Depuis le lancement de Gemini 3.5 Flash le 19 mai 2026, la question qui brûle les lèvres de la communauté des développeurs n'est pas de savoir s'il fonctionne, mais s'il peut remplacer directement le Gemini 3.1 Pro Preview utilisé depuis la fin de l'année dernière. Google insiste sur le fait que le 3.5 Flash surpasse le 3.1 Pro en matière de codage, d'invocation d'outils et de tâches d'agents. Avec un tarif de 1,50 $ / 9 $ contre 2 $ / 12 $ pour le Pro, soit une réduction de 25 %, l'offre semble alléchante. Pourtant, les scores globaux de BenchLM placent le 3.1 Pro à 92 points, contre 87 pour le 3.5 Flash. Qui croire ? Cet article propose une analyse comparative complète selon 8 dimensions, basée sur des sources primaires (Google, LLM-Stats, Artificial Analysis, Engadget, DataCamp).

Pour résumer : pour les équipes gérant des flux de travail d'agents, du codage Copilot ou du traitement de longs documents, Gemini 3.5 Flash est une affaire en or — prix réduit et intelligence d'agent accrue. En revanche, pour le raisonnement académique, la logique abstraite et les contextes ultra-longs de plus de 200 000 jetons, Gemini 3.1 Pro Preview reste inégalé. Nous vous conseillons de tester les deux modèles sur vos cas d'usage réels via le crédit gratuit d'APIYI (apiyi.com) avant de décider de la répartition de vos charges de travail.
Aperçu des différences clés : Gemini 3.5 Flash vs Gemini 3.1 Pro Preview
Bien qu'appartenant à la famille Gemini 3.x, ces deux modèles ont des positionnements distincts. Gemini 3.5 Flash est le modèle "Agentic Flash" lancé officiellement par Google le 19 mai 2026 (ID : gemini-3.5-flash), sans suffixe "preview". Gemini 3.1 Pro Preview, lancé fin 2025, est un modèle de raisonnement phare (ID : gemini-3.1-pro-preview) axé sur la résolution de problèmes complexes, conservant son statut de préversion, ce qui implique une stabilité SLA moindre.
Le tableau ci-dessous résume les spécifications clés, basées sur les données de Google AI for Developers et LLM-Stats.
| Dimension de comparaison | Gemini 3.5 Flash | Gemini 3.1 Pro Preview | Vainqueur |
|---|---|---|---|
| État de publication | GA (Disponibilité générale) | Preview (Préversion) | 3.5 Flash |
| ID du modèle | gemini-3.5-flash |
gemini-3.1-pro-preview |
— |
| Fenêtre de contexte | 1 048 576 entrée / 65 536 sortie | 1 048 576 entrée / 65 536 sortie | Égalité |
| Modalités d'entrée | Texte + Image + Audio + Vidéo | Texte + Image + Audio + Vidéo + Code | 3.1 Pro |
| Date de coupure des connaissances | Janvier 2026 | Fin 2025 | 3.5 Flash |
| Réflexion dynamique | Activée par défaut | Configuration manuelle requise | 3.5 Flash |
| Capacités d'outils | Appel de fonction / Recherche / Exécution de code | Appel de fonction / Recherche / Exécution de code | Égalité |
| Vitesse de sortie | ~289 jetons/s (4x plus rapide) | Plus lent, typiquement 60-90 jetons/s | 3.5 Flash |
| Accès via APIYI | Disponible, 0,05 $ offerts | Disponible, 0,05 $ offerts | Égalité |
🎯 Conseil d'intégration : Gemini 3.5 Flash et Gemini 3.1 Pro Preview sont tous deux disponibles sur la plateforme APIYI (apiyi.com). Vous pouvez basculer entre les deux sans coût supplémentaire en utilisant l'interface compatible OpenAI, il suffit de modifier le champ
modelentregemini-3.5-flashetgemini-3.1-pro-previewsans avoir à réécrire votre logique d'authentification ou de routage.
La vérité sur le "plus de contenu au même prix" : analyse factuelle des tarifs
Revenons à la question centrale de cet article : Gemini 3.5 Flash offre-t-il vraiment "plus de contenu au même prix" ? Pour y répondre, il faut croiser quatre dimensions : le prix officiel, le tarif avec mise en cache, le coût progressif pour les contextes ultra-longs et le score d'intelligence global.
