作者注:Seed 2.0 Lite 260228 の入力コストはわずか $0.25/Mトークン、Gemini 3.1 Pro Preview は 1M トークンのコンテキストウィンドウと ARC-AGI-2 77.1% の推論能力を誇ります。本記事では、ベンチマーク、価格設定、コンテキストウィンドウなど6つの観点から、両モデルを詳細に比較します。
2026年2月、2つの異なるポジショニングを持つモデルが相次いで登場しました。ByteDanceの Seed 2.0 Lite 260228 は BytePlus 公式中継チャネルを通じてリリースされ、究極のコストパフォーマンスを追求。一方、Google DeepMind の Gemini 3.1 Pro Preview は、ARC-AGI-2 ベンチマークで推論能力が倍増した記録を更新しました。
本記事の価値: この記事を読めば、様々なビジネスシナリオにおいて Seed 2.0 Lite 260228 と Gemini 3.1 Pro Preview のどちらを選択すべきか、そして8倍の価格差の中で最適解を見つける方法が明確になります。
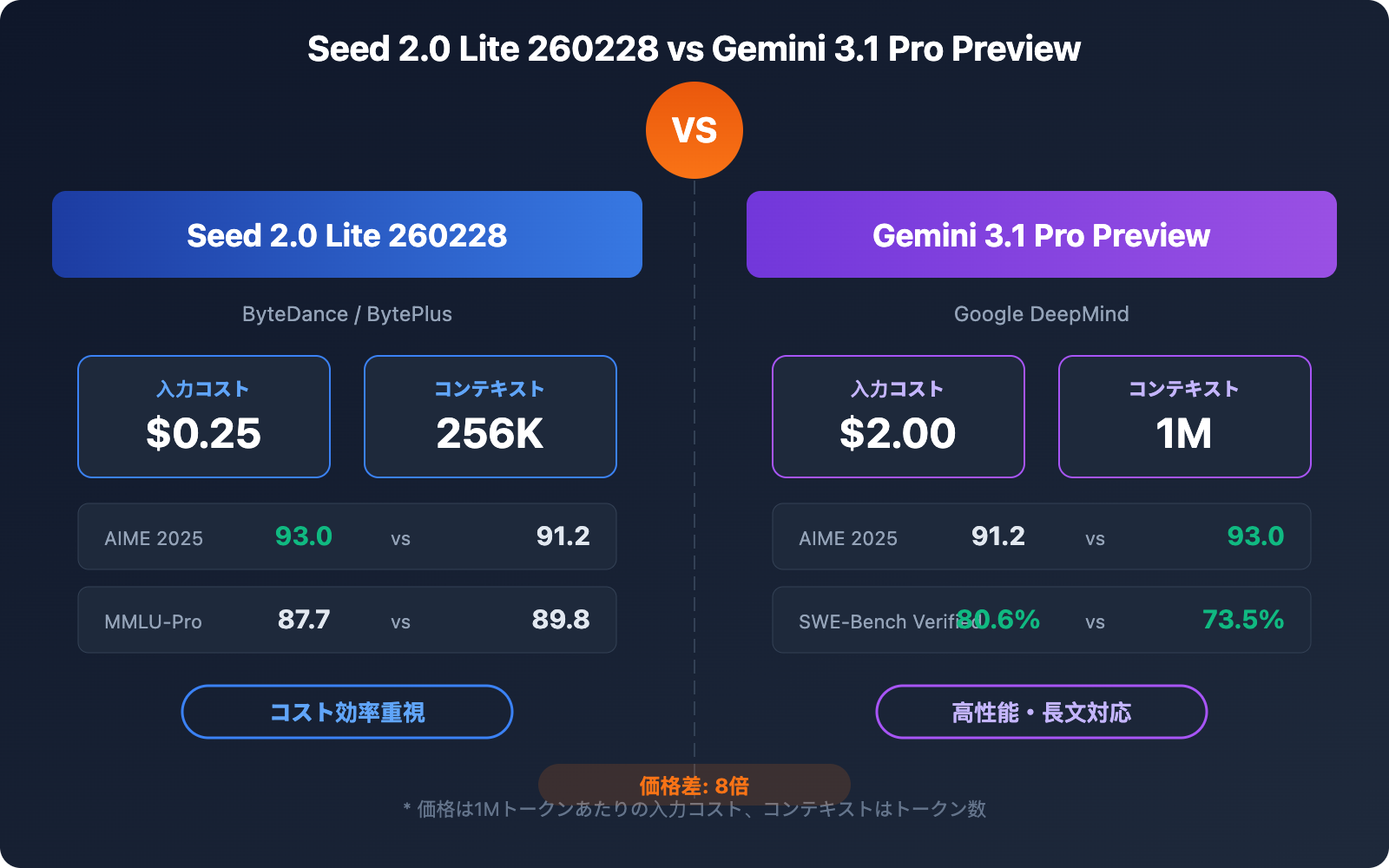
Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview の核心的な違い
| 観点 | Seed 2.0 Lite 260228 | Gemini 3.1 Pro Preview | 差異分析 |
|---|---|---|---|
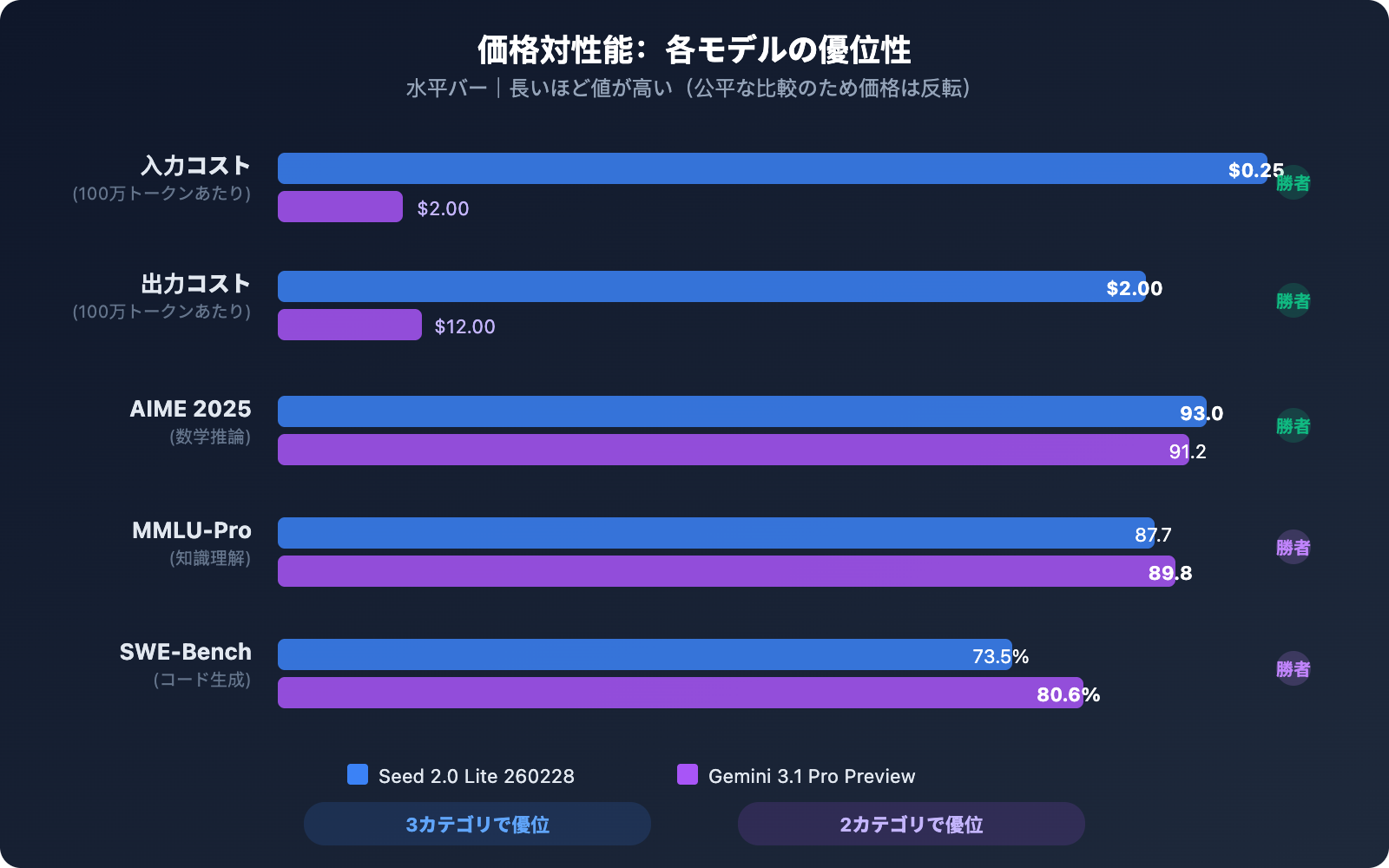
| 入力価格 | $0.25/M トークン | $2.00/M トークン | Seed が 8 倍安い |
| 出力価格 | $2.00/M トークン | $12.00/M トークン | Seed が 6 倍安い |
| コンテキストウィンドウ | 256K トークン | 1M トークン | Gemini が 4 倍大きい |
| AIME 2025 | 93.0 | 91.2 | Seed がやや高い |
| MMLU-Pro | 87.7 | 89.8 | Gemini がやや高い |
| SWE-Bench Verified | 73.5% | 80.6% | Gemini が 7 ポイントリード |
Seed 2.0 Lite 260228 と Gemini 3.1 Pro のポジショニングの違い
これら2つのモデルのポジショニングには根本的な違いがあります。Seed 2.0 Lite 260228 は ByteDance の Seed 2.0 シリーズの中間モデルであり、高コストパフォーマンスの本番環境向け汎用モデルとして位置づけられています。一方、Gemini 3.1 Pro Preview は Google DeepMind のフラグシップモデルであり、Gemini 3 Pro をベースに推論能力を大幅に向上させています。
