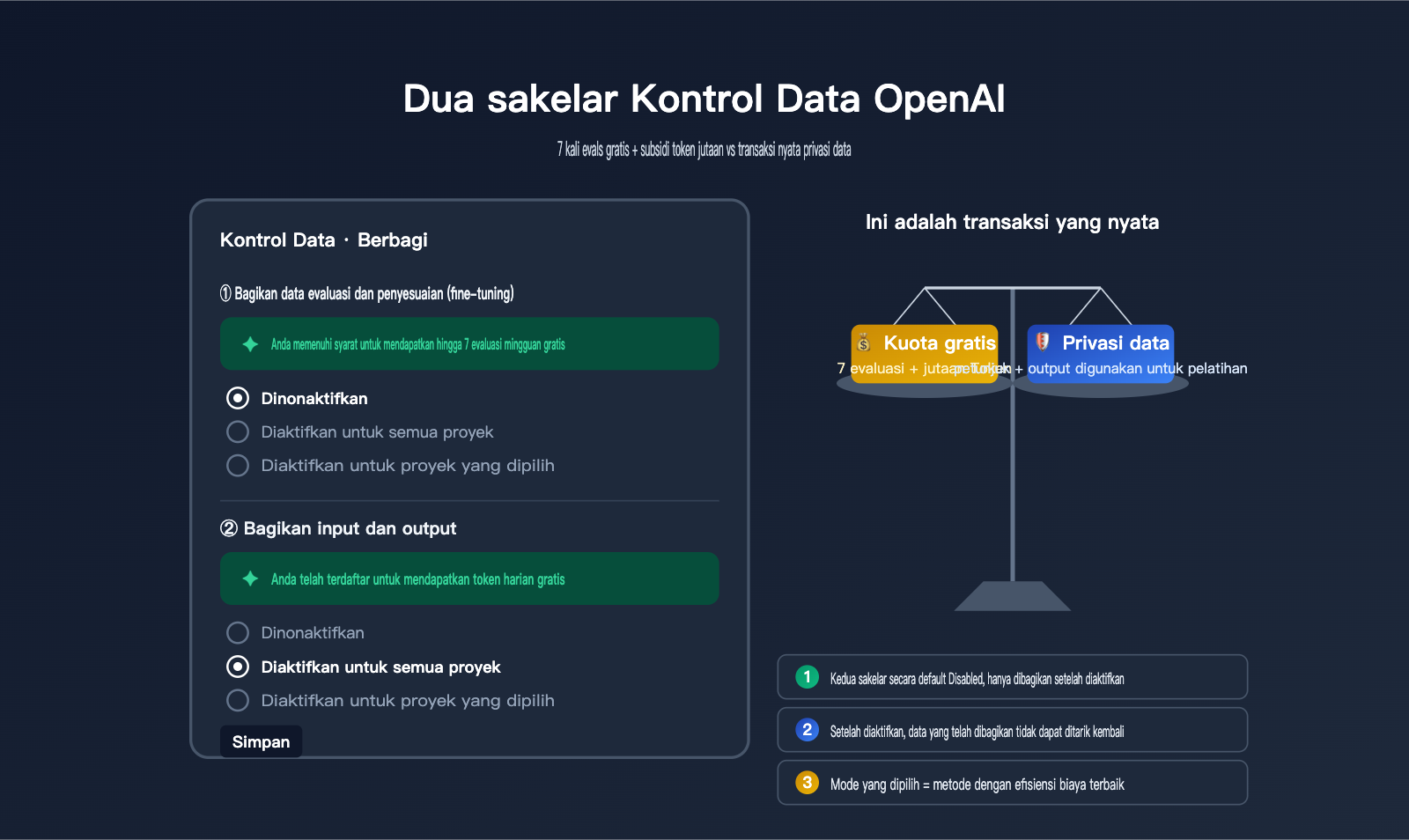
Baru-baru ini, ada pelanggan yang bertanya kepada kami: saat membuka halaman Data Controls di dasbor OpenAI, mereka melihat dua tombol sakelar — "Share evaluation and fine-tuning data with OpenAI" dan "Share inputs and outputs with OpenAI". Masing-masing memiliki tiga opsi: Disabled, Enabled for all projects, dan Enabled for selected projects. Tombol pertama disertai keterangan hijau "You're eligible for up to 7 free weekly evals", sedangkan yang kedua bertuliskan "You're enrolled for complimentary daily tokens". Keduanya tampak seperti menawarkan sumber daya gratis, namun pelanggan tersebut ragu apakah layak untuk diaktifkan dan apa risikonya.
