Google Gemma 4 est officiellement disponible. Il adopte pour la première fois une licence open source complète Apache 2.0 et propose 4 modèles couvrant tous les scénarios de puissance de calcul, du Raspberry Pi aux centres de données. En tant que version open source de la technologie Gemini 3, Gemma 4 surpasse largement son prédécesseur en matière de raisonnement, de codage, de vision et de gestion de contextes longs.
Valeur ajoutée : En lisant cet article, vous maîtriserez la sélection parmi les 4 modèles Gemma 4, leurs innovations architecturales, les limites de leurs capacités multimodales et les prérequis matériels pour un déploiement local.

Aperçu des informations clés sur Gemma 4
Gemma 4 a été lancé le 2 avril 2026 lors de l'événement Google Cloud Next. Construit sur les recherches issues de Gemini 3, il représente la quatrième génération de la famille de modèles open source de Google.
| Élément | Détails |
|---|---|
| Date de sortie | 2 avril 2026 |
| Nombre de modèles | 4 (E2B / E4B / 26B-A4B / 31B) |
| Licence | Apache 2.0 (une première, auparavant sous licence propriétaire Google) |
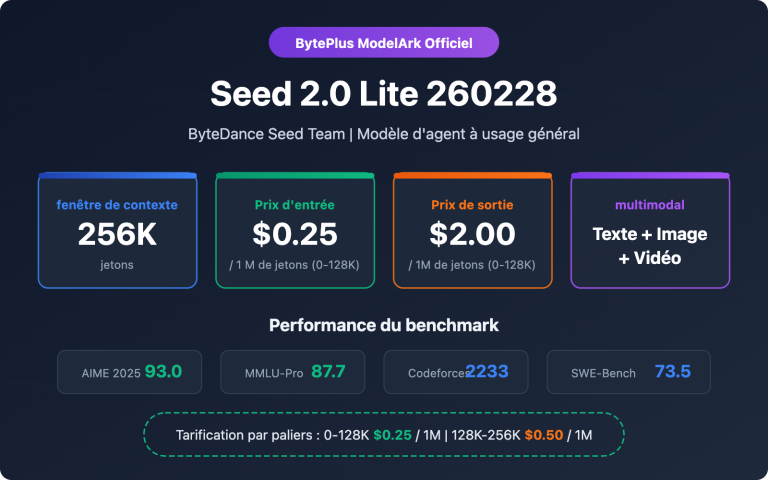
| Fenêtre de contexte max. | 256K tokens (31B et 26B-A4B) |
| Multimodal | Texte + image + vidéo + audio (E2B/E4B) |
| Points forts de l'architecture | Première variante MoE, technologie PLE, attention hybride |
| Plateformes disponibles | Hugging Face, Google AI Studio, Vertex AI, Ollama, etc. |
Vue d'ensemble des quatre modèles Gemma 4
| Modèle | Paramètres effectifs | Paramètres totaux | Architecture | Contexte | Multimodal |
|---|---|---|---|---|---|
| Gemma 4 E2B | 2.3B | 5.1B | Dense | 128K | Texte+image+vidéo+audio |
| Gemma 4 E4B | 4.5B | 8B | Dense | 128K | Texte+image+vidéo+audio |
| Gemma 4 26B-A4B | 3.8B activés | 25.2B | MoE | 256K | Texte+image+vidéo |
| Gemma 4 31B | 30.7B | 30.7B | Dense | 256K | Texte+image+vidéo |
Règles de nommage : Le préfixe "E" signifie "Paramètres effectifs" (Effective Parameters), car la technologie PLE rend le nombre total de paramètres supérieur aux paramètres effectifs. 26B-A4B indique une architecture MoE avec 26B de paramètres totaux et 4B de paramètres activés par token.
🎯 Conseil technique : Les 4 modèles Gemma 4 couvrent tous les scénarios, de l'appareil en périphérie (edge) à l'inférence dans le cloud. Si vous devez comparer les performances entre plusieurs modèles open source, je vous recommande d'utiliser la plateforme APIYI apiyi.com pour une intégration unifiée, facilitant ainsi le basculement et l'évaluation des différents modèles.
