数学問題の解決にどのAIモデルを使うべきかは、開発者や学生にとって常に重要な選択肢の一つです。本記事では、2026年に最新リリースされた数学推論モデルであるGemini 3.1 Pro Preview、Claude Sonnet 4.6、GPT-5.4の3つを比較し、ベンチマークテストのスコア、推論能力、API価格、適したシナリオなどの観点から明確なアドバイスを提供します。
核心的な価値:この記事を読むことで、さまざまな数学問題解決シナリオにおいてどのAIモデルを選択すべきか、そしてそれらを最適なコストで呼び出す方法を明確に理解できるようになります。

数学問題解決AIモデル 主要比較速覧
詳細な分析に入る前に、主要データ比較表を見て、3つの数学問題解決AIモデルの重要な違いを素早く把握しましょう。
| 比較項目 | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| リリース日 | 2026年2月19日 | 2026年初頭 | 2026年3月6日 |
| AIME 2025 | 92%(ツールなし) | — | 100%(満点) |
| MATH ベンチマーク | 95.1% | 89% | 88.6% |
| GPQA Diamond | 94.3% | 74.1% | 84.2% |
| ARC-AGI-2 | 77.1% | 58.3% | 73.3% |
| 入力価格 | $2.00/100万トークン | $3.00/100万トークン | $2.50/100万トークン |
| 出力価格 | $12.00/100万トークン | $15.00/100万トークン | $15.00/100万トークン |
| 総合おすすめ度 | ⭐ 第一候補 | ⭐ 学習向け第一候補 | ⭐ 競技向け第一候補 |
数学問題解決AIモデル おすすめ順位
総合的なコストパフォーマンスの観点から、以下の順位付けを提案します:
- 第一候補 Gemini 3.1 Pro Preview:MATHベンチマーク95.1%でトップ、価格が最も低く、総合的な数学能力が最も高い
- 第二候補 Claude Sonnet 4.6:数学能力が27ポイント向上、解答プロセスが明確で理解しやすく、学習シーンに適している
- 競技レベル GPT-5.4:AIME 2025で満点100%、高難度の数学競技や専門研究に適している
🎯 技術アドバイス:3つのモデルはすべてAPIYI apiyi.comプラットフォームで統一して呼び出すことができます。実際の数学問題でそれぞれテストを行い、あなたのニーズに最も合ったモデルを選ぶことをおすすめします。
Gemini 3.1 Pro Preview 数学問題解決能力の詳細解説
Gemini 3.1 Pro Previewは、Google DeepMindが2026年2月19日にリリースした最新のフラッグシップモデルです。これはGoogleが初めて「.1」バージョンの増分を使用したもので(これまでの中間アップデートはすべて「.5」を使用)、知的推論能力に特化した指向性アップグレードであることを示しています。
Gemini 3.1 Pro 数学ベンチマークテスト成績
| ベンチマークテスト | スコア | 説明 |
|---|---|---|
| MATH | 95.1% | 代数、幾何、微積分など多分野をカバーする総合数学テスト |
| AIME 2025(ツールなし) | 92% | アメリカ数学招待試験、高校競技レベル難易度 |
| AIME 2025(コード実行) | 100% | 前世代Gemini 3 Proがコード実行を有効にすると満点 |
| GPQA Diamond | 94.3% | 大学院レベルの科学Q&A、すべての同級モデルをリード |
| ARC-AGI-2 | 77.1% | 抽象的推論能力、前世代3 Proから倍増 |
| MathArena Apex | 顕著にリード | 前世代から20倍以上向上 |
Gemini 3.1 Proは、Googleが公式に発表した18の主要ベンチマークテストのうち、12項目で1位の成績を収めました。数学推論においては、MATHベンチマーク95.1%の成績が特に際立っており、代数、幾何、確率、微積分など数学の各サブ分野において非常に強力な問題解決能力を備えていることを意味します。
Gemini 3.1 Pro 三段階思考システム
Gemini 3.1 Proは、重要なアーキテクチャ革新を導入しました——三段階思考システムです:
- Low(高速モード):単純な数学計算や公式の導出を処理し、応答速度が最速
- Medium(バランスモード):新たに追加された中間層、中程度の難易度の数学問題を処理し、速度と正確性のバランスを取る
- High(深度モード):競技レベルの数学問題のような複雑な多段階推論問題を処理
