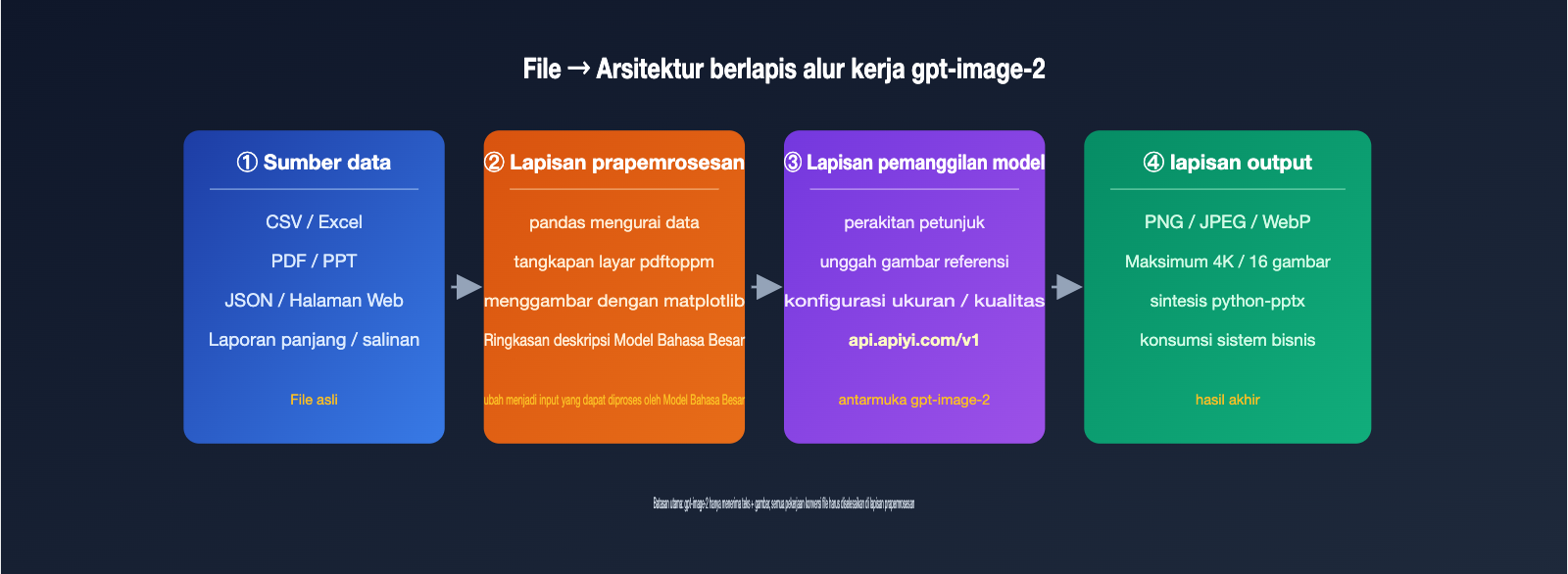
Seorang rekan pengembang baru-baru ini bertanya di grup: "Bisakah gpt-image-2 membuat gambar berdasarkan file CSV atau Excel? Saya melihat di TikTok ada orang yang menggunakan model image untuk membuat PPT, jadi saya ingin mencoba apakah model ini bisa membaca informasi file." Jawabannya singkat: Tidak bisa. gpt-image-2 yang dirilis OpenAI pada April 2026 hanya menerima petunjuk teks dan gambar sebagai input; ia tidak membaca file CSV/Excel, juga tidak menghasilkan file PPTX/PDF.
Namun, bukan berarti jalan ini buntu. Mengekstrak konten file menjadi teks, mengambil tangkapan layar (screenshot) halaman file, lalu memberikannya kepada gpt-image-2 untuk pembuatan gambar adalah alur kerja utama yang lazim digunakan saat ini. Artikel ini akan menjelaskan batasan kemampuan unggah file gpt-image-2 dan 5 solusi alternatif agar Anda dapat mewujudkan kebutuhan klien yang sebelumnya dianggap mustahil.

