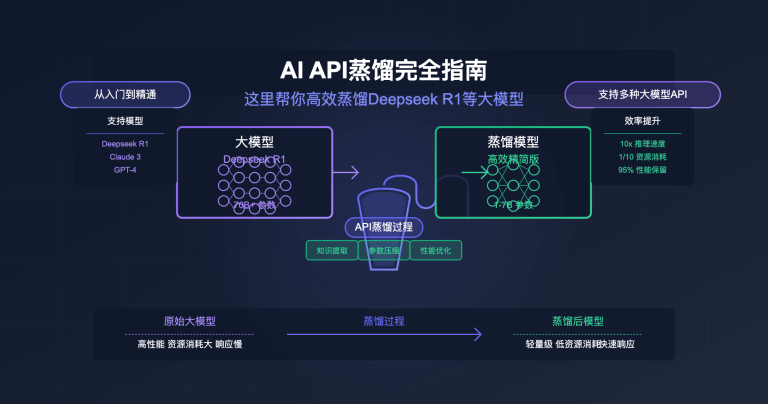
站长注:深度解析DeepSeek R1-0528官方64K与第三方128K上下文长度差异,掌握长文档处理优势
根据DeepSeek官方2025年5月28日发布的最新公告,DeepSeek R1-0528在官方平台的上下文长度限制为64K,但第三方平台可以提供128K的开源版本。这意味着选择合适的平台,你能获得双倍的上下文处理能力,处理更长的文档、更复杂的推理任务。
💡 实践建议:文章涉及的128K上下文长度优势可以在 API易 免费试用(送 1.1 美金起)
128K上下文长度 背景介绍
在DeepSeek R1-0528的更新中,官方明确提到了一个重要的技术细节:上下文长度的平台差异化。这个看似简单的数字背后,实际上隐藏着巨大的应用价值差异。
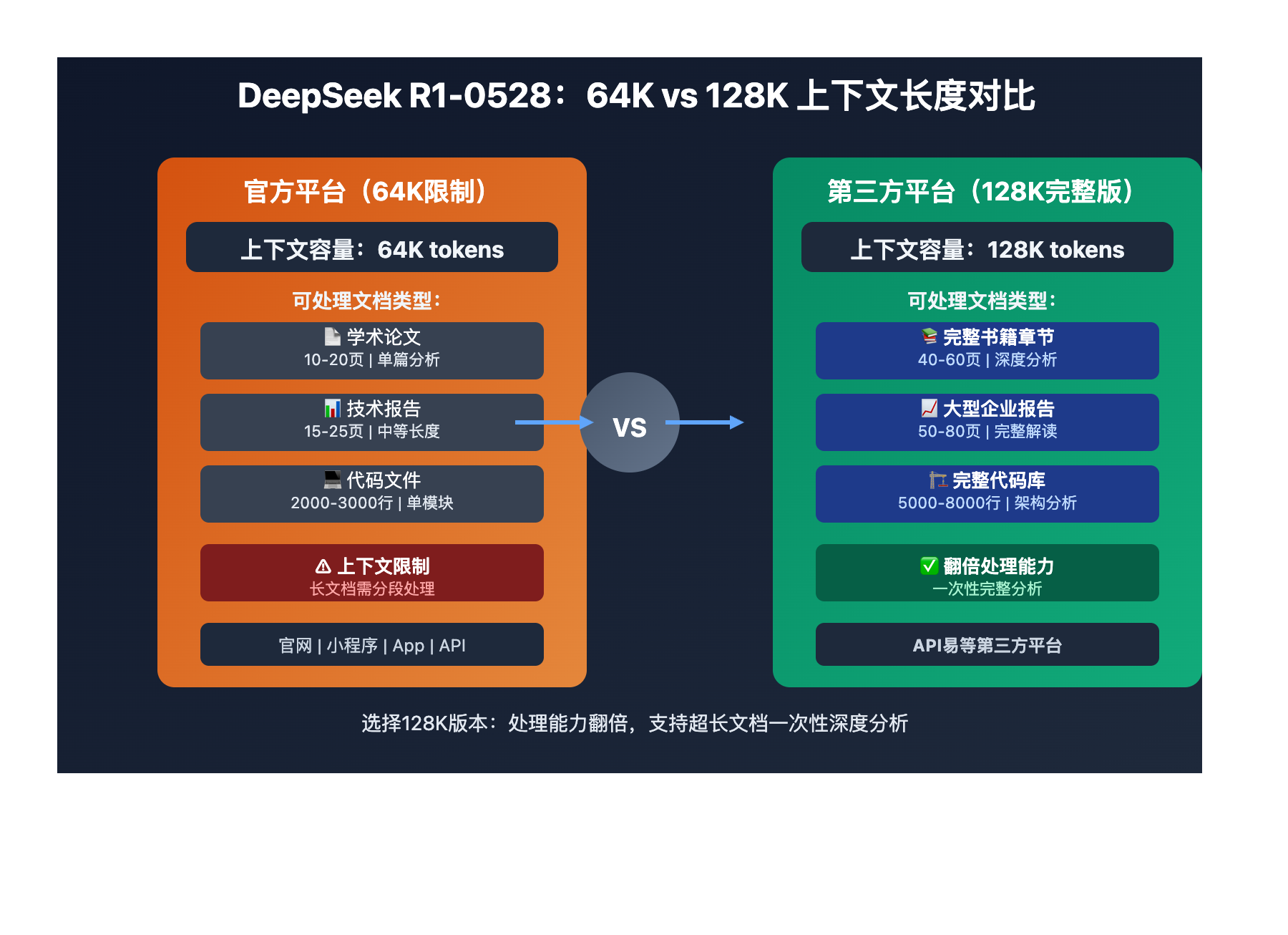
官方平台 vs 第三方平台对比:
- 官方平台:网站、小程序、App端、API均为64K上下文
- 第三方平台:可调用128K开源版本,上下文长度翻倍
- 技术基础:同样的685B参数模型,仅上下文窗口不同
- 应用影响:处理能力、文档长度、任务复杂度大幅提升
这个差异直接决定了你能处理的文档长度、代码复杂度、以及推理任务的深度。选择128K版本,意味着你可以:
- 处理整本书籍或长篇报告
- 分析大型代码库的完整逻辑
- 进行跨章节的深度推理分析
128K上下文长度 核心优势详解
以下是 DeepSeek R1-0528 128K上下文 相比64K版本的核心优势:
| 对比维度 | 64K版本 | 128K版本 | 提升幅度 |
|---|---|---|---|
| 文档处理 | 中等长度报告 | 完整书籍章节 | 翻倍提升 |
| 代码分析 | 单个模块 | 完整项目架构 | 100%增长 |
| 推理深度 | 标准思维链 | 超长推理链 | 深度翻倍 |
🔥 128K上下文 技术优势分析
长文档处理能力突破
128K上下文长度带来的最直观优势是文档处理能力的质变:
文档类型覆盖范围:
64K版本可处理:
• 学术论文(10-20页)
• 技术报告(15-25页)
• 中等代码文件(2000-3000行)
128K版本可处理:
• 完整技术书籍章节(40-60页)
• 大型企业报告(50-80页)
• 完整代码库分析(5000-8000行)
• 多文档综合分析
128K上下文 应用场景革新
学术研究场景:
# 可以处理完整的博士论文章节
context_capacity = "128K tokens"
document_types = [
"完整学术论文分析",
"多篇文献综述对比",
"大型数据集文档解读",
"跨章节逻辑推理"
]
企业应用场景:
# 处理完整的企业级文档
business_scenarios = [
"年度财报深度分析",
"完整产品需求文档",
"大型项目技术方案",
"多部门协作文档整合"
]
代码开发场景:
# 分析完整的代码库架构
code_analysis_scope = [
"微服务架构全貌分析",
"多模块依赖关系梳理",
