Pada tahun 2026, 41% dari commit kode sudah dihasilkan dengan bantuan AI—namun tingkat cacat pada kode buatan AI 1,7 kali lebih tinggi dibandingkan kode buatan manusia. Kecepatan pembuatan kode terus meningkat, tetapi kapasitas untuk melakukan peninjauan kode (code review) sangat tertinggal, dengan kesenjangan kualitas yang diprediksi mencapai 40% pada tahun 2026.
Peninjauan kode oleh AI bukan lagi soal "perlu atau tidak", melainkan soal "bagaimana melakukannya dengan benar". Artikel ini akan membahas 7 praktik terbaik yang telah teruji, serta analisis mendalam mengapa Claude Opus 4.6 dan Sonnet 4.6 menjadi model AI yang paling mumpuni untuk peninjauan kode saat ini.
Nilai Inti: Setelah membaca artikel ini, Anda akan menguasai alur kerja peninjauan kode AI yang lengkap dan memahami cara memilih model yang paling tepat untuk meningkatkan kualitas kode tim Anda.
Status Quo Tinjauan Kode AI: Mengapa Ini Harus Menjadi Prioritas Sekarang
Tantangan Tinjauan Kode Tahun 2026
| Tantangan | Data | Dampak |
|---|---|---|
| Lonjakan Kode AI | 41% commit dihasilkan dengan bantuan AI | Kebutuhan tinjauan melonjak |
| Tingkat Cacat Kode AI | 1,7x lebih tinggi dibanding kode manusia | Perlu tinjauan yang lebih ketat |
| Kesenjangan Kualitas | Diprediksi mencapai 40% pada 2026 | Kapasitas tinjauan tidak mengejar kecepatan produksi |
| Risiko Keamanan | 45% kode AI mengandung kerentanan OWASP Top 10 | Tinjauan keamanan menjadi sangat mendesak |
| Tingkat Adopsi Saran | Saran AI hanya 16,6%, saran manusia 56,5% | Kualitas tinjauan AI perlu ditingkatkan |
Tinjauan Kode AI vs Tinjauan Kode Manusia
AI tidak hadir untuk menggantikan peninjau manusia, melainkan untuk meningkatkan kemampuan tinjauan manusia. Tim yang menggunakan tinjauan kode AI melaporkan:
- Waktu tinjauan berkurang 40-60%
- Peningkatan deteksi cacat—terutama untuk kerentanan keamanan dan kondisi batas (boundary conditions)
- Konsistensi gaya kode meningkat drastis
Namun, tinjauan AI memiliki batasan yang jelas:
- ❌ Tidak dapat memahami tenggat waktu bisnis dan konteks proyek
- ❌ Tidak dapat merasakan kompromi historis pada sistem warisan (legacy)
- ❌ Tidak dapat memikul tanggung jawab akhir atas tinjauan
- ❌ Tidak dapat melakukan transfer pengetahuan tim dan bimbingan (mentoring)
🎯 Strategi Terbaik: Gunakan AI untuk pemindaian tahap pertama (gaya, bug, keamanan), dan manusia untuk keputusan akhir (arsitektur, niat, risiko). Melalui platform APIYI (apiyi.com), Anda dapat memanggil API Claude Opus 4.6 atau Sonnet 4.6 untuk mengintegrasikan tinjauan kode AI ke dalam alur kerja CI/CD yang sudah ada dengan cepat.