Gemma 4 vs Gemma 3 : La plus grande avancée générationnelle de l'histoire
Google affirme que Gemma 4 représente "la plus grande amélioration de performance sur une seule génération dans le domaine des modèles open source". Les données de benchmark confirment pleinement cette déclaration.
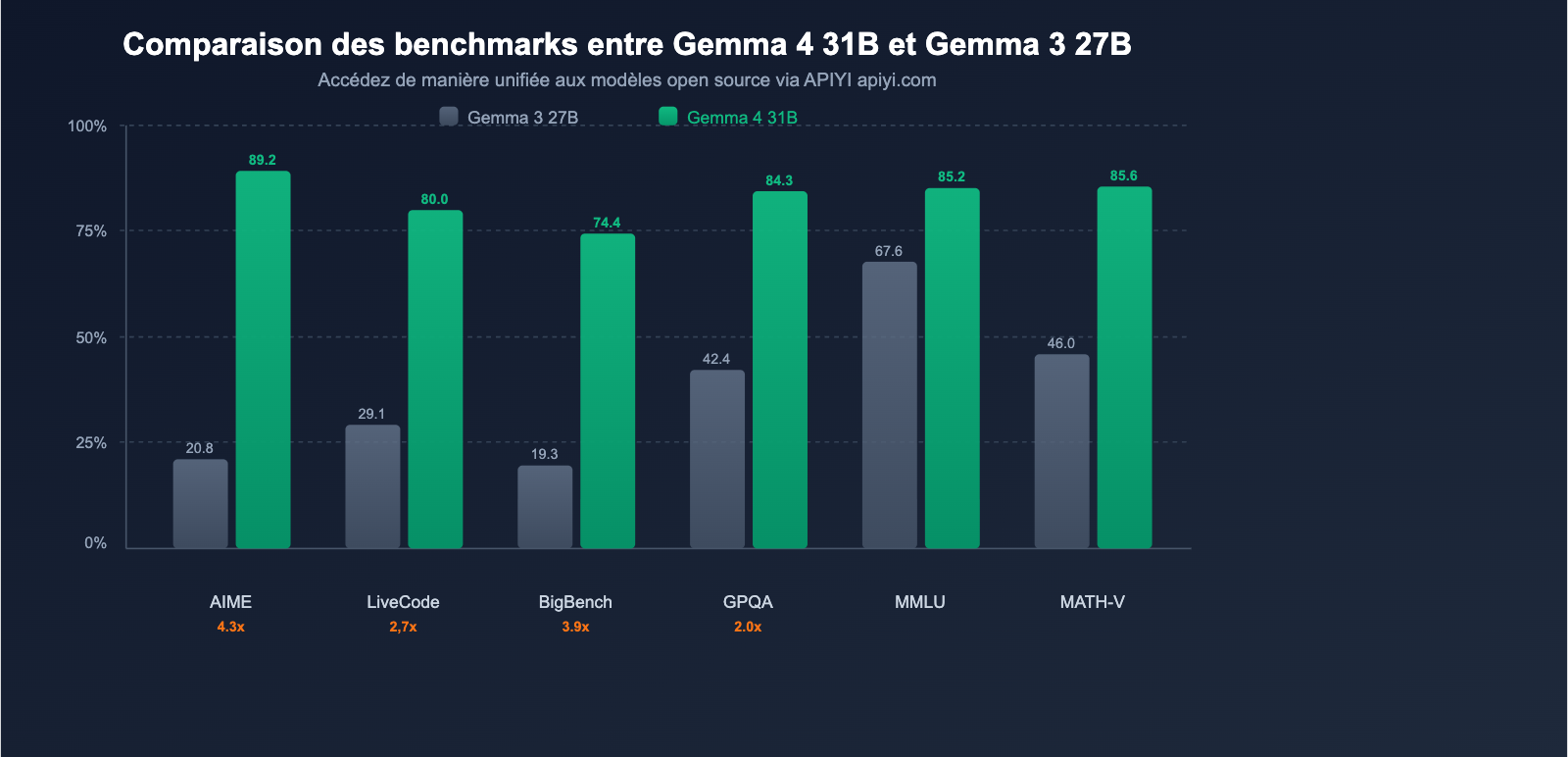
Comparaison des benchmarks clés
| Benchmark | Gemma 3 27B | Gemma 4 31B | Amélioration |
|---|---|---|---|
| AIME 2026 (raisonnement mathématique) | 20.8% | 89.2% | +68.4 pts (4.3x) |
| LiveCodeBench v6 (codage) | 29.1% | 80.0% | +50.9 pts (2.7x) |
| BigBench Extra Hard (raisonnement) | 19.3% | 74.4% | +55.1 pts (3.9x) |
| GPQA Diamond (raisonnement scientifique) | 42.4% | 84.3% | +41.9 pts (2.0x) |
| MMLU Pro (connaissances) | 67.6% | 85.2% | +17.6 pts |
| MATH-Vision (mathématiques visuelles) | 46.0% | 85.6% | +39.6 pts |
| MRCR 128K (contexte long) | 13.5% | 66.4% | +52.9 pts |
Constat clé : Le raisonnement mathématique AIME est passé de 20,8 % à 89,2 %, soit une multiplication par 4,3 ; le codage LiveCodeBench est passé de 29,1 % à 80,0 %, soit une multiplication par 2,7. Il ne s'agit pas d'une amélioration progressive, mais d'un saut générationnel.
Données complètes des benchmarks pour les 4 modèles
