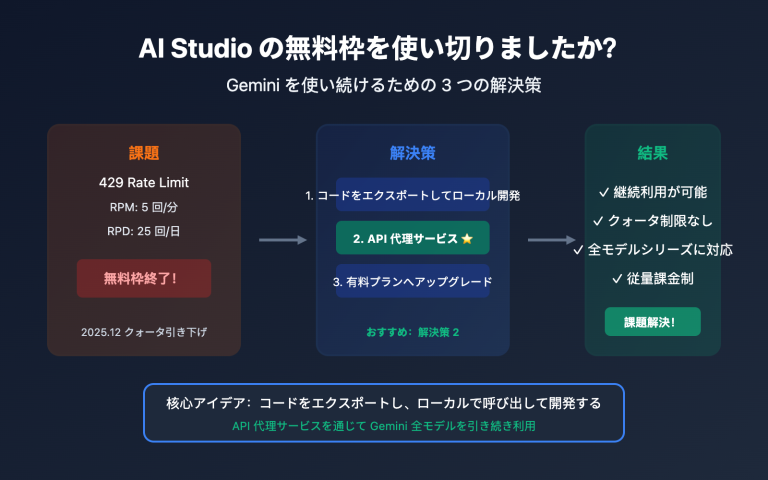
Google AI Studio を使用してプロジェクトを開発している最中、突然 429 RESOURCE_EXHAUSTED エラーが発生しましたか?あなただけではありません。2025年12月に Google が無料枠の割り当てを大幅に削減して以来、世界中の何万人もの開発者のプロジェクトが一夜にして停滞しています。
この記事では、Google AI Studio の制限メカニズムを詳しく解説し、開発を迅速に再開するための5つの実証済みの解決策を紹介します。
Google AI Studio 制限メカニズムの詳細解説
Google AI Studio の制限とは
Google AI Studio は、Gemini API の呼び出しに対して多角的な制限を課しています。主な項目は以下の通りです。
| 制限項目 | 意味 | リセットタイミング |
|---|---|---|
| RPM (Requests Per Minute) | 1分あたりのリクエスト数 | 1分ごとのローリングリセット |
| RPD (Requests Per Day) | 1日あたりのリクエスト数 | 太平洋標準時の深夜にリセット |
| TPM (Tokens Per Minute) | 1分あたりの処理トークン数 | 1分ごとのローリングリセット |
| IPM (Images Per Minute) | 1分あたりの画像処理数 | 1分ごとのローリングリセット |
🔑 重要ポイント: 制限はプロジェクト(Project)単位で計算され、APIキー単位ではありません。複数のAPIキーを作成しても割り当ては増えません。
2026年最新 Google AI Studio 無料枠の制限
2025年12月7日、Google は Gemini API の無料枠の割り当てを大幅に(50%〜92%)削減しました。現在の各モデルの制限は以下の通りです。
| モデル | RPM 制限 | RPD 制限 | TPM 制限 |
|---|---|---|---|
| Gemini 2.5 Pro | 5 | 100 | 250,000 |
| Gemini 2.5 Flash | 10 | 250 | 250,000 |
| Gemini 2.5 Flash-Lite | 15 | 1,000 | 250,000 |
| Gemini 3 Pro Preview | 10-50* | 100+* | 250,000 |
*Gemini 3 Pro Preview の制限は、アカウントの作成時期や地域によって動的に調整されます。

なぜ Google AI Studio 429 エラーが発生するのか
429 エラーは、いずれかの制限項目が上限に達したときに発生します。主なシナリオは以下の通りです。
- RPM 制限超過: 短時間に大量のリクエストを送信した場合。
- RPD 枯渇: 1日のリクエスト総数が上限に到達した場合。
- TPM 制限超過: 1回のリクエストのトークン数が長すぎる、または同時実行リクエストが多すぎる場合。
- アカウント状態の異常: Tier 1 にアップグレードしても、一部のユーザーで無料枠の制限が適用される事象が報告されています。
# 典型的な 429 エラーレスポンス
{
"error": {
"code": 429,
"message": "You exceeded your current quota, please check your plan and billing details.",
"status": "RESOURCE_EXHAUSTED"
}
}
Google AI Studio の制限(クォータ)を解決する 5 つの方法
方法 1:クォータのリセットを待つ(無料だが時間がかかる)
適用シーン: 軽度のテスト、非緊急のプロジェクト
Google AI Studio のクォータリセットルールは以下の通りです:
- RPM/TPM: 60 秒のローリングウィンドウで自動的にリセットされます。
- RPD: 太平洋標準時の午前 0 時(日本時間 午後 5 時)にリセットされます。
指数バックオフによる再試行の実装:
import time
import random
def call_with_retry(func, max_retries=5):
"""指数バックオフを用いた再試行メカニズム"""
for attempt in range(max_retries):
try:
return func()
except Exception as e:
if "429" in str(e):
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"クォータ超過。{wait_time:.1f} 秒後に再試行します...")
