著者注:開発者が最もよく尋ねる質問に答えます:大規模言語モデルAPIにPDFを直接渡せるか?答えはほとんどの場合「NO」です。本文では、テキスト化抽出、画像理解、クライアント処理の3つの実用的な解決策を詳しく解説します。
「大規模言語モデルAPIにPDFファイルを直接渡せますか?」——これは私たちのカスタマーサポートグループで最もよく聞かれる質問の一つです。多くの開発者は、ウェブ版のChatGPTやClaudeで「PDFをドラッグ&ドロップして直接会話する」機能に慣れているため、APIでも同じように操作できると考えがちです。
実際の状況はこうです:ほとんどの大規模言語モデルAPIは、PDFファイルの直接入力をサポートしていません。OpenAIやAnthropicのような主要ベンダーであっても、APIインターフェースのコア入力形式は依然としてテキストと画像であり、PDFは標準サポートの範囲外です。さらに重要なことに、APIYIなどのサードパーティAPI中継プラットフォームもPDFの直接アップロードをサポートしていません。なぜなら、基盤となるプロトコル自体がサポートしていないからです。
しかし、心配はいりません。PDF処理には実際、3つの成熟した解決策があります。この記事では、その背景を明確にし、あなたに最適な方法を選ぶ手助けをします。
核心的価値: この記事を読み終えると、大規模言語モデルAPIがなぜPDFをサポートしないのかを理解し、3つの前処理方法でPDF入力のニーズを効率的に解決する方法がわかるようになります。

大規模言語モデル API における PDF 入力の核心ポイント
| 要点 | 説明 | 影響 |
|---|---|---|
| API は PDF を直接受け付けない | GPT、DeepSeek、Llama、Qwen などの主流モデル API の標準入力はテキストと画像 | 前処理のプロセスが必要 |
| ウェブ版 ≠ API | ChatGPT、Claude ウェブ版の PDF アップロードは、フロントエンドで前処理を行った後に API を呼び出している | ウェブ版の体験を API の能力と混同しないこと |
| サードパーティプラットフォームも同様に非対応 | APIYI などの API中継サービスは元の API プロトコルを透過的に転送するため、基盤がサポートしていなければプラットフォームもサポートしない | 中継プラットフォームが追加で PDF を処理することを期待しないこと |
| 3つの前処理手法は成熟して信頼性が高い | テキスト化抽出、画像理解、クライアント処理はそれぞれ適したシナリオがある | 「PDF をサポートする API」を探すよりも、適切な手法を選ぶことが現実的 |
大規模言語モデル API が PDF 入力をサポートしない理由
多くの開発者が疑問に思うのは、ウェブ版では PDF をアップロードできるのに、なぜ API ではできないのか?その理由は単純です。ウェブ版の「PDF アップロード」機能は、モデル自体が PDF を処理しているのではなく、フロントエンド/バックエンドがユーザーに見えないところで前処理を行っているからです:
- テキスト抽出: フロントエンドが PDF 内のテキストを抽出し、プレーンテキストに変換してからモデルに渡す
- ページレンダリング: PDF の各ページを画像としてレンダリングし、Vision 機能を使ってモデルに理解させる
- RAG 検索: PDF の内容をベクトル化して保存し、会話時に関連する断片のみをモデルに送信する
これらの前処理ステップは、ウェブ版製品の中にカプセル化されており、ユーザーはそれを意識することはありません。しかし、API を直接呼び出す場合、これらの前処理は自分で行う必要があります。
大規模言語モデル API の PDF サポート状況 早見表
| モデル | API での PDF 直接送信 | 標準入力形式 | PDF 処理の推奨方法 |
|---|---|---|---|
| GPT-4o / GPT-4.1 | 非対応 | テキスト + 画像(Base64) | 事前にテキストを抽出するか、画像に変換する |
| Claude | 一部対応(Beta) | テキスト + 画像 | 互換性と安定性のため、前処理プロセスを経ることを推奨 |
| Gemini | 一部対応 | テキスト + 画像 | 制御性を高めるため、前処理プロセスを経ることを推奨 |
| DeepSeek | 非対応 | プレーンテキスト | 事前にテキストを抽出する必要がある |
| Llama / Qwen | 非対応 | テキスト(一部は画像対応) | 事前にテキストを抽出する必要がある |
