站长注:深入解析OpenAI的GPT Image模型特性、功能与实践案例,掌握图像生成和编辑的最新技术,API易平台支持一键调用
GPT-Image-1 是OpenAI推出的全新大型语言模型,具备强大的图像生成能力。相比前代DALL-E模型,GPT Image不仅指令遵循能力更强,还能生成更加逼真的图像,同时拥有丰富的世界知识,能够理解复杂的生成需求。本文将详细介绍GPT Image的核心功能、特点以及如何在实际项目中应用这一强大工具。
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持 GPT Image 等 OpenAI 全系列 API,让AI图像生成更简单
注册可送 1.1 美金额度起,约 300万 Tokens 额度体验。立即免费注册
加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。
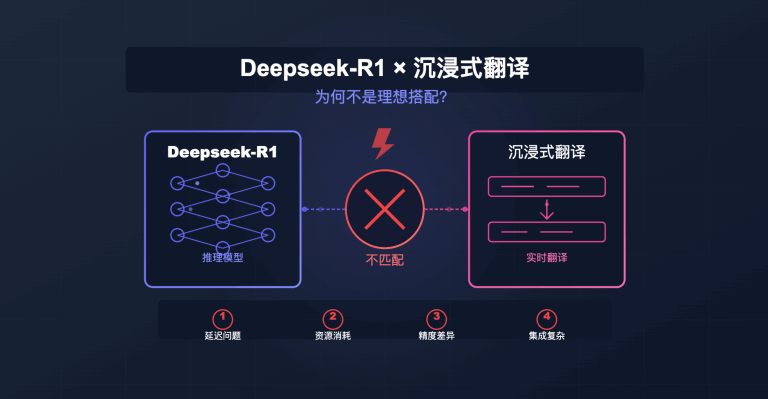
GPT-Image-1API 背景介绍
GPT Image(gpt-image-1)是OpenAI在2025年4月推出的最新图像生成模型,首先在 4o 模型上率先上线的模型,效果惊艳,再正式推出了这个 API。与DALL-E 2和DALL-E 3等前代模型相比,GPT Image具有更强的指令遵循能力和更高的逼真度,能够生成更符合用户期望的图像。
GPT Image基于大型语言模型技术,不仅继承了GPT系列模型的语言理解能力,还专门针对图像生成任务进行了优化。它能够理解复杂的自然语言描述,并将其转化为视觉上令人惊叹的图像。无论是创意概念艺术、产品可视化,还是照片级写实图像,GPT Image都能表现出色。
