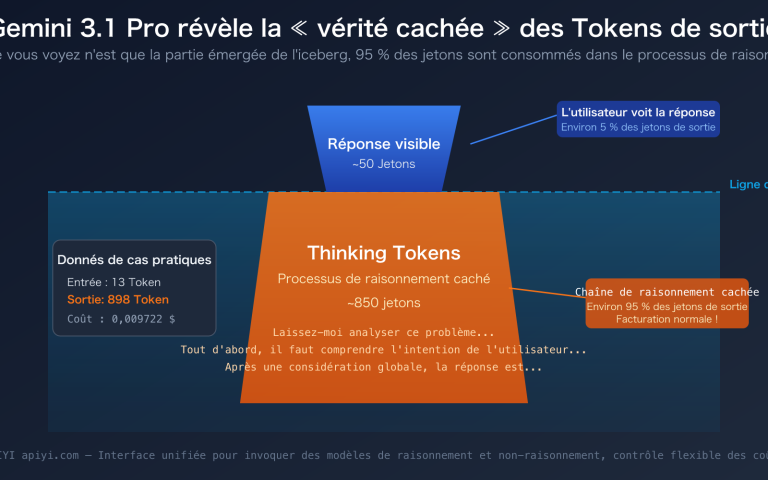
Vous rencontrez l'erreur thinking_budget and thinking_level are not supported together en appelant les modèles Gemini 3.0 Pro Preview ou gemini-3-flash-preview ? Il s'agit d'un problème de compatibilité dû à une mise à jour des paramètres entre les différentes versions de l'API Gemini de Google. Cet article analyse la cause profonde de cette erreur sous l'angle de l'évolution de l'API et vous présente la méthode de configuration correcte.
Valeur ajoutée : Après avoir lu cet article, vous saurez configurer correctement les paramètres du mode réflexion pour les modèles Gemini 2.5 et 3.0, évitant ainsi les erreurs d'appel d'API courantes tout en optimisant les performances d'inférence et le contrôle des coûts.

Points clés de l'évolution des paramètres du mode réflexion de l'API Gemini
| Version du modèle | Paramètre recommandé | Type de paramètre | Exemple de configuration | Cas d'usage |
|---|---|---|---|---|
| Gemini 2.5 Flash/Flash-Lite | thinking_budget |
Entier ou -1 | thinking_budget: 0 (désactivé)thinking_budget: -1 (dynamique) |
Contrôle précis du budget de tokens de réflexion |
| Gemini 3.0 Pro/Flash | thinking_level |
Valeur énumérée | thinking_level: "minimal"/"low"/"medium"/"high" |
Configuration simplifiée selon le scénario |
| Note de compatibilité | ⚠️ Non cumulables | – | Envoyer les deux paramètres simultanément déclenchera une erreur 400 | Choisir l'un ou l'autre selon la version du modèle |
Différences fondamentales des paramètres de réflexion Gemini
La raison principale pour laquelle Google a introduit le paramètre thinking_level dans Gemini 3.0 est de simplifier l'expérience de configuration pour les développeurs. Alors que le thinking_budget de Gemini 2.5 obligeait les développeurs à estimer précisément le nombre de tokens de réflexion, le thinking_level de Gemini 3.0 abstrait cette complexité en 4 niveaux sémantiques, abaissant ainsi la barrière à l'entrée pour la configuration.
Ce changement de conception reflète un arbitrage de Google dans l'évolution de son API : sacrifier une partie de la précision du contrôle au profit d'une meilleure ergonomie et d'une cohérence accrue entre les modèles. Pour la plupart des applications, l'abstraction offerte par thinking_level est largement suffisante. Le recours à thinking_budget ne se justifie que lorsqu'une optimisation extrême des coûts ou un contrôle très spécifique du budget de tokens est nécessaire.
💡 Conseil technique : Pour vos développements, nous vous suggérons d'effectuer vos tests d'appels d'interface via la plateforme APIYI (apiyi.com). Elle propose une interface API unifiée supportant les modèles Gemini 2.5 Flash, Gemini 3.0 Pro, Gemini 3.0 Flash, etc., ce qui facilite la validation rapide des effets réels et des différences de coûts entre les différentes configurations de mode réflexion.
