Note de l'auteur : Le modèle phare d'xAI, Grok 4.20 Beta, continue d'évoluer avec un taux d'hallucination de 78 %, le plus bas du secteur. Il intègre une collaboration multi-agents native à 4 agents, une fenêtre de contexte de 2 millions de jetons, ainsi que la prise en charge des conversations vocales et de la génération d'images et de vidéos. Cet article propose une analyse approfondie de ses capacités fondamentales et de sa valeur réelle.
xAI, l'entreprise d'Elon Musk, a lancé Grok 4.20 Beta début 2026, et le modèle n'a cessé d'être optimisé depuis. L'atout le plus distinctif de ce modèle est son "taux d'hallucination le plus bas du secteur" — atteignant un taux de non-hallucination de 78 % lors des tests d'Artificial Analysis Omniscience, tout en introduisant une architecture multi-agents native à 4 agents et une fenêtre de contexte de 2 millions de jetons. La mise à jour d'avril a encore amélioré le suivi des instructions, la composition LaTeX et la précision du déclenchement de la recherche d'images.
Valeur ajoutée : Découvrez en 5 minutes les capacités clés de Grok 4.20 Beta, les différences entre ses 3 variantes de modèles, ses capacités multimodales et son positionnement par rapport à Claude et GPT.

Aperçu des informations clés de Grok 4.20 Beta
| Élément | Détails |
|---|---|
| Date de sortie | 17 février 2026 (bêta publique) / 10 mars (API) |
| Développeur | xAI (Elon Musk) |
| Positionnement | Fiabilité élevée + multi-agents + multimodal phare |
| Taux d'hallucination | 78 % de non-hallucination (le plus élevé du secteur) |
| Fenêtre de contexte | 2 millions de jetons (contre 256K pour Grok 4) |
| Variantes de modèle | Raisonnement / Sans raisonnement / Multi-agents |
| Vitesse de sortie | 247,8 jetons/s (médiane des modèles de raisonnement : 68,5) |
| Tarification | Entrée 2 $/MTok, sortie 6 $/MTok |
| Multimodal | Entrée/sortie texte/image/vidéo/voix |
Positionnement sur le marché de Grok 4.20 Beta
Dans le paysage concurrentiel des grands modèles de langage, Grok 4.20 Beta a choisi une voie différenciée : ne pas chercher à obtenir le score le plus élevé sur toutes les évaluations, mais établir un avantage unique sur trois dimensions : la fiabilité (faible hallucination), la vitesse et la collaboration multi-agents.
Avec un score d'indice d'intelligence Artificial Analysis de 48, il surpasse la médiane des modèles de même gamme (31), bien qu'il reste en retrait par rapport aux scores de pointe de Claude Opus 4.5 et GPT-5.4. La stratégie d'xAI est simple : plutôt que de vous proposer un modèle occasionnellement brillant mais souvent erroné, autant vous offrir un modèle toujours fiable.
Analyse détaillée des capacités de Grok 4.20 Beta
Capacité 1 : Le taux d'hallucination le plus bas du secteur
La force majeure de Grok 4.20 Beta réside dans son contrôle des hallucinations :
| Évaluation | Grok 4.20 | Moyenne du secteur | Remarques |
|---|---|---|---|
| Taux sans hallucination AA-Omniscience | 78 % | ~60-70 % | Meilleur du secteur |
| Suivi des instructions | Excellent | – | Respect strict de l'invite |
| Mise en page LaTeX | Optimisation continue | – | Amélioré en avril |
Un taux de 78 % sans hallucination signifie que pour les questions factuelles, Grok 4.20 fournit une réponse exacte dans environ 4 cas sur 5, ce qui en fait le modèle le plus performant parmi ceux testés. Pour les domaines exigeant une fiabilité absolue (conseils médicaux, analyse juridique, recherche universitaire), ce faible taux d'hallucination est souvent plus précieux qu'un simple "indice d'intelligence" élevé.
Optimisations continues d'avril : La dernière itération améliore encore le suivi des instructions, la mise en page des formules mathématiques LaTeX, ainsi que la précision du déclenchement de la recherche d'images.