OpenAI通过GPT Image展示了将语言理解与图像生成结合的强大潜力,使得AI创作工具更加强大和灵活。API易平台作为官方认证的转发服务商,为开发者提供稳定、便捷的GPT Image API访问,让开发者能够轻松将这一技术集成到自己的应用中。
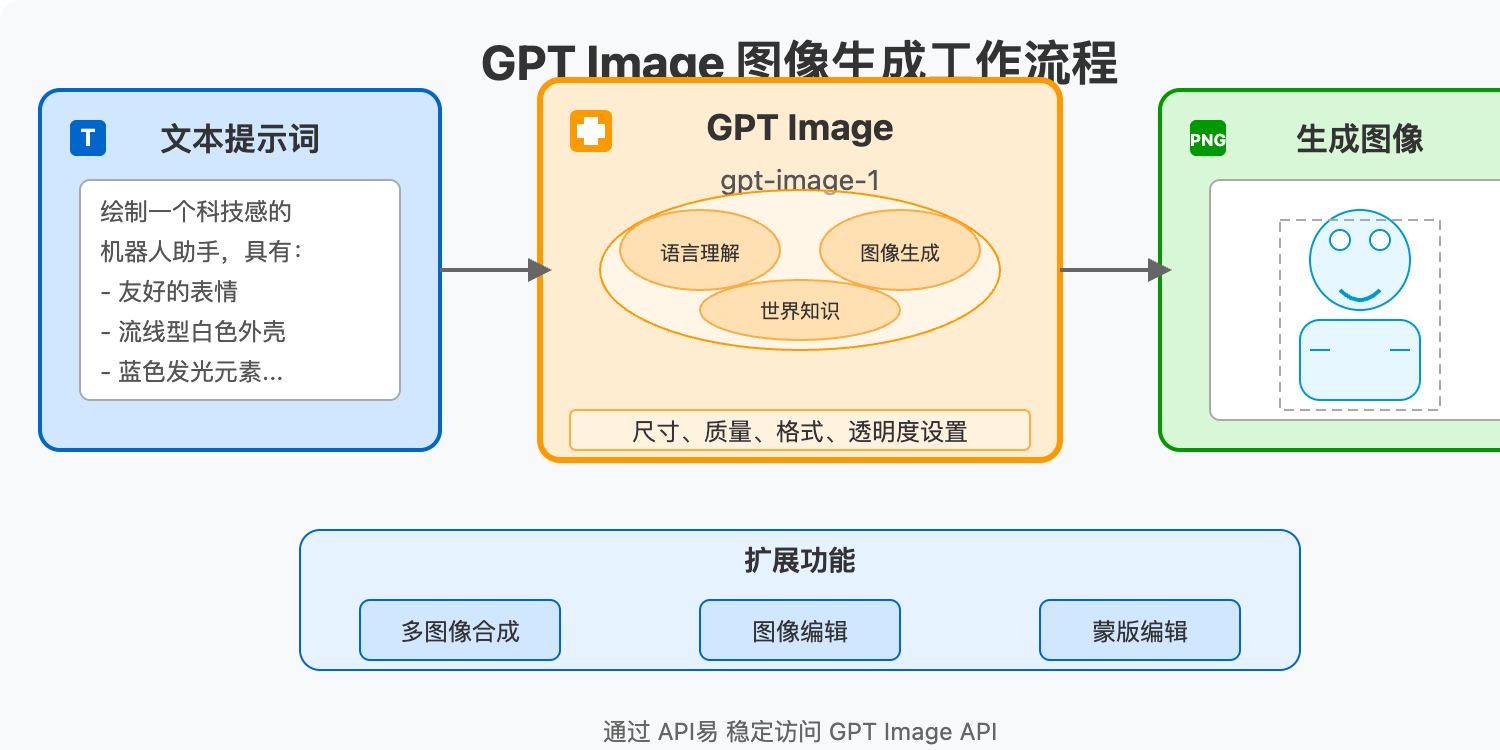
GPT Image API 核心功能
强大的图像生成能力
GPT Image最基本也是最核心的功能是根据文本提示生成全新的图像。模型能够理解复杂、详细的指令,并生成与描述高度匹配的图像。以下是一些GPT Image擅长的图像生成类型:
- 角色和生物设计:能够根据详细描述生成独特的角色、生物或虚构实体
- 场景渲染:可创建复杂的室内、室外场景,包括特定氛围或风格
- 概念艺术:为产品、游戏、电影等创作概念设计图
- 写实图像:生成高度逼真的人物、物体和环境
- 特定艺术风格:模拟特定艺术风格,如像素艺术、水彩画、油画等
通过提供详细的文本描述,用户可以控制生成图像的各种细节,包括主体、背景、色彩、风格、构图等。比起简单的提示词,GPT Image更善于理解结构化的、详细的描述,这让创建复杂视觉内容变得前所未有的简单。
图像编辑与合成
除了从零创建图像外,GPT Image还提供强大的图像编辑功能:
- 多图像合成:可以接收最多10张输入图像,并根据描述将它们智能合成
- 图像编辑:修改已有图像的特定部分,同时保持整体风格一致
- 蒙版编辑:通过提供蒙版(具有alpha通道的透明区域),精确控制哪些区域可以被编辑
这些功能极大地扩展了GPT Image的实用性,使其不仅是创作工具,也是强大的编辑助手。例如,设计师可以上传初步草图,然后指示模型完善特定细节;摄影师可以上传照片,要求模型改变背景或添加元素;营销人员可以将产品图与不同场景合成,创建多样化的宣传材料。