Cause racine de l'erreur : stratégie de rétrocompatibilité de la conception des paramètres
Analyse du message d'erreur API
{
"status_code": 400,
"error": {
"message": "Unable to submit request because thinking_budget and thinking_level are not supported together.",
"type": "upstream_error",
"code": 400
}
}
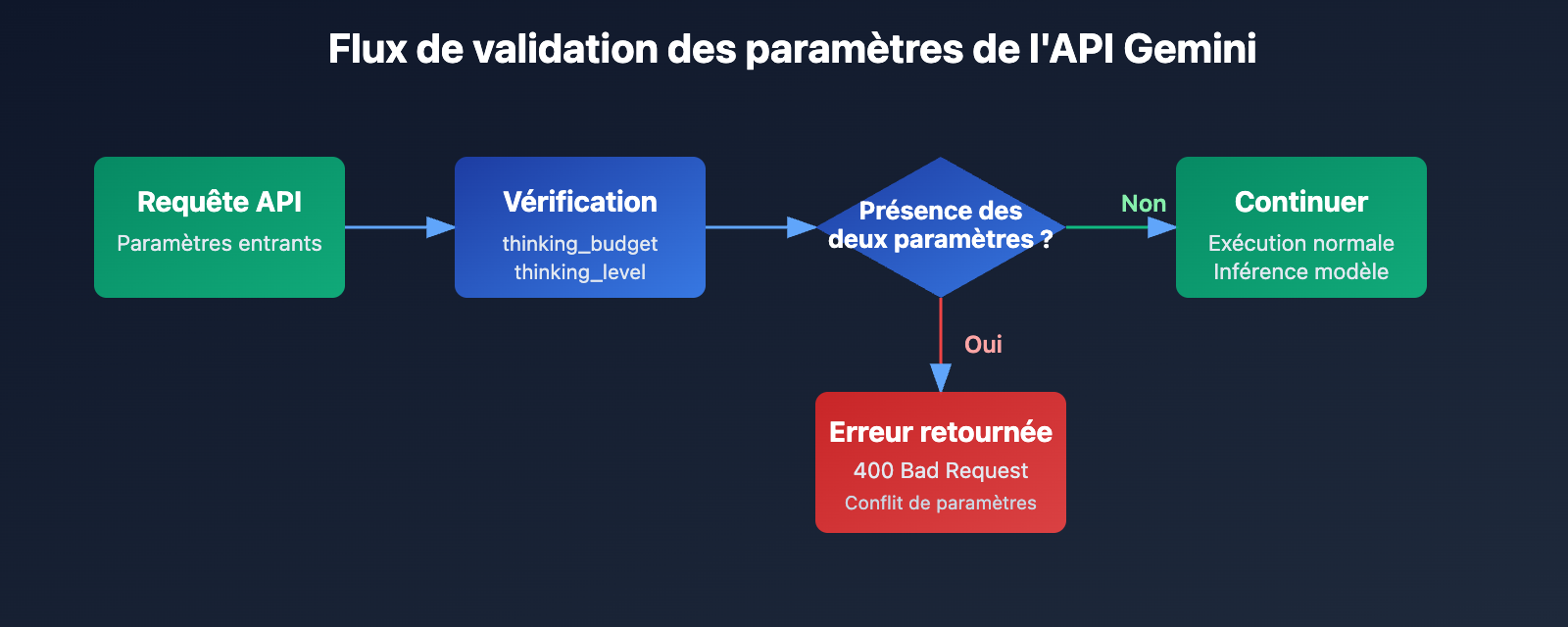
L'information clé de cette erreur est que thinking_budget et thinking_level ne peuvent pas exister simultanément. Lorsque Google a introduit de nouveaux paramètres pour Gemini 3.0, il n'a pas totalement abandonné les anciens, mais a adopté une stratégie d'exclusion mutuelle :
- Modèles Gemini 2.5 : acceptent uniquement
thinking_budgetet ignorentthinking_level. - Modèles Gemini 3.0 : utilisent en priorité
thinking_level, tout en acceptantthinking_budgetpour maintenir la compatibilité descendante, mais interdisent la transmission des deux en même temps. - Condition de déclenchement de l'erreur : la requête API contient à la fois les paramètres
thinking_budgetetthinking_level.
Pourquoi cette erreur se produit-elle ?