価格面では、Seed 2.0 Lite の入力コストは Gemini 3.1 Pro のわずか8分の1です。しかし、Gemini 3.1 Pro は4倍のコンテキストウィンドウと、より強力なコードエンジニアリング能力を提供します。どちらのモデルを選択するかは、アプリケーションシナリオにおけるコストと能力の具体的な要件によって決まります。
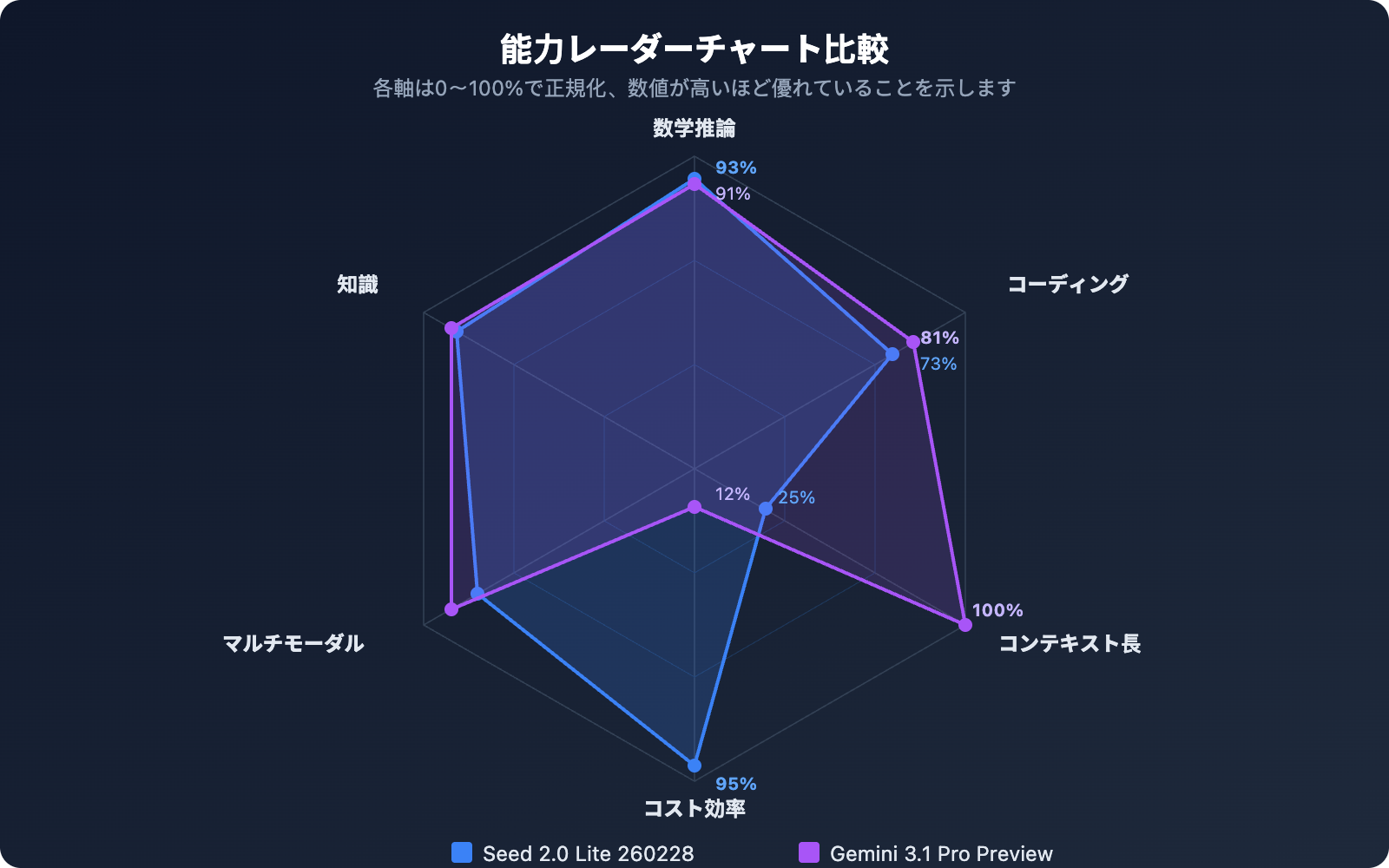
Seed 2.0 Lite 260228 対 Gemini 3.1 Pro Preview ベンチマーク比較
数学的推論能力の比較
AIME 2025 数学的推論ベンチマークにおいて、Seed 2.0 Lite 260228 は 93.0 点を獲得し、Gemini 3.1 Pro Preview の 91.2 点をわずかに上回りました。この結果は驚くべきものです——中価格帯のモデルが、フラッグシップ級の競合モデルを数学的推論で凌駕したのです。
留意点として、Seed 2.0 Pro (フラッグシップ版) は AIME 2025 で 98.3 点を達成しており、ByteDanceのSeedシリーズが数学的推論において深い技術的蓄積を持ち、Lite版もこの強みを受け継いでいることが示されています。
知識理解能力の比較
MMLU-Proは、モデルの総合的な知識理解能力を測る中核的なベンチマークです。Gemini 3.1 Pro Preview はこのテストで 89.8 点を獲得し、Seed 2.0 Lite 260228 の 87.7 点を約2ポイントリードしました。両者の差はわずかで、同じレベルにあると言えます。
プログラミング能力の比較
プログラミング能力は、両モデルの差が最も顕著な分野です。
Gemini 3.1 Pro Preview は SWE-Bench Verified で 80.6%、LiveCodeBench Pro Elo スコアで 2887 を達成し、優れた性能を示しました。一方、Seed 2.0 Lite 260228 は SWE-Bench Verified で 73.5%、Codeforces スコアで 2233 でした。
実際のソフトウェアエンジニアリングタスク (SWE-Bench) において、Gemini 3.1 Pro は約7ポイントリードしており、コード集約型プロジェクトにとっては考慮すべき差です。
Seed 2.0 Lite 260228 対 Gemini 3.1 Pro Preview 完全ベンチマーク比較