自定义输出选项
GPT Image提供多种自定义选项,让用户能够根据需求调整生成的图像:
- 质量设置:提供”low”(低)、”medium”(中)、”high”(高)和”auto”(自动,默认)四种质量选择
- 尺寸选择:支持”1024×1024″(正方形)、”1536×1024″(纵向)、”1024×1536″(横向)或”auto”(自动,默认)四种尺寸
- 压缩级别:可调整JPEG和WEBP格式的压缩比例(0-100%)
- 透明背景:支持生成带透明背景的图像(仅适用于PNG或WEBP格式)
- 输出格式:支持JPEG、PNG、WEBP等常见图像格式
这些选项使开发者能够根据应用场景优化图像输出,在质量和性能之间找到平衡点。例如,对于需要快速预览的场景,可以选择较低质量和较高压缩率;而对于需要高质量展示的场景,则可以选择高质量和低压缩率。

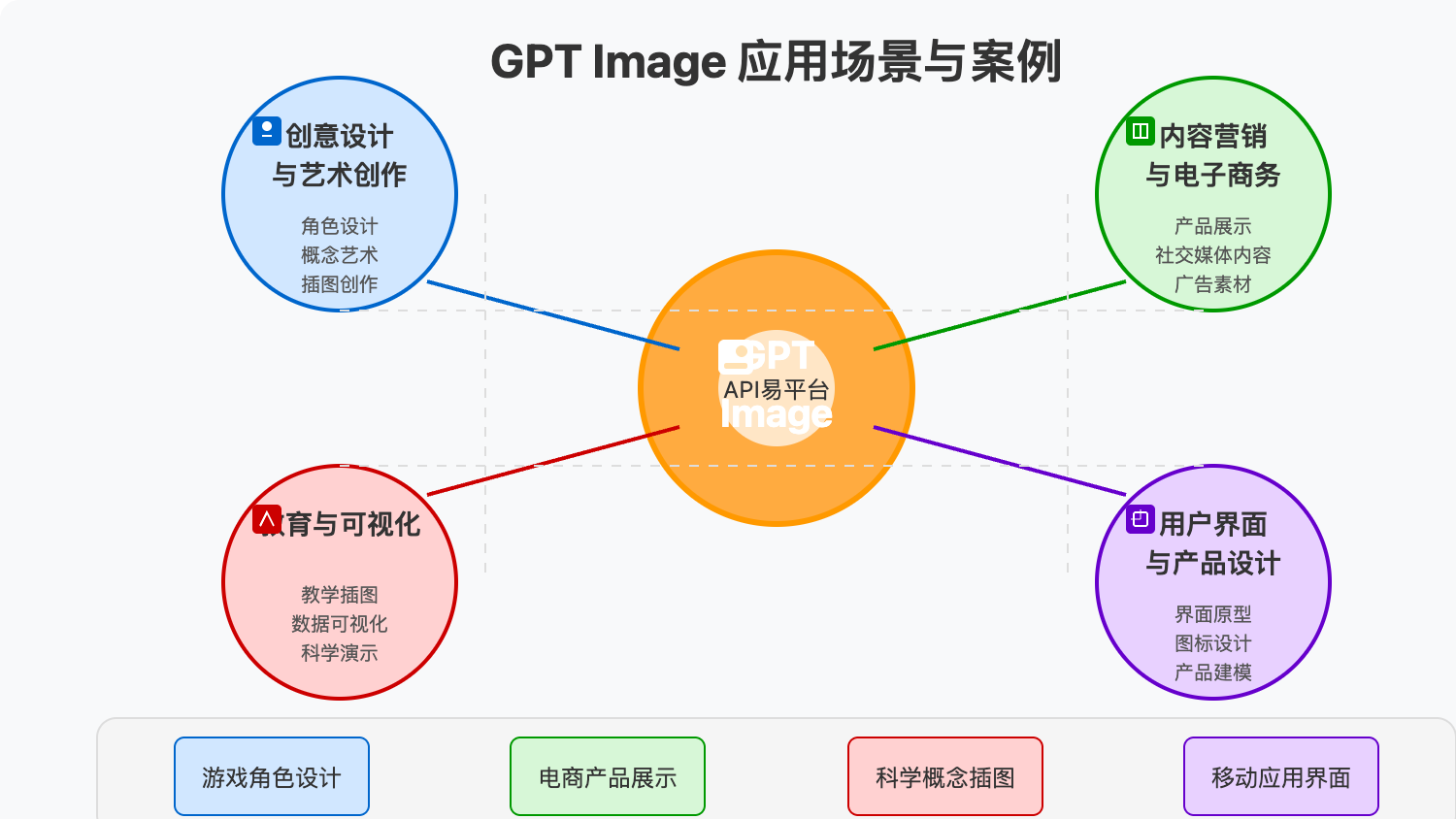
GPT Image API 应用场景
GPT Image的强大能力使其在各个领域都有广泛的应用前景:
创意设计与艺术创作
设计师和艺术家可以利用GPT Image快速实现创意概念:
- 角色设计:游戏开发者可以描述角色特征,快速获得角色原型图
- 概念艺术:电影、游戏制作人可以生成场景、道具、服装等概念图
- 插图创作:为书籍、文章、博客等创作配图
- 艺术探索:艺术家可以探索不同风格和技法的可能性
GPT Image尤其擅长理解复杂的角色设计说明。例如,一个游戏开发者可以提供详细的角色规格说明,包括体型、材质、颜色、表情等,GPT Image能够理解这些复杂指令并生成符合预期的形象。