"完整API文档生成",
"大型重构方案设计"
]

128K上下文长度 应用场景
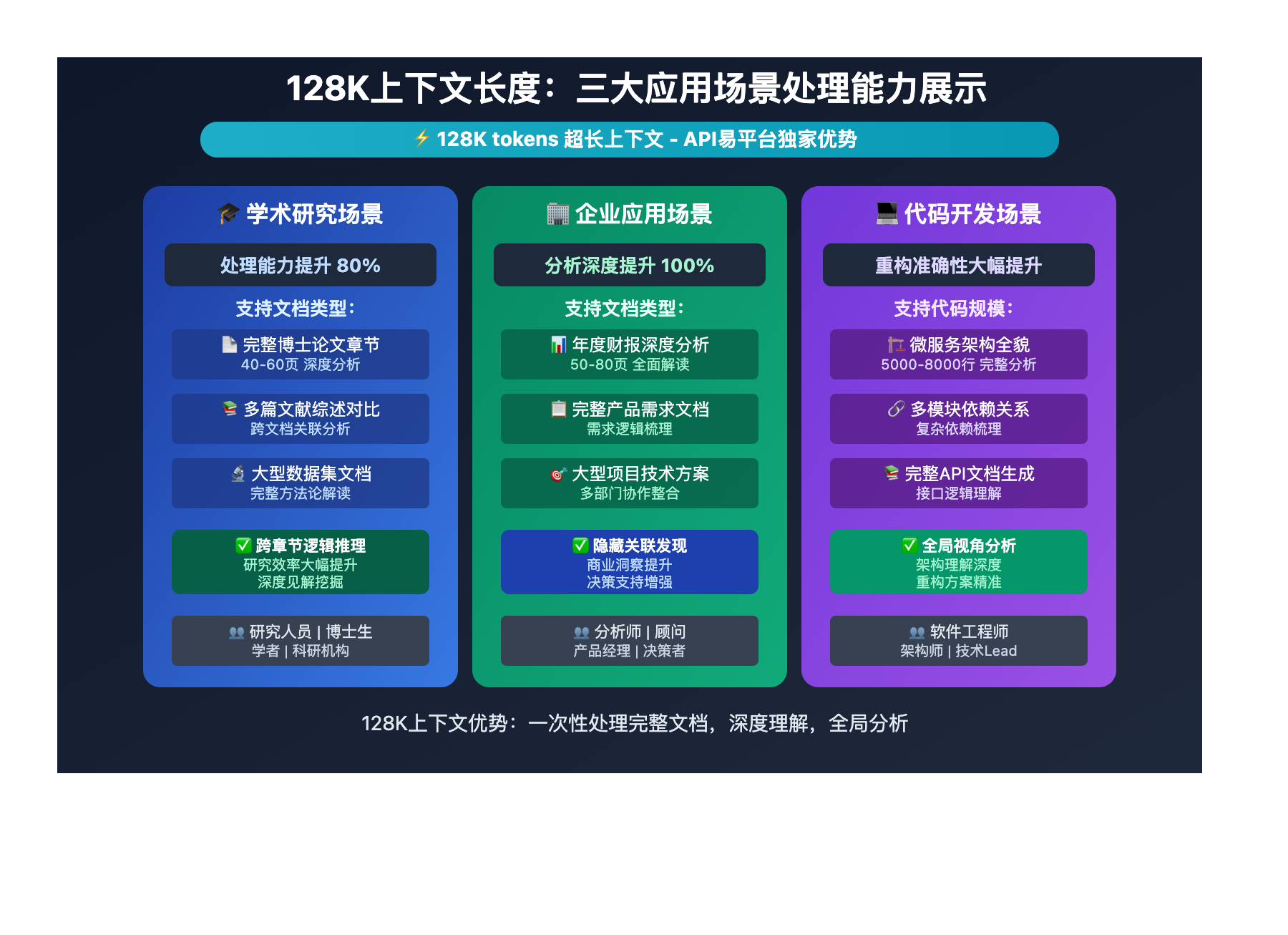
128K上下文长度 在以下场景中表现出色:
| 应用场景 | 适用对象 | 核心优势 | 预期效果 |
|---|---|---|---|
| 🎯 学术研究分析 | 研究人员、学者 | 处理完整论文章节 | 研究效率提升80% |
| 🚀 企业文档分析 | 分析师、顾问 | 完整报告深度解读 | 分析深度提升100% |
| 💡 代码库重构 | 软件工程师 | 全架构理解分析 | 重构准确性大幅提升 |
128K上下文长度 开发指南
在开始体验128K上下文优势之前,你需要选择支持该规格的平台。根据官方文档,API易这样的第三方平台可以提供完整的128K上下文版本。建议先到 API易 注册一个账号(3分钟搞定,新用户送免费额度),这样就能直接体验128K的强大能力。
💻 128K上下文 实战示例
# 🚀 128K上下文长文档分析示例
curl https://vip.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $替换你的API易后台的Key$" \
-d '{
"model": "deepseek-r1",
"max_tokens": 32000,
"stream": false,
"messages": [
{"role": "system", "content": "你是一个专业的文档分析专家,擅长处理长篇文档。"},
{"role": "user", "content": "请分析这份完整的技术白皮书,包含以下内容:[此处可插入最多128K tokens的完整文档内容]"}
]
}'
Python完整示例:
from openai import OpenAI
import json
client = OpenAI(api_key="你的Key", base_url="https://vip.apiyi.com/v1")
def analyze_long_document(document_content, analysis_type="comprehensive"):
"""
利用128K上下文分析长文档
"""
# 检查文档长度(支持最大128K tokens)
if len(document_content.split()) > 100000: # 粗略估算
print("警告:文档可能超过128K限制,建议分段处理")
# 根据分析类型定制提示词
analysis_prompts = {
"comprehensive": "请对以下完整文档进行全面分析,包括主要观点、逻辑结构、关键结论和实用价值。",
"summary": "请为以下长文档提供结构化摘要,突出核心要点和关键信息。",
"critique": "请对以下文档进行批判性分析,指出优点、不足和改进建议。",
"comparison": "请分析文档中不同观点或方案的对比,提供综合评估。"
}
completion = client.chat.completions.create(
