Beaucoup d'équipes intégrant l'API Gemini pour des tâches de reconnaissance d'images ont rencontré la même frustration : vous envoyez la même image et la même invite sur gemini.google.com, et le modèle identifie les détails avec précision tout en fournissant une réponse structurée ; mais une fois passé à l'API gemini-3.5-flash pour la même opération, le résultat est nettement plus sommaire, voire omet des informations cruciales. Ce sentiment que "le site web est puissant, mais l'API est faible" ne signifie pas que le modèle a été bridé, mais simplement que vous percevez le fossé technique entre l'interface web et l'API.
Cet article se concentre sur une conclusion clé : la version web de Gemini est un Agent complet qui optimise automatiquement vos invites, effectue des raisonnements en plusieurs étapes, appelle des outils et vérifie les résultats ; l'appel API, quant à lui, utilise le modèle "nu", où vous obtenez exactement ce que vous demandez. Une fois ce décalage compris, 6 astuces d'optimisation API — qui vont bien au-delà du simple "ajustement d'invite" — vous permettront de stabiliser vos résultats de reconnaissance d'images au niveau de ceux du site officiel.

Pourquoi la reconnaissance d'images via l'API Gemini est moins performante que sur le site web : Le fossé entre l'Agent et le modèle nu
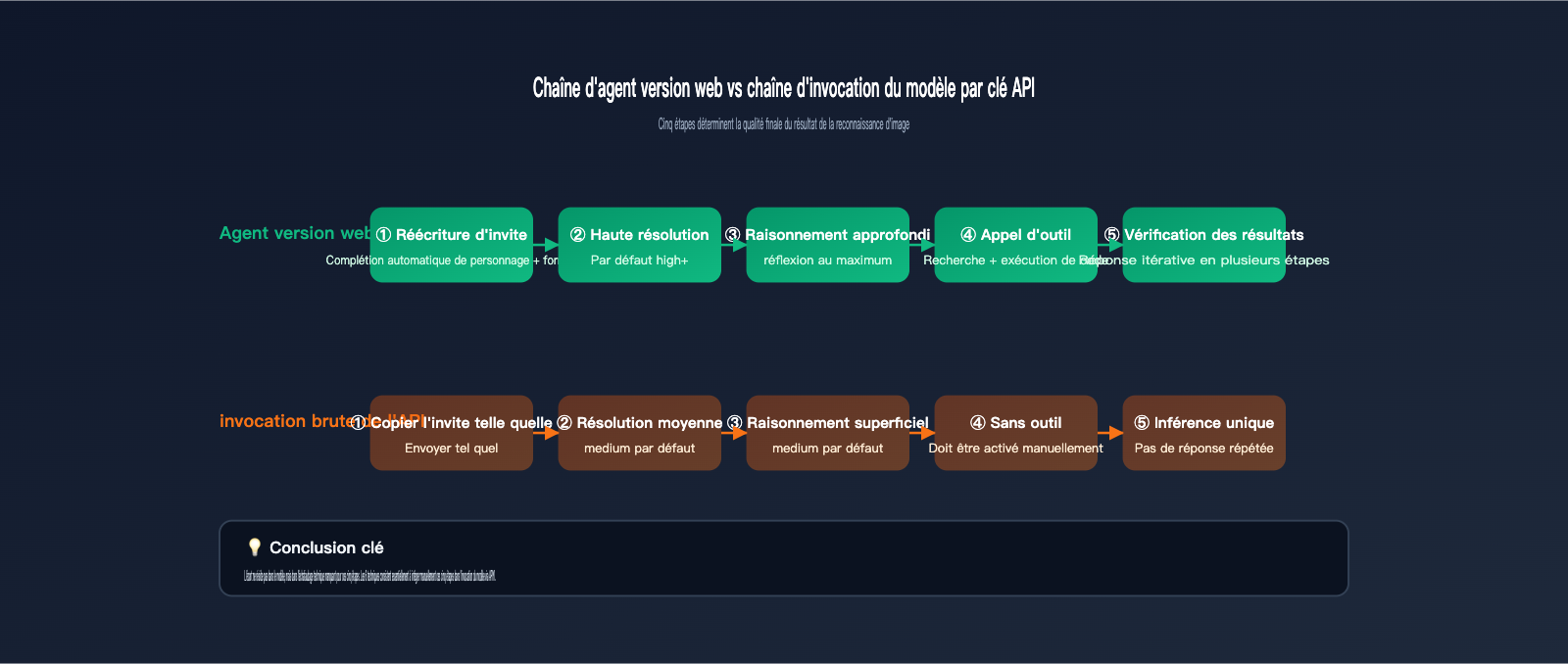
Pour bien comprendre cette différence, il faut d'abord réaliser tout ce que gemini.google.com fait pour vous entre le moment où vous soumettez une image et celui où vous obtenez la réponse finale. D'après la documentation sur les agents de vision de Google et les différences que nous avons observées sur APIYI (apiyi.com) entre le site officiel et l'API, la version web est essentiellement un Agent de niveau produit construit autour du modèle de base. Il accomplit au moins 5 tâches que vous n'avez pas explicitement demandées :
- Réécriture automatique de votre invite pour la compléter avec un rôle, une mission et un format de sortie.