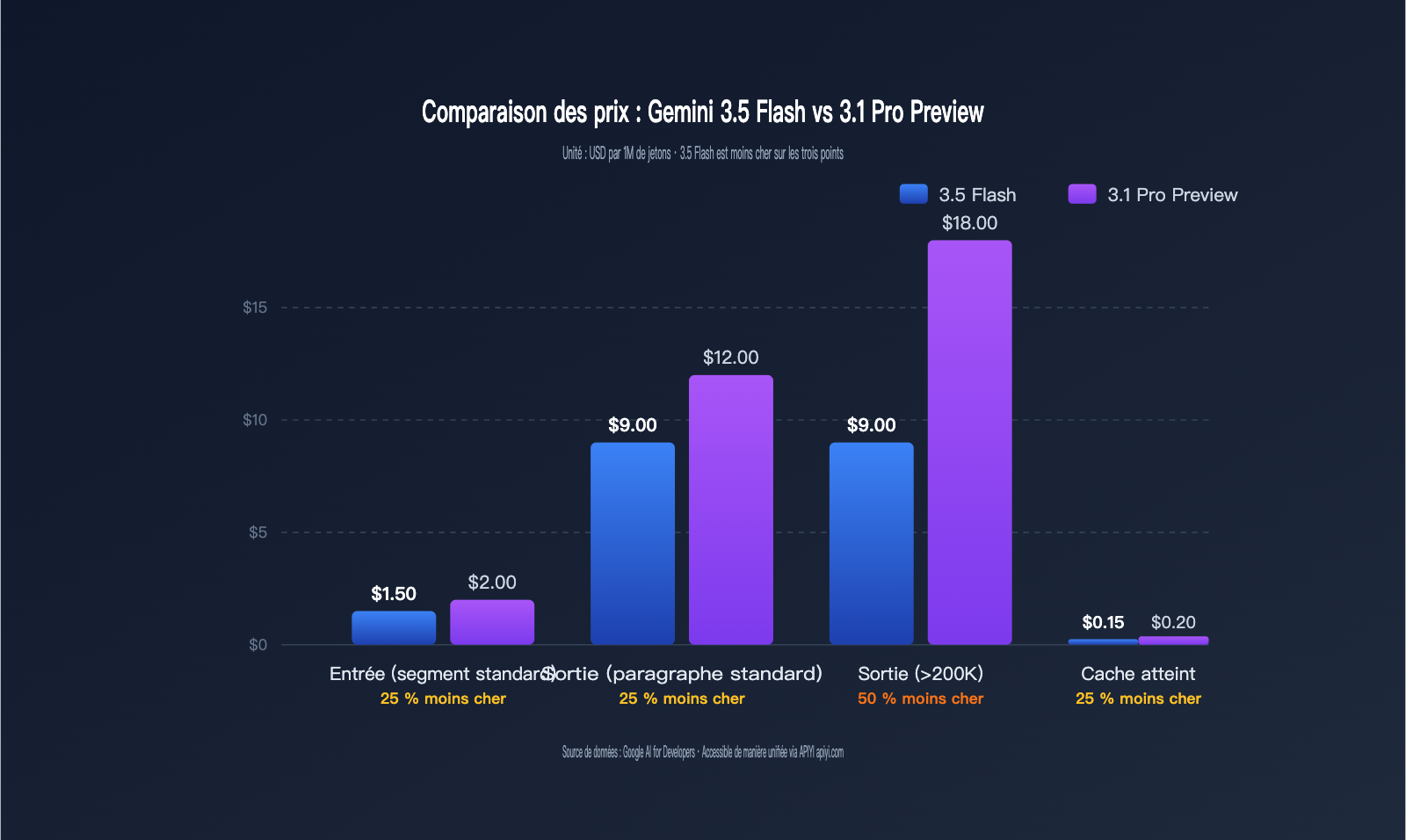
Le tableau ci-dessous présente la structure tarifaire complète des deux modèles, tous les prix étant exprimés en dollars par million de jetons.
