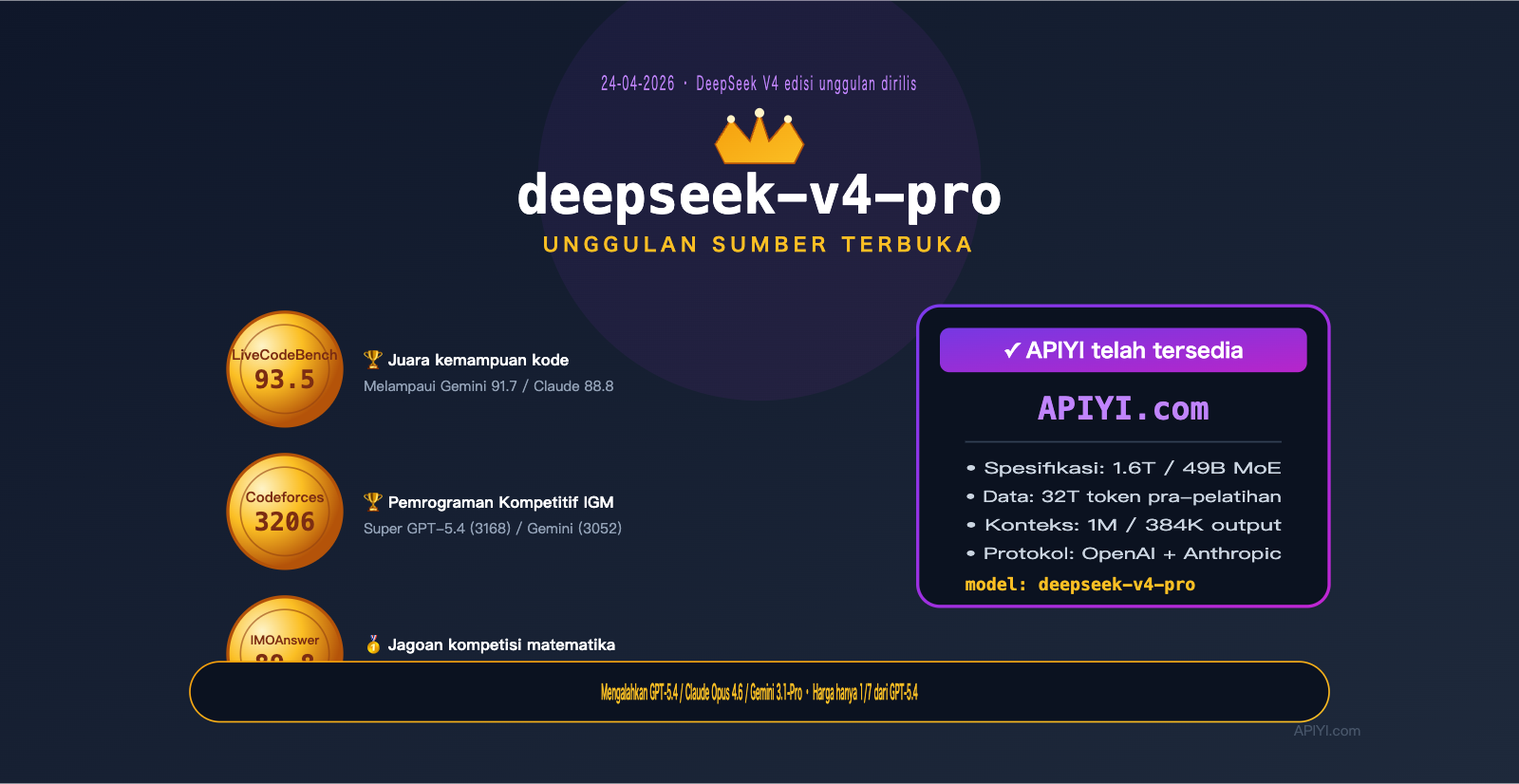
Pada 24 April 2026, DeepSeek secara resmi merilis V4-Pro dan V4-Flash ke ranah sumber terbuka (open source). Jika Flash adalah pilihan ekonomis yang "cukup untuk kebutuhan sehari-hari", maka V4-Pro adalah produk yang berada di kelas yang benar-benar berbeda:
Ini adalah Model Bahasa Besar sumber terbuka dengan kemampuan coding terkuat saat ini.