内容营销与电子商务
市场营销人员可以利用GPT Image提升内容吸引力:
- 产品展示:生成不同场景下的产品使用图
- 社交媒体内容:创建引人注目的社交媒体图像
- 广告素材:快速制作各种尺寸和风格的广告图像
- 电商图片:创建产品在不同环境、搭配中的展示图
例如,服装品牌可以上传基础产品图,然后使用GPT Image的编辑功能将产品放置在不同场景中,或者展示不同搭配方案,大大提高产品展示的多样性和吸引力。
教育与可视化
教育工作者和研究人员可以利用GPT Image增强知识传递:
- 教学插图:为复杂概念创建直观的可视化图像
- 数据可视化:将抽象数据转化为易于理解的图表和图像
- 科学演示:可视化科学概念、实验设置或结果
- 历史重现:根据历史描述重现场景或事件
教师可以描述一个复杂的科学概念,让GPT Image生成清晰的教学插图,帮助学生更好地理解和记忆知识点。
用户界面与产品设计
设计师和产品开发人员可以加速UI/UX设计过程:
- 界面原型:快速生成应用界面或网站设计概念
- 图标设计:创建统一风格的图标集
- 产品模型:生成产品外观设计的虚拟模型
- 包装设计:为产品创建引人注目的包装图案
产品设计师可以描述一个新产品的外观特点,使用GPT Image生成初步设计概念,加速产品开发过程。
GPT Image API 开发指南
1. 模型选择
模型服务介绍
本站均为官方源头转发,价格略有优势,聚合各种优秀大模型,使用起来很方便。
企业级专业稳定的OpenAI o1/Deepseek R1/Gemini 等全模型官方同源接口的中转分发。不限速,不过期,不惧封号,按量计费,长期可靠服务;让技术助力科研、公益事业!