この三段階システムにより、開発者は数学問題の難易度に応じて柔軟にルーティングでき、「速いが粗い」と「遅いが精密」の二者択一を迫られることがありません。異なる難易度の数学問題を一括処理するシナリオ(例えば教育プラットフォームの適応型出題システム)では、このアーキテクチャの優位性が特に顕著です。
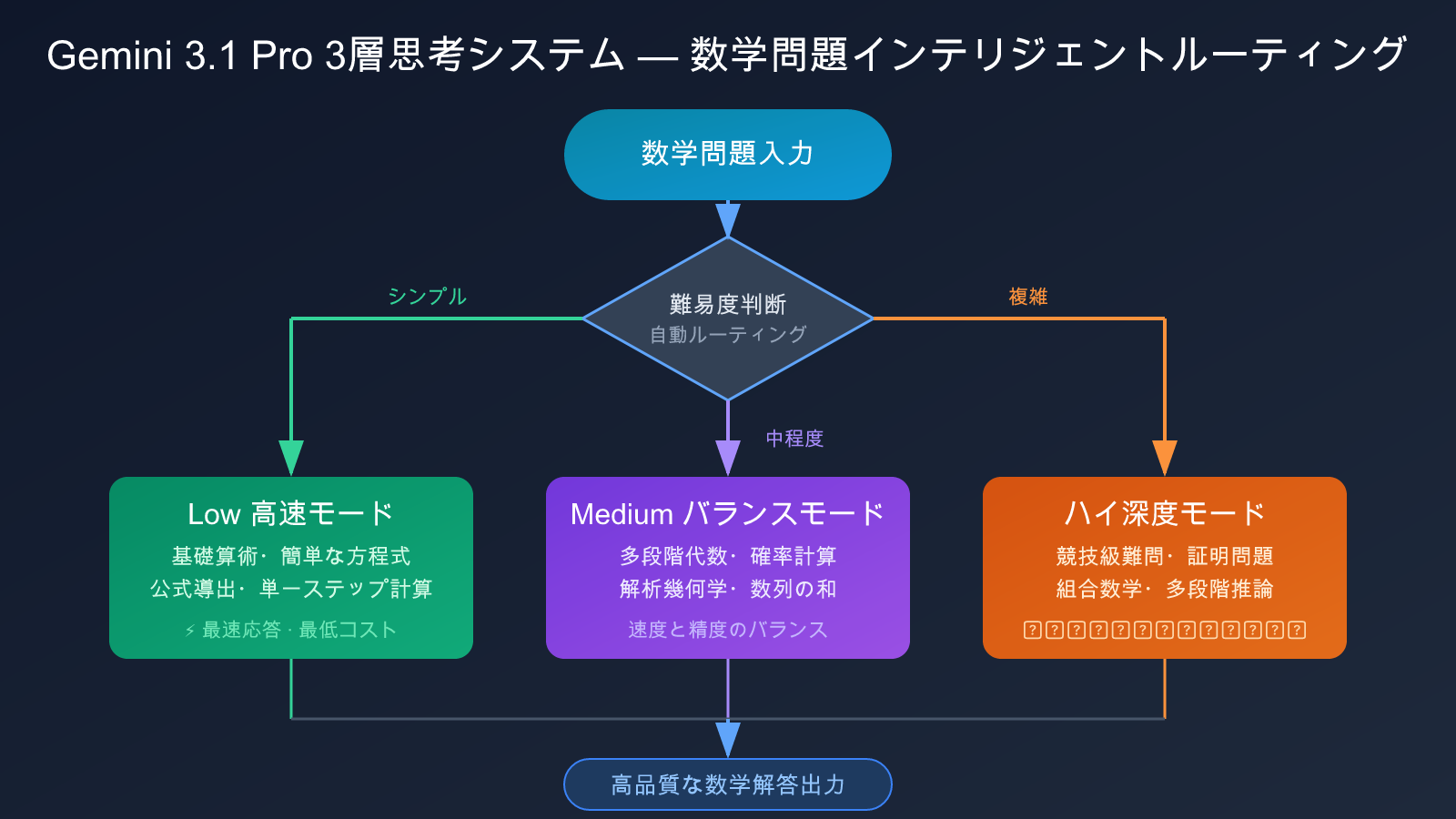
Gemini 3.1 Pro 数学問題解決の実際の体験
実際の数学問題解決において、Gemini 3.1 Pro Previewのパフォーマンスは「包括的で安定している」と要約できます:
- 代数分野:多項式演算、連立方程式の求解、不等式の証明などの問題はほぼミスなく、MATH 95.1%の高いカバレッジに支えられています
- 幾何分野:解析幾何学と立体幾何学の推論チェーンが完全で、特に座標系に関連する計算問題で優れたパフォーマンスを示します
- 確率統計:条件付き確率、順列組み合わせなどの問題の推論ロジックが明確で、複雑な段階的計算を正しく処理できます
- 微積分:定積分、不定積分の求解が正確で、一般的な積分テクニックを認識し正しく適用できます
Gemini 3.1 Proが18の主要ベンチマークで12項目1位の成績を収めたのは偶然ではありません。そのArtificial Analysis Intelligence Indexスコアは57点で、GPT-5.4(xhigh)と並んで1位であり、中央値28点を大きく上回り、全方位的な知的推論の優位性を示しています。
Claude Sonnet 4.6 数学解题能力の詳細
Claude Sonnet 4.6は、Anthropicがリリースした最新の中間層モデルであり、数学的推論能力において質的な飛躍を遂げました。前世代のSonnet 4.5の62%から、一気に89%へと向上し、実に27パーセントポイントの大幅な改善です。
Claude Sonnet 4.6 数学ベンチマークテスト結果
| ベンチマークテスト | Sonnet 4.6 | Sonnet 4.5(前世代) | 向上幅 |
|---|---|---|---|
| 数学総合 | 89% | 62% | +27 パーセントポイント |
| ARC-AGI-2 | 58.3% | 13.6% | 4.3倍の向上 |
| GPQA Diamond | 74.1% | — | 大学院レベルの科学的推論 |
| プログラミング能力 | 79.6% | — | Opus 4.6の80.8%に接近 |
| 金融分析 | 63.3% | — | 同クラスで最高 |
数学能力が62%から89%へと飛躍したことは、Sonnet 4.6の最も注目すべき変化の一つです。これは、「時々数学の問題で間違えるモデル」から、「複雑な計算を確実に処理できるモデル」へと変貌したことを意味します。
Claude Sonnet 4.6 適応的思考メカニズム
Claude Sonnet 4.6のもう一つの見どころは、適応的思考深度(Adaptive Thinking)メカニズムです。
- 単純な問題: 推論リソースを無駄にせず、迅速に応答します。例:基礎的な算術、簡単な方程式の求解
- 中程度の問題: 思考連鎖を適度に拡張します。例:多段階の代数演算、確率計算
- 複雑な問題: 自動的に深い推論連鎖を開始します。例:組合せ数学、証明問題、競技レベルの問題
この適応的メカニズムの実際の使用における利点は、推論深度を手動で調整する必要がなく、モデルが自動的に数学問題の難易度を判断し、適切な計算リソースを割り当てることで、遅延とコストの最適なバランスを実現することです。
Claude Sonnet 4.6 の独自の強み:解答プロセス
数学の問題解決シナリオにおいて、Claude Sonnet 4.6には広く認められている独自の強みがあります。それは、解答プロセスの明瞭さです。複数の評価で、Claudeモデルは数学的概念の説明において最高のパフォーマンスを示すと指摘されています。さらに、Anthropicが導入したLearning Mode(学習モード)は、答えを直接与えるのではなく、学生の推論プロセスを導くために特別に設計されています。
これにより、Claude Sonnet 4.6は特に以下の用途に適しています:
- 数学教育および個別指導のシナリオ
- 解答手順を理解する必要がある学習者
- 解答の考え方を検証したい研究者
💡 学習アドバイス: あなたの核心的なニーズが「答えを得ること」だけでなく「数学の解答プロセスを理解すること」であるなら、Claude Sonnet 4.6が最良の選択です。APIYI apiyi.com で無料テスト枠を取得し、その解答プロセスの詳細さを体験できます。
GPT-5.4 数学解题能力の詳細
GPT-5.4は、OpenAIが2026年3月6日にリリースした最新のフラッグシップモデルです。これは、最先端の専門能力、プログラミング能力(GPT-5.3-Codexから)、ネイティブなコンピュータ操作、そして1.05Mトークンのコンテキストウィンドウを、単一のデフォルトモデルに統合した初めてのOpenAI推論モデルです。
