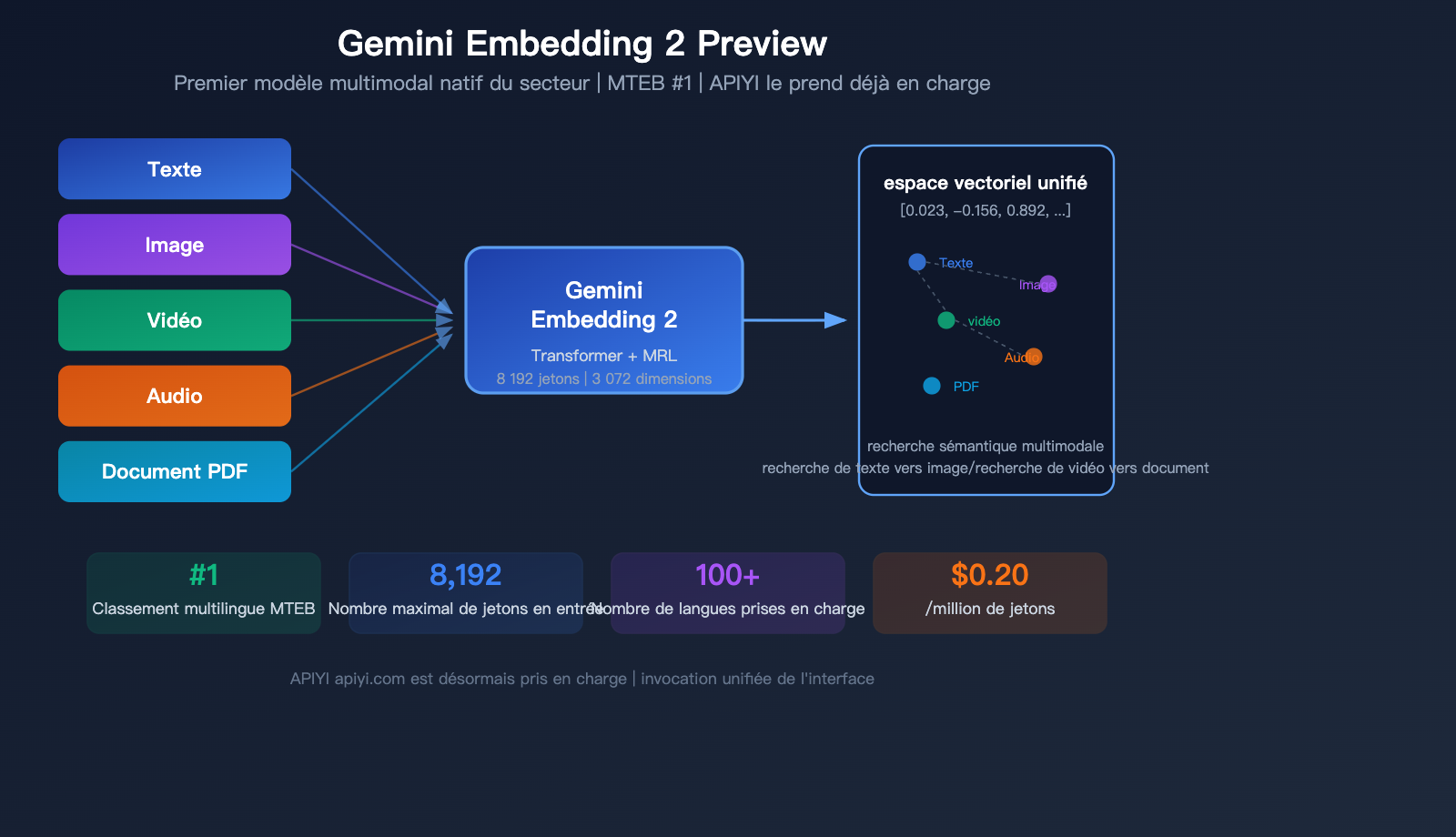
En mars 2026, Google a lancé un modèle majeur : Gemini Embedding 2 Preview, le premier modèle d'embedding multimodal natif de l'industrie. Il permet de mapper uniformément le texte, les images, les vidéos, l'audio et les documents PDF dans un même espace vectoriel. Il se classe premier au benchmark multilingue MTEB, avec plus de 5 points d'avance sur le second.