- Traitement interne de l'image à une résolution plus élevée pour éviter que les détails ne soient compressés en pixels flous.
- Activation par défaut d'un budget de raisonnement intensif (similaire à
thinking_level=high), donnant au modèle le temps de "réfléchir". - Appel d'outils intégrés (exécution de code, recherche web, etc.) pour une vérification croisée lorsque nécessaire, afin de confirmer la véracité des détails.
- Formatage des résultats et jugement sur la nécessité d'une "réponse révisée" ; si la réponse est floue, il interroge à nouveau le modèle.
Lorsque vous appelez directement l'API, aucune de ces 5 étapes ne se produit automatiquement. En d'autres termes, vous utilisez un "modèle" complet, mais vous avez perdu tout l'"échafaudage technique". Le tableau ci-dessous détaille les différences entre les deux modes d'utilisation sur les maillons clés :
| Dimension de comparaison | Site web gemini.google.com | API gemini-3.5-flash |
|---|---|---|
| Traitement de l'invite | Réécriture auto, ajout de rôle/format | Utilisation brute de l'entrée utilisateur |
| Résolution d'image | Haute résolution par défaut | Résolution moyenne par défaut (réglage manuel requis) |
| Budget de raisonnement | Intensif, sans limite explicite | Moyen par défaut, réglable via thinking_level |
| Appel d'outils | Recherche et exécution de code activées | Désactivé par défaut, activation explicite requise |
| Vérification des résultats | Validation multi-étapes par l'Agent | Inférence unique, sans vérification |
| Transparence de facturation | Couverte par l'abonnement mensuel | Facturation par Token |
Nous vous suggérons d'utiliser une passerelle d'agrégation comme APIYI (apiyi.com) pour tester simultanément la même image et la même invite sur l'API gemini-3.5-flash, Claude Opus et GPT-5.5. Cela permet de déterminer rapidement si la limite actuelle de votre tâche provient des capacités du modèle ou de la chaîne technique.
Astuce n°1 pour la reconnaissance d'images avec l'API Gemini : augmentez le paramètre media_resolution