| ベンチマークテスト | Seed 2.0 Lite 260228 | Gemini 3.1 Pro Preview | 優位性 |
|---|---|---|---|
| AIME 2025 | 93.0 | 91.2 | Seed Lite |
| MMLU-Pro | 87.7 | 89.8 | Gemini |
| SWE-Bench Verified | 73.5% | 80.6% | Gemini |
| Codeforces / LiveCodeBench | 2233 | 2887 Elo | Gemini |
| ARC-AGI-2 | – | 77.1% | Gemini |
| GPQA Diamond | – | 94.3% | Gemini |
総合的に見ると、Gemini 3.1 Pro Preview はプログラミングと推論において全体的に強く、特に ARC-AGI-2 と SWE-Bench の性能が際立っています。一方、Seed 2.0 Lite 260228 は数学的推論 (AIME) で逆転し、知識理解 (MMLU-Pro) の差もわずかです。
選択のアドバイス: もしあなたのコアニーズがコードエンジニアリングと複雑な推論であるなら、SWE-Bench で 80.6% の性能を示す Gemini 3.1 Pro の方が確実性が高いでしょう。予算が限られているが総合的な汎用能力が必要な場合、Seed 2.0 Lite は Gemini の約1/8の価格で、数学的推論能力の90%を提供します。APIYI apiyi.com プラットフォームを利用すれば、両モデルを同時に呼び出し、あなたの具体的なシナリオでの実際の性能を素早く比較できます。
Seed 2.0 Lite 260228 対 Gemini 3.1 Pro Preview 価格比較
価格はこの2つのモデル間で最も大きな違いです。以下が完全な費用比較です。
Seed 2.0 Lite 260228 対 Gemini 3.1 Pro Preview 段階的価格比較
| 価格設定の観点 | Seed 2.0 Lite 260228 | Gemini 3.1 Pro Preview |
|---|---|---|
| 入力 (標準範囲) | $0.25/M tokens (0-128K) | $2.00/M tokens (0-200K) |
| 入力 (長文範囲) | $0.50/M tokens (128K-256K) | $4.00/M tokens (200K-1M) |
| 出力 (標準範囲) | $2.00/M tokens (0-128K) | $12.00/M tokens (0-200K) |
| 出力 (長文範囲) | $4.00/M tokens (128K-256K) | $18.00/M tokens (200K-1M) |