当前模型推荐(均为稳定供给)
全部模型和价格请看网站后台 https://www.apiyi.com/account/pricing
- 图像生成模型
gpt-image-1:OpenAI最新的图像生成模型,本文主角(推荐指数:⭐⭐⭐⭐⭐)dall-e-3:OpenAI上一代图像生成模型,指令遵循能力较弱sora-image:具备视频能力的衍生模型gemini-2.5-pro-exp-03-25:Google的多模态模型,也具备图像生成能力
- 辅助图像任务的语言模型
gpt-4o:强大的多模态模型,可以理解和描述图像,配合使用效果更佳o1:推理增强型模型,适合生成复杂的图像提示词
场景推荐
- 创意图像生成场景
- 首选:
gpt-image-1(最佳图像质量和指令遵循能力) - 辅助:
gpt-4o(用于优化提示词和分析生成结果)
- 首选:
- 图像编辑和合成场景
- 首选:
gpt-image-1(支持多图像输入和蒙版编辑) - 备选:
dall-e-3(某些特定风格可能有独特表现)
- 首选:
- 特殊风格创作场景
- 首选:
gpt-image-1(支持更广泛的艺术风格控制) - 备选:
sora-image(具有独特的视觉风格)
- 首选:
- 辅助内容创作场景
- 组合:
gpt-image-1+gpt-4o(前者生成图像,后者提供描述和建议)
- 组合:
注意:具体价格请参考 API易价格页面,目前GPT Image的调用价格为$0.008/张(1024×1024),$0.016/张(1536×1024或1024×1536)
实践示例
以下是使用GPT Image API的几个实用代码示例:
1. 基础图像生成
import os
import base64
from openai import OpenAI
from io import BytesIO
from PIL import Image
# 初始化客户端
client = OpenAI(
api_key="YOUR_APIYI_KEY", # 替换为您的API易API密钥
base_url="https://vip.apiyi.com/v1" # API易的基础URL
)
def generate_image(prompt, output_path, size="1024x1024", quality="high"):
"""
使用GPT Image生成图像并保存到文件
参数:
prompt (str): 描述要生成什么图像的文本
output_path (str): 保存图像的路径
size (str): 图像尺寸,可选值:"1024x1024", "1536x1024", "1024x1536"
quality (str): 图像质量,可选值:"low", "medium", "high", "auto"
"""
# 生成图像
response = client.images.generate(
model="gpt-image-1",
prompt=prompt,
size=size,
quality=quality,
n=1 # 生成图像的数量
)
# 获取base64编码的图像
image_base64 = response.data[0].b64_json
# 解码并保存图像
image_bytes = base64.b64decode(image_base64)
with open(output_path, "wb") as image_file:
image_file.write(image_bytes)
print(f"图像已保存至: {output_path}")
return output_path
# 使用示例
prompt = """
绘制一个科技感十足的智能机器人助手,具有以下特征:
- 友好的表情和大眼睛
- 流线型的白色外壳
- 蓝色发光元素点缀
- 漂浮在未来风格的办公室环境中
- 周围有全息投影界面
请使用3D渲染风格,光线明亮,细节丰富
"""
output_file = "robot_assistant.png"
generate_image(prompt, output_file)
2. 多图像合成
import os
import base64
from openai import OpenAI
from PIL import Image
from io import BytesIO
# 初始化客户端
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
def combine_images(images_paths, prompt, output_path, size="1024x1024"):
"""
将多张图像根据提示词合成为一张新图像
参数:
images_paths (list): 图像文件路径列表
prompt (str): 描述如何合成图像的文本
output_path (str): 输出图像的保存路径
size (str): 输出图像尺寸
"""
# 读取所有图像文件
image_files = []
for img_path in images_paths:
with open(img_path, "rb") as img_file:
image_files.append(img_file.read())
# 调用API合成图像
response = client.images.edit(