7 Praktik Terbaik Tinjauan Kode AI
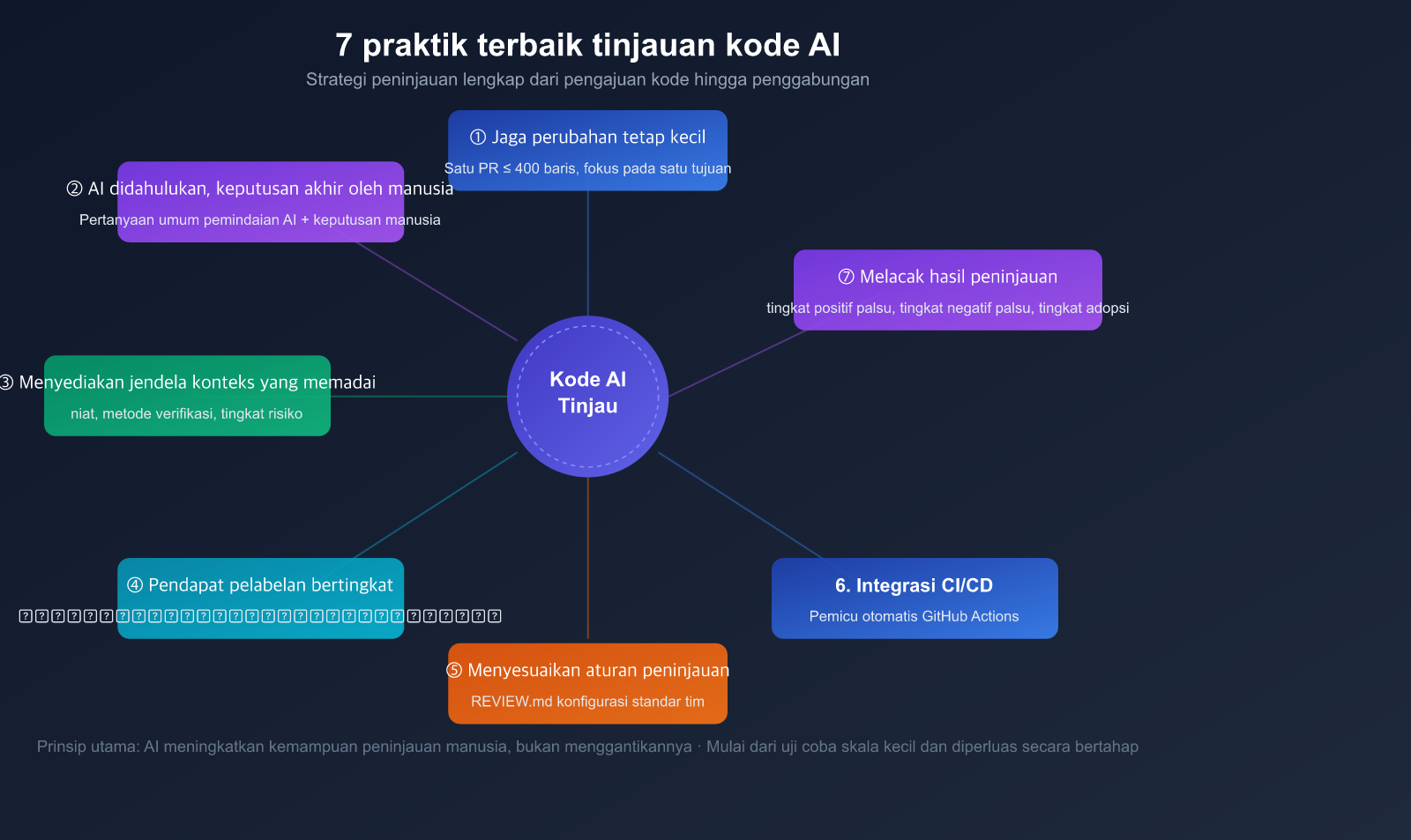
Praktik 1: Jaga Perubahan Tetap Kecil dan Fokus
Peninjau AI akan kehilangan koherensi secara signifikan setelah diff melebihi 1000 baris. Meskipun Claude Opus 4.6 memiliki jendela konteks 1 juta token, kualitas tinjauan untuk perubahan besar tetap tidak sebaik perubahan kecil.
Langkah konkret:
- Batasi setiap PR dalam rentang 200-400 baris
- Pecah refaktorisasi besar menjadi beberapa PR yang logis dan independen
- Pastikan setiap PR hanya melakukan satu hal
Praktik 2: AI Terlebih Dahulu, Manusia sebagai Penentu Akhir
Alur kerja yang paling efektif adalah model "tinjauan dua lapis":
Commit Kode → Tinjauan Otomatis AI (Tahap Pertama)
↓
Tandai masalah + Klasifikasi tingkat keparahan
↓
Peninjau manusia fokus pada area berisiko tinggi (Keputusan Akhir)
↓
Gabungkan (Merge) atau Tolak
AI bertanggung jawab memindai semua masalah rutin (gaya, penamaan, kode mati, bug sederhana), sementara manusia fokus pada:
- Rasionalitas arsitektur
- Kebenaran logika bisnis
- Keputusan kritis keamanan
- Evaluasi dampak performa
Praktik 3: Berikan Konteks yang Cukup
Semakin banyak informasi yang diberikan kepada peninjau AI, semakin tinggi kualitas tinjauannya. Disarankan untuk menyertakan hal berikut dalam deskripsi PR:
# Deskripsi PR
- Tujuan: (Apa masalah yang diselesaikan?)