Ini bukan sekadar ungkapan halus untuk "terkuat di antara model open source", melainkan juara yang data mentahnya secara langsung melampaui GPT-5.4 / Claude Opus 4.6 / Gemini 3.1-Pro:
- LiveCodeBench 93.5 — Peringkat pertama, mengungguli Gemini 3.1-Pro (91.7) dan Claude Opus 4.6 (88.8)
- Codeforces Rating 3206 — Melampaui GPT-5.4 (3168) dan Gemini 3.1-Pro (3052)
- Apex Shortlist Pass@1 90.2 — Unggul jauh di atas GPT-5.4 (78.1) dan Claude (85.9)
- IMOAnswerBench 89.8 — Pada soal kompetisi matematika, ia mengungguli Claude Opus 4.6 (75.3) dengan selisih 14 poin
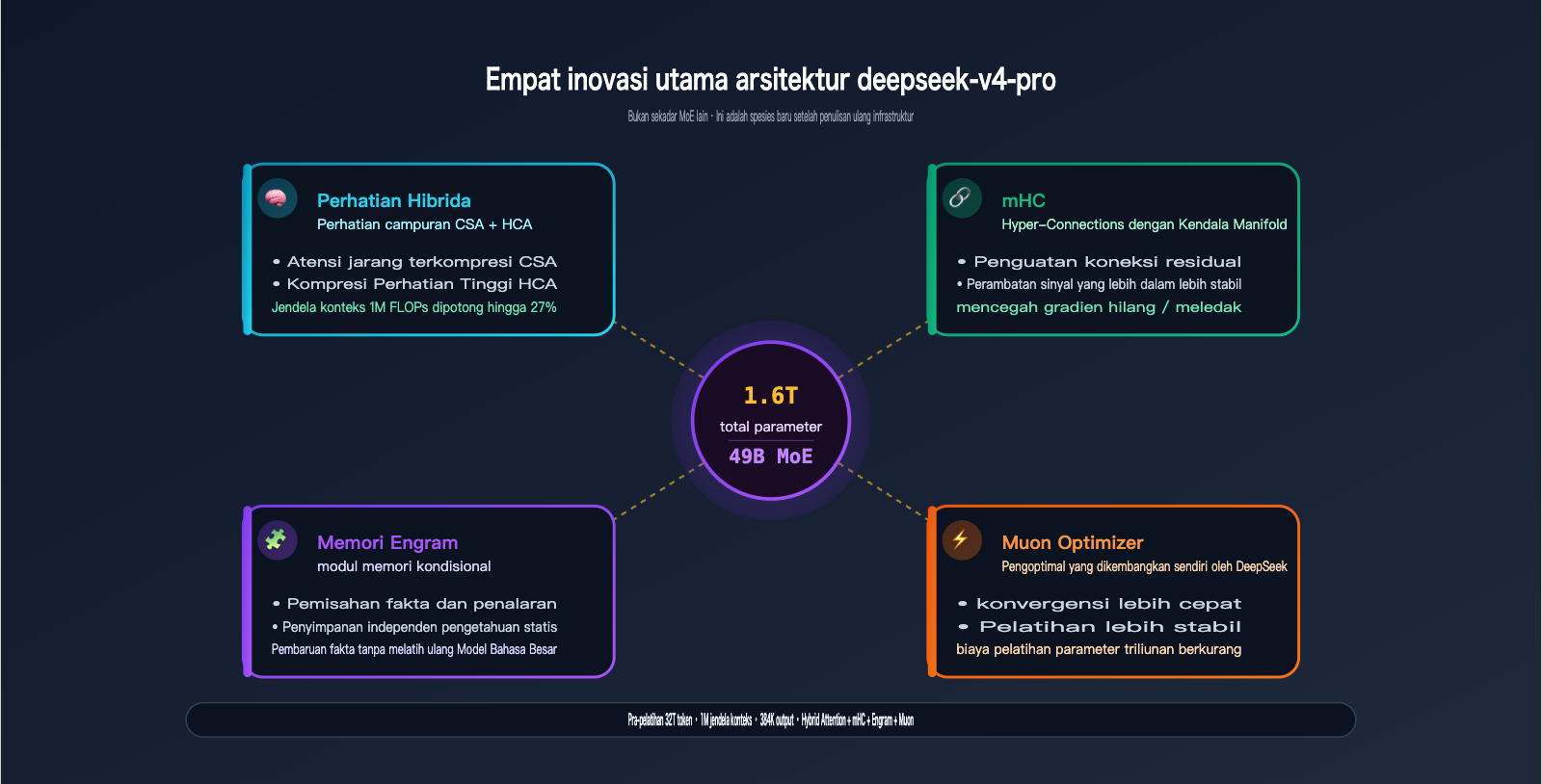
Spesifikasi teknisnya mencakup: 1.6T total parameter / 49B aktivasi / 32T token pra-pelatihan / 1M jendela konteks / 384K output, ditambah dengan empat inovasi arsitektur yang dirancang khusus oleh DeepSeek untuk seri V4: Hybrid Attention, Manifold-Constrained Hyper-Connections (mHC), Engram Conditional Memory, dan Muon Optimizer.
deepseek-v4-pro kini telah tersedia di APIYI apiyi.com. Anda dapat mengintegrasikannya tanpa perlu perubahan kode menggunakan SDK protokol OpenAI atau Anthropic, dengan harga hanya 1/7 dari biaya GPT-5.4.
Artikel ini tidak akan mengulang dasar-dasar "cara migrasi/cara memilih model murah" yang sudah dibahas di artikel seri Flash—ini adalah panduan mendalam khusus bagi para pengikut setia teknologi deepseek-v4-pro:
- Pahami dalam 3 menit mengapa Pro layak disebut sebagai "flagship" (arsitektur + data + skala)
- 4 tabel perbandingan Benchmark untuk melihat di medan perang mana Pro menang dan kalah
- 5 menit integrasi + 2 skenario nyata penggunaan kode/matematika
Satu. Empat Kemampuan Unggulan deepseek-v4-pro
1.1 Tabel Spesifikasi Inti
| Dimensi | deepseek-v4-pro |
|---|---|
| Tanggal Rilis | 24-04-2026 (Versi Pratinjau) |
| Repositori Open Source | huggingface.co/deepseek-ai/DeepSeek-V4-Pro |
| Total Parameter | 1.6T (Mixture of Experts) |
| Parameter Aktif | 49B |
| Data Pra-pelatihan | > 32T token |
| Jendela konteks | 1M token |
| Output Maksimum | 384K token |
| Inovasi Arsitektur | Hybrid Attention + mHC + Engram Memory + Muon |
| Mode Inferensi | Mode Thinking / Non-Thinking |
| Function Calling | ✅ Didukung |
| Mode JSON | ✅ Didukung |
| Protokol API | Kompatibilitas ganda OpenAI + Anthropic |
| Harga Input | $1.74 / M token |
| Harga Output | $3.48 / M token |
Ingat 4 angka paling krusial ini: 1.6T / 49B / 32T / 1M—inilah fondasi dari model unggulan ini.