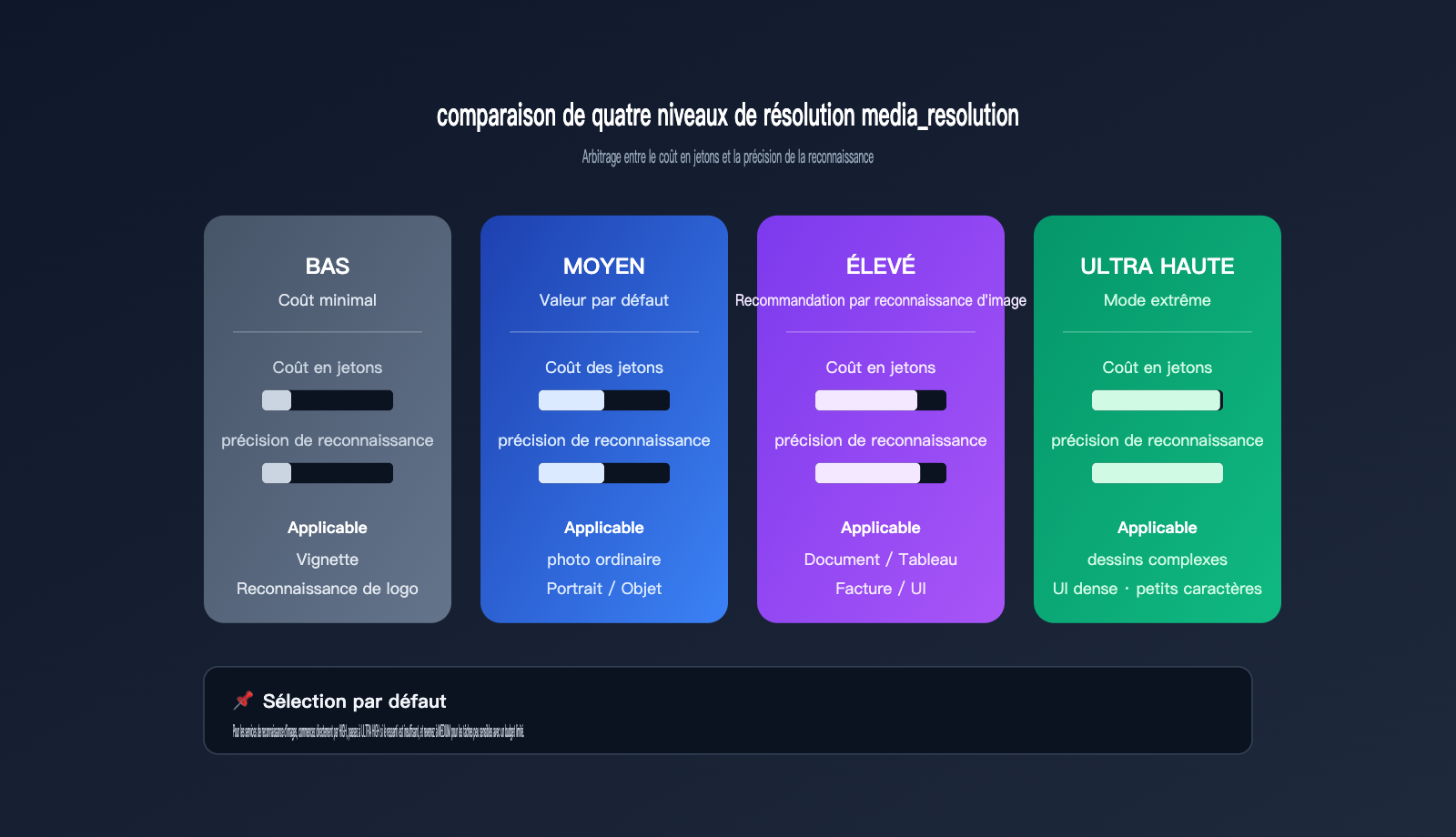
La série Gemini 3 a introduit le paramètre media_resolution, qui contrôle directement la quantité de jetons (tokens) que l'API alloue pour « voir » une image. Ce paramètre propose quatre niveaux : low, medium, high et ultra high, le réglage par défaut étant généralement medium. Pour les images riches en détails comme les petits caractères, les reçus, les schémas de circuits ou les captures d'écran d'interfaces utilisateur, le niveau medium est souvent insuffisant : le modèle compresse l'image en une carte de caractéristiques trop grossière, ce qui entraîne une perte de détails.
Le tableau ci-dessous présente les différences réelles entre ces quatre niveaux pour vous aider à choisir selon votre cas d'usage :
| Niveau de résolution | Consommation de jetons | Scénarios d'utilisation | Problèmes typiques |
|---|---|---|---|
| low | Minimale | Miniatures, logos | Petits caractères illisibles |
| medium (par défaut) | Moyenne | Photos classiques, portraits | Détails flous |
| high | Élevée | Documents, tableaux, reçus | Informations lisibles |
| ultra high | Maximale | Schémas complexes, UI dense | Qualité proche du site web |
Pour vos besoins en reconnaissance d'images, passer ce paramètre de medium à high permet souvent d'améliorer immédiatement la précision d'un cran. Si votre budget le permet et que vos tâches impliquent réellement des petits caractères ou des tableaux denses, le passage à ultra high est un choix judicieux.
# Appel de gemini-3.5-flash via APIYI, avec résolution média définie sur high
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "Extrayez tout le texte visible de l'image et présentez-le sous forme de tableau"],
config=types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH"
)
)
print(resp.text)
Lorsque vous effectuez des appels via APIYI (apiyi.com), les paramètres sont transmis directement à l'infrastructure sous-jacente sans reconditionnement par la passerelle. Vous pouvez donc transmettre les valeurs en toute confiance, comme indiqué dans la documentation officielle.