| 課金方式 | 従量課金 Chat | 従量課金 |
| 無料枠 | BytePlus 新規ユーザーに付与 | Google AI Studio 無料枠 |
Seed 2.0 Lite 260228 対 Gemini 3.1 Pro Preview 実際のコストシミュレーション
以下は、異なる使用シナリオにおける月間コストの見積もりです。
| 使用シナリオ | 月間呼び出し量 | Seed 2.0 Lite 260228 コスト | Gemini 3.1 Pro Preview コスト | 節約率 |
|---|---|---|---|---|
| 軽度使用 (日常会話) | 10M in + 5M out | $12.50 | $80.00 | 84% |
| 中度使用 (文書処理) | 50M in + 20M out | $52.50 | $340.00 | 85% |
| 重度使用 (コード生成) | 200M in + 100M out | $250.00 | $1,600.00 | 84% |
全ての使用量レベルにおいて、Seed 2.0 Lite 260228 のコストは Gemini 3.1 Pro Preview より約 84-85% 低くなっています。月間API予算が $100 以内の個人開発者や小規模チームにとって、Seed 2.0 Lite のコスト優位性は非常に明らかです。
コスト最適化のアドバイス: 両モデルを組み合わせて使用することが最適な戦略です。日常会話や文書処理は Seed 2.0 Lite に任せ、複雑なコードエンジニアリングや深い推論は Gemini 3.1 Pro に任せましょう。APIYI apiyi.com プラットフォームは、両モデルを統一インターフェースで呼び出すことをサポートしており、model パラメータを変更するだけで切り替えが可能で、2つのSDKを維持する必要はありません。
Seed 2.0 Lite 260228 vs Gemini 3.1 Pro Preview クイックスタート
極簡サンプル — 統一インターフェースで2つのモデルを切り替え
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # APIYI統一インターフェース
)
# Seed 2.0 Lite 260228 を呼び出す (低コスト日常タスク)
response = client.chat.completions.create(
model="seed-2-0-lite-260228",
messages=[{"role": "user", "content": "このレポートの核心的な観点を要約してください"}]
)
print("Seed Lite:", response.choices[0].message.content)