Status Dukungan Unggah File gpt-image-2: Input Hanya Menerima Teks dan Gambar
Mari kita perjelas batasan resminya terlebih dahulu, karena semua solusi di bawah ini dibangun di atas batasan tersebut. Menurut dokumentasi pengembang OpenAI, gpt-image-2 (snapshot gpt-image-2-2026-04-21) adalah model pembuatan gambar multimodal asli. Tabel dukungan modalitas berikut dengan jelas mencantumkan cakupan input dan outputnya.
| Tipe Modalitas | Mendukung Input | Mendukung Output | Keterangan |
|---|---|---|---|
| Teks | ✅ Ya | ❌ Tidak | Digunakan sebagai petunjuk, mendukung multibahasa |
| Gambar | ✅ Ya | ✅ Ya | Input untuk pengeditan/referensi, output PNG/JPEG/WebP |
| Audio | ❌ Tidak | ❌ Tidak | Tidak relevan dengan pembuatan gambar |
| Video | ❌ Tidak | ❌ Tidak | Tidak relevan dengan pembuatan gambar |
| Dokumen (CSV/Excel/PDF/Word/PPT) | ❌ Tidak | ❌ Tidak | Tidak dapat diunggah langsung atau diekspor |
Singkatnya, gpt-image-2 bukanlah "otak universal" seperti GPT-4; ia dikhususkan untuk pembuatan dan pengeditan gambar, sehingga OpenAI tidak menyediakan jalur parsing untuk CSV/Excel/PDF. Jika Anda mengirimkan biner Excel, API akan langsung mengembalikan error 400. Jika proyek Anda memerlukan jalur pemanggilan gpt-image-2 yang stabil dan memiliki RPM tinggi, kami menyarankan untuk mengaksesnya melalui platform proksi API seperti APIYI (apiyi.com). Platform ini telah mendokumentasikan validasi input dan batasan parameter model, sehingga pemula tidak akan mudah terjebak.
🎯 Pemahaman Inti: Batasan kemampuan gpt-image-2 adalah "Teks + Gambar → Gambar", jangan menganggapnya sebagai Agen serba bisa. Kebutuhan terkait file harus dilengkapi dengan alat lain di lapisan luar, lapisan proksi (seperti APIYI) bertanggung jawab untuk menjamin stabilitas pemanggilan, dan lapisan bisnis bertanggung jawab untuk pra-pemrosesan data.
Mengapa "Pembuatan PPT" dan "Pembuatan Gambar dari File" yang Ditanyakan Klien Adalah Dua Hal Berbeda
Banyak klien mencampuradukkan "AI sekali klik buat PPT" dengan "Model membaca file untuk buat gambar", padahal keduanya adalah alur kerja yang sangat berbeda. Kasus otomatisasi PPT yang terlihat di TikTok atau media sosial hampir semuanya adalah alur kerja multi-langkah: pertama, gunakan Model Bahasa Besar untuk menyaring data menjadi naskah, lalu gunakan model gambar untuk membuat ilustrasi setiap halaman, dan terakhir gunakan program untuk menyusunnya menjadi PPTX.
Bagian yang bertanggung jawab untuk membuat gambar biasanya adalah model seperti gpt-image-2. Model ini hanya melihat petunjuk teks dan gambar referensi yang diterimanya, dan sama sekali tidak tahu apakah sumbernya berasal dari Excel atau Notion. Setelah poin ini dipahami, 5 solusi berikutnya akan terasa masuk akal.
Apa Saja Peningkatan Dibandingkan Generasi Sebelumnya (gpt-image-1)
Banyak pengguna lama bertanya: jika tidak bisa mengunggah file, apa kelebihan gpt-image-2 dibandingkan gpt-image-1? Perbedaannya sebenarnya sangat krusial dan secara langsung menentukan apakah metode "input tangkapan layar untuk membuat gambar" bisa berjalan. Versi baru ini memiliki peningkatan besar dalam rendering teks, jumlah gambar referensi, dan kemampuan penalaran.
| Dimensi Kemampuan | gpt-image-1 | gpt-image-2 |
|---|---|---|
| Jumlah Maksimum Gambar Referensi | 4 gambar | 16 gambar (disarankan ≤4 untuk hasil terbaik) |
| Rendering Teks | Bahasa Inggris baik, bahasa Asia sering error | Akurasi multibahasa (Tionghoa, Jepang, Korea, dll.) meningkat drastis |
| Kemampuan Penalaran | Tidak ada | Mode thinking bawaan, mampu menangani tata letak kompleks |
| Batas Pengetahuan | Awal 2024 | Desember 2025 |
| Resolusi Output | Maksimum 1024×1024 | Maksimum 3840×2160 (4K) |
Artinya, jika sebelumnya Anda menggunakan gpt-image-1 untuk memproses "tangkapan layar untuk mengubah gaya" dan hasilnya kurang memuaskan, menjalankan ulang dengan gpt-image-2 sangat layak dilakukan, terutama untuk skenario seperti poster bahasa Mandarin atau halaman dalam PPT yang memerlukan rendering teks presisi.