model="gpt-image-1",
image=image_files, # 最多可以提供10张图像
prompt=prompt,
size=size
)
# 保存结果
image_base64 = response.data[0].b64_json
image_bytes = base64.b64decode(image_base64)
with open(output_path, "wb") as image_file:
image_file.write(image_bytes)
print(f"合成图像已保存至: {output_path}")
return output_path
# 使用示例
image_paths = ["cat.jpg", "hat.png"]
prompt = "将猫和帽子合成一张图片,让猫戴着帽子坐在树上,保持像素艺术风格"
output_file = "cat_with_hat.png"
combine_images(image_paths, prompt, output_file)
3. 带蒙版的图像编辑
import os
import base64
from openai import OpenAI
from PIL import Image
from io import BytesIO
# 初始化客户端
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
def edit_with_mask(image_path, mask_path, prompt, output_path, size="1024x1024"):
"""
使用蒙版编辑图像的特定部分
参数:
image_path (str): 要编辑的原始图像路径
mask_path (str): 蒙版图像路径(需要包含alpha通道)
prompt (str): 描述编辑内容的文本
output_path (str): 输出图像路径
size (str): 输出图像尺寸
"""
# 读取原始图像和蒙版
with open(image_path, "rb") as img_file:
image_data = img_file.read()
with open(mask_path, "rb") as mask_file:
mask_data = mask_file.read()
# 调用API进行编辑
response = client.images.edit(
model="gpt-image-1",
image=image_data,
mask=mask_data,
prompt=prompt,
size=size
)
# 保存结果
image_base64 = response.data[0].b64_json
image_bytes = base64.b64decode(image_base64)
with open(output_path, "wb") as image_file:
image_file.write(image_bytes)
print(f"编辑后的图像已保存至: {output_path}")
return output_path
# 使用示例
original_image = "character.png"
mask_image = "character_mask.png" # 带透明通道的蒙版
prompt = "将角色放置在充满星星和行星的彩色星系背景中"
output_file = "character_in_space.png"
edit_with_mask(original_image, mask_image, prompt, output_file)
GPT Image API 最佳实践
要充分发挥GPT Image的潜力,以下是一些推荐的最佳实践:
- 编写详细的提示词
- 提供具体的视觉描述,包括主体、背景、风格、光线等
- 使用结构化的格式,如分点列出不同元素
- 指定希望的艺术风格、渲染方式或参考灵感
- 图像质量与性能平衡
- 对于快速预览或迭代,使用”low”质量设置
- 对于最终作品,使用”high”质量设置
- 根据应用需求选择合适的图像尺寸和格式
- 多图像合成技巧
- 选择视觉风格相似的图像以获得更好的合成效果
- 在提示词中明确指出每个输入图像的角色
- 最多使用10张输入图像,但建议保持在5张以内以获得最佳效果
- 蒙版编辑技巧
- 确保蒙版包含alpha通道
- 白色区域表示要保留的部分,黑色区域表示要编辑的部分
- 提示词应描述整个最终图像,而不仅仅是编辑区域
- 错误处理与重试
- 实现错误处理机制,特别是在处理大量图像时
- 如果结果不理想,尝试调整提示词或模型参数后重试
- 保存中间结果,便于进行渐进式编辑
GPT Image API 常见问题
问题1:GPT Image与DALL-E 3相比有什么优势?
GPT Image相比DALL-E 3有以下几个关键优势:
- 更强的指令遵循能力:能够更准确地按照复杂指令生成图像
- 更高的写实度:生成的照片级图像更加逼真
- 更丰富的世界知识:能够基于更广泛的世界知识生成内容
- 多图像处理:支持多达10张输入图像的合成和编辑
- 更灵活的输出选项:提供更多的尺寸、质量和格式选择
此外,GPT Image在艺术风格模拟、角色设计等方面也表现更好,适合更广泛的应用场景。
问题2:如何创建好的GPT Image提示词?