Astuce n°2 pour l'API Gemini : activez explicitement thinking_level=high
Gemini 3.5 Flash a introduit le paramètre thinking_level, qui contrôle la profondeur de réflexion interne du modèle avant de produire une réponse. Dans les tâches de reconnaissance d'images, la différence entre "bien voir" et "mal interpréter" tient souvent à la capacité du modèle à "prendre le temps de réfléchir". Par défaut, l'API privilégie la vitesse à la qualité ; pour la reconnaissance d'images, il est recommandé de régler ce paramètre sur high afin que le modèle dispose de suffisamment de temps pour effectuer des raisonnements spatiaux et des comptages, comme sur la version web.
| thinking_level | Scénarios recommandés | Ressenti |
|---|---|---|
| low | Conversations simples, style | Rapide, reconnaissance sommaire |
| medium | Questions-réponses classiques | Niveau standard |
| high (recommandé) | Documents, reçus, comptage, raisonnement spatial | Proche de l'expérience web |
La documentation officielle souligne un point contre-intuitif : une fois thinking_level=high activé, il est préférable de rédiger vos invites de manière plus directe et concise, en évitant les anciennes techniques de type "chaîne de pensée" (Chain-of-Thought) du genre "veuillez réfléchir étape par étape". Ces méthodes étaient destinées aux anciens modèles ; avec la série Gemini 3, elles risquent de provoquer une "sur-analyse".
🎯 Conseil de configuration : Utilisez la combinaison
media_resolution=HIGHetthinking_level=highcomme réglage par défaut pour vos tâches de reconnaissance d'images dans vos modèles d'appel APIYI (apiyi.com). Ajustez ensuite versultra highoulowselon les besoins réels de votre activité, afin d'éviter de tester les paramètres à chaque requête.
Astuce n°3 pour l'API Gemini : placez vos instructions dans system_instruction plutôt que dans l'invite utilisateur
Une erreur courante lors de l'utilisation de l'API consiste à tout regrouper dans l'invite utilisateur (user prompt) : la définition du rôle, les instructions de tâche, le format de sortie et la question de l'utilisateur se retrouvent mélangés dans un seul bloc de texte. Cette approche oblige le modèle à relire l'intégralité du contexte à chaque fois, alors que les "instructions système" de la version web bénéficient d'une mise en cache et d'une réutilisation.
La bonne pratique consiste à placer vos "instructions stables" dans system_instruction :
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=(
"Tu es un assistant rigoureux d'analyse d'images."
"Réponds uniquement en citant les détails clairement visibles dans l'image, sans faire de suppositions."
"Produis un JSON structuré avec les champs fixes : entities/attributes/text."
)
)
Cette méthode offre deux avantages : le modèle répond systématiquement selon des règles uniformes, ce qui rend les résultats plus stables ; et une fois le System Prompt Caching activé, les coûts d'entrée peuvent chuter jusqu'à 10 fois, ce qui est extrêmement précieux pour les tâches d'analyse d'images traitées par lots sur le long terme. Sur le tableau de bord d'APIYI (apiyi.com), vous pouvez consulter le taux de réussite du cache par ID de modèle, ce qui facilite le suivi de vos optimisations.
Astuce n°4 pour l'API Gemini : activez l'exécution de code pour permettre au modèle de "zoomer" sur les images
Dans son annonce sur la vision agentique de Gemini 3 Flash, Google a fourni une donnée claire : l'activation de l'outil d'exécution de code en complément du modèle natif permet d'obtenir une amélioration de la qualité de 5 % à 10 % en moyenne sur les tâches d'analyse d'images. Le principe est simple : le modèle peut générer en interne du code Python pour recadrer, agrandir, faire pivoter ou lire les pixels de l'image, puis se renvoyer les sous-images traitées pour analyse. C'est exactement ce que fait la version web par défaut.