model="deepseek-r1",
max_tokens=32000,
stream=False,
messages=[
{"role": "system", "content": "你是一个专业的文档分析专家,擅长处理超长文档的深度分析。"},
{"role": "user", "content": f"{analysis_prompts.get(analysis_type, analysis_prompts['comprehensive'])}\n\n文档内容:\n{document_content}"}
]
)
return completion.choices[0].message.content
# 使用示例:处理完整的技术白皮书
with open("technical_whitepaper.txt", "r", encoding="utf-8") as f:
long_document = f.read()
analysis_result = analyze_long_document(
document_content=long_document,
analysis_type="comprehensive"
)
print(f"分析完成,输出长度: {len(analysis_result)} 字符")
print(f"分析结果预览: {analysis_result[:500]}...")
🎯 模型选择策略
这里简单介绍下我们使用的API平台。API易 是一个AI模型聚合平台,特点是 一个令牌,无限模型,可以用统一的接口调用 OpenAI o3、Claude 4、Gemini 2.5 Pro、Deepseek R1、Grok 等各种模型。对开发者来说很方便,不用为每个模型都申请单独的API密钥了。
平台优势:官方源头转发、不限速调用、按量计费、7×24技术支持。特别重要的是,API易提供128K上下文版本的DeepSeek R1-0528,相比官方64K版本有显著优势。
🔥 针对 128K上下文长度 的推荐模型
| 模型名称 | 上下文长度 | 适用场景 | 推荐指数 |
|---|---|---|---|
| deepseek-r1(API易128K版) | 128K | 长文档深度分析 | ⭐⭐⭐⭐⭐ |
| deepseek-r1(官方64K版) | 64K | 标准文档处理 | ⭐⭐⭐⭐ |
| claude-sonnet-4 | 200K | 超长文档对比参考 | ⭐⭐⭐⭐ |
🎯 平台选择建议:基于 128K上下文长度 的优势,我们推荐优先选择 API易平台的DeepSeek R1-0528,它在 长文档处理和完整推理链展示 方面表现突出。
🎯 128K上下文长度 场景推荐表
| 使用场景 | 官方64K版本 | API易128K版本 | 优势对比 | 特点说明 |
|---|---|---|---|---|
| 🔥 学术论文分析 | 单篇短论文 | 完整博士论文章节 | 翻倍处理能力 | 支持跨章节深度推理 |
| 🖼️ 代码库分析 | 单个模块 | 完整项目架构 | 全局视角分析 | 理解复杂依赖关系 |