Les développeurs rencontrent généralement cette erreur dans les trois scénarios suivants :
| Scénario | Raison | Caractéristiques typiques du code |
|---|---|---|
| Scénario 1 : Remplissage automatique par le SDK | Certains frameworks d'IA (comme LiteLLM ou AG2) remplissent automatiquement les paramètres selon le nom du modèle, ce qui entraîne la transmission des deux paramètres. | Utilisation d'un SDK packagé sans vérifier le corps réel de la requête. |
| Scénario 2 : Configuration codée en dur | Le paramètre thinking_budget est codé en dur dans le code, et n'a pas été mis à jour lors du passage au modèle Gemini 3.0. |
Attribution simultanée des deux paramètres dans les fichiers de configuration ou le code. |
| Scénario 3 : Mauvaise interprétation de l'alias du modèle | Utilisation d'un alias comme gemini-flash-preview qui pointe vers Gemini 3.0, alors que les paramètres sont configurés pour la version 2.5. |
Le nom du modèle contient preview ou latest, mais la configuration des paramètres n'est pas synchronisée. |
🎯 Conseil de sélection : Lors du changement de version du modèle Gemini, il est recommandé de tester d'abord la compatibilité des paramètres via la plateforme APIYI (apiyi.com). Cette plateforme permet de basculer rapidement entre les modèles des séries Gemini 2.5 et 3.0, facilitant ainsi la comparaison de la qualité des réponses et des différences de latence selon les configurations du mode de réflexion, tout en évitant les conflits de paramètres en production.
3 solutions : choisir les bons paramètres selon la version du modèle
Solution 1 : Configuration du modèle Gemini 2.5 (utiliser thinking_budget)
Modèles concernés : gemini-2.5-flash, gemini-2.5-pro, etc.
Description des paramètres :
thinking_budget: 0– Désactive complètement le mode de réflexion, latence et coût minimaux.thinking_budget: -1– Mode de réflexion dynamique, le modèle s'ajuste selon la complexité de la requête.thinking_budget: <entier positif>– Spécifie précisément la limite maximale de tokens de réflexion.
Exemple minimaliste
import openai
client = openai.OpenAI(
api_key="VOTRE_CLÉ_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "Explique le principe de l'intrication quantique"}],
extra_body={
"thinking_budget": -1 # Mode de réflexion dynamique
}
)
print(response.choices[0].message.content)
Voir le code complet (incluant l’extraction du contenu de réflexion)
import openai
client = openai.OpenAI(
api_key="VOTRE_CLÉ_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "Explique le principe de l'intrication quantique"}],
extra_body={
"thinking_budget": -1, # Mode de réflexion dynamique
"include_thoughts": True # Activer le retour du résumé de réflexion
}
)
# Extraire le contenu de réflexion (si activé)
for part in response.choices[0].message.content:
if hasattr(part, 'thought') and part.thought:
print(f"Processus de réflexion : {part.text}")
# Extraire la réponse finale
final_answer = response.choices[0].message.content
print(f"Réponse finale : {final_answer}")
Note : Le modèle Gemini 2.5 sera retiré le 3 mars 2026. Il est conseillé de migrer vers la série Gemini 3.0 dès que possible. Vous pouvez comparer rapidement la qualité des réponses avant et après migration sur la plateforme APIYI (apiyi.com).
Solution 2 : Configuration du modèle Gemini 3.0 (utiliser thinking_level)
Modèles concernés : gemini-3.0-flash-preview, gemini-3.0-pro-preview
Description des paramètres :
thinking_level: "minimal"– Réflexion minimale, budget proche de zéro, nécessite la transmission de signatures de réflexion (Thought Signatures).thinking_level: "low"– Réflexion de faible intensité, adaptée au suivi d'instructions simples et au chat.thinking_level: "medium"– Réflexion d'intensité moyenne, adaptée aux tâches de raisonnement général (uniquement supporté par Gemini 3.0 Flash).thinking_level: "high"– Réflexion de haute intensité, maximise la profondeur du raisonnement, idéale pour les problèmes complexes (valeur par défaut).