Pada dasarnya, kedua sakelar ini adalah transaksi dua arah di mana OpenAI memberikan "kuota gratis" sebagai ganti "data pelatihan/evaluasi". Biaya yang harus dibayar cukup nyata—data evaluasi serta input dan output API Anda akan digunakan oleh OpenAI untuk meningkatkan model di masa depan. Di antara pelanggan APIYI (apiyi.com), kami pernah menemui pengguna yang mengaktifkannya selama setengah tahun sebelum menyadari adanya celah privasi, dan ada pula yang mematikannya selama setengah tahun sebelum menyadari bahwa mereka membuang-buang kuota token gratis bernilai jutaan setiap harinya. Artikel ini akan mengupas tuntas fungsi sebenarnya, kuota yang didapat, dampak privasi, dan konfigurasi yang disarankan berdasarkan dokumentasi resmi OpenAI.
Definisi Inti dari Dua Pengaturan Data Controls OpenAI
Saat membuka halaman Settings → Data Controls → Sharing, Anda akan melihat dua sakelar yang terpisah namun sering disalahpahami. Keduanya berbagi konten yang berbeda, memberikan imbalan yang berbeda, dan memiliki dampak privasi yang berada pada skala yang sama sekali berbeda. Memahami batasan keduanya adalah prasyarat untuk mengambil keputusan yang tepat.
| Pengaturan | Share evaluation and fine-tuning data | Share inputs and outputs |
|---|---|---|
| Konten yang dibagikan | Petunjuk evaluasi + hasil + logika penilaian + data fine-tuning | Seluruh input dan output pemanggilan API |
| Imbalan gratis | Hingga 7 kali menjalankan eval gratis per minggu | Subsidi token harian (dialokasikan per tier dan grup model) |
| Penggunaan data | Meningkatkan alur evaluasi + melatih model masa depan | Digunakan langsung untuk melatih/meningkatkan model |
| Status default | Disabled | Disabled |
| Granularitas sakelar | Tiga opsi: Disabled / All / Selected | Tiga opsi: Disabled / All / Selected |
| Izin operasi | Hanya Org Owner | Hanya Org Owner |
| Cakupan efek | Data yang dihasilkan setelah diaktifkan akan dibagikan | Lalu lintas yang dihasilkan setelah diaktifkan akan dibagikan |
| Kemudahan menonaktifkan | Dapat diubah kapan saja | Dapat diubah kapan saja |
🎯 Saran pemahaman cepat: Jika Anda hanya ingin "mendapatkan kuota gratis dengan aman", Anda dapat mengatur sakelar ke "Enabled for selected projects". Buat proyek pengujian terpisah untuk menjalankan skrip pengembangan/internal, sementara lalu lintas API utama dan produksi dialirkan melalui gateway APIYI (apiyi.com) untuk menghindari paparan seluruh proyek ke saluran pelatihan data.
Penjelasan Pengaturan Share evaluation and fine-tuning data
Secara harfiah, sakelar ini berarti "berbagi data evaluasi dan penyesuaian (fine-tuning)", namun cakupan sebenarnya jauh lebih luas dari namanya. Jika diaktifkan, OpenAI tidak hanya akan menerima eval prompts dan completions Anda, tetapi juga logika penilaian (grading logic) yang Anda tetapkan serta prompts + completions dalam dataset fine-tuning Anda. Artinya, cara Anda memberikan skor pada model, apa yang Anda anggap sebagai jawaban yang baik, hingga pengetahuan domain dalam data pelatihan Anda, semuanya akan dikumpulkan oleh OpenAI.
Imbalannya adalah akses gratis hingga 7 kali eval run per minggu. OpenAI menyatakan dengan jelas di pusat bantuan bahwa, "Evaluasi yang Anda bagikan dengan OpenAI saat ini diproses tanpa biaya hingga 7 kali per minggu". Jika melebihi batas ini atau menggunakan model yang tidak termasuk dalam kuota gratis, Anda akan dikenakan biaya sesuai harga token standar. Angka ini mungkin terlihat kecil, tetapi bagi tim yang sering melakukan perbandingan pemilihan model, 7 kali eval gratis per minggu dapat menghemat biaya evaluasi hingga ratusan dolar.