| Benchmark | 31B | 26B-A4B | E4B | E2B |
|---|---|---|---|---|
| MMLU Pro | 85.2% | 82.6% | 69.4% | 60.0% |
| AIME 2026 | 89.2% | 88.3% | 42.5% | 37.5% |
| GPQA Diamond | 84.3% | 82.3% | 58.6% | 43.4% |
| LiveCodeBench v6 | 80.0% | 77.1% | 52.0% | 44.0% |
| MATH-Vision | 85.6% | 82.4% | 59.5% | 52.4% |
| MMMU Pro (visuel) | 76.9% | 73.8% | 52.6% | 44.2% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 |
Avantage d'efficacité du MoE : Le modèle 26B-A4B atteint environ 97 % des performances du modèle 31B Dense avec seulement 3,8B de paramètres activés, ce qui réduit considérablement les coûts d'inférence. Sur LMArena, le 26B-A4B (~1441 ELO) surpasse même le gpt-oss-120B d'OpenAI.
💡 Conseil de sélection : Choisissez le 31B pour des performances optimales, ou le 26B-A4B pour un meilleur rapport coût-efficacité (97 % des performances avec seulement 12 % des paramètres activés). La plateforme APIYI apiyi.com vous permet de comparer rapidement les performances réelles de ces deux versions dans vos scénarios métier spécifiques.
Les 6 innovations technologiques majeures de l'architecture Gemma 4
Gemma 4 introduit plusieurs avancées technologiques au niveau de son architecture, ce qui explique son bond en termes de performances.