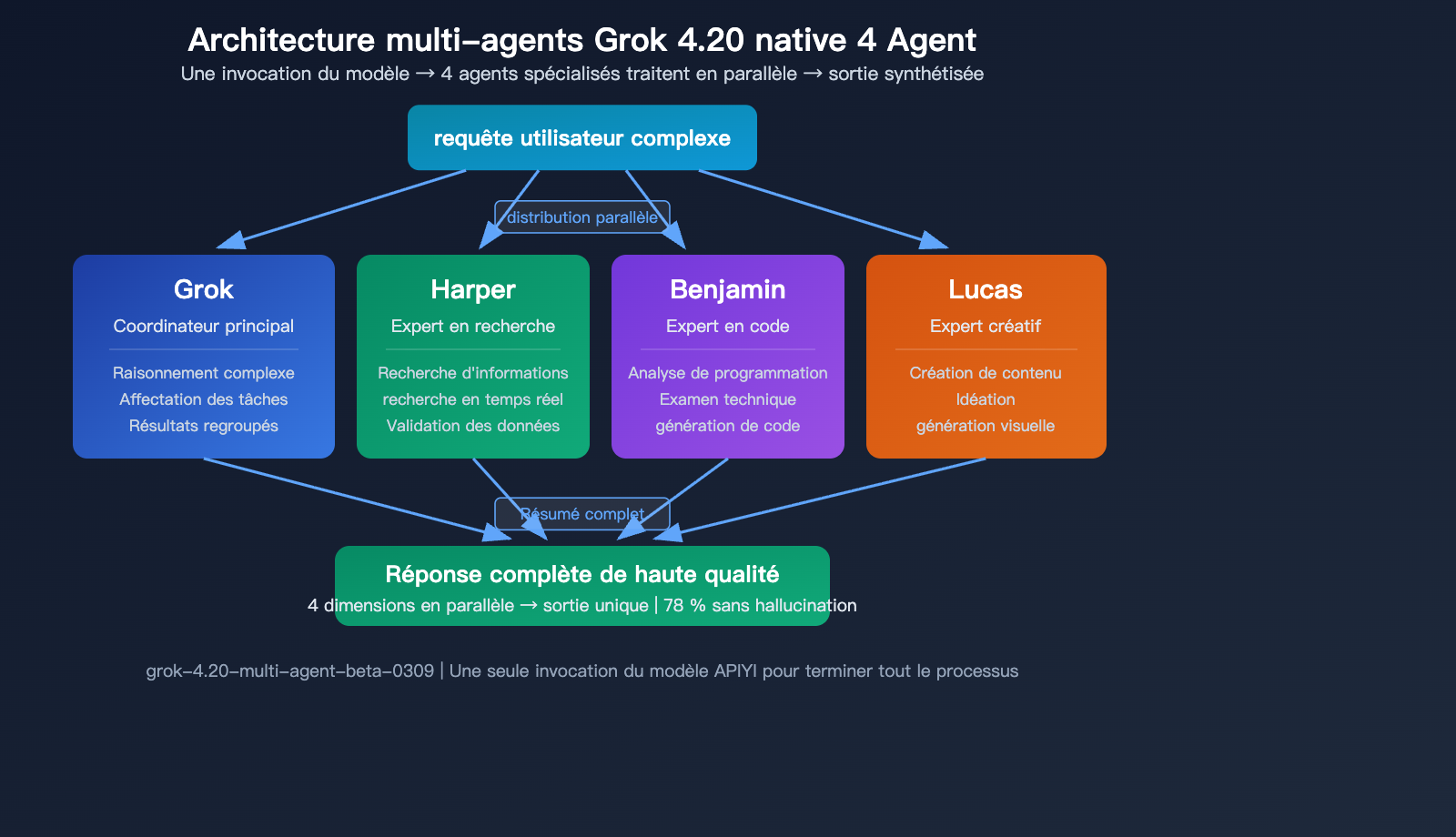
Capacité 2 : Architecture multi-agents native à 4 agents
Grok 4.20 Beta introduit la première API multi-agents native du secteur : une seule invocation d'API déclenche 4 agents spécialisés travaillant en parallèle en arrière-plan :
| Nom de l'agent | Spécialité | Rôle |
|---|---|---|
| Grok | Raisonnement et dialogue | Coordinateur principal |
| Harper | Recherche et extraction d'infos | Expert en recherche |
| Benjamin | Programmation et analyse technique | Expert en code |
| Lucas | Créativité et génération de contenu | Expert créatif |
Lorsque vous envoyez une requête complexe via l'API multi-agents, les 4 agents travaillent simultanément en parallèle, chacun apportant son expertise, avant que Grok ne synthétise le tout. Cette architecture est bien plus efficace pour traiter des tâches complexes nécessitant des compétences multidimensionnelles.
