Google Gemma 4 が正式リリースされました。初めて Apache 2.0 の完全オープンソースライセンスを採用し、ラズパイからデータセンターまで、あらゆるコンピューティング環境をカバーする4つのモデルを展開します。Gemini 3 と同源の技術をベースにしたオープンソース版である Gemma 4 は、推論、コーディング、視覚認識、長文コンテキストなどのあらゆる面で、Gemma 3 を圧倒する性能向上を実現しました。
コアバリュー: 本記事を読むことで、Gemma 4 の4つのモデル選定基準、アーキテクチャの革新性、マルチモーダル能力の境界、そしてローカルデプロイに必要なハードウェア要件を理解できます。

Gemma 4 核心情報まとめ
Gemma 4 は2026年4月2日に Google Cloud Next で発表されました。Gemini 3 の同源研究に基づいて構築された、Google オープンソースモデルファミリーの第4世代製品です。
| 項目 | 詳細 |
|---|---|
| リリース日 | 2026年4月2日 |
| モデル数 | 4種類 (E2B / E4B / 26B-A4B / 31B) |
| ライセンス | Apache 2.0 (初採用、以前は Google 独自ライセンス) |
| 最大コンテキスト | 256K トークン (31B および 26B-A4B) |
| マルチモーダル | テキスト + 画像 + 動画 + 音声 (E2B/E4B) |
| アーキテクチャ | 初の MoE バリアント、PLE 技術、ハイブリッドアテンション |
| 利用プラットフォーム | Hugging Face、Google AI Studio、Vertex AI、Ollama など |
Gemma 4 の4つのモデル一覧
| モデル | 有効パラメータ | 総パラメータ | アーキテクチャ | コンテキスト | マルチモーダル |
|---|---|---|---|---|---|
| Gemma 4 E2B | 2.3B | 5.1B | Dense | 128K | テキスト+画像+動画+音声 |
| Gemma 4 E4B | 4.5B | 8B | Dense | 128K | テキスト+画像+動画+音声 |
| Gemma 4 26B-A4B | 3.8B 活性化 | 25.2B | MoE | 256K | テキスト+画像+動画 |
| Gemma 4 31B | 30.7B | 30.7B | Dense | 256K | テキスト+画像+動画 |
命名規則: 「E」プレフィックスは「Effective Parameters(有効パラメータ)」を表し、PLE 技術により総パラメータ数が有効パラメータ数よりも大きくなっています。26B-A4B は、総パラメータ数 26B、トークンあたりの活性化パラメータ数 4B の MoE アーキテクチャであることを示しています。
🎯 技術アドバイス: Gemma 4 の4つのモデルは、エッジデバイスからクラウド推論まであらゆるシーンをカバーしています。複数のオープンソースモデル間で効果を比較したい場合は、APIYI (apiyi.com) プラットフォームを通じて統合的にアクセスし、迅速に切り替えて評価することをお勧めします。
description: Googleの最新モデル「Gemma 4」と「Gemma 3」の性能を徹底比較。史上最大の飛躍と言われるベンチマーク結果や、MoEモデルの効率性、最適なモデルの選び方まで詳しく解説します。
Gemma 4 vs Gemma 3 性能比較:史上最大の世代間進化