L'API ne l'active pas par défaut, vous devez donc le déclarer explicitement :
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
tools=[types.Tool(code_execution=types.ToolCodeExecution())]
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "Compte tous les boutons rouges sur l'image et liste leurs positions"],
config=config
)
Pour les tâches de comptage, de raisonnement spatial ou d'analyse d'interfaces utilisateur denses — des domaines où l'exécution de code est officiellement reconnue comme un atout — il s'agit de l'optimisation au meilleur rapport coût-efficacité. Chez APIYI (apiyi.com), nous avons observé que l'activation de l'exécution de code entraîne une légère augmentation de la latence globale. Nous recommandons donc de l'activer par défaut pour les processus asynchrones et de l'utiliser à la demande pour les processus synchrones.
Astuce n°5 pour l'API Gemini : Utilisez l'API File pour les images volumineuses plutôt que l'encodage base64
Pour les images dépassant quelques Mo, de nombreuses équipes intègrent directement le fichier dans le corps de la requête via base64. Si cette méthode fonctionne bien pour les petites images, elle déclenche les limitations de Gemini dès que la taille totale de la requête dépasse 20 Mo. Résultat : certaines images sont compressées silencieusement, ce qui dégrade inévitablement la qualité de la reconnaissance.
Les seuils officiels sont pourtant très clairs :
| Taille de l'image | Méthode de transfert recommandée | Raison |
|---|---|---|
| Moins de 5 Mo | base64 en ligne | Requête légère, invocation simple |
| 5~20 Mo | Téléversement via File API | Évite l'explosion du volume de la requête |
| Plus de 20 Mo | File API obligatoire | L'encodage base64 corrompt la requête |
| Réutilisation multiple | File API recommandée | Un seul téléversement, économie de jetons |
L'autre avantage de l'API File est qu'une même image peut être réutilisée dans plusieurs requêtes, ce qui évite les coûts liés à des téléversements répétitifs. Avec la passerelle APIYI (apiyi.com), le point de terminaison de l'API File utilise le même jeu d'identifiants, vous n'avez donc pas besoin d'ouvrir un compte Google Cloud spécifique pour le téléversement d'images.
Astuce n°6 pour l'API Gemini : Construire une chaîne d'agents pour une vérification en plusieurs étapes
Après avoir maîtrisé les 5 premières astuces, vos invocations d'API sont désormais très proches de l'expérience offerte par l'interface web. Cependant, la version web possède un atout majeur : la vérification en plusieurs étapes. Après avoir généré une réponse, elle effectue une seconde inférence pour valider les faits clés et, en cas de doute, procède à une "re-génération". Cette capacité n'est pas disponible nativement via un simple interrupteur dans l'API ; vous devez donc construire une chaîne d'agents simple.
Une chaîne minimale en deux étapes fonctionne comme suit :
- Première invocation : Demandez à
gemini-3.5-flashde générer des résultats d'identification structurés (sortie JSON). - Seconde invocation : Réinjectez les résultats de la première étape avec l'image originale et demandez au modèle : "Sur la base de cette image, est-ce que chacune des conclusions suivantes est exacte ?"
Si la seconde invocation identifie un champ "inexact", vous déclenchez une troisième étape de "re-génération". Cette chaîne peut être mise en place directement sur APIYI (apiyi.com) en utilisant la même base_url et la même clé API, sans nécessiter de service supplémentaire. Pour les activités exigeant une grande précision (identification de contrats, annotation assistée d'imagerie médicale, contrôle de conformité), cette vérification multi-étapes est l'étape cruciale pour faire passer le taux de réussite de 90 % à 98 %.
| Type de tâche | Chaîne suggérée | Paramètres par étape |
|---|---|---|
| Questions-réponses générales | Étape unique | high + thinking_high |
| Extraction de documents | Étape unique + validation JSON | ultra high + thinking_high |
| Comptage complexe | Deux étapes + exécution de code | high + thinking_high + tools |
| Activités haute précision | Chaîne en trois étapes (identification → vérification → re-génération) | ultra high + thinking_high + tools |
Modèle de paramètres pratique : enchaîner les 6 astuces en un appel réutilisable
Pour vous faciliter la tâche, voici un "modèle par défaut pour les tâches d'identification" qui intègre les 6 astuces précédentes, idéal comme point de départ pour la plupart des besoins métier :
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
SYSTEM = (
"Tu es un assistant d'analyse d'image rigoureux. Cite uniquement ce qui est clairement visible dans l'image, "
"ne fais aucune supposition. Produis un JSON strict avec les champs entities/attributes/text."