time.sleep(wait_time)
else:
raise
raise Exception("再試行回数の上限に達しました")
| メリット | デメリット |
|---|---|
| ✅ 完全に無料 | ❌ 数時間待つ必要がある |
| ✅ 設定不要 | ❌ クォータ自体は依然として少ない |
| ✅ 学習やテストに最適 | ❌ 本格的な開発には不向き |
方法 2:Tier 1 有料プランへのアップグレード
適用シーン: 国際クレジットカードを所有している開発者
Tier 1 にアップグレードした後のクォータ向上:
| 指標 | 無料プラン | Tier 1 |
|---|---|---|
| RPM | 5-15 | 150-300 |
| RPD | 100-1000 | 基本的に無制限 |
| 反映時間 | – | 即時 |
アップグレードの手順:
- Google AI Studio コンソールにアクセスします。
- 「API Keys」ページに移動します。
- 「Set up Billing」ボタンをクリックします。
- Google Cloud 請求先アカウントを紐付けます。
- Tier 1 プランを選択します。
Tier 1 の料金参考:
- Gemini 2.5 Flash: $0.075 / 100万入力トークン
- Gemini 2.5 Pro: $1.25 / 100万入力トークン
- 4K 画像生成: $0.24 / 枚
| メリット | デメリット |
|---|---|
| ✅ RPM が 150-300 に向上 | ❌ 国際クレジットカードが必要 |
| ✅ RPD 制限がほぼ解除される | ❌ 一部のモデルには依然として制限がある |
| ✅ 即時反映 | ❌ 地域によってはカード登録が困難な場合がある |
方法 3:APIYI 中継サービスの利用(推奨)
適用シーン: すべての開発者、特に支払いやアクセス制限を回避したいユーザー
🎯 推奨プラン: APIYI (apiyi.com) プラットフォームを通じて Gemini API を呼び出すことで、クォータ制限を気にすることなく利用できます。Alipay や WeChat Pay での決済にも対応しています。
APIYI の優位性比較:
| 比較項目 | Google 公式 | APIYI |
|---|---|---|
| RPM 制限 | 5-300 | 無制限 |
| RPD 制限 | 100-無限 | 無制限 |
| 4K 画像価格 | $0.24/枚 | $0.05/枚 |
| 支払い方法 | 国際クレジットカード | Alipay/WeChat Pay |
| アクセス性 | プロキシが必要な場合あり | 直接アクセス可能 |
| サポート | 英語 | 中国語/日本語対応 |

クイック導入コード:
import openai
# APIYI 接続設定
client = openai.OpenAI(
api_key="your-apiyi-key", # api.apiyi.com で取得
base_url="https://api.apiyi.com/v1"
)
# Gemini モデルの呼び出し
response = client.chat.completions.create(
model="gemini-2.5-pro",
messages=[
{"role": "user", "content": "こんにちは、自己紹介をしてください"}
]
)
print(response.choices[0].message.content)
💡 アドバイス: 開発やテストには APIYI (apiyi.com) プラットフォームの利用をお勧めします。このプラットフォームは 200 以上の主要な AI モデルの統合インターフェースをサポートしており、価格は公式の約 20% 程度に抑えられています。
方法 4:複数の Google Cloud プロジェクトを作成する
適用シーン: 技術力の高い開発者
クォータはプロジェクトごとに計算されるため、理論上は複数のプロジェクトを作成することで総クォータを増やすことができます。
import random
class MultiProjectClient:
"""複数プロジェクトのラウンドロビンクライアント"""
def __init__(self, api_keys: list):
self.api_keys = api_keys
self.current_index = 0
def get_next_key(self):
"""ラウンドロビンで次の API Key を取得"""
key = self.api_keys[self.current_index]
self.current_index = (self.current_index + 1) % len(self.api_keys)
return key
def call_api(self, prompt):
"""取得した Key を使用して API を呼び出す"""
api_key = self.get_next_key()
# この key を使用して Gemini API を呼び出す処理
pass
# 使用例
client = MultiProjectClient([
"key_from_project_1",
"key_from_project_2",