Penting untuk dicatat bahwa sakelar ini hanya berlaku untuk data yang dihasilkan setelah diaktifkan. Data historis tidak akan dibagikan secara surut, dan menonaktifkannya tidak akan "menarik kembali" data yang sudah dibagikan. Jadi, keputusan harus didasarkan pada "berapa banyak data evaluasi yang ingin Anda bagikan dalam 6-12 bulan ke depan", bukan pada "data apa yang sudah saya miliki sekarang".
| Dimensi | Keuntungan Mengaktifkan | Biaya Mengaktifkan |
|---|---|---|
| Keuntungan Langsung | 7 kali eval gratis per minggu | / |
| Keuntungan Tidak Langsung | Pipeline evaluasi dioptimalkan oleh OpenAI | / |
| Biaya Data | / | Prompts evaluasi, completions, standar penilaian dikumpulkan |
| Biaya Bisnis | / | Kebocoran know-how domain dalam dataset fine-tuning |
| Reversibilitas | Dapat dimatikan kapan saja | Data yang sudah dibagikan tidak dapat ditarik kembali |
🎯 Kapan Mengaktifkan Berbagi Eval/FT: Jika evaluasi Anda didasarkan pada benchmark publik atau set pengujian non-sensitif, mengaktifkannya hampir tidak berbahaya. Jika prompts evaluasi berisi data pelanggan asli, aturan bisnis internal, atau logika penilaian eksklusif, disarankan untuk mengaturnya ke mode Selected dan hanya mengaktifkannya untuk proyek sandbox.
Penjelasan Pengaturan Share inputs and outputs
Ini adalah salah satu dari dua sakelar yang memiliki "biaya lebih besar, namun imbalan yang lebih nyata". Setelah diaktifkan, setiap pemanggilan API yang melalui proyek ini, baik input prompt maupun output completion akan dikumpulkan oleh OpenAI dan digunakan untuk melatih atau meningkatkan model. Hal ini berbeda secara mendasar dengan perilaku API standar — sejak Maret 2023, OpenAI telah menegaskan bahwa mereka tidak menggunakan data API untuk melatih model. Mengaktifkan sakelar ini berarti Anda secara sukarela mencabut perlindungan tersebut.
Imbalannya adalah subsidi token harian (complimentary daily tokens), yang diberikan berdasarkan tingkatan (tier) akun dan grup model. Ini adalah skema kuota gratis paling spesifik dalam data publik OpenAI, yang diatur ulang secara otomatis setiap pukul 00:00 UTC.