5 Skema Alur Kerja untuk Menghasilkan Gambar dari Konten File dengan gpt-image-2
Kelima skema di bawah ini disesuaikan dengan berbagai sumber data dan skenario implementasi. Pilihan Anda bergantung pada jenis file, format output, dan tingkat otomatisasi yang diinginkan. Kami mengurutkannya dari yang paling ringan hingga yang paling kompleks.
Skema 1: Konversi File ke Petunjuk Teks, Langsung ke gpt-image-2
Cocok untuk data terstruktur seperti CSV, Excel, JSON, dan teks biasa. Alurnya adalah menggunakan skrip (pandas, openpyxl) untuk membaca file, menyusun header, baris kunci, dan indikator statistik menjadi deskripsi bahasa alami, lalu memanggil /v1/images/generations sebagai prompt. Contohnya, merangkum data penjualan menjadi "Grafik batang penjualan Q1 2026 di tiga wilayah utama, Tiongkok Timur 12 juta, Tiongkok Utara 9,8 juta, Tiongkok Selatan 7,6 juta, gaya bisnis gelap."
Kelebihan metode ini adalah sederhana dan langsung, tanpa memerlukan input gambar. Kekurangannya adalah informasi yang bisa dimasukkan ke dalam prompt terbatas. gpt-image-2 bekerja dengan baik dalam akurasi angka, namun tidak sempurna; Anda harus menuliskan nilai setiap batang secara eksplisit di dalam petunjuk, jika tidak, model akan mendistribusikan ulang tinggi batang berdasarkan estetika visual.
Skema 2: Tangkapan Layar Halaman File sebagai Input Gambar Referensi
Cocok untuk PDF, PPT dengan tata letak yang sudah ada, laporan web, dan konten yang "sudah berbentuk gambar". Ubah halaman target menjadi PNG (bisa menggunakan pratinjau macOS, pdftoppm, Puppeteer, dll.), lalu unggah melalui endpoint /v1/images/edits sebagai parameter image, dipadukan dengan prompt yang menjelaskan perubahan yang diinginkan, misalnya "Pertahankan tata letak, ubah judul bahasa Inggris menjadi bahasa Mandarin, ubah grafik batang menjadi gaya Apple."
Dalam versi 2026, gpt-image-2 dapat menerima hingga 16 gambar referensi, namun pengujian resmi dan komunitas menyarankan penggunaan 1 gambar referensi utama + 1–2 gambar referensi gaya. Menambahkan terlalu banyak gambar akan mengencerkan fokus model. Disarankan untuk menjaga ukuran setiap gambar di bawah 1,5 MB agar konsumsi token input tidak melonjak drastis.
Skema 3: Visualisasi Data Terlebih Dahulu, Baru Dipercantik oleh gpt-image-2
Cocok untuk skenario visualisasi data yang mengejar "akurasi sekaligus estetika". Gunakan matplotlib, ECharts, atau grafik bawaan Excel untuk menggambar versi dasar data dan ekspor sebagai PNG; kemudian, jadikan gambar dasar ini sebagai input untuk gpt-image-2 dengan prompt "Pertahankan posisi titik data dan nilai, ubah gaya grafik menjadi gaya gelap, neon highlight, dan infografis."
Ini adalah cara paling stabil untuk menggabungkan grafik data + estetika AI saat ini. Nilai asli dijamin oleh pustaka grafik yang deterministik, sementara gaya visual dibentuk ulang oleh gpt-image-2; keduanya melakukan apa yang mereka kuasai. Jika Anda ingin menjalankan alur ini secara massal, disarankan untuk memanggil gpt-image-2 melalui APIYI apiyi.com, yang memiliki penjadwalan kumpulan akun hulu untuk skenario konkurensi tinggi 5000 RPM, cocok untuk tugas ribuan gambar per hari.