# Gemini 3.1 Pro Preview を呼び出す (複雑な推論タスク)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "このコードのセキュリティ脆弱性を分析し、修正案を提示してください"}]
)
print("Gemini Pro:", response.choices[0].message.content)
完全な比較テストコードを表示 (所要時間とコスト計算を含む)
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
MODELS = {
"seed-2-0-lite-260228": {"input_price": 0.25, "output_price": 2.00},
"gemini-3.1-pro-preview": {"input_price": 2.00, "output_price": 12.00},
}
def compare_models(prompt: str, system_prompt: str = None):
"""2つのモデルの応答品質、速度、コストを比較"""
results = {}
for model_name, pricing in MODELS.items():
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=messages,
max_tokens=2000
)
elapsed = time.time() - start
usage = response.usage
cost = (usage.prompt_tokens * pricing["input_price"]
+ usage.completion_tokens * pricing["output_price"]) / 1_000_000
results[model_name] = {
"content": response.choices[0].message.content,
"time": f"{elapsed:.2f}s",
"tokens": f"{usage.prompt_tokens}+{usage.completion_tokens}",
"cost": f"${cost:.6f}"
}
for name, r in results.items():
print(f"\n{'='*50}")
print(f"Model: {name}")
print(f"Time: {r['time']} | Tokens: {r['tokens']} | Cost: {r['cost']}")
print(f"Response: {r['content'][:200]}...")
