最近、多くの開発者がGemini APIを呼び出す際に、次のようなエラーメッセージに遭遇しています。
{
"error": {
"code": 503,
"message": "This model is currently experiencing high demand. Spikes in demand are usually temporary. Please try again later.",
"status": "UNAVAILABLE"
}
}
簡単に言うと、このモデルは現在非常に人気があり、サーバーが処理しきれていないため、後でもう一度お試しください、ということです。
この問題は、Gemini 3.1 Pro Preview および Gemini 3.1 Flash Image Preview(Nano Banana 2)という2つの新しいモデルで特に顕著です。本記事では、このエラーの本質、他の一般的なエラーとの違い、そして実際に効果が確認された5つの解決策について徹底的に解説します。
主な価値: 本記事を読み終えることで、503 high demandエラーの根本原因を正確に理解し、すぐに実践できる5つの解決策を習得し、このエラーによって開発が滞ることはなくなるでしょう。
Gemini API 503 High Demand エラーとは一体何なのか
まず、身近な例えでこの問題を理解してみましょう。
GoogleのGeminiサーバーを、人気のレストランだと想像してみてください。 普段は繁盛していて、席も十分あります。ある日突然、SNSで話題になり(新モデル発表)、街中の人が押し寄せて行列ができました。レストランの収容人数には限りがあり、満席になったらそれ以上は入れません。この時、あなたが店の入口に着くと、店員がこう言います。「申し訳ございません、ただいま大変混雑しております。ピークタイムは一時的なものですので、しばらくしてからまたお越しください。」
これが This model is currently experiencing high demand の本質です。つまり、あなたのコードに問題があるわけでも、APIキーに問題があるわけでもなく、Google側のサーバーの計算能力が不足しているのです。
Gemini 503 エラーに関する3つの重要な事実
| 事実 | 説明 | 影響 |
|---|---|---|
| サーバー側の問題 | 503はGoogleサーバーの容量不足によるもので、あなたのコードや設定とは関係ありません | 有料プランにアップグレードしても解決しません |
| すべてのユーザーが影響を受ける | 無料ユーザー、有料ユーザー、法人顧客すべてが遭遇します | 「お金を払えば解決する」問題ではありません |
| 通常は一時的 | ピーク時には約70%の503エラーが60分以内に自己回復します | コードの修正ではなく、リトライメカニズムが必要です |
なぜGemini 3.1 ProとNano Banana 2は特に503エラーが発生しやすいのか
2026年2月の503エラー多発には明確なタイムラインがあります。
- 2月19日: GoogleがGemini 3.1 Pro Previewをリリースし、多数の開発者がテストに殺到
- 2月26日: Nano Banana 2(
gemini-3.1-flash-image-preview)がリリースされ、画像生成の需要が急増 - 2月17日~21日: StatusGatorがGeminiサービス低下の警告を1週間にわたり連続して記録
- ピーク時の失敗率約45%: コミュニティのデータによると、ピーク時のリクエスト失敗率がほぼ半分に
根本原因: 新しいモデルがリリースされたばかりで、Googleが割り当てた計算能力(GPUクラスター)がまだ需要に応じて拡張されていないためです。Preview 状態のモデルサーバーリソースは元々限られており、さらに世界中の開発者が同時にテストに殺到したことで、供給不足の状態が発生しています。

Gemini 503 High Demand と 429 Rate Limit の本質的な違い
多くの開発者が503と429を混同しがちですが、これら二つのエラーの原因は全く異なり、解決策も全く異なります。方向性を間違えると、無駄な労力を使うことになります。
| 比較項目 | 503 High Demand | 429 Rate Limit |
|---|---|---|
| エラーメッセージ | "This model is currently experiencing high demand" | "Resource has been exhausted" |
| 根本原因 | Googleサーバーの計算能力不足 | 個人のリクエスト頻度超過 |
| 影響範囲 | すべてのユーザーが影響を受ける | 自分のみが影響を受ける |
| アップグレードで解決可能か | ❌ 有料プランへのアップグレードでは解決不可 | ✅ Tier 1へのアップグレードで解決可能 |
| リトライは有効か | ✅ しばらく待つと通常回復する | ❌ 頻度を下げないとエラーが続く |
| ピーク時の特徴 | 北米の営業時間(9AM-5PM PT)に頻発 | 時間帯に関係なく、超過するとエラー |
| 根本的な解決策 | リトライ + 予備モデル + ピーク時を避ける | リクエスト頻度を下げる、またはプランをアップグレードする |
一言で判断する方法
- 503が表示された場合 → Google側の問題なので、しばらく待つか、別のモデルに切り替えてください
- 429が表示された場合 → ご自身のリクエストが速すぎるので、頻度を落とすか、プランをアップグレードしてください