Exemple minimaliste
import openai
client = openai.OpenAI(
api_key="VOTRE_CLÉ_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[{"role": "user", "content": "Analyse la complexité temporelle de ce code"}],
extra_body={
"thinking_level": "medium" # Réflexion d'intensité moyenne
}
)
print(response.choices[0].message.content)
Voir le code complet (incluant la transmission de signature de réflexion)
import openai
client = openai.OpenAI(
api_key="VOTRE_CLÉ_API",
base_url="https://api.apiyi.com/v1"
)
# Premier tour de dialogue
response_1 = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[{"role": "user", "content": "Conçois un algorithme de cache LRU"}],
extra_body={
"thinking_level": "high",
"include_thoughts": True
}
)
# Extraire la signature de réflexion (retournée automatiquement par Gemini 3.0)
thought_signatures = []
for part in response_1.choices[0].message.content:
if hasattr(part, 'thought_signature'):
thought_signatures.append(part.thought_signature)
# Deuxième tour de dialogue, transmission de la signature pour maintenir la chaîne de raisonnement
response_2 = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[
{"role": "user", "content": "Conçois un algorithme de cache LRU"},
{"role": "assistant", "content": response_1.choices[0].message.content, "thought_signatures": thought_signatures},
{"role": "user", "content": "Optimise la complexité spatiale de cet algorithme"}
],
extra_body={
"thinking_level": "high"
}
)
print(response_2.choices[0].message.content)
💰 Optimisation des coûts : Pour les projets sensibles au budget, vous pouvez envisager d'utiliser l'API Gemini 3.0 Flash via APIYI (apiyi.com). La plateforme propose une facturation flexible et des tarifs avantageux, idéaux pour les petites et moyennes équipes ainsi que les développeurs individuels. L'utilisation de
thinking_level: "low"permet de réduire encore davantage les coûts.
Solution 3 : Stratégie d'adaptation des paramètres pour le basculement dynamique de modèle
Cas d'usage : Nécessité de supporter à la fois les modèles Gemini 2.5 et 3.0 dans le code.
Fonction d'adaptation intelligente des paramètres
def get_thinking_config(model_name: str, complexity: str = "medium") -> dict:
"""
Sélectionne automatiquement le bon paramètre de mode de réflexion selon la version du modèle.
Args:
model_name: Nom du modèle Gemini
complexity: Complexité de réflexion ("minimal", "low", "medium", "high", "dynamic")
Returns:
Dictionnaire de paramètres pour extra_body
"""
# Liste des modèles Gemini 3.0
gemini_3_models = [
"gemini-3.0-flash-preview",
"gemini-3.0-pro-preview",
"gemini-3-flash",
"gemini-3-pro"
]
# Liste des modèles Gemini 2.5
gemini_2_5_models = [
"gemini-2.5-flash-preview-04-17",
"gemini-2.5-flash-lite",
"gemini-2-flash",
"gemini-2-flash-lite"
]
# Déterminer la version du modèle
if any(m in model_name for m in gemini_3_models):
# Gemini 3.0 utilise thinking_level
level_map = {
"minimal": "minimal",
"low": "low",
"medium": "medium",
"high": "high",
"dynamic": "high" # Haute intensité par défaut
}
return {"thinking_level": level_map.get(complexity, "medium")}
elif any(m in model_name for m in gemini_2_5_models):
# Gemini 2.5 utilise thinking_budget
budget_map = {
"minimal": 0,
"low": 512,
"medium": 2048,
"high": 8192,
"dynamic": -1
}
return {"thinking_budget": budget_map.get(complexity, -1)}
else:
# Modèle inconnu, paramètres Gemini 3.0 par défaut
return {"thinking_level": "medium"}
# Exemple d'utilisation
import openai
client = openai.OpenAI(
api_key="VOTRE_CLÉ_API",
base_url="https://api.apiyi.com/v1"
)
model = "gemini-3.0-flash-preview" # Peut être basculé dynamiquement
thinking_config = get_thinking_config(model, complexity="high")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Votre question"}],
extra_body=thinking_config
)

| Complexité de réflexion | Gemini 2.5 (thinking_budget) | Gemini 3.0 (thinking_level) | Scénarios recommandés |
|---|---|---|---|
| Minimale | 0 |
"minimal" |
Suivi d'instructions simples, apps à haut débit |
| Basse | 512 |
"low" |
Chatbots, FAQ légères |
| Moyenne | 2048 |
"medium" |
Tâches de raisonnement général, génération de code |
| Haute | 8192 |
"high" |
Résolution de problèmes complexes, analyse approfondie |
| Dynamique | -1 |
"high" (par défaut) |
Adaptation automatique de la complexité |
🚀 Démarrage rapide : Nous vous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour prototyper rapidement. La plateforme fournit une interface API Gemini prête à l'emploi, sans configuration complexe. L'intégration se fait en 5 minutes et permet de basculer en un clic entre les différents paramètres de réflexion pour comparer les résultats.