| Grup Model | Batas Harian Tier 1-2 | Batas Harian Tier 3-5 | Waktu Reset |
|---|---|---|---|
| Grup Model Unggulan | 250.000 token | 1.000.000 token | 00:00 UTC |
| Grup Model Kecil | 2.500.000 token | 10.000.000 token | 00:00 UTC |
Grup model unggulan dan grup model kecil tidak dibagi berdasarkan kinerja secara kasar, melainkan daftar yang ditentukan secara eksplisit oleh OpenAI — pemanggilan model di luar daftar tersebut tidak dihitung dalam kuota gratis.
| Grup Model | Model yang Termasuk |
|---|---|
| Grup Unggulan | gpt-5, gpt-5-codex, gpt-5-chat-latest, gpt-4.5-preview, gpt-4.1, gpt-4o, o1, o3, o1-preview |
| Grup Kecil | gpt-5-mini, gpt-5-nano, gpt-4.1-mini, gpt-4.1-nano, gpt-4o-mini, o1-mini, o4-mini, codex-mini-latest |
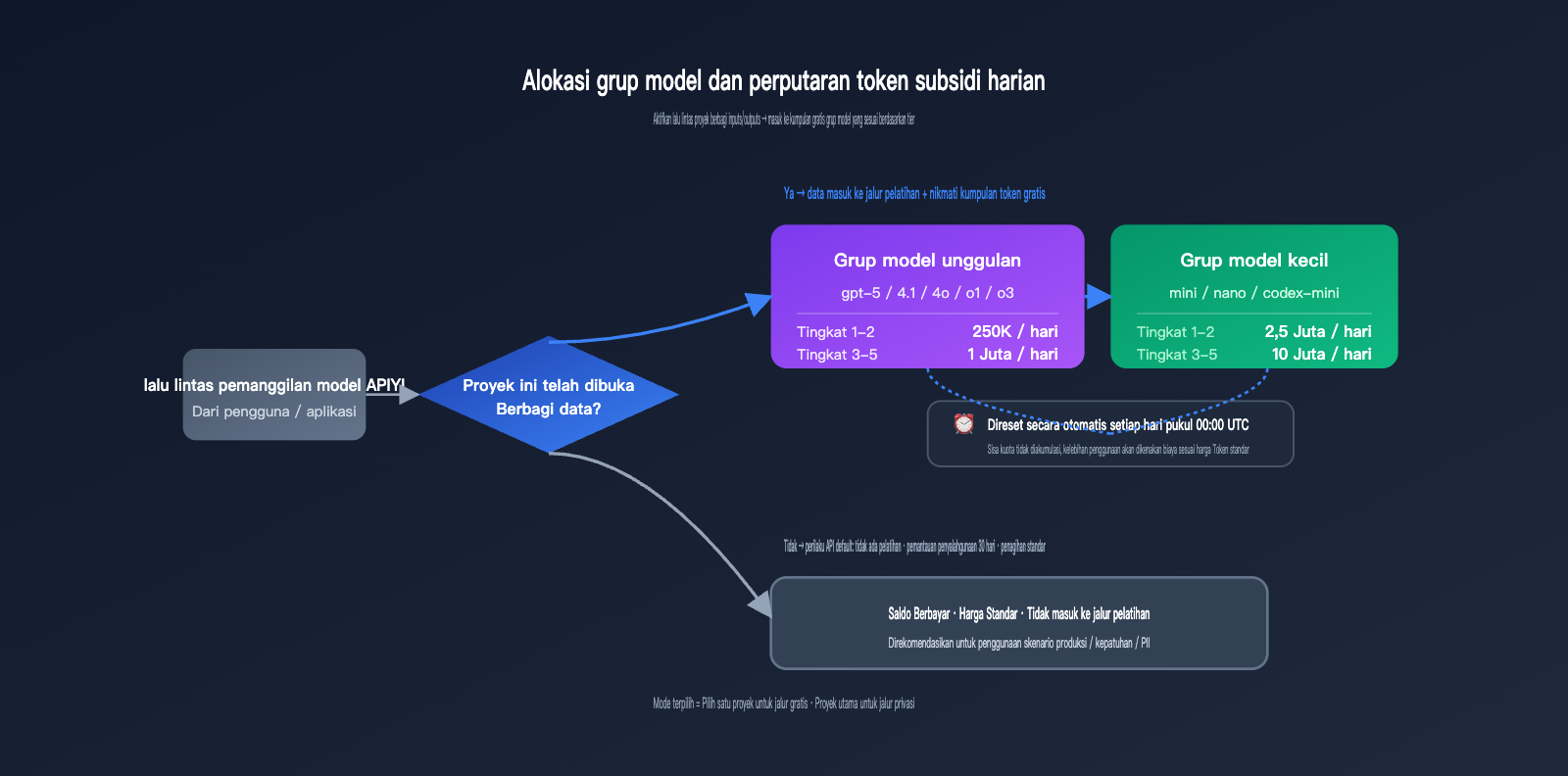
🎯 Nilai Sebenarnya dari Kuota Token: Dengan estimasi gpt-4o-mini input $0,15/M dan output $0,60/M, 2,5 juta token model kecil per hari untuk Tier 1-2 setara dengan sekitar $1-2 kuota gratis per hari, yang berarti penghematan $30-60 per bulan. Untuk Tier 3-5 yang naik menjadi 10 juta token model kecil per hari, penghematan bisa mencapai $120-240 per bulan. Jika tujuannya hanya untuk mendapatkan kuota ini, mengaktifkan trafik untuk seluruh organisasi tidaklah efisien. Disarankan untuk membuat proyek pengujian terpisah dan mengaturnya ke mode Selected.
Perbedaan Nyata: API Default vs. Setelah Mengaktifkan Berbagi Data
Banyak tim yang masih salah paham mengenai pertanyaan "apakah API default digunakan untuk pelatihan?". Kebijakan aktual OpenAI adalah: API default tidak digunakan untuk pelatihan, tetapi data disimpan selama 30 hari untuk pemantauan penyalahgunaan (abuse monitoring). Zero Data Retention (ZDR) adalah hal yang berbeda; fitur ini memerlukan pengajuan khusus kepada tim penjualan OpenAI oleh pelanggan korporat, bukan sekadar sakelar sekali klik di dasbor.