compare_models("クイックソートアルゴリズムの時間計算量分析を説明してください")
クイックスタート: APIYI apiyi.com プラットフォームでは、1つのAPIキーでSeed 2.0 LiteとGemini 3.1 Proを同時に呼び出せます。BytePlusとGoogle Cloudにそれぞれ登録する手間が省けます。プラットフォームは無料テスト枠を提供しており、5分で接続が完了します。
Seed 2.0 Lite 260228 と Gemini 3.1 Pro Preview のシーン別推奨
両モデルの能力と価格設定の違いに基づき、異なるシーンでの推奨は以下の通りです:
Seed 2.0 Lite 260228 を選ぶシーン:
- 日常会話とカスタマーサポートシステム: トークンあたり $0.25/M の低コストで、高頻度呼び出しシーンに適しています。
- ドキュメント要約と情報抽出: AIME 93.0 と MMLU-Pro 87.7 は、十分な知識理解能力を示しています。
- 予算に敏感なスタートアッププロジェクト: 月額コストは Gemini のわずか 15-16% です。
- マルチモーダルコンテンツ理解: テキスト、画像、動画入力に対応し、256K のコンテキストウィンドウでほとんどのニーズを満たします。
- バッチデータ処理: 低単価により、大規模なバッチ処理の総コストを抑えられます。
Gemini 3.1 Pro Preview を選ぶシーン:
- 複雑なコードエンジニアリング: SWE-Bench 80.6% は、実際の開発タスクにおいてより信頼性が高いことを示しています。
- 超長文ドキュメント分析: 100万トークンのコンテキストウィンドウで、書籍全体や大規模なコードベースを処理できます。
- 最先端の推論タスク: ARC-AGI-2 77.1% と GPQA Diamond 94.3% は、トップレベルの推論能力を表しています。
- 深い思考を必要とするタスク:
thinking_levelパラメータが low/medium/high/max の4段階調整をサポートします。 - コードセキュリティ監査: LiveCodeBench Pro 2887 Elo の競技レベルのプログラミング能力を備えています。
シーン別アドバイス: ベストプラクティスは、両モデルをハイブリッドでデプロイすることです。APIYI (apiyi.com) プラットフォームは統一インターフェースでの呼び出しをサポートしており、アプリケーション層でタスクの複雑度に基づいて自動的に異なるモデルにルーティングすることで、パフォーマンスとコストの最適なバランスを実現できます。
よくある質問
Q1: Seed 2.0 Lite 260228 は数学推論で Gemini 3.1 Pro を上回っていますが、なぜ Gemini を選ぶ必要があるのですか?
AIME 2025 は数学推論の一側面に過ぎません。Gemini 3.1 Pro は、ARC-AGI-2 (77.1%) で新しい論理パターンの推論能力を、GPQA Diamond (94.3%) で大学院レベルの科学的推論能力をテストされており、これらの側面では Gemini の優位性がより大きいです。さらに、SWE-Bench 80.6% という実際のコードエンジニアリング能力は、多くの開発者が最も重視する指標です。あなたのシーンが数学計算に重点を置くなら、Seed Lite の方が確実にお得です。複雑な推論やコードに重点を置くなら、Gemini の方が適しています。
Q2: 8倍の価格差は価値がありますか?どのような場合に高価な Gemini 3.1 Pro を選ぶべきですか?