| 🧠 企业报告解读 | 摘要级别 | 完整报告分析 | 深度洞察能力 | 发现隐藏关联信息 |
💰 价格参考:具体价格请参考 API易价格页面
✅ 128K上下文 最佳实践
| 实践要点 | 具体建议 | 注意事项 |
|---|---|---|
| 🎯 文档预处理 | 清理无关格式,保留核心内容 | 避免冗余信息占用上下文 |
| ⚡ 分析策略优化 | 明确分析目标,聚焦关键问题 | 充分利用128K容量优势 |
| 💡 结果验证 | 对超长分析结果进行逻辑检查 | 确保分析的连贯性和准确性 |
🔧 高级应用技巧
def smart_document_processor(file_path, chunk_strategy="smart"):
"""
智能文档处理:充分利用128K上下文
"""
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 估算token数量(粗略计算)
estimated_tokens = len(content.split()) * 1.3
if estimated_tokens <= 120000: # 留出一些余量
# 可以一次性处理
return process_single_document(content)
else:
# 智能分段处理
return process_chunked_document(content, chunk_strategy)
def process_single_document(content):
"""单次处理完整文档"""
completion = client.chat.completions.create(
model="deepseek-r1",
max_tokens=32000,
messages=[
{"role": "system", "content": "利用完整上下文进行深度分析。"},
{"role": "user", "content": f"请分析以下完整文档:\n\n{content}"}
]
)
return completion.choices[0].message.content
def process_chunked_document(content, strategy):
"""分段处理超长文档"""
# 智能分段逻辑
chunks = smart_chunk_document(content, max_size=100000)
results = []
for i, chunk in enumerate(chunks):
result = process_single_document(chunk)
results.append(f"第{i+1}部分分析:{result}")
# 综合分析
summary = synthesize_results(results)
return summary
# 使用示例
analysis = smart_document_processor("large_technical_report.pdf")
print(f"文档分析完成: {analysis[:300]}...")