Capacité 3 : Fenêtre de contexte de 2 millions de jetons
La fenêtre de contexte de Grok 4.20 passe de 256 000 jetons sur la génération précédente à 2 millions de jetons, soit la plus longue parmi tous les modèles API grand public actuels :
| Modèle | Fenêtre de contexte | Comparaison |
|---|---|---|
| Grok 4.20 Beta | 2 millions de jetons | La plus longue du secteur |
| GPT-5.4 (extension) | 1 million de jetons | 2x Grok |
| Claude Opus 4.5 | 200 000 jetons | 10x Grok |
| Gemini 2.5 Pro | 1 million de jetons | 2x Grok |
2 millions de jetons équivalent à environ 1,5 million de caractères chinois ou 3 millions de mots anglais, de quoi contenir un roman complet ou un vaste dépôt de code.
🎯 Conseil aux développeurs : Grok 4.20 Beta se distingue par son contrôle des hallucinations et sa longueur de contexte. Via le service proxy API APIYI (apiyi.com), vous pouvez accéder simultanément à Grok 4.20, Claude et GPT pour comparer la fiabilité et la précision des différents modèles sur vos tâches réelles.
3 variantes du modèle Grok 4.20 Beta
La famille de modèles Grok 4.20
xAI a lancé 3 variantes distinctes de Grok 4.20, proposées au même tarif mais avec des capacités spécifiques :
| Variante | ID du modèle | Capacités clés | Cas d'usage |
|---|---|---|---|
| Non-Reasoning | grok-4.20-beta-0309-non-reasoning | Réponses rapides et directes | Conversations quotidiennes, tâches simples |
| Reasoning | grok-4.20-beta-0309-reasoning | Chaîne de réflexion approfondie | Analyse complexe, mathématiques |
| Multi-Agent | grok-4.20-multi-agent-beta-0309 | 4 agents en parallèle | Tâches multidimensionnelles complexes |
Analyse tarifaire de Grok 4.20
| Élément tarifaire | Grok 4.20 | Grok 4 (génération précédente) | Évolution |
|---|---|---|---|
| Entrée | 2 $/MTok | 3 $/MTok | -33 % |
| Sortie | 6 $/MTok | 15 $/MTok | -60 % |
| Trois variantes | Prix identique | – | Choix selon les besoins |
La tarification de Grok 4.20 est extrêmement compétitive : 2 $ en entrée et 6 $ en sortie, soit une baisse de 33 à 60 % par rapport au Grok 4. Comparé à la concurrence : le GPT-5.4 standard est à 2,5 $/15 $ et Claude Opus 4.5 est plus onéreux. Parmi les modèles de même gamme, Grok 4.20 affiche le taux d'hallucination le plus bas et la vitesse la plus élevée (247,8 tok/s).
Architecture Rapid Learning de Grok 4.20
L'une des technologies uniques de Grok 4.20 est son architecture Rapid Learning (apprentissage rapide) : le modèle met automatiquement à jour ses capacités chaque semaine en se basant sur les données d'utilisation réelles des utilisateurs, sans nécessiter la publication manuelle d'une nouvelle version. Cela signifie que le Grok 4.20 que vous utilisez s'améliore continuellement avec le temps — le Grok 4.20 d'avril est déjà plus performant que la version de février.
💡 Avantage différenciateur : Le Rapid Learning est exclusif à Grok — là où les autres modèles nécessitent une nouvelle version pour être mis à jour, Grok 4.20 évolue en continu au sein de la même version. C'est pourquoi cette "itération continue d'avril" est cruciale pour les utilisateurs de Grok.
