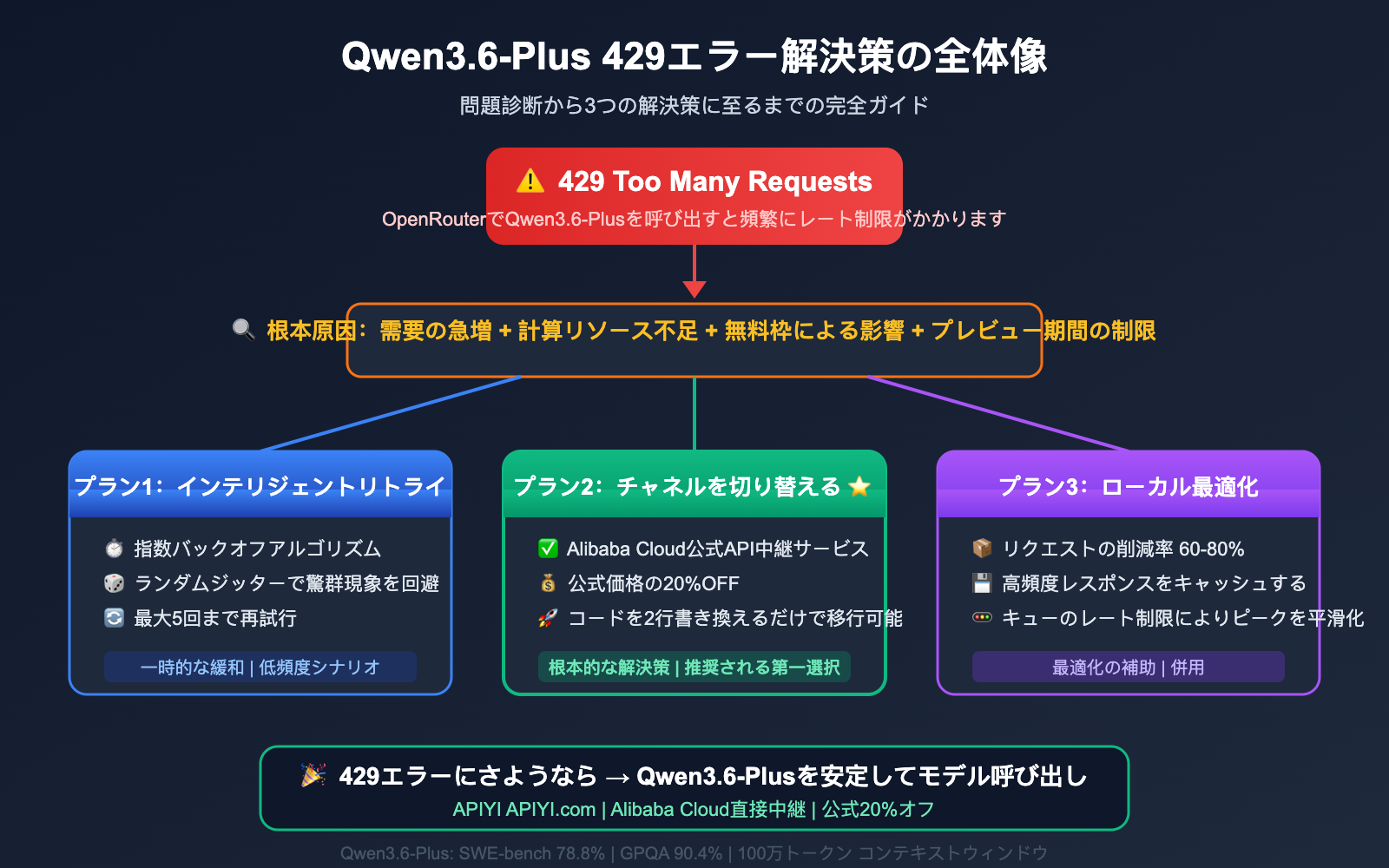
Qwen3.6-Plus を利用する開発者なら、誰もが一度は経験したことがあるはずです。OpenRouter でこのモデルを呼び出すと、「429 Too Many Requests」エラーが日常茶飯事のように発生します。料金を支払っているにもかかわらず、無料ユーザーではないにもかかわらず、あまりの制限の多さに嫌気が差してしまうことも少なくありません。
核心的価値: 本記事では、Qwen3.6-Plus で発生する 429 エラーの根本原因を深く分析し、すぐに実践できる 3 つの解決策を提示します。さらに、Alibaba Cloud(阿里云)の公式直結ルートを通じて、安定かつ低コストで API を呼び出す方法を共有します。
Qwen3.6-Plus 429 エラーの重要ポイント
| ポイント | 説明 | 開発者のメリット |
|---|---|---|
| 429 原因分析 | 需要過多 + 無料枠の乱用 + 計算リソース配分戦略 | 問題の本質を理解し、無意味な再試行を回避 |
| 3 つの解決策 | 再試行戦略 / チャンネル切り替え / 公式直結 | シナリオに応じた最適なパスを選択 |
| 性能実測 | Qwen3.6-Plus 各チャンネルの遅延比較 | 最も安定した接続方法を選択 |
| コード例 | Python/Node.js ですぐに実行可能 | 5 分で移行完了 |
なぜ Qwen3.6-Plus はこれほど人気なのか
Qwen3.6-Plus は、Alibaba の Qwen チームが 2026 年 4 月にリリースしたフラッグシップモデルであり、Claude Opus 4.5 や GPT-5.4 に直接対抗する性能を持っています。人気を集める理由は単純で、「高性能かつ低価格」だからです。
| ベンチマーク | Qwen3.6-Plus | Claude Opus 4.5 | GPT-5.4 |
|---|---|---|---|
| SWE-bench Verified | 78.8% | 80.9% | 76.2% |
| Terminal-Bench 2.0 | 61.6% | 59.3% | 57.8% |
| GPQA (大学院レベルの科学) | 90.4% | 87.0% | 88.1% |
| MCPMark (ツール呼び出し) | 48.2% | 45.6% | 43.9% |
| コンテキストウィンドウ | 100 万トークン | 100 万トークン | 25.6 万トークン |
| 最大出力 | 65,536 トークン | 32,000 トークン | 16,384 トークン |
Terminal-Bench と GPQA という 2 つの重要なベンチマークにおいて、Qwen3.6-Plus は Claude Opus 4.5 を上回っています。それにもかかわらず、公式 API 価格は Claude の約 17 分の 1 です。このコストパフォーマンスが開発者の需要を爆発させ、それがそのまま 429 エラーの根本原因となっています。
description: Qwen3.6-Plusで頻発する429エラーの原因を徹底分析。OpenRouterの混雑回避策や、APIYIを通じた安定した接続方法を解説します。
Qwen3.6-Plus 429 エラーの深掘り分析
429 エラーとは何か
HTTP 429 ステータスコードの意味は非常に明確です。Too Many Requests(リクエスト過多)を指します。サーバーが単位時間あたりに処理できる能力や、あらかじめ設定された制限を超えてリクエストを受け取った際に返されるエラーです。
典型的な 429 エラーのレスポンス例:
{
"error": {
"code": 429,