- Konteks: (Tautan ke tiket Jira/GitHub)
- Area Risiko: (Bagian mana yang paling sensitif?)
- Perubahan Utama: (Ringkasan perubahan arsitektur)
Tujuan Perubahan
Jelaskan "mengapa perubahan ini dilakukan" dalam 1-2 kalimat singkat.
Metode Verifikasi
- Pengujian unit berhasil dilewati
- Telah melakukan pengujian manual pada skenario XX
- Tidak ada penurunan performa
Tingkat Risiko
Rendah/Sedang/Tinggi + Penjelasan
Pernyataan Bantuan AI
Pada perubahan kali ini, bagian XX dihasilkan oleh AI, mohon untuk diperiksa dengan saksama.
Area Fokus Manual
Harap berikan perhatian khusus pada perubahan logika otorisasi di direktori src/auth/.
### Praktik 4: Penandaan Tingkat Keparahan untuk Ulasan
Masalah umum dalam ulasan AI adalah "terlalu banyak kebisingan"—mencampur saran gaya dengan bug serius, yang menyebabkan pengembang mengabaikan umpan balik penting.
**Tingkat keparahan yang disarankan**:
| Penanda | Arti | Cara Penanganan |
|------|------|----------|
| 🔴 **Bug** | Cacat yang harus diperbaiki sebelum merge | Memblokir merge |
| 🟡 **Nit** | Masalah kecil yang layak diperbaiki tapi tidak memblokir | Perbaikan opsional |
| 🟣 **Pre-existing** | Masalah lama yang bukan disebabkan oleh perubahan ini | Dicatat tapi tidak memblokir |
| 💡 **Suggestion** | Saran perbaikan | Diputuskan setelah diskusi |
Fitur ulasan kode bawaan Claude Code telah mengimplementasikan sistem tingkatan ini (Merah/Kuning/Ungu).
### Praktik 5: Menyesuaikan Aturan Ulasan
Ulasan AI umum mungkin tidak sesuai dengan standar tim Anda. Sesuaikan perilaku ulasan melalui file konfigurasi:
```markdown
# REVIEW.md (diletakkan di direktori root proyek)
## Wajib Diperiksa
- Semua kueri basis data harus menggunakan pernyataan terparameter
- Endpoint API harus menyertakan middleware otentikasi
- Semua input pengguna harus divalidasi
Bisa dilewati
- Gaya penamaan kelas CSS (sudah diformat otomatis oleh prettier)
- Pengurutan import (sudah ditangani otomatis oleh ruff)
- Bahasa komentar (bisa bahasa Mandarin atau Inggris)
Perjanjian Tim
- Prioritaskan komposisi daripada pewarisan (inheritance)
- Penanganan error menggunakan pola Result
- Level log: INFO untuk peristiwa bisnis, DEBUG untuk debugging
### Praktik 6: Integrasi ke Pipeline CI/CD
Tinjauan kode AI harus bersifat otomatis, bukan dipicu secara manual.
**Cara integrasi yang direkomendasikan**:
```yaml
# Contoh GitHub Actions
name: AI Code Review
on:
pull_request:
types: [opened, synchronize]
jobs:
ai-review:
runs-on: ubuntu-latest
steps:
- uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
review_mode: "auto"
Anda juga bisa melakukan pemanggilan model Claude secara langsung melalui API untuk tinjauan kustom:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Antarmuka terpadu APIYI
)
diff_content = open("pr_diff.patch").read()
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": """Anda adalah pakar tinjauan kode senior.
Silakan analisis perubahan kode berikut, klasifikasikan berdasarkan tingkat keparahan:
- 🔴 Bug: Harus diperbaiki
- 🟡 Nit: Disarankan untuk diperbaiki
- 💡 Suggestion: Saran perbaikan
Tunjukkan nomor baris spesifik dan solusi perbaikan untuk setiap masalah."""},
{"role": "user", "content": f"Silakan tinjau perubahan kode berikut:\n\n{diff_content}"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Praktik 7: Melacak Efektivitas Tinjauan
Tinjauan kode AI tidak berhenti setelah diterapkan. Anda perlu terus melacak metrik utama:
- Tingkat Positif Palsu (False Positive Rate): Berapa banyak masalah yang ditandai AI adalah masalah nyata
- Tingkat Negatif Palsu (False Negative Rate): Berapa banyak bug yang ditemukan setelah rilis yang tidak terdeteksi oleh AI
- Tingkat Adopsi: Proporsi saran AI yang benar-benar diterima oleh pengembang
- Perubahan Waktu Tinjauan: Apakah rata-rata waktu tinjauan oleh manusia berkurang
💡 Saran Implementasi: Jika tim Anda baru mulai mencoba tinjauan kode AI, disarankan untuk memulai uji coba dari PR di jalur yang tidak kritis. Gunakan Claude Sonnet 4.6 melalui APIYI apiyi.com untuk eksperimen awal; biayanya hanya 1/5 dari Opus dengan kualitas tinjauan yang mendekati level Opus, menjadikannya solusi awal yang paling hemat biaya.