🎯 技術的なヒント: プロダクション環境で503と429の両方のエラーを処理することは、API連携の基本です。APIYI (apiyi.com) プラットフォームを通じてGeminiシリーズのモデルを呼び出すと、プラットフォームに組み込まれたインテリジェントなリトライとロードバランシングメカニズムにより、エンドユーザーが体感する503エラーの頻度を大幅に低減できます。
解決策1:指数バックオフによるリトライ(最も基本的な方法)
503が「しばらくしてからもう一度」を意味する以上、最も直接的な対処法は自動リトライです。しかし、無計画なリトライは避けるべきです。サーバーへの負荷増大を避けるため、「指数バックオフ」戦略を使用し、リトライ間隔を毎回倍にする必要があります。
Gemini 503 指数バックオフによるリトライコード
import openai
import time
import random
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 統一インターフェース
)
def call_gemini_with_retry(messages, model="gemini-3.1-pro-preview", max_retries=5):
"""指数バックオフ付きのGemini API呼び出し"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model=model,
messages=messages
)
return response
except openai.APIStatusError as e:
if e.status_code == 503:
# 指数バックオフ: 2秒, 4秒, 8秒, 16秒, 32秒 + ランダムなジッター
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"⏳ 503 High Demand - {attempt+1}回目のリトライ、{wait_time:.1f}秒待機中...")
time.sleep(wait_time)
elif e.status_code == 429:
# 429 レート制限:より長く待機
wait_time = 60 + random.uniform(0, 10)
print(f"🚫 429 Rate Limit - {wait_time:.1f}秒待機中...")
time.sleep(wait_time)
else:
raise # その他のエラーは直接スロー
raise Exception(f"{max_retries}回のリトライ後も失敗しました")
# 使用例
response = call_gemini_with_retry(
messages=[{"role": "user", "content": "Hello, Gemini!"}]
)
print(response.choices[0].message.content)
指数バックオフによるリトライの主要パラメータ
| パラメータ | 推奨値 | 説明 |
|---|---|---|
| 最大リトライ回数 | 5 回 | 5回を超えると、一時的な問題ではない可能性が高い |
| 初期待機時間 | 2 秒 | 短すぎるとサーバー負荷が増大する |
| バックオフ倍率 | 2x | 毎回倍増: 2秒 → 4秒 → 8秒 → 16秒 → 32秒 |
| ランダムなジッター | 0-1 秒 | 多数のクライアントが同時にリトライするのを避ける |
| 最長待機時間 | 32 秒 | 32秒を超えた場合は、代替ソリューションに切り替えるべき |
💡 実用的なヒント: ランダムなジッター(jitter)は非常に重要です。もしすべてのクライアントが正確に2秒後にリトライした場合、「一斉リトライによる集中」が発生し、すべてのリクエストが同時にサーバーに殺到し、次もまた503エラーが発生する原因となるでしょう。ランダムなジッターを加えることで、リトライリクエストを分散させることができます。
解決策2:モデルのダウングレード/予備モデルへの自動切り替え
Gemini 3.1 Pro Preview が継続的に503エラーを返す場合、最も実用的な解決策はより安定した予備モデルに自動的に切り替えることです。
Gemini 503 モデルダウングレード戦略
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# モデルダウングレードチェーン: 最も強力なモデルを優先し、それが機能しない場合はダウングレードする
FALLBACK_MODELS = [
"gemini-3.1-pro-preview", # 優先: 最新かつ最強
"gemini-3.0-pro", # 予備1: 前世代のPro、より安定
"gemini-2.5-flash-image-preview", # 予備2: Flashバージョン、高速
"gemini-2.5-flash", # 最終手段: 最も安定したFlash
]
def call_with_fallback(messages):
"""モデルダウングレード付きのAPI呼び出し"""
for model in FALLBACK_MODELS:
try:
response = client.chat.completions.create(
model=model,
messages=messages
)
if model != FALLBACK_MODELS[0]:
print(f"⚠️ 予備モデルにダウングレードしました: {model}")
return response
except openai.APIStatusError as e:
if e.status_code in (503, 429):
print(f"❌ {model} が {e.status_code} を返しました。次のモデルを試します...")
