した効率的なプロンプトへ
本記事の 7 つの章を通じて、gpt-image-2 のエラー処理体系を習得できたはずです。
- ✅ 本質を理解する ——
moderation_blockedはリクエストレベルの 400 エラーであり、課金されず、再試行しても無意味。 - ✅ アーキテクチャを把握する —— 2 段階の安全審査(ステージ 1:入力フィルター、ステージ 2:出力フィルター)。
- ✅ トリガーシーンに慣れる —— 7 つの主要違反カテゴリーと
violenceサブカテゴリーの詳細。 - ✅ 違反を診断する ——
safety_violationsフィールドで正確に特定する。 - ✅ 5 つの最適化戦略 —— 敏感度の低減、主体の置換、フレームワーク宣言、ステップ分解、moderation パラメータの活用。
- ✅ エンジニアリング手法 —— 事前チェック、自動書き換え、スマート再試行、コンプライアンス監視。
最も重要な認識:gpt-image-2 の moderation_blocked エラーはバグではなく、製品のコンプライアンスの境界線です。過剰だと不満を言うよりも、「コンプライアンスに準拠したプロンプトエンジニアリング」を生産能力として構築することこそが、AI 製品が一般ユーザー向けに展開される際のコアコンピタンスとなります。
もしチームで頻繁に moderation_blocked エラーが発生しており、生産ライン向けのプロンプト監査フローを構築したい、あるいはエンジニアリング手法で違反率を下げたい場合は、ぜひ APIYI(apiyi.com)からテスト用キーを申請し、本記事の「事前チェック+自動書き換え」コードテンプレートを試してみてください。すべてのサンプルは公式 SDK および APIYI の公式中継チャネル(OpenAI と 100% 互換性のあるフィールド)に基づいているため、汎用性が高く、そのままプロジェクトに組み込むことが可能です。
参考資料
-
OpenAI ChatGPT Images 2.0 System Card:公式の安全ポリシーおよびブロックメカニズムに関する説明
- リンク:
deploymentsafety.openai.com/chatgpt-images-2-0/live-blocking - 説明: 2段階フィルタリングアーキテクチャ、違反カテゴリの完全リストを含む
- リンク:
-
OpenAI Moderations API ドキュメント:事前検証ツールの公式利用ガイド
- リンク:
developers.openai.com/api/docs/guides/moderation - 説明: 11種類の違反カテゴリ、API呼び出し方法
- リンク:
-
OpenAI Usage Policies:利用ポリシーに関する公式説明
- リンク:
openai.com/policies/usage-policies/ - 説明: 禁止事項、責任の所在、コンプライアンス要件
- リンク:
-
OpenAI GPT Image Models Prompting Guide:公式プロンプトのベストプラクティス
- リンク:
developers.openai.com/cookbook/examples/multimodal/image-gen-models-prompting-guide - 説明: コンプライアンスに準拠したプロンプトの記述方法と事例
- リンク:
-
APIYI gpt-image-2 接続ドキュメント:日本語版の完全な接続ガイド
- リンク:
docs.apiyi.com/api-capabilities/gpt-image-2/overview - 説明: moderationパラメータの詳細解説、エラーコードの処理方法を含む
- リンク:
著者: APIYI 技術チーム
公開日: 2026年4月27日
キーワード: gpt-image-2 エラー、moderation_blocked、safety_violations、コンテンツ審査、プロンプト最適化、APIYI、OpenAIコンプライアンス