Valeur ajoutée : En lisant cet article, vous découvrirez les 5 percées techniques de Gemini Embedding 2 Preview, une comparaison de ses performances et de sa tarification face à la concurrence, ainsi que la manière de l'intégrer rapidement via API.
Qu'est-ce que Gemini Embedding 2 Preview ?
Gemini Embedding 2 Preview est le tout dernier modèle d'embedding publié par Google le 10 mars 2026. Initialisé sur l'architecture Gemini et utilisant une structure Transformer à attention bidirectionnelle, il s'agit du premier modèle d'embedding de Google à prendre en charge nativement les entrées multimodales.
| Spécifications | Détails |
|---|---|
| ID du modèle | gemini-embedding-2-preview |
| Date de sortie | 10 mars 2026 |
| État | Preview (version préliminaire, version finale à confirmer) |
| Dimension de sortie par défaut | 3 072 |
| Plage de dimensions optionnelles | 128 — 3 072 |
| Max Tokens en entrée | 8 192 (4 fois plus que la génération précédente) |
| Support multimodal | Texte, image, vidéo, audio, PDF |
| Support linguistique | Plus de 100 langues |
| Entraînement Matryoshka | Supporté (dimensions tronquables tout en conservant la qualité sémantique) |
| Plateformes disponibles | Gemini API, Vertex AI, APIYI apiyi.com |
Différences clés avec la génération précédente
| Caractéristique | text-embedding-004 | gemini-embedding-001 | gemini-embedding-2-preview |
|---|---|---|---|
| Max Tokens en entrée | 2 048 | 2 048 | 8 192 |
| Dimension de sortie | Jusqu'à 768 | 128-3 072 | 128-3 072 |
| Multimodal | Texte uniquement | Texte uniquement | Texte+Image+Vidéo+Audio+PDF |
| Spécification de tâche | Champ task_type |
Champ task_type |
Instructions intégrées à l'invite |
| Support MRL | Non supporté | Supporté | Supporté |
| Prix / million de tokens | Service arrêté | 0,15 $ | 0,20 $ |
🎯 Conseil d'intégration : APIYI apiyi.com prend déjà en charge l'invocation du modèle gemini-embedding-2-preview.
Vous pouvez l'intégrer via l'interface compatible OpenAI, sans avoir besoin de configurer une clé API Google séparée.
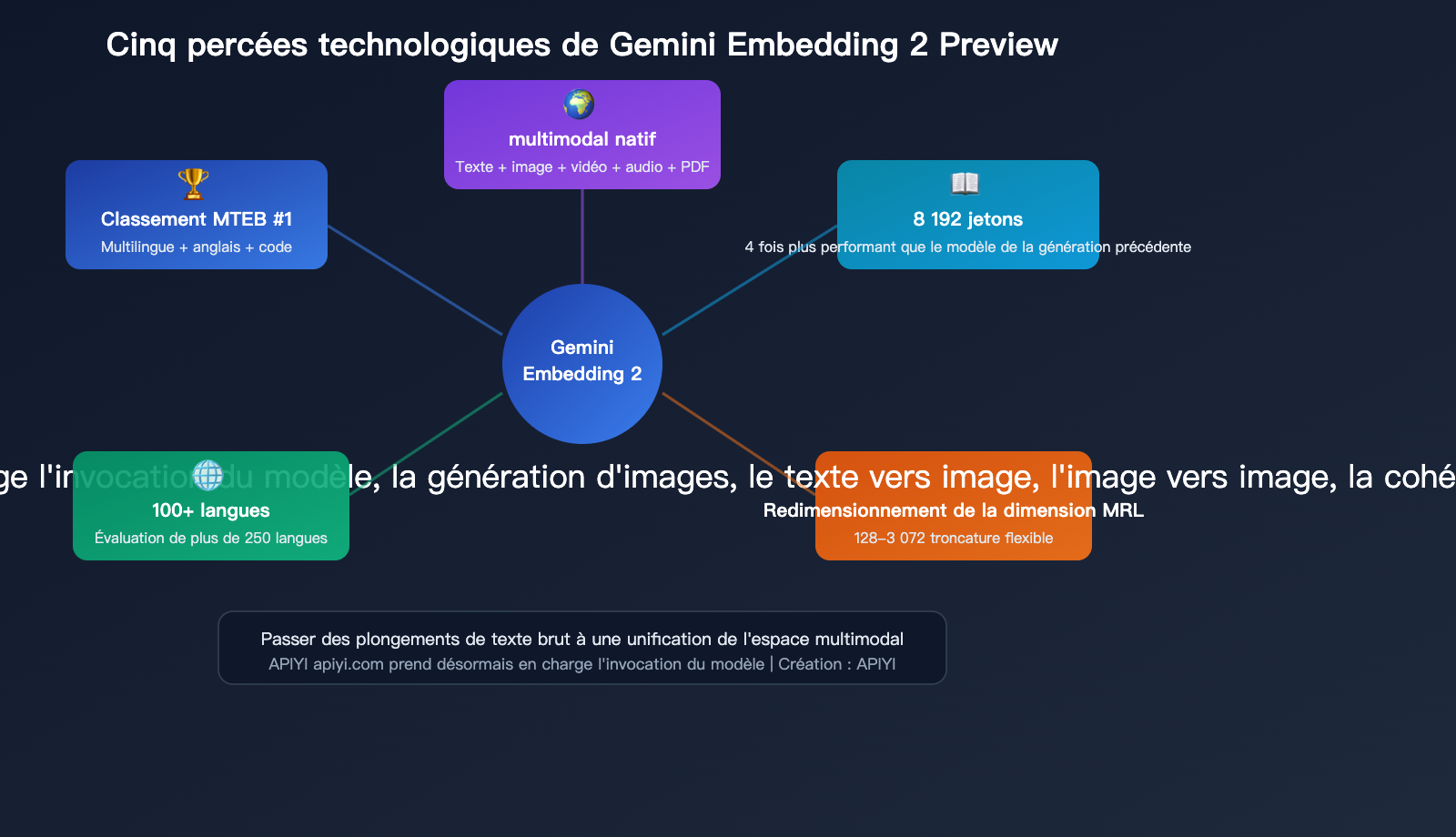
Analyse détaillée des 5 percées technologiques