1.2 1.6T / 49B MoE: "Langit-langit" Open Source dalam Hal Skala
DeepSeek-V4-Pro memiliki total 1,6 triliun parameter, menggunakan arsitektur Mixture of Experts, dengan setiap token hanya mengaktifkan 49B parameter. Berikut makna dari angka-angka tersebut:
| Model | Total Parameter | Parameter Aktif | Tipe |
|---|---|---|---|
| Llama 3 70B | 70B | 70B | Dense (Aktif Penuh) |
| Mistral Large 2 | 123B | 123B | Dense |
| DeepSeek-V3.2 | 671B | 37B | MoE |
| DeepSeek-V4-Pro | 1.6T | 49B | MoE ⭐ |
| Claude Opus 4.6 | Tidak diungkap | Tidak diungkap | Closed Source |
Total parameter 1.6T memberikan cakupan pengetahuan yang mendekati level GPT-5.4 / Claude Opus, sementara parameter aktif 49B menjaga biaya inferensi per token tetap terkendali—inilah alasan mendasar mengapa arsitektur MoE mampu mencapai performa mutakhir.
1.3 Pra-pelatihan 32T token: Total Data yang Maksimal
Data pra-pelatihan > 32T token
Ini adalah angka yang sangat mengesankan:
- Data pra-pelatihan GPT-4 sekitar 13T token (estimasi industri)
- Llama 3 15T token
- DeepSeek-V3 14.8T token
- DeepSeek-V4-Pro: >32T token ⭐
Manfaat langsung dari penggandaan jumlah data adalah: cakupan pengetahuan ekor panjang yang lebih lengkap, korpus kode yang lebih mutakhir, dan basis soal matematika yang lebih mendalam—inilah akar penyebab V4-Pro mendominasi papan peringkat di LiveCodeBench dan IMOAnswerBench.
1.4 Empat Inovasi Arsitektur: Keunggulan Kompetitif Sejati Pro
Inilah yang membedakan V4-Pro dari sekadar "model MoE lainnya". Empat inovasi inti yang diungkap secara resmi:
| Inovasi | Nama Lengkap | Masalah yang Diselesaikan |
|---|---|---|
| Hybrid Attention | CSA + HCA Mixed Attention | Masalah FLOPs dan VRAM pada inferensi konteks panjang (1M) |
| mHC | Manifold-Constrained Hyper-Connections | Stabilitas koneksi residual dalam, mencegah gradien hilang/meledak |
| Engram | Engram Conditional Memory | Memisahkan "fakta statis" dan "kemampuan penalaran", pembaruan fakta lebih murah |
| Muon | Muon Optimizer | Kecepatan konvergensi pelatihan dan stabilitas, menurunkan biaya pelatihan |
Setiap poin layak untuk dibahas lebih dalam:
-
Hybrid Attention (CSA + HCA): Kompleksitas attention pada Transformer tradisional adalah O(n²), yang akan meledak pada konteks 1M. V4 menggunakan Compressed Sparse Attention (CSA) untuk penyaringan kasar dan Highly Compressed Attention (HCA) untuk fokus detail, yang digabungkan untuk memangkas FLOPs hingga 27% dari V3.2, dan cache KV hanya 10%. Inilah kunci mengapa deepseek-v4-pro bisa "menjalankan" konteks 1M dengan lancar.
-
mHC (Manifold-Constrained Hyper-Connections): Saat melatih model MoE yang dalam, sinyal koneksi residual bisa terdistorsi setelah puluhan lapisan. mHC menambahkan batasan pada ruang manifold agar transmisi sinyal lebih stabil. Secara praktis: model dapat dilatih lebih dalam dan lebih lama tanpa mengalami crash.
-
Engram Conditional Memory: Inovasi yang sangat teknis. Ini memisahkan "fakta dalam memori model" dari "kemampuan penalaran"—fakta disimpan dalam modul memori khusus, sementara rantai penalaran menempuh jalur lain. Hasilnya, saat pengetahuan dunia perlu diperbarui, tidak perlu melatih ulang seluruh model, yang akan sangat menurunkan biaya rilis versi Pro di masa depan.
-
Muon Optimizer: Pengoptimal yang dikembangkan sendiri oleh DeepSeek, lebih cepat konvergen dan lebih stabil dibandingkan AdamW. Pada skala pelatihan triliunan parameter, ini berarti pelatihan yang lebih optimal dengan daya komputasi yang sama.
🎯 Wawasan Teknis: deepseek-v4-pro bukan sekadar memperbesar arsitektur lama, melainkan menulis ulang infrastrukturnya dari awal. Inilah alasan mendasar mengapa model ini mampu mencapai level raksasa closed-source dalam status open-source. Jika Anda berencana menggunakannya secara intensif, disarankan untuk mencoba serangkaian petunjuk bisnis tipikal melalui APIYI apiyi.com untuk merasakan perbedaan dari peningkatan arsitektur ini—terutama pada skenario konteks panjang dan penalaran multi-langkah.