在实践过程中,我发现选择支持128K上下文的平台很重要。特别是当需要处理完整的技术文档或代码库时,64K的限制会严重影响分析质量。API易 提供的128K版本在这方面有明显优势,可以作为长文档处理的首选平台。
❓ 128K上下文长度 常见问题解答
Q1: 为什么官方平台只提供64K,而第三方平台可以提供128K?
技术原理解释:
- DeepSeek R1-0528开源版本本身支持128K上下文
- 官方平台出于稳定性和成本考虑,限制为64K
- 第三方平台直接部署开源版本,可以提供完整的128K能力
选择建议:
- 标准文档处理:64K版本足够
- 长文档深度分析:选择128K版本平台
- API易等第三方平台提供完整128K支持
Q2: 128K上下文会增加多少成本?
成本分析:
- 按实际输入输出tokens计费,上下文长度不直接影响费用
- 长文档分析可能产生更多输出tokens
- 但分析质量和深度显著提升,性价比更高
优化策略:
- 预处理文档,去除无关内容
- 明确分析目标,避免过度分析
- 使用API易的用量监控功能优化成本
Q3: 如何判断文档是否适合128K一次性处理?
判断方法:
def estimate_document_tokens(file_path):
"""估算文档token数量"""
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 简单估算:1个token ≈ 0.75个英文单词 ≈ 0.5个中文字符
words = len(content.split())
chars = len(content)
estimated_tokens = max(words * 1.3, chars * 2)
if estimated_tokens <= 120000:
return True, f"估算{estimated_tokens}tokens,适合一次性处理"
else:
return False, f"估算{estimated_tokens}tokens,建议分段处理"
# 使用示例
suitable, message = estimate_document_tokens("document.txt")
print(f"处理建议: {message}")
🏆 为什么选择「API易」AI大模型API聚合平台
| 核心优势 | 具体说明 | 竞争对比 |
|---|---|---|
| 🛡️ 完整128K上下文支持 | • 提供DeepSeek R1-0528完整128K版本 • 相比官方64K版本翻倍处理能力 • 支持超长文档一次性分析 |
上下文长度优势明显 |
| 🎨 多场景应用支持 | • 学术研究长文档分析 • 企业级报告深度解读 • 代码库完整架构分析 |
一个令牌,无限模型 |
| ⚡ 高性能稳定服务 | • 128K上下文稳定调用 • 不限速处理长文档 • 7×24 技术支持 |
服务稳定性更高 |
| 🔧 开发者友好 | • OpenAI 兼容接口 • 详细的长文档处理文档 • 实时用量监控 |
开发体验更佳 |
| 💰 透明灵活计费 | • 按实际tokens计费 • 上下文长度不额外收费 • 免费额度充足测试 |
成本优势明显 |
💡 128K上下文长度优势示例
使用API易平台,你可以:
- 一次性处理完整的60页技术白皮书
- 分析5000行代码的完整项目架构
- 对比多篇学术论文的核心观点
- 享受稳定的超长上下文处理服务
🎯 总结
通过本文的详细对比分析,相信你已经充分理解了128K上下文长度相比64K版本的巨大优势。选择支持128K的平台,不仅仅是数字上的翻倍,更是应用场景和分析深度的质变提升。
重点回顾:官方平台64K vs 第三方128K,处理能力翻倍,长文档分析优势明显,API易平台提供完整128K支持
希望这篇文章能帮助你更好地理解和应用 128K上下文长度优势。如果想要实际体验差异,记得可以在 API易 注册即可获赠免费额度来测试完整的128K能力。
有任何技术问题,欢迎添加站长微信 8765058 交流讨论,会分享《大模型使用指南》等资料包。
📝 本文作者:API易团队
🔔 关注更新:欢迎关注我们的更新,持续分享 AI 开发经验和最新动态。