| APIYI などのサードパーティ | 非対応 | 元のプロトコルを透過的に転送 | 呼び出し前に自分で前処理を行う必要がある |
🎯 重要説明: Claude と Gemini の公式 API ドキュメントでは PDF 入力機能について言及されていますが、この機能には互換性と安定性に関する不確実性があり、APIYI などのサードパーティ中継プラットフォーム経由で呼び出す場合は PDF の直接送信をサポートしていません。互換性が最も高く、最も安定した方法として、前処理手法を統一して行うことをお勧めします。
大規模言語モデル API PDF 処理手法 1:事前のテキスト化抽出
これは最も汎用的で、コストが低く、すべてのモデルと互換性のある手法です。核となる考え方は、まず Python ライブラリを使って PDF を Markdown またはプレーンテキストに変換し、そのテキストをプロンプトとして API に渡すことです。
PDF テキスト化抽出ツール比較
| ツール | 速度 | 最適なシナリオ | 特徴 |
|---|---|---|---|
| PyMuPDF4LLM | ~0.14秒/ドキュメント | 汎用テキスト + 表抽出 | 速度と品質のバランスが最適、Markdown 出力 |
| pdfplumber | 中程度 | 表データの抽出 | 座標ベースの表抽出で精度が高い |
| Marker-PDF | ~11秒/ドキュメント | 複雑なレイアウトの忠実な変換 | 構造の保持が最も優れている、速度は遅め |
| PyPDF2 | 速い | シンプルなプレーンテキスト PDF | 軽量、基本的な抽出に適している |
PDF テキスト化抽出 コード例
以下は最も一般的な手法で、PDF テキストを抽出して大規模言語モデル API に渡します:
import pymupdf4llm
import openai
# ステップ1: PDF を Markdown に変換
md_text = pymupdf4llm.to_markdown("report.pdf")
# ステップ2: プレーンテキストを任意の大規模言語モデルに渡す
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"このレポートの核心ポイントを要約してください:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
適用シナリオ: 契約書、論文、レポート、技術文書など、テキストが主体の PDF。PDF にテキストレイヤーが埋め込まれている(スキャン画像ではない)限り、抽出効果は良好です。
推奨: テキスト化抽出手法は、すべての大規模言語モデル(GPT、Claude、DeepSeek、Llama、Qwen)と互換性があります。APIYI apiyi.com で API キーを取得すれば、1つのキーですべてのモデルを呼び出して比較テストを行うことができます。
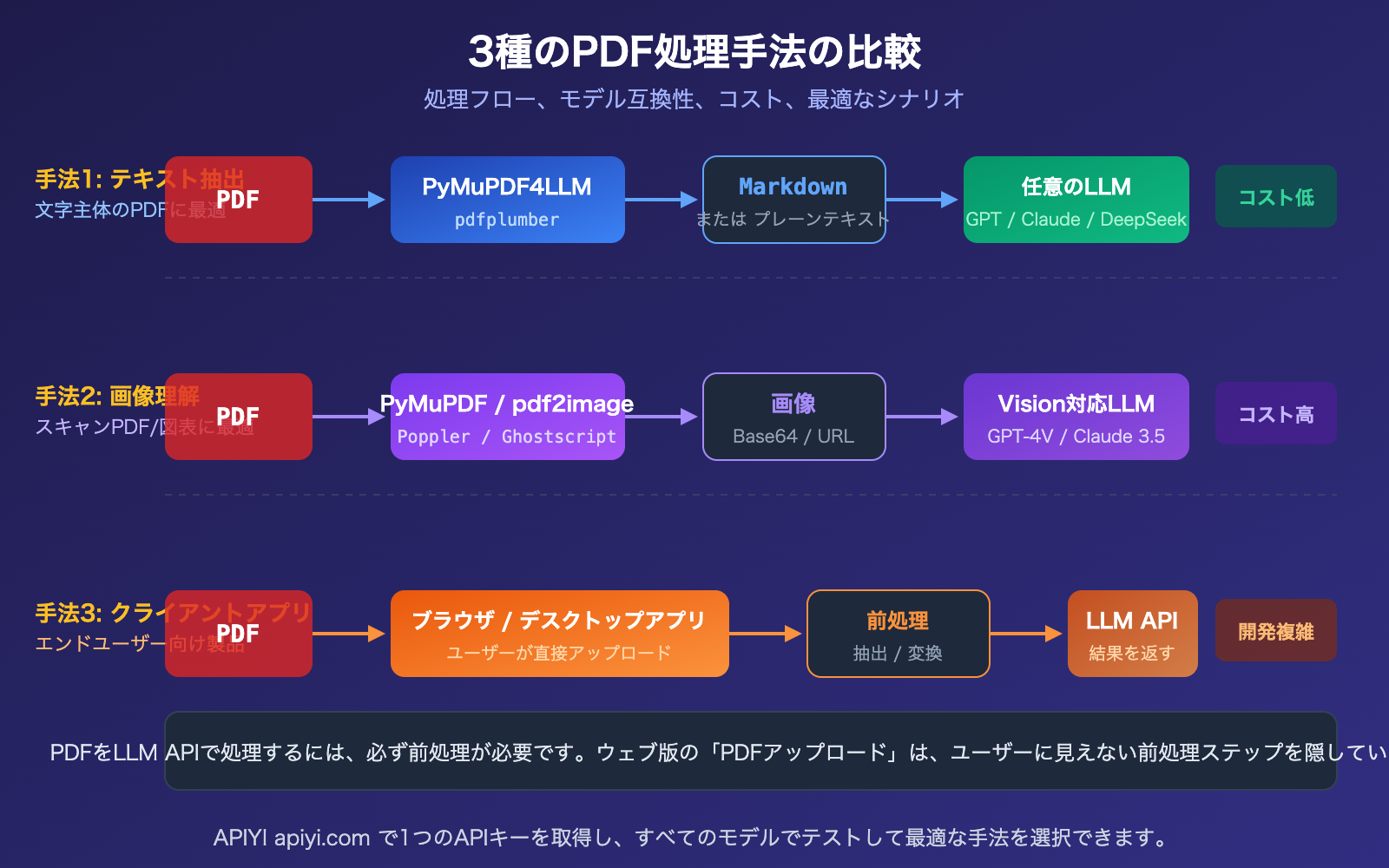
大規模言語モデル API PDF 処理ソリューション 2:画像変換 + 視覚理解
PDF に図表、スキャン画像、複雑なレイアウトなどの視覚情報が含まれている場合、純粋なテキスト抽出ではこれらの内容が失われてしまいます。このような場合、PDF の各ページを画像としてレンダリングし、Vision 機能をサポートするモデルを通じて画像理解を行う必要があります。
PDF から画像への変換コード例
import fitz # PyMuPDF
import base64
import openai
# ステップ1: PDF をページごとに PNG 画像に変換
doc = fitz.open("report.pdf")
images = []
for page in doc:
pix = page.get_pixmap(dpi=200)
b64 = base64.b64encode(pix.tobytes("png")).decode()
images.append(b64)
完全なコードを表示:画像を Vision API に渡す
import fitz
import base64
import openai
def pdf_to_vision(pdf_path, question, max_pages=10):
"""PDF を画像に変換して Vision API に渡す"""
doc = fitz.open(pdf_path)
# 複数画像メッセージの構築(トークン超過を避けるためページ数を制御)
content = [{"type": "text", "text": question}]