"message": "Rate limit exceeded. Please slow down your requests.",
"metadata": {
"provider_name": "Qwen",
"raw": "{\"error\":{\"message\":\"Rate limit reached\",\"type\":\"rate_limit_error\"}}"
}
}
}
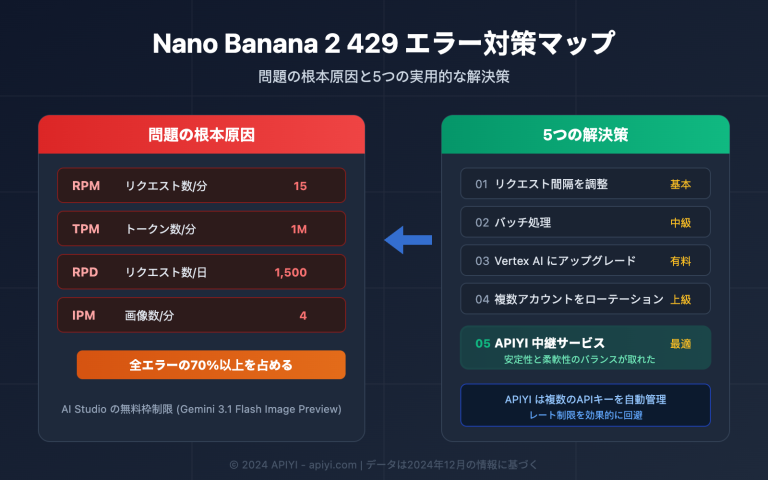
OpenRouter で Qwen3.6-Plus の 429 エラーが頻発する 4 つの理由
理由 1:需要が供給を大幅に上回っている
Qwen3.6-Plus はコストパフォーマンスが非常に高いモデルです。公式 API の入門価格は約 $0.29/100万入力トークンと、Claude Opus 4.5 の 17 分の 1 です。多くの開発者が殺到していますが、OpenRouter は中継プラットフォームとして、Alibaba Cloud から提供される計算リソースの枠(クォータ)に制限があります。
理由 2:無料ユーザーによるリソース占有
OpenRouter は qwen/qwen3.6-plus:free という無料モデルを提供しており、これが大量のゼロコストユーザーを引き寄せています。これらの無料リクエストと有料リクエストが同じバックエンドリソースプールを共有しているため、有料ユーザーまでもが「とばっちり」を受けています。
理由 3:プレビュー期間中の慎重なリソース割り当て
Qwen3.6-Plus は現在まだプレビュー段階(3 月 30 日にプレビュー版公開、4 月 2 日に正式リリース)にあります。Alibaba Cloud はプレビュー期間中、サードパーティプラットフォームへのリソース割り当てを控えめに設定し、自社プラットフォーム(DashScope / 百煉)のサービス品質を優先する傾向があります。
理由 4:モデル自体の推論速度のボトルネック
コミュニティのテストでは、Qwen3.6-Plus のスループットは Claude Opus 4.6 の約 3 倍とされていますが、実際の運用では 100 万トークンのコンテキストウィンドウと MoE アーキテクチャが、複雑なエージェントタスクを処理する際に高い応答遅延を引き起こします。つまり、各リクエストが GPU を占有する時間が長くなり、単位時間あたりに処理できる総リクエスト数が減少してしまうのです。

🎯 核心洞察: 429 エラーはコードの問題ではなく、需給バランスの崩れによるものです。解決策は、無限にリトライすることではなく、供給が安定している別のルートへ切り替えることです。APIYI (apiyi.com) を通じて Alibaba Cloud 公式の直接接続ルートを利用することで、OpenRouter のレート制限問題を効果的に回避できます。
Qwen3.6-Plus 429 エラー解決策 1:インテリジェント・リトライ戦略
指数バックオフによるリトライ
一時的に別のルートへ切り替えられない場合、適切なリトライ戦略を用いることで問題を緩和(根本解決は不可)できます。
import openai
import time
import random
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 統合インターフェース、Alibaba Cloud 公式直結
)
def call_qwen36_with_retry(messages, max_retries=5):
"""指数バックオフを用いた Qwen3.6-Plus 呼び出し"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=messages,
max_tokens=4096