Googleは公式に、Gemma 4を「オープンモデル史上、単一世代で最大の性能向上を実現したモデル」と位置づけています。ベンチマークデータは、この主張を完全に裏付けるものとなっています。
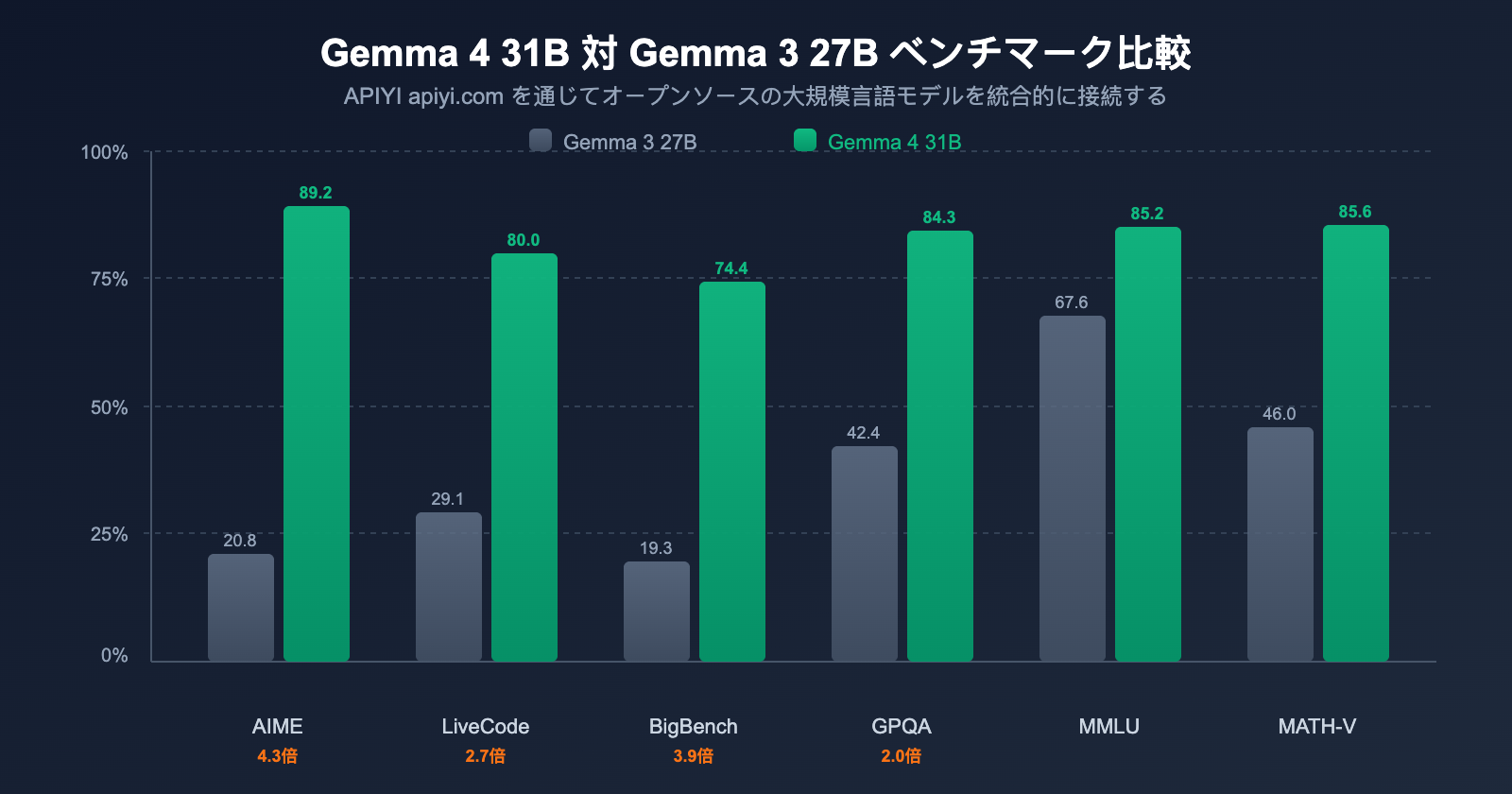
主要なベンチマーク比較
| ベンチマーク | Gemma 3 27B | Gemma 4 31B | 向上幅 |
|---|---|---|---|
| AIME 2026 (数学的推論) | 20.8% | 89.2% | +68.4 pts (4.3倍) |
| LiveCodeBench v6 (コーディング) | 29.1% | 80.0% | +50.9 pts (2.7倍) |
| BigBench Extra Hard (推論) | 19.3% | 74.4% | +55.1 pts (3.9倍) |
| GPQA Diamond (科学的推論) | 42.4% | 84.3% | +41.9 pts (2.0倍) |
| MMLU Pro (知識) | 67.6% | 85.2% | +17.6 pts |
| MATH-Vision (視覚数学) | 46.0% | 85.6% | +39.6 pts |
| MRCR 128K (長文コンテキスト) | 13.5% | 66.4% | +52.9 pts |
重要な発見: 数学的推論のAIMEでは20.8%から89.2%へと4.3倍の飛躍を見せ、コーディングのLiveCodeBenchでも29.1%から80.0%へと2.7倍の向上を達成しました。これは漸進的な改善ではなく、まさに世代を超えた飛躍と言えます。
4モデルの完全ベンチマークデータ
| ベンチマーク | 31B | 26B-A4B | E4B | E2B |
|---|---|---|---|---|
| MMLU Pro | 85.2% | 82.6% | 69.4% | 60.0% |
| AIME 2026 | 89.2% | 88.3% | 42.5% | 37.5% |
| GPQA Diamond | 84.3% | 82.3% | 58.6% | 43.4% |
| LiveCodeBench v6 | 80.0% | 77.1% | 52.0% | 44.0% |
| MATH-Vision | 85.6% | 82.4% | 59.5% | 52.4% |
| MMMU Pro (視覚) | 76.9% | 73.8% | 52.6% | 44.2% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 |
MoE(混合エキスパート)の効率性: 26B-A4Bモデルは、わずか3.8Bの有効パラメータ数で31B Denseモデルの約97%の性能に到達しており、推論コストを大幅に削減可能です。LMArenaにおいて、26B-A4B(約1441 ELO)は、OpenAIのgpt-oss-120Bすら上回る結果を残しています。
💡 選択のアドバイス: 究極の性能を求めるなら31Bを、コストパフォーマンスを重視するなら26B-A4B(97%の性能をわずか12%の有効パラメータで実現)がおすすめです。APIYI (apiyi.com) プラットフォームを利用すれば、これら2つのバージョンを実際のビジネスシナリオで素早く比較・検証できます。
Gemma 4 アーキテクチャの革新:6つのコア技術
Gemma 4 はアーキテクチャレベルで数々の革新的な技術を導入しており、これが飛躍的な性能向上の原動力となっています。

技術 1: Per-Layer Embeddings (PLE)