Gemini 3.0 : Comprendre le mécanisme des Signatures de Pensée (Thought Signatures)
Qu'est-ce qu'une signature de pensée ?
Les Signatures de Pensée (Thought Signatures) introduites par Gemini 3.0 sont une représentation chiffrée du processus de raisonnement interne du modèle. Lorsque vous activez include_thoughts: true, le modèle renvoie une signature chiffrée de son cheminement intellectuel dans la réponse. Vous pouvez ensuite transmettre ces signatures dans les échanges suivants pour permettre au modèle de maintenir la cohérence de sa chaîne de raisonnement.
Caractéristiques principales :
- Représentation chiffrée : Le contenu de la signature est illisible par l'humain et ne peut être analysé que par le modèle lui-même.
- Maintien de la chaîne de raisonnement : En transmettant la signature lors d'un dialogue multi-tours, le modèle peut poursuivre son raisonnement en se basant sur ses réflexions précédentes.
- Retour forcé : Par défaut, Gemini 3.0 renvoie une signature de pensée, même si elle n'a pas été explicitement demandée.
Scénarios d'utilisation réelle des signatures de pensée
| Scénario | Faut-il transmettre la signature ? | Description |
|---|---|---|
| Question simple (tour unique) | ❌ Non | Question isolée, pas besoin de maintenir une chaîne de raisonnement. |
| Dialogue multi-tours (simple) | ❌ Non | Le contexte textuel suffit, pas de dépendance à un raisonnement complexe. |
| Dialogue multi-tours (raisonnement complexe) | ✅ Oui | Par exemple : refactorisation de code, démonstration mathématique, analyse en plusieurs étapes. |
| Mode de pensée minimal (minimal) | ✅ Obligatoire | Le paramètre thinking_level: "minimal" exige la transmission de la signature, sinon une erreur 400 est renvoyée. |
Exemple de code pour la transmission de signatures de pensée
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# 第一轮:让模型设计算法
response_1 = client.chat.completions.create(
model="gemini-3.0-pro-preview",
messages=[{"role": "user", "content": "设计一个分布式限流算法"}],
extra_body={
"thinking_level": "high",
"include_thoughts": True
}
)
# 提取思考签名
signatures = []
for part in response_1.choices[0].message.content:
if hasattr(part, 'thought_signature'):
signatures.append(part.thought_signature)
# 第二轮:基于之前的推理继续优化
response_2 = client.chat.completions.create(
model="gemini-3.0-pro-preview",
messages=[
{"role": "user", "content": "设计一个分布式限流算法"},
{
"role": "assistant",
"content": response_1.choices[0].message.content,
"thought_signatures": signatures # 传递思考签名
},
{"role": "user", "content": "如何处理分布式时钟不一致问题?"}
],
extra_body={"thinking_level": "high"}
)
💡 Bonne pratique : Pour les scénarios nécessitant un raisonnement complexe sur plusieurs tours (comme la conception de systèmes, l'optimisation d'algorithmes ou la revue de code), il est recommandé de tester l'impact de la transmission des signatures via la plateforme APIYI (apiyi.com). Cette plateforme prend en charge l'intégralité du mécanisme de signature de pensée de Gemini 3.0, facilitant la validation de la qualité du raisonnement selon les différentes configurations.
Questions Fréquemment Posées
Q1 : Pourquoi Gemini 2.5 Flash renvoie-t-il toujours du contenu de pensée après avoir défini thinking_budget=0 ?
Il s'agit d'un bug connu. Dans la version Gemini 2.5 Flash Preview 04-17, la valeur thinking_budget=0 n'est pas correctement exécutée. Le forum officiel de Google a confirmé ce problème.
Solutions temporaires :
- Utilisez
thinking_budget=1(valeur minimale) au lieu de 0. - Passez à Gemini 3.0 Flash et utilisez
thinking_level="minimal". - Filtrez le contenu de pensée lors du post-traitement (si l'API renvoie un champ
thought).
Il est recommandé de passer rapidement au modèle Gemini 3.0 Flash via APIYI (apiyi.com) ; la plateforme supporte la dernière version et permet d'éviter ce genre de bugs.
Q2 : Comment savoir si j’utilise un modèle Gemini 2.5 ou 3.0 ?