1.5 Konteks 1M + Output 384K: Titik Balik Pembuatan Teks Panjang
Spesifikasi konteks Pro dan Flash sama: input 1M token, output 384K token. Namun, keunggulan Pro bukan pada "seberapa panjang yang bisa dibaca", melainkan "seberapa dalam ia bisa berpikir pada 1M token".
Makna praktis untuk skenario teks panjang:
| Tugas | Era V3.2 | Era V4-Pro |
|---|---|---|
| Revisi penuh naskah 500 ribu kata | Harus dibagi menjadi 10+ bagian | Diproses sekaligus dalam jendela 1M |
| Tanya jawab dokumen teknis 200 halaman | Harus membangun RAG | Masukkan langsung |
| Audit repositori kode menengah | Analisis berbasis ringkasan | Pemeriksaan konsistensi antar file |
| Koherensi penulisan novel | Harus mengelola memori sendiri | Output 384K dalam sekali jalan |
Dua. Takhta Benchmark deepseek-v4-pro
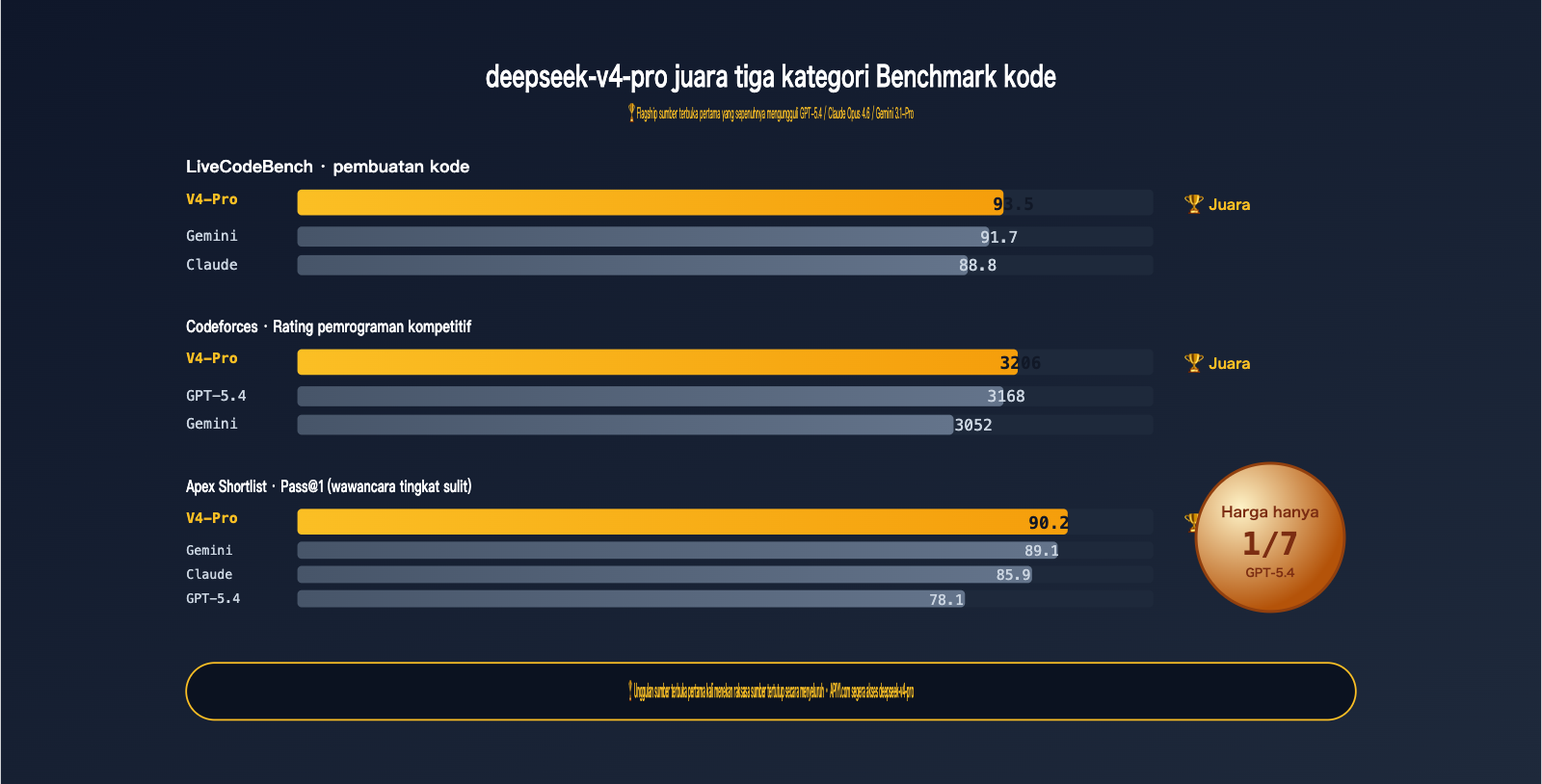
2.1 Kemampuan Kode: deepseek-v4-pro Mendominasi Tiga Papan Peringkat
Mari lihat data paling konkret—kemampuan pemrograman:
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro | Peringkat 1 |
|---|---|---|---|---|---|
| LiveCodeBench | 93.5 | — | 88.8 | 91.7 | V4-Pro 🏆 |
| Codeforces Rating | 3206 | 3168 | — | 3052 | V4-Pro 🏆 |
| Apex Shortlist Pass@1 | 90.2 | 78.1 | 85.9 | 89.1 | V4-Pro 🏆 |
| SWE-bench Verified | 80.6–82.1 | — | 80.8 | 80.6 | Seri |
| Terminal-Bench 2.0 | 67.9 | 75.1 | 65.4 | 68.5 | GPT-5.4 |
Memimpin di tiga kategori, dan "seri atau kalah tipis" di dua kategori. Untuk pertama kalinya, model open-source mengungguli raksasa closed-source dalam kemampuan kode—ini adalah peristiwa yang sangat signifikan di tahun 2026.