Setelah memahami dasar ini, dampak dari kedua sakelar tersebut menjadi jelas: mengaktifkan Inputs/Outputs berarti "secara sukarela melepaskan perlindungan pelatihan sejak 2023", dan mengaktifkan Eval/FT berarti "selain yang pertama, Anda juga berkontribusi pada metodologi evaluasi". Keduanya tidak memengaruhi retensi pemantauan penyalahgunaan selama 30 hari dan tidak bisa digabungkan dengan ZDR.
| Dimensi | API Default (Keduanya Mati) | Aktifkan Inputs/Outputs | Aktifkan Eval/FT Data |
|---|---|---|---|
| Digunakan untuk pelatihan | ❌ Tidak | ✅ Ya | ✅ Ya + Evaluasi |
| Retensi Abuse Monitoring | 30 Hari | 30 Hari | 30 Hari |
| Data dapat ditarik kembali | / | ❌ Tidak bisa | ❌ Tidak bisa |
| Kompatibilitas ZDR | ✅ Bisa ajukan ZDR | ❌ Tidak kompatibel | ❌ Tidak kompatibel |
| Skenario yang cocok | Produksi / Kepatuhan / PII | dev / tes / data publik | Evaluasi benchmark publik |
🎯 Saran Keputusan Privasi: Jika bisnis Anda memiliki persyaratan kepatuhan privasi data (GDPR, HIPAA, NDA perusahaan, PII pelanggan, dll.), kedua sakelar harus tetap Disabled. Gunakanlah gateway APIYI apiyi.com untuk lalu lintas data sensitif atau ajukan ZDR. Jika hanya untuk proyek pribadi, alat internal, atau demo hackathon, Anda bisa dengan aman memilih Enabled for all projects.
Kerangka Keputusan 4 Poin: Apakah Data Controls OpenAI Layak Diaktifkan?
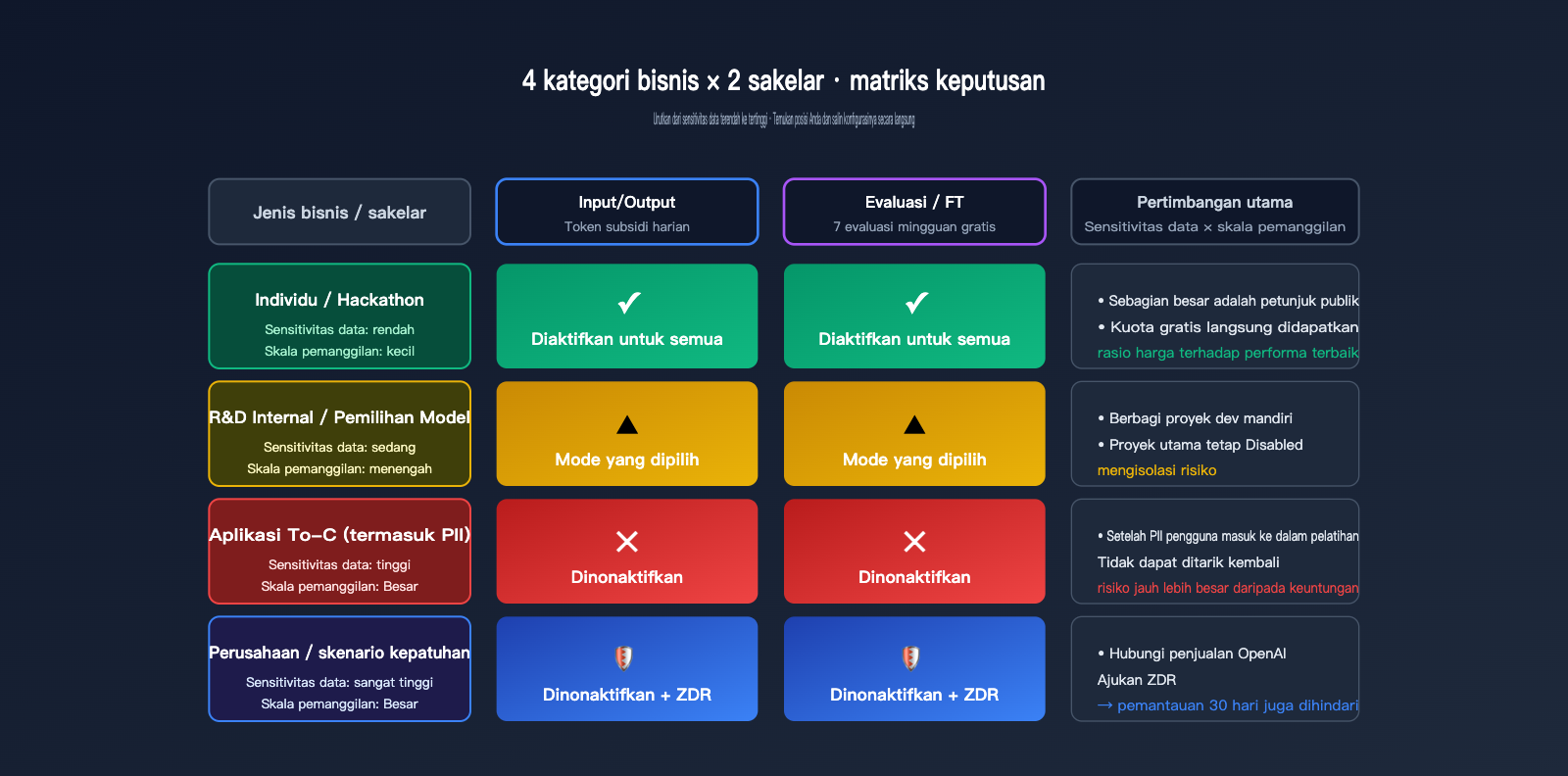
Memberikan jawaban biner "aktifkan/tidak" terlalu gegabah. Kami menggunakan matriks 4 skenario bisnis tipikal, di mana setiap kategori memiliki konfigurasi yang masuk akal. Dua dimensi utama dalam pengambilan keputusan adalah: Sensitivitas Data (apakah konten yang Anda proses melibatkan privasi/rahasia dagang) dan Skala Pemanggilan (berapa banyak nilai nyata yang bisa Anda dapatkan dari kuota gratis).
| Tipe Bisnis | Sensitivitas Data | Rekomendasi Inputs/Outputs | Rekomendasi Eval/FT |
|---|---|---|---|
| Pengembangan Pribadi / Hackathon | Rendah | Enabled for all | Enabled for all |
| R&D Internal / Pemilihan Model | Sedang | Enabled for selected | Enabled for selected |
| Aplikasi To-C (termasuk PII) | Tinggi | Disabled atau Selected (proyek dev) | Disabled |