"key_from_project_3"
])
| メリット | デメリット |
|---|---|
| ✅ 無料でクォータを増やせる | ❌ 管理が複雑 |
| ✅ 支払いが不要 | ❌ 利用規約(ToS)違反のリスク |
| – | ❌ Google に検知されアカウント停止される可能性がある |
⚠️ リスク提示: この方法は Google のサービス利用規約に抵触するリスクがあるため、本番環境での利用は推奨されません。
方法 5:リクエスト戦略の最適化
適用シーン: すべての開発者
限られたクォータであっても、戦略を最適化することで最大限に活用できます。
1. リクエストキューの実装:
import asyncio
from collections import deque
class RateLimitedQueue:
"""レート制限付きリクエストキュー"""
def __init__(self, rpm_limit=5):
self.rpm_limit = rpm_limit
self.queue = deque()
self.request_times = deque()
async def add_request(self, request_func):
"""リクエストをキューに追加"""
self.queue.append(request_func)
await self._process_queue()
async def _process_queue(self):
"""キュー内のリクエストを処理"""
now = asyncio.get_event_loop().time()
# 60秒以上経過した記録を削除
while self.request_times and now - self.request_times[0] > 60:
self.request_times.popleft()
# リクエスト送信可能かチェック
if len(self.request_times) < self.rpm_limit and self.queue:
request_func = self.queue.popleft()
self.request_times.append(now)
await request_func()
2. リクエストのバッチ処理:
def batch_prompts(prompts: list, batch_size: int = 5):
"""複数のプロンプトを 1 つのバッチリクエストに統合"""
combined_prompt = "\n\n---\n\n".join([
f"質問 {i+1}: {p}" for i, p in enumerate(prompts)
])
return combined_prompt
# 5つの独立したリクエストを1つに統合
prompts = ["質問1", "質問2", "質問3", "質問4", "質問5"]
batch_prompt = batch_prompts(prompts)
# これにより RPM クォータの消費を 1 回に抑える
3. 重複リクエストのキャッシュ:
import hashlib
import json
class ResponseCache:
"""レスポンスキャッシュ"""
def __init__(self):
self.cache = {}
def get_cache_key(self, prompt, model):
"""キャッシュキーの生成"""
content = f"{model}:{prompt}"
return hashlib.md5(content.encode()).hexdigest()
def get(self, prompt, model):
"""キャッシュの取得"""
key = self.get_cache_key(prompt, model)
return self.cache.get(key)
def set(self, prompt, model, response):
"""キャッシュの設定"""
key = self.get_cache_key(prompt, model)
self.cache[key] = response
Google AI Studio 制限プランの比較
以上の5つのプランをまとめると、詳細な比較は以下の通りです。
| プラン | コスト | クォータの増加 | 導入難易度 | 推奨度 |
|---|---|---|---|---|
| リセットを待つ | 無料 | なし | ⭐ | ⭐⭐ |
| Tier 1へアップグレード | 従量課金 | 10〜60倍 | ⭐⭐ | ⭐⭐⭐ |
| APIYI転送 | 公式の20%価格 | 無制限 | ⭐ | ⭐⭐⭐⭐⭐ |
| 複数プロジェクトのローテーション | 無料 | プロジェクト数に比例 | ⭐⭐⭐⭐ | ⭐⭐ |
| 最適化戦略 | 無料 | 間接的な向上 | ⭐⭐⭐ | ⭐⭐⭐ |
🎯 選択のアドバイス: ほとんどの開発者にとって、主要な解決策として APIYI (apiyi.com) の使用をお勧めします。このプラットフォームはクォータ制限の問題を解決するだけでなく、公式サイトの約20%という低価格と、充実したテクニカルサポートを提供しています。
よくある質問 (FAQ)
Q1: Tier 1にアップグレードしたのに、なぜまだ429エラーが出るのですか?