continue
raise
raise Exception("すべてのモデルが利用できません")
response = call_with_fallback(
messages=[{"role": "user", "content": "このコードのパフォーマンスボトルネックを分析してください"}]
)
Gemini モデル安定性ランキング
| モデル | 安定性 | 503エラー頻度 | 推奨シナリオ |
|---|---|---|---|
gemini-2.5-flash |
⭐⭐⭐⭐⭐ | 極めて低い | 高可用性本番環境の最終手段 |
gemini-3.0-pro |
⭐⭐⭐⭐ | 低い | Proの能力が必要な安定したシナリオ |
gemini-2.5-flash-image-preview |
⭐⭐⭐ | 中程度 | 画像生成の予備 |
gemini-3.1-pro-preview |
⭐⭐ | やや高い | 最新の能力が必要だが、偶発的な失敗は許容できる場合 |
gemini-3.1-flash-image-preview |
⭐⭐ | やや高い | Nano Banana 2 画像生成 |
🚀 クイックスタート: APIYI (apiyi.com) プラットフォームを利用すれば、1つのAPIキーで上記のすべてのモデルを呼び出すことができます。モデルの切り替えは、
modelパラメータを変更するだけでよく、認証を再設定する必要はありません。コード内でモデルダウングレードチェーンを実装するのは非常に簡単です。
解決策3:オフピーク呼び出し(ゼロコストソリューション)
503エラーの需要集中には、明確な時間帯のパターンがあります。コミュニティのデータによると:
- ピーク時 (9AM-5PM PT): 失敗率 約45%
- オフピーク時 (2AM-7AM PT): 失敗率 5%未満
北京時間に換算すると:
| 時間帯(北京時間) | 対応する太平洋時間 | Gemini 503エラー頻度 | 推奨 |
|---|---|---|---|
| 午前1:00 – 午前10:00 | 9AM-6PM PT (前日) | 🔴 ピーク | 避けるか、予備モデルを使用 |
| 午前10:00 – 午後3:00 | 6PM-11PM PT (前日) | 🟡 中程度 | リトライメカニズム付きで呼び出し |
| 午後3:00 – 午後11:00 | 11PM-7AM PT | 🟢 オフピーク | 最適な呼び出し時間帯 |
| 午後11:00 – 午前1:00 | 7AM-9AM PT | 🟡 中程度 | 上昇開始 |
オフピーク呼び出しが適したシナリオ
- バッチデータ処理: リアルタイム応答が不要なタスクは、オフピーク時間帯に実行するようにスケジュールする
- 定期タスク: cronジョブをオフピーク時間帯に実行するよう設定する
- コンテンツ生成: 記事や画像など、事前に生成して公開を遅らせることができるシナリオ
ソリューション4:組み合わせ戦略(本番環境推奨)
実際の生産環境では、単一のソリューションだけでは不十分な場合が多いです。前の3つのソリューションを組み合わせて使用することをお勧めします。
プロダクションレベルのGemini API呼び出しソリューション
import openai
import time
import random
from datetime import datetime
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
FALLBACK_MODELS = [
"gemini-3.1-pro-preview",
"gemini-3.0-pro",
"gemini-2.5-flash",
]
def smart_gemini_call(messages, max_retries=3):
"""
プロダクションレベルのGemini API呼び出し