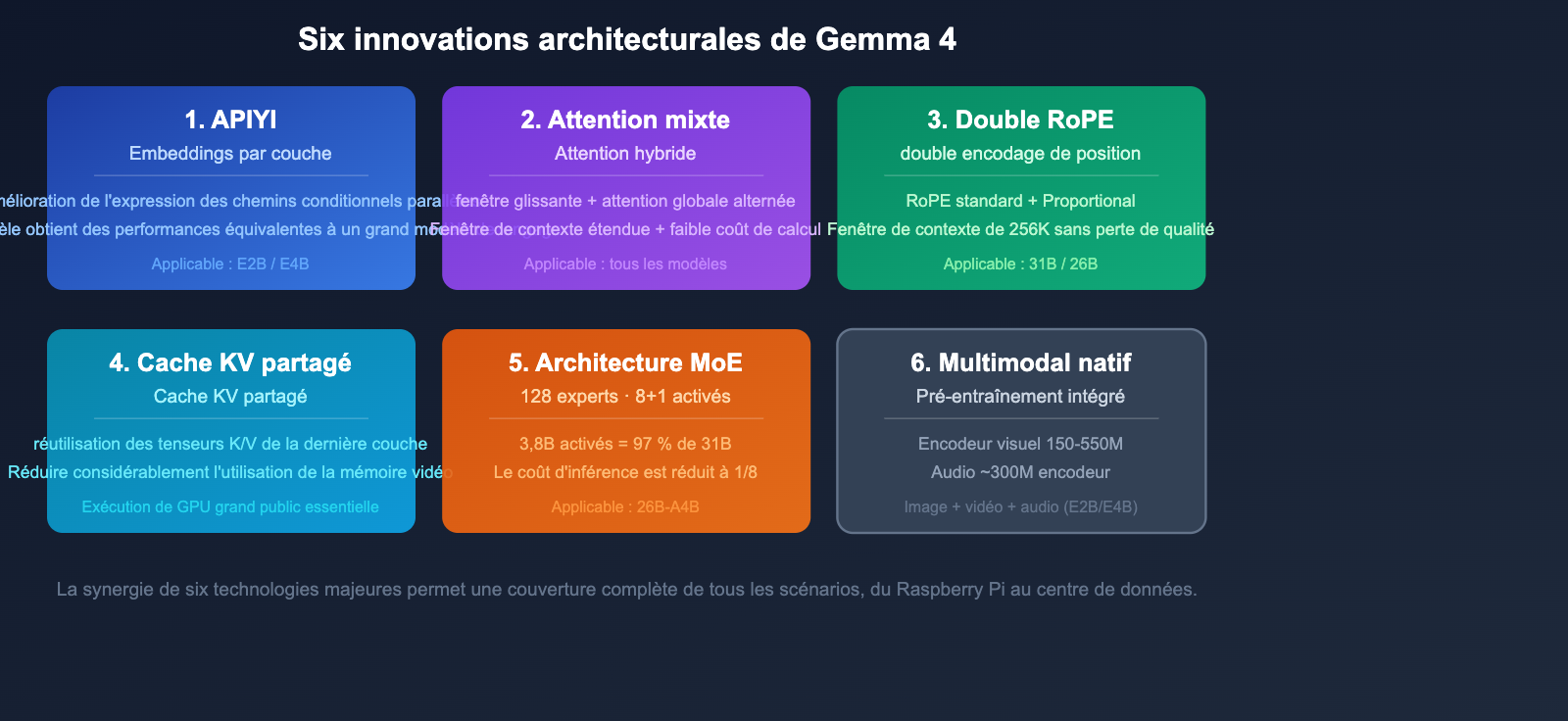
Technique 1 : Per-Layer Embeddings (PLE)
Le PLE ajoute un chemin conditionnel parallèle en dehors du flux résiduel principal, générant des vecteurs de jetons dédiés pour chaque couche du décodeur. Cette technique améliore la capacité d'expression des petits modèles, permettant au modèle E2B (2,3 milliards de paramètres effectifs) d'obtenir des performances bien supérieures à ce que suggère sa taille.
Technique 2 : Attention hybride (Hybrid Attention)
Utilisation alternée de couches d'attention à fenêtre glissante locale et d'attention globale sur le contexte complet :
- Couche à fenêtre glissante : traite le contexte local (E2B/E4B : 512 jetons ; 31B/26B : 1024 jetons).
- Couche d'attention globale : traite l'intégralité du contexte.
Cette conception hybride réduit considérablement les coûts de calcul tout en préservant la gestion des contextes longs.
Technique 3 : Encodage de position Dual RoPE
- La couche à fenêtre glissante utilise le RoPE standard.
- La couche d'attention globale utilise le Proportional RoPE.
Cette conception à double RoPE permet d'atteindre une fenêtre de contexte de 256 000 jetons sans perte de qualité.
Technique 4 : Cache KV partagé
Les N dernières couches réutilisent les tenseurs K/V de la dernière couche non partagée du même type, ce qui réduit considérablement le volume de calcul et l'utilisation de la mémoire vidéo. C'est l'une des technologies clés permettant à Gemma 4 de faire tourner de grands modèles sur du matériel grand public.