)
return response.choices[0].message.content
except openai.RateLimitError as e:
if attempt == max_retries - 1:
raise
# 指数バックオフとランダムなジッター(揺らぎ)を追加
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"429 レート制限発生、{attempt+1} 回目のリトライ、{wait_time:.1f}秒待機中...")
time.sleep(wait_time)
# 使用例
result = call_qwen36_with_retry([
{"role": "user", "content": "このコードのパフォーマンスボトルネックを分析してください"}
])
print(result)
リトライ戦略の推奨パラメータ
| パラメータ | 推奨値 | 説明 |
|---|---|---|
| 最大リトライ回数 | 3-5 回 | 5 回を超えても失敗する場合は、ルート自体が不安定です |
| 初期待機時間 | 1-2 秒 | 短すぎると効果がなく、長すぎると時間の無駄になります |
| バックオフ倍数 | 2倍 | 指数バックオフは業界標準です |
| ランダムジッター | 0-1 秒 | 「驚群効果(Thundering Herd Problem)」を避けるため |
| タイムアウト上限 | 30 秒 | 1 回の待機時間は 30 秒を超えないようにします |
リトライ戦略の限界
明確にしておくべき点は、リトライは鎮痛剤であり、治療法ではないということです。OpenRouter の Qwen3.6-Plus バックエンドが継続的に過負荷状態にある場合、リトライ戦略の成功率は急激に低下します。より根本的な解決策は、供給が安定している API ルートへ切り替えることです。
Qwen3.6-Plus 429 エラー解決策 2:API チャンネルの切り替え
なぜ再試行よりもチャンネル切り替えが有効なのか
OpenRouter で 429 エラーが頻発する本質的な原因は、そのチャンネルにおける Qwen3.6-Plus の計算リソース(クォータ)不足にあります。Alibaba Cloud(阿里云)の計算リソースに直接接続するチャンネルに切り替えることで、根本的な解決が可能になります。
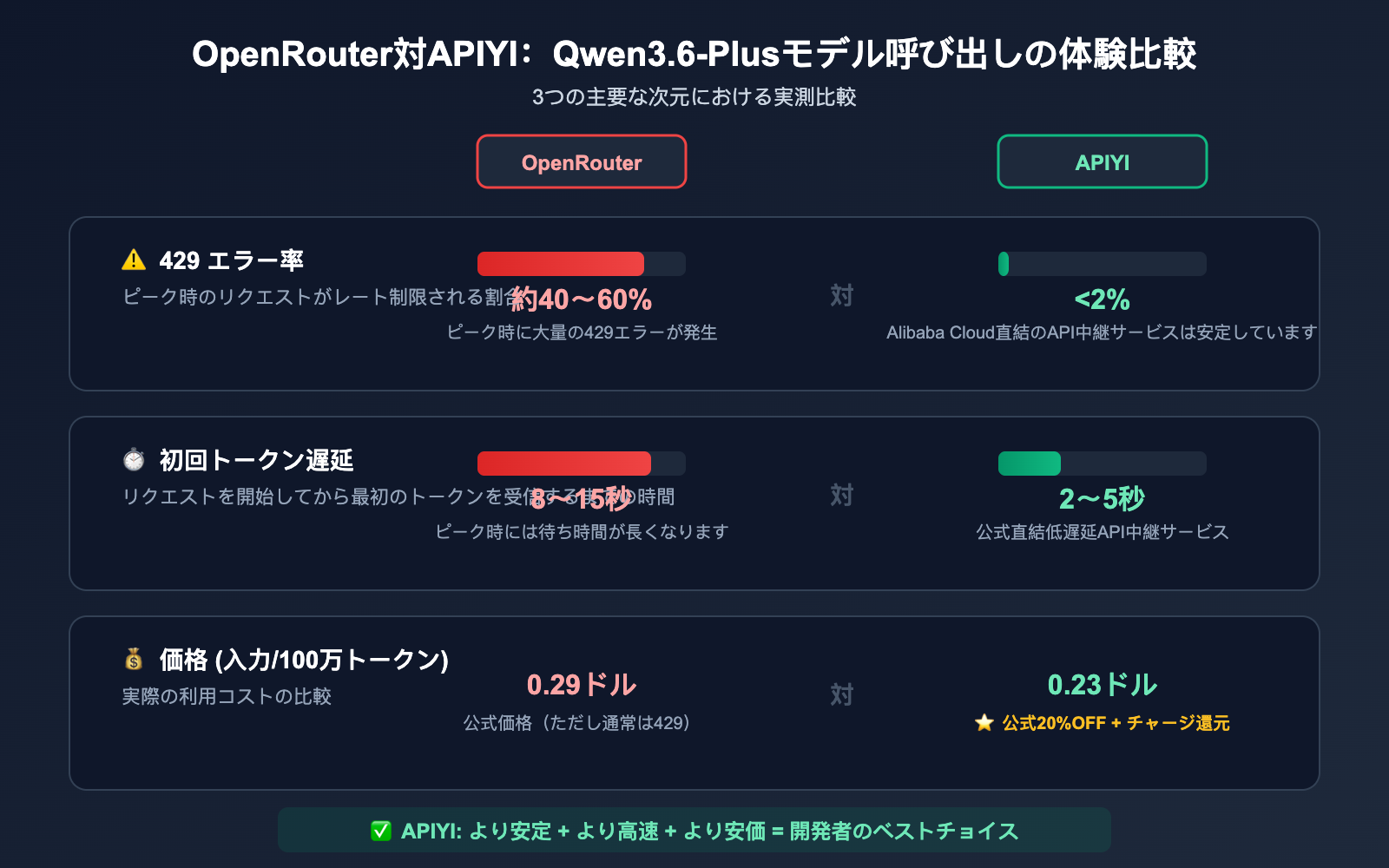
Qwen3.6-Plus API チャンネル比較
| チャンネル | 安定性 | 価格 (入力/100万トークン) | 429 発生頻度 | データ収集 |
|---|---|---|---|---|
| OpenRouter Free | 低 | 無料 | 非常に高い | あり (学習データ) |
| OpenRouter Paid | 普通 | ~$0.29 | 頻繁 | あり (プレビュー期間) |
| 阿里云百炼 | 高 | ¥2.00 | 低 | 規約による |
| APIYI (阿里云直結) | 高 | 公式の 20% OFF | 低 | なし |
💡 推奨事項: アプリケーションの安定性が重要な場合、APIYI (apiyi.com) を通じて Qwen3.6-Plus に接続することをお勧めします。このプラットフォームは Alibaba Cloud の公式直結チャンネルを採用しており、価格は公式の 20% OFF(グループ価格 0.88 倍 + 100 ドルチャージで 10 ドル還元)で、OpenRouter のレート制限問題を回避できます。
OpenRouter から APIYI への移行はコード 2 行の変更のみ
移行コストは非常に低く、base_url と api_key を変更するだけです:
import openai
# ❌ 以前: OpenRouter (頻繁に 429 が発生)
# client = openai.OpenAI(
# api_key="sk-or-v1-xxxx",
# base_url="https://openrouter.ai/api/v1"
# )
# ✅ 現在: APIYI 阿里云直結 (安定しており 429 は発生しません)
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "あなたはプロのコードレビューアシスタントです"},
{"role": "user", "content": "この SQL クエリのパフォーマンスを最適化してください"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Node.js 版:
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'YOUR_APIYI_KEY',
baseURL: 'https://api.apiyi.com/v1' // APIYI 統合インターフェース
});
const response = await client.chat.completions.create({
model: 'qwen3.6-plus',
messages: [
{ role: 'user', content: 'このコードの時間計算量を分析してください' }
],
max_tokens: 4096
});
console.log(response.choices[0].message.content);
Qwen3.6-Plus 429 エラー解決策 3:ローカルリクエストの最適化
不要な API 呼び出しを減らす
チャンネルの切り替えに加え、リクエストパターンを最適化することでも 429 エラーの発生確率を下げることができます:
1. リクエストの結合
# ❌ 非効率: 1件ずつ送信
for item in data_list:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"分析: {item}"}]
)
# ✅ 効率的: バッチで結合
batch_content = "\n".join([f"{i+1}. {item}" for i, item in enumerate(data_list)])
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"以下の内容を順に分析してください:\n{batch_content}"}],
max_tokens=16384
)
2. 高頻度レスポンスのキャッシュ
import hashlib
import json
_cache = {}
def cached_qwen_call(prompt, model="qwen3.6-plus"):
cache_key = hashlib.md5(f"{model}:{prompt}".encode()).hexdigest()
if cache_key in _cache:
return _cache[cache_key]
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content
_cache[cache_key] = result
return result
3. リクエストキューのレート制限
| 最適化戦略 | 効果 | 適用シーン |
|---|---|---|
| リクエスト結合 | リクエスト量を 60-80% 削減 | バッチデータ処理 |
| レスポンスキャッシュ | 同一リクエストの API 呼び出しゼロ | 重複クエリシーン |