Capacités multimodales de Grok 4.20 Beta
Matrice multimodale complète de Grok 4.20
| Modalité | Entrée | Sortie | Description |
|---|---|---|---|
| Texte | ✓ | ✓ | Capacité principale |
| Image | ✓ | ✓ | API Grok Imagine |
| Vidéo | ✓ | ✓ | Génération vidéo de bout en bout |
| Audio | ✓ | ✓ | Grok Voice à faible latence |
| Code | ✓ | ✓ | Spécialité de l'agent Benjamin |
| Recherche | – | ✓ | Recherche web en temps réel |
Capacités vocales avec Grok Voice
Grok Voice est l'une des capacités multimodales les plus différenciantes de Grok 4.20 :
- Voix à faible latence : Prise en charge de conversations vocales en temps réel dans des dizaines de langues
- Appel d'outils : Possibilité de déclencher des outils et des recherches en mode vocal
- Données en temps réel : Accès aux données web en direct pendant les conversations vocales
- API Agent : Intégration possible dans des applications tierces via API
Cela fait de Grok 4.20 bien plus qu'un simple modèle textuel : c'est un assistant IA multimodal capable d'"écouter, parler, voir et chercher".
Génération d'images et de vidéos avec Grok Imagine
xAI a introduit dans Grok 4.20 l'API Grok Imagine, une suite unifiée de génération vidéo et audio de bout en bout. Elle permet de générer des images et des vidéos à partir de descriptions textuelles, et la précision du déclenchement de la recherche d'images a été encore améliorée lors de la mise à jour d'avril.

Comparatif : Grok 4.20 Beta face à ses concurrents
Grok 4.20 vs GPT-5.4 vs Claude Opus 4.5
| Dimension de comparaison | Grok 4.20 Beta | GPT-5.4 | Claude Opus 4.5 |
|---|---|---|---|
| Taux d'hallucination | 78 % (le plus bas) | ~65 % | ~70 % |
| Indice d'intelligence | 48 | ~55+ | ~55+ |
| Fenêtre de contexte | 2 millions de jetons | 272K-1M | 200K |
| Vitesse de sortie | 247,8 jetons/s | ~100 jetons/s | ~80 jetons/s |
| Prix d'entrée | 2 $/MTok | 2,5 $/MTok | Plus élevé |
| Prix de sortie | 6 $/MTok | 15 $/MTok | Plus élevé |
| Multi-agents | 4 agents natifs | Aucun | Aucun |
| Dialogue vocal | Support natif | Limité | Aucun |
| Contrôle PC | Aucun | Support natif | Limité |
| Évaluation programmation | Moyen-supérieur | Top niveau | Top niveau |
Points forts de Grok 4.20 : contrôle des hallucinations, vitesse, tarification, longueur de la fenêtre de contexte, multi-agents, voix.
Points faibles de Grok 4.20 : intelligence pure/raisonnement, évaluation spécialisée en programmation.
Conseil de sélection : Si vous privilégiez la précision et la fiabilité des réponses, Grok 4.20 est le choix idéal. Si vous misez tout sur les capacités de programmation et le raisonnement complexe, Claude ou GPT restent supérieurs.
🚀 Conseil de comparaison : Grâce à APIYI (apiyi.com), vous pouvez accéder simultanément à Grok 4.20, GPT-5.4 et Claude. Une seule clé API suffit pour basculer librement entre les trois modèles et trouver rapidement celui qui convient le mieux à votre cas d'usage.
Intégration de l'API Grok 4.20 Beta
Accès rapide via APIYI
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1"
)
# Mode Non-Reasoning (réponse rapide)
response = client.chat.completions.create(
model="grok-4.20-beta-0309-non-reasoning",
messages=[{"role": "user", "content": "Explique les principes fondamentaux de l'informatique quantique"}]
)
print(response.choices[0].message.content)
Voir les appels pour les modes Reasoning et Multi-Agent
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://vip.apiyi.com/v1"
)
# Mode Reasoning (raisonnement approfondi)
response = client.chat.completions.create(
model="grok-4.20-beta-0309-reasoning",
messages=[{"role": "user", "content": "Analyse les risques de la chaîne d'approvisionnement mondiale en puces IA"}]
)
# Mode Multi-Agent (4 agents en parallèle)
response = client.chat.completions.create(
model="grok-4.20-multi-agent-beta-0309",
messages=[{
"role": "user",
"content": "Rédige un rapport de recherche sur les perspectives commerciales de l'informatique quantique"
}]
)
# 4 agents (Grok/Harper/Benjamin/Lucas) traitent la demande en parallèle
print(response.choices[0].message.content)
💰 Avantage coût : La tarification de 2 $/6 $ de Grok 4.20 est l'une des plus basses parmi les modèles phares actuels. L'utilisation via APIYI (apiyi.com) permet d'optimiser davantage vos coûts tout en supportant une commutation à la demande entre Grok, Claude, GPT et Gemini.