Penjelasan:
- LiveCodeBench 93.5: LiveCodeBench memperbarui soal setiap bulan untuk menghindari kontaminasi data pelatihan. Skor 93.5 V4-Pro menunjukkan kemampuan kodenya bersifat generalisasi dan mampu mengerjakan soal baru, bukan sekadar menghafal bank soal.
- Codeforces 3206: Peringkat pemrograman kompetitif, skor 3206 mendekati level IGM (International Grandmaster). Skor ini sudah sangat mumpuni untuk menangani kode bisnis sehari-hari.
- Apex Shortlist Pass@1 90.2 vs GPT-5.4 78.1: Kesenjangan ini bersifat sistemik. Apex Shortlist adalah kumpulan soal wawancara tingkat tinggi, V4-Pro unggul 12 poin persentase.
- Terminal-Bench 2.0 sedikit lemah: Ini adalah kemampuan penggunaan alat baris perintah multi-langkah. GPT-5.4 masih unggul di sini, menunjukkan bahwa GPT-5.4 memiliki keunggulan pada skenario "Agent kompleks multi-langkah".
2.2 Matematika dan Penalaran: deepseek-v4-pro Mendekati Batas Mutakhir
Dalam dimensi matematika, Pro dan raksasa closed-source "saling mengejar", tidak sepenuhnya memimpin:
| Benchmark | V4-Pro | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1-Pro |
|---|---|---|---|---|
| MMLU-Pro | 87.5 | 87.5 | 89.1 | 91.0 |
| IMOAnswerBench | 89.8 | 91.4 | 75.3 | 81.0 |
| HMMT 2026 | 95.2 | 97.7 | 96.2 | — |
| MATH | 92% | — | — | — |
| HumanEval | 90% | — | — | — |
| MMLU | 89% | — | — | — |
Sorotan pada IMOAnswerBench: Kumpulan soal Olimpiade Matematika Internasional, V4-Pro mencetak 89.8 poin, mengungguli Claude Opus 4.6 sebesar 14.5 poin, dan mengungguli Gemini 3.1-Pro sebesar 8.8 poin. Untuk tugas tingkat tinggi seperti penalaran matematika dan pembuktian formal, Pro adalah langit-langit untuk model open-source saat ini.
Kelemahan pada pengetahuan umum MMLU-Pro: Skor 87.5 Pro setara dengan GPT-5.4, namun tertinggal 3.5 poin dari Gemini 3.1-Pro yang mencapai 91.0. Gemini masih memiliki keunggulan tertentu dalam skenario tanya jawab pengetahuan umum.
2.3 Peta Medan Perang: Di mana deepseek-v4-pro Menang dan Kalah
| Medan Perang | Juara | Posisi V4-Pro |
|---|---|---|
| Pembuatan Kode (LiveCodeBench) | V4-Pro 🏆 | Juara |
| Pemrograman Kompetitif (Codeforces) | V4-Pro 🏆 | Juara |
| Wawancara Tingkat Tinggi (Apex) | V4-Pro 🏆 | Juara (Unggul jauh) |
| Rekayasa Perangkat Lunak (SWE-bench) | Seri | Seri pertama |
| Olimpiade Matematika (IMO) | GPT-5.4 | Kedua (Jauh di atas Claude/Gemini) |
| Pengetahuan Umum (MMLU-Pro) | Gemini 3.1-Pro | Ketiga |
| Rantai Alat Multi-langkah (Terminal-Bench) | GPT-5.4 | Kedua |
| Penalaran Konsistensi (HMMT) | GPT-5.4 | Ketiga |
Kesimpulan: Jika beban kerja Anda didominasi oleh kode, deepseek-v4-pro adalah salah satu pilihan terkuat di dunia saat ini (termasuk open-source dan closed-source). Jika didominasi oleh rantai alat Agent multi-langkah, GPT-5.4 masih memiliki keunggulan tipis; jika didominasi oleh tanya jawab pengetahuan umum, Gemini 3.1-Pro lebih kuat.
🎯 Saran Pemilihan: Kami menyarankan Anda untuk menjalankan serangkaian perbandingan AB antara V4-Pro vs model yang ada menggunakan petunjuk bisnis tipikal Anda di APIYI apiyi.com (20–50 baris sudah cukup). Jangan percaya begitu saja pada Benchmark publik untuk menentukan pilihan—distribusi petunjuk Anda sendiri adalah Benchmark yang sebenarnya. Untuk menjalankan perbandingan AB dalam jumlah besar, disarankan menggunakan jalur konkurensi tinggi
vip.apiyi.com.
III. 5 Menit untuk Memanggil deepseek-v4-pro di APIYI apiyi.com
3.1 Langkah 1: Ambil Kunci dan Pilih Jalur
Lingkungan prasyarat: Python 3.8+ atau Node.js 18+, pilih salah satu antara SDK OpenAI resmi atau SDK Anthropic.
Ambil Kunci:
- Kunjungi APIYI
apiyi.com, buka Dasbor → API Keys → Buat kunci baru. - Disarankan untuk mengatur kuota harian terpisah untuk kunci Pro (¥200–500, tergantung skala bisnis Anda).