| Poste de coût | Gemini 3.5 Flash | Gemini 3.1 Pro Preview | Différence |
|---|---|---|---|
| Entrée standard (<200K) | 1,50 $ | 2,00 $ | 25 % moins cher |
| Sortie standard (<200K) | 9,00 $ | 12,00 $ | 25 % moins cher |
| Entrée longue (>200K) | 1,50 $ (pas de palier) | 4,00 $ | 62,5 % moins cher |
| Sortie longue (>200K) | 9,00 $ (pas de palier) | 18,00 $ | 50 % moins cher |
| Entrée avec cache | 0,15 $ | 0,20 $ | 25 % moins cher |
| Écriture cache | Gratuit (cache implicite) | 0,38 $ | Nettement moins cher |
Cette comparaison met en lumière trois faits clés. Premièrement, dans la plage de contexte standard (<200K jetons), le 3.5 Flash est globalement 25 % moins cher que le 3.1 Pro Preview, ce qui équivaut à une remise permanente de 10 %. Deuxièmement, la plage de contexte ultra-long est une véritable "zone de choc" : le 3.1 Pro Preview déclenche une hausse tarifaire par paliers au-delà de 200K jetons, doublant le prix d'entrée à 4 $ / 1M et celui de sortie à 18 $ / 1M, tandis que le 3.5 Flash reste à prix fixe, réduisant les coûts de 50 à 62,5 % pour le RAG sur documents longs et les agents à contexte massif. Troisièmement, le prix d'entrée avec cache à 0,15 $ est 25 % moins cher que les 0,20 $ du 3.1 Pro, et combiné à l'écriture gratuite, cela permet de réduire les coûts réels pour des scénarios de type "longue invite système + dialogue multi-tours" à un tiers de ceux du 3.1 Pro.
💡 Conseil d'estimation des coûts : Si votre charge de travail moyenne est inférieure à 200K de contexte, choisissez le 3.5 Flash pour économiser immédiatement 25 %. Si votre contexte dépasse souvent les 200K (analyse de base de code, longs documents, RAG de base de connaissances d'entreprise), les économies réalisées avec le 3.5 Flash par rapport au 3.1 Pro pourraient suffire à doubler votre volume d'appels. Nous vous recommandons de tester votre trafic réel sur APIYI (apiyi.com) pendant une semaine avant de prendre une décision finale sur le routage des modèles.
Gemini 3.5 Flash vs 3.1 Pro : Comparaison des benchmarks et zones de supériorité
Le prix bas n'a aucun intérêt si les performances ne suivent pas. Les données comparatives publiées par Google et LLM-Stats montrent que le Gemini 3.5 Flash surpasse effectivement le Gemini 3.1 Pro sur les agents, les appels d'outils et les tâches de codage, mais reste à la traîne sur le raisonnement académique pur et abstrait. Le tableau ci-dessous résume les résultats de 8 benchmarks représentatifs.
| Benchmark | Gemini 3.5 Flash | Gemini 3.1 Pro Preview | Vainqueur | Capacité évaluée |
|---|---|---|---|---|
| Terminal-Bench 2.1 | 76,2 % | 70,3 % | 3.5 Flash | Agent de codage terminal |
| MCP Atlas | 83,6 % | 78,2 % | 3.5 Flash | Appels d'outils MCP |
| Finance Agent v2 | 57,9 % | 43,0 % | 3.5 Flash | Agent financier |
| GDPval-AA (Elo) | 1656 | 1314 | 3.5 Flash | Agent généraliste |
| CharXiv Reasoning | 84,2 % | Plus bas | 3.5 Flash | Raisonnement graphique |
| Humanity's Last Exam | 40,2 % | 44,4 % | 3.1 Pro | Raisonnement académique |
| ARC-AGI-2 | 72,1 % | 77,1 % | 3.1 Pro | Raisonnement abstrait |
| AA Intelligence Index | 55 | 57 | 3.1 Pro (+2) | Intelligence globale |
La bonne façon de lire ce tableau est de diviser les résultats en deux groupes. Le premier concerne les tâches d'agent et d'outils, où le Gemini 3.5 Flash domine largement : un écart de +14,9 points sur Finance Agent v2 et 342 points Elo sur GDPval-AA, ce qui signifie une amélioration générationnelle dans l'orchestration d'outils multi-étapes, la récupération d'erreurs et le traitement de documents structurés. Le second groupe concerne les tâches cognitives pures, où le Gemini 3.1 Pro Preview conserve une longueur d'avance : +5 points sur ARC-AGI-2 et +4,2 points sur Humanity's Last Exam.