Percée 1 : Espace d'embedding unifié et multimodal natif
C'est l'avantage différenciateur majeur de Gemini Embedding 2 : le contenu de 5 modalités est mappé dans le même espace vectoriel.
| Modalité | Exigences de format | Limite par requête | Note |
|---|---|---|---|
| Texte | Texte brut | 8 192 tokens | Supporte 100+ langues |
| Image | PNG, JPEG | Jusqu'à 6 par requête | Traitement direct des pixels |
| Vidéo | MP4, MOV | 120 secondes max | Échantillonnage auto jusqu'à 32 images |
| Audio | MP3, WAV | 80 secondes max | Traitement natif, sans transcription |
| Document PDF | Jusqu'à 6 pages par requête | Capacité OCR incluse |
Cas d'utilisation concrets :
- Rechercher des images avec du texte ("voiture de sport rouge sur circuit" → renvoie les images correspondantes)
- Rechercher des segments vidéo similaires à partir d'une image
- Rechercher des documents pertinents via une description vocale
- Construire une base de connaissances unifiée et intermodale
C'était impossible avec les modèles d'embedding précédents : la série text-embedding-3 d'OpenAI ne supporte que le texte. Pour la recherche d'images, il fallait auparavant utiliser un modèle visuel pour extraire une description avant l'embedding, ce qui ajoutait une étape et entraînait une perte d'informations.
Percée 2 : Fenêtre de contexte de 8 192 tokens
La fenêtre d'entrée passe de 2 048 à 8 192 tokens, ce qui signifie qu'il est désormais possible d'intégrer des segments de documents beaucoup plus longs.
Pour les systèmes RAG (génération augmentée par récupération), cette amélioration est très pratique :
- Auparavant, il fallait découper les documents en petits segments de 500 à 1 000 tokens.
- Désormais, vous pouvez utiliser de grands segments de 2 000 à 4 000 tokens, conservant ainsi davantage de contexte.
- Des segments plus grands = moins de découpage = des résultats de recherche plus complets.
Percée 3 : Mise à l'échelle dimensionnelle Matryoshka
Gemini Embedding 2 utilise l'entraînement Matryoshka Representation Learning (MRL), où le modèle concentre les informations sémantiques les plus importantes dans les premières dimensions du vecteur.