Mengapa Claude Opus 4.6 dan Sonnet 4.6 Direkomendasikan untuk Code Review
Di antara banyaknya Model Bahasa Besar yang tersedia, seri Claude 4.6 memiliki keunggulan unik untuk kebutuhan code review atau tinjauan kode.
Perbandingan Parameter Utama Model Claude 4.6
| Parameter | Claude Opus 4.6 | Claude Sonnet 4.6 |
|---|---|---|
| ID Model | claude-opus-4-6 |
claude-sonnet-4-6 |
| Tanggal Rilis | 5 Februari 2026 | 17 Februari 2026 |
| Jendela Konteks | 1 juta token (beta) | 1 juta token (beta) |
| Output Maksimum | 128K token | 64K token |
| SWE-bench Verified | 81,42% | 79,6% |
| Harga (Input/Output) | $5/$25 per juta token | $3/$15 per juta token |
| Skenario Penggunaan | Tinjauan arsitektur kompleks, audit keamanan | Tinjauan PR harian, pemeriksaan gaya kode |
| Harga APIYI | Lebih hemat | Lebih hemat |
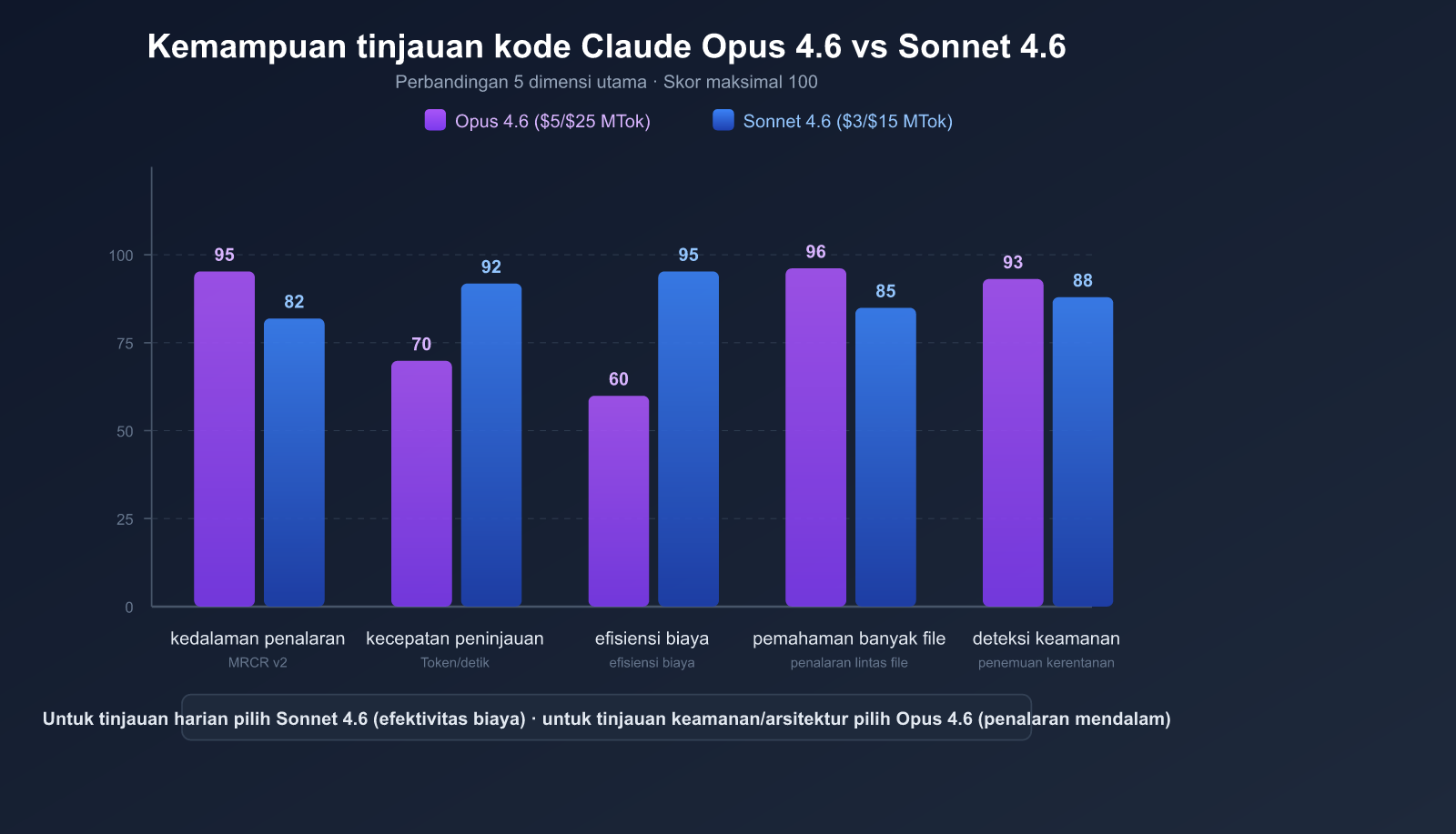
Keunggulan 1: Jendela Konteks 1 Juta Token
Ini adalah keunggulan teknis paling krusial untuk code review.
Satu pull request (PR) pada proyek besar bisa melibatkan puluhan file. Keterbatasan jendela konteks pada model AI tradisional memaksa Anda memotong kode, sehingga peninjau tidak bisa melihat konteks secara utuh.
Jendela konteks 1 juta token Claude 4.6 dapat menampung sekaligus:
- Diff PR lengkap (biasanya ratusan hingga ribuan baris)
- Seluruh kode file terkait (rantai impor, fungsi yang dipanggil)
- Diagram relasi dependensi dan definisi tipe
- File pengujian dan file konfigurasi
- README dan dokumentasi arsitektur proyek
Artinya, AI dapat melakukan tinjauan layaknya pengembang senior dengan pemahaman konteks yang menyeluruh.