戦略: 指数バックオフによる再試行 + モデルのフォールバック + エラー分類
"""
for model in FALLBACK_MODELS:
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model=model,
messages=messages,
timeout=30
)
return response, model
except openai.APIStatusError as e:
if e.status_code == 503:
if attempt < max_retries - 1:
wait = (2 ** attempt) + random.uniform(0, 1)
print(f"⏳ {model} 503 - 再試行 {attempt+1}/{max_retries}、{wait:.1f}秒待機")
time.sleep(wait)
else:
print(f"⚠️ {model} 継続的な503エラー、次のモデルにフォールバックします")
break # 再試行を中断し、モデルを切り替える
elif e.status_code == 429:
wait = 60
print(f"🚫 {model} 429 レート制限 - {wait}秒待機")
time.sleep(wait)
else:
raise
except openai.APITimeoutError:
print(f"⏰ {model} リクエストタイムアウト、次のモデルを試行します")
break
raise Exception("すべてのモデルと再試行が失敗しました。ネットワークを確認するか、後でもう一度お試しください")
# 使用例
response, used_model = smart_gemini_call(
messages=[{"role": "user", "content": "こんにちは"}]
)
print(f"✅ 使用モデル: {used_model}")
print(response.choices[0].message.content)
完全なプロダクションレベルのラッパー(ログ、監視、キャッシュを含む)を見る
import openai
import time
import random
import hashlib
import json
import logging
from datetime import datetime
from functools import lru_cache
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("gemini_client")
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# シンプルなリクエストキャッシュ
_cache = {}
def get_cache_key(messages, model):
"""リクエストのキャッシュキーを生成"""
content = json.dumps(messages, sort_keys=True) + model
return hashlib.md5(content.encode()).hexdigest()
def gemini_call_production(
messages,
models=None,
max_retries=3,
cache_ttl=3600,
enable_cache=True
):
"""
プロダクションレベルのGemini API呼び出しラッパー
特徴:
- 指数バックオフによる再試行(503エラーの処理)
- モデルの自動フォールバック
- レスポンスキャッシュ(重複リクエストの削減)
- 構造化ログ
"""
if models is None:
models = ["gemini-3.1-pro-preview", "gemini-3.0-pro", "gemini-2.5-flash"]
# キャッシュの確認
if enable_cache:
cache_key = get_cache_key(messages, models[0])
if cache_key in _cache:
cached_time, cached_response = _cache[cache_key]
if time.time() - cached_time < cache_ttl:
logger.info("キャッシュヒット、API呼び出しをスキップ")
return cached_response, "cache"
errors = []
for model in models:
for attempt in range(max_retries):
try:
start_time = time.time()
response = client.chat.completions.create(
model=model,
messages=messages,
timeout=30
)
elapsed = time.time() - start_time
logger.info(f"成功 | model={model} | 処理時間={elapsed:.2f}s")
# キャッシュに書き込み
if enable_cache:
_cache[cache_key] = (time.time(), response)
return response, model
except openai.APIStatusError as e:
errors.append(f"{model}:{e.status_code}")
if e.status_code == 503:
if attempt < max_retries - 1:
wait = (2 ** attempt) + random.uniform(0, 1)
logger.warning(f"503 | model={model} | retry={attempt+1} | wait={wait:.1f}s")
time.sleep(wait)
else:
logger.warning(f"503 継続 | model={model} | 次のモデルにフォールバック")
break
elif e.status_code == 429:
logger.warning(f"429 レート制限 | model={model}")
time.sleep(60)
else:
raise
except Exception as e:
logger.error(f"異常 | model={model} | error={e}")
break
raise Exception(f"すべて失敗: {errors}")
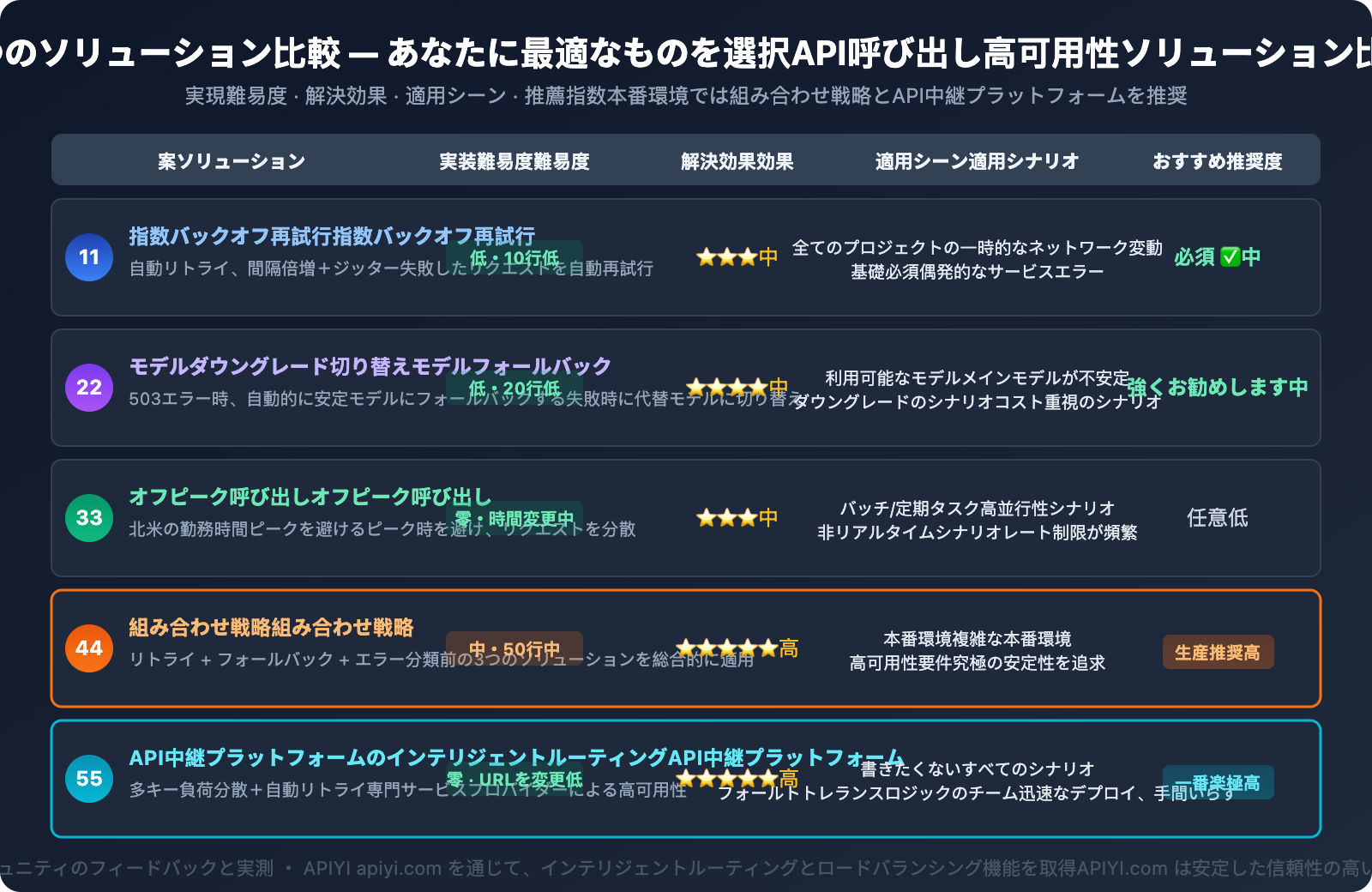
解決策5:API中継プラットフォームのスマートルーティングを利用する
上記のような複雑なリトライやフォールバックロジックを自分で実装したくない場合、もっと手軽な選択肢があります。それは、スマートルーティング機能を備えたAPI中継プラットフォームを利用することです。
API中継プラットフォームがGemini 503問題をどのように解決するか
プロフェッショナルなAPI中継プラットフォームは通常、以下の機能を備えています。
- 複数キーのローテーション: プラットフォームが複数のGoogle APIキーを保持し、単一のキーがレート制限された際に自動的に切り替えます。
- スマートリトライ: プラットフォームレベルで指数バックオフリトライが実装されており、開発者からは透過的です。
- ロードバランシング: リクエストを複数のGoogleアカウントとリージョンに分散します。