GPT-5.4 数学ベンチマークテスト結果
| ベンチマークテスト | スコア | 説明 |
|---|---|---|
| AIME 2025 | 100%(満点) | 高校数学競技レベル、完璧なパフォーマンス |
| GSM8K | 99% | 小学校の文章題、ほぼ完璧 |
| MATH | 88.6% | 総合数学推論ベンチマーク |
| GPQA Diamond | 84.2%(標準)/ 92.8%(高推論) | 大学院レベルの科学的推論 |
| ARC-AGI-2 | 73.3%(標準)/ 83.3%(Pro) | 抽象的推論能力 |
| FrontierMath(前世代 5.2) | 40.3% | 専門家レベルの最先端数学における新記録 |
GPT-5.4は、AIME 2025で驚異的な満点100%を達成しました。これは、アメリカ数学招待試験のすべての高難度競技問題を完璧に解決できることを意味します。競技レベルの数学問題を解決する必要があるユーザーにとって、このパフォーマンスは非常に説得力があります。
注目すべきは、GPT-5.4のMATHベンチマークでのスコアが88.6%であり、Gemini 3.1 Proの95.1%と比較して一定の差があることです。これは、GPT-5.4が競技レベルの難問では完璧なパフォーマンスを示す一方で、広範な数学分野をカバーする総合テストでは最強ではないことを示唆しています。
GPT-5.4 推論設定オプション
GPT-5.4は、さまざまな数学問題に適応するために複数の推論設定を提供しています:
- GPT-5.4 標準版: 日常的な数学計算や中程度の難易度の問題に適しています
- GPT-5.4 Thinking: 高度な推論を有効化し、複雑な多段階推論や証明に適しています
- GPT-5.4 Pro: 最高のパフォーマンス設定で、ARC-AGI-2で83.3%を達成可能。最高難易度のシナリオに適しています
ただし、GPT-5.4 Proの価格は$30.00/1M入力 + $180.00/1M出力であり、標準版よりもはるかに高コストであることに注意が必要です。ほとんどの数学問題解決シナリオでは、標準版で十分です。
GPT-5.4 数学問題解決の実際の体験
GPT-5.4は、競技レベルの数学問題におけるパフォーマンスが特に印象的です:
- 競技数学: AMC/AIMEレベルの数論、組合せ、幾何の総合問題に対してほぼ完璧に解答し、満点100%のAIME成績は名実ともに優れています
- 証明問題: 完全な数学的証明の連鎖を構築でき、論理的で厳密、かつステップ間のつながりが自然です
- 応用数学: GSM8Kで99%の成績は、実際の応用問題(エンジニアリング計算、経済モデリングなど)においても非常に信頼性が高いことを示しています
- 多段階推論: 1.05Mトークンの超長いコンテキストウィンドウのおかげで、完全な推論連鎖を維持しながら、非常に複雑な多段階の数学問題を処理できます
GPT-5.4の独自の強みの一つは、その前世代であるGPT-5.2がFrontierMath(専門家レベルの最先端数学)で40.3%という新記録を樹立したことです。これは、GPTシリーズが、真に最先端の、未解決の数学問題においても一定の探求能力を備えていることを意味し、これは現在他のモデルでは達成が難しいものです。
数学問題解決AIモデル ベンチマークテスト解説
数学問題解決AIモデルを比較する前に、各ベンチマークテストの意味と重点を理解し、モデルの能力をより正確に判断することが重要です:
| ベンチマークテスト | 正式名称 | テスト内容 | 難易度レベル |
|---|---|---|---|
| AIME 2025 | American Invitational Mathematics Examination | アメリカ数学招待試験の過去問、数論、組み合わせ、幾何などを含む | 高校競技レベル(上位5%の学生) |
| MATH | Mathematics Aptitude Test of Heuristics | 代数、幾何、微積分など7分野をカバーする総合テスト | 高校から大学学部レベル |
| GSM8K | Grade School Math 8K | 8000問の小学校から中学校レベルの文章題 | 基礎レベル |
| GPQA Diamond | Graduate-Level Google-Proof QA | 大学院レベルの科学的推論問題、分野の専門家が作成 | 大学院/博士レベル |
| ARC-AGI-2 | Abstraction and Reasoning Corpus | 新しい論理パターン認識、抽象的推論能力をテスト | 汎用人工知能レベル |
| FrontierMath | Frontier Mathematics | 専門家レベルの最先端数学問題、未解決または新分野を含む | 専門家/研究者レベル |