- Salin kunci yang diawali dengan
sk-.
Pilih Jalur (tiga jalur berbagi satu kunci yang sama):
| base_url | Penggunaan |
|---|---|
https://api.apiyi.com/v1 |
Pemanggilan harian, skenario interaktif |
https://vip.apiyi.com/v1 |
Tugas batch, konkurensi tinggi |
https://b.apiyi.com/v1 |
Cadangan saat situs utama mengalami gangguan |
3.2 Langkah 2: Pemanggilan Minimal Python (Non-Thinking)
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "Anda adalah seorang insinyur Python senior."},
{"role": "user", "content": "Tulis cache LRU yang siap produksi dalam 30 baris."},
],
max_tokens=2048,
)
print(resp.choices[0].message.content)
Ubah dua bagian: base_url dan model — kode SDK OpenAI lainnya tidak perlu diubah.
3.3 Langkah 3: Mengaktifkan Mode Penalaran Thinking (Keunggulan Utama Pro)
Nilai sebenarnya dari deepseek-v4-pro baru akan terasa sepenuhnya dalam mode Thinking. Benchmark seperti IMOAnswerBench 89.8 dan LiveCodeBench 93.5 semuanya diukur dalam mode Thinking.
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": """
Tolong implementasikan pembatas laju (rate limiter) token bucket yang aman untuk konkurensi, dengan syarat:
1. Mendukung penyesuaian laju dinamis
2. Mendukung cadangan lalu lintas lonjakan
3. Implementasi tanpa kunci (CAS atau operasi atomik)
4. Menyertakan pengujian unit yang lengkap
"""},
],
extra_body={
"reasoning": {"enabled": True, "effort": "high"},
},
max_tokens=16384,
)
print("--- Proses Penalaran ---")
print(resp.choices[0].message.reasoning_content)
print("\n--- Jawaban Akhir ---")
print(resp.choices[0].message.content)
Saat effort=high, Pro akan melakukan perencanaan yang sangat mendalam—Anda akan melihatnya menganalisis kebutuhan, merancang API, mendiskusikan berbagai skema implementasi, dan akhirnya memberikan kode. Inilah alasan mengapa deepseek-v4-pro layak dibayar lebih dibandingkan versi Flash.
3.4 Langkah 4: Skenario Perbaikan Kode di Dunia Nyata
Skenario bisnis nyata: Meminta Pro memperbaiki bug.
buggy_code = """
def find_kth_largest(nums, k):
nums.sort()
return nums[k] # BUG di sini
"""
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "system", "content": "Anda adalah peninjau kode senior. Identifikasi bug, jelaskan akar penyebabnya, dan berikan kode yang sudah diperbaiki."},
{"role": "user", "content": f"Tinjau kode ini:\n```python\n{buggy_code}\n```"},
],
extra_body={"reasoning": {"enabled": True}},
max_tokens=4096,
)
print(resp.choices[0].message.content)
Pro akan menunjukkan: indeks seharusnya -k (setelah diurutkan, elemen terbesar ke-k berada di posisi ke-k dari belakang), serta memberikan perbaikan + penanganan kondisi batas (k <= 0, k > len(nums)) + kasus uji.
Data SWE-bench 80%+ adalah pengalaman nyata yang akan Anda rasakan dalam skenario ini.
3.5 Langkah 5: Function Calling / Penggunaan Alat
Pro sangat stabil dalam pemanggilan alat tunggal, meskipun rantai alat multi-langkah sedikit di bawah GPT-5.4, namun tetap memimpin di atas Claude:
tools = [
{
"type": "function",
"function": {
"name": "run_sql",
"description": "Jalankan kueri SQL khusus baca pada DB analitik.",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "SQL khusus SELECT"},
},
"required": ["query"],
},
},
},
]
resp = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": "5 kota dengan DAU tertinggi dalam 30 hari terakhir?"},
],
tools=tools,
tool_choice="auto",
)
print(resp.choices[0].message.tool_calls)
3.6 Langkah 6: Protokol Anthropic (Menghubungkan Claude Code ke Pro)
Jalur ini adalah nilai dari deepseek-v4-pro yang paling sering diremehkan: Anda dapat mengganti model dasar semua proyek SDK Claude / Claude Code Anda yang sudah ada ke V4-Pro tanpa mengubah kode bisnis apa pun.
from anthropic import Anthropic
client = Anthropic(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com", # Perhatikan, tanpa /v1
)
resp = client.messages.create(
model="deepseek-v4-pro",
max_tokens=4096,
messages=[
{"role": "user", "content": "Refaktorkan kode Python ini ke gaya async/await..."},
],
)
print(resp.content[0].text)
Terminal Claude Code: Dalam konfigurasi, atur ANTHROPIC_BASE_URL=https://api.apiyi.com + ANTHROPIC_API_KEY=sk-... + ubah model menjadi deepseek-v4-pro, Anda akan langsung mendapatkan Agen terminal dengan kemampuan koding yang unggul.
3.7 Langkah 7: Menghubungkan deepseek-v4-pro di Cursor
Buka Settings → Models → Custom OpenAI-Compatible di Cursor:
- Base URL:
https://api.apiyi.com/v1 - API Key:
sk-... - Model Name:
deepseek-v4-pro
Setelah selesai, ketiga pintu masuk Cursor (Chat / Cmd+K / Composer) akan menggunakan V4-Pro, dan kualitas pelengkapan kode serta refaktorisasi akan meningkat secara signifikan.