PLE はメインの残差ストリームとは別に並列の条件パスを追加し、各デコーダー層専用のトークンベクトルを生成します。この技術により小規模モデルの表現能力が向上し、2.3Bの有効パラメータを持つE2Bモデルは、そのパラメータ数からは想像できないほどの高性能を実現しています。
技術 2: ハイブリッド・アテンション (Hybrid Attention)
局所的なスライディングウィンドウ・アテンションと、グローバルなフルコンテキスト・アテンション層を交互に配置しています。
- スライディングウィンドウ層: 局所的なコンテキストを処理 (E2B/E4B: 512トークン、31B/26B: 1024トークン)
- グローバル・アテンション層: コンテキスト全体を処理
このハイブリッド設計により、長いコンテキストを維持しつつ、計算コストを大幅に削減しています。
技術 3: Dual RoPE 位置エンコーディング
- スライディングウィンドウ層には標準の RoPE を採用
- グローバル・アテンション層には Proportional RoPE を採用
このデュアル RoPE 設計により、品質を損なうことなく256Kのコンテキスト長を実現しました。
技術 4: 共有 KV キャッシュ
最後のN層において、同タイプの最後の非共有層のK/Vテンソルを再利用することで、計算量とメモリ消費量を大幅に削減しています。これは、Gemma 4 がコンシューマー向けハードウェアで大規模言語モデルを動作させるための重要な技術の一つです。
技術 5: MoE 専門家混合 (26B-A4B)
Gemma 4 では初めて MoE (Mixture of Experts) バリアントが導入されました。
- 128個の小型専門家モデル
- 1トークンあたり8個の専門家 + 1個の共有専門家をアクティブ化
- 3.8Bのアクティブパラメータで、31BのDenseモデルの約97%の性能を達成
技術 6: ネイティブ・マルチモーダル
視覚および音声機能が事前学習段階から直接統合されています。
- 視覚エンコーダー: E2B/E4Bで約150Mパラメータ、31B/26Bで約550Mパラメータ
- 音声エンコーダー: USMスタイルのConformer、約300Mパラメータ (E2B/E4Bのみ)
- 可変アスペクト比の画像をサポートし、トークン予算を構成可能 (70〜1120トークン)
description: Gemma 4のマルチモーダル機能とエージェント能力を徹底解説。APIYI経由での関数呼び出しや、ローカル環境でのハードウェア要件まで詳しく紹介します。
Gemma 4 マルチモーダルおよびエージェント能力の詳細
Gemma 4は単なる対話モデルではなく、完全なエージェント能力を備えたマルチモーダルシステムです。
マルチモーダル入力能力
| モダリティ | E2B | E4B | 31B | 26B-A4B |
|---|---|---|---|---|
| テキスト | ✅ | ✅ | ✅ | ✅ |
| 画像 | ✅ | ✅ | ✅ | ✅ |
| 動画 (最大60秒 1fps) | ✅ | ✅ | ✅ | ✅ |
| 音声 (最大30秒) | ✅ | ✅ | ❌ | ❌ |
視覚能力のカバー範囲:
- 物体検出とバウンディングボックス出力 (ネイティブJSON形式)
- GUI要素の検出とポインティング
- ドキュメント/PDF解析、グラフ理解
- スクリーン/UIインターフェースの理解
- 画像とテキストのクロス入力 (任意の順序で混合可能)
ネイティブ関数呼び出しとエージェント能力
Gemma 4は学習段階から関数呼び出し能力が組み込まれており、後付けの微調整ではありません。