Keunggulan 2: Kemampuan Penalaran Lintas File yang Unggul
Nilai utama dari code review bukan sekadar mencari kesalahan sintaks, melainkan menemukan masalah logika lintas file.
Claude Opus 4.6 mencetak skor 76% dalam tes MRCR (Multi-file Retrieval and Reasoning), jauh melampaui Sonnet 4.5 yang hanya 18,5%. Ini berarti Opus 4.6 sangat andal dalam skenario berikut:
- Mendeteksi jika file A mengubah antarmuka, tetapi panggilan di file B tidak diperbarui.
- Menemukan celah validasi pada alur data dari titik masuk hingga ke basis data.
- Mengidentifikasi kondisi balapan (race condition) dalam skenario konkuren.
Kasus nyata: Dalam pengujian, Claude Opus 4.6 menemukan race condition pada PR migrasi basis data sepanjang 2400 baris—sebuah cacat logika rollback yang hanya terpicu jika migrasi terputus di tengah jalan. Ini adalah skenario yang tidak bisa dijangkau oleh pengujian otomatis biasa.
Keunggulan 3: Kedalaman Berpikir Adaptif
Claude 4.6 memperkenalkan mode adaptive thinking—AI akan secara otomatis menentukan seberapa dalam ia harus "berpikir" berdasarkan kompleksitas masalah.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Antarmuka terpadu APIYI
)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": "Tinjau perubahan kode ini untuk masalah keamanan."},
{"role": "user", "content": diff_content}
],
# Penalaran adaptif Claude 4.6: masalah sederhana diproses cepat, masalah kompleks dianalisis mendalam
extra_body={"thinking": {"type": "adaptive"}}
)
- Masalah gaya kode sederhana → Keputusan cepat, menghemat token.
- Masalah konkurensi atau keamanan kompleks → Penalaran mendalam, memberikan analisis komprehensif.