🎯 Saran Integrasi IDE: Alat pemrograman AI arus utama seperti Cursor, Windsurf, Cline, dan Continue semuanya kompatibel dengan protokol OpenAI. Cukup arahkan
base_urlke APIYIapi.apiyi.com/v1dan ubah model menjadideepseek-v4-prountuk migrasi tanpa hambatan. Contoh konfigurasi IDE yang mendetail dapat dilihat di kolom DeepSeek V4 pada dokumentasi resmi APIYIdocs.apiyi.com.
IV. Kapan Harus Memilih deepseek-v4-pro dan Kapan Tidak
4.1 Kondisi Keputusan Memilih Pro
✅ Pilih langsung deepseek-v4-pro untuk skenario berikut:
| Skenario | Mengapa |
|---|---|
| Pembuatan, refaktorisasi, peninjauan kode | Juara LiveCodeBench 93.5 |
| Pemrograman kompetitif, latihan soal algoritma | Setara level IGM Codeforces 3206 |
| Jawaban massal soal wawancara | Apex Shortlist 90.2, memimpin jauh |
| Penalaran matematika, pembuktian formal | IMOAnswerBench 89.8, memimpin 14 poin dari Claude |
| Pemahaman repositori besar | 1M jendela konteks + 49B aktivasi |
| Penulisan dan penyuntingan teks panjang | 384K output dalam sekali jalan |
| Deployment lokal / pelatihan ulang | Bobot sumber terbuka + modul Engram untuk fine-tuning |
| Mengganti model dasar Cursor / Claude Code | Akses tanpa modifikasi melalui protokol Anthropic |
4.2 Situasi Tidak Perlu Memilih Pro
❌ Jangan buang daya komputasi Pro untuk skenario berikut:
| Skenario | Saran |
|---|---|
| Percakapan harian, FAQ | Gunakan Flash (hemat 12x lipat) |
| Klasifikasi, ekstraksi teks pendek | Gunakan Flash atau model yang lebih kecil |
| Rantai alat Agen kompleks multi-langkah | Prioritaskan GPT-5.4 (memimpin di Terminal-Bench) |
| Terutama untuk tanya jawab pengetahuan umum | Gemini 3.1-Pro lebih kuat |
| Interaksi daring yang sensitif terhadap latensi | Gunakan Flash (mode Non-Thinking) atau tambahkan cache |
4.3 Saran Perutean Campuran
Solusi terbaik untuk lingkungan produksi biasanya adalah perutean berlapis:
def pick_model(request_type: str, complexity: str) -> str:
# Pekerjaan berat terkait kode → Pro
if request_type in ("code_gen", "code_review", "refactor") and complexity == "hard":
return "deepseek-v4-pro"
# Penalaran matematika → Pro
if request_type in ("math_proof", "competitive_programming"):
return "deepseek-v4-pro"
# Pemahaman mendalam dokumen panjang → Pro
if request_type == "long_doc_analysis":
return "deepseek-v4-pro"
# Lainnya harian → Flash
return "deepseek-v4-flash"
Di APIYI apiyi.com, kedua model ini berbagi satu kunci yang sama, peralihan hanya perlu mengubah kolom model, tanpa mengubah konfigurasi lainnya.
V. FAQ Pertanyaan Umum deepseek-v4-pro
Q1: Mengapa kemampuan coding Pro begitu kuat?
Ada tiga alasan utama yang saling mendukung:
- Pre-training 32T tokens mencakup korpus kode berkualitas tinggi dalam jumlah besar.
- 1.6T MoE / 49B aktivasi memungkinkan pengetahuan kode tersimpan dengan baik dan dapat dipanggil secara efisien.
- Mode Thinking + Engram Memory memisahkan "mengingat paradigma kode" dengan "penalaran kode baru".
Ketiga hal ini tidak akan mencapai skor LiveCodeBench 93.5 jika dilakukan secara terpisah; kombinasi ketiganya lah yang membuatnya unggul.
Q2: Apakah parameter 1.6T akan membuat respons menjadi lambat?
Kecepatan respons ditentukan oleh parameter aktivasi, bukan total parameter. Pro hanya mengaktifkan 49B per token. Ditambah dengan optimasi FLOPs dari Hybrid Attention, latensi token pertama hampir setara dengan Flash. Mode Thinking memang akan sedikit lebih lambat (karena harus mengeluarkan proses penalaran), namun ini adalah kompromi desain—Anda membayar waktu demi kualitas penalaran.
Q3: Apakah mode Thinking wajib diaktifkan?
Tidak wajib. Untuk percakapan biasa, kode sederhana, dan tanya jawab sehari-hari, Anda bisa mematikannya. Namun, sebagian besar nilai dari harga Pro yang Anda bayar terletak pada mode Thinking—untuk kode kompleks, soal matematika, dan penalaran logis bertahap, pastikan untuk mengaktifkan reasoning.enabled=true + effort=high.
Q4: Bagaimana cara menggunakannya di Cursor / Claude Code?
- Cursor: Settings → Models → Custom OpenAI-Compatible, isi Base URL dengan
https://api.apiyi.com/v1, dan Model dengandeepseek-v4-pro. - Claude Code: Gunakan variabel lingkungan
ANTHROPIC_BASE_URL=https://api.apiyi.com+ANTHROPIC_API_KEY=sk-..., lalu tentukan modeldeepseek-v4-prosaat memulai.
Langkah-langkah tangkapan layar yang mendetail dapat ditemukan di kolom integrasi IDE pada docs.apiyi.com.
Q5: Dibandingkan dengan GPT-5.4, mana yang lebih layak?