| キューのレート制限 | リクエストのピークを平滑化 | 高並列アプリケーション |
| ダウングレード戦略 | 429 発生時に自動で軽量モデルへ切り替え | 遅延に敏感なサービス |
🔧 技術アドバイス: 上記のローカル最適化戦略は、安定した API チャンネルと組み合わせることで最大の効果を発揮します。APIYI (apiyi.com) を通じて Qwen3.6-Plus に接続し、リクエスト結合やキャッシュ戦略を併用することで、安定性を確保しつつコストをさらに削減できます。
Qwen3.6-Plus モデルの速度低下に関する原因分析
Qwen3.6-Plus の応答が時折遅くなる理由
多くの開発者から、429 エラーが発生していないにもかかわらず、Qwen3.6-Plus の応答速度が「なぜか遅い」というフィードバックが寄せられています。これは個別の事象ではなく、技術的な背景が存在します。
1. MoE アーキテクチャによる推論オーバーヘッド
Qwen3.6-Plus は混合エキスパート(MoE)アーキテクチャを採用しています。MoE は学習コストを大幅に削減できますが、推論段階ではルーティングの決定やエキスパートの切り替えによるオーバーヘッドが発生します。特に長いコンテキストを処理する場合、MoE アーキテクチャの推論効率は、同パラメータ数の Dense モデルよりも低くなります。
2. 100 万トークンのコンテキストによるメモリ負荷
100 万トークンのコンテキストウィンドウは Qwen3.6-Plus の最大の売りですが、これは KV キャッシュが占有する GPU メモリが非常に大きいことを意味します。複数のユーザーが同時に長文コンテキストのリクエストを行うと、GPU メモリがボトルネックとなり、推論速度が著しく低下します。
3. プレビュー期間中の計算リソースの制限
Qwen3.6-Plus は現在プレビュー期間中です。Alibaba Cloud はこの段階では、正式リリース時と同規模の計算リソースを投入しないのが一般的です。公式は実際の利用パターンを観察した上で、段階的に容量を拡張していく可能性があります。
4. Always-On 推論チェーンによる追加トークン消費
Qwen3.6-Plus はデフォルトで Always-On Chain-of-Thought(思考の連鎖)推論モードが有効になっています。これは、モデルが応答ごとに内部的な思考プロセスを生成することを意味し、実際に生成されるトークン数は最終的な出力よりもはるかに多くなります。これらの「隠れたトークン」が追加の推論時間を消費します。
各チャネルにおける遅延の実測値(参考)
| チャネル | 初回トークン遅延 | スループット (トークン/秒) | 備考 |
|---|---|---|---|
| OpenRouter (ピーク時) | 8-15秒 | 15-25 | 429エラー多発 |
| OpenRouter (オフピーク) | 3-5秒 | 30-50 | 深夜帯 |
| Alibaba Cloud 百煉 | 2-4秒 | 40-60 | 国内直結 |
| APIYI (直接中継) | 2-5秒 | 35-55 | 海外からの安定アクセス |
💰 コストに関するヒント: Qwen3.6-Plus の速度はチャネルや負荷によって大きく異なります。遅延に敏感な場合は、APIYI (apiyi.com) を通じて実際のテストを行うことをお勧めします。当プラットフォームは Alibaba Cloud 公式の直接中継チャネルを提供しており、公式価格の 20% OFF で利用できるだけでなく、より安定した応答速度を実現しています。
Qwen3.6-Plus クイックスタートガイド
APIYI を使用して Qwen3.6-Plus を呼び出す完全なサンプル