- ネイティブ関数呼び出し: 学習段階で直接最適化されており、複数ツールのオーケストレーションをサポート
- Extended Thinking:
enable_thinking=Trueを通じて多段階推論を有効化可能 - 構造化出力: ネイティブJSON出力に対応し、API統合に最適
- マルチターンエージェントフロー: 計画-実行-観察を行う自律型エージェントループをサポート
# Gemma 4 関数呼び出しの例 (APIYIの統一インターフェース経由)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "指定された都市の天気を取得する",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string"}
},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="gemma-4-31b-it",
messages=[{"role": "user", "content": "北京の今日の天気はどうですか?"}],
tools=tools,
tool_choice="auto",
)
🚀 クイックスタート: Gemma 4のネイティブ関数呼び出しは、AIエージェント構築に最適です。APIYI (apiyi.com) プラットフォームを利用すれば、OpenAI互換インターフェースにより追加の適応なしで素早く接続できます。
Gemma 4 ローカルデプロイのハードウェアガイド
Apache 2.0ライセンスにより、あらゆるハードウェアで自由にGemma 4をデプロイ可能です。各モデルのハードウェア要件は以下の通りです。
ハードウェア要件一覧
| モデル | 最低ハードウェア | 推奨デプロイ環境 |
|---|---|---|
| E2B (2.3B) | 1.5GB未満のメモリ | Raspberry Pi 5 (プリフィル 133 tok/s, デコード 7.6 tok/s) |
| E4B (4.5B) | スマホクラスのNPU/GPU | モバイルデバイス、Apple Silicon (MLX) |
| 26B-A4B (MoE) | コンシューマー向けGPU 1枚 (量子化) | 個人ワークステーション、小型サーバー |
| 31B (Dense) | 80GB H100 GPU 1枚 (FP16) | クラウド推論、データセンター |
サポートされているハードウェアとフレームワーク
| ハードウェア/フレームワーク | サポート状況 |
|---|---|
| NVIDIA (H100/B200/RTX) | ✅ 全シリーズ対応 |
| Google TPU (Trillium/Ironwood) | ✅ ネイティブ最適化 |
| Apple Silicon (MLX) | ✅ mlx-community/gemma-4-* |
| AMD ROCm | ✅ 対応 |
| Qualcomm NPU (IQ8) | ✅ モバイル推論 |
| GGUF (llama.cpp/Ollama) | ✅ 2-bit/4-bit 量子化 |
| ONNX (WebGPU/ブラウザ) | ✅ onnx-community/gemma-4-* |
| NVIDIA NIM | ✅ コンテナ化デプロイ |
E2BはRaspberry Pi 5上で毎秒7.6トークンの速度でデコードを実行でき、エッジAIアプリケーションの可能性を大きく広げます。
Apache 2.0 ライセンス:なぜ今回が特別なのか