これは Google AI Studio の既知の問題です。一部のユーザーから、有料アカウントを紐付けた後でも、システムが依然として無料枠の制限を適用しているという報告があります。
解決方法:
- AI Studio に入り、すべてのプロジェクトがアップグレードされているか確認する
- APIキーを再生成する
- システムの同期が完了するまで最大24時間待つ
問題が解決しない場合は、クォータの心配がない APIYI (apiyi.com) などのサードパーティプラットフォームへの切り替えを検討してください。
Q2: RPD クォータはいつリセットされますか?
Google AI Studio の RPD(1日あたりのリクエスト数)は、太平洋標準時(PST)の午前0時にリセットされます。これは日本時間の 午後5時(夏時間の場合は午後4時) に相当します。
Q3: Gemini 3 Pro Preview の制限が一定ではないのはなぜですか?
プレビュー版モデルであるため、Gemini 3 Pro Preview の制限は以下の要因に基づいて動的に調整されます:
- アカウントの作成時期
- 利用地域
- 過去の利用実績
- Google サーバーの負荷状況
Q4: 現在のクォータ使用状況を確認するにはどうすればよいですか?
- Google AI Studio にログインします。
- 「API Keys」ページに移動します。
- 「Quota」セクションで使用量の統計を確認できます。
Q5: APIYI はどの Gemini モデルをサポートしていますか?
APIYI は、Google がリリースしている主要な Gemini モデルをすべてサポートしています:
- Gemini 2.5 Pro / Flash / Flash-Lite
- Gemini 3 Pro Preview
- その他 200 以上の AI モデル(Claude、GPT、Llama など)
最新のモデルリストとリアルタイム価格については、apiyi.com をご確認ください。
Q6: 複数プロジェクトのローテーションは Google に BAN されますか?
リスクは存在します。Google の利用規約では、制限を回避するために複数のアカウントを作成することを禁止しています。現時点で大規模な BAN の報告はありませんが、本番環境での利用は推奨されません。
まとめ
Google AI Studio が 2025 年末に無料枠を大幅に削減したことで、開発者はより厳しい RPM/RPD 制限に直面しています。本記事で紹介した 5 つの解決策には、それぞれメリットとデメリットがあります。
- クォータのリセットを待つ: 学習やテストには適していますが、効率が非常に低いです。
- Tier 1 へアップグレード: クォータは大幅に増加しますが、海外で利用可能なクレジットカードが必要です。
- APIYI プロキシ: クォータ制限がなく、価格も安価です。Alipay や WeChat Pay にも対応しており、最も推奨される方法です。
- 複数プロジェクトのローテーション: アカウント停止のリスクがあるため、推奨されません。
- リクエスト戦略の最適化: 習得する価値があり、他の方法と組み合わせて使用できます。
中国の開発者の皆様には、APIYI(apiyi.com)プラットフォームの直接利用をお勧めします。クォータ制限、決済の難しさ、ネットワークアクセスの 3 つの課題をワンストップで解決できます。
📝 著者: APIYI Team
🔗 APIYI 公式サイト: apiyi.com – 安定性と信頼性の高い AI 大規模言語モデル API プロキシプラットフォーム。200 以上のモデルに対応し、価格は公式サイトの最大 80% オフ。