import openai
# APIYIのAPIキーとベースURLを設定
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# 基本的な対話
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "あなたは熟練したPython開発のエキスパートです"},
{"role": "user", "content": "高性能な非同期クローラーフレームワークを書いてください"}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
ストリーミング出力のコード全体を表示
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# ストリーミング出力 - リアルタイムのフィードバックが必要なシナリオ向け
stream = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "あなたは熟練したアーキテクトです"},
{"role": "user", "content": "百万単位の同時接続をサポートするメッセージキューシステムを設計してください"}
],
max_tokens=16384,
temperature=0.7,
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # 改行
🚀 クイックスタート: APIYI (apiyi.com) プラットフォームで API キーを取得し、Qwen3.6-Plus を呼び出すことをお勧めします。登録後すぐに利用可能で、100ドルのチャージで10ドル分がプレゼントされます。また、Qwen3.6-Plus は公式価格から 20% OFF でご利用いただけます。
Qwen3.6-Plus の適用シナリオと選定のヒント
Qwen3.6-Plus が特に適しているシナリオ
| アプリケーション | 推奨理由 | 代替案 |
|---|---|---|
| エージェント自動化 | Terminal-Bench 61.6% でリード、ネイティブなツール呼び出し | Claude Opus 4.5 |
| コードレビュー/修正 | SWE-bench 78.8%、Claude 水準に匹敵 | Claude Opus 4.5 |
| 科学的推論 | GPQA 90.4% で最高スコア | GPT-5.4 |
| 長文ドキュメント処理 | 100 万トークンのコンテキストウィンドウ | Gemini 2.5 Pro |
| コスト重視のプロジェクト | Claude の約 1/17 の価格 | DeepSeek V3 |
注意が必要なシナリオ
- 遅延に極めて敏感なリアルタイムアプリケーション: Qwen3.6-Plus の MoE アーキテクチャは、長いコンテキストにおいて遅延が大きくなる傾向があります。
- 本番環境のクリティカルパス: プレビュー版モデルのため、予期せぬ挙動の変化が発生する可能性があります。
- 厳格な SLA 保障が必要な環境: プレビュー期間中は正式な SLA が提供されません。
🎯 選定のアドバイス: 複数のモデルを併用するプロジェクトでは、APIYI (apiyi.com) プラットフォームを通じた統合的なアクセスをおすすめします。同プラットフォームは Qwen3.6-Plus、Claude、GPT などの主要モデルの OpenAI 互換インターフェースをサポートしており、1 つの API キーでモデルを切り替えられるため、状況に応じた柔軟な運用が可能です。
Qwen3.6-Plus の 429 エラーに関するよくある質問
Q1: OpenRouter で課金しているのに 429 エラーが出るのはなぜですか?