创建有效的GPT Image提示词建议遵循以下原则:
- 结构化描述:将复杂提示词分解为结构化的部分
主题: [描述主要对象/人物/场景] 视觉风格: [描述艺术风格、渲染方式等] 背景: [描述环境、光线、氛围等] 详细特征: [列出重要的视觉细节] 构图: [描述如何安排画面中的元素] - 使用视觉语言:使用具体的视觉描述词,而非抽象概念
- 好的例子:”渐变蓝色背景,带有模糊的光斑和柔和的阴影”
- 不好的例子:”美丽的背景”
- 参考特定风格:引用特定的艺术风格或技法
- 例如:”像素艺术风格”、”水彩画风格”、”摄影写实风格”
- 避免过度约束:给模型留有创意空间
- 详细描述最重要的元素,但不必指定每个细节
问题3:为什么有时图像生成结果与预期不符?
图像生成结果与预期不符可能有以下原因:
- 提示词不够明确:缺乏具体的视觉描述或存在模糊的指令
- 提示词过于复杂:包含太多相互矛盾的要求
- 模型限制:某些极其复杂的场景或特定概念超出模型能力
- 质量设置:低质量设置可能导致细节丢失
- 内容策略:某些敏感内容可能被过滤或修改
解决方法包括:重新编写更清晰的提示词、分解复杂要求、尝试不同的质量设置,或者使用多步骤方法(先生成基础图像,然后编辑)。
问题4:如何处理带透明背景的图像生成?
要生成带透明背景的图像,请注意以下几点:
- 在提示词中明确要求:包含”透明背景”的描述
- 选择支持透明度的格式:使用PNG或WEBP格式(JPEG不支持透明)
- 设置正确的参数:
response = client.images.generate( model="gpt-image-1", prompt="在透明背景上绘制一顶绿色水桶帽", output_format="png" # 必须是支持透明的格式 )
如果透明背景是重要需求,建议在提示词中强调这一点,并确保正确设置输出格式。
为什么选择 API易 AI大模型聚合平台
- 稳定可靠的GPT Image API访问
- 官方源头转发,确保API调用稳定性
- 无限速限制,支持高并发应用场景
- 与官方API完全兼容,无需修改现有代码
- 更具性价比的定价策略
- 透明的按量计费模式,无最低消费要求
- 新用户赠送试用额度,降低尝试成本
- 与直接使用官方API相比具有价格优势
- 多模型聚合优势
- 同时提供多种图像生成模型,便于对比和选择
- 支持GPT-4o等语言模型,可与图像生成模型协同工作
- 一个API密钥访问所有模型,简化开发流程
- 专业的技术支持
- 提供中文技术文档和支持
- 7×24小时响应服务
- 解决模型集成和使用过程中的问题
- 便捷的开发体验
- 简化的API密钥管理
- 详细的调用统计和成本分析
- 兼容官方SDK,无缝迁移
提示:使用API易平台调用GPT Image API时,只需将OpenAI客户端的初始化代码中的API密钥替换为API易提供的密钥,并设置base_url为”https://vip.apiyi.com/v1″,其他代码无需修改。
总结
GPT Image代表了AI图像生成技术的重大进步,它将强大的语言理解能力与卓越的图像生成能力相结合,为创意工作者、开发者和企业提供了前所未有的视觉创作工具。无论是生成全新图像,还是编辑和合成现有图像,GPT Image都能以惊人的质量和准确度完成任务。
通过本文详细介绍的核心功能、应用场景和开发指南,您已经了解了如何利用GPT Image API创建各种令人惊叹的视觉内容。从基础的图像生成到复杂的多图像合成和蒙版编辑,GPT Image提供了满足各种创意需求的功能。
API易平台为您提供稳定、便捷、经济的GPT Image API访问服务,让您无需担心API限制、稳定性或技术支持问题,专注于创造令人惊叹的视觉体验。无论您是设计师、开发者还是内容创作者,GPT Image都将成为您创意工作流程中的强大助手。
现在,就通过API易平台开始探索GPT Image的无限可能性吧!
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持 GPT Image 等全系列模型,让AI图像生成更简单
加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。

本文作者:API易团队
欢迎关注我们的更新,持续分享 AI 开发经验和最新动态。