Keunggulan 4: Deteksi Celah Keamanan Jauh Melampaui Alat Tradisional
Penelitian menunjukkan bahwa LLM setingkat Claude jauh lebih unggul dalam tinjauan kode keamanan dibandingkan alat analisis statis tradisional:
| Dimensi Perbandingan | Claude (LLM) | CodeQL (SAST Tradisional) |
|---|---|---|
| Jumlah Celah Terdeteksi | 55 | 27 |
| Penemuan Celah Baru | 4 celah zero-day | 0 |
| Kategori Deteksi | 10+ kategori (injeksi, otentikasi, kebocoran data, dll) | Berbasis pencocokan pola |
| Dukungan Bahasa | Bahasa pemrograman apa pun | Bahasa spesifik |
| Filter Positif Palsu | AI memfilter otomatis | Perlu filter manual |
Jenis celah keamanan yang dapat dideteksi Claude:
- Injeksi SQL/Perintah/LDAP/XPath/NoSQL
- Cacat otentikasi dan otorisasi
- Kunci hardcoded, log data sensitif
- Algoritma enkripsi lemah, manajemen kunci yang buruk
- Race condition (TOCTOU)
- Konfigurasi default tidak aman, CORS
- RCE deserialisasi, injeksi pickle/eval
- XSS (Reflected, Stored, DOM)
Keunggulan 5: Fleksibilitas Biaya
Harga Sonnet 4.6 hanya 1/5 dari Opus 4.6, namun performanya di SWE-bench hanya tertinggal 1-2 persen poin.
Strategi pemilihan model yang direkomendasikan:
| Skenario | Model yang Direkomendasikan | Alasan |
|---|---|---|
| Tinjauan PR harian | Sonnet 4.6 | Efektivitas biaya terbaik, kualitas mendekati Opus |
| Kode kritis keamanan | Opus 4.6 | Penalaran terdalam, tidak melewatkan masalah risiko tinggi |
| Tinjauan refaktor besar | Opus 4.6 | Kemampuan penalaran lintas file terbaik |
| Pemeriksaan gaya kode | Sonnet 4.6 | Tugas sederhana tidak memerlukan Opus |
| Tinjauan otomatis CI/CD | Sonnet 4.6 | Biaya terkontrol, cocok untuk setiap commit |
🚀 Saran pemilihan: Rekomendasi resmi Anthropic adalah "Gunakan Sonnet 4.6 sebagai default, dan tingkatkan ke Opus 4.6 hanya saat memerlukan penalaran terdalam". Dalam pengujian internal Claude Code, tingkat preferensi pengembang terhadap Sonnet 4.6 meningkat 70% dibanding generasi sebelumnya, bahkan 59% lebih tinggi dari model unggulan sebelumnya, Opus 4.5. Anda bisa menikmati harga yang lebih hemat dengan memanggil kedua model tersebut melalui APIYI (apiyi.com).
Alur Kerja Peninjauan Kode AI yang Lengkap
Gambaran Umum Alur Kerja
Pengembang mengirimkan PR
↓
AI memicu peninjauan otomatis (Sonnet 4.6)
↓
┌─── Perubahan risiko rendah ──→ AI menandai Nit, lolos otomatis
│
├─── Perubahan risiko sedang ──→ AI menandai masalah, konfirmasi manual cepat
│
└─── Perubahan risiko tinggi ──→ Eskalasi ke Opus 4.6 untuk peninjauan mendalam
↓
Tinjauan akhir manual oleh pakar keamanan
↓
Gabungkan atau tolak
Contoh Kode: Membangun Sistem Peninjauan AI Kustom
import openai
import subprocess
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Antarmuka terpadu APIYI
)
def get_pr_diff(pr_number):
"""Mendapatkan konten diff dari PR"""
result = subprocess.run(
["gh", "pr", "diff", str(pr_number)],
capture_output=True, text=True
)
return result.stdout
def review_code(diff, risk_level="medium"):
"""Memilih model untuk peninjauan berdasarkan tingkat risiko"""
model = "claude-opus-4-6" if risk_level == "high" else "claude-sonnet-4-6"
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"Tinjau perubahan berikut:\n\n{diff}"}
],
max_tokens=8192
)
return response.choices[0].message.content
# Contoh penggunaan
diff = get_pr_diff(123)
review = review_code(diff, risk_level="high")
print(review)
Lihat Templat Petunjuk Peninjauan Lengkap
REVIEW_PROMPT = """Anda adalah insinyur perangkat lunak senior yang berpengalaman dan sedang melakukan peninjauan kode.
## Fokus Peninjauan
1. **Kebenaran logika**: Apakah kode mengimplementasikan fungsi yang diharapkan? Apakah ada kondisi batas yang terlewat?