重要な理解点:AIMEは競技レベルの数学的テクニックと創造的思考に重点を置き、MATHは広範な分野の総合的なカバー能力に重点を置いています。あるモデルがAIMEで満点でもMATHで最高得点ではない場合(例:GPT-5.4)、それは競技レベルの巧妙な問題には非常に強いが、一部の基礎分野でのカバー範囲がMATHでより高い得点のモデルにやや劣る可能性があることを示しています。
これが、総合的な第一選択としてGemini 3.1 Pro Previewを推奨する理由です——MATH 95.1%は、あらゆる数学のサブ分野でよりバランスの取れたパフォーマンスを意味します。
注意すべき点は、AIME 2025ベンチマークは現在飽和状態に近づいていることです——複数のトップモデル(コード実行と組み合わせて)が95%以上、さらには満点を達成できます。したがって、モデルの真の数学的能力をより区別できるのは、MathArena ApexやFrontierMathのようなより高難度のベンチマークです。MathArena Apexでは、Gemini 3.1 Proは前世代比で20倍以上の向上を示し、非常に強力な内在的数学的推論基盤を示しています。
もう一つ注目すべき次元は、ARC-AGI-2(抽象的推論能力) です。このテストは、モデルが訓練中に一度も見たことのない新しい論理パターンを認識する能力を評価します。Gemini 3.1 Pro Previewが77.1%でリードしていることは、見たことのある問題を解決するだけでなく、より強力な汎化推論能力を持ち、全く新しいタイプの数学問題に直面した際により良いパフォーマンスを発揮することを示唆しています。
数学問題解決AIモデル API呼び出し実践
以下は、APIを使用して数学問題解決AIモデルを呼び出す最小限のコード例です。10行のコードで実行できます:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # APIYI 統一インターフェース
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # claude-sonnet-4.6 や gpt-5.4 に切り替え可能
messages=[{"role": "user", "content": "求解: 已知等差数列{an}的首项a1=2,公差d=3,求前20项的和S20"}]
)
print(response.choices[0].message.content)
完全な数学問題解決呼び出しコードを表示(複数モデル比較含む)
import openai
from typing import Optional
def solve_math(
problem: str,
model: str = "gemini-3.1-pro-preview",
system_prompt: Optional[str] = None
) -> str:
"""
AIモデルを呼び出して数学問題を解く
Args:
problem: 数学問題の説明
model: モデル名、gemini-3.1-pro-preview / claude-sonnet-4.6 / gpt-5.4 をサポート
system_prompt: システムプロンプト、解答スタイルを指定可能
Returns:
モデルの解答応答
"""
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # APIYI 統一インターフェース
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
else:
messages.append({
"role": "system",
"content": "あなたは数学問題解決の専門家です。数学問題を明確なステップで解答し、各ステップの推論根拠を説明してください。"
})
messages.append({"role": "user", "content": problem})
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=2000
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 使用例:同じ問題を3つのモデルで解答比較
problem = "在三角形ABC中,已知a=5, b=7, C=60°,求三角形面积和第三边c的长度"
models = ["gemini-3.1-pro-preview", "claude-sonnet-4.6", "gpt-5.4"]
for m in models:
print(f"\n{'='*50}")
print(f"モデル: {m}")
print(f"{'='*50}")
result = solve_math(problem, model=m)
print(result)