Jika harus memilih salah satu:
- Kode harian / Kompetisi / Matematika / Sensitif terhadap biaya → deepseek-v4-pro (Juara coding, harga 1/7).
- Agent alur kerja bertahap / Tanya jawab pengetahuan umum → GPT-5.4.
- Penggunaan campuran adalah solusi terbaik (menggunakan satu kunci API yang sama dari APIYI apiyi.com untuk berpindah antar model).
Q6: Apakah bisa di-deploy secara lokal?
Bisa, V4-Pro telah membuka bobot lengkapnya di Hugging Face (deepseek-ai/DeepSeek-V4-Pro). Namun, persyaratan deployment mandiri adalah:
- Perangkat tunggal ≥ 8×H200 atau GPU yang setara.
- Memerlukan cache KV tambahan untuk konteks 1M (meskipun Pro telah menekan cache hingga 10% dari V3.2).
- Biaya rekayasa untuk memelihara layanan inferensi.
Estimasi biaya: Kecuali volume panggilan bulanan Anda melebihi 50 miliar token, menggunakan layanan hosting dari APIYI apiyi.com jauh lebih ekonomis daripada deployment mandiri.
Q7: Berapa batas konkurensi maksimum?
Saran untuk lingkungan produksi:
- Situs utama
api.apiyi.com: Aman untuk 50 konkurensi. - Jalur konkurensi tinggi
vip.apiyi.com: 200+ konkurensi. - Cadangan
b.apiyi.com: Otomatis fallback saat jalur utama mengalami gangguan.
Pro memiliki latensi yang lebih tinggi untuk tugas Thinking yang kompleks, jadi konkurensi yang tinggi tidak selalu lebih baik—lebih tepat untuk mengestimasi jendela konkurensi yang diperlukan berdasarkan QPS × rata-rata waktu respons.
Q8: Apakah versi resmi Pro akan segera dirilis?
Versi yang dirilis pada 24-04-2026 adalah versi pratinjau (Preview). Mengikuti ritme DeepSeek sebelumnya, versi resmi biasanya dirilis 1–2 bulan setelah pratinjau dan mungkin akan ada peningkatan Benchmark kecil. Menggunakan versi pratinjau di APIYI apiyi.com saat ini tidak masalah—ID model kemungkinan besar akan tetap deepseek-v4-pro di versi resmi, sehingga kompatibel ke belakang.
VI. Kesimpulan Peluncuran deepseek-v4-pro
Jika Anda melewatkan bagian tengah dan langsung ke kesimpulan, inilah intinya:
- ✅ deepseek-v4-pro adalah model open-source dengan kemampuan coding terkuat saat ini—mengalahkan GPT-5.4 / Claude Opus 4.6 / Gemini 3.1-Pro dalam tiga Benchmark keras: LiveCodeBench / Codeforces / Apex.
- ✅ Empat inovasi arsitektur (Hybrid Attention / mHC / Engram Memory / Muon) menjadikannya bukan sekadar "Model Bahasa Besar biasa", melainkan spesies baru setelah penulisan ulang infrastruktur.
- ✅ 1.6T / 49B MoE + pre-training 32T tokens + konteks 1M mencapai batas atas open-source dalam hal skala.
- ✅ Telah tersedia di APIYI apiyi.com, kompatibel dengan protokol ganda OpenAI + Anthropic, tanpa perlu modifikasi untuk alat utama seperti Cursor / Claude Code / Cline.
- ✅ Harga hanya 1/7 dari GPT-5.4, dan mode Thinking adalah keunggulan utamanya.
Bagi tim pengembang yang berfokus pada kode, deepseek-v4-pro layak untuk segera diuji—ini bukan sekadar "alternatif yang lebih murah", tetapi model unggulan yang berpotensi menjadi standar baru.
🎯 Saran Tindakan: Disarankan untuk mengajukan satu kunci API dari APIYI
apiyi.comhari ini (khusus untuk Pro, atur kuota harian ¥200–500). Jalankan 20 petunjuk kode / matematika / teks panjang yang paling mewakili bisnis Anda, lalu lakukan perbandingan AB antara V4-Pro (mode Thinking) dengan model utama Anda saat ini. Jika kualitas tugas coding meningkat secara signifikan, pindahkan model default di Cursor / Claude Code Anda; jika memerlukan model murah untuk penggunaan harian, tambahkan V4-Flash (lihat panduan migrasi sebelumnya). Gunakanvip.apiyi.comsaat menjalankan tes batch, danb.apiyi.comakan otomatis fallback jika situs utama mengalami gangguan. Contoh integrasi lengkap, konfigurasi IDE, dan skrip replikasi Benchmark dapat ditemukan didocs.apiyi.com.
Signifikansi deepseek-v4-pro melampaui sekadar "model SOTA murah lainnya". Ini menandai pertama kalinya model open-source menekan model unggulan closed-source secara menyeluruh dalam kemampuan inti coding—hal ini sendiri layak diuji secara serius oleh setiap tim yang menangani rekayasa AI.
Penulis: Tim Teknis APIYI
Sumber Terkait:
- Pengumuman Resmi DeepSeek: api-docs.deepseek.com/news/news260424
- Repositori Open-source Hugging Face: huggingface.co/deepseek-ai/DeepSeek-V4-Pro
- Situs Resmi APIYI: apiyi.com
- Dokumentasi APIYI: docs.apiyi.com
- Situs Utama APIYI: api.apiyi.com (Cadangan vip.apiyi.com / b.apiyi.com)