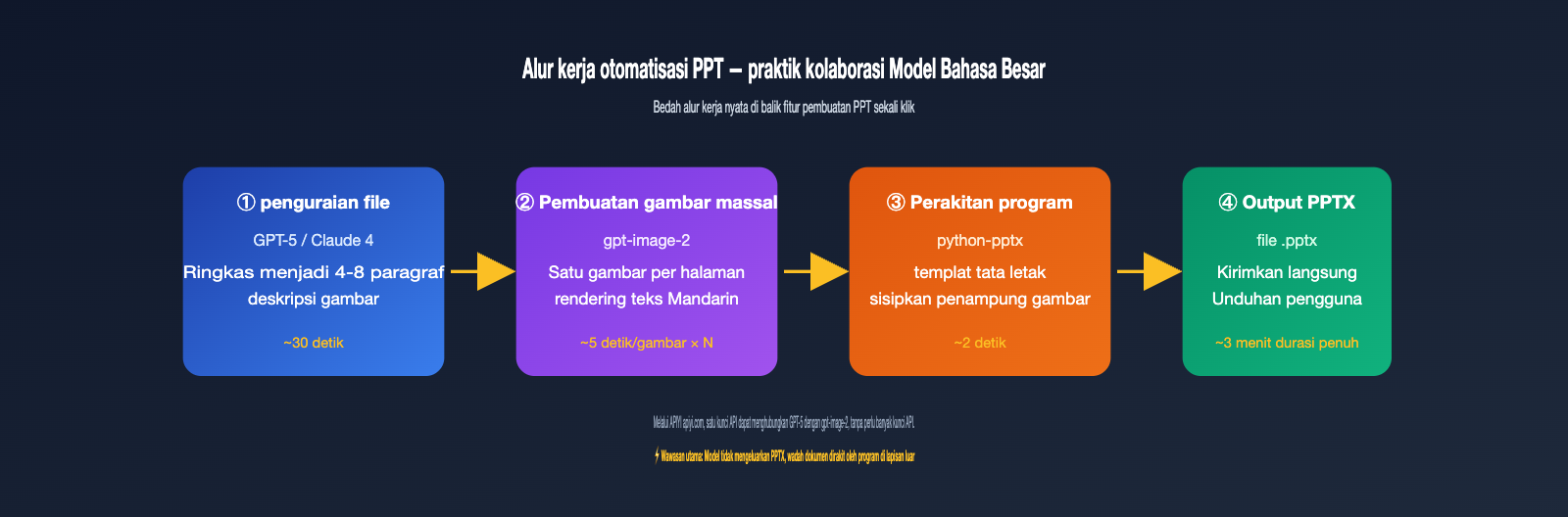
Skema 4: Alur Kerja Model Ganda LLM + gpt-image-2
Cocok untuk file dengan konten kompleks yang memerlukan pemahaman semantik, seperti laporan panjang, ringkasan kontrak, atau salinan produk. Gunakan seri GPT-4 atau Claude 4 untuk memahami file dan mengekstrak 4-8 deskripsi visual, lalu panggil gpt-image-2 secara berulang untuk menghasilkan jumlah gambar yang sesuai.
Kunci dari langkah ini adalah memisahkan "pemahaman semantik" dan "pembuatan gambar". LLM bertanggung jawab untuk menentukan "apa yang harus digambar di halaman ini", dan gpt-image-2 bertanggung jawab untuk "menggambar sesuai dengan petunjuk tersebut". Seluruh alur kerja dapat dihubungkan menggunakan kunci API yang sama di APIYI apiyi.com, sehingga menghemat kerumitan dalam mengganti SDK dan manajemen kunci API.
Skema 5: Sintesis PPT/Poster Terprogram Setelah Pembuatan Gambar Massal
Inilah rahasia di balik kasus "PPT sekali klik" yang sering muncul di TikTok. Model itu sendiri tidak akan mengeluarkan file PPTX, tetapi dapat menghasilkan gambar untuk setiap halaman, lalu menggunakan python-pptx atau PptxGenJS di sisi frontend untuk memasukkan gambar ke posisi yang sesuai dalam templat PPT.