提案:APIYI apiyi.com で無料テストクレジットを取得し、1つのAPIキーで上記3つの数学問題解決モデルを呼び出し、実際の問題におけるパフォーマンスの違いを素早く比較できます。
数学問題解決AIモデルの価格とコストパフォーマンス比較
数学問題解決AIモデルを選択する際、価格は無視できない要素です。以下は3つのモデルの詳細な価格比較です:
| 価格次元 | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| 入力価格 | $2.00/100万トークン | $3.00/100万トークン | $2.50/100万トークン |
| 出力価格 | $12.00/100万トークン | $15.00/100万トークン | $15.00/100万トークン |
| 混合価格(3:1) | $4.50/100万トークン | $6.00/100万トークン | $5.63/100万トークン |
| 長いコンテキスト追加料金 | >200Kで2倍 | なし | >272Kで2倍 |
| コンテキストウィンドウ | 100万トークン | 標準ウィンドウ | 105万トークン |
| 最大出力 | 65,536トークン | 標準出力 | 128,000トークン |
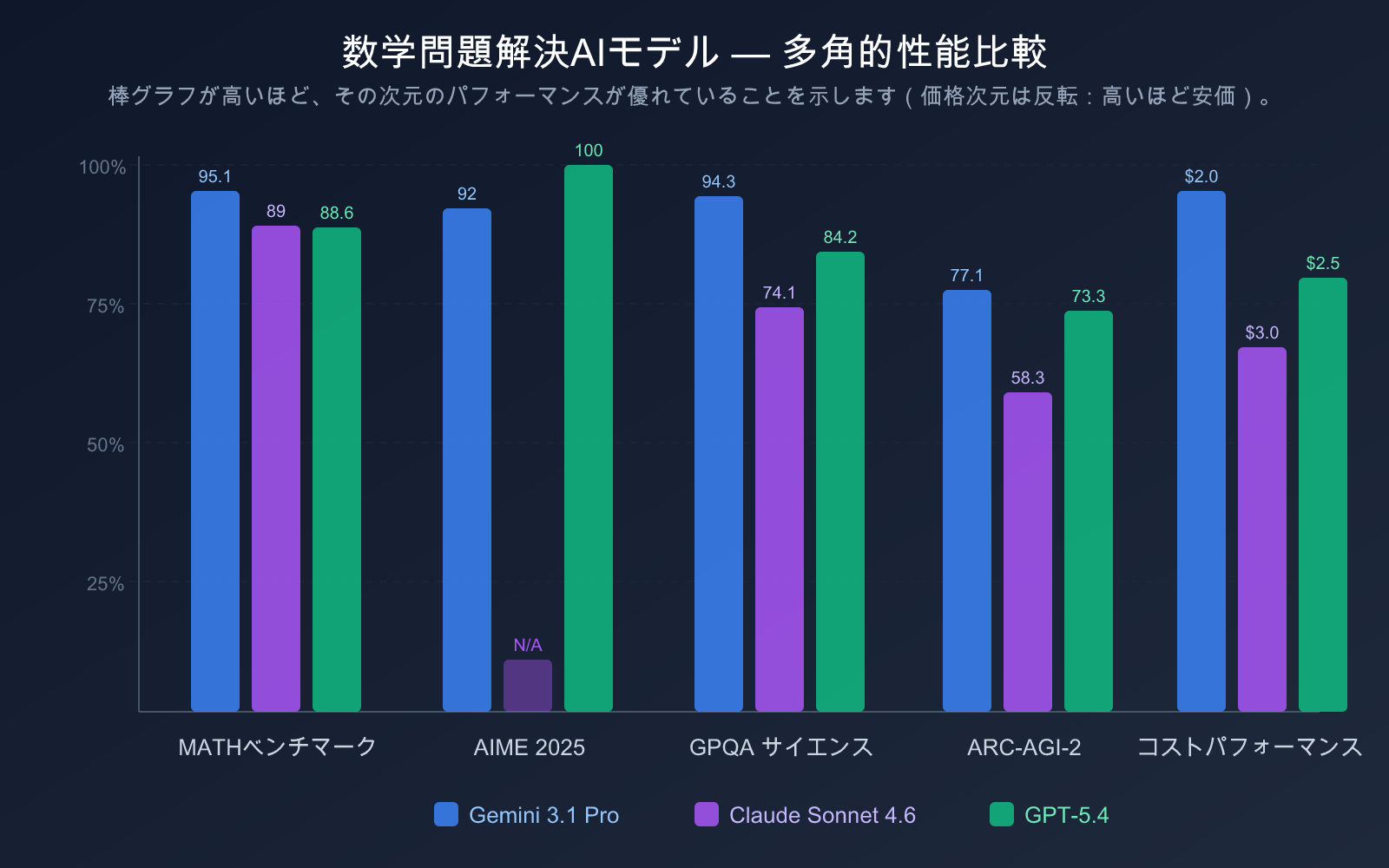
コストパフォーマンスの観点から分析すると:
- Gemini 3.1 Pro Preview が最もコストパフォーマンスが高い:入力価格がわずか$2.00/100万トークンで、MATHベンチマークで95.1%の成績を達成しリードしています。Artificial Analysisの分析によると、その運用コストはClaude Opus 4.6の約1/7.5でありながら、数学とプログラミングのベンチマークでは同等かそれ以上の性能を発揮しています
- Claude Sonnet 4.6 は価格が適正:$3.00/$15.00の価格設定は前世代のSonnet 4.5と同等ですが、数学能力は27パーセントポイント向上しており、コストパフォーマンスが大幅に改善されています
- GPT-5.4 標準版は価格が合理的:$2.50/$15.00の価格設定は妥当な範囲内ですが、GPT-5.4 Pro($30/$180)を使用するとコストが大幅に上昇します
💰 コストに関するアドバイス:日常的な数学問題解決のニーズには、最適なコストパフォーマンスを得るためにGemini 3.1 Pro Previewの使用をお勧めします。さらにコストを最適化したい場合は、APIYIなどのAPI中継サービスを利用してより柔軟な料金プランを検討することもできます。
数学問題解決の実際のコスト見積もり
コストの違いをより直感的に理解していただくために、典型的な数学問題解決シナリオのコスト見積もりを以下に示します:
シナリオの前提:毎日100問の中程度の難易度の数学問題を解答し、各問題で平均500入力トークン+1500出力トークンを消費します。
| モデル | 日次入力コスト | 日次出力コスト | 日次総コスト | 月間コスト(30日) |
|---|---|---|---|---|
| Gemini 3.1 Pro | $0.10 | $1.80 | $1.90 | $57.00 |
| GPT-5.4 | $0.13 | $2.25 | $2.38 | $71.25 |
| Claude Sonnet 4.6 | $0.15 | $2.25 | $2.40 | $72.00 |
| GPT-5.4 Pro | $1.50 | $27.00 | $28.50 | $855.00 |
| DeepSeek R2 | $0.03 | $0.33 | $0.36 | $10.80 |
コスト見積もりから明確にわかることは:
- Gemini 3.1 Pro Previewの月間コストは約$57で、3つの主力モデルの中で最も経済的です
- Claude Sonnet 4.6とGPT-5.4標準版のコストはほぼ同等で、約$71-72/月です
- GPT-5.4 Proのコストは$855/月と高額で、予算が豊富で極めて高い精度が必要なシナリオにのみ適しています
- DeepSeek R2は$10.80/月という超低コストで、非常に競争力のあるソリューションを提供しています
数学問題解決AIモデル 総合知能指数比較
単体のベンチマークテストに加えて、総合知能指数はモデルの数学的推論ポテンシャルをより包括的に反映します。Artificial Analysis Intelligence Indexは現在最も権威ある総合評価体系の一つであり、推論、知識、数学、プログラミングの4つの次元に基づいてモデルの総合スコアを計算します。
| モデル | 総合知能指数 | AIME 2025 | MATH | GPQA Diamond | ARC-AGI-2 | 総合評価 |
|---|---|---|---|---|---|---|