Il convient de mentionner les données globales de BenchLM. Dans leur comparatif, le Gemini 3.1 Pro obtient 92 points contre 87 pour le Gemini 3.5 Flash. Ces 5 points d'écart proviennent principalement de la supériorité du Pro en raisonnement (77,1 vs 74,7) et en connaissances, compensée par les avantages du Flash en matière d'agentivité et de codage. En résumé : plus votre flux de travail est orienté "agent", plus le Flash est avantageux ; plus vous vous rapprochez du question-réponse statique, plus le Pro est performant. Cette différence détermine votre choix, et l'interface unifiée d'APIYI (apiyi.com) vous permet de vérifier à faible coût l'écart réel entre les deux pour vos tâches spécifiques.
Recommandations de scénarios : quand choisir Flash 3.5 et quand privilégier Pro 3.1
Plutôt que de vous laisser avec une comparaison abstraite en 8 dimensions, voici un tableau de recommandations actionnables. L'idée n'est pas de vous donner une réponse universelle, mais de vous aider à identifier la solution la plus pertinente pour chaque cas d'usage métier.
| Scénario | Modèle recommandé | Raison principale |
|---|---|---|
| Copilot de code / Assistant IDE | Gemini 3.5 Flash | +5,9 points sur Terminal-Bench 2.1, 4x plus rapide |
| Agent avec appel d'outils multi-étapes | Gemini 3.5 Flash | Avantage net sur MCP Atlas / GDPval-AA |
| RAG sur longs documents (50K-1M tokens) | Gemini 3.5 Flash | Prix compétitif, écriture en cache gratuite |
| Traitement de documents financiers/juridiques | Gemini 3.5 Flash | +14,9 points sur Finance Agent v2 |
| Concours de maths et raisonnement type AIME | Gemini 3.1 Pro Preview | Supériorité en raisonnement académique |
| Raisonnement abstrait ARC-AGI | Gemini 3.1 Pro Preview | +5 points d'avance |
| Analyse mono-tour de thèses/livres très longs | Gemini 3.1 Pro Preview | Avantage sur le raisonnement dense en contexte long |
| Chatbot conversationnel généraliste | Gemini 3.5 Flash | Meilleur rapport prix/vitesse |
| Flux de travail d'automatisation en entreprise | Gemini 3.5 Flash | Validé par Shopify, Salesforce, Databricks |
| "Couche d'outils universelle" pour routage | Gemini 3.5 Flash | Meilleur rapport performance/coût global |
Dans la pratique, la stratégie idéale n'est pas de choisir l'un ou l'autre, mais d'adopter un routage par tâche. Je vous conseille de définir Gemini 3.5 Flash comme modèle par défaut pour vos agents et le développement, tout en gardant Gemini 3.1 Pro Preview comme modèle de secours pour les tâches de raisonnement complexes. Grâce à l'interface unifiée d'APIYI (apiyi.com), vous pouvez basculer entre les modèles avec une seule clé API. Vous profitez ainsi de l'avantage économique de Flash 3.5 tout en conservant un plafond de performance élevé pour les problèmes difficiles.