- 障害検知: 特定のモデルで503エラーの頻度が高まった場合、そのモデルへのリクエスト割り当て比率を自動的に下げます。
🎯 技術的アドバイス: APIYI (apiyi.com) プラットフォームは、Geminiシリーズモデルに対して上記のスマートルーティング機能を提供しています。OpenAI互換インターフェースを使用して呼び出すことで、プラットフォームがバックエンドで503エラーのリトライと複数キーのロードバランシングを自動的に処理するため、開発者は複雑な耐障害性ロジックを自分で実装する必要がありません。
API中継プラットフォームソリューションのコード例(最小限)
import openai
# APIYI API中継プラットフォームを使用。503エラーの処理はプラットフォームが担当します。
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# これだけで簡単、503エラーを自分で処理する必要はありません。
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "你好"}]
)
print(response.choices[0].message.content)
Gemini APIエラーの完全なトラブルシューティングプロセス
Gemini APIでエラーが発生した場合、以下の手順に従って迅速に問題を特定してください。
ステップ1:エラーコードを確認する
| エラーコード | エラーメッセージ | タイプ | 即座の対応 |
|---|---|---|---|
| 503 | "high demand" / "overloaded" | サーバーの処理能力不足 | リトライを待つか、モデルを切り替える |
| 429 | "resource exhausted" | 個人のレート制限 | リクエスト頻度を下げるか、プランをアップグレードする |
| 400 | "invalid request" | リクエストパラメータエラー | リクエストの形式とパラメータを確認する |
| 401 | "unauthorized" | 認証失敗 | APIキーを確認する |
| 500 | "internal error" | サーバー内部エラー | リトライを待つ |
ステップ2:503エラーか429エラーかを区別する
- 複数のAPIキーでエラーが発生する場合 → 503、Googleサーバー側の問題です。
- あなたのキーのみでエラーが発生する場合 → 429、あなた個人の制限の問題です。
ステップ3:対応する解決策を選択する
- 503: 指数バックオフリトライ → モデルのダウングレード → オフピーク時の呼び出し
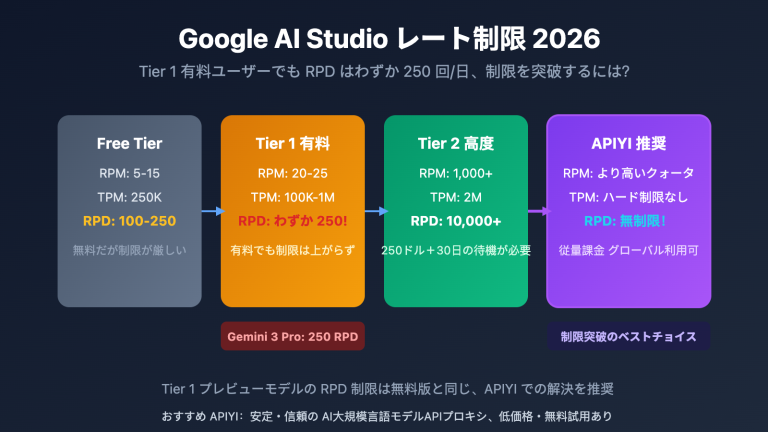
- 429: リクエスト頻度を下げる → 課金を有効にしてTier 1にアップグレードする(無料ティアは5-15 RPM、Tier 1は150-300 RPM)
よくある質問
Q1: 料金を支払ったのに、なぜ503 High Demandに遭遇するのですか?
503エラーは、お客様が料金を支払っているかどうかとは全く関係ありません。503はGoogleサーバーの計算能力不足が原因であり、無料ユーザーであろうと企業顧客であろうと発生します。これは429のスロットリングとは異なります。429はプランをアップグレードすることで解決できますが、503は解決できません。503に遭遇した場合は、指数バックオフによるリトライを使用するか、より安定したモデルバージョンに切り替えることをお勧めします。APIYI apiyi.com プラットフォームを介したモデル呼び出しでは、複数のAPIキーによる負荷分散を利用して、503の発生頻度を低減できます。
Q2: Gemini 3.1 Pro Previewの503エラーはいつ改善されますか?