OpenRouter では、有料ユーザーと無料ユーザーがバックエンドの計算リソースプールを共有しているためです。有料ユーザーであっても、OpenRouter が Alibaba Cloud から取得している計算リソースのクォータを超えると、制限がかかる場合があります。解決策としては、APIYI (apiyi.com) を通じて Alibaba Cloud の公式直結チャンネルを利用するなど、供給が安定しているルートへ切り替えることを推奨します。
Q2: Qwen3.6-Plus の 429 エラーは改善されますか?
Alibaba Cloud のリソース拡張やモデルの正式 GA(一般公開)に伴い、429 エラーは徐々に解消される見込みです。ただし、OpenRouter のようなマルチプラットフォームの中継サービスは、常に上位供給元のリソース配分に依存します。業務の安定性が求められる場合は、中継プラットフォームに依存せず、Alibaba Cloud に直接接続するチャネルを長期的に利用することをおすすめします。
Q3: APIYI の Qwen3.6-Plus と OpenRouter の違いは何ですか?
最大の違いは計算リソースの供給元です。APIYI (apiyi.com) プラットフォームは Alibaba Cloud の公式直結チャンネルを採用しており、リソースは Alibaba Cloud の「百錬(Bailian)」プラットフォームから直接供給されます。これにより、429 エラーの発生率を抑え、より安定した応答速度を実現しています。価格面でも、APIYI は公式の 8 割引(グループ 0.88 倍の割引+チャージ還元)を提供しており、OpenAI SDK 互換インターフェースのため、移行コストはほぼゼロです。
Q4: Qwen3.6-Plus の動作が遅いのは正常ですか?
Qwen3.6-Plus の MoE アーキテクチャと 100 万トークンのコンテキストウィンドウは、推論時に Dense モデルよりも大きな負荷がかかります。加えて、プレビュー期間中は計算リソースの設定が控えめであるため、現段階では動作が遅く感じられるのが一般的です。ただし、絶対的なスループットは依然として高いため、ストリーミング出力(stream=True)を活用してユーザー体験を改善することをおすすめします。
Q5: Claude Code で Qwen3.6-Plus を使うにはどうすればいいですか?
Qwen3.6-Plus は Anthropic プロトコルと OpenAI プロトコルの両方に対応しています。Claude Code の API エンドポイント設定を変更することで利用可能です。APIYI (apiyi.com) プラットフォーム経由で接続する場合は、標準の OpenAI SDK 形式を使用してください。具体的な設定手順はプラットフォームのドキュメントをご参照ください。

Qwen3.6-Plus 429 エラー解決策のまとめ
Qwen3.6-Plus で発生する 429 エラーは、本質的には需要と供給の不均衡に起因する問題です。モデルの性能が高く、価格が手頃であるために需要が急増しており、OpenRouter の計算リソース枠がすべてのユーザーの要求を処理しきれていない状況です。
以下に、3つの解決策とその適用シーンをまとめました。
- インテリジェントなリトライ: 一時的な対策。呼び出し頻度が低いシーンに適しています。
- ローカル環境での最適化: リクエスト量を削減する対策。あらゆるシーンで有効です。
- チャネルの切り替え: 根本的な解決策。安定性が求められるプロジェクトに最適です。
Qwen3.6-Plus を安定して利用したい開発者の方には、APIYI (apiyi.com) プラットフォームを通じて、Alibaba Cloud の公式直結チャンネルへ接続することをおすすめします。公式価格から 20% オフの料金で利用できるだけでなく、429 エラーによる制限から解放され、エラー処理ではなく本来のビジネスロジックの開発に集中できるようになります。
📝 著者: APIYI Team | AI モデルの API 接続チュートリアルやトラブルシューティングガイドの詳細は、APIYI ヘルプセンターをご覧ください: help.apiyi.com