Technique 5 : Mélange d'experts MoE (26B-A4B)
Gemma 4 introduit pour la première fois une variante MoE :
- 128 petits experts.
- 8 experts activés par jeton + 1 expert partagé.
- Atteint environ 97 % des performances d'un modèle dense de 31B avec seulement 3,8B de paramètres activés.
Technique 6 : Multimodalité native
Les capacités visuelles et audio sont directement intégrées dès la phase de pré-entraînement :
- Encodeur visuel : ~150M de paramètres pour E2B/E4B ; ~550M pour 31B/26B.
- Encodeur audio : type USM conformer, ~300M de paramètres (uniquement pour E2B/E4B).
- Prise en charge d'images à rapport hauteur/largeur variable, avec un budget de jetons configurable (70 à 1120 jetons).
Analyse détaillée des capacités multimodales et Agent de Gemma 4
Gemma 4 n'est pas seulement un modèle de conversation ; c'est un système multimodal doté de capacités d'Agent complètes.
Capacités d'entrée multimodale
| Modalité | E2B | E4B | 31B | 26B-A4B |
|---|---|---|---|---|
| Texte | ✅ | ✅ | ✅ | ✅ |
| Image | ✅ | ✅ | ✅ | ✅ |
| Vidéo (max 60s, 1fps) | ✅ | ✅ | ✅ | ✅ |
| Audio (max 30s) | ✅ | ✅ | ❌ | ❌ |
Les capacités visuelles couvrent :
- Détection d'objets et sortie de boîtes englobantes (format JSON natif)
- Détection et pointage d'éléments d'interface graphique (GUI)
- Analyse de documents/PDF, compréhension de graphiques
- Compréhension d'écrans/interfaces utilisateur
- Entrées croisées texte-image (mélange dans n'importe quel ordre)
Appel de fonction natif et capacités d'Agent
Gemma 4 intègre des capacités d'appel de fonction dès la phase d'entraînement, et non via un réglage fin ultérieur :
- Appel de fonction natif : optimisé directement lors de l'entraînement, prend en charge l'orchestration multi-outils
- Extended Thinking : permet un raisonnement en plusieurs étapes via
enable_thinking=True - Sortie structurée : sortie JSON native, idéale pour l'intégration API
- Flux d'Agent multi-tours : prend en charge la boucle d'Agent autonome "planifier-exécuter-observer"
# Exemple d'appel de fonction Gemma 4 (via l'interface unifiée APIYI)
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Obtenir la météo pour une ville donnée",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string"}
},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="gemma-4-31b-it",
messages=[{"role": "user", "content": "Quel temps fait-il à Pékin aujourd'hui ?"}],
tools=tools,
tool_choice="auto",
)
🚀 Démarrage rapide : L'appel de fonction natif de Gemma 4 en fait un choix idéal pour construire des Agents IA. Nous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour une intégration rapide, compatible avec l'interface OpenAI, sans besoin d'adaptation supplémentaire.
Guide matériel pour le déploiement local de Gemma 4
La licence Apache 2.0 signifie que vous pouvez déployer Gemma 4 librement sur n'importe quel matériel. Voici les besoins matériels pour chaque modèle.
Aperçu des besoins matériels
| Modèle | Matériel minimal | Scénario de déploiement typique |
|---|---|---|
| E2B (2.3B) | <1.5 Go de RAM | Raspberry Pi 5 (133 tok/s pré-remplissage, 7.6 tok/s décodage) |
| E4B (4.5B) | NPU/GPU mobile | Appareils mobiles, Apple Silicon (MLX) |
| 26B-A4B (MoE) | GPU grand public unique (quantifié) | Station de travail personnelle, petit serveur |
| 31B (Dense) | H100 80 Go unique (FP16) | Inférence cloud, centre de données |
Matériel et frameworks pris en charge
| Matériel/Framework | État du support |
|---|---|
| NVIDIA (H100/B200/RTX) | ✅ Support complet de la gamme |
| Google TPU (Trillium/Ironwood) | ✅ Optimisation native |
| Apple Silicon (MLX) | ✅ mlx-community/gemma-4-* |
| AMD ROCm | ✅ Supporté |
| Qualcomm NPU (IQ8) | ✅ Inférence mobile |
| GGUF (llama.cpp/Ollama) | ✅ Quantification 2-bit/4-bit |
| ONNX (WebGPU/Navigateur) | ✅ onnx-community/gemma-4-* |
| NVIDIA NIM | ✅ Déploiement conteneurisé |
Le modèle E2B peut fonctionner sur un Raspberry Pi 5 avec une vitesse de décodage de 7,6 tokens par seconde, ce qui ouvre de toutes nouvelles possibilités pour les applications d'IA en périphérie (Edge AI).