for i, page in enumerate(doc):
if i >= max_pages:
break
pix = page.get_pixmap(dpi=150)
b64 = base64.b64encode(pix.tobytes("png")).decode()
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{b64}"}
})
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
return response.choices[0].message.content
# 使用例
result = pdf_to_vision(
"financial_report.pdf",
"この財務報告書のトレンドチャートを分析し、主要データを要約してください",
max_pages=5 # ページ数を制御。1ページあたり約765トークン消費
)
print(result)
適用シナリオ: チャート付きの調査レポート、スキャン文書、請求書、建築図面など、視覚情報が豊富な PDF。
コスト注意: 1ページの画像は約 765 トークン(GPT-4o 標準解像度)を消費します。10ページの PDF では画像だけで約 7,650 トークン、テキストの質問と回答を加えると 10,000 トークンを超える可能性があります。ページ数の制御は必須です。
🎯 コスト管理のアドバイス: 一度に PDF の全ページを送信しないでください。まずソリューション1でテキストを抽出して大まかにフィルタリングし、重要なページを特定した後、ソリューション2で特定のページの画像理解を行います。APIYI apiyi.com の使用量ダッシュボードでトークン消費をリアルタイムに監視できます。
大規模言語モデル API PDF 処理ソリューション 3:AI クライアントでの処理
コードを書きたくなく、日常の会話の中で「PDF の内容について質問したい」だけの場合、AI クライアントを使用するのが最も手間のかからない方法です。
Cherry Studio などのクライアントにおける PDF 処理の仕組み
この種のクライアントは、基本的にソリューション1と2の作業を自動的に完了してくれます:
- 自動ベクトル化: PDF の内容を抽出し、小さなチャンクに分割してローカルベクトルデータベースに保存します。
- 意味的検索: 質問時に、クライアントはまず最も関連性の高い内容の断片を検索します。
- 正確な送信: 全文ではなく、関連する断片のみを大規模言語モデル API に送信します。
- トークンの節約: RAG 検索により、モデルに送信する内容量を大幅に削減します。
クライアントで PDF を処理する際の注意点
- API キーの設定: クライアントに APIYI apiyi.com の API キーを入力するだけで、1つのキーですべてのモデルにアクセスできます。
- ファイルサイズの制御: 超大容量の PDF(数百ページ)はベクトル化に時間がかかるため、分割して処理することをお勧めします。
- トークン費用に注意: RAG は内容を圧縮しますが、長文書では依然として高い費用が発生する可能性があります。
- 適切なモデルの選択: 簡単な質問には安価なモデル(例:GPT-4o-mini)、複雑な分析にはフラッグシップモデルを使用します。
大規模言語モデル API を用いた PDF 処理 3 つの手法比較

| 手法 | Token コスト | 図表サポート | 開発難易度 | モデル互換性 | 最適なシナリオ |
|---|---|---|---|---|---|
| テキスト抽出 | 最低(300-1500/ページ) | 非対応 | 中程度 | 全てのモデル | テキスト主体のPDF、大量処理 |
| 画像変換理解 | 高い(~765/ページ) | 完全対応 | 中程度 | Visionモデルが必要 | 図表、スキャン文書 |
| クライアント処理 | 中程度(RAG圧縮) | クライアント依存 | コード不要 | 全てのモデル | 日常会話、非開発者向け |
比較のポイント: 3つの手法は排他的ではなく、実際のプロジェクトでは組み合わせて使用されることが多いです。例えば、まず手法1でテキストを抽出して大まかな選別を行い、重要なページに対して手法2で画像理解を適用します。APIYI apiyi.com を通じて、すべてのモデルに統一してアクセスできます。
よくある質問
Q1: ChatGPTのウェブ版はPDFをアップロードできるのに、なぜAPIはサポートしていないのですか?