)
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=SYSTEM,
tools=[types.Tool(code_execution=types.ToolCodeExecution())],
response_mime_type="application/json"
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "Identifie cette image selon les instructions SYSTEM"],
config=config
)
print(resp.text)
Lors du déploiement réel, nous vous conseillons d'extraire ce modèle côté APIYI (apiyi.com) pour créer une couche d'appel SDK unifiée. Les équipes métier n'ont alors qu'à envoyer l'image et la question, les paramètres étant injectés uniformément par la passerelle, ce qui évite à chaque projet de refaire les mêmes erreurs.

FAQ : Différences entre l'API Gemini et la version web pour la reconnaissance d'images
Q1 : Si j'active tous ces paramètres, l'API sera-t-elle toujours moins performante que la version web ?
Pour la grande majorité des cas d'usage, vous atteindrez le même niveau que le site officiel. Cependant, pour certaines tâches complexes (textes minuscules, faible luminosité, styles artistiques particuliers), l'API peut rester légèrement en retrait, car la version web utilise des pipelines d'amélioration internes non publics. Pour ces scénarios, vous pouvez effectuer des tests comparatifs sur APIYI (apiyi.com) avec d'autres modèles de vision pour identifier celui qui convient le mieux à vos besoins.
Q2 : Le paramètre thinking_level=high double-t-il les coûts ?
Cela augmente la consommation de jetons (tokens) de raisonnement interne, mais cela n'affecte que la phase de sortie. De plus, dans le coût global d'une tâche de reconnaissance d'images, les jetons liés à l'image représentent généralement la part la plus importante. Le gain de précision apporté par le niveau high justifie largement le surcoût, surtout si votre processus remplace une vérification humaine.
Q3 : Comment modifier base_url si j'utilise le SDK officiel de Google ?
Le SDK google-genai permet de rediriger les requêtes vers la passerelle APIYI (apiyi.com) via http_options={"base_url": "https://api.apiyi.com"}. Utilisez simplement la clé API générée dans votre tableau de bord APIYI ; aucun projet Google Cloud séparé n'est requis.
Q4 : Est-il possible de résoudre le problème uniquement en optimisant l'invite ?
L'optimisation de l'invite a ses limites. Elle ne peut pas compenser les capacités "hors modèle" telles que la résolution, la profondeur de raisonnement ou l'appel à des outils. Dans les 6 astuces présentées ici, seule la troisième concerne l'invite ; les 5 autres sont des leviers d'ingénierie.
Q5 : Que faire si l'API ignore les "filigranes en chinois" que la version web détecte sans problème ?
La détection de détails comme les filigranes dépend souvent d'une combinaison entre une haute résolution et l'exécution de code pour le recadrage. Réglez media_resolution sur ultra high, activez code execution, et utilisez une chaîne de vérification en deux étapes pour obtenir une reconnaissance stable.
Conclusion : Intégrer les capacités d'ingénierie de la version web dans vos appels API
Revenons à la question initiale : pourquoi la reconnaissance d'images via l'API Gemini semble-t-elle moins performante que la version web ? La réponse n'est pas que le modèle est plus faible, mais que la version web est équipée d'un "échafaudage" technique très complet. Lorsque vous appelez directement l'API gemini-3.5-flash, vous devez gérer explicitement la réécriture de l'invite, les niveaux de résolution, le budget de raisonnement, l'appel d'outils et la validation des résultats. Une fois ce point compris, l'essence de ces 6 astuces est simple : "transférer ce que la version web fait pour vous dans votre propre chaîne d'appel API".
La marche à suivre est claire : commencez par pousser media_resolution et thinking_level au maximum, intégrez vos instructions dans system_instruction en activant la mise en cache, utilisez code execution pour les tâches complexes, passez les images volumineuses par l'API File, et enfin, utilisez une chaîne d'agents en deux ou trois étapes pour garantir une haute précision. En appliquant cette combinaison et en comparant les taux de réussite et la latence sur le tableau de bord APIYI (apiyi.com), la plupart des équipes parviennent à réduire l'écart entre la version web et l'API à un niveau quasi imperceptible.
📌 Auteur : Cet article a été rédigé par l'équipe technique d'APIYI (apiyi.com). Pour plus de guides pratiques sur l'intégration et le réglage des modèles Gemini, Claude et GPT, consultez le centre d'aide d'APIYI.