FAQ
Q1 : Lequel des trois modèles Grok 4.20 choisir ?
Pour les conversations quotidiennes, optez pour le modèle Non-Reasoning (le plus rapide) ; pour des analyses complexes, choisissez Reasoning (plus approfondi) ; et pour des tâches complexes multidimensionnelles, privilégiez Multi-Agent (4 agents en parallèle). Les trois variantes ont la même tarification (2 $/6 $ par million de jetons), vous pouvez donc basculer librement selon vos besoins. Une seule clé API via APIYI (apiyi.com) suffit pour invoquer toutes ces variantes.
Q2 : Que signifie le taux d’hallucination le plus bas de Grok 4.20 ?
Un taux de non-hallucination de 78 % signifie que, pour les réponses factuelles, Grok est moins enclin à "inventer" des informations que les autres modèles. Pour les scénarios exigeant une grande fiabilité (médical, juridique, académique, décisions d'entreprise), cela a plus de valeur pratique qu'un simple "indice d'intelligence" élevé. Cependant, pour l'écriture créative et le brainstorming, une "hallucination" modérée peut parfois s'avérer être un avantage.
Q3 : Grok 4.20 continuera-t-il à être mis à jour ?
Oui. Grok 4.20 adopte une architecture d'apprentissage rapide (Rapid Learning), optimisée automatiquement chaque semaine en fonction des données d'utilisation des utilisateurs. La mise à jour d'avril a déjà amélioré le suivi des instructions, la mise en forme LaTeX et la recherche d'images. Les capacités sous le même ID de modèle continueront de progresser sans qu'il soit nécessaire d'attendre un nouveau numéro de version. En passant par APIYI (apiyi.com), vous bénéficiez automatiquement des dernières optimisations.
Résumé
Le verdict sur la valeur fondamentale de Grok 4.20 Beta :
- Taux d'hallucination le plus bas du secteur : 78 % de non-hallucination, offrant un avantage unique dans les scénarios nécessitant une haute fiabilité.
- Multi-agent natif : 4 agents (Grok/Harper/Benjamin/Lucas) collaborant en parallèle pour une efficacité accrue sur les tâches complexes.
- Fenêtre de contexte ultra-longue de 2 millions de jetons : La plus longue parmi les modèles API grand public, associée à une vitesse impressionnante de 247,8 jetons/s.
- Évolution continue : Mises à jour automatiques hebdomadaires via Rapid Learning ; la version d'avril est déjà plus performante que celle du lancement en février.
Grok 4.20 Beta a choisi une voie différenciée : plutôt que de chercher à être le meilleur partout, il se positionne comme leader sur trois dimensions : la fiabilité, la vitesse et l'approche multi-agent. Nous vous recommandons d'accéder à Grok 4.20, ainsi qu'à Claude et GPT, via APIYI (apiyi.com) avec une seule clé API, afin de comparer les modèles et de trouver la solution la mieux adaptée à vos besoins.
📚 Références
-
Actualités officielles de xAI sur Grok 4.20 : Dernières mises à jour et annonces de fonctionnalités
- Lien :
x.ai/news - Description : Contient le journal d'itération continue et les mises à jour des fonctionnalités de Grok 4.20
- Lien :
-
Artificial Analysis – Évaluation de Grok 4.20 : Évaluations et données tierces indépendantes
- Lien :
artificialanalysis.ai/models/grok-4-20 - Description : Inclut une analyse détaillée de l'indice d'intelligence, du taux d'hallucination, de la vitesse et de la tarification
- Lien :
-
Détails sur les multi-agents de Grok 4.20 : Comparaison complète des 4 variantes de modèles
- Lien :
help.apiyi.com/en/grok-4-20-beta-4-models-multi-agent-reasoning-api-guide-en.html - Description : Couvre les scénarios d'utilisation détaillés pour le raisonnement (Reasoning), le non-raisonnement (Non-Reasoning) et les multi-agents
- Lien :
-
Analyse complète de Grok 4.20 Beta : Analyse approfondie de l'architecture et des fonctionnalités
- Lien :
buildfastwithai.com/blogs/grok-4-20-beta-explained-2026 - Description : Détaille l'architecture Rapid Learning et les capacités multimodales
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à partager votre expérience avec Grok 4.20 dans les commentaires. Pour plus d'informations sur l'intégration de modèles d'IA, consultez la documentation APIYI sur docs.apiyi.com