2. **Keamanan**: Apakah ada risiko keamanan seperti injeksi, XSS, CSRF, kunci API yang di-hardcode, dll.?
3. **Performa**: Apakah ada kueri N+1, alokasi memori yang tidak perlu, atau operasi pemblokiran?
4. **Pemeliharaan**: Apakah penamaan sudah jelas? Apakah kompleksitas terkendali? Apakah ada kode duplikat?
5. **Penanganan kesalahan**: Apakah pengecualian ditangkap dan ditangani dengan benar?
6. **Keamanan konkurensi**: Apakah ada risiko kondisi balapan (race condition) atau kebuntuan (deadlock)?
Format Output
Kategorikan output berdasarkan tingkat keparahan:
🔴 Harus Diperbaiki (Bug/Keamanan)
- [Nama file:Nomor baris] Deskripsi masalah
- Dampak: …
- Saran perbaikan: …
🟡 Saran Perbaikan (Nit)
- [Nama file:Nomor baris] Deskripsi masalah
- Saran: …
💡 Saran Peningkatan (Suggestion)
- [Nama file:Nomor baris] Poin peningkatan
- Penjelasan: …
Jika kualitas kode sudah baik dan tidak ditemukan masalah, harap nyatakan dengan jelas "Tinjauan selesai, tidak ditemukan masalah".
Jangan mengada-ada masalah yang tidak ada hanya demi memenuhi format output.
💰 Optimasi Biaya: Lakukan tinjauan kode menggunakan model Claude 4.6 melalui APIYI (apiyi.com) dengan harga yang lebih terjangkau dibandingkan harga resmi. Platform ini mendukung peralihan fleksibel antara Opus 4.6 dan Sonnet 4.6, sehingga Anda dapat memilih model yang paling hemat biaya berdasarkan tingkat risiko PR.
Keterbatasan dan Hal yang Perlu Diperhatikan dalam Tinjauan Kode AI
5 Keterbatasan yang Harus Diketahui
- Recall sekitar 50%: Kerentanan yang ditemukan oleh LLM biasanya akurat (presisi ~80%), namun sekitar setengah dari kerentanan yang ada kemungkinan terlewatkan.
- Risiko injeksi petunjuk: Alat tinjauan AI berisiko terkena injeksi saat memproses PR yang tidak tepercaya.
- Titik buta konteks: AI tidak dapat memahami latar belakang bisnis proyek, kemampuan anggota tim, dan keputusan historis.
- Akumulasi biaya: Jika tinjauan dipicu pada setiap commit, biaya untuk repositori dengan frekuensi tinggi bisa menjadi mahal.
- Risiko ketergantungan berlebih: Anggota tim mungkin secara bertahap mengurangi ketelitian dalam tinjauan manual.
Strategi Mitigasi
| Keterbatasan | Strategi Mitigasi |
|---|---|
| Tingkat deteksi rendah | Jaminan ganda: Tinjauan AI + Tinjauan manual |
| Injeksi petunjuk | Hanya tinjau PR dari sumber tepercaya |
| Konteks kurang | Sediakan latar belakang proyek di dalam REVIEW.md |
| Biaya tinggi | Gunakan Sonnet 4.6 untuk harian, Opus 4.6 untuk jalur kritis |
| Ketergantungan berlebih | Terapkan sistem "Saran AI + Keputusan manusia" |
Pertanyaan Umum
Q1: Bisakah peninjauan kode AI sepenuhnya menggantikan peninjauan manusia?
Tidak bisa. Peninjauan kode AI adalah "peningkatan" dan bukan "pengganti". AI sangat mahir dalam menemukan masalah berbasis pola (gaya penulisan, bug umum, pola kerentanan yang diketahui), tetapi tidak dapat memahami niat bisnis, pertimbangan di balik keputusan arsitektur, dan pengetahuan implisit dalam kolaborasi tim. Praktik terbaiknya adalah membiarkan AI melakukan pemindaian awal, lalu manusia yang membuat keputusan akhir. Anda dapat membangun alur kerja peninjauan AI dengan cepat melalui pemanggilan model Claude 4.6 di APIYI apiyi.com, sehingga peninjau manusia bisa fokus pada pekerjaan yang bernilai lebih tinggi.
Q2: Pilih Opus 4.6 atau Sonnet 4.6 untuk peninjauan kode?