Singkatnya: PPT pada dasarnya adalah dokumen presentasi yang terdiri dari banyak gambar, gpt-image-2 menyelesaikan masalah "gambar", dan python-pptx menyelesaikan masalah "wadah dokumen". Pembagian umum adalah: gambar berkualitas tinggi 4K untuk sampul, kualitas sedang 1536×1024 untuk halaman isi, dan draf kualitas rendah untuk halaman daftar isi dan transisi, dengan mengontrol biaya melalui perbedaan parameter quality. PPT 20 halaman memerlukan sekitar 20-30 pemanggilan model, dan pada saluran proksi API 5000 RPM, proses ini bisa selesai dalam beberapa menit.
| Skema | Jenis File yang Cocok | Beban Kerja | Kualitas Output | Skenario Rekomendasi |
|---|---|---|---|---|
| Skema 1 Konversi ke Teks | CSV/Excel/JSON | Rendah | Sedang | Grafik sederhana, ilustrasi gaya |
| Skema 2 Input Tangkapan Layar | PDF/PPT/Web | Rendah | Sedang-Tinggi | Penulisan ulang tata letak, transfer gaya |
| Skema 3 Pra-render Visualisasi | CSV/Excel | Sedang | Tinggi | Mempercantik grafik data |
| Skema 4 LLM + gpt-image-2 | Laporan/Salinan | Sedang-Tinggi | Tinggi | Kartu konten, gambar tutorial |
| Skema 5 Sintesis PPT Massal | Apa saja | Tinggi | Tinggi | Otomatisasi dokumen presentasi |
Contoh Kode Pemanggilan API: Bagaimana Mengubah Konten File Menjadi Input untuk gpt-image-2
Melihat konsep ini langsung ke level kode akan jauh lebih intuitif. Berikut adalah contoh Python minimal yang dapat dijalankan, yang mengubah tabel Excel menjadi petunjuk teks, lalu memanggil gpt-image-2 untuk menghasilkan bagan visualisasi yang sesuai. Kita menggunakan APIYI (apiyi.com) sebagai pintu masuk layanan proksi API terpadu, Anda hanya perlu mengganti base_url, sementara penulisan SDK lainnya sepenuhnya sama dengan versi resmi.
from openai import OpenAI
import pandas as pd
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
# Membaca file Excel
df = pd.read_excel("sales_q1.xlsx")
summary = df.groupby("region")["sales"].sum().to_dict()
# Mengubah data menjadi deskripsi teks
prompt_text = (
f"Buat bagan batang penjualan regional Q1 tahun 2026,"
f"dengan data: {summary}, "
f"gaya bisnis gelap, judul putih bersih, label data terlihat jelas."
)
# Memanggil model untuk pembuatan gambar
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt_text,
size="1536x1024",
quality="high"
)
# Menyimpan hasil gambar
img_b64 = resp.data[0].b64_json
with open("sales_chart.png", "wb") as f:
f.write(base64.b64decode(img_b64))
Logika kodenya sangat jelas: lapisan bisnis mengurai Excel menjadi deskripsi teks, dan lapisan model hanya menerima teks. Jika menggunakan metode gambar ke gambar (skema kedua), cukup ganti client.images.generate menjadi client.images.edit, dan masukkan gambar melalui image=open("page.png", "rb").
| Parameter | Rentang Nilai | Penjelasan |
|---|---|---|
model |
gpt-image-2 / gpt-image-2-mini |
Versi mini lebih cepat dan lebih murah |
size |
1024×1024 / 1536×1024 / 1024×1536 / kustom | Sisi terpanjang ≤ 3840px, panjang sisi harus kelipatan 16 |
quality |
low / medium / high / auto | Kualitas tinggi memakan waktu lebih lama dan konsumsi token lebih besar |
n |
1–4 | Jumlah gambar per pembuatan, untuk batch disarankan gunakan loop luar |
response_format |
png(default)/ jpeg / webp | gpt-image-2 tidak mendukung output PDF/PPTX |
🎯 Saran Level Kode: Untuk menjalankan alur ini dengan cepat, kami sarankan untuk mendaftar akun di APIYI (apiyi.com), ubah
base_urlkehttps://api.apiyi.com/v1agar Anda bisa menggunakan antarmuka terpadu untuk memanggil gpt-image-2, GPT-5, dan seri Claude 4 secara bersamaan, sehingga Anda tidak perlu repot melakukan integrasi ke berbagai vendor satu per satu.