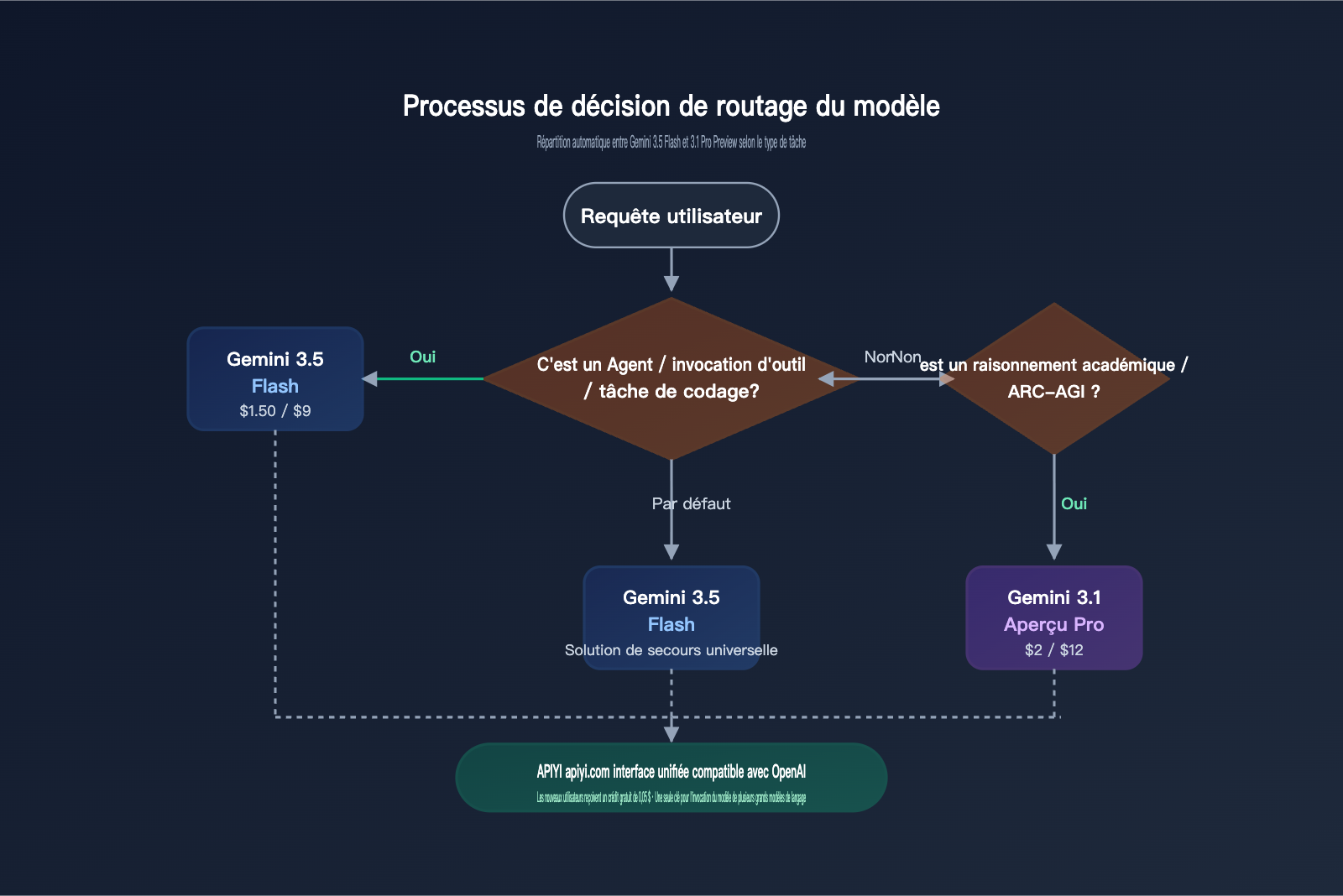
Scénarios typiques pour choisir Gemini 3.5 Flash
Si votre produit intègre un flux de travail de type "lecture de document → appel d'outils → sortie de résultats structurés", Gemini 3.5 Flash est sans doute le meilleur choix actuel. Engadget rapporte que Google l'a déjà déployé dans des environnements de production d'entreprise tels que Shopify (analyse de données), Macquarie Bank (documents financiers), Salesforce (automatisation), Ramp (OCR de factures), Xero (flux fiscaux) et Databricks (surveillance de jeux de données). Avec l'interface compatible OpenAI d'APIYI (apiyi.com), le coût de migration est quasi nul.
Scénarios où Gemini 3.1 Pro Preview reste recommandé
Si votre tâche principale relève du raisonnement complexe (type "Humanity's Last Exam"), de la reconnaissance de motifs abstraits (ARC-AGI) ou de preuves mathématiques à longue chaîne, Gemini 3.1 Pro Preview conserve un avantage stable de +2 à +5 points. Dans ces cas-là, le coût n'est pas la priorité : c'est le "plafond" de performance du modèle sur les problèmes difficiles qui compte. Vous pouvez continuer à utiliser gemini-3.1-pro-preview sur APIYI (apiyi.com) pour ces tâches, en attendant la sortie officielle de Gemini 3.5 Pro prévue pour juin.