Cela signifie que vous pouvez choisir la dimension de manière flexible selon vos besoins :
| Dimension | Taille du vecteur | Cas d'utilisation | Perte de qualité |
|---|---|---|---|
| 3 072 (défaut) | 12,3 Ko | Recherche haute précision | Aucune |
| 1 536 | 6,1 Ko | Équilibre précision/stockage | Très faible |
| 768 | 3,1 Ko | Choix privilégié pour déploiement à grande échelle | Faible |
| 256 | 1,0 Ko | Systèmes de recommandation en temps réel | Moyenne |
| 128 | 0,5 Ko | Scénarios de compression extrême | Importante |
Note : Lors de l'utilisation de dimensions inférieures à 3 072, il est nécessaire de normaliser manuellement le vecteur avant de calculer la similarité.
Percée 4 : Support de plus de 100 langues
Dans les benchmarks multilingues MTEB, Gemini Embedding 2 a été évalué sur plus de 250 langues, couvrant une portée bien plus large que ses concurrents.
Indicateurs de performance clés :
- Minage de textes bilingues (Bitext Mining) : 79,32 points
- Recherche interlingue (XOR-Retrieve) : Recall@5kt 90,42 points
- Compréhension multilingue (XTREME-UP) : MRR@10 64,33 points
Percée 5 : N°1 dans plusieurs classements MTEB
| Benchmark | Score | Classement | Marge d'avance |
|---|---|---|---|
| MTEB Multilingue (Moyenne des tâches) | 68,32 | 1er | +5,09 |
| MTEB Multilingue (Moyenne par type) | 59,64 | 1er | — |
| MTEB Anglais v2 (Moyenne des tâches) | 73,30 | 1er | — |
| MTEB Anglais v2 (Moyenne par type) | 67,67 | 1er | — |