過去の経験から、新しいモデルがリリースされた後の503エラーのピークは通常1〜3週間続き、Googleが段階的に容量を増やすにつれて大幅に改善されます。Gemini 3.0 Proもリリース当初に同様の503エラーの波を経験しましたが、現在は非常に安定しています。待機期間中は、モデルのダウングレード戦略を実装し、503エラー発生時に自動的にgemini-3.0-proまたはgemini-2.5-flashにフォールバックすることをお勧めします。
Q3: “high demand”と”model is overloaded”は同じエラーですか?
本質的には同じ問題の異なる表現です。"This model is currently experiencing high demand"と"The model is overloaded"はどちらも503ステータスコードであり、Googleサーバーの計算能力不足を示しています。前者は比較的新しいAPIバージョンでよく見られ、後者は初期バージョンでより多く出現しました。処理方法は全く同じです。
Q4: Gemini APIが503エラーになるかどうかを事前に知る方法はありますか?
公式の事前警告はありません。しかし、いくつかの兆候に注目することができます。(1) Googleが新しいモデルをリリースした後の1〜2週間は高リスク期間です。(2) 北米の勤務時間(北京時間の深夜から午前中)は503エラーの頻度が高くなります。(3) コミュニティフォーラム discuss.ai.google.dev では通常、リアルタイムのフィードバックがあります。問題が発生してから一時的に追加するのではなく、コードには常にリトライとダウングレードのロジックを保持しておくことをお勧めします。APIYI apiyi.com プラットフォームはモデルの可用性ステータス監視を提供しており、事前に感知するのに役立ちます。
Q5: コード内で503と429の両方を同時に処理すべきですか?
はい、必須です。本番環境では503と429の両方に遭遇する可能性があり、処理戦略は異なりますが、どちらも同様に重要です。503には指数バックオフによるリトライとモデルのダウングレードを、429にはリクエスト頻度の低減とスロットリングキューイングを使用します。本記事の「解決策4:組み合わせ戦略」のコードは、これら2種類のエラーを同時に処理しており、本番環境で直接利用できます。
まとめ
This model is currently experiencing high demandという503エラーの本質は非常にシンプルです。それはGoogleのサーバーの計算能力が一時的に不足しているということです。特にGemini 3.1 Pro Preview、Nano Banana 2のような新しいモデルは、リリース直後の段階でほぼ確実に遭遇します。
推奨優先順位に基づく5つの解決策:
- 指数バックオフによるリトライ — 最も基本的で、すべてのプロジェクトに実装すべきです
- モデルのダウングレードチェーン — 503エラー時に自動的に安定したモデルに切り替えます
- ピークオフ時の呼び出し — リアルタイムではないタスクをオフピーク時に実行します
- 組み合わせ戦略 — 本番環境で推奨される、リトライ + ダウングレード + エラー分類
- API中継サービスのスマートルーティング — 最も手間がかからず、プラットフォームがフォールトトレランスロジックを処理します
どの解決策を選択するにしても、核となる原則は次のとおりです。503エラーはあなたのせいではありませんが、それを適切に処理する必要があります。APIYI apiyi.com を通じてGeminiシリーズモデルを迅速に統合し、組み込みのスマートルーティングとリトライ機能を活用することをお勧めします。
参考資料
-
Google AI Developers Forum – 503 エラーに関する議論
- リンク:
discuss.ai.google.dev - 説明: Gemini API 503 エラーに関するコミュニティでの議論と公式回答
- リンク:
-
Google Gemini API – レート制限に関するドキュメント
- リンク:
ai.google.dev/gemini-api/docs/rate-limits - 説明: 公式のレート制限ルールと各ティアの割り当てに関する説明
- リンク:
-
Google Gemini API – トラブルシューティングガイド
- リンク:
ai.google.dev/gemini-api/docs/troubleshooting - 説明: 公式のエラー解決ガイド
- リンク:
📝 著者: APIYI Team | 技術交流やAPI連携については apiyi.com をご覧ください