Conseils de décision et intégration de Gemini 3.5 Flash / 3.1 Pro Preview
Pour répondre à la question centrale de cet article, "Plus de performances sans augmentation de prix ?", notre conclusion est la suivante : pour plus de 70 % des cas d'usage réels, la réponse est "oui". Le modèle 3.5 Flash vous permet d'obtenir une intelligence d'Agent supérieure à un coût réduit. Cependant, pour les 30 % de tâches complexes nécessitant un raisonnement abstrait, les scores élevés du 3.1 Pro Preview justifient toujours son maintien. La stratégie d'intégration la plus prudente n'est pas de choisir l'un ou l'autre, mais de connecter les deux modèles à votre flux de travail via un routage.
Voici un exemple d'intégration Python minimaliste pour appeler simultanément Gemini 3.5 Flash et Gemini 3.1 Pro Preview via APIYI (apiyi.com), tout en conservant une compatibilité totale avec OpenAI.
from openai import OpenAI
client = OpenAI(
api_key="VOTRE_CLE_APIYI",
base_url="https://api.apiyi.com/v1",
)
def call_gemini(model_id: str, prompt: str) -> str:
resp = client.chat.completions.create(
model=model_id,
messages=[{"role": "user", "content": prompt}],
)
return resp.choices[0].message.content
flash_answer = call_gemini("gemini-3.5-flash", "Planifie en trois étapes un Agent pour le rapport hebdomadaire des PR GitHub")
pro_answer = call_gemini("gemini-3.1-pro-preview", "Démontre que pour tout entier naturel n, n^3 - n est divisible par 6")
print("Flash:", flash_answer)
print("Pro Preview:", pro_answer)
Voir l’implémentation complète avec stratégie de routage
from openai import OpenAI
client = OpenAI(
api_key="VOTRE_CLE_APIYI",
base_url="https://api.apiyi.com/v1",
)
AGENT_KEYWORDS = ("outil", "fonction", "agent", "code", "appel", "flux de travail")
REASONING_KEYWORDS = ("démontre", "déduction", "ARC", "AIME", "concours mathématique", "olymp")
def route_model(task_prompt: str) -> str:
lower = task_prompt.lower()
if any(k in lower for k in REASONING_KEYWORDS):
return "gemini-3.1-pro-preview"
if any(k in task_prompt for k in AGENT_KEYWORDS):
return "gemini-3.5-flash"
return "gemini-3.5-flash"
def smart_call(prompt: str) -> dict:
model = route_model(prompt)
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
)
return {
"model": model,
"content": resp.choices[0].message.content,
"usage": resp.usage.model_dump() if resp.usage else None,
}
if __name__ == "__main__":
print(smart_call("Aide-moi à écrire un Agent qui appelle l'API GitHub pour récupérer les PR fusionnés cette semaine"))
print(smart_call("Démontre que l'espace de solution du problème 42 de l'ARC-AGI ne dépasse pas 8 types"))
💡 Conseil d'essai : Les nouveaux utilisateurs d'APIYI (apiyi.com) reçoivent un crédit gratuit de 0,05 $. Selon la tarification de 1,50 $/9 $ pour Gemini 3.5 Flash, vous pouvez effectuer 30 à 50 appels de longueur moyenne, ou 20 à 30 appels avec Gemini 3.1 Pro Preview (2 $/12 $). Nous vous recommandons d'utiliser ce crédit pour tester vos tâches réelles, comparer la qualité des réponses et la latence, puis décider de la répartition du trafic.
FAQ : Gemini 3.5 Flash vs 3.1 Pro Preview
Q1 : Gemini 3.5 Flash peut-il totalement remplacer Gemini 3.1 Pro Preview ?