以下の条件が満たされる場合、Gemini を選ぶ価値があります:(1) 単一タスクで 256K トークンを超える入力処理が必要な場合;(2) SWE-Bench 80%+ レベルのコードエンジニアリング信頼性が必要な場合;(3) タスクが推論の深さに極めて高い要求を課す場合 (thinking_level=max が必要)。ほとんどの日常的な API 呼び出しでは、Seed 2.0 Lite の性能で十分であり、8倍のコスト差は、同じ予算で8倍の呼び出し量が可能であることを意味します。APIYI (apiyi.com) を利用すれば柔軟に切り替えられるので、二者択一である必要はありません。
Q3: 自分のシーンでの両モデルのパフォーマンスを素早く比較するにはどうすればよいですか?
最速の方法:
- APIYI (apiyi.com) にアクセスしてアカウントを登録し、統一 API キーを取得します。
- 本記事で提供されている比較テストコードを使用し、実際の業務プロンプトを入力として与えます。
- 両モデルの応答品質、速度、コストを比較し、最適なものを選択します。
まとめ
Seed 2.0 Lite 260228 と Gemini 3.1 Pro Preview の核心的な結論:
- 価格差は8倍: Seed Lite 入力 $0.25/M 対 Gemini $2.00/M、出力 $2.00/M 対 $12.00/M。同等の予算で、Seed の呼び出し量は Gemini の 6-8 倍です。
- 数学的推論は Seed がやや優位: AIME 2025 で Seed Lite 93.0 が Gemini 91.2 を上回り、ミッドレンジ価格でフラグシップレベルの性能を実現しています。
- コードエンジニアリングは Gemini がリード: SWE-Bench 80.6% 対 73.5%、LiveCodeBench 2887 対 Codeforces 2233。Gemini は実際の開発タスクにおいてより信頼性が高いです。
- コンテキスト長は Gemini が圧倒的: 1M 対 256K。Gemini は超長文ドキュメントや大規模コードベースの分析に適しています。
- 最適な戦略は併用: 日常タスクは Seed Lite でコスト削減、複雑な推論は Gemini で品質を確保します。
APIYI (apiyi.com) を通じて両モデルに統一アクセスすることをお勧めします。プラットフォームは無料枠と OpenAI 互換インターフェースを提供しており、1つの APIキーで自由に切り替えることができます。
参考資料
-
ByteDance Seed 2.0 公式紹介: Seed 2.0 シリーズのモデル能力とベンチマークデータ
- リンク:
seed.bytedance.com/en/seed2 - 説明: Pro/Lite/Mini 全シリーズの技術仕様とテスト結果
- リンク:
-
Google Gemini 3.1 Pro 公式ブログ: Gemini 3.1 Pro のリリース情報と能力詳細
- リンク:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/ - 説明: ARC-AGI-2、SWE-Bench などの核心ベンチマーク結果と機能特性
- リンク:
-
Gemini 3.1 Pro Model Card: Google DeepMind 公式モデルカード
- リンク:
deepmind.google/models/model-cards/gemini-3-1-pro/ - 説明: 詳細な技術仕様、安全性評価、使用ガイド
- リンク:
-
BytePlus ModelArk 料金設定: Seed モデル公式 API 料金
- リンク:
docs.byteplus.com/en/docs/ModelArk/1544106 - 説明: 段階課金の詳細と各モデルの価格表
- リンク:
-
Artificial Analysis – モデル比較: 独立系サードパーティ評価プラットフォーム
- リンク:
artificialanalysis.ai/models/gemini-3-1-pro-preview - 説明: 性能、価格、レイテンシの総合分析データ
- リンク:
著者: APIYI 技術チーム
技術交流: コメント欄で Seed 2.0 Lite と Gemini 3.1 Pro の使用体験を共有してください。その他のモデル比較ガイドは APIYI ドキュメントセンター (docs.apiyi.com) をご覧ください。