| MTEB Code (Moyenne globale) | 74,66 | 1er | — |
À titre de comparaison, le deuxième modèle, gte-Qwen2-7B-instruct, obtient un score de 62,51 sur le MTEB multilingue. Gemini Embedding 2 le devance de près de 6 points, ce qui représente un écart considérable dans le domaine des modèles d'embedding.
💡 Conseil de développement : Si vous construisez un système RAG ou une application de recherche sémantique,
Gemini Embedding 2 est actuellement le choix le plus puissant pour les scénarios multilingues et de code.
Via APIYI apiyi.com, vous pouvez accéder à ce modèle en un clic, tout en supportant les modèles d'embedding OpenAI,
ce qui facilite la comparaison rapide des résultats.
Comparaison des prix et des performances avec la concurrence
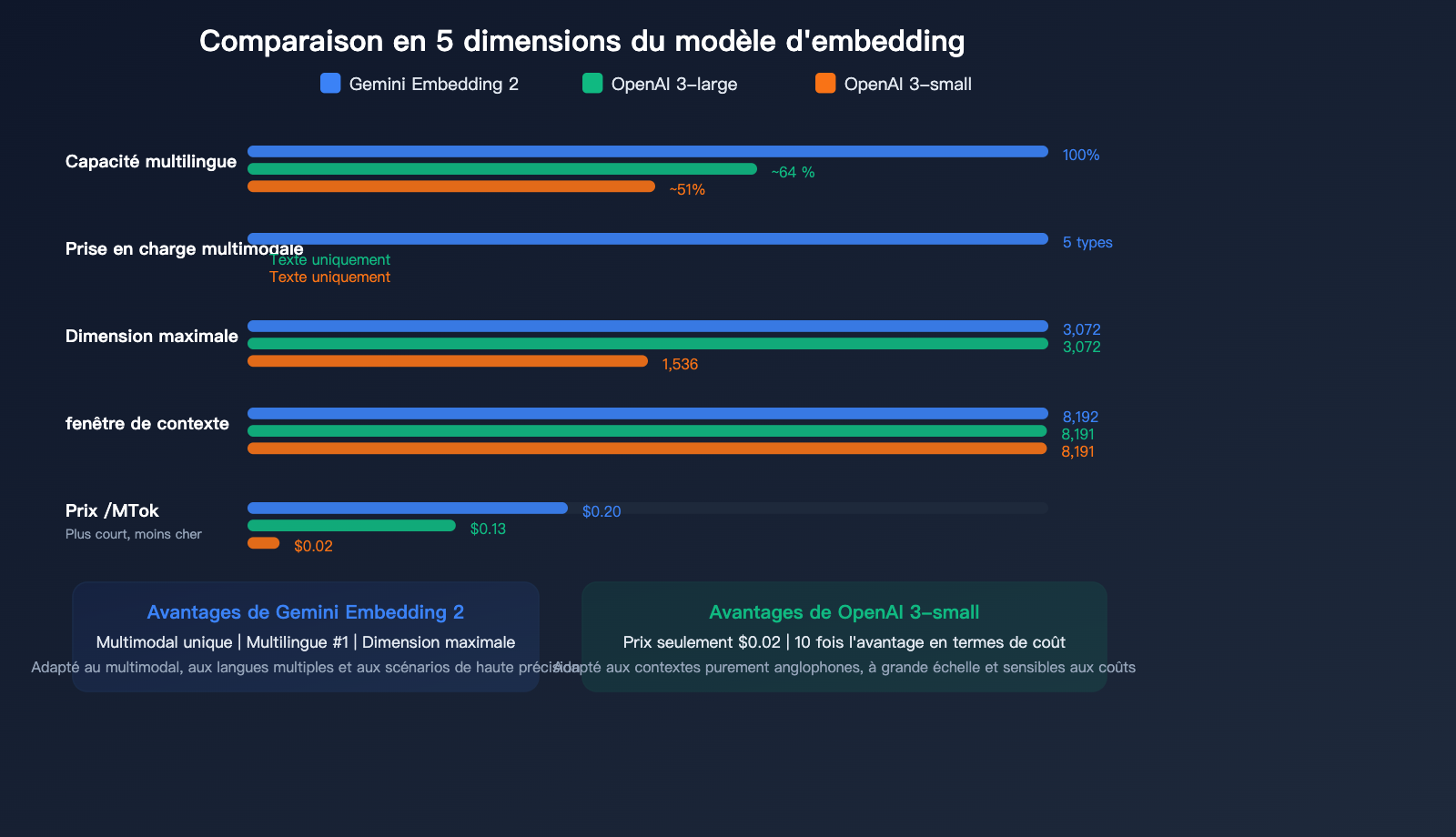
Comparaison des prix des embeddings textuels
| Modèle | Prix/M de tokens | Dimension max. | Entrée max. | Multimodal | Rang multilingue |
|---|---|---|---|---|---|
| Gemini Embedding 2 | 0,20 $ | 3 072 | 8 192 | ✅ 5 modes | #1 |
| gemini-embedding-001 | 0,15 $ | 3 072 | 2 048 | ❌ | — |
| OpenAI text-embedding-3-large | 0,13 $ | 3 072 | 8 191 | ❌ | — |
| OpenAI text-embedding-3-small | 0,02 $ | 1 536 | 8 191 | ❌ | — |
Tarification du contenu multimodal (exclusivité Gemini Embedding 2) :
| Type d'entrée | Prix standard/M de tokens | Prix par lot/M de tokens |
|---|---|---|
| Texte | 0,20 $ | 0,10 $ |
| Image | 0,45 $ (~0,00012 $/image) | 0,225 $ |