Gemma 4 は今回初めて Apache 2.0 ライセンスを採用しました。これは非常に大きな変化です。これまでの Gemma モデルはすべて Google 独自のライセンス契約に基づいており、特定の使用制限や利用停止権が存在していました。
ライセンス比較
| 項目 | Gemma 3 (Google ライセンス) | Gemma 4 (Apache 2.0) |
|---|---|---|
| 商用利用 | 制限あり | ✅ 完全自由 |
| 改変・配布 | 追加条項の遵守が必要 | ✅ 完全自由 |
| 派生モデル | 制限あり | ✅ 完全自由 |
| 利用停止権 | Google が権利を保持 | ❌ 取り消し不可 |
| 特許ライセンス | 限定的 | ✅ 明示的に付与 |
Apache 2.0 が意味するもの:
- 企業が法的なリスクを懸念することなく、商用製品に安心して組み込める
- 派生モデルの微調整や配布が自由に行える
- Meta の Llama や DeepSeek のオープンソース戦略と足並みが揃った
- 企業による導入のコンプライアンス上のハードルが大幅に下がった
💰 コスト最適化: Apache 2.0 + ローカルデプロイ = API 呼び出しコストゼロ。推論量が多いシナリオでは、ローカル環境へのデプロイの方が API 呼び出しよりも経済的になる可能性があります。ローカルデプロイと API 呼び出しの費用対効果を比較したい場合は、APIYI (apiyi.com) プラットフォームでまず API を使って効果を検証し、その後にローカルデプロイするかどうかを判断することをお勧めします。
Gemma 4 モデルの入手とクイックスタート
モデルのダウンロード先
| プラットフォーム | 利用可能なモデル | 用途 |
|---|---|---|
| Hugging Face | 全4種類 (base + IT) | 一般的なダウンロード、研究 |
| Google AI Studio | 31B、26B MoE | 無料のオンライン体験 |
| Vertex AI | 全4種類 | エンタープライズ向けデプロイ |
| Ollama / llama.cpp | GGUF 量子化版 | ローカル環境での迅速なデプロイ |
| Google AI Edge Gallery | E4B、E2B | モバイル端末向けデプロイ |
Ollama によるワンクリックデプロイ
# Gemma 4 31B をデプロイ (推奨)
ollama run gemma4:31b
# MoE バージョンをデプロイ (コストパフォーマンス重視)
ollama run gemma4:26b-a4b
# 軽量版をデプロイ (エッジデバイス向け)
ollama run gemma4:e4b
微調整(ファインチューニング)のサポート
Gemma 4 は充実した微調整エコシステムを提供しています:
| フレームワーク | サポート内容 |
|---|---|
| TRL | SFT、DPO、強化学習 (マルチモーダルを含む) |
| PEFT | LoRA、QLoRA (bitsandbytes 経由) |
| Vertex AI | マネージドトレーニング |
| Unsloth Studio | UI ベースの微調整 |
視覚および音声エンコーダーを凍結し、テキスト部分のみを微調整することで、微調整コストを大幅に削減可能です。
🎯 技術的なアドバイス: まずは APIYI (apiyi.com) プラットフォームを通じて API 経由で Gemma 4 の性能をテストし、要件を満たしていることを確認してから、ローカルデプロイや微調整を行うことで、リソースの無駄を防ぐことができます。
よくある質問
Q1: Gemma 4 と Gemini 3 の関係は?