Untuk sebagian besar skenario, pilih Sonnet 4.6. Skornya di SWE-bench hanya terpaut 1-2 persen di bawah Opus, namun biayanya hanya 1/5. Anda hanya perlu beralih ke Opus 4.6 saat meninjau kode yang kritis terhadap keamanan, melakukan perombakan arsitektur skala besar, atau saat membutuhkan penalaran mendalam lintas file. Melalui APIYI apiyi.com, Anda dapat beralih antar model secara fleksibel sesuai kebutuhan.
Q3: Berapa perkiraan biaya peninjauan kode AI?
Fitur peninjauan bawaan Claude Code rata-rata memakan biaya $15-25 per sesi, tergantung pada ukuran PR dan kompleksitas basis kode. Jika Anda membangun sistem peninjauan sendiri melalui API, biayanya bergantung pada konsumsi token. Sebagai contoh, dengan Sonnet 4.6, meninjau PR sepanjang 500 baris (sekitar 2000 token input + 1000 token output) hanya memakan biaya sekitar $0,02. Anda bahkan bisa mendapatkan harga yang lebih kompetitif melalui APIYI apiyi.com.
Q4: Bagaimana cara mengevaluasi efektivitas peninjauan kode AI?
Disarankan untuk melacak 4 metrik utama: (1) Tingkat positif palsu—proporsi masalah nyata di antara masalah yang ditandai AI; (2) Tingkat deteksi yang terlewat—proporsi bug yang ditemukan setelah rilis yang tidak ditandai oleh AI; (3) Tingkat adopsi—proporsi saran AI yang benar-benar diterima oleh pengembang; (4) Perubahan waktu peninjauan—apakah rata-rata waktu peninjauan manusia berkurang. Selama dua bulan pertama, disarankan untuk melakukan evaluasi mingguan.
Q5: Bagaimana cara cepat untuk mulai mencoba peninjauan kode AI?
Cara termudah adalah dengan tiga langkah: (1) Daftar dan dapatkan kunci API melalui APIYI apiyi.com; (2) Lakukan uji peninjauan pada PR terbaru menggunakan Sonnet 4.6; (3) Tentukan apakah akan mengintegrasikannya ke dalam otomatisasi CI/CD berdasarkan hasilnya. Mulailah dari kode yang tidak kritis sebagai percontohan, lalu kembangkan secara bertahap ke seluruh sistem.
Kesimpulan: Peninjauan Kode AI adalah Pengganda Efisiensi Tim
Peninjauan kode AI bukanlah pilihan, melainkan kemampuan wajib bagi tim pengembangan perangkat lunak di tahun 2026. Claude Opus 4.6 dan Sonnet 4.6, dengan jendela konteks 1 juta token, skor SWE-bench 81%+, penalaran adaptif, dan kemampuan deteksi keamanan yang kuat, adalah pilihan terbaik saat ini untuk skenario peninjauan kode.
Saran Pemilihan:
- Peninjauan Harian: Gunakan Sonnet 4.6 sebagai standar, rajanya efisiensi biaya.
- Peninjauan Keamanan/Arsitektur: Tingkatkan ke Opus 4.6 untuk kedalaman penalaran tanpa kompromi.
Direkomendasikan untuk mengakses rangkaian lengkap model Claude 4.6 dengan cepat melalui APIYI apiyi.com guna membangun kemampuan peninjauan kode AI bagi tim Anda dengan biaya yang optimal.
Referensi
-
Resmi Anthropic: Pengumuman rilis Claude Opus 4.6 dan Sonnet 4.6
- Tautan:
anthropic.com/news
- Tautan:
-
Dokumentasi Tinjauan Kode Claude Code: Panduan penggunaan fitur tinjauan bawaan
- Tautan:
code.claude.com/docs/en/code-review
- Tautan:
-
Tinjauan Keamanan Claude Code: GitHub Action tinjauan keamanan sumber terbuka
- Tautan:
github.com/anthropics/claude-code-security-review
- Tautan:
-
Praktik Terbaik Tinjauan Kode AI 2026: Analisis komprehensif industri
- Tautan:
verdent.ai/guides
- Tautan:
-
Makalah Penelitian IRIS: Deteksi kerentanan analisis statis berbantuan Model Bahasa Besar
- Tautan:
arxiv.org
- Tautan:
Penulis: Tim APIYI | Menjelajahi praktik terbaik pengembangan perangkat lunak berbasis AI. Kunjungi APIYI di apiyi.com untuk mendapatkan akses API dan dukungan teknis untuk seluruh seri model Claude 4.6.