| GPT-5.4(xhigh) | 57 | 100% | 88.6% | 84.2% | 73.3% | 競技問題の王者、総合指数で首位タイ |
| Gemini 3.1 Pro Preview | 57 | 92% | 95.1% | 94.3% | 77.1% | 総合指数で首位タイ、数学カバレッジが最も広範 |
| Claude Opus 4.6 | 53 | — | — | 91.3% | — | 科学的推論と説明能力がトップクラス |
| Claude Sonnet 4.6(max) | 52 | — | 89% | 74.1% | 58.3% | コストパフォーマンス優秀、解答プロセスが最も明確 |
総合知能指数から見ると、GPT-5.4(xhigh)とGemini 3.1 Pro Previewが57点で首位を分け合っていますが、両者の強みは異なります:
- GPT-5.4:AIMEのような競技問題で完璧なパフォーマンス(100%)を示しますが、MATH総合ベンチマーク(88.6%)はやや低めです。
- Gemini 3.1 Pro:MATH総合ベンチマーク(95.1%)と科学的推論GPQA Diamond(94.3%)でよりバランスの取れた結果を示しています。
これは、数学のニーズが競技や極端に難しい問題に偏っている場合はGPT-5.4が優位であり、広範な数学分野をカバーする安定したパフォーマンスが必要な場合はGemini 3.1 Pro Previewがより安全な選択肢であることを意味します。
数学問題解決AIモデル シーン別おすすめ
異なる数学応用シーンでは、モデルに異なる要求があります。以下は実際の使用シーンに基づく推奨プランです:
Gemini 3.1 Pro Previewを選ぶべき数学シーン
- 総合数学学習プラットフォーム:代数、幾何、微積分など全分野をカバー。MATH 95.1%の総合力が最強です。
- 大量の数学問題処理:価格が最も低く、3層思考システムが問題の難易度に自動適応し、処理コストを削減します。
- 科学計算との連携シーン:GPQA Diamond 94.3%の科学的推論能力を持ち、物理、化学と数学が交差する問題に適しています。
- 可視化された数学問題:図表や幾何学的図形を含む数学問題の処理において、Geminiのマルチモーダル能力が優位です。
Claude Sonnet 4.6を選ぶべき数学シーン
- 数学教育と学習指導:解答プロセスが最も明確。Learning Modeは学生の推論を導くことに特化し、直接答えを与えるのではなく思考を導きます。
- 解答ステップの学習:「なぜこのように解くのか」を理解する必要があるシーン。Claudeの説明能力は最高と公認されています。ユーザーの70%が前世代の4.5ではなくSonnet 4.6を好むことから、ユーザー体験が質的に向上したことがわかります。
- 数学研究の補助:詳細な導出プロセスを必要とする研究者がアイデアを検証するのに適しています。適応的思考深度が問題の複雑さに自動的にマッチします。
- オフィスおよび金融計算:金融分析63.3%で同クラス最高、オフィス生産性GDPval-AAスコア1633 Eloはより高価なOpus 4.6を超えています。
- プログラミング+数学の連携:プログラミング能力79.6%はOpus 4.6に近く、数学計算プログラムを作成する必要がある開発者に適しています。
GPT-5.4を選ぶべき数学シーン
- 高難度数学競技:AIME満点100%、競技レベルの数学問題の第一選択モデルです。
- 長文書の数学的推論:1.05Mのコンテキストウィンドウを持ち、大量の数学的背景情報を必要とする複雑な問題の処理に適しています。
- 専門的な数学研究:前世代GPT-5.2はFrontierMathで40.3%の新記録を樹立し、専門家レベルの最先端数学能力を持っています。
- 投資銀行と量的金融:投資銀行モデリングタスクで87.3%の高得点、高度な金融数学シーンに適しています。
併用戦略:数学問題解決モデルの最適な組み合わせ
実際の本番環境では、多くのチームが最適な結果を得るために併用戦略を採用しています:
戦略1:難易度別ルーティング
- 基礎問題(算数、簡単な方程式)→ Gemini 3.1 Pro Lowモード、コストが最も低い
- 中級問題(多段階推論、応用問題)→ Claude Sonnet 4.6適応モード、解答プロセスが明確
- 高難度問題(競技、証明)→ GPT-5.4思考モード、精度が最高
戦略2:クロスチェック
- まずGemini 3.1 Proで素早く解答(コスト低、速度速)
- 重要な結果はGPT-5.4で再検証(精度高)
- ユーザーに説明が必要な場合はClaude Sonnet 4.6で再表現(表現が明確)
🚀 実装アドバイス:上記の併用戦略は、APIYI apiyi.comプラットフォームで簡単に実装できます。1つのAPIキーですべてのモデルを呼び出せ、コード内でmodelパラメータを切り替えるだけです。