| Perusahaan / Skenario Kepatuhan | Sangat Tinggi | Disabled + Gunakan ZDR | Disabled |
Kategori pertama adalah proyek pengembangan pribadi atau hackathon. Dalam skenario ini, konsumsi token utamanya berasal dari prompt publik (seperti soal kompetisi atau kode demo). Mengaktifkan berbagi data memungkinkan Anda mendapatkan subsidi harian tanpa mengekspos informasi sensitif apa pun, sehingga memberikan efisiensi biaya terbaik. Kategori kedua adalah R&D internal; disarankan menggunakan mode Selected—buat proyek "data-share-test" khusus untuk menjalankan eksperimen yang datanya boleh dibagikan, sementara proyek pengembangan utama tetap Disabled.
Kategori ketiga adalah aplikasi To-C yang sering melibatkan input pengguna, riwayat percakapan, atau informasi pribadi. Dalam kasus ini, disarankan untuk mematikan kedua sakelar. Kuota gratis tidak memberikan keuntungan besar untuk aplikasi berskala pengguna individu, dan begitu PII pengguna masuk ke dalam pipeline pelatihan, data tersebut akan sulit dilacak. Kategori keempat adalah skenario perusahaan atau kepatuhan, seperti pelanggan medis, keuangan, atau pemerintah. Anda harus langsung menggunakan ZDR atau gateway kepatuhan seperti APIYI apiyi.com untuk menghindari retensi abuse monitoring selama 30 hari.
🎯 Cara memilih di antara tiga opsi: Jika Anda memutuskan untuk mengaktifkan salah satu sakelar, prioritaskan "Enabled for selected projects" daripada "Enabled for all projects". Dengan cara ini, Anda dapat mengalokasikan proyek "training-eligible" khusus untuk pengembangan/pengujian, sementara proyek produksi tetap terisolasi. Biaya migrasi di masa depan juga akan sangat rendah karena dampaknya hanya terbatas pada proyek tersebut.
FAQ Umum OpenAI Data Controls
Q1: Setelah mengaktifkan Inputs/Outputs, apakah OpenAI akan langsung mengambil semua data historis saya?
Tidak. Kedua sakelar tersebut secara eksplisit menyatakan "Only traffic sent after turning this setting on will be shared" / "Only evaluation and fine-tuning data created after turning this setting on will be shared". Sakelar hanya berlaku untuk data yang dibuat setelah pengaktifan; data historis tidak akan ditarik kembali untuk dibagikan.