| Audio | 6,50 $ (~0,00016 $/sec) | 3,25 $ |
| Vidéo | 12,00 $ (~0,00079 $/frame) | 6,00 $ |
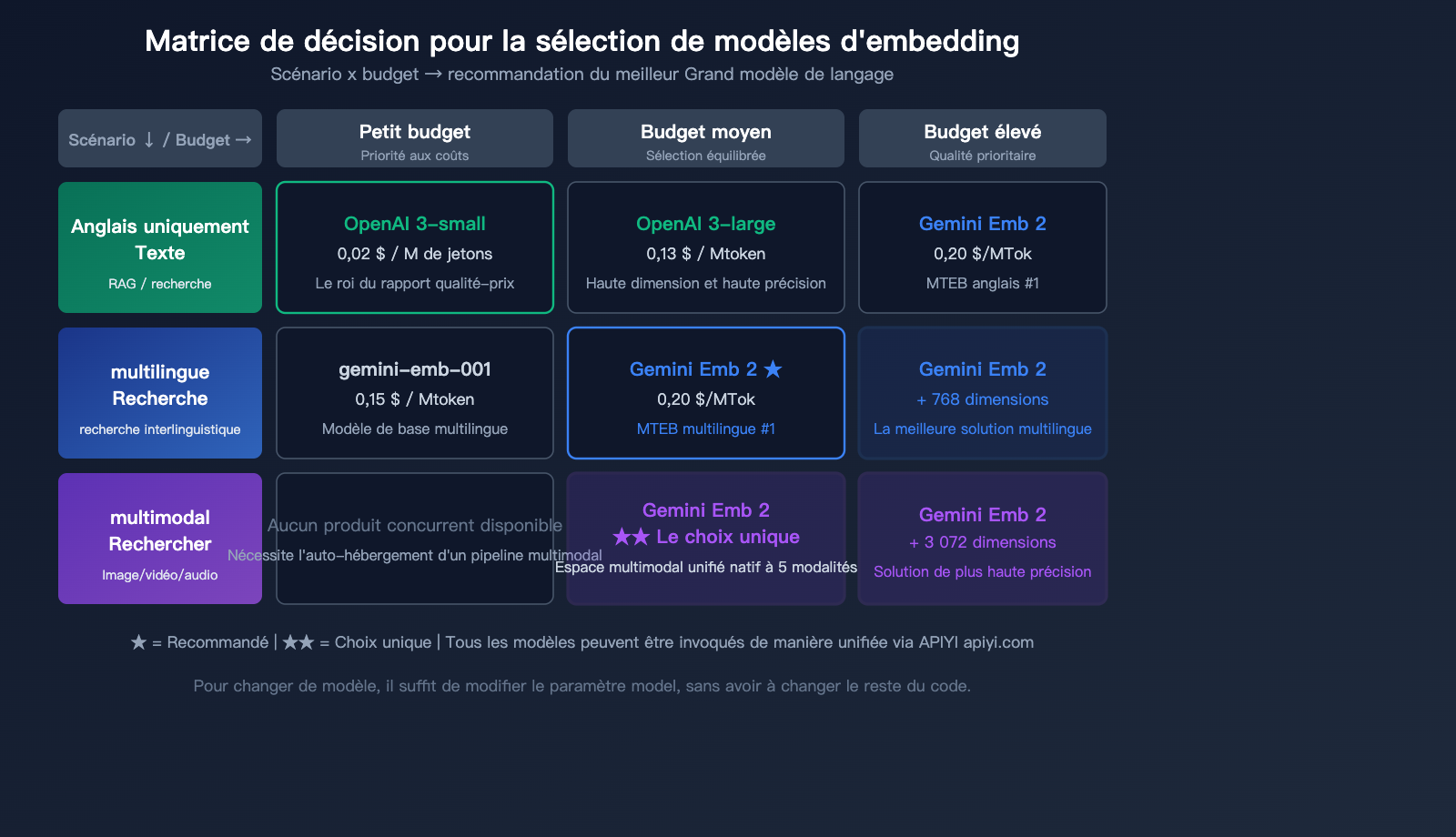
Conseils de sélection
| Scénario | Modèle recommandé | Raison |
|---|---|---|
| Texte pur, sensible au coût | OpenAI text-embedding-3-small | Le moins cher (0,02 $) |
| Texte pur, haute précision | Gemini Embedding 2 ou OpenAI 3-large | Précision similaire, Gemini meilleur en multilingue |
| Recherche multimodale | Gemini Embedding 2 | Seule solution native multimodale |
| Recherche multilingue | Gemini Embedding 2 | #1 MTEB multilingue |
| Recherche de code | Gemini Embedding 2 | #1 MTEB code |
| Volume massif, bas coût | OpenAI 3-small + API par lot | Avantage tarifaire x10 |
🎯 Conseil: Le choix du modèle d'embedding dépend de votre cas d'usage.
Nous vous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour tester simultanément les modèles Gemini et OpenAI.
Comparez les résultats de recherche avec vos propres données avant de décider. La plateforme offre une interface unifiée, permettant de changer de modèle sans modifier votre code.
Explication détaillée de l'invocation de l'API
Méthode de spécification du type de tâche (changement important)
Contrairement à gemini-embedding-001, Gemini Embedding 2 n'utilise plus le paramètre task_type. Vous devez désormais spécifier le type de tâche en intégrant des instructions directement dans le contenu d'entrée.