数学問題解決AIモデル 選択アドバイス
上記の分析を総合すると、以下のようなユーザータイプ別の選択アドバイスとなります:
| ユーザータイプ | 推奨モデル | 推奨理由 |
|---|---|---|
| 学生/独学者 | Claude Sonnet 4.6 | 解答プロセスが明確で、Learning Modeが思考を導く |
| 教育プラットフォーム開発者 | Gemini 3.1 Pro Preview | 総合能力が最も高く、価格が最も安く、三段階思考が難易度に適応 |
| 競技参加者/コーチ | GPT-5.4 | AIME満点、競技レベルの問題解決能力が最も高い |
| 研究者 | Gemini 3.1 Pro Preview | GPQA Diamond 94.3%、科学と数学のクロスオーバー能力がリード |
| 企業のバッチ処理 | Gemini 3.1 Pro Preview | コストパフォーマンスが最も高く、入力$2.00/1Mトークン |
| 金融定量分析チーム | GPT-5.4 | 投資銀行モデリング87.3%、金融数学シナリオで最強 |
💡 選択アドバイス:どの数学問題解決AIモデルを選ぶかは、主に具体的な応用シナリオによります。どれが最適かわからない場合は、APIYI apiyi.com プラットフォームで同じ数学問題を使って3つのモデルをテストし、解答の質と応答速度に基づいて最終的な選択を行うことをお勧めします。プラットフォームは統一インターフェースでの呼び出しをサポートしており、迅速な比較と切り替えが可能です。
注目すべきその他の数学問題解決モデル
上記の3つの主力モデルに加えて、特定のシナリオで注目に値する数学問題解決AIモデルがいくつかあります:
| モデル名 | AIME 2025 | コア強み | API価格(入力/出力) | 適したシナリオ |
|---|---|---|---|---|
| DeepSeek R2 | Gemini 3.1 Proを上回る | 究極のコストパフォーマンス | $0.55/$2.19 per 1M | 予算に敏感なバッチ数学処理 |
| Claude Opus 4.6 | — | GPQA 91.3%、説明が最も深い | $15/$75 per 1M | ハイエンド研究と深い推論 |
| Qwen3-235B | 89.2% | オープンソース最強 | 自己デプロイメントコスト | プライベートデプロイメントが必要なシナリオ |
| DeepSeek R1 | 約87.5% | オープンソースのベンチマーク、671B MoE | 自己デプロイメントコスト | オープンソースコミュニティの研究と二次開発 |
| MiMo-V2-Flash | 94.1% | 推論コストがClaudeのわずか2.5% | 極めて低い | 超大規模な低コスト推論 |
特に注目すべきは DeepSeek R2 で、AIMEでGemini 3.1 Pro Previewを上回りながら、価格は後者の約1/4です。数学問題解決シナリオで予算が非常に厳しい場合、DeepSeek R2は非常に競争力のある選択肢です。
一方、MiMo-V2-Flash はAIME 2025で94.1%の高スコアを達成しながら、推論コストはClaudeのわずか2.5%であり、大規模なバッチ処理が必要なEdTechプラットフォームに非常に適しています。
数学問題解決AIモデル プロンプト最適化テクニック
どのモデルを選択しても、優れたプロンプトは数学問題解決の質を大幅に向上させることができます。以下は検証済みの数学問題解決プロンプトテクニックです:
- 問題タイプを明確にする:プロンプトに「これは組み合わせ数学の問題です」や「これは解析幾何学の問題です」と注記し、モデルが正しい解決戦略を呼び出すのを助ける
- ステップバイステップの解答を要求する:「段階的に導出し、各ステップで使用する定理や公式を明記してください」を追加し、解答プロセスの可読性を向上させる
- 出力フォーマットを指定する:「数学公式はLaTeX形式で出力してください」や「最終答えはボックスで囲んでください」など
- 背景の制約を提供する:「xを正の整数と仮定する」や「実数範囲で解を求める」など、モデルが不必要な場合分けを生成するのを防ぐ
- 複数モデルでのクロスチェック:重要な結果については、異なるモデルで答えの一貫性を検証し、信頼度を高める
よくある質問
Q1:数学問題解決AIモデルのベンチマークスコアは信頼できますか?
ベンチマークは標準化された横断比較の根拠を提供しますが、実際の効果は問題の種類やプロンプトの質などの要因にも影響されます。AIMEとMATHは現在最も権威ある数学推論ベンチマークであり、学界と産業界で広く認められています。ベンチマークデータを参考にする一方で、ご自身の実際の問題を使ってテスト検証を行うことをお勧めします。
Q2:学生ですが、どの数学問題解決AIモデルを選べばよいですか?