Licence Apache 2.0 : pourquoi cette fois est différente
Gemma 4 adopte pour la première fois la licence Apache 2.0, ce qui constitue un changement majeur. Auparavant, tous les modèles Gemma utilisaient la licence propriétaire de Google, assortie de restrictions d'utilisation spécifiques et de droits de résiliation.
Comparaison des licences
| Dimension | Gemma 3 (Licence Google) | Gemma 4 (Apache 2.0) |
|---|---|---|
| Usage commercial | Conditions limitées | ✅ Totalement libre |
| Modification et distribution | Soumis à des clauses additionnelles | ✅ Totalement libre |
| Modèles dérivés | Restrictions appliquées | ✅ Totalement libre |
| Droit de résiliation | Google conserve un droit de résiliation | ❌ Irrévocable |
| Octroi de brevets | Limité | ✅ Octroi explicite |
Apache 2.0 signifie que :
- Les entreprises peuvent l'utiliser en toute sérénité pour des produits commerciaux, sans risque juridique.
- Il est possible de modifier et de distribuer librement des modèles dérivés.
- La stratégie s'aligne sur l'open source de Meta Llama et DeepSeek.
- Le seuil de conformité pour l'adoption en entreprise est considérablement réduit.
💰 Optimisation des coûts : Licence Apache 2.0 + déploiement local = zéro coût d'invocation du modèle. Pour les scénarios à fort volume d'inférence, le déploiement local de Gemma 4 peut s'avérer plus économique que l'utilisation via API. Si vous souhaitez comparer la rentabilité entre le déploiement local et l'invocation du modèle, vous pouvez utiliser la plateforme APIYI apiyi.com pour valider les résultats avant de décider d'un déploiement local.
Obtention et prise en main rapide de Gemma 4
Canaux de téléchargement des modèles
| Plateforme | Modèles disponibles | Usage |
|---|---|---|
| Hugging Face | Les 4 versions (base + IT) | Téléchargement général, recherche |
| Google AI Studio | 31B, 26B MoE | Essai en ligne gratuit |
| Vertex AI | Les 4 versions | Déploiement en entreprise |
| Ollama / llama.cpp | Versions quantifiées GGUF | Déploiement local rapide |
| Google AI Edge Gallery | E4B, E2B | Déploiement sur mobile |
Déploiement en un clic avec Ollama
# Déployer Gemma 4 31B (recommandé)
ollama run gemma4:31b
# Déployer la version MoE (meilleur rapport performance/coût)
ollama run gemma4:26b-a4b
# Déployer la version légère (appareils en périphérie)
ollama run gemma4:e4b
Support du fine-tuning
Gemma 4 propose un écosystème complet pour le fine-tuning :
| Framework | Méthodes supportées |
|---|---|
| TRL | SFT, DPO, apprentissage par renforcement (incluant le multimodal) |
| PEFT | LoRA, QLoRA (via bitsandbytes) |
| Vertex AI | Entraînement managé |
| Unsloth Studio | Fine-tuning via interface graphique |
Les encodeurs visuels et audio peuvent être gelés, permettant de ne fine-tuner que la partie textuelle, ce qui réduit considérablement les coûts de fine-tuning.