8 types de tâches pris en charge :
| Type de tâche | Format côté requête | Format côté document |
|---|---|---|
| Recherche/Récupération | task: search result | query: {contenu} |
title: {titre} | text: {contenu} |
| Questions-réponses | task: question answering | query: {question} |
title: {titre} | text: {contenu} |
| Vérification des faits | task: fact checking | query: {affirmation} |
title: {titre} | text: {contenu} |
| Récupération de code | task: code retrieval | query: {description} |
title: {titre} | text: {code} |
| Classification | task: classification | query: {contenu} |
Même format |
| Clustering | task: clustering | query: {contenu} |
Même format |
| Similarité de phrases | task: sentence similarity | query: {phrase} |
Même format |
Pour le côté document, si aucun titre n'est disponible, utilisez title: none.
Exemple d'invocation en Python
import openai
# Appel via l'interface unifiée d'APIYI
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Embedding de texte - scénario de recherche
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input="task: search result | query: qu'est-ce qu'une base de données vectorielle",
dimensions=768 # Dimensions optionnelles : 128-3072
)
embedding = response.data[0].embedding
print(f"Dimension du vecteur: {len(embedding)}")
print(f"5 premières valeurs: {embedding[:5]}")
Voir le code complet du processus de récupération RAG
import openai
import numpy as np
from typing import List
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def get_embedding(text: str, task: str = "search result", dim: int = 768) -> List[float]:
"""Obtenir le vecteur d'embedding de texte"""
formatted = f"task: {task} | query: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
# La dimension de troncature MRL nécessite une normalisation manuelle
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def get_doc_embedding(title: str, text: str, dim: int = 768) -> List[float]:
"""Obtenir le vecteur d'embedding de document"""
formatted = f"title: {title} | text: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def cosine_similarity(a: List[float], b: List[float]) -> float:
"""Calculer la similarité cosinus"""
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# Exemple d'utilisation
query_vec = get_embedding("Comment optimiser les résultats de récupération RAG")
doc_vec = get_doc_embedding(
"Guide d'optimisation RAG",
"Cet article présente 5 méthodes pour optimiser la qualité de récupération RAG..."
)
similarity = cosine_similarity(query_vec, doc_vec)
print(f"Similarité: {similarity:.4f}")
🚀 Démarrage rapide : Nous recommandons d'utiliser la plateforme APIYI (apiyi.com) pour intégrer rapidement Gemini Embedding 2.
Cette plateforme fournit une interface d'embedding compatible avec OpenAI, permettant une intégration en 5 minutes, tout en prenant en charge l'invocation unifiée des principaux modèles d'embedding comme OpenAI, Gemini et Cohere.
Précautions d'utilisation
Limitations de l'état Preview
| Limitation | Description | Impact |
|---|---|---|
| Changements de version | Les spécifications et la tarification peuvent évoluer durant la phase Preview | Prévoyez des solutions de repli pour l'environnement de production |
| Incompatibilité d'espace vectoriel | Impossible de mélanger avec les vecteurs d'anciens modèles | La mise à niveau nécessite une réindexation complète |
| Normalisation requise | Nécessite une normalisation manuelle pour les dimensions < 3 072 | Ajoutez une étape de normalisation dans votre code |
| Limites de débit strictes | Le quota du modèle Preview est inférieur à celui du modèle GA | Demandez une augmentation de quota pour une utilisation à grande échelle |
| Utilisation des données | Les données du niveau gratuit sont utilisées pour améliorer le produit | Utilisez le niveau payant pour les données sensibles |
Conseils pour la migration depuis d'anciens modèles
- Réindexation obligatoire : Les espaces vectoriels des différents modèles ne sont pas compatibles ; vous ne pouvez pas les mélanger dans la même base de données.
- Changement de format pour le type de tâche : Passage du paramètre
task_typeaux instructions intégrées dans l'invite. - Traitement de normalisation : Si vous utilisez une dimension autre que celle par défaut, vous devez ajouter une logique de normalisation dans votre code.
- Testez avant de migrer : Il est conseillé de comparer les performances de récupération entre les anciens et les nouveaux modèles dans un environnement de test avant de finaliser la migration.
Foire aux questions
Q1 : Quels sont les avantages de Gemini Embedding 2 Preview par rapport à OpenAI text-embedding-3-large ?
Les avantages principaux se situent sur trois points : une prise en charge native du multimodal (OpenAI ne gère que le texte), une première place au classement multilingue MTEB (avec une avance significative), et une meilleure qualité d'encodage de code. Cependant, OpenAI text-embedding-3-large est moins cher (0,13 $ contre 0,20 $) et, si vous n'avez besoin que d'encodages pour du texte anglais, les performances sont très proches. Via APIYI apiyi.com, vous pouvez invoquer les deux modèles pour les comparer avec vos propres données.