4 Masalah Paling Umum yang Dihadapi Pelanggan dan Cara Mengatasinya
Setelah memahami 5 skema tersebut, saat implementasi nyata Anda mungkin akan menemui beberapa kendala teknis. Kami telah merangkum 4 jenis masalah yang paling sering ditanyakan di grup layanan pelanggan kami.
Masalah 1: Memasukkan CSV berkode base64 ke dalam petunjuk
Ada yang mencoba "cara cerdas": membaca file CSV menjadi string base64 dan memasukkannya ke dalam petunjuk, dengan asumsi model akan mendekodenya sendiri. Cara ini sama sekali tidak berhasil, gpt-image-2 tidak akan menjalankan kode, dan tidak akan memperlakukan string tersebut sebagai data; ia hanya akan menganggap string base64 sebagai karakter yang tidak berarti dan menghasilkan gambar yang berantakan. Cara yang benar adalah dengan mengurai CSV menjadi deskripsi teks di lapisan bisnis, lihat skema pertama.
Masalah 2: Berharap gpt-image-2 menggambar tabel "sama persis seperti Excel"
Model sangat mahir dalam konsistensi visual dan gaya, tetapi reproduksi tingkat piksel adalah hal yang berbeda. Jika Anda memerlukan tabel yang ketat, kami sarankan strategi kombinasi: gunakan ECharts/matplotlib untuk menggambar versi yang akurat (skema ketiga), lalu biarkan gpt-image-2 mempercantik tampilannya. Mengharapkan satu petunjuk agar model menggambar 100 baris data secara akurat, saat ini belum bisa dilakukan.
Masalah 3: Output file yang diinginkan adalah format vektor SVG atau PDF
Format output gpt-image-2 hanya tersedia dalam tiga format bitmap: PNG, JPEG, dan WebP, tidak ada format vektor seperti SVG, PDF, atau AI. Jika memerlukan gambar vektor, silakan gunakan Stable Diffusion yang dikombinasikan dengan vectorizer.ai, atau langsung minta GPT-5 untuk menghasilkan kode SVG. Pastikan format output sebelum memilih model untuk menghindari pengerjaan ulang.
Masalah 4: Mengunggah gambar referensi yang sama berulang kali, konsumsi token melonjak
gpt-image-2 memproses setiap gambar input dengan fidelitas tinggi, meskipun petunjuk Anda hanya sedikit berubah, setiap permintaan akan menghitung ulang input token. Disarankan untuk melakukan caching gambar referensi di sisi klien, atau gunakan previous_response_id untuk pengeditan percakapan (Responses API) guna menggunakan kembali konteks gambar sebelumnya.
Detail lain yang perlu diperhatikan: meskipun target output Anda hanya gambar kecil 256×256, selama gambar referensinya adalah gambar 4K, input token tetap dihitung berdasarkan 4K. Kompres gambar referensi secara lokal ke sisi terpanjang 1024 sebelum diunggah, Anda dapat menghemat lebih dari 60% input token, ini adalah poin kontrol biaya yang paling mudah diabaikan dalam tugas batch besar.
| Gejala Kesalahan | Penyebab Utama | Solusi yang Disarankan |
|---|---|---|
| 400 invalid_request_error | Mengunggah biner non-gambar (CSV/Excel) | Ubah file menjadi teks atau tangkapan layar di lapisan luar |
| Karakter menjadi berantakan | String base64 digunakan sebagai petunjuk | Gunakan deskripsi bahasa alami yang telah diurai |
| Data tabel tidak akurat | Menggunakan petunjuk untuk menggambar tabel presisi | Gunakan pra-render visualisasi skema ketiga |
| Ingin output SVG | Model tidak mendukung format vektor | Gunakan GPT-5 untuk menghasilkan kode SVG |
| Konsumsi token melebihi ekspektasi | Gambar referensi besar diunggah berulang kali | Kompres ke bawah 1.5MB, aktifkan caching |
Pertanyaan Umum (FAQ)
Q1: Apakah gpt-image-2 benar-benar tidak bisa mengunggah PDF sama sekali?