🎯 Conseil technique : Nous vous recommandons de tester d'abord les performances de Gemma 4 via l'invocation du modèle sur la plateforme APIYI apiyi.com. Une fois que vous avez confirmé que le modèle répond à vos besoins, vous pourrez procéder au déploiement local ou au fine-tuning pour éviter tout gaspillage de ressources.
FAQ
Q1 : Quel est le lien entre Gemma 4 et Gemini 3 ?
Gemma 4 est construit sur les recherches fondamentales de Gemini 3 ; on peut le considérer comme la version open source de la technologie Gemini 3. Bien que la taille du modèle Gemma 4 soit plus réduite (maximum 31B contre plusieurs centaines de milliards pour Gemini), il adopte les mêmes innovations d'architecture centrale. Vous pouvez utiliser la plateforme APIYI apiyi.com pour tester et comparer simultanément Gemma 4 et la série de modèles Gemini.
Q2 : Comment choisir entre le modèle MoE 26B et le modèle Dense 31B ?
Si votre matériel est limité ou si vous avez besoin d'un débit élevé, choisissez le 26B-A4B MoE : il atteint environ 97 % des performances du 31B avec seulement 3,8B de paramètres activés. Si vous recherchez des performances optimales et disposez d'un GPU de 80 Go, optez pour le 31B Dense. Le coût d'inférence de la version MoE représente environ 1/8 de celui de la version Dense.
Q3 : Pour quels scénarios les modèles E2B et E4B sont-ils adaptés ?
Le modèle E2B est idéal pour les scénarios de périphérie extrême (Raspberry Pi, appareils IoT, smartphones), tandis que le E4B convient aux appareils mobiles et au déploiement sur PC légers. Tous deux prennent en charge l'entrée audio, ce que ne permettent pas les modèles 31B et 26B. Si votre application nécessite une compréhension vocale, vous devez impérativement choisir E2B ou E4B.
Q4 : Quel est l’impact de la licence Apache 2.0 sur l’utilisation commerciale ?
La licence Apache 2.0 est l'une des licences open source les plus permissives ; elle autorise une utilisation commerciale, une modification et une distribution totalement libres et irrévocables. Contrairement à la licence propriétaire de Google pour Gemma 3, les entreprises n'ont pas à craindre de risques de conformité. Vous pouvez tester les modèles via l'API sur la plateforme APIYI apiyi.com, puis procéder à un déploiement local pour vos produits commerciaux une fois les résultats validés.
Conclusion
Gemma 4 marque une mise à jour majeure de la stratégie IA open source de Google. La licence Apache 2.0 lève les barrières à l'utilisation ; les quatre modèles couvrent tous les scénarios de calcul, du Raspberry Pi au H100. Avec des bonds de performance générationnels de 4,3x sur AIME et 2,7x sur LiveCodeBench, ainsi qu'un support multimodal natif et l'appel de fonctions, il s'impose comme le modèle de base privilégié pour le développement d'agents open source.
Points clés à retenir :
- Licence : Première licence Apache 2.0, utilisation commerciale totalement libre
- Modèles : 4 variantes couvrant de 2B à 31B, incluant le premier modèle MoE
- Performance : AIME +68 pts (4,3x), LiveCodeBench +51 pts (2,7x)
- Multimodalité : Intégration native de texte, image, vidéo et audio
- Agent : Appel de fonctions natif + Extended Thinking
- Déploiement : Couverture complète du Raspberry Pi au H100, formats GGUF/ONNX/MLX
Nous vous recommandons d'accéder rapidement à la série Gemma 4 via APIYI apiyi.com pour comparer les performances réelles des différents modèles sous une interface unifiée.
Références
- Blog officiel de Google – Lancement de Gemma 4 :
blog.google/innovation-and-ai/technology/developers-tools/gemma-4/ - Hugging Face – Modèle Gemma 4 :
huggingface.co/blog/gemma4 - Google AI – Fiche technique du modèle Gemma 4 :
ai.google.dev/gemma/docs/core/model_card_4
Cet article a été rédigé par l'équipe technique d'APIYI. Pour plus de tutoriels sur l'utilisation des modèles d'IA, veuillez consulter APIYI sur apiyi.com.