Méthode 1 : Vérifier le nom du modèle
- Gemini 2.x : Le nom contient
2.5-flash,2-flash-lite. - Gemini 3.x : Le nom contient
3.0-flash,3-pro,gemini-3-flash.
Méthode 2 : Envoyer une requête de test
# 仅传递 thinking_level,观察响应
response = client.chat.completions.create(
model="your-model-name",
messages=[{"role": "user", "content": "test"}],
extra_body={"thinking_level": "low"}
)
# 如果返回 400 错误且提示不支持 thinking_level,说明是 Gemini 2.5
Méthode 3 : Consulter les en-têtes de réponse API
Certaines implémentations d'API renvoient un champ X-Model-Version dans les en-têtes, permettant d'identifier directement la version du modèle.
Q3 : Combien de tokens consomment concrètement les différents niveaux de thinking_level de Gemini 3.0 ?
Google n'a pas rendu public le budget exact de tokens correspondant à chaque thinking_level, mais donne les indications suivantes :
| thinking_level | Coût relatif | Latence relative | Profondeur de raisonnement |
|---|---|---|---|
| minimal | Très bas | Très basse | Presque aucune réflexion |
| low | Bas | Basse | Raisonnement superficiel |
| medium | Moyen | Moyenne | Raisonnement modéré |
| high | Élevé | Élevée | Raisonnement profond |
Conseils pratiques :
- Utilisez la plateforme APIYI (apiyi.com) pour comparer la consommation réelle de tokens entre les différents niveaux.
- Avec une même invite, appelez successivement les niveaux low/medium/high pour observer les différences de facturation.
- Choisissez le niveau approprié en fonction de vos besoins métier (qualité de la réponse vs coût).
Q4 : Peut-on forcer l’utilisation de thinking_budget avec Gemini 3.0 ?
Oui, mais ce n'est pas recommandé.
Pour assurer la rétrocompatibilité, Gemini 3.0 accepte toujours le paramètre thinking_budget, mais la documentation officielle précise clairement :
"Bien que
thinking_budgetsoit accepté pour la compatibilité ascendante, son utilisation avec Gemini 3 Pro peut entraîner des performances sous-optimales."
Pourquoi ?
- Le mécanisme de raisonnement interne de Gemini 3.0 a été optimisé pour
thinking_level. - Forcer l'utilisation de
thinking_budgetpourrait contourner les nouvelles stratégies de raisonnement de cette version. - Cela peut entraîner une baisse de la qualité des réponses ou une augmentation de la latence.
La bonne approche :
- Migrez vers le paramètre
thinking_level. - Référez-vous à la fonction d'adaptation des paramètres mentionnée dans la "Solution 3" pour choisir dynamiquement le bon paramètre.
Résumé
Points clés concernant les erreurs thinking_budget et thinking_level de l'API Gemini :
- Exclusivité des paramètres : Gemini 2.5 utilise
thinking_budget, alors que Gemini 3.0 utilisethinking_level. Ces deux paramètres ne peuvent pas être envoyés simultanément. - Identification du modèle : Identifiez la version via le nom du modèle. La série 2.5 utilise
thinking_budget, et la série 3.0 utilisethinking_level. - Adaptation dynamique : Utilisez une fonction d'adaptation des paramètres pour sélectionner automatiquement le bon argument en fonction du nom du modèle, évitant ainsi de coder les valeurs en dur.
- Signatures de réflexion : Gemini 3.0 introduit un mécanisme de signature de réflexion. Pour les scénarios de raisonnement complexes multi-tours, il est nécessaire de transmettre cette signature pour maintenir la continuité de la chaîne de réflexion.
- Conseil de migration : Gemini 2.5 sera retiré le 3 mars 2026. Nous vous recommandons de migrer vers la série 3.0 le plus tôt possible.
Nous vous recommandons d'utiliser APIYI (apiyi.com) pour valider rapidement l'impact réel des différentes configurations du mode réflexion. Cette plateforme prend en charge toute la gamme des modèles Gemini, propose une interface unifiée et des modes de facturation flexibles, parfaits pour vos tests comparatifs rapides et vos déploiements en production.
Auteur : Équipe technique APIYI | Pour toute question technique, n'hésitez pas à visiter APIYI (apiyi.com) pour découvrir plus de solutions d'intégration de Grand modèle de langage.