Q2 : À quoi servent concrètement les encodages multimodaux ?
L'application la plus directe est la recherche intermodale : l'utilisateur saisit du texte et le système renvoie des images, vidéos ou documents pertinents. Par exemple, dans le e-commerce, vous pouvez rechercher des produits avec "robe rouge", ou dans une base de connaissances d'entreprise, retrouver des segments spécifiques dans des vidéos de formation via une description textuelle. Auparavant, il fallait utiliser un modèle visuel pour extraire une description avant d'encadrer le texte ; Gemini Embedding 2 traite directement les images/vidéos brutes, limitant ainsi la perte d'informations.
Q3 : Quelle dimension choisir ? Y a-t-il une grande différence entre 768 et 3072 ?
Pour la plupart des applications, 768 dimensions constituent l'équilibre idéal : le coût de stockage est quatre fois inférieur à celui du 3072, avec une perte de qualité de recherche minime (grâce à l'entraînement Matryoshka). Si votre jeu de données est restreint (< 1 million d'entrées) et que vous exigez une précision maximale, utilisez 3072. Si vous gérez de gros volumes ou avez besoin d'une recherche en temps réel, 768, voire 256, sont des choix tout à fait pertinents.
Q4 : Comment APIYI prend-il en charge Gemini Embedding 2 ? Faut-il une configuration particulière ?
APIYI apiyi.com prend déjà en charge le modèle gemini-embedding-2-preview. Vous pouvez l'invoquer via l'interface d'encodage standard compatible avec OpenAI, sans avoir besoin d'une clé API Google supplémentaire. Il suffit de spécifier gemini-embedding-2-preview dans le paramètre model ; les autres paramètres (dimensions, etc.) sont strictement identiques à ceux de l'interface OpenAI.
Résumé : Une nouvelle référence pour les plongements multimodaux
Gemini Embedding 2 Preview marque une étape importante pour les modèles de plongement (embedding) : le passage d'une approche purement textuelle à un espace multimodal véritablement unifié. En décrochant la première place simultanément dans les dimensions multilingue, anglais et code du benchmark MTEB, et en y ajoutant une fenêtre de contexte de 8K ainsi que la flexibilité dimensionnelle MRL, il offre les capacités fondamentales les plus puissantes à ce jour pour les systèmes RAG, la recherche sémantique et la création de bases de connaissances.
Points clés à retenir :
- Premier modèle de plongement natif à cinq modalités de l'industrie (texte + image + vidéo + audio + PDF)
- 1ère place au benchmark multilingue MTEB, avec plus de 5 points d'avance
- Fenêtre de contexte de 8 192 jetons, soit 4 fois plus que la génération précédente
- Entraînement MRL prenant en charge une flexibilité dimensionnelle de 128 à 3 072
- Prix de 0,20 $ par million de jetons, un excellent rapport qualité-prix pour les scénarios multimodaux
Nous vous recommandons d'accéder rapidement à Gemini Embedding 2 Preview via APIYI (apiyi.com). Une seule clé API permet de prendre en charge les principaux modèles d'embedding comme Gemini et OpenAI, facilitant ainsi les comparaisons et les transitions.
📝 Auteur de cet article : Équipe technique APIYI | APIYI apiyi.com – Plateforme d'accès unifié à plus de 300 API de grands modèles de langage.
Références
-
Blog officiel de Google : Annonce de la sortie de Gemini Embedding 2
- Lien :
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/ - Description : Contient la philosophie de conception du modèle et une présentation de ses capacités multimodales.
- Lien :
-
Documentation de l'API Gemini Embedding : Guide d'utilisation officiel de l'API
- Lien :
ai.google.dev/gemini-api/docs/embeddings - Description : Paramètres complets de l'API et exemples d'invocation du modèle.
- Lien :
-
Article de recherche sur Gemini Embedding : Détails techniques et benchmarks
- Lien :
arxiv.org/html/2503.07891v1 - Description : Données de test détaillées du MTEB et analyse de l'architecture du modèle.
- Lien :
-
Tarification de l'API Gemini : Informations détaillées sur la tarification par modalité
- Lien :
ai.google.dev/gemini-api/docs/pricing - Description : Tarification détaillée pour le texte, l'image, l'audio et la vidéo.
- Lien :