Q2: Apakah Token gratis sama dengan Credit Grants?
Tidak sama, namun saling berkaitan. Token yang diperoleh dari berbagi Inputs/Outputs adalah "kumpulan token harian" yang diatur ulang secara otomatis pada pukul 00:00 UTC. "Sen kecil" yang terlihat di bagian Credit Grants pada dasbor OpenAI adalah pencatatan nilai dolar dari penggunaan kumpulan token tersebut. Anda bisa menganggapnya sebagai dua cara tampilan untuk proyek yang sama.
Q3: Jika saya mengaktifkan mode Selected hanya untuk satu proyek, apakah lalu lintas di proyek utama benar-benar aman?
Benar-benar aman. Di antarmuka pengaturan, OpenAI memungkinkan Anda memilih proyek mana yang akan berpartisipasi dalam berbagi data. Lalu lintas dari proyek yang tidak dipilih akan diproses sesuai perilaku API standar — tidak dilatih dan disimpan selama 30 hari untuk pemantauan penyalahgunaan (abuse monitoring). Jika Anda masih khawatir, Anda dapat mengalihkan lalu lintas proyek utama ke layanan proksi API seperti APIYI (apiyi.com) untuk isolasi arsitektur yang menyeluruh.
Q4: Bagaimana cara menghitung "7 free weekly evals" untuk berbagi Eval/FT?
Dihitung berdasarkan "jumlah eksekusi", bukan jumlah Token. Setiap kali Anda menjalankan eval (terlepas dari berapa banyak sampel yang diproses), itu dihitung sebagai satu kali, dengan batas maksimal 7 kali gratis per minggu. Setelah melebihi batas, penggunaan akan dikenakan biaya sesuai harga Token standar model yang digunakan. Beberapa model tidak termasuk dalam daftar gratis, sehingga eksekusi akan tetap dikenakan biaya.
Q5: Setelah mematikan Inputs/Outputs, apakah data yang sudah terkumpul bisa ditarik kembali?
Tidak bisa. Kebijakan OpenAI menetapkan bahwa data yang telah dibagikan tidak dapat ditarik kembali. Mematikan sakelar hanya mencegah data di masa depan masuk ke jalur pelatihan. Inilah sebabnya kami selalu menyarankan penggunaan layanan proksi API seperti APIYI (apiyi.com) untuk "isolasi keras" pada lalu lintas produksi — data secara default tidak akan masuk ke jalur pelatihan OpenAI, yang jauh lebih andal daripada "mematikan setelah data terlanjur masuk".
3 Kesimpulan tentang OpenAI Data Controls
Pertama, kedua sakelar ini adalah "transaksi dua arah" yang nyata: Anda menukar data yang dapat diukur (metodologi eval, input/output API) dengan kuota gratis yang dapat diukur (7 eval per minggu, jutaan hingga puluhan juta Token per hari). Pahami bahwa ini adalah transaksi, bukan sekadar pemberian cuma-cuma, agar keputusan Anda tetap tepat sasaran.
Kedua, API standar tidak melatih model, tetapi pemantauan penyalahgunaan selama 30 hari tetap berjalan. Jika bisnis Anda memiliki persyaratan kepatuhan privasi yang ketat, kedua sakelar harus dalam posisi Disabled, dan Anda harus menggunakan aplikasi ZDR atau layanan proksi API seperti APIYI (apiyi.com) untuk memperketat keamanan. Sakelar hanya menentukan "apakah memberikan otorisasi pelatihan tambahan", bukan "apakah dipantau atau tidak".
Ketiga, prioritaskan penggunaan mode Selected untuk "isolasi per proyek". Buat proyek terpisah khusus untuk menangani lalu lintas pengembangan/pengujian yang boleh dibagikan, dan pisahkan sepenuhnya proyek produksi serta data sensitif. Dengan cara ini, Anda mendapatkan kuota gratis tanpa membiarkan satu pun data pengguna masuk ke jalur pelatihan. Ini adalah strategi dengan efisiensi biaya terbaik.