ウェブ版の「PDFをアップロード」機能は、製品のフロントエンドが前処理(テキストの抽出、画像のレンダリング、検索インデックスの作成)を行い、その後で基盤となるAPIを呼び出しています。API自体のコア入力形式はテキストと画像であり、複雑なドキュメントコンテナ形式であるPDFは標準サポートの対象外です。APIを呼び出す際には、これらの前処理ステップを自分で完了させる必要があります。
Q2: APIYIなどのサードパーティ中継プラットフォームは、PDFの処理を代行してくれますか?
いいえ、できません。APIYIなどのAPI中継サービスの本質は、APIリクエストを透過的に転送することです。基盤となるプロトコルがPDFをサポートしていない場合、プラットフォームも処理できません。APIを呼び出す前に、PDFの前処理(テキストの抽出または画像への変換)を自分で行い、処理済みのテキストまたは画像をAPIYI apiyi.comを通じて大規模言語モデルに送信する必要があります。
Q3: PDFを処理する際、トークン費用をどのように管理すればよいですか?
いくつかの実用的なテクニックをご紹介します:
- コストが最も低いため、まず**方法1(テキスト抽出)**を優先してください
- 必要なページだけを処理し、一度にドキュメント全体を送らないでください
- RAG技術で分割+検索を行い、関連する部分だけをモデルに送信します
- 簡単な質問には安価なモデル(GPT-4o-mini)を、複雑な分析にはフラッグシップモデルを使用します
- APIYI apiyi.comの使用量パネルで消費量をリアルタイムに監視します
まとめ
大規模言語モデルAPIへのPDF入力に関する核心的なポイント:
- ほとんどのAPIは直接的なPDF入力をサポートしていません: 大規模言語モデルのコア入力はテキストと画像であり、PDFを使用するには前処理が必要です
- サードパーティプラットフォームも同様にサポートしていません: APIYIなどのAPI中継サービスは元のプロトコルを転送するため、PDFを追加で処理することはできません
- 3つの方法からニーズに合わせて選択: 純粋なテキストPDFには文字化け抽出(最もコスト効率が良い)、画像付きPDFには画像変換理解(最も忠実度が高い)、日常的な対話にはクライアントアプリ(最も手間がかからない)
「どのAPIがPDFをサポートしているか」にこだわるのではなく、適切な前処理方法を選ぶことに集中してください——これが正しい考え方です。
APIYI apiyi.comで無料枠を取得し、PDFを前処理した後、1つのAPIキーでGPT、Claude、DeepSeekなどすべての主要モデルを呼び出してテスト・比較することをお勧めします。
📚 参考文献
-
PyMuPDF4LLM ドキュメント: PDFテキスト抽出ツール
- リンク:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - 説明: 最速のPDFからMarkdownへの変換ツール。優先的に推奨します。
- リンク:
-
pdfplumber ドキュメント: 表抽出専用ツール
- リンク:
github.com/jsvine/pdfplumber - 説明: PDF内の表データ抽出で最も精度の高いツールです。
- リンク:
-
Cherry Studio: オープンソースAIクライアント
- リンク:
github.com/CherryHQ/cherry-studio - 説明: PDFをドラッグ&ドロップで会話に追加できる無料クライアント。APIYIをバックエンドとして設定可能です。
- リンク:
-
APIYIプラットフォーム ドキュメント: 主要な大規模言語モデルAPIへの統一アクセス
- リンク:
docs.apiyi.com - 説明: APIキーの取得方法、モデル一覧、呼び出し例など。
- リンク:
著者: APIYI 技術チーム
技術交流: コメント欄での議論を歓迎します。詳細な資料はAPIYIのドキュメントセンターdocs.apiyi.comをご覧ください。