Gemma 4 は Gemini 3 と同源の研究に基づいて構築されており、Gemini 3 技術のオープンソース版と理解して差し支えありません。Gemma 4 はモデル規模がより小さく(最大 31B 対 Gemini の数千億パラメータ)、同じコアアーキテクチャの革新を採用しています。APIYI (apiyi.com) プラットフォームでは、Gemma 4 と Gemini シリーズの両モデルを同時に利用して比較することが可能です。
Q2: 26B MoE と 31B Dense はどちらを選ぶべき?
ハードウェアに制限がある場合や、高いスループットが必要な場合は「26B-A4B MoE」がおすすめです。わずか 3.8B のアクティブパラメータで 31B モデルの約 97% の性能を発揮します。究極の性能を追求し、80GB GPU を利用できる環境であれば「31B Dense」を選びましょう。なお、MoE バージョンの推論コストは Dense バージョンの約 8 分の 1 です。
Q3: E2B と E4B はどのようなシーンに適していますか?
E2B は究極のエッジシーン(Raspberry Pi、IoT デバイス、モバイル端末)に、E4B はモバイル端末や軽量な PC へのデプロイに適しています。どちらも音声入力をサポートしており、これは 31B や 26B では対応していません。アプリケーションで音声理解が必要な場合は、E2B または E4B を選択する必要があります。
Q4: Apache 2.0 ライセンスは商用利用にどのような影響がありますか?
Apache 2.0 は最も寛容なオープンソースライセンスの一つであり、商用利用、改変、配布が完全に自由で、取り消し不可能です。Gemini 3 の Google 独自ライセンスと比較して、企業はコンプライアンスリスクを心配する必要がありません。APIYI (apiyi.com) プラットフォームでまず API をテストし、効果を確認してから商用製品向けにローカルデプロイを行うことができます。
まとめ
Gemma 4 は、Google のオープンソース AI 戦略における大きな飛躍です。Apache 2.0 ライセンスの採用により、これまでの利用障壁が取り払われました。4 つのモデルは Raspberry Pi から H100 まで、あらゆる計算リソースのシーンをカバーします。AIME で 4.3 倍、LiveCodeBench で 2.7 倍という世代間の性能向上、そしてネイティブなマルチモーダル対応と関数呼び出し機能により、オープンソースのエージェント開発における第一の選択肢となる基盤モデルです。
要点まとめ:
- ライセンス: 初の Apache 2.0 採用、完全商用利用可能
- モデル: 2B〜31B をカバーする 4 モデル展開、初の MoE バリアントを含む
- 性能: AIME +68pts (4.3倍)、LiveCodeBench +51pts (2.7倍)
- マルチモーダル: テキスト、画像、動画、音声をネイティブ統合
- エージェント: ネイティブ関数呼び出し + Extended Thinking 対応
- デプロイ: Raspberry Pi から H100 まで網羅、GGUF/ONNX/MLX 等の複数フレームワーク対応
APIYI (apiyi.com) を通じて Gemma 4 シリーズに素早くアクセスし、統一されたインターフェースで各モデルの実力を比較してみることをおすすめします。
参考資料
- Google 公式ブログ – Gemma 4 リリース:
blog.google/innovation-and-ai/technology/developers-tools/gemma-4/ - Hugging Face – Gemma 4 モデル:
huggingface.co/blog/gemma4 - Google AI – Gemma 4 モデルカード:
ai.google.dev/gemma/docs/core/model_card_4
本記事は APIYI チームの技術担当者が執筆しました。AI モデルの活用に関するその他のチュートリアルについては、APIYI (apiyi.com) をご確認ください。