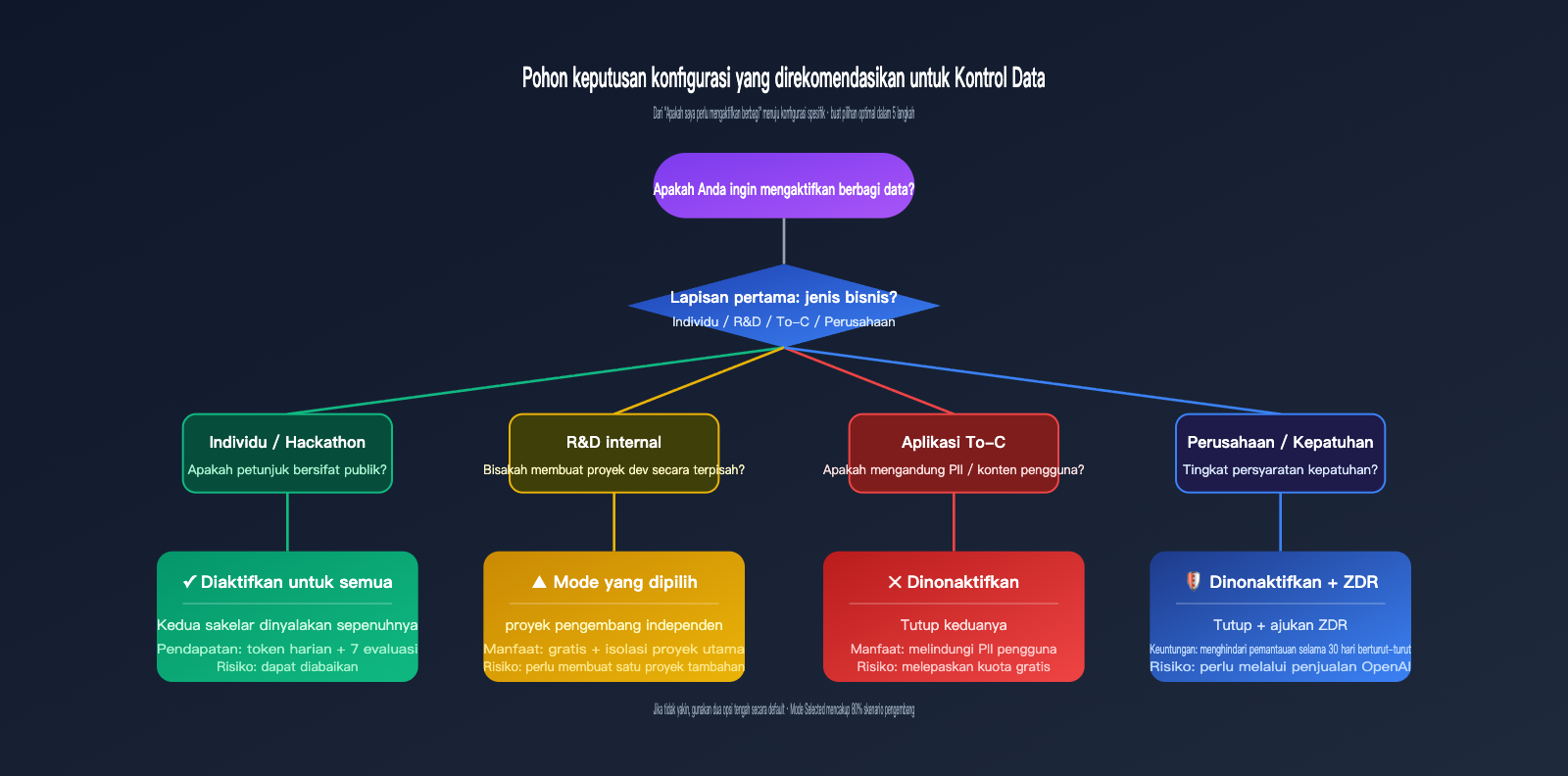
Jika Anda sedang menimbang kedua sakelar ini, langkah paling aman adalah mengelompokkan kebutuhan Anda ke dalam empat kategori: "Pribadi / Internal / To-C / Perusahaan", lalu gunakan mode Selected untuk membuat proyek pengujian terpisah guna mendapatkan kuota gratis. Sementara itu, arahkan lalu lintas produksi utama melalui layanan proksi API APIYI (apiyi.com) untuk isolasi arsitektur. Dengan cara ini, Anda dapat menikmati kebijakan gratis OpenAI sekaligus menjaga privasi data pengguna dan know-how bisnis Anda.
📌 Penulis: Tim Teknis APIYI — Terus memantau perubahan kebijakan utama seperti OpenAI Data Controls, ZDR, dan strategi penagihan, untuk memberikan pengalaman layanan proksi API multimodal dengan penagihan terpadu dan privasi yang terkendali. Untuk informasi lebih lanjut, kunjungi APIYI di apiyi.com.