Claude Sonnet 4.6を最初に試すことをお勧めします。その解答プロセスは最も明確で、各ステップに明確な推論説明があり、数学問題の解法を学習・理解するのに最適です。AnthropicのLearning Mode機能は、直接答えを出すのではなく、自分で考えるよう導くことができます。特に難しい競技問題に遭遇した場合は、GPT-5.4に切り替えて助けを求めることができます。
Q3:これらの数学問題解決AIモデルを素早くテスト開始するにはどうすればよいですか?
複数モデルの統一インターフェースをサポートするAPI集約プラットフォームを使用してテストすることをお勧めします:
- APIYI apiyi.com にアクセスしてアカウント登録
- APIキーと無料テスト枠を取得
- 本記事で提供しているPythonコード例を使用し、modelパラメータを変更するだけで異なるモデルに切り替え可能
- 同じ数学問題を使って3つのモデルをそれぞれテストし、解答の質と応答速度を比較
Q4:これらの数学問題解決AIモデルはLaTeX数式出力をサポートしていますか?
3つのモデルはいずれもLaTeX形式の数学式出力をサポートしています。プロンプトに「すべての数学式をLaTeX形式で出力してください」と追加するだけです。Gemini 3.1 ProとGPT-5.4のLaTeXフォーマットはより標準的で、Claude Sonnet 4.6は数式間のテキスト説明がより詳細です。論文に直接数式をコピーする必要がある場面では、GeminiまたはGPTの使用をお勧めします。
Q5:数学問題解決AIモデルは画像内の数学問題を処理できますか?
Gemini 3.1 Pro PreviewとGPT-5.4はいずれもマルチモーダル入力をサポートしており、数学問題を含む画像を直接アップロードして解答することができます。Geminiは幾何学図形や手書きの数式を含む画像の処理で特に優れたパフォーマンスを発揮します。Claude Sonnet 4.6も画像入力をサポートしていますが、複雑な幾何学図形の認識ではGeminiにやや劣ります。数学問題が頻繁に画像形式で現れる場合(例:写真検索問題)は、Gemini 3.1 Pro Previewが最適な選択です。
まとめ
数学問題解決AIモデルを選ぶ際の核心ポイント:
- 総合能力ならGemini 3.1 Pro Preview:MATH 95.1%で総合的にリード、$2.00/1Mトークンで最適な価格、3層思考システムで異なる難易度に柔軟に対応
- 学習理解ならClaude Sonnet 4.6:数学能力が27ポイント躍進して89%に、解答ステップが明確、適応的思考深度でコストと品質のバランスを取る
- 競技難問ならGPT-5.4:AIME 2025で満点100%、1.05Mの超長いコンテキストウィンドウ、高難度推論能力は他に並ぶものなし
すべての数学シナリオにおいて最適なモデルは一つもありません。2026年の数学問題解決AIモデルの競争状況は以下のようにまとめることができます:
- 総合カバレッジ:Gemini 3.1 Pro PreviewがMATH 95.1%と最低価格で総合首位の座を占める
- 学習教育:Claude Sonnet 4.6が27ポイントの数学躍進と比類なき解答説明能力により、教育シーンでの最適な選択となる
- 極限競技:GPT-5.4がAIME満点の絶対的な実力で、高難度数学競技領域では誰にも及ばない
- 予算優先:DeepSeek R2はGeminiの1/4以下の価格で同等の数学推論能力を提供
最も賢明な戦略は、実際のニーズに基づいて適切なモデルを選択し、さらには異なる難易度の問題で複数のモデルを混合使用し、各モデルの独自の強みを最大限に活用することです。
APIYI apiyi.comを通じてこれらのモデルを迅速にテスト・比較することをお勧めします。このプラットフォームは無料枠と統一APIインターフェースを提供し、一度の接続で主要な数学推論モデルをすべて柔軟に呼び出し、多モデル混合使用戦略を簡単に実現できます。
📚 参考文献
-
Google DeepMind Gemini 3.1 Pro モデルカード: 公式ベンチマークデータと技術詳細
- リンク:
deepmind.google/models/model-cards/gemini-3-1-pro/ - 説明: 完全なベンチマークテスト結果とアーキテクチャの説明を含む
- リンク:
-
Anthropic Claude Sonnet 4.6 リリースノート: 数学的推論能力向上の詳細
- リンク:
docs.anthropic.com - 説明: Sonnet 4.6 と前世代の比較データ、適応的思考メカニズムの説明を含む
- リンク:
-
OpenAI GPT-5.4 リリース発表: 最新モデルの機能とベンチマークデータ
- リンク:
openai.com/index/introducing-gpt-5-4/ - 説明: GPT-5.4 の完全なベンチマークテスト結果と推論設定の説明を含む
- リンク:
-
Artificial Analysis モデル評価: 独立したサードパーティのベンチマーク比較プラットフォーム
- リンク:
artificialanalysis.ai/evaluations/aime-2025 - 説明: AIME 2025 などのベンチマークテストの独立したランキングと分析を提供
- リンク:
-
AIME 2025 ベンチマークランキング: 数学的推論能力の権威ある比較
- リンク:
vals.ai/benchmarks/aime - 説明: 継続的に更新されるAI数学的推論ベンチマークのランキングデータ
- リンク:
著者: APIYI 技術チーム
技術交流: コメント欄であなたの数学問題解決AIの使用体験を共有してください。より多くのモデル呼び出しチュートリアルは APIYI docs.apiyi.com ドキュメントセンターでご覧いただけます。