Pas à 100 %, mais il suffit pour plus de 70 % des cas d'usage. Le 3.5 Flash est plus performant et moins cher pour les Agents, l'appel d'outils, le codage et le traitement de longs documents. Cependant, pour des tâches comme "Humanity's Last Exam", "ARC-AGI-2" ou le raisonnement mathématique complexe, le 3.1 Pro Preview conserve une avance de 2 à 5 points. Nous suggérons d'utiliser les deux modèles sur APIYI (apiyi.com) et d'effectuer un routage basé sur le type de tâche.
Q2 : Pourquoi dit-on que Gemini 3.5 Flash offre « plus de performances sans augmentation de prix » ?
L'amélioration se manifeste sur trois points : d'abord, les benchmarks Agent/Codage surpassent le 3.1 Pro (Terminal-Bench 2.1 +5,9 pts, MCP Atlas +5,4 pts, Finance Agent v2 +14,9 pts) ; ensuite, la date limite de connaissance est repoussée à janvier 2026 ; enfin, la réflexion dynamique est activée par défaut. Quant au prix, le tarif standard de 1,50 $/9 $ est 25 % moins cher que celui du 3.1 Pro (2 $/12 $), avec un écart atteignant 50 à 62 % au-delà de 200 000 jetons de fenêtre de contexte.
Q3 : Combien de temps Gemini 3.1 Pro Preview sera-t-il maintenu ? Faut-il migrer maintenant ?
Google n'a pas encore annoncé de date de fin de vie officielle, mais selon les informations disponibles, Gemini 3.5 Pro devrait sortir en juin 2026, date à laquelle le 3.1 Pro Preview passera probablement en maintenance. Nous vous conseillons de ne pas supprimer le 3.1 Pro Preview immédiatement, mais de le rétrograder en "modèle de secours pour raisonnement complexe", tout en basculant le trafic principal vers le 3.5 Flash. La plateforme APIYI (apiyi.com) suivra le cycle de vie des modèles et vous alertera avant toute mise hors service.
Q4 : Y a-t-il une différence entre Gemini 3.5 Flash et 3.1 Pro pour les entrées multimodales ?
La différence est minime. Les deux modèles supportent le texte, les images, l'audio et la vidéo. Le Gemini 3.1 Pro Preview liste explicitement le "code" comme une modalité distincte dans sa documentation, ce qui se traduit par une gestion légèrement plus stable des blocs de code volumineux. Si votre tâche principale est la "compréhension d'image + appel d'outil", commencez par le Gemini 3.5 Flash, car il est 4 fois plus rapide et supporte la réflexion dynamique. Ne repassez au 3.1 Pro Preview que si vous devez traiter des bases de code massives en une seule fois. Vous pouvez basculer entre les deux en un clic via APIYI (apiyi.com).
Résumé : La synergie idéale entre Gemini 3.5 Flash et 3.1 Pro Preview
Revenons à la question centrale : "Plus de performances sans augmentation de prix ?" Sur le plan tarifaire, le Gemini 3.5 Flash est 25 % moins cher sur les segments standards, jusqu'à 62,5 % sur les contextes ultra-longs, et permet une économie supplémentaire de 25 % avec la mise en cache. C'est donc un pari gagné. Côté capacités, il surpasse le 3.1 Pro sur les agents et le codage, bien qu'il reste légèrement en retrait (de 2 à 5 points) sur le raisonnement académique et abstrait. En résumé : une amélioration dans 70 % des cas et un léger compromis dans les 30 % restants.
La conclusion la plus pragmatique est de ne pas considérer ces deux modèles comme des concurrents, mais comme des partenaires. Utilisez Gemini 3.5 Flash comme moteur principal pour vos agents et le développement de code, et gardez Gemini 3.1 Pro Preview comme solution de repli pour les raisonnements complexes. Grâce à l'interface compatible OpenAI d'APIYI (apiyi.com), vous pouvez facilement basculer entre les deux. Les nouveaux utilisateurs reçoivent un crédit gratuit de 0,05 $ pour tester les deux modèles sans frais et déterminer la répartition optimale pour leur flux de production.
Auteur : Équipe technique d'APIYI · apiyi.com
Date de publication : 20 mai 2026
Références : Google AI for Developers, Google DeepMind Model Card, LLM-Stats, Artificial Analysis, Engadget, DataCamp, BenchLM, OfficeChai