Tidak bisa diunggah langsung. Namun, Anda bisa menggunakan pdftoppm untuk mengubah setiap halaman menjadi PNG, lalu mengunggahnya sebagai gambar. Jika Anda butuh "memahami konten PDF untuk membuat gambar", disarankan menggunakan GPT-5 untuk membaca PDF dan merangkum deskripsinya, lalu berikan deskripsi tersebut ke gpt-image-2. Kombinasi ini bisa dijalankan dengan satu kunci API di APIYI apiyi.com.
Q2: Apakah aman mengirim file yang berisi data sensitif ke model?
Proses konversi file menjadi teks dilakukan di server Anda sendiri, hanya teks petunjuk akhir yang dikirim ke model, sehingga Anda bisa melakukan anonimisasi saat konversi teks. Jika menggunakan layanan proksi API, antarmuka APIYI apiyi.com secara eksplisit tidak menyimpan prompt pengguna maupun konten balasan, sehingga dari sisi kepatuhan lebih terkontrol dibandingkan menggunakan proxy luar negeri secara langsung.
Q3: Apakah alat "buat PPT sekali klik" di TikTok menggunakan gpt-image-2?
Ada yang pakai, ada yang tidak. Logikanya biasanya: Model Bahasa Besar menulis naskah → model gambar (gpt-image-2 / Nano Banana Pro / Flux) membuat ilustrasi → backend menggunakan python-pptx untuk merakitnya. gpt-image-2 memiliki performa terbaik dalam rendering teks, terutama teks Mandarin, sehingga sangat cocok untuk ilustrasi halaman dalam PPT.
Q4: Mengapa ada yang bilang bisa mengunggah Excel?
Itu karena mereka mengambil tangkapan layar Excel dan mengunggahnya sebagai gambar. Pada dasarnya, itu tetap input gambar, bukan model yang memahami struktur Excel. Jika Anda melihat angka di tangkapan layar buram, model pun hanya bisa menggambar ulang sesuai dengan tampilan yang buram tersebut.
Q5: Pilih gpt-image-2 atau gpt-image-2-mini?
Versi mini lebih cepat dan murah, cocok untuk draf massal dan thumbnail; gunakan versi standar untuk materi publikasi resmi. Batasan input kedua versi ini sama persis (keduanya tidak mendukung file dokumen), Anda hanya perlu mengganti ID model pada parameter model, tanpa perlu mengubah penulisan SDK.
Kesimpulan
gpt-image-2 tidak mendukung unggahan langsung file CSV/Excel/PPT, dan juga tidak mengeluarkan file PPTX/PDF. Ini adalah batasan kemampuan model, bukan karena parameter akses yang salah. Setelah memahami batasan ini, lakukan pra-pemrosesan konten file—seperti mengubahnya menjadi teks, tangkapan layar, atau visualisasi terlebih dahulu—maka model ini bisa melayani sebagian besar kebutuhan yang "tampak memerlukan input file". Alat PPT sekali klik, pengubah Excel menjadi poster, atau pengubah gaya PDF yang Anda lihat di TikTok pada dasarnya adalah kombinasi rekayasa alur kerja multi-langkah. Kuncinya adalah memisahkan tugas antara inferensi model dan pemrosesan data.
Inti dari implementasi ini hanya satu: Lapisan model hanya mengerjakan apa yang dikuasai model, sementara lapisan data harus diselesaikan di luar sebelumnya. Jika Anda ingin menjalankan alur kerja yang lengkap, kami merekomendasikan untuk mengakses GPT-5 (untuk pemahaman teks) dan gpt-image-2 (untuk pembuatan gambar) di APIYI apiyi.com. Satu kunci API untuk seluruh alur, dengan kemampuan konkurensi tinggi hingga 5000 RPM agar tugas massal berjalan lancar, tanpa perlu repot mengelola banyak kunci API dan SDK untuk model yang berbeda.
Tentang Penulis: Tim APIYI berfokus pada agregasi multi-model dan infrastruktur inferensi konkurensi tinggi, menangani banyak konsultasi API pembuatan gambar setiap harinya. Artikel ini disusun berdasarkan dokumentasi resmi OpenAI dan konsultasi klien nyata. Jika Anda ingin mengetahui solusi akses gpt-image-2, silakan kunjungi APIYI apiyi.com.